
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
این نوت بوک نحوه آموزش رمزگذار خودکار متغیر (VAE) ( 1 ، 2 ) را بر روی مجموعه داده MNIST نشان می دهد. VAE یک برداشت احتمالی از رمزگذار خودکار است، مدلی که داده های ورودی با ابعاد بالا را می گیرد و آن را به یک نمایش کوچکتر فشرده می کند. بر خلاف رمزگذار خودکار سنتی، که ورودی را بر روی یک بردار نهفته نگاشت میکند، یک VAE دادههای ورودی را در پارامترهای توزیع احتمال، مانند میانگین و واریانس گاوسی نگاشت میکند. این رویکرد یک فضای پنهان پیوسته و ساختار یافته را ایجاد می کند که برای تولید تصویر مفید است.

برپایی
pip install tensorflow-probability# to generate gifspip install imageiopip install git+https://github.com/tensorflow/docs
from IPython import display
import glob
import imageio
import matplotlib.pyplot as plt
import numpy as np
import PIL
import tensorflow as tf
import tensorflow_probability as tfp
import time
مجموعه داده MNIST را بارگیری کنید
هر تصویر MNIST در اصل بردار 784 عدد صحیح است که هر کدام بین 0-255 است و شدت یک پیکسل را نشان می دهد. هر پیکسل را با توزیع برنولی در مدل ما مدل کنید و مجموعه داده را به صورت استاتیکی باینری کنید.
(train_images, _), (test_images, _) = tf.keras.datasets.mnist.load_data()
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz 11493376/11490434 [==============================] - 0s 0us/step 11501568/11490434 [==============================] - 0s 0us/step
def preprocess_images(images):
images = images.reshape((images.shape[0], 28, 28, 1)) / 255.
return np.where(images > .5, 1.0, 0.0).astype('float32')
train_images = preprocess_images(train_images)
test_images = preprocess_images(test_images)
train_size = 60000
batch_size = 32
test_size = 10000
از tf.data برای دسته بندی و به هم زدن داده ها استفاده کنید
train_dataset = (tf.data.Dataset.from_tensor_slices(train_images)
.shuffle(train_size).batch(batch_size))
test_dataset = (tf.data.Dataset.from_tensor_slices(test_images)
.shuffle(test_size).batch(batch_size))
شبکه های رمزگذار و رمزگشا را با tf.keras.Sequential تعریف کنید
در این مثال VAE، از دو ConvNet کوچک برای شبکه های رمزگذار و رمزگشا استفاده کنید. در ادبیات، این شبکه ها به ترتیب به عنوان مدل های استنتاج/شناخت و مولد نیز شناخته می شوند. از tf.keras.Sequential برای ساده سازی پیاده سازی استفاده کنید. اجازه دهید \(x\) و \(z\) به ترتیب متغیر مشاهده و پنهان را در توضیحات زیر نشان دهند.
شبکه رمزگذار
این توزیع تقریبی پسین \(q(z|x)\)را تعریف می کند، که به عنوان ورودی یک مشاهده می گیرد و مجموعه ای از پارامترها را برای تعیین توزیع شرطی نمایش پنهان \(z\)خروجی می دهد. در این مثال، به سادگی توزیع را به صورت یک گاوسی مورب مدل کنید، و شبکه پارامترهای میانگین و لگاریتم واریانس یک گاوس فاکتور شده را خروجی میدهد. خروجی ورود واریانس به جای واریانس مستقیم برای ثبات عددی.
شبکه رمزگشا
این توزیع مشروط مشاهده \(p(x|z)\)را تعریف می کند، که یک نمونه پنهان \(z\) را به عنوان ورودی می گیرد و پارامترهای یک توزیع مشروط مشاهده را خروجی می کند. توزیع پنهان قبل از \(p(z)\) را به عنوان یک واحد گاوسی مدل کنید.
ترفند پارامترسازی مجدد
برای تولید یک نمونه \(z\) برای رمزگشا در طول آموزش، می توانید از توزیع پنهان تعریف شده توسط پارامترهای خروجی توسط رمزگذار، با توجه به مشاهده ورودی \(x\)نمونه برداری کنید. با این حال، این عملیات نمونهبرداری یک گلوگاه ایجاد میکند، زیرا پس انتشار نمیتواند از طریق یک گره تصادفی جریان یابد.
