
| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন | |
এই টিউটোরিয়ালটি ফাস্ট গ্রেডিয়েন্ট সাইনড মেথড (FGSM) আক্রমণ ব্যবহার করে একটি প্রতিকূল উদাহরণ তৈরি করে যেমন গুডফেলো এট আল -এর দ্বারা ব্যাখ্যা করা এবং ব্যবহার করা প্রতিপক্ষের উদাহরণে বর্ণিত হয়েছে। এটি একটি নিউরাল নেটওয়ার্ককে বোকা বানানোর প্রথম এবং সবচেয়ে জনপ্রিয় আক্রমণগুলির মধ্যে একটি।
একটি প্রতিপক্ষ উদাহরণ কি?
প্রতিকূল উদাহরণগুলি একটি নিউরাল নেটওয়ার্ককে বিভ্রান্ত করার উদ্দেশ্যে তৈরি করা বিশেষ ইনপুট, যার ফলে একটি প্রদত্ত ইনপুটের ভুল শ্রেণিবিন্যাস হয়। এই কুখ্যাত ইনপুটগুলি মানুষের চোখে আলাদা করা যায় না, কিন্তু নেটওয়ার্কটি ছবির বিষয়বস্তু সনাক্ত করতে ব্যর্থ হয়। এই ধরনের আক্রমণের বিভিন্ন প্রকার রয়েছে, তবে, এখানে ফোকাস করা হয়েছে দ্রুত গ্রেডিয়েন্ট সাইন মেথড অ্যাটাক, যা একটি হোয়াইট বক্স অ্যাটাক যার লক্ষ্য হল ভুল শ্রেণীবিভাগ নিশ্চিত করা। একটি সাদা বক্স আক্রমণ হল যেখানে আক্রমণকারীর আক্রমণ করা মডেলটিতে সম্পূর্ণ অ্যাক্সেস থাকে। নীচে দেখানো একটি প্রতিপক্ষের চিত্রের সবচেয়ে বিখ্যাত উদাহরণগুলির মধ্যে একটি পূর্বোক্ত কাগজ থেকে নেওয়া হয়েছে।

এখানে, একটি পান্ডার ছবি দিয়ে শুরু করে, আক্রমণকারী মূল ছবিতে ছোট ছোট বিকৃতি (বিকৃতি) যোগ করে, যার ফলস্বরূপ মডেলটি উচ্চ আত্মবিশ্বাসের সাথে এই ছবিটিকে গিবন হিসাবে লেবেল করে। এই বিরক্তি যোগ করার প্রক্রিয়া নীচে ব্যাখ্যা করা হয়েছে.
দ্রুত গ্রেডিয়েন্ট সাইন পদ্ধতি
দ্রুত গ্রেডিয়েন্ট সাইন পদ্ধতি একটি প্রতিকূল উদাহরণ তৈরি করতে নিউরাল নেটওয়ার্কের গ্রেডিয়েন্ট ব্যবহার করে কাজ করে। ইনপুট ইমেজের জন্য, পদ্ধতিটি ইনপুট ইমেজের ক্ষেত্রে ক্ষতির গ্রেডিয়েন্ট ব্যবহার করে একটি নতুন ইমেজ তৈরি করে যা ক্ষতিকে সর্বাধিক করে। এই নতুন ছবিকে বলা হয় প্রতিপক্ষের ছবি। এটি নিম্নলিখিত অভিব্যক্তি ব্যবহার করে সংক্ষিপ্ত করা যেতে পারে:
\[adv\_x = x + \epsilon*\text{sign}(\nabla_xJ(\theta, x, y))\]
কোথায়
- adv_x : প্রতিপক্ষের ছবি।
- x : আসল ইনপুট ইমেজ।
- y: মূল ইনপুট লেবেল।
- \(\epsilon\) : বিশৃঙ্খলতা ছোট তা নিশ্চিত করার জন্য গুণক।
- \(\theta\) : মডেল প্যারামিটার।
- \(J\) : ক্ষতি।
এখানে একটি চমকপ্রদ বৈশিষ্ট্য হল যে গ্রেডিয়েন্টগুলি ইনপুট চিত্রের সাথে নেওয়া হয়। এটি করা হয়েছে কারণ উদ্দেশ্যটি এমন একটি চিত্র তৈরি করা যা ক্ষতিকে সর্বাধিক করে। এটি সম্পন্ন করার একটি পদ্ধতি হল চিত্রের প্রতিটি পিক্সেল ক্ষতির মানকে কতটা অবদান রাখে তা খুঁজে বের করা এবং সেই অনুযায়ী একটি বিভ্রান্তি যোগ করা। এটি বেশ দ্রুত কাজ করে কারণ চেইন নিয়ম ব্যবহার করে এবং প্রয়োজনীয় গ্রেডিয়েন্ট খুঁজে বের করার মাধ্যমে প্রতিটি ইনপুট পিক্সেল কীভাবে ক্ষতিতে অবদান রাখে তা খুঁজে পাওয়া সহজ। সুতরাং, গ্রেডিয়েন্টগুলি চিত্রের সাপেক্ষে নেওয়া হয়। উপরন্তু, যেহেতু মডেলটিকে আর প্রশিক্ষিত করা হচ্ছে না (এইভাবে প্রশিক্ষনযোগ্য ভেরিয়েবলের ক্ষেত্রে গ্রেডিয়েন্ট নেওয়া হয় না, অর্থাৎ মডেল প্যারামিটার), এবং তাই মডেল প্যারামিটারগুলি স্থির থাকে। একমাত্র লক্ষ্য হল ইতিমধ্যে প্রশিক্ষিত মডেলকে বোকা বানানো।
