
| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub | |
Ten notatnik przedstawia translację niesparowanego obrazu na obraz przy użyciu warunkowego GAN, zgodnie z opisem w sekcji Niesparowane tłumaczenie obrazu na obraz przy użyciu sieci przeciwstawnych typu Cycle-Consistent , znanej również jako CycleGAN. W artykule zaproponowano metodę, która może uchwycić cechy jednej domeny obrazu i dowiedzieć się, jak te cechy można przełożyć na inną domenę obrazu, a wszystko to przy braku jakichkolwiek sparowanych przykładów treningu.
W tym notatniku zakładamy, że znasz Pix2Pix, o którym możesz się dowiedzieć z samouczka Pix2Pix . Kod dla CycleGAN jest podobny, główną różnicą jest dodatkowa funkcja straty i użycie niesparowanych danych treningowych.
CycleGAN wykorzystuje utratę spójności cyklu, aby umożliwić trening bez potrzeby sparowania danych. Innymi słowy, może tłumaczyć z jednej domeny na drugą bez mapowania jeden do jednego między domeną źródłową a docelową.
Otwiera to możliwość wykonania wielu interesujących zadań, takich jak ulepszanie zdjęć, kolorowanie obrazu, przenoszenie stylu itp. Wszystko, czego potrzebujesz, to źródłowy i docelowy zestaw danych (który jest po prostu katalogiem obrazów).


Skonfiguruj potok wejściowy
Zainstaluj pakiet tensorflow_examples , który umożliwia zaimportowanie generatora i dyskryminatora.
pip install git+https://github.com/tensorflow/examples.git
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow_examples.models.pix2pix import pix2pix
import os
import time
import matplotlib.pyplot as plt
from IPython.display import clear_output
AUTOTUNE = tf.data.AUTOTUNE
Potok wejściowy
Ten samouczek szkoli model do tłumaczenia obrazów koni na obrazy zebr. Ten zbiór danych i podobne można znaleźć tutaj .
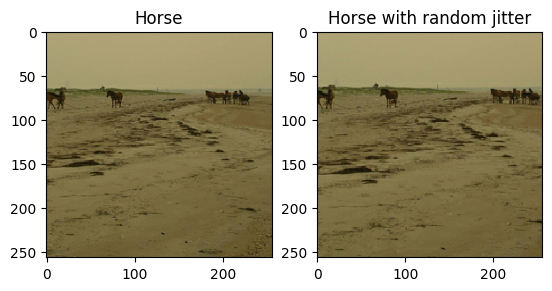
Jak wspomniano w artykule , zastosuj losowe drgania i odbicia lustrzane do zestawu danych treningowych. Oto niektóre z technik powiększania obrazu, które pozwalają uniknąć nadmiernego dopasowania.
Jest to podobne do tego, co zrobiono w pix2pix
- W przypadku losowych drgań obraz jest zmieniany na
286 x 286, a następnie losowo przycinany do256 x 256. - W losowym odbiciu lustrzanym obraz jest losowo odwracany w poziomie, tj. od lewej do prawej.
dataset, metadata = tfds.load('cycle_gan/horse2zebra',
with_info=True, as_supervised=True)
train_horses, train_zebras = dataset['trainA'], dataset['trainB']
test_horses, test_zebras = dataset['testA'], dataset['testB']
BUFFER_SIZE = 1000
BATCH_SIZE = 1
IMG_WIDTH = 256
IMG_HEIGHT = 256
def random_crop(image):
cropped_image = tf.image.random_crop(
image, size=[IMG_HEIGHT, IMG_WIDTH, 3])
return cropped_image
# normalizing the images to [-1, 1]
def normalize(image):
image = tf.cast(image, tf.float32)
image = (image / 127.5) - 1
return image
def random_jitter(image):
# resizing to 286 x 286 x 3
image = tf.image.resize(image, [286, 286],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
# randomly cropping to 256 x 256 x 3
image = random_crop(image)
# random mirroring
image = tf.image.random_flip_left_right(image)
return image
def preprocess_image_train(image, label):
image = random_jitter(image)
image = normalize(image)
return image