برای رفع این مشکل، از ترفند پارامترسازی مجدد استفاده کنید. در مثال ما، شما \(z\) را با استفاده از پارامترهای رمزگشا و پارامتر دیگر \(\epsilon\) را به صورت زیر تقریب میزنید:
\[z = \mu + \sigma \odot \epsilon\]
که در آن \(\mu\) و \(\sigma\) به ترتیب میانگین و انحراف استاندارد یک توزیع گاوسی را نشان می دهند. آنها را می توان از خروجی رمزگشا به دست آورد. \(\epsilon\) را می توان به عنوان یک نویز تصادفی در نظر گرفت که برای حفظ تصادفی \(z\)استفاده می شود. \(\epsilon\) را از یک توزیع نرمال استاندارد ایجاد کنید.
متغیر نهفته \(z\) اکنون توسط تابعی از \(\mu\)، \(\sigma\) و \(\epsilon\)تولید می شود، که مدل را قادر می سازد تا گرادیان ها را در رمزگذار از طریق \(\mu\) placeholder، در حالی که 10n-placeholderlystoholder22 و \(\sigma\) به طور قابل توجهی منتشر کند، ایجاد می کند. \(\epsilon\).
معماری شبکه
برای شبکه رمزگذار، از دو لایه کانولوشن و به دنبال آن یک لایه کاملا متصل استفاده کنید. در شبکه رمزگشا، این معماری را با استفاده از یک لایه کاملاً متصل و به دنبال آن سه لایه انتقال کانولوشن (که در برخی زمینهها به لایههای دکانولوشنال معروف است) منعکس کنید. توجه داشته باشید، پرهیز از استفاده از نرمال سازی دسته ای هنگام آموزش VAE ها معمول است، زیرا تصادفی اضافی ناشی از استفاده از مینی بچ ها ممکن است ناپایداری در بالای تصادفی ناشی از نمونه برداری را تشدید کند.
class CVAE(tf.keras.Model):
"""Convolutional variational autoencoder."""
def __init__(self, latent_dim):
super(CVAE, self).__init__()
self.latent_dim = latent_dim
self.encoder = tf.keras.Sequential(
[
tf.keras.layers.InputLayer(input_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(
filters=32, kernel_size=3, strides=(2, 2), activation='relu'),
tf.keras.layers.Conv2D(
filters=64, kernel_size=3, strides=(2, 2), activation='relu'),
tf.keras.layers.Flatten(),
# No activation
tf.keras.layers.Dense(latent_dim + latent_dim),
]
)
self.decoder = tf.keras.Sequential(
[
tf.keras.layers.InputLayer(input_shape=(latent_dim,)),
tf.keras.layers.Dense(units=7*7*32, activation=tf.nn.relu),
tf.keras.layers.Reshape(target_shape=(7, 7, 32)),
tf.keras.layers.Conv2DTranspose(
filters=64, kernel_size=3, strides=2, padding='same',
activation='relu'),
tf.keras.layers.Conv2DTranspose(
filters=32, kernel_size=3, strides=2, padding='same',
activation='relu'),
# No activation
tf.keras.layers.Conv2DTranspose(
filters=1, kernel_size=3, strides=1, padding='same'),
]
)
@tf.function
def sample(self, eps=None):
if eps is None:
eps = tf.random.normal(shape=(100, self.latent_dim))
return self.decode(eps, apply_sigmoid=True)
def encode(self, x):
mean, logvar = tf.split(self.encoder(x), num_or_size_splits=2, axis=1)
return mean, logvar
def reparameterize(self, mean, logvar):
eps = tf.random.normal(shape=mean.shape)
return eps * tf.exp(logvar * .5) + mean
def decode(self, z, apply_sigmoid=False):
logits = self.decoder(z)
if apply_sigmoid:
probs = tf.sigmoid(logits)
return probs
return logits
تابع ضرر و بهینه ساز را تعریف کنید
VAEها با به حداکثر رساندن کران پایین شواهد (ELBO) در لاگ احتمال حاشیه ای تمرین می کنند:
\[\log p(x) \ge \text{ELBO} = \mathbb{E}_{q(z|x)}\left[\log \frac{p(x, z)}{q(z|x)}\right].\]
در عمل، تخمین تک نمونه مونت کارلو از این انتظار را بهینه کنید:
\[\log p(x| z) + \log p(z) - \log q(z|x),\]
که در آن \(z\) از \(q(z|x)\)placeholder28 نمونه برداری شده است.
