
| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন | |
এই নোটবুকটি MNIST ডেটাসেটে একটি ভেরিয়েশনাল অটোএনকোডার (VAE) ( 1 , 2 ) কীভাবে প্রশিক্ষণ দিতে হয় তা প্রদর্শন করে৷ একটি VAE হল অটোএনকোডারের উপর একটি সম্ভাব্য গ্রহণ, একটি মডেল যা উচ্চ মাত্রিক ইনপুট ডেটা নেয় এবং এটিকে একটি ছোট উপস্থাপনায় সংকুচিত করে। একটি প্রথাগত অটোএনকোডারের বিপরীতে, যা একটি সুপ্ত ভেক্টরে ইনপুটকে ম্যাপ করে, একটি VAE ইনপুট ডেটাকে একটি সম্ভাব্যতা বণ্টনের প্যারামিটারে ম্যাপ করে, যেমন একটি গাউসিয়ানের গড় এবং প্রকরণ। এই পদ্ধতিটি একটি অবিচ্ছিন্ন, কাঠামোগত সুপ্ত স্থান তৈরি করে, যা চিত্র তৈরির জন্য দরকারী।

সেটআপ
pip install tensorflow-probability# to generate gifspip install imageiopip install git+https://github.com/tensorflow/docs
from IPython import display
import glob
import imageio
import matplotlib.pyplot as plt
import numpy as np
import PIL
import tensorflow as tf
import tensorflow_probability as tfp
import time
MNIST ডেটাসেট লোড করুন
প্রতিটি MNIST চিত্র মূলত 784 পূর্ণসংখ্যার একটি ভেক্টর, যার প্রতিটি 0-255 এর মধ্যে এবং একটি পিক্সেলের তীব্রতা উপস্থাপন করে। আমাদের মডেলে একটি Bernoulli ডিস্ট্রিবিউশন সহ প্রতিটি পিক্সেল মডেল করুন এবং ডেটাসেটটিকে স্ট্যাটিকভাবে বাইনারি করুন।
(train_images, _), (test_images, _) = tf.keras.datasets.mnist.load_data()
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz 11493376/11490434 [==============================] - 0s 0us/step 11501568/11490434 [==============================] - 0s 0us/step
def preprocess_images(images):
images = images.reshape((images.shape[0], 28, 28, 1)) / 255.
return np.where(images > .5, 1.0, 0.0).astype('float32')
train_images = preprocess_images(train_images)
test_images = preprocess_images(test_images)
train_size = 60000
batch_size = 32
test_size = 10000
ব্যাচ এবং ডাটা শাফেল করতে tf.data ব্যবহার করুন
train_dataset = (tf.data.Dataset.from_tensor_slices(train_images)
.shuffle(train_size).batch(batch_size))
test_dataset = (tf.data.Dataset.from_tensor_slices(test_images)
.shuffle(test_size).batch(batch_size))
tf.keras.Sequential দিয়ে এনকোডার এবং ডিকোডার নেটওয়ার্ক সংজ্ঞায়িত করুন
এই VAE উদাহরণে, এনকোডার এবং ডিকোডার নেটওয়ার্কের জন্য দুটি ছোট কনভনেট ব্যবহার করুন। সাহিত্যে, এই নেটওয়ার্কগুলিকে যথাক্রমে অনুমান/স্বীকৃতি এবং জেনারেটিভ মডেল হিসাবেও উল্লেখ করা হয়। বাস্তবায়ন সহজ করতে tf.keras.Sequential ব্যবহার করুন। নিম্নোক্ত বর্ণনায় \(x\) এবং \(z\) যথাক্রমে পর্যবেক্ষণ এবং প্রচ্ছন্ন পরিবর্তনশীল নির্দেশ করে।
এনকোডার নেটওয়ার্ক
