
| | |  ดูแหล่งที่มาบน GitHub ดูแหล่งที่มาบน GitHub | |
สมุดบันทึกนี้สาธิตการแปลรูปภาพเป็นรูปภาพแบบไม่จับคู่โดยใช้เงื่อนไข GAN ตามที่อธิบายไว้ใน การแปลรูปภาพเป็นรูปภาพที่ไม่จับคู่โดยใช้เครือข่ายปฏิปักษ์ที่สอดคล้องตามรอบ หรือที่เรียกว่า CycleGAN บทความนี้เสนอวิธีการที่สามารถจับภาพลักษณะของโดเมนรูปภาพหนึ่งๆ และค้นหาว่าคุณลักษณะเหล่านี้สามารถแปลเป็นโดเมนรูปภาพอื่นได้อย่างไร ทั้งหมดนี้ไม่มีตัวอย่างการฝึกอบรมที่จับคู่ไว้
สมุดบันทึกนี้ถือว่าคุณคุ้นเคยกับ Pix2Pix ซึ่งคุณสามารถเรียนรู้ได้ใน บทช่วยสอน Pix2Pix รหัสสำหรับ CycleGAN คล้ายกัน ข้อแตกต่างที่สำคัญคือฟังก์ชันการสูญเสียเพิ่มเติม และการใช้ข้อมูลการฝึกที่ไม่จับคู่
CycleGAN ใช้การสูญเสียความสม่ำเสมอของวงจรเพื่อเปิดใช้งานการฝึกอบรมโดยไม่จำเป็นต้องจับคู่ข้อมูล กล่าวอีกนัยหนึ่ง มันสามารถแปลจากโดเมนหนึ่งไปยังอีกโดเมนหนึ่งโดยไม่ต้องทำการแมปแบบหนึ่งต่อหนึ่งระหว่างโดเมนต้นทางและโดเมนเป้าหมาย
การทำเช่นนี้จะเปิดโอกาสในการทำงานที่น่าสนใจมากมาย เช่น การเพิ่มประสิทธิภาพของภาพถ่าย การปรับสีของรูปภาพ การถ่ายโอนสไตล์ ฯลฯ สิ่งที่คุณต้องมีคือแหล่งข้อมูลและชุดข้อมูลเป้าหมาย (ซึ่งเป็นเพียงไดเร็กทอรีของรูปภาพ)


ตั้งค่าไปป์ไลน์อินพุต
ติดตั้งแพ็คเกจ tensorflow_examples ที่เปิดใช้งานการนำเข้าตัวสร้างและตัวแบ่งแยก
pip install git+https://github.com/tensorflow/examples.git
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow_examples.models.pix2pix import pix2pix
import os
import time
import matplotlib.pyplot as plt
from IPython.display import clear_output
AUTOTUNE = tf.data.AUTOTUNE
อินพุตไปป์ไลน์
บทช่วยสอนนี้ฝึกแบบจำลองเพื่อแปลจากภาพม้าเป็นภาพม้าลาย คุณสามารถค้นหาชุดข้อมูลนี้และชุดข้อมูลที่คล้ายกันได้ที่ นี่
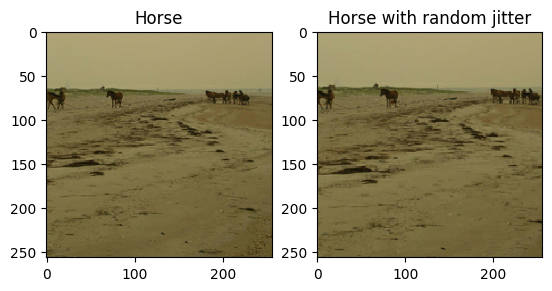
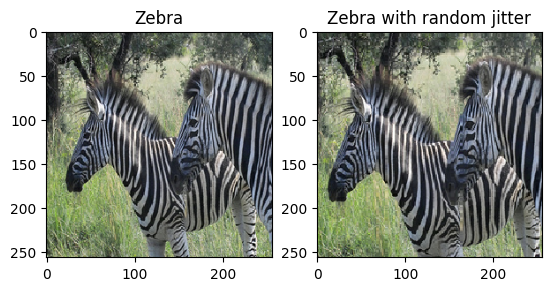
ตามที่กล่าวไว้ใน บทความ ให้ใช้การกระตุกแบบสุ่มและการมิเรอร์กับชุดข้อมูลการฝึกอบรม นี่คือเทคนิคการเพิ่มรูปภาพบางส่วนที่หลีกเลี่ยงไม่ให้เกินพอดี
สิ่งนี้คล้ายกับสิ่งที่ทำใน pix2pix
- ในการกระตุกแบบสุ่ม รูปภาพจะถูกปรับขนาดเป็น
286 x 286จากนั้นจึงครอบตัดแบบสุ่มเป็น256 x 256 - ในการสะท้อนแบบสุ่ม รูปภาพจะพลิกแบบสุ่มในแนวนอน กล่าวคือ ซ้ายไปขวา
dataset, metadata = tfds.load('cycle_gan/horse2zebra',
with_info=True, as_supervised=True)