তাই আসুন একটি পূর্বপ্রশিক্ষিত মডেলকে বোকা বানানোর চেষ্টা করি। এই টিউটোরিয়ালে, মডেলটি হল MobileNetV2 মডেল, যা ইমেজনেট-এ প্রিট্রিন করা হয়েছে।
import tensorflow as tf
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rcParams['figure.figsize'] = (8, 8)
mpl.rcParams['axes.grid'] = False
চলুন পূর্বপ্রশিক্ষিত MobileNetV2 মডেল এবং ImageNet শ্রেণীর নাম লোড করা যাক।
pretrained_model = tf.keras.applications.MobileNetV2(include_top=True,
weights='imagenet')
pretrained_model.trainable = False
# ImageNet labels
decode_predictions = tf.keras.applications.mobilenet_v2.decode_predictions
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_224.h5 14540800/14536120 [==============================] - 0s 0us/step 14548992/14536120 [==============================] - 0s 0us/step
# Helper function to preprocess the image so that it can be inputted in MobileNetV2
def preprocess(image):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, (224, 224))
image = tf.keras.applications.mobilenet_v2.preprocess_input(image)
image = image[None, ...]
return image
# Helper function to extract labels from probability vector
def get_imagenet_label(probs):
return decode_predictions(probs, top=1)[0][0]
আসল ছবি
আসুন উইকিমিডিয়া কমন থেকে মিরকো সিসি-বাই-এসএ 3.0- এর একটি ল্যাব্রাডর রিট্রিভারের একটি নমুনা চিত্র ব্যবহার করি এবং এটি থেকে প্রতিপক্ষের উদাহরণ তৈরি করি। প্রথম ধাপ হল এটিকে প্রিপ্রসেস করা যাতে এটি MobileNetV2 মডেলে একটি ইনপুট হিসাবে খাওয়ানো যায়৷
{kind=link}
image_path = tf.keras.utils.get_file('YellowLabradorLooking_new.jpg', 'https://storage.googleapis.com/download.tensorflow.org/example_images/YellowLabradorLooking_new.jpg')
image_raw = tf.io.read_file(image_path)
image = tf.image.decode_image(image_raw)
image = preprocess(image)
image_probs = pretrained_model.predict(image)
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/YellowLabradorLooking_new.jpg 90112/83281 [================================] - 0s 0us/step 98304/83281 [===================================] - 0s 0us/step
এর ইমেজ কটাক্ষপাত আছে.
