
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
این آموزش یک مثال خصمانه را با استفاده از حمله Fast Gradient Signed Method (FGSM) همانطور که در توضیح و مهار مثالهای متخاصم توسط Goodfellow و همکاران توضیح داده شده است، ایجاد میکند. این یکی از اولین و محبوب ترین حملات برای فریب دادن یک شبکه عصبی بود.
مثال خصمانه چیست؟
نمونههای متخاصم ورودیهای تخصصی هستند که با هدف گیج کردن یک شبکه عصبی ایجاد میشوند که منجر به طبقهبندی اشتباه یک ورودی داده شده میشود. این ورودیهای بدنام برای چشم انسان قابل تشخیص نیستند، اما باعث میشوند شبکه نتواند محتوای تصویر را شناسایی کند. انواع مختلفی از این حملات وجود دارد، با این حال، در اینجا تمرکز بر روی حمله روش نشانه گرادیان سریع است، که یک حمله جعبه سفید است که هدف آن اطمینان از طبقه بندی اشتباه است. حمله جعبه سفید جایی است که مهاجم به مدل مورد حمله دسترسی کامل دارد. یکی از معروف ترین نمونه های تصویر خصمانه که در زیر نشان داده شده است، از مقاله فوق الذکر گرفته شده است.

در اینجا، با شروع تصویر یک پاندا، مهاجم اغتشاشات (اعوجاج) کوچکی را به تصویر اصلی اضافه میکند که نتیجه آن این است که مدل با اطمینان بالا، این تصویر را به عنوان یک گیبون برچسبگذاری میکند. فرآیند اضافه کردن این اغتشاشات در زیر توضیح داده شده است.
روش نشانه شیب سریع
روش علامت گرادیان سریع با استفاده از گرادیان های شبکه عصبی برای ایجاد یک مثال مخالف کار می کند. برای یک تصویر ورودی، این روش از گرادیان های از دست دادن با توجه به تصویر ورودی استفاده می کند تا تصویر جدیدی ایجاد کند که تلفات را به حداکثر برساند. این تصویر جدید، تصویر متخاصم نامیده می شود. این را می توان با استفاده از عبارت زیر خلاصه کرد:
\[adv\_x = x + \epsilon*\text{sign}(\nabla_xJ(\theta, x, y))\]
جایی که
- adv_x : تصویر خصمانه.
- x : تصویر ورودی اصلی.
- y: برچسب ورودی اصلی.
- \(\epsilon\) : ضرب کننده برای اطمینان از کوچک بودن اغتشاشات.
- \(\theta\) : پارامترهای مدل.
- \(J\) : ضرر.
یک ویژگی جالب در اینجا، این واقعیت است که گرادیان ها با توجه به تصویر ورودی گرفته می شوند. این کار به این دلیل انجام می شود که هدف ایجاد تصویری است که ضرر را به حداکثر برساند. یک روش برای انجام این کار این است که بفهمیم هر پیکسل در تصویر چقدر به مقدار از دست دادن کمک می کند و بر این اساس یک اغتشاش اضافه می کند. این بسیار سریع عمل می کند زیرا به راحتی می توان با استفاده از قانون زنجیره ای و یافتن گرادیان های مورد نیاز، پیدا کرد که چگونه هر پیکسل ورودی به از دست دادن کمک می کند. بنابراین، گرادیان ها با توجه به تصویر گرفته می شوند. علاوه بر این، از آنجایی که مدل دیگر آموزش داده نمیشود (بنابراین، گرادیان با توجه به متغیرهای قابل آموزش، یعنی پارامترهای مدل گرفته نمیشود)، و بنابراین پارامترهای مدل ثابت میمانند. تنها هدف این است که یک مدل از قبل آموزش دیده را فریب دهید.
