
| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub | |
Sổ tay này trình bày cách đào tạo một Bộ mã tự động biến thể (VAE) ( 1 , 2 ) trên tập dữ liệu MNIST. VAE là một mô hình xác suất sử dụng tự động mã hóa, một mô hình lấy dữ liệu đầu vào có chiều cao và nén nó thành một biểu diễn nhỏ hơn. Không giống như một bộ mã tự động truyền thống, ánh xạ đầu vào vào một vectơ tiềm ẩn, một VAE ánh xạ dữ liệu đầu vào thành các tham số của phân phối xác suất, chẳng hạn như giá trị trung bình và phương sai của một Gaussian. Cách tiếp cận này tạo ra một không gian tiềm ẩn có cấu trúc, liên tục, rất hữu ích cho việc tạo hình ảnh.

Thành lập
pip install tensorflow-probability# to generate gifspip install imageiopip install git+https://github.com/tensorflow/docs
from IPython import display
import glob
import imageio
import matplotlib.pyplot as plt
import numpy as np
import PIL
import tensorflow as tf
import tensorflow_probability as tfp
import time
Tải tập dữ liệu MNIST
Mỗi hình ảnh MNIST ban đầu là một vectơ gồm 784 số nguyên, mỗi vectơ nằm trong khoảng từ 0-255 và thể hiện cường độ của một pixel. Lập mô hình từng pixel với phân phối Bernoulli trong mô hình của chúng tôi và mã hóa tĩnh bộ dữ liệu.
(train_images, _), (test_images, _) = tf.keras.datasets.mnist.load_data()
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz 11493376/11490434 [==============================] - 0s 0us/step 11501568/11490434 [==============================] - 0s 0us/step
def preprocess_images(images):
images = images.reshape((images.shape[0], 28, 28, 1)) / 255.
return np.where(images > .5, 1.0, 0.0).astype('float32')
train_images = preprocess_images(train_images)
test_images = preprocess_images(test_images)
train_size = 60000
batch_size = 32
test_size = 10000
Sử dụng tf.data để trộn và trộn dữ liệu
train_dataset = (tf.data.Dataset.from_tensor_slices(train_images)
.shuffle(train_size).batch(batch_size))
test_dataset = (tf.data.Dataset.from_tensor_slices(test_images)
.shuffle(test_size).batch(batch_size))
Xác định bộ mã hóa và mạng giải mã với tf.keras.
Trong ví dụ VAE này, sử dụng hai ConvNets nhỏ cho mạng bộ mã hóa và bộ giải mã. Trong tài liệu, các mạng này cũng được gọi tương ứng là mô hình suy luận / công nhận và mô hình tổng hợp. Sử dụng tf.keras.Sequential để đơn giản hóa việc triển khai. Gọi \(x\) và \(z\) lần lượt biểu thị biến quan sát và biến tiềm ẩn trong các mô tả sau.
Mạng mã hóa
Điều này xác định phân phối sau gần đúng \(q(z|x)\), lấy đầu vào là một quan sát và xuất ra một tập hợp các tham số để chỉ định phân phối có điều kiện của biểu diễn tiềm ẩn \(z\). Trong ví dụ này, chỉ cần lập mô hình phân phối dưới dạng Gaussian chéo và mạng xuất ra các tham số trung bình và log-phương sai của một Gauss đã phân tích nhân tử. Xuất log-variance thay vì phương sai trực tiếp để ổn định số.
Mạng giải mã
Điều này xác định phân phối có điều kiện của quan sát \(p(x|z)\), lấy mẫu tiềm ẩn \(z\) làm đầu vào và đầu ra các tham số cho phân phối có điều kiện của quan sát. Lập mô hình phân phối tiềm ẩn trước \(p(z)\) dưới dạng Gaussian đơn vị.
Thủ thuật đánh giá lại
Để tạo mẫu \(z\) cho bộ giải mã trong quá trình đào tạo, bạn có thể lấy mẫu từ phân phối tiềm ẩn được xác định bởi các tham số do bộ mã hóa xuất ra, với một quan sát đầu vào \(x\). Tuy nhiên, hoạt động lấy mẫu này tạo ra một nút thắt cổ chai vì sự lan truyền ngược không thể chảy qua một nút ngẫu nhiên.
