
| | |  عرض المصدر على جيثب عرض المصدر على جيثب | |
يوضح هذا الكمبيوتر الدفتري صورة غير مقترنة بترجمة الصور باستخدام GAN الشرطي ، كما هو موضح في الترجمة غير المقترنة من صورة إلى صورة باستخدام شبكات الخصومة المتوافقة مع الدورة ، والمعروفة أيضًا باسم CycleGAN. تقترح الورقة طريقة يمكنها التقاط خصائص مجال صورة واحد ومعرفة كيف يمكن ترجمة هذه الخصائص إلى مجال صورة آخر ، كل ذلك في غياب أي أمثلة تدريبية مقترنة.
يفترض هذا الكمبيوتر الدفتري أنك على دراية بـ Pix2Pix ، والتي يمكنك التعرف عليها في البرنامج التعليمي Pix2Pix . رمز CycleGAN مشابه ، والفرق الرئيسي هو وظيفة خسارة إضافية ، واستخدام بيانات التدريب غير المقترنة.
يستخدم CycleGAN فقدان تناسق الدورة لتمكين التدريب دون الحاجة إلى البيانات المزدوجة. بمعنى آخر ، يمكن أن يترجم من مجال إلى آخر دون تعيين واحد لواحد بين المجال المصدر والمجال الهدف.
هذا يفتح إمكانية القيام بالكثير من المهام المثيرة للاهتمام مثل تحسين الصور ، تلوين الصورة ، نقل النمط ، إلخ. كل ما تحتاجه هو المصدر ومجموعة البيانات المستهدفة (والتي هي مجرد دليل للصور).


قم بإعداد خط أنابيب الإدخال
قم بتثبيت حزمة tensorflow_examples التي تتيح استيراد المولد والمميز.
pip install git+https://github.com/tensorflow/examples.git
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow_examples.models.pix2pix import pix2pix
import os
import time
import matplotlib.pyplot as plt
from IPython.display import clear_output
AUTOTUNE = tf.data.AUTOTUNE
خط أنابيب الإدخال
يقوم هذا البرنامج التعليمي بتدريب نموذج على الترجمة من صور الخيول إلى صور الحمر الوحشية. يمكنك العثور على مجموعة البيانات هذه وما شابهها هنا .
كما هو مذكور في الورقة ، قم بتطبيق النرفزة العشوائية والانعكاس على مجموعة بيانات التدريب. هذه بعض تقنيات تكبير الصورة التي تتجنب فرط التخصيص.
هذا مشابه لما تم عمله في pix2pix
- في الارتعاش العشوائي ، يتم تغيير حجم الصورة إلى
286 x 286ثم يتم اقتصاصها عشوائيًا إلى256 x 256. - في الانعكاس العشوائي ، يتم قلب الصورة بشكل عشوائي أفقيًا ، أي من اليسار إلى اليمين.
dataset, metadata = tfds.load('cycle_gan/horse2zebra',
with_info=True, as_supervised=True)
train_horses, train_zebras = dataset['trainA'], dataset['trainB']
test_horses, test_zebras = dataset['testA'], dataset['testB']
BUFFER_SIZE = 1000
BATCH_SIZE = 1
IMG_WIDTH = 256
IMG_HEIGHT = 256
def random_crop(image):
cropped_image = tf.image.random_crop(
image, size=[IMG_HEIGHT, IMG_WIDTH, 3])
return cropped_image
# normalizing the images to [-1, 1]
def normalize(image):
image = tf.cast(image, tf.float32)
image = (image / 127.5) - 1
return image
def random_jitter(image):
# resizing to 286 x 286 x 3
image = tf.image.resize(image, [286, 286],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
# randomly cropping to 256 x 256 x 3
image = random_crop(image)
# random mirroring
image = tf.image.random_flip_left_right(image)
return image
def preprocess_image_train(image, label):
image = random_jitter(image)
image = normalize(image)
return image
def preprocess_image_test(image, label):
image = normalize(image)
return image
train_horses = train_horses.cache().map(
preprocess_image_train, num_parallel_calls=AUTOTUNE).shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
train_zebras = train_zebras.cache().map(
preprocess_image_train, num_parallel_calls=AUTOTUNE).shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
test_horses = test_horses.map(
preprocess_image_test, num_parallel_calls=AUTOTUNE).cache().shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
test_zebras = test_zebras.map(
preprocess_image_test, num_parallel_calls=AUTOTUNE).cache().shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
sample_horse = next(iter(train_horses))
sample_zebra = next(iter(train_zebras))
2022-01-26 02:38:15.762422: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead. 2022-01-26 02:38:19.927846: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
plt.subplot(121)
plt.title('Horse')
plt.imshow(sample_horse[0] * 0.5 + 0.5)
plt.subplot(122)
plt.title('Horse with random jitter')
plt.imshow(random_jitter(sample_horse[0]) * 0.5 + 0.5)
<matplotlib.image.AxesImage at 0x7f7cf83e0050>
plt.subplot(121)
plt.title('Zebra')
plt.imshow(sample_zebra[0] * 0.5 + 0.5)
plt.subplot(122)
plt.title('Zebra with random jitter')
plt.imshow(random_jitter(sample_zebra[0]) * 0.5 + 0.5)
<matplotlib.image.AxesImage at 0x7f7cf8139490>
استيراد نماذج Pix2Pix وإعادة استخدامها
قم باستيراد المولد والمميز المستخدم في Pix2Pix عبر حزمة tensorflow_examples المثبتة.