এটি আনুমানিক পোস্টেরিয়র ডিস্ট্রিবিউশন \(q(z|x)\)সংজ্ঞায়িত করে, যা ইনপুট একটি পর্যবেক্ষণ হিসাবে নেয় এবং সুপ্ত উপস্থাপনা \(z\)এর শর্তসাপেক্ষ বন্টন নির্দিষ্ট করার জন্য প্যারামিটারের একটি সেট আউটপুট করে। এই উদাহরণে, একটি তির্যক গাউসিয়ান হিসাবে বন্টনটিকে সহজভাবে মডেল করুন এবং নেটওয়ার্কটি একটি ফ্যাক্টরাইজড গাউসিয়ানের গড় এবং লগ-ভেরিয়েন্স প্যারামিটারগুলিকে আউটপুট করে। সাংখ্যিক স্থিতিশীলতার জন্য সরাসরি প্রকরণের পরিবর্তে আউটপুট লগ-ভেরিয়েন্স।
ডিকোডার নেটওয়ার্ক
এটি পর্যবেক্ষণ \(p(x|z)\)এর শর্তসাপেক্ষ বন্টনকে সংজ্ঞায়িত করে, যা একটি সুপ্ত নমুনা \(z\) ইনপুট হিসাবে নেয় এবং পর্যবেক্ষণের শর্তসাপেক্ষ বন্টনের জন্য পরামিতিগুলিকে আউটপুট করে। একটি ইউনিট গাউসিয়ান হিসাবে \(p(z)\) পূর্বের সুপ্ত বন্টন মডেল করুন।
রিপ্যারামিটারাইজেশন কৌশল
প্রশিক্ষণের সময় ডিকোডারের জন্য একটি নমুনা \(z\) তৈরি করতে, আপনি একটি ইনপুট পর্যবেক্ষণ \(x\)দেওয়া এনকোডার দ্বারা আউটপুট করা প্যারামিটার দ্বারা সংজ্ঞায়িত সুপ্ত বন্টন থেকে নমুনা নিতে পারেন। যাইহোক, এই স্যাম্পলিং অপারেশনটি একটি বাধা সৃষ্টি করে কারণ ব্যাকপ্রপাগেশন এলোমেলো নোডের মাধ্যমে প্রবাহিত হতে পারে না।
এটি মোকাবেলা করার জন্য, একটি রিপ্যারামিটারাইজেশন কৌশল ব্যবহার করুন। আমাদের উদাহরণে, আপনি আনুমানিক \(z\) ডিকোডার প্যারামিটার ব্যবহার করে এবং অন্য একটি প্যারামিটার \(\epsilon\) নিম্নরূপ:
\[z = \mu + \sigma \odot \epsilon\]
যেখানে \(\mu\) এবং \(\sigma\) যথাক্রমে একটি গাউসিয়ান ডিস্ট্রিবিউশনের গড় এবং আদর্শ বিচ্যুতির প্রতিনিধিত্ব করে। এগুলি ডিকোডার আউটপুট থেকে প্রাপ্ত করা যেতে পারে। \(\epsilon\) কে \(z\)এর স্টোকাস্টিসিটি বজায় রাখতে ব্যবহৃত একটি এলোমেলো শব্দ হিসেবে ভাবা যেতে পারে। একটি আদর্শ স্বাভাবিক বিতরণ থেকে \(\epsilon\) তৈরি করুন।
সুপ্ত পরিবর্তনশীল \(z\) এখন \(\mu\), \(\sigma\) এবং \(\epsilon\)এর একটি ফাংশন দ্বারা তৈরি করা হয়েছে, যা মডেলটিকে l10n-placeholder এর মাধ্যমে এনকোডারে গ্রেডিয়েন্ট ব্যাকপ্রোপাগেট করতে সক্ষম করবে, যখন \(\mu\) এবং \(\sigma\) 232-এর মাধ্যমে বজায় রাখবে। \(\epsilon\)।
নেটওয়ার্ক আর্কিটেকচার
এনকোডার নেটওয়ার্কের জন্য, একটি সম্পূর্ণ-সংযুক্ত স্তর অনুসরণ করে দুটি কনভোল্যুশনাল লেয়ার ব্যবহার করুন। ডিকোডার নেটওয়ার্কে, তিনটি কনভোলিউশন ট্রান্সপোজ লেয়ার (কিছু প্রেক্ষাপটে ওরফে ডিকনভোলিউশনাল লেয়ার) দ্বারা অনুসরণ করে একটি সম্পূর্ণ-সংযুক্ত স্তর ব্যবহার করে এই আর্কিটেকচারটিকে মিরর করুন। দ্রষ্টব্য, VAE-গুলিকে প্রশিক্ষণ দেওয়ার সময় ব্যাচ স্বাভাবিককরণ ব্যবহার করা এড়িয়ে চলা সাধারণ অভ্যাস, যেহেতু মিনি-ব্যাচগুলি ব্যবহারের কারণে অতিরিক্ত স্টোকাস্টিসিটি নমুনা নেওয়া থেকে স্টোকাস্টিটির উপরে অস্থিরতা বাড়িয়ে তুলতে পারে।
class CVAE(tf.keras.Model):
"""Convolutional variational autoencoder."""