Để giải quyết vấn đề này, hãy sử dụng thủ thuật đánh giá lại. Trong ví dụ của chúng tôi, bạn ước \(z\) bằng cách sử dụng các tham số bộ giải mã và một tham số khác \(\epsilon\) như sau:
\[z = \mu + \sigma \odot \epsilon\]
trong đó \(\mu\) và \(\sigma\) đại diện cho giá trị trung bình và độ lệch chuẩn của phân phối Gaussian tương ứng. Chúng có thể được lấy từ đầu ra của bộ giải mã. Có thể coi \(\epsilon\) là một nhiễu ngẫu nhiên được sử dụng để duy trì ngẫu nhiên của \(z\). Tạo \(\epsilon\) từ phân phối chuẩn chuẩn.
Biến tiềm ẩn \(z\) hiện được tạo bởi một hàm của \(\mu\), \(\sigma\) và \(\epsilon\), cho phép mô hình sao chép ngược các gradient trong bộ mã hóa thông qua \(\mu\) và \(\sigma\) tương ứng, trong khi duy trì tính ngẫu nhiên thông qua \(\epsilon\).
Kiến trúc mạng
Đối với mạng bộ mã hóa, hãy sử dụng hai lớp phức hợp theo sau là một lớp được kết nối đầy đủ. Trong mạng bộ giải mã, phản chiếu kiến trúc này bằng cách sử dụng một lớp được kết nối đầy đủ theo sau là ba lớp chuyển vị tích chập (hay còn gọi là lớp giải mã trong một số ngữ cảnh). Lưu ý, thực tế phổ biến là tránh sử dụng chuẩn hóa hàng loạt khi đào tạo VAE, vì ngẫu nhiên bổ sung do sử dụng các lô nhỏ có thể làm trầm trọng thêm tính không ổn định bên cạnh ngẫu nhiên từ việc lấy mẫu.
class CVAE(tf.keras.Model):
"""Convolutional variational autoencoder."""
def __init__(self, latent_dim):
super(CVAE, self).__init__()
self.latent_dim = latent_dim
self.encoder = tf.keras.Sequential(
[
tf.keras.layers.InputLayer(input_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(
filters=32, kernel_size=3, strides=(2, 2), activation='relu'),
tf.keras.layers.Conv2D(
filters=64, kernel_size=3, strides=(2, 2), activation='relu'),
tf.keras.layers.Flatten(),
# No activation
tf.keras.layers.Dense(latent_dim + latent_dim),
]
)
self.decoder = tf.keras.Sequential(
[
tf.keras.layers.InputLayer(input_shape=(latent_dim,)),
tf.keras.layers.Dense(units=7*7*32, activation=tf.nn.relu),
tf.keras.layers.Reshape(target_shape=(7, 7, 32)),
tf.keras.layers.Conv2DTranspose(
filters=64, kernel_size=3, strides=2, padding='same',
activation='relu'),
tf.keras.layers.Conv2DTranspose(
filters=32, kernel_size=3, strides=2, padding='same',
activation='relu'),
# No activation
tf.keras.layers.Conv2DTranspose(
filters=1, kernel_size=3, strides=1, padding='same'),
]
)
@tf.function
def sample(self, eps=None):
if eps is None:
eps = tf.random.normal(shape=(100, self.latent_dim))
return self.decode(eps, apply_sigmoid=True)
def encode(self, x):
mean, logvar = tf.split(self.encoder(x), num_or_size_splits=2, axis=1)
return mean, logvar
def reparameterize(self, mean, logvar):
eps = tf.random.normal(shape=mean.shape)
return eps * tf.exp(logvar * .5) + mean
def decode(self, z, apply_sigmoid=False):
logits = self.decoder(z)
if apply_sigmoid:
probs = tf.sigmoid(logits)
return probs
return logits
Xác định hàm mất mát và trình tối ưu hóa
VAE đào tạo bằng cách tối đa hóa giới hạn dưới bằng chứng (ELBO) dựa trên khả năng log cận biên:
\[\log p(x) \ge \text{ELBO} = \mathbb{E}_{q(z|x)}\left[\log \frac{p(x, z)}{q(z|x)}\right].\]
Trên thực tế, hãy tối ưu hóa ước tính Monte Carlo mẫu đơn về kỳ vọng này:
\[\log p(x| z) + \log p(z) - \log q(z|x),\]
trong đó \(z\) được lấy mẫu từ \(q(z|x)\).
