
| | |  GitHub पर स्रोत देखें GitHub पर स्रोत देखें | |
यह नोटबुक दर्शाती है कि MNIST डेटासेट पर एक वेरिएशनल ऑटोएन्कोडर (VAE) ( 1 , 2 ) को कैसे प्रशिक्षित किया जाए। VAE ऑटोएन्कोडर पर एक संभाव्य टेक है, एक मॉडल जो उच्च आयामी इनपुट डेटा लेता है और इसे एक छोटे प्रतिनिधित्व में संपीड़ित करता है। एक पारंपरिक ऑटोएन्कोडर के विपरीत, जो एक गुप्त वेक्टर पर इनपुट को मैप करता है, एक वीएई इनपुट डेटा को संभाव्यता वितरण के पैरामीटर में मैप करता है, जैसे गॉसियन का माध्य और भिन्नता। यह दृष्टिकोण एक सतत, संरचित गुप्त स्थान उत्पन्न करता है, जो छवि निर्माण के लिए उपयोगी है।

सेट अप
35 एल10एन-प्लेसहोल्डरpip install tensorflow-probability# to generate gifspip install imageiopip install git+https://github.com/tensorflow/docs
from IPython import display
import glob
import imageio
import matplotlib.pyplot as plt
import numpy as np
import PIL
import tensorflow as tf
import tensorflow_probability as tfp
import time
MNIST डेटासेट लोड करें
प्रत्येक एमएनआईएसटी छवि मूल रूप से 784 पूर्णांकों का एक वेक्टर है, जिनमें से प्रत्येक 0-255 के बीच है और एक पिक्सेल की तीव्रता का प्रतिनिधित्व करता है। हमारे मॉडल में बर्नौली वितरण के साथ प्रत्येक पिक्सेल को मॉडल करें, और डेटासेट को स्थिर रूप से बाइनरी करें।
(train_images, _), (test_images, _) = tf.keras.datasets.mnist.load_data()
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz 11493376/11490434 [==============================] - 0s 0us/step 11501568/11490434 [==============================] - 0s 0us/step
def preprocess_images(images):
images = images.reshape((images.shape[0], 28, 28, 1)) / 255.
return np.where(images > .5, 1.0, 0.0).astype('float32')
train_images = preprocess_images(train_images)
test_images = preprocess_images(test_images)
train_size = 60000
batch_size = 32
test_size = 10000
डेटा को बैचने और फेरबदल करने के लिए tf.data का उपयोग करें
train_dataset = (tf.data.Dataset.from_tensor_slices(train_images)
.shuffle(train_size).batch(batch_size))
test_dataset = (tf.data.Dataset.from_tensor_slices(test_images)
.shuffle(test_size).batch(batch_size))
एन्कोडर और डिकोडर नेटवर्क को tf.keras.Sequential के साथ परिभाषित करें
इस VAE उदाहरण में, एन्कोडर और डिकोडर नेटवर्क के लिए दो छोटे ConvNets का उपयोग करें। साहित्य में, इन नेटवर्कों को क्रमशः अनुमान/मान्यता और जनक मॉडल के रूप में भी जाना जाता है। कार्यान्वयन को आसान बनाने के लिए tf.keras.Sequential का उपयोग करें। मान लीजिए \(x\) और \(z\) निम्नलिखित विवरण में क्रमशः प्रेक्षण और गुप्त चर को निरूपित करते हैं।
एनकोडर नेटवर्क
यह अनुमानित पश्च वितरण \(q(z|x)\)को परिभाषित करता है, जो इनपुट के रूप में एक अवलोकन लेता है और गुप्त प्रतिनिधित्व \(z\)के सशर्त वितरण को निर्दिष्ट करने के लिए पैरामीटर का एक सेट आउटपुट करता है। इस उदाहरण में, वितरण को केवल एक विकर्ण गाऊसी के रूप में मॉडल करें, और नेटवर्क एक कारक गाऊसी के माध्य और लॉग-विचरण मापदंडों को आउटपुट करता है। संख्यात्मक स्थिरता के लिए सीधे विचरण के बजाय आउटपुट लॉग-विचरण।
डिकोडर नेटवर्क
यह अवलोकन \(p(x|z)\)के सशर्त वितरण को परिभाषित करता है, जो इनपुट के रूप में एक गुप्त नमूना \(z\) लेता है और अवलोकन के सशर्त वितरण के लिए पैरामीटर आउटपुट करता है। एक इकाई गाऊसी के रूप में पूर्व \(p(z)\) के गुप्त वितरण को मॉडल करें।
रिपैरामीटराइजेशन ट्रिक
प्रशिक्षण के दौरान डिकोडर के लिए नमूना \(z\) उत्पन्न करने के लिए, आप इनपुट अवलोकन \(x\)दिए गए एन्कोडर द्वारा आउटपुट पैरामीटर द्वारा परिभाषित गुप्त वितरण से नमूना ले सकते हैं। हालाँकि, यह सैंपलिंग ऑपरेशन एक अड़चन पैदा करता है क्योंकि बैकप्रोपेगेशन एक यादृच्छिक नोड के माध्यम से प्रवाहित नहीं हो सकता है।
इसे संबोधित करने के लिए, एक पुनर्मूल्यांकन चाल का उपयोग करें। हमारे उदाहरण में, आप डिकोडर पैरामीटर और अन्य पैरामीटर \(\epsilon\) placeholder11 का उपयोग करके \(z\) का अनुमान लगाते हैं:
\[z = \mu + \sigma \odot \epsilon\]