def __init__(self, latent_dim):
super(CVAE, self).__init__()
self.latent_dim = latent_dim
self.encoder = tf.keras.Sequential(
[
tf.keras.layers.InputLayer(input_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(
filters=32, kernel_size=3, strides=(2, 2), activation='relu'),
tf.keras.layers.Conv2D(
filters=64, kernel_size=3, strides=(2, 2), activation='relu'),
tf.keras.layers.Flatten(),
# No activation
tf.keras.layers.Dense(latent_dim + latent_dim),
]
)
self.decoder = tf.keras.Sequential(
[
tf.keras.layers.InputLayer(input_shape=(latent_dim,)),
tf.keras.layers.Dense(units=7*7*32, activation=tf.nn.relu),
tf.keras.layers.Reshape(target_shape=(7, 7, 32)),
tf.keras.layers.Conv2DTranspose(
filters=64, kernel_size=3, strides=2, padding='same',
activation='relu'),
tf.keras.layers.Conv2DTranspose(
filters=32, kernel_size=3, strides=2, padding='same',
activation='relu'),
# No activation
tf.keras.layers.Conv2DTranspose(
filters=1, kernel_size=3, strides=1, padding='same'),
]
)
@tf.function
def sample(self, eps=None):
if eps is None:
eps = tf.random.normal(shape=(100, self.latent_dim))
return self.decode(eps, apply_sigmoid=True)
def encode(self, x):
mean, logvar = tf.split(self.encoder(x), num_or_size_splits=2, axis=1)
return mean, logvar
def reparameterize(self, mean, logvar):
eps = tf.random.normal(shape=mean.shape)
return eps * tf.exp(logvar * .5) + mean
def decode(self, z, apply_sigmoid=False):
logits = self.decoder(z)
if apply_sigmoid:
probs = tf.sigmoid(logits)
return probs
return logits
ক্ষতি ফাংশন এবং অপ্টিমাইজার সংজ্ঞায়িত করুন
VAEs প্রান্তিক লগ-সম্ভাবনার উপর প্রমাণ লোয়ার বাউন্ড (ELBO) সর্বাধিক করে প্রশিক্ষণ দেয়:
\[\log p(x) \ge \text{ELBO} = \mathbb{E}_{q(z|x)}\left[\log \frac{p(x, z)}{q(z|x)}\right].\]
অনুশীলনে, এই প্রত্যাশার একক নমুনা মন্টে কার্লো অনুমানটি অপ্টিমাইজ করুন:
\[\log p(x| z) + \log p(z) - \log q(z|x),\]
যেখানে \(z\) কে \(q(z|x)\)-placeholder28 থেকে নমুনা করা হয়েছে।
optimizer = tf.keras.optimizers.Adam(1e-4)
def log_normal_pdf(sample, mean, logvar, raxis=1):
log2pi = tf.math.log(2. * np.pi)
return tf.reduce_sum(
-.5 * ((sample - mean) ** 2. * tf.exp(-logvar) + logvar + log2pi),
axis=raxis)
def compute_loss(model, x):
mean, logvar = model.encode(x)
z = model.reparameterize(mean, logvar)
x_logit = model.decode(z)
cross_ent = tf.nn.sigmoid_cross_entropy_with_logits(logits=x_logit, labels=x)
logpx_z = -tf.reduce_sum(cross_ent, axis=[1, 2, 3])
logpz = log_normal_pdf(z, 0., 0.)
logqz_x = log_normal_pdf(z, mean, logvar)
return -tf.reduce_mean(logpx_z + logpz - logqz_x)
@tf.function
def train_step(model, x, optimizer):
"""Executes one training step and returns the loss.
This function computes the loss and gradients, and uses the latter to
update the model's parameters.