إن بنية النموذج المستخدمة في هذا البرنامج التعليمي مشابهة جدًا لما تم استخدامه في pix2pix . بعض الاختلافات هي:
- يستخدم Cyclegan تطبيع المثيل بدلاً من تطبيع الدُفعات .
- يستخدم ورق CycleGAN
resnetمعدلاً يعتمد على إعادة الشبكة. يستخدم هذا البرنامج التعليمي منشئunetالمعدل للبساطة.
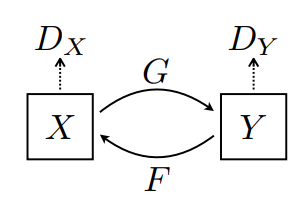
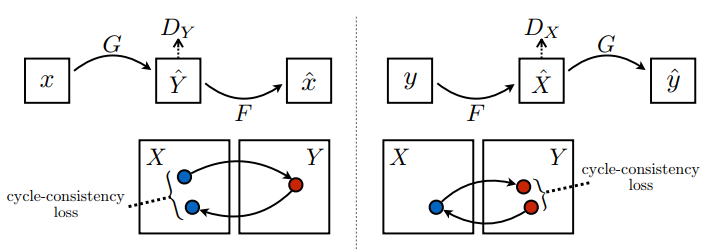
يوجد هنا مولدان (G و F) ومميزان (X و Y) يتم تدريبهما هنا.
- يتعلم المولد
Gتحويل الصورةXإلى الصورةY\((G: X -> Y)\) - يتعلم المولد
Fتحويل الصورةYإلى الصورةX\((F: Y -> X)\) - يتعلم Discriminator
D_Xالتفريق بين الصورةXوالصورة المولدةX(F(Y)). - يتعلم Discriminator
D_Yالتفريق بين الصورةYوالصورة المولدةY(G(X)).
OUTPUT_CHANNELS = 3
generator_g = pix2pix.unet_generator(OUTPUT_CHANNELS, norm_type='instancenorm')
generator_f = pix2pix.unet_generator(OUTPUT_CHANNELS, norm_type='instancenorm')
discriminator_x = pix2pix.discriminator(norm_type='instancenorm', target=False)
discriminator_y = pix2pix.discriminator(norm_type='instancenorm', target=False)
to_zebra = generator_g(sample_horse)
to_horse = generator_f(sample_zebra)
plt.figure(figsize=(8, 8))
contrast = 8
imgs = [sample_horse, to_zebra, sample_zebra, to_horse]
title = ['Horse', 'To Zebra', 'Zebra', 'To Horse']
for i in range(len(imgs)):
plt.subplot(2, 2, i+1)
plt.title(title[i])
if i % 2 == 0:
plt.imshow(imgs[i][0] * 0.5 + 0.5)
else:
plt.imshow(imgs[i][0] * 0.5 * contrast + 0.5)
plt.show()
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
plt.figure(figsize=(8, 8))
plt.subplot(121)
plt.title('Is a real zebra?')
plt.imshow(discriminator_y(sample_zebra)[0, ..., -1], cmap='RdBu_r')
plt.subplot(122)
plt.title('Is a real horse?')
plt.imshow(discriminator_x(sample_horse)[0, ..., -1], cmap='RdBu_r')
plt.show()

وظائف الخسارة
في CycleGAN ، لا توجد بيانات مقترنة للتدريب عليها ، وبالتالي لا يوجد ضمان بأن المدخلات x والزوج y المستهدف لهما معنى أثناء التدريب. وبالتالي من أجل فرض أن الشبكة تتعلم التعيين الصحيح ، يقترح المؤلفون فقدان تناسق الدورة.
