
| | |  Visualizza l'origine su GitHub Visualizza l'origine su GitHub | |
Questo quaderno mostra la traduzione da immagine a immagine non accoppiata utilizzando GAN condizionali, come descritto in Traduzione da immagine a immagine non accoppiata utilizzando reti contraddittorie coerenti con il ciclo , noto anche come CycleGAN. Il documento propone un metodo in grado di catturare le caratteristiche di un dominio dell'immagine e capire come queste caratteristiche potrebbero essere tradotte in un altro dominio dell'immagine, il tutto in assenza di esempi di formazione accoppiati.
Questo taccuino presuppone che tu abbia familiarità con Pix2Pix, che puoi conoscere nel tutorial Pix2Pix . Il codice per CycleGAN è simile, la differenza principale è una funzione di perdita aggiuntiva e l'uso di dati di allenamento non accoppiati.
CycleGAN utilizza una perdita di coerenza del ciclo per abilitare l'allenamento senza la necessità di dati associati. In altre parole, può tradurre da un dominio all'altro senza una mappatura uno-a-uno tra il dominio di origine e quello di destinazione.
Questo apre la possibilità di svolgere molte attività interessanti come il miglioramento delle foto, la colorazione delle immagini, il trasferimento dello stile, ecc. Tutto ciò di cui hai bisogno è il set di dati di origine e di destinazione (che è semplicemente una directory di immagini).


Configura la pipeline di input
Installa il pacchetto tensorflow_examples che abilita l'importazione del generatore e del discriminatore.
pip install git+https://github.com/tensorflow/examples.git
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow_examples.models.pix2pix import pix2pix
import os
import time
import matplotlib.pyplot as plt
from IPython.display import clear_output
AUTOTUNE = tf.data.AUTOTUNE
Pipeline di ingresso
Questo tutorial addestra un modello per tradurre da immagini di cavalli a immagini di zebre. Puoi trovare questo set di dati e altri simili qui .
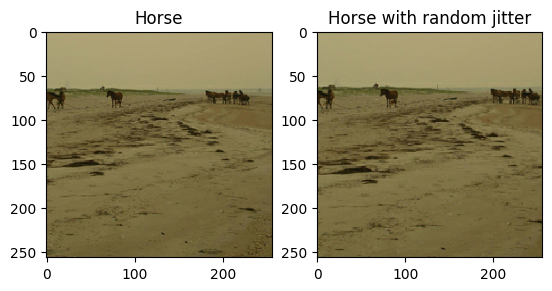
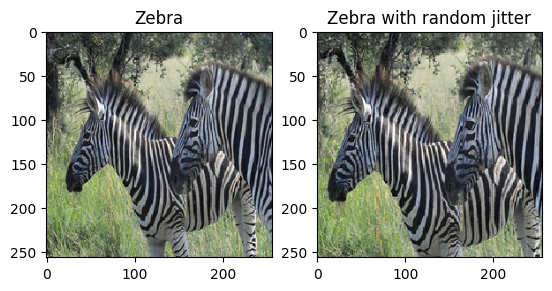
Come accennato nel documento , applica il jittering casuale e il mirroring al set di dati di addestramento. Queste sono alcune delle tecniche di aumento dell'immagine che evitano l'overfitting.
Questo è simile a quello che è stato fatto in pix2pix
- Nel jittering casuale, l'immagine viene ridimensionata a
286 x 286e quindi ritagliata casualmente a256 x 256. - Nel mirroring casuale, l'immagine viene capovolta in modo casuale orizzontalmente, ovvero da sinistra a destra.