train_horses, train_zebras = dataset['trainA'], dataset['trainB']
test_horses, test_zebras = dataset['testA'], dataset['testB']
BUFFER_SIZE = 1000
BATCH_SIZE = 1
IMG_WIDTH = 256
IMG_HEIGHT = 256
def random_crop(image):
cropped_image = tf.image.random_crop(
image, size=[IMG_HEIGHT, IMG_WIDTH, 3])
return cropped_image
# normalizing the images to [-1, 1]
def normalize(image):
image = tf.cast(image, tf.float32)
image = (image / 127.5) - 1
return image
def random_jitter(image):
# resizing to 286 x 286 x 3
image = tf.image.resize(image, [286, 286],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
# randomly cropping to 256 x 256 x 3
image = random_crop(image)
# random mirroring
image = tf.image.random_flip_left_right(image)
return image
def preprocess_image_train(image, label):
image = random_jitter(image)
image = normalize(image)
return image
def preprocess_image_test(image, label):
image = normalize(image)
return image
train_horses = train_horses.cache().map(
preprocess_image_train, num_parallel_calls=AUTOTUNE).shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
train_zebras = train_zebras.cache().map(
preprocess_image_train, num_parallel_calls=AUTOTUNE).shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
test_horses = test_horses.map(
preprocess_image_test, num_parallel_calls=AUTOTUNE).cache().shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
test_zebras = test_zebras.map(
preprocess_image_test, num_parallel_calls=AUTOTUNE).cache().shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
sample_horse = next(iter(train_horses))
sample_zebra = next(iter(train_zebras))
2022-01-26 02:38:15.762422: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead. 2022-01-26 02:38:19.927846: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
plt.subplot(121)
plt.title('Horse')
plt.imshow(sample_horse[0] * 0.5 + 0.5)
plt.subplot(122)
plt.title('Horse with random jitter')
plt.imshow(random_jitter(sample_horse[0]) * 0.5 + 0.5)
<matplotlib.image.AxesImage at 0x7f7cf83e0050>
plt.subplot(121)
plt.title('Zebra')
plt.imshow(sample_zebra[0] * 0.5 + 0.5)