بنابراین بیایید سعی کنیم یک مدل از قبل آموزش دیده را فریب دهیم. در این آموزش، مدل MobileNetV2 است که در ImageNet از قبل آموزش داده شده است.
import tensorflow as tf
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rcParams['figure.figsize'] = (8, 8)
mpl.rcParams['axes.grid'] = False
بیایید مدل از پیش آموزش دیده MobileNetV2 و نام کلاس ImageNet را بارگذاری کنیم.
pretrained_model = tf.keras.applications.MobileNetV2(include_top=True,
weights='imagenet')
pretrained_model.trainable = False
# ImageNet labels
decode_predictions = tf.keras.applications.mobilenet_v2.decode_predictions
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_224.h5 14540800/14536120 [==============================] - 0s 0us/step 14548992/14536120 [==============================] - 0s 0us/step
# Helper function to preprocess the image so that it can be inputted in MobileNetV2
def preprocess(image):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, (224, 224))
image = tf.keras.applications.mobilenet_v2.preprocess_input(image)
image = image[None, ...]
return image
# Helper function to extract labels from probability vector
def get_imagenet_label(probs):
return decode_predictions(probs, top=1)[0][0]
تصویر اصلی
بیایید از یک تصویر نمونه از لابرادور رتریور توسط Mirko CC-BY-SA 3.0 از ویکیمدیا کامن استفاده کنیم و نمونههای متضاد از آن ایجاد کنیم. اولین قدم این است که آن را از قبل پردازش کنید تا بتوان آن را به عنوان ورودی به مدل MobileNetV2 تغذیه کرد.
{kind=link}
image_path = tf.keras.utils.get_file('YellowLabradorLooking_new.jpg', 'https://storage.googleapis.com/download.tensorflow.org/example_images/YellowLabradorLooking_new.jpg')
image_raw = tf.io.read_file(image_path)
image = tf.image.decode_image(image_raw)
image = preprocess(image)
image_probs = pretrained_model.predict(image)
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/YellowLabradorLooking_new.jpg 90112/83281 [================================] - 0s 0us/step 98304/83281 [===================================] - 0s 0us/step
بیایید نگاهی به تصویر بیندازیم.
plt.figure()
plt.imshow(image[0] * 0.5 + 0.5) # To change [-1, 1] to [0,1]
_, image_class, class_confidence = get_imagenet_label(image_probs)
plt.title('{} : {:.2f}% Confidence'.format(image_class, class_confidence*100))
plt.show()
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/imagenet_class_index.json 40960/35363 [==================================] - 0s 0us/step 49152/35363 [=========================================] - 0s 0us/step

تصویر خصمانه را ایجاد کنید
اجرای روش علامت گرادیان سریع