optimizer = tf.keras.optimizers.Adam(1e-4)
def log_normal_pdf(sample, mean, logvar, raxis=1):
log2pi = tf.math.log(2. * np.pi)
return tf.reduce_sum(
-.5 * ((sample - mean) ** 2. * tf.exp(-logvar) + logvar + log2pi),
axis=raxis)
def compute_loss(model, x):
mean, logvar = model.encode(x)
z = model.reparameterize(mean, logvar)
x_logit = model.decode(z)
cross_ent = tf.nn.sigmoid_cross_entropy_with_logits(logits=x_logit, labels=x)
logpx_z = -tf.reduce_sum(cross_ent, axis=[1, 2, 3])
logpz = log_normal_pdf(z, 0., 0.)
logqz_x = log_normal_pdf(z, mean, logvar)
return -tf.reduce_mean(logpx_z + logpz - logqz_x)
@tf.function
def train_step(model, x, optimizer):
"""Executes one training step and returns the loss.
This function computes the loss and gradients, and uses the latter to
update the model's parameters.
"""
with tf.GradientTape() as tape:
loss = compute_loss(model, x)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
آموزش
- با تکرار روی مجموعه داده شروع کنید
- در طول هر تکرار، تصویر را به رمزگذار ارسال کنید تا مجموعهای از پارامترهای میانگین و log-واریانس از \(q(z|x)\)خلفی تقریبی به دست آید.
- سپس ترفند پارامترسازی مجدد را برای نمونه از \(q(z|x)\)اعمال کنید
- در نهایت، نمونه های مجدد پارامتر شده را به رمزگشا ارسال کنید تا logit های توزیع مولد \(p(x|z)\)به دست آید.
- توجه: از آنجایی که از مجموعه داده بارگیری شده توسط keras با 60k نقطه داده در مجموعه آموزشی و 10k نقطه داده در مجموعه آزمایشی استفاده میکنید، ELBO حاصل در مجموعه آزمایشی کمی بالاتر از نتایج گزارششده در ادبیات است که از باینریسازی پویا MNIST Larochelle استفاده میکند.
تولید تصاویر
- بعد از آموزش نوبت به تولید چند تصویر می رسد
- با نمونه برداری از مجموعه ای از بردارهای پنهان از واحد توزیع قبلی گاوسی \(p(z)\)شروع کنید.
- سپس مولد نمونه نهفته \(z\) را به logits مشاهدات تبدیل می کند و توزیع \(p(x|z)\)دهد.