optimizer = tf.keras.optimizers.Adam(1e-4)
def log_normal_pdf(sample, mean, logvar, raxis=1):
log2pi = tf.math.log(2. * np.pi)
return tf.reduce_sum(
-.5 * ((sample - mean) ** 2. * tf.exp(-logvar) + logvar + log2pi),
axis=raxis)
def compute_loss(model, x):
mean, logvar = model.encode(x)
z = model.reparameterize(mean, logvar)
x_logit = model.decode(z)
cross_ent = tf.nn.sigmoid_cross_entropy_with_logits(logits=x_logit, labels=x)
logpx_z = -tf.reduce_sum(cross_ent, axis=[1, 2, 3])
logpz = log_normal_pdf(z, 0., 0.)
logqz_x = log_normal_pdf(z, mean, logvar)
return -tf.reduce_mean(logpx_z + logpz - logqz_x)
@tf.function
def train_step(model, x, optimizer):
"""Executes one training step and returns the loss.
This function computes the loss and gradients, and uses the latter to
update the model's parameters.
"""
with tf.GradientTape() as tape:
loss = compute_loss(model, x)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
Tập huấn
- Bắt đầu bằng cách lặp lại tập dữ liệu
- Trong mỗi lần lặp lại, hãy chuyển hình ảnh đến bộ mã hóa để có được một tập hợp các tham số trung bình và log-phương sai của \(q(z|x)\)gần đúng ở phía sau29
- sau đó áp dụng thủ thuật phân loại lại để lấy mẫu từ \(q(z|x)\)
- Cuối cùng, chuyển các mẫu đã được đánh giá lại cho bộ giải mã để lấy nhật ký của phân phối tạo sinh \(p(x|z)\)
- Lưu ý: Vì bạn sử dụng tập dữ liệu được tải bởi keras với 60 nghìn điểm dữ liệu trong tập huấn luyện và 10k điểm dữ liệu trong tập thử nghiệm, kết quả ELBO của chúng tôi trên tập thử nghiệm cao hơn một chút so với kết quả được báo cáo trong tài liệu sử dụng binarization động của MNIST của Larochelle.
Tạo hình ảnh
- Sau khi đào tạo, đã đến lúc tạo ra một số hình ảnh
- Bắt đầu bằng cách lấy mẫu một tập hợp các vectơ tiềm ẩn từ đơn vị phân phối trước Gaussian \(p(z)\)
- Sau đó, bộ tạo sẽ chuyển đổi mẫu tiềm ẩn \(z\) thành log của quan sát, tạo ra một phân phối \(p(x|z)\)