def preprocess_image_test(image, label):
image = normalize(image)
return image
train_horses = train_horses.cache().map(
preprocess_image_train, num_parallel_calls=AUTOTUNE).shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
train_zebras = train_zebras.cache().map(
preprocess_image_train, num_parallel_calls=AUTOTUNE).shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
test_horses = test_horses.map(
preprocess_image_test, num_parallel_calls=AUTOTUNE).cache().shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
test_zebras = test_zebras.map(
preprocess_image_test, num_parallel_calls=AUTOTUNE).cache().shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
sample_horse = next(iter(train_horses))
sample_zebra = next(iter(train_zebras))
2022-01-26 02:38:15.762422: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead. 2022-01-26 02:38:19.927846: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
plt.subplot(121)
plt.title('Horse')
plt.imshow(sample_horse[0] * 0.5 + 0.5)
plt.subplot(122)
plt.title('Horse with random jitter')
plt.imshow(random_jitter(sample_horse[0]) * 0.5 + 0.5)
<matplotlib.image.AxesImage at 0x7f7cf83e0050>
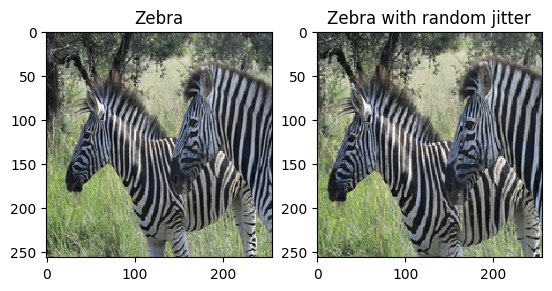
plt.subplot(121)
plt.title('Zebra')
plt.imshow(sample_zebra[0] * 0.5 + 0.5)
plt.subplot(122)
plt.title('Zebra with random jitter')
plt.imshow(random_jitter(sample_zebra[0]) * 0.5 + 0.5)
<matplotlib.image.AxesImage at 0x7f7cf8139490>
Importuj i ponownie używaj modeli Pix2Pix
Zaimportuj generator i dyskryminator używane w Pix2Pix za pośrednictwem zainstalowanego pakietu tensorflow_examples .
Architektura modelu użyta w tym samouczku jest bardzo podobna do architektury używanej w pix2pix . Niektóre z różnic to:
- Cyclegan używa normalizacji instancji zamiast normalizacji wsadowej .
- Artykuł CycleGAN wykorzystuje zmodyfikowany generator oparty na
resnet. Ten samouczek używa zmodyfikowanego generatoraunetdla uproszczenia.
Trenowane są tutaj 2 generatory (G i F) oraz 2 dyskryminatory (X i Y).
- Generator
Guczy się przekształcać obrazXna obrazY. \((G: X -> Y)\) - Generator
Fuczy się przekształcać obrazYw obrazX. \((F: Y -> X)\) - Dyskryminator
D_Xuczy się rozróżniać pomiędzy obrazemXa wygenerowanym obrazemX(F(Y)). - Dyskryminator
D_Yuczy się odróżniać obrazYod wygenerowanego obrazuY(G(X)).
OUTPUT_CHANNELS = 3
generator_g = pix2pix.unet_generator(OUTPUT_CHANNELS, norm_type='instancenorm')
generator_f = pix2pix.unet_generator(OUTPUT_CHANNELS, norm_type='instancenorm')
discriminator_x = pix2pix.discriminator(norm_type='instancenorm', target=False)
discriminator_y = pix2pix.discriminator(norm_type='instancenorm', target=False)
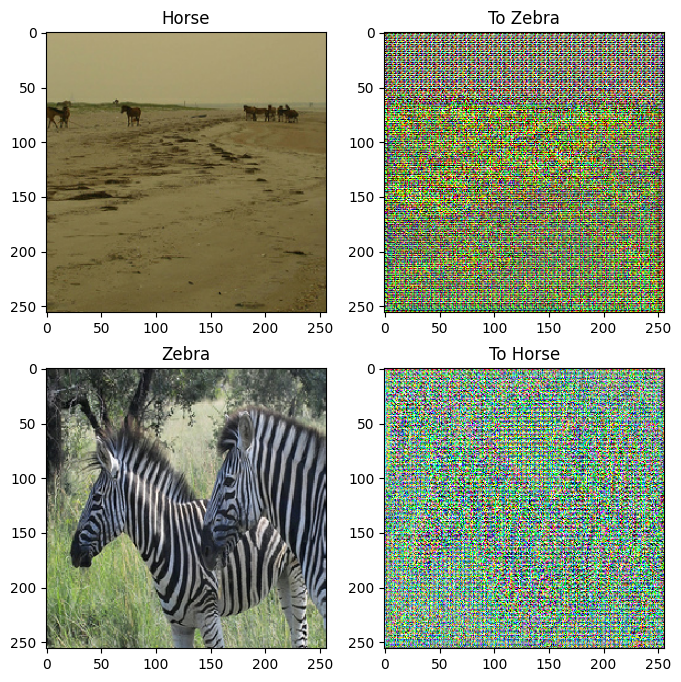
to_zebra = generator_g(sample_horse)
to_horse = generator_f(sample_zebra)
plt.figure(figsize=(8, 8))
contrast = 8
imgs = [sample_horse, to_zebra, sample_zebra, to_horse]
title = ['Horse', 'To Zebra', 'Zebra', 'To Horse']
for i in range(len(imgs)):
plt.subplot(2, 2, i+1)
plt.title(title[i])
if i % 2 == 0:
plt.imshow(imgs[i][0] * 0.5 + 0.5)
else:
plt.imshow(imgs[i][0] * 0.5 * contrast + 0.5)
plt.show()
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
plt.figure(figsize=(8, 8))
plt.subplot(121)
plt.title('Is a real zebra?')