- در اینجا احتمالات توزیع های برنولی را رسم کنید
epochs = 10
# set the dimensionality of the latent space to a plane for visualization later
latent_dim = 2
num_examples_to_generate = 16
# keeping the random vector constant for generation (prediction) so
# it will be easier to see the improvement.
random_vector_for_generation = tf.random.normal(
shape=[num_examples_to_generate, latent_dim])
model = CVAE(latent_dim)
def generate_and_save_images(model, epoch, test_sample):
mean, logvar = model.encode(test_sample)
z = model.reparameterize(mean, logvar)
predictions = model.sample(z)
fig = plt.figure(figsize=(4, 4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i + 1)
plt.imshow(predictions[i, :, :, 0], cmap='gray')
plt.axis('off')
# tight_layout minimizes the overlap between 2 sub-plots
plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
# Pick a sample of the test set for generating output images
assert batch_size >= num_examples_to_generate
for test_batch in test_dataset.take(1):
test_sample = test_batch[0:num_examples_to_generate, :, :, :]
generate_and_save_images(model, 0, test_sample)
for epoch in range(1, epochs + 1):
start_time = time.time()
for train_x in train_dataset:
train_step(model, train_x, optimizer)
end_time = time.time()
loss = tf.keras.metrics.Mean()
for test_x in test_dataset:
loss(compute_loss(model, test_x))
elbo = -loss.result()
display.clear_output(wait=False)
print('Epoch: {}, Test set ELBO: {}, time elapse for current epoch: {}'
.format(epoch, elbo, end_time - start_time))
generate_and_save_images(model, epoch, test_sample)
Epoch: 10, Test set ELBO: -156.4964141845703, time elapse for current epoch: 4.854437351226807

نمایش یک تصویر تولید شده از آخرین دوره آموزشی
def display_image(epoch_no):
return PIL.Image.open('image_at_epoch_{:04d}.png'.format(epoch_no))
plt.imshow(display_image(epoch))
plt.axis('off') # Display images
(-0.5, 287.5, 287.5, -0.5)
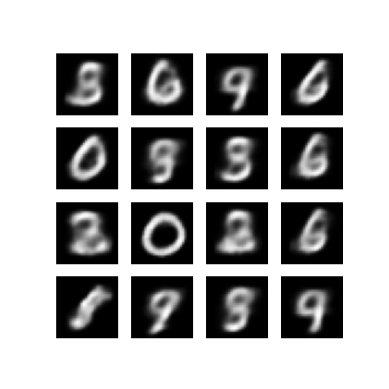
نمایش یک GIF متحرک از تمام تصاویر ذخیره شده
anim_file = 'cvae.gif'
with imageio.get_writer(anim_file, mode='I') as writer:
filenames = glob.glob('image*.png')
filenames = sorted(filenames)
for filename in filenames:
image = imageio.imread(filename)
writer.append_data(image)
image = imageio.imread(filename)
writer.append_data(image)
import tensorflow_docs.vis.embed as embed
embed.embed_file(anim_file)

نمایش منیفولد 2 بعدی از اعداد از فضای پنهان
اجرای کد زیر یک توزیع پیوسته از کلاسهای رقمی مختلف را نشان میدهد که هر رقم در فضای پنهان دوبعدی به رقم دیگری تبدیل میشود. از TensorFlow Probability برای ایجاد یک توزیع نرمال استاندارد برای فضای پنهان استفاده کنید.
def plot_latent_images(model, n, digit_size=28):
"""Plots n x n digit images decoded from the latent space."""
norm = tfp.distributions.Normal(0, 1)
grid_x = norm.quantile(np.linspace(0.05, 0.95, n))
grid_y = norm.quantile(np.linspace(0.05, 0.95, n))
image_width = digit_size*n
image_height = image_width
image = np.zeros((image_height, image_width))
for i, yi in enumerate(grid_x):
for j, xi in enumerate(grid_y):
z = np.array([[xi, yi]])
x_decoded = model.sample(z)
digit = tf.reshape(x_decoded[0], (digit_size, digit_size))
image[i * digit_size: (i + 1) * digit_size,
j * digit_size: (j + 1) * digit_size] = digit.numpy()
plt.figure(figsize=(10, 10))
plt.imshow(image, cmap='Greys_r')
plt.axis('Off')
plt.show()
plot_latent_images(model, 20)

مراحل بعدی
این آموزش نشان داده است که چگونه می توان یک رمزگذار خودکار متغیر کانولوشن را با استفاده از TensorFlow پیاده سازی کرد.
به عنوان گام بعدی، می توانید سعی کنید خروجی مدل را با افزایش اندازه شبکه بهبود بخشید. به عنوان مثال، میتوانید پارامترهای filter را برای هر یک از لایههای Conv2D و Conv2DTranspose روی 512 تنظیم کنید. توجه داشته باشید که برای ایجاد نمودار نهایی تصویر نهفته دو بعدی، باید latent_dim را روی 2 نگه دارید. همچنین، زمان آموزش افزایش مییابد. با افزایش اندازه شبکه
همچنین می توانید یک VAE را با استفاده از مجموعه داده های متفاوتی مانند CIFAR-10 پیاده سازی کنید.
VAE ها را می توان در چندین سبک مختلف و با پیچیدگی های متفاوت پیاده سازی کرد. می توانید پیاده سازی های اضافی را در منابع زیر بیابید:
- رمزگذار خودکار متغیر (keras.io)
- مثال VAE از راهنمای «نوشتن لایهها و مدلهای سفارشی» (tensorflow.org)
- لایههای احتمالی TFP: رمزگذار خودکار متغیر
اگر میخواهید درباره جزئیات VAE اطلاعات بیشتری کسب کنید، لطفاً به مقدمهای بر رمزگذارهای خودکار متغیر مراجعه کنید.