dataset, metadata = tfds.load('cycle_gan/horse2zebra',
with_info=True, as_supervised=True)
train_horses, train_zebras = dataset['trainA'], dataset['trainB']
test_horses, test_zebras = dataset['testA'], dataset['testB']
BUFFER_SIZE = 1000
BATCH_SIZE = 1
IMG_WIDTH = 256
IMG_HEIGHT = 256
def random_crop(image):
cropped_image = tf.image.random_crop(
image, size=[IMG_HEIGHT, IMG_WIDTH, 3])
return cropped_image
# normalizing the images to [-1, 1]
def normalize(image):
image = tf.cast(image, tf.float32)
image = (image / 127.5) - 1
return image
def random_jitter(image):
# resizing to 286 x 286 x 3
image = tf.image.resize(image, [286, 286],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
# randomly cropping to 256 x 256 x 3
image = random_crop(image)
# random mirroring
image = tf.image.random_flip_left_right(image)
return image
def preprocess_image_train(image, label):
image = random_jitter(image)
image = normalize(image)
return image
def preprocess_image_test(image, label):
image = normalize(image)
return image
train_horses = train_horses.cache().map(
preprocess_image_train, num_parallel_calls=AUTOTUNE).shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
train_zebras = train_zebras.cache().map(
preprocess_image_train, num_parallel_calls=AUTOTUNE).shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
test_horses = test_horses.map(
preprocess_image_test, num_parallel_calls=AUTOTUNE).cache().shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
test_zebras = test_zebras.map(
preprocess_image_test, num_parallel_calls=AUTOTUNE).cache().shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
sample_horse = next(iter(train_horses))
sample_zebra = next(iter(train_zebras))
2022-01-26 02:38:15.762422: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead. 2022-01-26 02:38:19.927846: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
plt.subplot(121)
plt.title('Horse')
plt.imshow(sample_horse[0] * 0.5 + 0.5)
plt.subplot(122)
plt.title('Horse with random jitter')
plt.imshow(random_jitter(sample_horse[0]) * 0.5 + 0.5)
<matplotlib.image.AxesImage at 0x7f7cf83e0050>
plt.subplot(121)
plt.title('Zebra')
plt.imshow(sample_zebra[0] * 0.5 + 0.5)
plt.subplot(122)
plt.title('Zebra with random jitter')
plt.imshow(random_jitter(sample_zebra[0]) * 0.5 + 0.5)
<matplotlib.image.AxesImage at 0x7f7cf8139490>
Importa e riutilizza i modelli Pix2Pix
Importa il generatore e il discriminatore utilizzati in Pix2Pix tramite il pacchetto tensorflow_examples installato.
L'architettura del modello utilizzata in questo tutorial è molto simile a quella utilizzata in pix2pix . Alcune delle differenze sono:
- Cyclegan utilizza la normalizzazione dell'istanza invece della normalizzazione batch .
- La carta CycleGAN utilizza un generatore basato su
resnetmodificato. Questo tutorial utilizza un generatore diunetmodificato per semplicità.
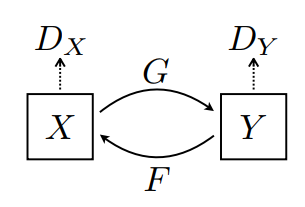
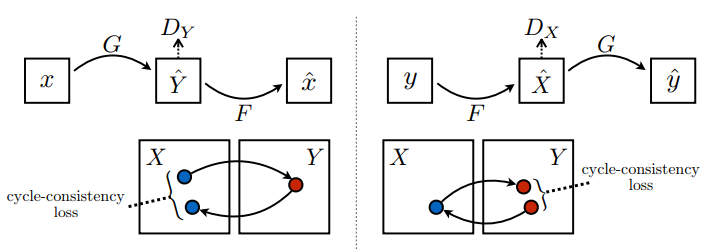
Ci sono 2 generatori (G e F) e 2 discriminatori (X e Y) che vengono addestrati qui.
- Il generatore
Gimpara a trasformare l'immagineXnell'immagineY\((G: X -> Y)\) - Il generatore
Fimpara a trasformare l'immagineYnell'immagineX. \((F: Y -> X)\) - Il discriminatore
D_Ximpara a distinguere tra l'immagineXe l'immagine generataX(F(Y)). - Il discriminatore
D_Yimpara a distinguere tra l'immagineYe l'immagine generataY(G(X)).
OUTPUT_CHANNELS = 3
generator_g = pix2pix.unet_generator(OUTPUT_CHANNELS, norm_type='instancenorm')
generator_f = pix2pix.unet_generator(OUTPUT_CHANNELS, norm_type='instancenorm')
discriminator_x = pix2pix.discriminator(norm_type='instancenorm', target=False)
discriminator_y = pix2pix.discriminator(norm_type='instancenorm', target=False)
to_zebra = generator_g(sample_horse)
to_horse = generator_f(sample_zebra)
plt.figure(figsize=(8, 8))
contrast = 8
imgs = [sample_horse, to_zebra, sample_zebra, to_horse]
title = ['Horse', 'To Zebra', 'Zebra', 'To Horse']
for i in range(len(imgs)):
plt.subplot(2, 2, i+1)
plt.title(title[i])
if i % 2 == 0:
plt.imshow(imgs[i][0] * 0.5 + 0.5)
else:
plt.imshow(imgs[i][0] * 0.5 * contrast + 0.5)
plt.show()
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
plt.figure(figsize=(8, 8))
plt.subplot(121)
plt.title('Is a real zebra?')