plt.subplot(122)
plt.title('Zebra with random jitter')
plt.imshow(random_jitter(sample_zebra[0]) * 0.5 + 0.5)
<matplotlib.image.AxesImage at 0x7f7cf8139490>
นำเข้าและนำโมเดล Pix2Pix กลับมาใช้ใหม่
นำเข้าตัวสร้างและตัวจำแนกที่ใช้ใน Pix2Pix ผ่านแพ็คเกจ tensorflow_examples ที่ติดตั้ง
สถาปัตยกรรมแบบจำลองที่ใช้ในบทช่วยสอนนี้คล้ายกับที่ใช้ใน pix2pix มาก ความแตกต่างบางประการคือ:
- Cyclegan ใช้ การทำให้เป็นมาตรฐานของอินสแตนซ์ แทน การทำให้เป็นมาตรฐานแบบแบ ตช์
- กระดาษ
resnetใช้เครื่องกำเนิดสัญญาณ Resnet ที่ดัดแปลง บทช่วยสอนนี้ใช้ตัวสร้างunetที่แก้ไขแล้วเพื่อความง่าย
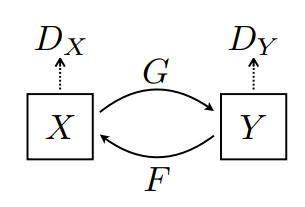
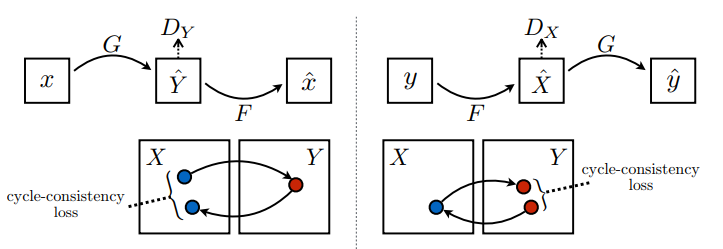
มีเครื่องกำเนิดไฟฟ้า 2 เครื่อง (G และ F) และ 2 เครื่องแยกความแตกต่าง (X และ Y) กำลังได้รับการฝึกอบรมที่นี่
- Generator
Gเรียนรู้ที่จะแปลงภาพXเป็นภาพY\((G: X -> Y)\) - ตัวสร้าง
Fเรียนรู้ที่จะแปลงรูปภาพYเป็นรูปภาพX\((F: Y -> X)\) - Discriminator
D_Xเรียนรู้ที่จะแยกความแตกต่างระหว่างรูปภาพXและรูปภาพที่สร้างขึ้นX(F(Y)) - Discriminator
D_Yเรียนรู้ที่จะแยกความแตกต่างระหว่างรูปภาพYและรูปภาพที่สร้างขึ้นY(G(X))
OUTPUT_CHANNELS = 3
generator_g = pix2pix.unet_generator(OUTPUT_CHANNELS, norm_type='instancenorm')
generator_f = pix2pix.unet_generator(OUTPUT_CHANNELS, norm_type='instancenorm')
discriminator_x = pix2pix.discriminator(norm_type='instancenorm', target=False)
discriminator_y = pix2pix.discriminator(norm_type='instancenorm', target=False)
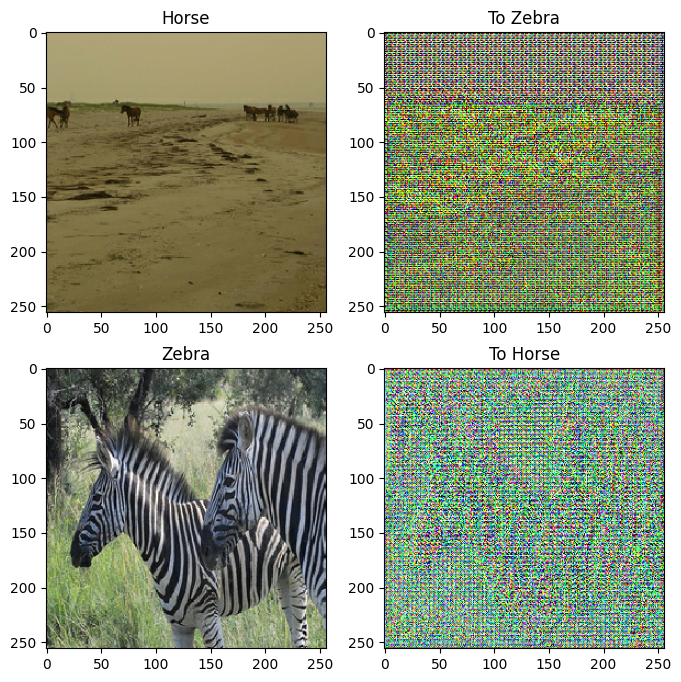
to_zebra = generator_g(sample_horse)
to_horse = generator_f(sample_zebra)
plt.figure(figsize=(8, 8))
contrast = 8
imgs = [sample_horse, to_zebra, sample_zebra, to_horse]
title = ['Horse', 'To Zebra', 'Zebra', 'To Horse']
for i in range(len(imgs)):
plt.subplot(2, 2, i+1)
plt.title(title[i])
if i % 2 == 0:
plt.imshow(imgs[i][0] * 0.5 + 0.5)
else:
plt.imshow(imgs[i][0] * 0.5 * contrast + 0.5)
plt.show()
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
plt.figure(figsize=(8, 8))
plt.subplot(121)
plt.title('Is a real zebra?')
plt.imshow(discriminator_y(sample_zebra)[0, ..., -1], cmap='RdBu_r')
plt.subplot(122)
plt.title('Is a real horse?')