जहाँ \(\mu\) और \(\sigma\) क्रमशः गाऊसी वितरण के माध्य और मानक विचलन का प्रतिनिधित्व करते हैं। उन्हें डिकोडर आउटपुट से प्राप्त किया जा सकता है। \(\epsilon\) को एक यादृच्छिक शोर के रूप में माना जा सकता है जिसका उपयोग \(z\)की स्टोचैस्टिसिटी बनाए रखने के लिए किया जाता है। मानक सामान्य वितरण से \(\epsilon\) उत्पन्न करें।
अव्यक्त चर \(z\) अब \(\mu\), \(\sigma\) और \(\epsilon\)के एक फ़ंक्शन द्वारा उत्पन्न होता है, जो मॉडल को क्रमशः l10n \(\mu\) और \(\sigma\) के माध्यम से एन्कोडर में ग्रेडिएंट को बैकप्रोपेगेट करने में सक्षम बनाता है, जबकि स्टोचैस्टिसिटी बनाए रखता है \(\epsilon\)।
नेटवर्क आर्किटेक्चर
एन्कोडर नेटवर्क के लिए, दो कन्वेन्शनल लेयर्स का उपयोग करें और उसके बाद पूरी तरह से कनेक्टेड लेयर का उपयोग करें। डिकोडर नेटवर्क में, पूरी तरह से जुड़ी हुई परत का उपयोग करके इस आर्किटेक्चर को मिरर करें, इसके बाद तीन कनवल्शन ट्रांसपोज़ लेयर्स (कुछ संदर्भों में उर्फ डीकोनवोल्यूशनल लेयर्स) का उपयोग करें। ध्यान दें, वीएई को प्रशिक्षण देते समय बैच सामान्यीकरण का उपयोग करने से बचना आम बात है, क्योंकि मिनी-बैच का उपयोग करने के कारण अतिरिक्त स्टोचैस्टिसिटी नमूनाकरण से स्टोचैस्टिसिटी के शीर्ष पर अस्थिरता को बढ़ा सकती है।
class CVAE(tf.keras.Model):
"""Convolutional variational autoencoder."""
def __init__(self, latent_dim):
super(CVAE, self).__init__()
self.latent_dim = latent_dim
self.encoder = tf.keras.Sequential(
[
tf.keras.layers.InputLayer(input_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(
filters=32, kernel_size=3, strides=(2, 2), activation='relu'),
tf.keras.layers.Conv2D(
filters=64, kernel_size=3, strides=(2, 2), activation='relu'),
tf.keras.layers.Flatten(),
# No activation
tf.keras.layers.Dense(latent_dim + latent_dim),
]
)
self.decoder = tf.keras.Sequential(
[
tf.keras.layers.InputLayer(input_shape=(latent_dim,)),
tf.keras.layers.Dense(units=7*7*32, activation=tf.nn.relu),
tf.keras.layers.Reshape(target_shape=(7, 7, 32)),
tf.keras.layers.Conv2DTranspose(
filters=64, kernel_size=3, strides=2, padding='same',
activation='relu'),
tf.keras.layers.Conv2DTranspose(
filters=32, kernel_size=3, strides=2, padding='same',
activation='relu'),
# No activation
tf.keras.layers.Conv2DTranspose(
filters=1, kernel_size=3, strides=1, padding='same'),
]
)
@tf.function
def sample(self, eps=None):
if eps is None:
eps = tf.random.normal(shape=(100, self.latent_dim))
return self.decode(eps, apply_sigmoid=True)
def encode(self, x):
mean, logvar = tf.split(self.encoder(x), num_or_size_splits=2, axis=1)
return mean, logvar
def reparameterize(self, mean, logvar):
eps = tf.random.normal(shape=mean.shape)
return eps * tf.exp(logvar * .5) + mean
def decode(self, z, apply_sigmoid=False):
logits = self.decoder(z)
if apply_sigmoid:
probs = tf.sigmoid(logits)
return probs
return logits
हानि फ़ंक्शन और अनुकूलक को परिभाषित करें
वीएई सीमांत लॉग-संभावना पर साक्ष्य को कम करने वाले (ईएलबीओ) को अधिकतम करके प्रशिक्षित करते हैं:
\[\log p(x) \ge \text{ELBO} = \mathbb{E}_{q(z|x)}\left[\log \frac{p(x, z)}{q(z|x)}\right].\]
व्यवहार में, इस अपेक्षा के एकल नमूना मोंटे कार्लो अनुमान का अनुकूलन करें:
\[\log p(x| z) + \log p(z) - \log q(z|x),\]
जहां \(z\) \(q(z|x)\)नमूना लिया गया है।
optimizer = tf.keras.optimizers.Adam(1e-4)
def log_normal_pdf(sample, mean, logvar, raxis=1):
log2pi = tf.math.log(2. * np.pi)
return tf.reduce_sum(
-.5 * ((sample - mean) ** 2. * tf.exp(-logvar) + logvar + log2pi),
axis=raxis)
def compute_loss(model, x):
mean, logvar = model.encode(x)
z = model.reparameterize(mean, logvar)
x_logit = model.decode(z)
cross_ent = tf.nn.sigmoid_cross_entropy_with_logits(logits=x_logit, labels=x)
logpx_z = -tf.reduce_sum(cross_ent, axis=[1, 2, 3])
logpz = log_normal_pdf(z, 0., 0.)