"""
with tf.GradientTape() as tape:
loss = compute_loss(model, x)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
প্রশিক্ষণ
- ডেটাসেটের উপর পুনরাবৃত্তি করে শুরু করুন
- প্রতিটি পুনরাবৃত্তির সময়, আনুমানিক পোস্টেরিয়র \(q(z|x)\)এর গড় এবং লগ-ভেরিয়েন্স প্যারামিটারের একটি সেট পেতে এনকোডারে ছবিটি পাস করুন
- তারপর \(q(z|x)\)থেকে নমুনাতে পুনরায় প্যারামিটারাইজেশন কৌশল প্রয়োগ করুন
- অবশেষে, জেনারেটিভ ডিস্ট্রিবিউশন \(p(x|z)\)এর লগিটগুলি পেতে ডিকোডারে পুনরায় প্যারামিটারাইজড নমুনাগুলি পাস করুন
- দ্রষ্টব্য: যেহেতু আপনি প্রশিক্ষণ সেটে 60k ডেটাপয়েন্ট এবং পরীক্ষা সেটে 10k ডেটাপয়েন্ট সহ কেরাস দ্বারা লোড করা ডেটাসেট ব্যবহার করেন, তাই পরীক্ষার সেটে আমাদের ফলাফল পাওয়া ELBO সাহিত্যে রিপোর্ট করা ফলাফলের তুলনায় সামান্য বেশি যা Larochelle-এর MNIST-এর গতিশীল বাইনারিকরণ ব্যবহার করে৷
ছবি তৈরি করা হচ্ছে
- প্রশিক্ষণের পরে, এটি কিছু চিত্র তৈরি করার সময়
- গাউসিয়ান পূর্ব বন্টন \(p(z)\)ইউনিট থেকে সুপ্ত ভেক্টরের একটি সেট নমুনা করে শুরু করুন
- জেনারেটর তারপর সুপ্ত নমুনা \(z\) কে পর্যবেক্ষণের লগিটগুলিতে রূপান্তর করবে, একটি বিতরণ দেবে \(p(x|z)\)
- এখানে, Bernoulli বিতরণের সম্ভাব্যতা প্লট করুন
epochs = 10
# set the dimensionality of the latent space to a plane for visualization later
latent_dim = 2
num_examples_to_generate = 16
# keeping the random vector constant for generation (prediction) so
# it will be easier to see the improvement.
random_vector_for_generation = tf.random.normal(
shape=[num_examples_to_generate, latent_dim])
model = CVAE(latent_dim)
def generate_and_save_images(model, epoch, test_sample):
mean, logvar = model.encode(test_sample)
z = model.reparameterize(mean, logvar)
predictions = model.sample(z)
fig = plt.figure(figsize=(4, 4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i + 1)
plt.imshow(predictions[i, :, :, 0], cmap='gray')
plt.axis('off')
# tight_layout minimizes the overlap between 2 sub-plots
plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
# Pick a sample of the test set for generating output images
assert batch_size >= num_examples_to_generate
for test_batch in test_dataset.take(1):
test_sample = test_batch[0:num_examples_to_generate, :, :, :]
generate_and_save_images(model, 0, test_sample)
for epoch in range(1, epochs + 1):
start_time = time.time()
for train_x in train_dataset:
train_step(model, train_x, optimizer)
end_time = time.time()
loss = tf.keras.metrics.Mean()
for test_x in test_dataset:
loss(compute_loss(model, test_x))
elbo = -loss.result()
display.clear_output(wait=False)
print('Epoch: {}, Test set ELBO: {}, time elapse for current epoch: {}'
.format(epoch, elbo, end_time - start_time))
generate_and_save_images(model, epoch, test_sample)
Epoch: 10, Test set ELBO: -156.4964141845703, time elapse for current epoch: 4.854437351226807