plt.imshow(discriminator_y(sample_zebra)[0, ..., -1], cmap='RdBu_r')
plt.subplot(122)
plt.title('Is a real horse?')
plt.imshow(discriminator_x(sample_horse)[0, ..., -1], cmap='RdBu_r')
plt.show()

Funkcje strat
W CycleGAN nie ma sparowanych danych do trenowania, dlatego nie ma gwarancji, że dane wejściowe x i docelowa para y mają znaczenie podczas treningu. Tak więc, aby wymusić nauczenie się przez sieć poprawnego mapowania, autorzy proponują utratę spójności cyklu.
Strata dyskryminatora i strata generatora są podobne do stosowanych w pix2pix .
LAMBDA = 10
loss_obj = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def discriminator_loss(real, generated):
real_loss = loss_obj(tf.ones_like(real), real)
generated_loss = loss_obj(tf.zeros_like(generated), generated)
total_disc_loss = real_loss + generated_loss
return total_disc_loss * 0.5
def generator_loss(generated):
return loss_obj(tf.ones_like(generated), generated)
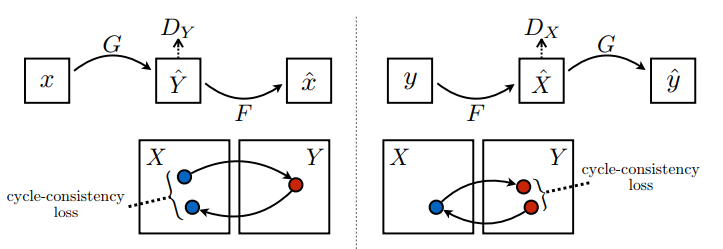
Spójność cyklu oznacza, że wynik powinien być zbliżony do pierwotnego wyniku. Na przykład, jeśli ktoś przetłumaczy zdanie z angielskiego na francuski, a następnie przetłumaczy je z powrotem z francuskiego na angielski, to wynikowe zdanie powinno być takie samo jak zdanie oryginalne.
W cyklu utraty konsystencji,
- Obraz \(X\) jest przekazywany przez generator \(G\) , który daje wygenerowany obraz \(\hat{Y}\).
- Wygenerowany obraz \(\hat{Y}\) jest przekazywany przez generator \(F\) , który daje cyklicznie wyświetlany obraz \(\hat{X}\).
- Średni błąd bezwzględny jest obliczany między \(X\) a \(\hat{X}\).
\[forward\ cycle\ consistency\ loss: X -> G(X) -> F(G(X)) \sim \hat{X}\]
\[backward\ cycle\ consistency\ loss: Y -> F(Y) -> G(F(Y)) \sim \hat{Y}\]
def calc_cycle_loss(real_image, cycled_image):
loss1 = tf.reduce_mean(tf.abs(real_image - cycled_image))
return LAMBDA * loss1
Jak pokazano powyżej, generator \(G\) odpowiada za tłumaczenie obrazu \(X\) na obraz \(Y\). Utrata tożsamości mówi, że jeśli wprowadzisz obraz \(Y\) do generatora \(G\), powinno to dać prawdziwy obraz \(Y\) lub coś podobnego do obrazu \(Y\).
Jeśli uruchomisz model zebry do konia na koniu lub model konia do zebry na zebry, nie powinno to znacząco modyfikować obrazu, ponieważ obraz zawiera już klasę docelową.
\[Identity\ loss = |G(Y) - Y| + |F(X) - X|\]
def identity_loss(real_image, same_image):
loss = tf.reduce_mean(tf.abs(real_image - same_image))
return LAMBDA * 0.5 * loss
Zainicjuj optymalizatory dla wszystkich generatorów i dyskryminatorów.
generator_g_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
generator_f_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_x_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_y_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
Punkty kontrolne
checkpoint_path = "./checkpoints/train"
ckpt = tf.train.Checkpoint(generator_g=generator_g,
generator_f=generator_f,
discriminator_x=discriminator_x,
discriminator_y=discriminator_y,
generator_g_optimizer=generator_g_optimizer,
generator_f_optimizer=generator_f_optimizer,
discriminator_x_optimizer=discriminator_x_optimizer,
discriminator_y_optimizer=discriminator_y_optimizer)
ckpt_manager = tf.train.CheckpointManager(ckpt, checkpoint_path, max_to_keep=5)
# if a checkpoint exists, restore the latest checkpoint.
if ckpt_manager.latest_checkpoint:
ckpt.restore(ckpt_manager.latest_checkpoint)
print ('Latest checkpoint restored!!')