logqz_x = log_normal_pdf(z, mean, logvar)
return -tf.reduce_mean(logpx_z + logpz - logqz_x)
@tf.function
def train_step(model, x, optimizer):
"""Executes one training step and returns the loss.
This function computes the loss and gradients, and uses the latter to
update the model's parameters.
"""
with tf.GradientTape() as tape:
loss = compute_loss(model, x)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
प्रशिक्षण
- डेटासेट पर पुनरावृति करके प्रारंभ करें
- प्रत्येक पुनरावृत्ति के दौरान, अनुमानित पश्च \(q(z|x)\)के माध्य और लॉग-विचरण मापदंडों का एक सेट प्राप्त करने के लिए छवि को एन्कोडर को पास करें
- फिर \(q(z|x)\). से नमूने के लिए रिपैरामीटराइजेशन ट्रिक लागू करें
- अंत में, जनरेटिव डिस्ट्रीब्यूशन l10n- \(p(x|z)\)31 के लॉग प्राप्त करने के लिए डिकोडर को रिपैरामीटराइज्ड सैंपल पास करें
- नोट: चूंकि आप केरस द्वारा लोड किए गए डेटासेट का उपयोग प्रशिक्षण सेट में 60k डेटापॉइंट्स और परीक्षण सेट में 10k डेटापॉइंट्स के साथ करते हैं, इसलिए परीक्षण सेट पर हमारा परिणामी ELBO साहित्य में रिपोर्ट किए गए परिणामों की तुलना में थोड़ा अधिक है जो लैरोशेल के MNIST के डायनेमिक बायनेराइज़ेशन का उपयोग करता है।
चित्र बनाना
- प्रशिक्षण के बाद, कुछ चित्र बनाने का समय आ गया है
- इकाई गाऊसी पूर्व वितरण \(p(z)\). से अव्यक्त वैक्टर के एक सेट का नमूना लेकर प्रारंभ करें
- इसके बाद जनरेटर अव्यक्त नमूने \(z\) को प्रेक्षण के लॉग में बदल देगा, जिससे वितरण \(p(x|z)\)हो जाएगा।