শেষ প্রশিক্ষণ যুগ থেকে একটি উৎপন্ন চিত্র প্রদর্শন করুন
def display_image(epoch_no):
return PIL.Image.open('image_at_epoch_{:04d}.png'.format(epoch_no))
plt.imshow(display_image(epoch))
plt.axis('off') # Display images
(-0.5, 287.5, 287.5, -0.5)
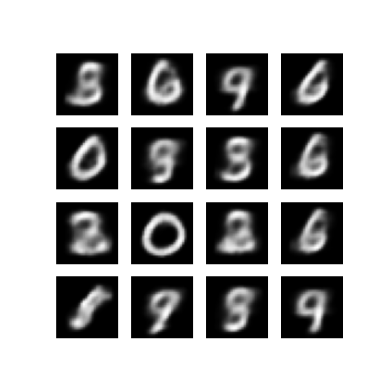
সমস্ত সংরক্ষিত ছবিগুলির একটি অ্যানিমেটেড GIF প্রদর্শন করুন৷
anim_file = 'cvae.gif'
with imageio.get_writer(anim_file, mode='I') as writer:
filenames = glob.glob('image*.png')
filenames = sorted(filenames)
for filename in filenames:
image = imageio.imread(filename)
writer.append_data(image)
image = imageio.imread(filename)
writer.append_data(image)
import tensorflow_docs.vis.embed as embed
embed.embed_file(anim_file)

সুপ্ত স্থান থেকে সংখ্যার একটি 2D বহুগুণ প্রদর্শন করুন
নীচের কোডটি চালানোর ফলে 2D সুপ্ত স্থান জুড়ে প্রতিটি ডিজিটকে অন্য একটিতে রূপান্তরের সাথে বিভিন্ন ডিজিটের ক্লাসগুলির একটি ক্রমাগত বিতরণ দেখাবে। সুপ্ত স্থানের জন্য একটি আদর্শ স্বাভাবিক বন্টন তৈরি করতে TensorFlow সম্ভাব্যতা ব্যবহার করুন।
def plot_latent_images(model, n, digit_size=28):
"""Plots n x n digit images decoded from the latent space."""
norm = tfp.distributions.Normal(0, 1)
grid_x = norm.quantile(np.linspace(0.05, 0.95, n))
grid_y = norm.quantile(np.linspace(0.05, 0.95, n))
image_width = digit_size*n
image_height = image_width
image = np.zeros((image_height, image_width))
for i, yi in enumerate(grid_x):
for j, xi in enumerate(grid_y):
z = np.array([[xi, yi]])
x_decoded = model.sample(z)
digit = tf.reshape(x_decoded[0], (digit_size, digit_size))
image[i * digit_size: (i + 1) * digit_size,
j * digit_size: (j + 1) * digit_size] = digit.numpy()
plt.figure(figsize=(10, 10))
plt.imshow(image, cmap='Greys_r')
plt.axis('Off')
plt.show()
plot_latent_images(model, 20)

পরবর্তী পদক্ষেপ
এই টিউটোরিয়ালটি দেখিয়েছে কিভাবে TensorFlow ব্যবহার করে একটি কনভোলিউশনাল ভ্যারিয়েশনাল অটোএনকোডার বাস্তবায়ন করা যায়।
পরবর্তী পদক্ষেপ হিসাবে, আপনি নেটওয়ার্কের আকার বাড়িয়ে মডেল আউটপুট উন্নত করার চেষ্টা করতে পারেন। উদাহরণস্বরূপ, আপনি প্রতিটি Conv2D এবং Conv2DTranspose স্তরগুলির জন্য filter পরামিতিগুলি 512 এ সেট করার চেষ্টা করতে পারেন৷ মনে রাখবেন যে চূড়ান্ত 2D সুপ্ত চিত্র প্লট তৈরি করার জন্য, আপনাকে 2-এ latent_dim রাখতে হবে৷ এছাড়াও, প্রশিক্ষণের সময় বৃদ্ধি পাবে৷ নেটওয়ার্কের আকার বাড়ার সাথে সাথে।
আপনি একটি ভিন্ন ডেটাসেট ব্যবহার করে একটি VAE প্রয়োগ করার চেষ্টা করতে পারেন, যেমন CIFAR-10।
VAEগুলি বিভিন্ন শৈলী এবং বিভিন্ন জটিলতায় প্রয়োগ করা যেতে পারে। আপনি নিম্নলিখিত উত্সগুলিতে অতিরিক্ত বাস্তবায়ন পেতে পারেন:
- ভেরিয়েশনাল অটোএনকোডার (keras.io)
- "কাস্টম স্তর এবং মডেল লেখা" নির্দেশিকা থেকে VAE উদাহরণ (tensorflow.org)
- TFP সম্ভাব্য স্তর: পরিবর্তনশীল অটো এনকোডার
আপনি যদি VAE-এর বিশদ বিবরণ সম্পর্কে আরও জানতে চান, তাহলে অনুগ্রহ করে ভেরিয়েশনাল অটোএনকোডারের পরিচিতি পড়ুন।