plt.imshow(discriminator_y(sample_zebra)[0, ..., -1], cmap='RdBu_r')
plt.subplot(122)
plt.title('Is a real horse?')
plt.imshow(discriminator_x(sample_horse)[0, ..., -1], cmap='RdBu_r')
plt.show()

Funzioni di perdita
In CycleGAN, non ci sono dati accoppiati su cui allenarsi, quindi non vi è alcuna garanzia che l'input x e la coppia target y siano significativi durante l'allenamento. Pertanto, al fine di far sì che la rete apprenda la corretta mappatura, gli autori propongono la perdita di consistenza del ciclo.
La perdita del discriminatore e la perdita del generatore sono simili a quelle utilizzate in pix2pix .
LAMBDA = 10
loss_obj = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def discriminator_loss(real, generated):
real_loss = loss_obj(tf.ones_like(real), real)
generated_loss = loss_obj(tf.zeros_like(generated), generated)
total_disc_loss = real_loss + generated_loss
return total_disc_loss * 0.5
def generator_loss(generated):
return loss_obj(tf.ones_like(generated), generated)
La consistenza del ciclo significa che il risultato dovrebbe essere vicino all'input originale. Ad esempio, se si traduce una frase dall'inglese al francese e poi la si traduce dal francese all'inglese, la frase risultante dovrebbe essere la stessa della frase originale.
Nella perdita di consistenza del ciclo,
- L'immagine \(X\) viene passata tramite il generatore \(G\) che restituisce l'immagine generata \(\hat{Y}\).
- L'immagine generata \(\hat{Y}\) viene passata tramite il generatore \(F\) che restituisce l'immagine ciclica \(\hat{X}\).
- L'errore assoluto medio viene calcolato tra \(X\) e \(\hat{X}\).
\[forward\ cycle\ consistency\ loss: X -> G(X) -> F(G(X)) \sim \hat{X}\]
\[backward\ cycle\ consistency\ loss: Y -> F(Y) -> G(F(Y)) \sim \hat{Y}\]
def calc_cycle_loss(real_image, cycled_image):
loss1 = tf.reduce_mean(tf.abs(real_image - cycled_image))
return LAMBDA * loss1
Come mostrato sopra, il generatore \(G\) è responsabile della traduzione dell'immagine \(X\) nell'immagine \(Y\). La perdita di identità dice che, se hai inserito l'immagine \(Y\) nel generatore \(G\), dovrebbe produrre l'immagine reale \(Y\) o qualcosa di simile all'immagine \(Y\).
Se esegui il modello da zebra a cavallo su un cavallo o il modello da cavallo a zebra su una zebra, non dovrebbe modificare molto l'immagine poiché l'immagine contiene già la classe di destinazione.
\[Identity\ loss = |G(Y) - Y| + |F(X) - X|\]
def identity_loss(real_image, same_image):
loss = tf.reduce_mean(tf.abs(real_image - same_image))
return LAMBDA * 0.5 * loss
Inizializzare gli ottimizzatori per tutti i generatori ei discriminatori.
generator_g_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
generator_f_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_x_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_y_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
Punti di controllo
checkpoint_path = "./checkpoints/train"
ckpt = tf.train.Checkpoint(generator_g=generator_g,
generator_f=generator_f,
discriminator_x=discriminator_x,
discriminator_y=discriminator_y,
generator_g_optimizer=generator_g_optimizer,
generator_f_optimizer=generator_f_optimizer,
discriminator_x_optimizer=discriminator_x_optimizer,
discriminator_y_optimizer=discriminator_y_optimizer)
ckpt_manager = tf.train.CheckpointManager(ckpt, checkpoint_path, max_to_keep=5)
# if a checkpoint exists, restore the latest checkpoint.
if ckpt_manager.latest_checkpoint:
ckpt.restore(ckpt_manager.latest_checkpoint)
print ('Latest checkpoint restored!!')