- यहाँ, बर्नौली बंटन की प्रायिकताएँ आलेखित करें
epochs = 10
# set the dimensionality of the latent space to a plane for visualization later
latent_dim = 2
num_examples_to_generate = 16
# keeping the random vector constant for generation (prediction) so
# it will be easier to see the improvement.
random_vector_for_generation = tf.random.normal(
shape=[num_examples_to_generate, latent_dim])
model = CVAE(latent_dim)
def generate_and_save_images(model, epoch, test_sample):
mean, logvar = model.encode(test_sample)
z = model.reparameterize(mean, logvar)
predictions = model.sample(z)
fig = plt.figure(figsize=(4, 4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i + 1)
plt.imshow(predictions[i, :, :, 0], cmap='gray')
plt.axis('off')
# tight_layout minimizes the overlap between 2 sub-plots
plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
# Pick a sample of the test set for generating output images
assert batch_size >= num_examples_to_generate
for test_batch in test_dataset.take(1):
test_sample = test_batch[0:num_examples_to_generate, :, :, :]
generate_and_save_images(model, 0, test_sample)
for epoch in range(1, epochs + 1):
start_time = time.time()
for train_x in train_dataset:
train_step(model, train_x, optimizer)
end_time = time.time()
loss = tf.keras.metrics.Mean()
for test_x in test_dataset:
loss(compute_loss(model, test_x))
elbo = -loss.result()
display.clear_output(wait=False)
print('Epoch: {}, Test set ELBO: {}, time elapse for current epoch: {}'
.format(epoch, elbo, end_time - start_time))
generate_and_save_images(model, epoch, test_sample)
Epoch: 10, Test set ELBO: -156.4964141845703, time elapse for current epoch: 4.854437351226807

पिछले प्रशिक्षण युग से उत्पन्न छवि प्रदर्शित करें
def display_image(epoch_no):
return PIL.Image.open('image_at_epoch_{:04d}.png'.format(epoch_no))
plt.imshow(display_image(epoch))
plt.axis('off') # Display images
(-0.5, 287.5, 287.5, -0.5)
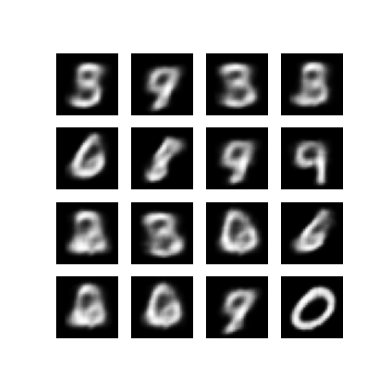
सभी सहेजी गई छवियों का एनिमेटेड GIF प्रदर्शित करें
anim_file = 'cvae.gif'
with imageio.get_writer(anim_file, mode='I') as writer:
filenames = glob.glob('image*.png')
filenames = sorted(filenames)
for filename in filenames:
image = imageio.imread(filename)
writer.append_data(image)
image = imageio.imread(filename)
writer.append_data(image)
import tensorflow_docs.vis.embed as embed
embed.embed_file(anim_file)

अव्यक्त स्थान से अंकों का एक 2D कई गुना प्रदर्शित करें
नीचे दिए गए कोड को चलाने से विभिन्न अंकों के वर्गों का निरंतर वितरण दिखाई देगा, जिसमें प्रत्येक अंक 2D गुप्त स्थान में दूसरे में रूपांतरित हो जाएगा। गुप्त स्थान के लिए मानक सामान्य वितरण उत्पन्न करने के लिए TensorFlow प्रायिकता का उपयोग करें।
def plot_latent_images(model, n, digit_size=28):
"""Plots n x n digit images decoded from the latent space."""
norm = tfp.distributions.Normal(0, 1)
grid_x = norm.quantile(np.linspace(0.05, 0.95, n))
grid_y = norm.quantile(np.linspace(0.05, 0.95, n))
image_width = digit_size*n
image_height = image_width
image = np.zeros((image_height, image_width))
for i, yi in enumerate(grid_x):
for j, xi in enumerate(grid_y):
z = np.array([[xi, yi]])
x_decoded = model.sample(z)
digit = tf.reshape(x_decoded[0], (digit_size, digit_size))
image[i * digit_size: (i + 1) * digit_size,
j * digit_size: (j + 1) * digit_size] = digit.numpy()
plt.figure(figsize=(10, 10))
plt.imshow(image, cmap='Greys_r')
plt.axis('Off')
plt.show()
plot_latent_images(model, 20)

अगले कदम
इस ट्यूटोरियल ने प्रदर्शित किया है कि TensorFlow का उपयोग करके एक कन्वेन्शनल वेरिएबल ऑटोएन्कोडर को कैसे कार्यान्वित किया जाए।
अगले चरण के रूप में, आप नेटवर्क आकार को बढ़ाकर मॉडल आउटपुट को बेहतर बनाने का प्रयास कर सकते हैं। उदाहरण के लिए, आप प्रत्येक Conv2D और Conv2DTranspose लेयर के लिए 512 पर filter पैरामीटर सेट करने का प्रयास कर सकते हैं। ध्यान दें कि अंतिम 2D अव्यक्त छवि प्लॉट उत्पन्न करने के लिए, आपको latent_dim को 2 पर रखना होगा। साथ ही, प्रशिक्षण समय में वृद्धि होगी जैसे-जैसे नेटवर्क का आकार बढ़ता है।
आप CIFAR-10 जैसे भिन्न डेटासेट का उपयोग करके VAE को लागू करने का भी प्रयास कर सकते हैं।
VAE को कई अलग-अलग शैलियों और अलग-अलग जटिलता में लागू किया जा सकता है। आप निम्नलिखित स्रोतों में अतिरिक्त कार्यान्वयन पा सकते हैं:
- वैरिएशनल ऑटोएन्कोडर (keras.io)
- "कस्टम परतें और मॉडल लिखना" मार्गदर्शिका से VAE उदाहरण (tensorflow.org)
- TFP संभाव्य परतें: भिन्न ऑटो एनकोडर
यदि आप वीएई के विवरण के बारे में अधिक जानना चाहते हैं, तो कृपया विविधतापूर्ण ऑटोएन्कोडर का परिचय देखें।