خسارة أداة التمييز وفقدان المولد مماثلة لتلك المستخدمة في pix2pix .
LAMBDA = 10
loss_obj = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def discriminator_loss(real, generated):
real_loss = loss_obj(tf.ones_like(real), real)
generated_loss = loss_obj(tf.zeros_like(generated), generated)
total_disc_loss = real_loss + generated_loss
return total_disc_loss * 0.5
def generator_loss(generated):
return loss_obj(tf.ones_like(generated), generated)
تناسق الدورة يعني أن النتيجة يجب أن تكون قريبة من المدخلات الأصلية. على سبيل المثال ، إذا ترجم المرء جملة من الإنجليزية إلى الفرنسية ، ثم ترجمها مرة أخرى من الفرنسية إلى الإنجليزية ، فيجب أن تكون الجملة الناتجة هي نفسها الجملة الأصلية.
في فقدان تناسق الدورة ،
- يتم تمرير الصورة \(X\) عبر المولد \(G\) الذي ينتج صورة \(\hat{Y}\).
- يتم تمرير الصورة \(\hat{Y}\) عبر المولد \(F\) الذي ينتج صورة \(\hat{X}\).
- يتم حساب متوسط الخطأ المطلق بين \(X\) و \(\hat{X}\).
\[forward\ cycle\ consistency\ loss: X -> G(X) -> F(G(X)) \sim \hat{X}\]
\[backward\ cycle\ consistency\ loss: Y -> F(Y) -> G(F(Y)) \sim \hat{Y}\]
def calc_cycle_loss(real_image, cycled_image):
loss1 = tf.reduce_mean(tf.abs(real_image - cycled_image))
return LAMBDA * loss1
كما هو موضح أعلاه ، فإن \(G\) مسؤول عن ترجمة الصورة \(X\) إلى الصورة \(Y\). يشير فقدان الهوية إلى أنه إذا قمت بتغذية الصورة \(Y\) بالمولد \(G\)، فيجب أن ينتج عنها الصورة الحقيقية \(Y\) أو شيء قريب من الصورة \(Y\).
إذا قمت بتشغيل نموذج zebra-to-horse على حصان أو نموذج من حصان إلى حمار وحشي على حمار وحشي ، فلا يجب تعديل الصورة كثيرًا نظرًا لأن الصورة تحتوي بالفعل على الفئة المستهدفة.
\[Identity\ loss = |G(Y) - Y| + |F(X) - X|\]
def identity_loss(real_image, same_image):
loss = tf.reduce_mean(tf.abs(real_image - same_image))
return LAMBDA * 0.5 * loss
تهيئة المُحسِّن لجميع المولدات والمميزات.
generator_g_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
generator_f_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_x_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_y_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
نقاط تفتيش
checkpoint_path = "./checkpoints/train"
ckpt = tf.train.Checkpoint(generator_g=generator_g,
generator_f=generator_f,
discriminator_x=discriminator_x,
discriminator_y=discriminator_y,
generator_g_optimizer=generator_g_optimizer,
generator_f_optimizer=generator_f_optimizer,
discriminator_x_optimizer=discriminator_x_optimizer,
discriminator_y_optimizer=discriminator_y_optimizer)
ckpt_manager = tf.train.CheckpointManager(ckpt, checkpoint_path, max_to_keep=5)
# if a checkpoint exists, restore the latest checkpoint.
if ckpt_manager.latest_checkpoint:
ckpt.restore(ckpt_manager.latest_checkpoint)
print ('Latest checkpoint restored!!')
تمرين
EPOCHS = 40
def generate_images(model, test_input):
prediction = model(test_input)
plt.figure(figsize=(12, 12))
display_list = [test_input[0], prediction[0]]
title = ['Input Image', 'Predicted Image']
for i in range(2):
plt.subplot(1, 2, i+1)
plt.title(title[i])
# getting the pixel values between [0, 1] to plot it.
plt.imshow(display_list[i] * 0.5 + 0.5)
plt.axis('off')
plt.show()
على الرغم من أن حلقة التدريب تبدو معقدة ، إلا أنها تتكون من أربع خطوات أساسية:
- احصل على التوقعات.