Trening
EPOCHS = 40
def generate_images(model, test_input):
prediction = model(test_input)
plt.figure(figsize=(12, 12))
display_list = [test_input[0], prediction[0]]
title = ['Input Image', 'Predicted Image']
for i in range(2):
plt.subplot(1, 2, i+1)
plt.title(title[i])
# getting the pixel values between [0, 1] to plot it.
plt.imshow(display_list[i] * 0.5 + 0.5)
plt.axis('off')
plt.show()
Choć pętla treningowa wygląda na skomplikowaną, składa się z czterech podstawowych kroków:
- Uzyskaj prognozy.
- Oblicz stratę.
- Oblicz gradienty za pomocą wstecznej propagacji.
- Zastosuj gradienty do optymalizatora.
@tf.function
def train_step(real_x, real_y):
# persistent is set to True because the tape is used more than
# once to calculate the gradients.
with tf.GradientTape(persistent=True) as tape:
# Generator G translates X -> Y
# Generator F translates Y -> X.
fake_y = generator_g(real_x, training=True)
cycled_x = generator_f(fake_y, training=True)
fake_x = generator_f(real_y, training=True)
cycled_y = generator_g(fake_x, training=True)
# same_x and same_y are used for identity loss.
same_x = generator_f(real_x, training=True)
same_y = generator_g(real_y, training=True)
disc_real_x = discriminator_x(real_x, training=True)
disc_real_y = discriminator_y(real_y, training=True)
disc_fake_x = discriminator_x(fake_x, training=True)
disc_fake_y = discriminator_y(fake_y, training=True)
# calculate the loss
gen_g_loss = generator_loss(disc_fake_y)
gen_f_loss = generator_loss(disc_fake_x)
total_cycle_loss = calc_cycle_loss(real_x, cycled_x) + calc_cycle_loss(real_y, cycled_y)
# Total generator loss = adversarial loss + cycle loss
total_gen_g_loss = gen_g_loss + total_cycle_loss + identity_loss(real_y, same_y)
total_gen_f_loss = gen_f_loss + total_cycle_loss + identity_loss(real_x, same_x)
disc_x_loss = discriminator_loss(disc_real_x, disc_fake_x)
disc_y_loss = discriminator_loss(disc_real_y, disc_fake_y)
# Calculate the gradients for generator and discriminator
generator_g_gradients = tape.gradient(total_gen_g_loss,
generator_g.trainable_variables)
generator_f_gradients = tape.gradient(total_gen_f_loss,
generator_f.trainable_variables)
discriminator_x_gradients = tape.gradient(disc_x_loss,
discriminator_x.trainable_variables)
discriminator_y_gradients = tape.gradient(disc_y_loss,
discriminator_y.trainable_variables)
# Apply the gradients to the optimizer
generator_g_optimizer.apply_gradients(zip(generator_g_gradients,
generator_g.trainable_variables))
generator_f_optimizer.apply_gradients(zip(generator_f_gradients,
generator_f.trainable_variables))
discriminator_x_optimizer.apply_gradients(zip(discriminator_x_gradients,
discriminator_x.trainable_variables))
discriminator_y_optimizer.apply_gradients(zip(discriminator_y_gradients,
discriminator_y.trainable_variables))
for epoch in range(EPOCHS):
start = time.time()
n = 0
for image_x, image_y in tf.data.Dataset.zip((train_horses, train_zebras)):
train_step(image_x, image_y)
if n % 10 == 0:
print ('.', end='')
n += 1
clear_output(wait=True)
# Using a consistent image (sample_horse) so that the progress of the model
# is clearly visible.
generate_images(generator_g, sample_horse)
if (epoch + 1) % 5 == 0:
ckpt_save_path = ckpt_manager.save()
print ('Saving checkpoint for epoch {} at {}'.format(epoch+1,
ckpt_save_path))
print ('Time taken for epoch {} is {} sec\n'.format(epoch + 1,
time.time()-start))

Saving checkpoint for epoch 40 at ./checkpoints/train/ckpt-8 Time taken for epoch 40 is 166.64579939842224 sec
Generuj przy użyciu testowego zbioru danych
# Run the trained model on the test dataset
for inp in test_horses.take(5):
generate_images(generator_g, inp)





Następne kroki
Ten samouczek pokazał, jak zaimplementować CycleGAN, zaczynając od generatora i dyskryminatora zaimplementowanego w samouczku Pix2Pix . W następnym kroku możesz spróbować użyć innego zestawu danych z TensorFlow Datasets .
Możesz także trenować przez większą liczbę epok, aby poprawić wyniki, lub możesz wdrożyć zmodyfikowany generator ResNet użyty w artykule zamiast generatora U-Net używanego tutaj.