اولین قدم ایجاد اختلالاتی است که برای تحریف تصویر اصلی و در نتیجه ایجاد یک تصویر متخاصم استفاده می شود. همانطور که گفته شد، برای این کار، گرادیان ها با توجه به تصویر گرفته می شوند.
loss_object = tf.keras.losses.CategoricalCrossentropy()
def create_adversarial_pattern(input_image, input_label):
with tf.GradientTape() as tape:
tape.watch(input_image)
prediction = pretrained_model(input_image)
loss = loss_object(input_label, prediction)
# Get the gradients of the loss w.r.t to the input image.
gradient = tape.gradient(loss, input_image)
# Get the sign of the gradients to create the perturbation
signed_grad = tf.sign(gradient)
return signed_grad
آشفتگی های حاصل را نیز می توان مشاهده کرد.
# Get the input label of the image.
labrador_retriever_index = 208
label = tf.one_hot(labrador_retriever_index, image_probs.shape[-1])
label = tf.reshape(label, (1, image_probs.shape[-1]))
perturbations = create_adversarial_pattern(image, label)
plt.imshow(perturbations[0] * 0.5 + 0.5); # To change [-1, 1] to [0,1]
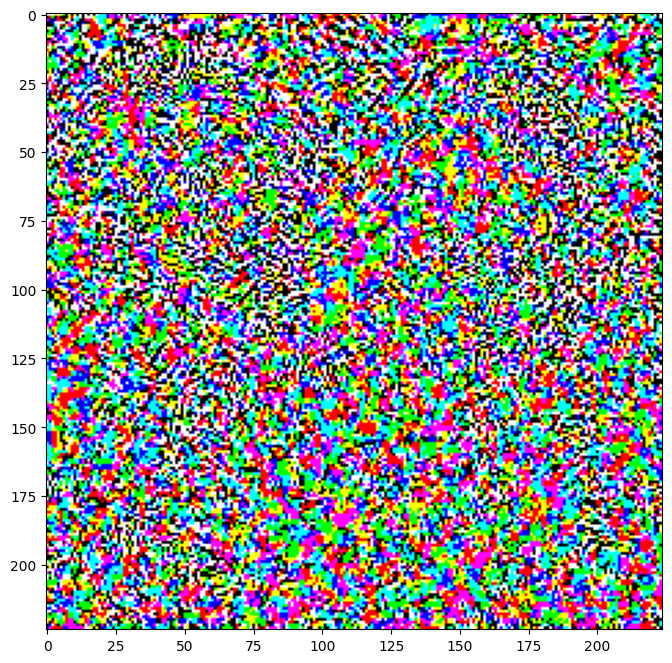
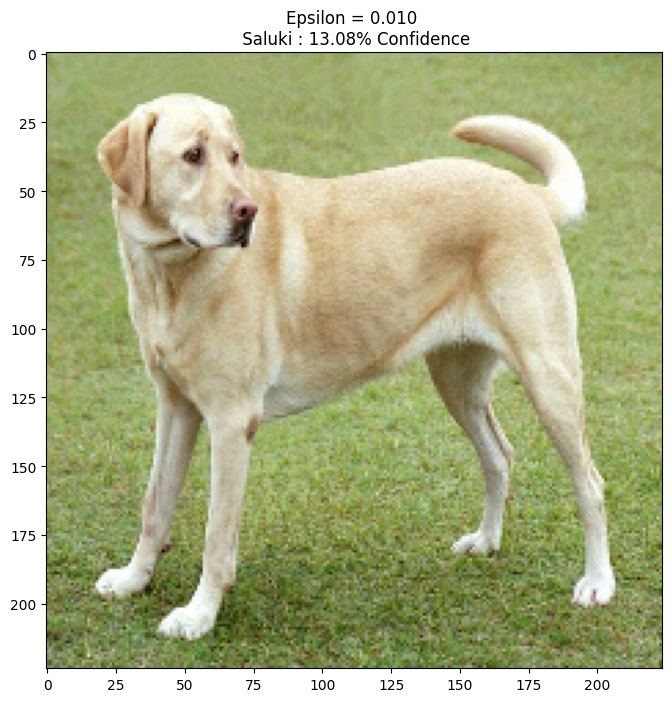
بیایید این را برای مقادیر مختلف اپسیلون امتحان کنیم و تصویر حاصل را مشاهده کنیم. متوجه خواهید شد که با افزایش ارزش اپسیلون، فریب دادن شبکه آسان تر می شود. با این حال، این به عنوان یک مبادله است که منجر به شناسایی بیشتر آشفتگی ها می شود.
def display_images(image, description):
_, label, confidence = get_imagenet_label(pretrained_model.predict(image))
plt.figure()
plt.imshow(image[0]*0.5+0.5)
plt.title('{} \n {} : {:.2f}% Confidence'.format(description,
label, confidence*100))
plt.show()
epsilons = [0, 0.01, 0.1, 0.15]
descriptions = [('Epsilon = {:0.3f}'.format(eps) if eps else 'Input')
for eps in epsilons]
for i, eps in enumerate(epsilons):
adv_x = image + eps*perturbations
adv_x = tf.clip_by_value(adv_x, -1, 1)
display_images(adv_x, descriptions[i])



مراحل بعدی
اکنون که در مورد حملات خصمانه می دانید، این را در مجموعه داده های مختلف و معماری های مختلف امتحان کنید. شما همچنین می توانید مدل خود را بسازید و آموزش دهید، و سپس با استفاده از همان روش سعی کنید آن را فریب دهید. همچنین میتوانید امتحان کنید و ببینید که چگونه با تغییر اپسیلون، اعتماد به پیشبینیها تغییر میکند.
اگرچه قدرتمند بود، اما حمله نشان داده شده در این آموزش فقط شروع تحقیقات در مورد حملات دشمن بود و از آن زمان تاکنون چندین مقاله وجود داشته است که حملات قدرتمندتری را ایجاد کرده است. علاوه بر حملات خصمانه، تحقیقات همچنین به ایجاد دفاعی منجر شده است که هدف آن ایجاد مدلهای یادگیری ماشینی قوی است. میتوانید این مقاله نظرسنجی را برای فهرستی جامع از حملات و دفاعهای دشمن مرور کنید.
برای بسیاری از پیاده سازی های بیشتر از حملات و دفاع های دشمن، ممکن است بخواهید کتابخانه نمونه خصمانه CleverHans را ببینید.