- احسب الخسارة.
- حساب التدرجات باستخدام backpropagation.
- تطبيق التدرجات على المحسن.
@tf.function
def train_step(real_x, real_y):
# persistent is set to True because the tape is used more than
# once to calculate the gradients.
with tf.GradientTape(persistent=True) as tape:
# Generator G translates X -> Y
# Generator F translates Y -> X.
fake_y = generator_g(real_x, training=True)
cycled_x = generator_f(fake_y, training=True)
fake_x = generator_f(real_y, training=True)
cycled_y = generator_g(fake_x, training=True)
# same_x and same_y are used for identity loss.
same_x = generator_f(real_x, training=True)
same_y = generator_g(real_y, training=True)
disc_real_x = discriminator_x(real_x, training=True)
disc_real_y = discriminator_y(real_y, training=True)
disc_fake_x = discriminator_x(fake_x, training=True)
disc_fake_y = discriminator_y(fake_y, training=True)
# calculate the loss
gen_g_loss = generator_loss(disc_fake_y)
gen_f_loss = generator_loss(disc_fake_x)
total_cycle_loss = calc_cycle_loss(real_x, cycled_x) + calc_cycle_loss(real_y, cycled_y)
# Total generator loss = adversarial loss + cycle loss
total_gen_g_loss = gen_g_loss + total_cycle_loss + identity_loss(real_y, same_y)
total_gen_f_loss = gen_f_loss + total_cycle_loss + identity_loss(real_x, same_x)
disc_x_loss = discriminator_loss(disc_real_x, disc_fake_x)
disc_y_loss = discriminator_loss(disc_real_y, disc_fake_y)
# Calculate the gradients for generator and discriminator
generator_g_gradients = tape.gradient(total_gen_g_loss,
generator_g.trainable_variables)
generator_f_gradients = tape.gradient(total_gen_f_loss,
generator_f.trainable_variables)
discriminator_x_gradients = tape.gradient(disc_x_loss,
discriminator_x.trainable_variables)
discriminator_y_gradients = tape.gradient(disc_y_loss,
discriminator_y.trainable_variables)
# Apply the gradients to the optimizer
generator_g_optimizer.apply_gradients(zip(generator_g_gradients,
generator_g.trainable_variables))
generator_f_optimizer.apply_gradients(zip(generator_f_gradients,
generator_f.trainable_variables))
discriminator_x_optimizer.apply_gradients(zip(discriminator_x_gradients,
discriminator_x.trainable_variables))
discriminator_y_optimizer.apply_gradients(zip(discriminator_y_gradients,
discriminator_y.trainable_variables))
for epoch in range(EPOCHS):
start = time.time()
n = 0
for image_x, image_y in tf.data.Dataset.zip((train_horses, train_zebras)):
train_step(image_x, image_y)
if n % 10 == 0:
print ('.', end='')
n += 1
clear_output(wait=True)
# Using a consistent image (sample_horse) so that the progress of the model
# is clearly visible.
generate_images(generator_g, sample_horse)
if (epoch + 1) % 5 == 0:
ckpt_save_path = ckpt_manager.save()
print ('Saving checkpoint for epoch {} at {}'.format(epoch+1,
ckpt_save_path))
print ('Time taken for epoch {} is {} sec\n'.format(epoch + 1,
time.time()-start))

Saving checkpoint for epoch 40 at ./checkpoints/train/ckpt-8 Time taken for epoch 40 is 166.64579939842224 sec
إنشاء باستخدام مجموعة بيانات الاختبار
# Run the trained model on the test dataset
for inp in test_horses.take(5):
generate_images(generator_g, inp)





الخطوات التالية
أظهر هذا البرنامج التعليمي كيفية تنفيذ CycleGAN بدءًا من المولد والمميز المطبق في البرنامج التعليمي Pix2Pix . كخطوة تالية ، يمكنك محاولة استخدام مجموعة بيانات مختلفة من مجموعات بيانات TensorFlow .
يمكنك أيضًا التدرب على عدد أكبر من الحقب لتحسين النتائج ، أو يمكنك تنفيذ مولد ResNet المعدل المستخدم في الورق بدلاً من مولد U-Net المستخدم هنا.