plt.figure()
plt.imshow(image[0] * 0.5 + 0.5) # To change [-1, 1] to [0,1]
_, image_class, class_confidence = get_imagenet_label(image_probs)
plt.title('{} : {:.2f}% Confidence'.format(image_class, class_confidence*100))
plt.show()
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/imagenet_class_index.json 40960/35363 [==================================] - 0s 0us/step 49152/35363 [=========================================] - 0s 0us/step

প্রতিপক্ষের ইমেজ তৈরি করুন
দ্রুত গ্রেডিয়েন্ট সাইন পদ্ধতি বাস্তবায়ন
প্রথম পদক্ষেপটি হল বিভ্রান্তি তৈরি করা যা মূল চিত্রটিকে বিকৃত করতে ব্যবহার করা হবে যার ফলে একটি প্রতিপক্ষের চিত্র তৈরি হবে। উল্লিখিত হিসাবে, এই কাজের জন্য, গ্রেডিয়েন্টগুলি চিত্রের সাপেক্ষে নেওয়া হয়।
loss_object = tf.keras.losses.CategoricalCrossentropy()
def create_adversarial_pattern(input_image, input_label):
with tf.GradientTape() as tape:
tape.watch(input_image)
prediction = pretrained_model(input_image)
loss = loss_object(input_label, prediction)
# Get the gradients of the loss w.r.t to the input image.
gradient = tape.gradient(loss, input_image)
# Get the sign of the gradients to create the perturbation
signed_grad = tf.sign(gradient)
return signed_grad
এর ফলে উদ্ভূত সমস্যাগুলিও কল্পনা করা যেতে পারে।
# Get the input label of the image.
labrador_retriever_index = 208
label = tf.one_hot(labrador_retriever_index, image_probs.shape[-1])
label = tf.reshape(label, (1, image_probs.shape[-1]))
perturbations = create_adversarial_pattern(image, label)
plt.imshow(perturbations[0] * 0.5 + 0.5); # To change [-1, 1] to [0,1]
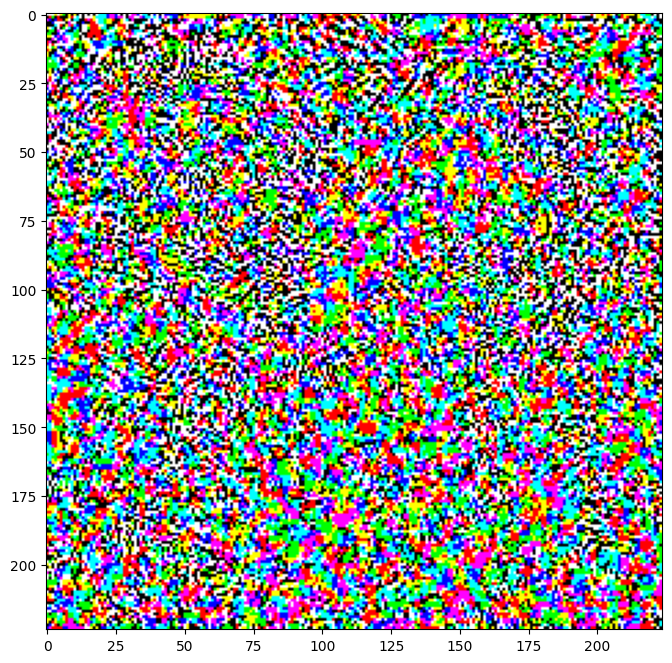
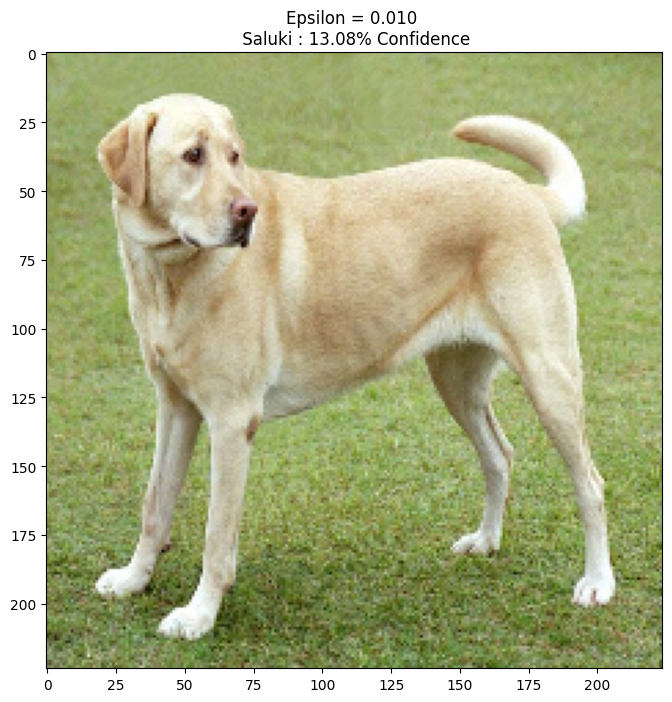