Formazione
EPOCHS = 40
def generate_images(model, test_input):
prediction = model(test_input)
plt.figure(figsize=(12, 12))
display_list = [test_input[0], prediction[0]]
title = ['Input Image', 'Predicted Image']
for i in range(2):
plt.subplot(1, 2, i+1)
plt.title(title[i])
# getting the pixel values between [0, 1] to plot it.
plt.imshow(display_list[i] * 0.5 + 0.5)
plt.axis('off')
plt.show()
Anche se il ciclo di formazione sembra complicato, si compone di quattro passaggi fondamentali:
- Ottieni le previsioni.
- Calcola la perdita.
- Calcola i gradienti usando la backpropagation.
- Applicare i gradienti all'ottimizzatore.
@tf.function
def train_step(real_x, real_y):
# persistent is set to True because the tape is used more than
# once to calculate the gradients.
with tf.GradientTape(persistent=True) as tape:
# Generator G translates X -> Y
# Generator F translates Y -> X.
fake_y = generator_g(real_x, training=True)
cycled_x = generator_f(fake_y, training=True)
fake_x = generator_f(real_y, training=True)
cycled_y = generator_g(fake_x, training=True)
# same_x and same_y are used for identity loss.
same_x = generator_f(real_x, training=True)
same_y = generator_g(real_y, training=True)
disc_real_x = discriminator_x(real_x, training=True)
disc_real_y = discriminator_y(real_y, training=True)
disc_fake_x = discriminator_x(fake_x, training=True)
disc_fake_y = discriminator_y(fake_y, training=True)
# calculate the loss
gen_g_loss = generator_loss(disc_fake_y)
gen_f_loss = generator_loss(disc_fake_x)
total_cycle_loss = calc_cycle_loss(real_x, cycled_x) + calc_cycle_loss(real_y, cycled_y)
# Total generator loss = adversarial loss + cycle loss
total_gen_g_loss = gen_g_loss + total_cycle_loss + identity_loss(real_y, same_y)
total_gen_f_loss = gen_f_loss + total_cycle_loss + identity_loss(real_x, same_x)
disc_x_loss = discriminator_loss(disc_real_x, disc_fake_x)
disc_y_loss = discriminator_loss(disc_real_y, disc_fake_y)
# Calculate the gradients for generator and discriminator
generator_g_gradients = tape.gradient(total_gen_g_loss,
generator_g.trainable_variables)
generator_f_gradients = tape.gradient(total_gen_f_loss,
generator_f.trainable_variables)
discriminator_x_gradients = tape.gradient(disc_x_loss,
discriminator_x.trainable_variables)
discriminator_y_gradients = tape.gradient(disc_y_loss,
discriminator_y.trainable_variables)
# Apply the gradients to the optimizer
generator_g_optimizer.apply_gradients(zip(generator_g_gradients,
generator_g.trainable_variables))
generator_f_optimizer.apply_gradients(zip(generator_f_gradients,
generator_f.trainable_variables))
discriminator_x_optimizer.apply_gradients(zip(discriminator_x_gradients,
discriminator_x.trainable_variables))
discriminator_y_optimizer.apply_gradients(zip(discriminator_y_gradients,
discriminator_y.trainable_variables))
for epoch in range(EPOCHS):
start = time.time()
n = 0
for image_x, image_y in tf.data.Dataset.zip((train_horses, train_zebras)):
train_step(image_x, image_y)
if n % 10 == 0:
print ('.', end='')
n += 1
clear_output(wait=True)
# Using a consistent image (sample_horse) so that the progress of the model
# is clearly visible.
generate_images(generator_g, sample_horse)
if (epoch + 1) % 5 == 0:
ckpt_save_path = ckpt_manager.save()
print ('Saving checkpoint for epoch {} at {}'.format(epoch+1,
ckpt_save_path))
print ('Time taken for epoch {} is {} sec\n'.format(epoch + 1,
time.time()-start))

Saving checkpoint for epoch 40 at ./checkpoints/train/ckpt-8 Time taken for epoch 40 is 166.64579939842224 sec
Genera utilizzando il set di dati di prova
# Run the trained model on the test dataset
for inp in test_horses.take(5):
generate_images(generator_g, inp)





Prossimi passi
Questo tutorial ha mostrato come implementare CycleGAN partendo dal generatore e discriminatore implementato nel tutorial Pix2Pix . Come passaggio successivo, potresti provare a utilizzare un set di dati diverso da TensorFlow Datasets .
Potresti anche allenarti per un numero maggiore di epoche per migliorare i risultati, oppure potresti implementare il generatore ResNet modificato utilizzato nel documento invece del generatore U-Net usato qui.