plt.imshow(discriminator_x(sample_horse)[0, ..., -1], cmap='RdBu_r')
plt.show()

ฟังก์ชั่นการสูญเสีย
ใน CycleGAN ไม่มีข้อมูลคู่ที่จะฝึก ดังนั้นจึงไม่มีการรับประกันว่าอินพุต x และคู่เป้าหมาย y มีความหมายระหว่างการฝึก ดังนั้น เพื่อบังคับให้เครือข่ายเรียนรู้การทำแผนที่ที่ถูกต้อง ผู้เขียนเสนอการสูญเสียความสม่ำเสมอของวงจร
การสูญเสียการแบ่งแยกและการสูญเสียเครื่องกำเนิดจะคล้ายกับที่ใช้ใน pix2pix
LAMBDA = 10
loss_obj = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def discriminator_loss(real, generated):
real_loss = loss_obj(tf.ones_like(real), real)
generated_loss = loss_obj(tf.zeros_like(generated), generated)
total_disc_loss = real_loss + generated_loss
return total_disc_loss * 0.5
def generator_loss(generated):
return loss_obj(tf.ones_like(generated), generated)
ความสม่ำเสมอของวงจรหมายถึงผลลัพธ์ควรใกล้เคียงกับอินพุตดั้งเดิม ตัวอย่างเช่น หากใครแปลประโยคจากภาษาอังกฤษเป็นภาษาฝรั่งเศส แล้วแปลกลับจากภาษาฝรั่งเศสเป็นภาษาอังกฤษ ประโยคผลลัพธ์ควรเหมือนกับประโยคต้นฉบับ
ในการสูญเสียความสม่ำเสมอของวงจร
- รูปภาพ \(X\) ถูกส่งผ่านตัวสร้าง \(G\) ที่ให้ผลตอบแทนที่สร้างภาพ \(\hat{Y}\)
- รูปภาพที่สร้าง \(\hat{Y}\) ถูกส่งผ่านตัวสร้าง \(F\) ที่ให้ผลลัพธ์ \(\hat{X}\)
- ค่าความผิดพลาดแบบสัมบูรณ์เฉลี่ยคำนวณระหว่าง \(X\) และ \(\hat{X}\)
\[forward\ cycle\ consistency\ loss: X -> G(X) -> F(G(X)) \sim \hat{X}\]
\[backward\ cycle\ consistency\ loss: Y -> F(Y) -> G(F(Y)) \sim \hat{Y}\]
def calc_cycle_loss(real_image, cycled_image):
loss1 = tf.reduce_mean(tf.abs(real_image - cycled_image))
return LAMBDA * loss1
ดังที่แสดงไว้ด้านบน ตัวกำเนิด \(G\) มีหน้าที่แปลรูปภาพ \(X\) เป็นรูปภาพ \(Y\)การสูญเสียข้อมูลประจำตัวบอกว่าหากคุณป้อน image \(Y\) ให้กับเครื่องกำเนิดไฟฟ้า \(G\)มันควรจะได้ภาพจริง \(Y\) หรือสิ่งที่ใกล้เคียงกับภาพ \(Y\)
หากคุณเรียกใช้โมเดล zebra-to-horse บนม้า หรือ แบบจำลอง horse-to-zebra บนม้าลาย โมเดลนั้นไม่ควรแก้ไขรูปภาพมากนัก เนื่องจากรูปภาพมีคลาสเป้าหมายอยู่แล้ว
\[Identity\ loss = |G(Y) - Y| + |F(X) - X|\]
def identity_loss(real_image, same_image):
loss = tf.reduce_mean(tf.abs(real_image - same_image))
return LAMBDA * 0.5 * loss
เริ่มต้นเครื่องมือเพิ่มประสิทธิภาพสำหรับตัวสร้างและตัวแบ่งแยกทั้งหมด
generator_g_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
generator_f_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_x_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_y_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
จุดตรวจ
checkpoint_path = "./checkpoints/train"
ckpt = tf.train.Checkpoint(generator_g=generator_g,
generator_f=generator_f,
discriminator_x=discriminator_x,
discriminator_y=discriminator_y,
generator_g_optimizer=generator_g_optimizer,
generator_f_optimizer=generator_f_optimizer,
discriminator_x_optimizer=discriminator_x_optimizer,
discriminator_y_optimizer=discriminator_y_optimizer)
ckpt_manager = tf.train.CheckpointManager(ckpt, checkpoint_path, max_to_keep=5)
# if a checkpoint exists, restore the latest checkpoint.
if ckpt_manager.latest_checkpoint:
ckpt.restore(ckpt_manager.latest_checkpoint)
print ('Latest checkpoint restored!!')
การฝึกอบรม
EPOCHS = 40
def generate_images(model, test_input):
prediction = model(test_input)
plt.figure(figsize=(12, 12))
display_list = [test_input[0], prediction[0]]
title = ['Input Image', 'Predicted Image']
for i in range(2):
plt.subplot(1, 2, i+1)
plt.title(title[i])
# getting the pixel values between [0, 1] to plot it.
plt.imshow(display_list[i] * 0.5 + 0.5)
plt.axis('off')
plt.show()
แม้ว่าวงจรการฝึกจะดูซับซ้อน แต่ก็มีสี่ขั้นตอนพื้นฐาน:
- รับคำทำนาย.