এপিসিলনের বিভিন্ন মানের জন্য এটি চেষ্টা করে দেখুন এবং ফলাফলের চিত্রটি পর্যবেক্ষণ করুন। আপনি লক্ষ্য করবেন যে এপসিলনের মান বাড়ার সাথে সাথে নেটওয়ার্ককে বোকা বানানো সহজ হয়ে যায়। যাইহোক, এটি একটি ট্রেড-অফ হিসাবে আসে যার ফলে বিশৃঙ্খলাগুলি আরও শনাক্তযোগ্য হয়ে ওঠে।
def display_images(image, description):
_, label, confidence = get_imagenet_label(pretrained_model.predict(image))
plt.figure()
plt.imshow(image[0]*0.5+0.5)
plt.title('{} \n {} : {:.2f}% Confidence'.format(description,
label, confidence*100))
plt.show()
epsilons = [0, 0.01, 0.1, 0.15]
descriptions = [('Epsilon = {:0.3f}'.format(eps) if eps else 'Input')
for eps in epsilons]
for i, eps in enumerate(epsilons):
adv_x = image + eps*perturbations
adv_x = tf.clip_by_value(adv_x, -1, 1)
display_images(adv_x, descriptions[i])



পরবর্তী পদক্ষেপ
এখন যেহেতু আপনি প্রতিপক্ষের আক্রমণ সম্পর্কে জানেন, বিভিন্ন ডেটাসেট এবং বিভিন্ন আর্কিটেকচারে এটি ব্যবহার করে দেখুন। আপনি আপনার নিজের মডেল তৈরি এবং প্রশিক্ষণ দিতে পারেন, এবং তারপর একই পদ্ধতি ব্যবহার করে এটি বোকা বানানোর চেষ্টা করতে পারেন। আপনি এপসিলন পরিবর্তন করার সাথে সাথে ভবিষ্যদ্বাণীতে আস্থা কীভাবে পরিবর্তিত হয় তা আপনি চেষ্টা করে দেখতে পারেন।
শক্তিশালী হলেও, এই টিউটোরিয়ালে দেখানো আক্রমণটি ছিল প্রতিপক্ষের আক্রমণের গবেষণার সূচনা, এবং তখন থেকে আরও শক্তিশালী আক্রমণ তৈরির একাধিক কাগজপত্র রয়েছে। প্রতিপক্ষের আক্রমণের পাশাপাশি, গবেষণার ফলে প্রতিরক্ষা ব্যবস্থাও তৈরি হয়েছে, যার লক্ষ্য শক্তিশালী মেশিন লার্নিং মডেল তৈরি করা। আপনি প্রতিপক্ষের আক্রমণ এবং প্রতিরক্ষার একটি বিস্তৃত তালিকার জন্য এই সমীক্ষা পত্রটি পর্যালোচনা করতে পারেন।
প্রতিপক্ষের আক্রমণ এবং প্রতিরক্ষার আরও অনেক বাস্তবায়নের জন্য, আপনি প্রতিপক্ষের উদাহরণ লাইব্রেরি CleverHans দেখতে চাইতে পারেন।