- Ở đây, hãy vẽ biểu đồ xác suất của các phân phối Bernoulli
epochs = 10
# set the dimensionality of the latent space to a plane for visualization later
latent_dim = 2
num_examples_to_generate = 16
# keeping the random vector constant for generation (prediction) so
# it will be easier to see the improvement.
random_vector_for_generation = tf.random.normal(
shape=[num_examples_to_generate, latent_dim])
model = CVAE(latent_dim)
def generate_and_save_images(model, epoch, test_sample):
mean, logvar = model.encode(test_sample)
z = model.reparameterize(mean, logvar)
predictions = model.sample(z)
fig = plt.figure(figsize=(4, 4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i + 1)
plt.imshow(predictions[i, :, :, 0], cmap='gray')
plt.axis('off')
# tight_layout minimizes the overlap between 2 sub-plots
plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
# Pick a sample of the test set for generating output images
assert batch_size >= num_examples_to_generate
for test_batch in test_dataset.take(1):
test_sample = test_batch[0:num_examples_to_generate, :, :, :]
generate_and_save_images(model, 0, test_sample)
for epoch in range(1, epochs + 1):
start_time = time.time()
for train_x in train_dataset:
train_step(model, train_x, optimizer)
end_time = time.time()
loss = tf.keras.metrics.Mean()
for test_x in test_dataset:
loss(compute_loss(model, test_x))
elbo = -loss.result()
display.clear_output(wait=False)
print('Epoch: {}, Test set ELBO: {}, time elapse for current epoch: {}'
.format(epoch, elbo, end_time - start_time))
generate_and_save_images(model, epoch, test_sample)
Epoch: 10, Test set ELBO: -156.4964141845703, time elapse for current epoch: 4.854437351226807

Hiển thị hình ảnh được tạo từ kỷ nguyên đào tạo cuối cùng
def display_image(epoch_no):
return PIL.Image.open('image_at_epoch_{:04d}.png'.format(epoch_no))
plt.imshow(display_image(epoch))
plt.axis('off') # Display images
(-0.5, 287.5, 287.5, -0.5)
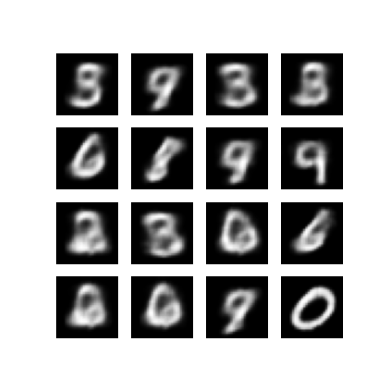
Hiển thị một GIF động của tất cả các hình ảnh đã lưu
anim_file = 'cvae.gif'
with imageio.get_writer(anim_file, mode='I') as writer:
filenames = glob.glob('image*.png')
filenames = sorted(filenames)
for filename in filenames:
image = imageio.imread(filename)
writer.append_data(image)
image = imageio.imread(filename)
writer.append_data(image)
import tensorflow_docs.vis.embed as embed
embed.embed_file(anim_file)

Hiển thị đa dạng chữ số 2D từ không gian ẩn
Chạy mã bên dưới sẽ hiển thị sự phân bố liên tục của các lớp chữ số khác nhau, với mỗi chữ số biến đổi thành một chữ số khác trên không gian tiềm ẩn 2D. Sử dụng Xác suất TensorFlow để tạo phân phối chuẩn chuẩn cho không gian tiềm ẩn.
def plot_latent_images(model, n, digit_size=28):
"""Plots n x n digit images decoded from the latent space."""
norm = tfp.distributions.Normal(0, 1)
grid_x = norm.quantile(np.linspace(0.05, 0.95, n))
grid_y = norm.quantile(np.linspace(0.05, 0.95, n))
image_width = digit_size*n
image_height = image_width
image = np.zeros((image_height, image_width))
for i, yi in enumerate(grid_x):
for j, xi in enumerate(grid_y):
z = np.array([[xi, yi]])
x_decoded = model.sample(z)
digit = tf.reshape(x_decoded[0], (digit_size, digit_size))
image[i * digit_size: (i + 1) * digit_size,
j * digit_size: (j + 1) * digit_size] = digit.numpy()
plt.figure(figsize=(10, 10))
plt.imshow(image, cmap='Greys_r')
plt.axis('Off')
plt.show()
plot_latent_images(model, 20)

Bước tiếp theo
Hướng dẫn này đã trình bày cách triển khai một bộ mã tự động biến thể phức hợp bằng cách sử dụng TensorFlow.
Bước tiếp theo, bạn có thể cố gắng cải thiện đầu ra của mô hình bằng cách tăng kích thước mạng. Ví dụ: bạn có thể thử đặt các thông số filter cho từng lớp Conv2D và Conv2DTranspose thành 512. Lưu ý rằng để tạo biểu đồ hình ảnh ẩn 2D cuối cùng, bạn cần giữ latent_dim thành 2. Ngoài ra, thời gian đào tạo sẽ tăng lên khi kích thước mạng tăng lên.
Bạn cũng có thể thử triển khai VAE bằng cách sử dụng một tập dữ liệu khác, chẳng hạn như CIFAR-10.
VAE có thể được thực hiện theo nhiều kiểu khác nhau và có độ phức tạp khác nhau. Bạn có thể tìm thấy các triển khai bổ sung trong các nguồn sau:
- Variational AutoEncoder (keras.io)
- Ví dụ về VAE từ hướng dẫn "Viết các lớp và mô hình tùy chỉnh" (tensorflow.org)
- Lớp xác suất TFP: Bộ mã hóa tự động biến thiên
Nếu bạn muốn tìm hiểu thêm về các chi tiết của VAE, vui lòng tham khảo Giới thiệu về Bộ mã tự động biến thể .