- คำนวณการสูญเสีย
- คำนวณการไล่ระดับสีโดยใช้ backpropagation
- ใช้การไล่ระดับสีกับเครื่องมือเพิ่มประสิทธิภาพ
@tf.function
def train_step(real_x, real_y):
# persistent is set to True because the tape is used more than
# once to calculate the gradients.
with tf.GradientTape(persistent=True) as tape:
# Generator G translates X -> Y
# Generator F translates Y -> X.
fake_y = generator_g(real_x, training=True)
cycled_x = generator_f(fake_y, training=True)
fake_x = generator_f(real_y, training=True)
cycled_y = generator_g(fake_x, training=True)
# same_x and same_y are used for identity loss.
same_x = generator_f(real_x, training=True)
same_y = generator_g(real_y, training=True)
disc_real_x = discriminator_x(real_x, training=True)
disc_real_y = discriminator_y(real_y, training=True)
disc_fake_x = discriminator_x(fake_x, training=True)
disc_fake_y = discriminator_y(fake_y, training=True)
# calculate the loss
gen_g_loss = generator_loss(disc_fake_y)
gen_f_loss = generator_loss(disc_fake_x)
total_cycle_loss = calc_cycle_loss(real_x, cycled_x) + calc_cycle_loss(real_y, cycled_y)
# Total generator loss = adversarial loss + cycle loss
total_gen_g_loss = gen_g_loss + total_cycle_loss + identity_loss(real_y, same_y)
total_gen_f_loss = gen_f_loss + total_cycle_loss + identity_loss(real_x, same_x)
disc_x_loss = discriminator_loss(disc_real_x, disc_fake_x)
disc_y_loss = discriminator_loss(disc_real_y, disc_fake_y)
# Calculate the gradients for generator and discriminator
generator_g_gradients = tape.gradient(total_gen_g_loss,
generator_g.trainable_variables)
generator_f_gradients = tape.gradient(total_gen_f_loss,
generator_f.trainable_variables)
discriminator_x_gradients = tape.gradient(disc_x_loss,
discriminator_x.trainable_variables)
discriminator_y_gradients = tape.gradient(disc_y_loss,
discriminator_y.trainable_variables)
# Apply the gradients to the optimizer
generator_g_optimizer.apply_gradients(zip(generator_g_gradients,
generator_g.trainable_variables))
generator_f_optimizer.apply_gradients(zip(generator_f_gradients,
generator_f.trainable_variables))
discriminator_x_optimizer.apply_gradients(zip(discriminator_x_gradients,
discriminator_x.trainable_variables))
discriminator_y_optimizer.apply_gradients(zip(discriminator_y_gradients,
discriminator_y.trainable_variables))
for epoch in range(EPOCHS):
start = time.time()
n = 0
for image_x, image_y in tf.data.Dataset.zip((train_horses, train_zebras)):
train_step(image_x, image_y)
if n % 10 == 0:
print ('.', end='')
n += 1
clear_output(wait=True)
# Using a consistent image (sample_horse) so that the progress of the model
# is clearly visible.
generate_images(generator_g, sample_horse)
if (epoch + 1) % 5 == 0:
ckpt_save_path = ckpt_manager.save()
print ('Saving checkpoint for epoch {} at {}'.format(epoch+1,
ckpt_save_path))
print ('Time taken for epoch {} is {} sec\n'.format(epoch + 1,
time.time()-start))

Saving checkpoint for epoch 40 at ./checkpoints/train/ckpt-8 Time taken for epoch 40 is 166.64579939842224 sec
สร้างโดยใช้ชุดข้อมูลทดสอบ
# Run the trained model on the test dataset
for inp in test_horses.take(5):
generate_images(generator_g, inp)





ขั้นตอนถัดไป
บทช่วยสอนนี้แสดงวิธีใช้งาน CycleGAN โดยเริ่มจากตัวสร้างและตัวแบ่งแยกที่นำไปใช้ในบทช่วยสอน Pix2Pix ในขั้นตอนต่อไป คุณสามารถลองใช้ชุดข้อมูลอื่นจาก TensorFlow Datasets
คุณยังสามารถฝึกสำหรับยุคจำนวนมากขึ้นเพื่อปรับปรุงผลลัพธ์ หรือคุณสามารถใช้ตัวสร้าง ResNet ที่แก้ไขแล้วที่ใช้ใน กระดาษ แทนตัวสร้าง U-Net ที่ใช้ที่นี่