
| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub | |
Ten samouczek tworzy przykład kontradyktoryjności za pomocą ataku Fast Gradient Signed Method (FGSM), jak opisano w Explaining and Harnessing Adversarial Przykłady autorstwa Goodfellow et al . Był to jeden z pierwszych i najpopularniejszych ataków mających na celu oszukanie sieci neuronowej.
Jaki jest przykład kontradyktoryjny?
Przykłady kontradyktoryjności to wyspecjalizowane dane wejściowe utworzone w celu zmylenia sieci neuronowej, co skutkuje błędną klasyfikacją danych wejściowych. Te znane dane wejściowe są nie do odróżnienia dla ludzkiego oka, ale powodują, że sieć nie identyfikuje zawartości obrazu. Istnieje kilka rodzajów takich ataków, jednak tutaj skupiamy się na szybkim ataku metodą znaku gradientu, który jest atakiem białą skrzynką , którego celem jest zapewnienie błędnej klasyfikacji. Atak białą skrzynką polega na tym, że atakujący ma pełny dostęp do atakowanego modelu. Jeden z najsłynniejszych przykładów obrazu kontradyktoryjnego pokazany poniżej został zaczerpnięty ze wspomnianego artykułu.

Tutaj, zaczynając od obrazu pandy, atakujący dodaje niewielkie perturbacje (zniekształcenia) do oryginalnego obrazu, co powoduje, że model z dużą pewnością oznacza ten obraz jako gibon. Proces dodawania tych perturbacji wyjaśniono poniżej.
Metoda szybkiego znaku gradientu
Metoda szybkiego znaku gradientu polega na wykorzystaniu gradientów sieci neuronowej do stworzenia przykładu kontradyktoryjnego. W przypadku obrazu wejściowego metoda wykorzystuje gradienty utraty w odniesieniu do obrazu wejściowego w celu utworzenia nowego obrazu, który maksymalizuje utratę. Ten nowy obraz nazywa się obrazem przeciwnika. Można to podsumować za pomocą następującego wyrażenia:
\[adv\_x = x + \epsilon*\text{sign}(\nabla_xJ(\theta, x, y))\]
gdzie
- adv_x : obraz przeciwnika.
- x : Oryginalny obraz wejściowy.
- y : Oryginalna etykieta wejściowa.
- \(\epsilon\) : Mnożnik zapewniający małe zakłócenia.
- \(\theta\) : Parametry modelu.
- \(J\) : Strata.
Intrygującą właściwością jest tutaj fakt, że gradienty są brane względem obrazu wejściowego. Dzieje się tak, ponieważ celem jest stworzenie obrazu, który maksymalizuje stratę. Sposobem na osiągnięcie tego jest ustalenie, w jakim stopniu każdy piksel na obrazie przyczynia się do wartości utraty, i odpowiednio dodać perturbację. Działa to dość szybko, ponieważ łatwo jest określić, w jaki sposób każdy piksel wejściowy przyczynia się do utraty, korzystając z reguły łańcucha i znajdując wymagane gradienty. W związku z tym gradienty są brane w odniesieniu do obrazu. Ponadto, ponieważ model nie jest już uczony (więc gradient nie jest przyjmowany w odniesieniu do zmiennych, które można trenować, tj. parametrów modelu), parametry modelu pozostają stałe. Jedynym celem jest oszukanie już wytrenowanego modelu.
Spróbujmy więc oszukać przeszkolony model. W tym samouczku modelem jest model MobileNetV2 , wstępnie wytrenowany w ImageNet .
import tensorflow as tf
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rcParams['figure.figsize'] = (8, 8)
mpl.rcParams['axes.grid'] = False
Załadujmy wstępnie wytrenowany model MobileNetV2 i nazwy klas ImageNet.
pretrained_model = tf.keras.applications.MobileNetV2(include_top=True,
weights='imagenet')
pretrained_model.trainable = False
# ImageNet labels
decode_predictions = tf.keras.applications.mobilenet_v2.decode_predictions
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_224.h5 14540800/14536120 [==============================] - 0s 0us/step 14548992/14536120 [==============================] - 0s 0us/step
# Helper function to preprocess the image so that it can be inputted in MobileNetV2
def preprocess(image):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, (224, 224))
image = tf.keras.applications.mobilenet_v2.preprocess_input(image)
image = image[None, ...]
return image
# Helper function to extract labels from probability vector
def get_imagenet_label(probs):
return decode_predictions(probs, top=1)[0][0]
Oryginalny obraz
Użyjmy przykładowego obrazu Labrador Retriever autorstwa Mirko CC-BY-SA 3.0 z Wikimedia Common i stwórzmy na jego podstawie przykłady kontradyktoryjności. Pierwszym krokiem jest wstępne przetworzenie go, aby można go było wprowadzić jako dane wejściowe do modelu MobileNetV2.
{kind=link}
image_path = tf.keras.utils.get_file('YellowLabradorLooking_new.jpg', 'https://storage.googleapis.com/download.tensorflow.org/example_images/YellowLabradorLooking_new.jpg')
image_raw = tf.io.read_file(image_path)
image = tf.image.decode_image(image_raw)
image = preprocess(image)
image_probs = pretrained_model.predict(image)
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/YellowLabradorLooking_new.jpg 90112/83281 [================================] - 0s 0us/step 98304/83281 [===================================] - 0s 0us/step
Przyjrzyjmy się obrazowi.
plt.figure()
plt.imshow(image[0] * 0.5 + 0.5) # To change [-1, 1] to [0,1]
_, image_class, class_confidence = get_imagenet_label(image_probs)
plt.title('{} : {:.2f}% Confidence'.format(image_class, class_confidence*100))
plt.show()
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/imagenet_class_index.json 40960/35363 [==================================] - 0s 0us/step 49152/35363 [=========================================] - 0s 0us/step

Stwórz obraz przeciwnika
Implementacja metody szybkiego znakowania gradientem
Pierwszym krokiem jest stworzenie perturbacji, które zostaną wykorzystane do zniekształcenia oryginalnego obrazu, w wyniku czego powstanie obraz przeciwnika. Jak wspomniano, w tym zadaniu gradienty są brane w odniesieniu do obrazu.
loss_object = tf.keras.losses.CategoricalCrossentropy()
def create_adversarial_pattern(input_image, input_label):
with tf.GradientTape() as tape:
tape.watch(input_image)
prediction = pretrained_model(input_image)
loss = loss_object(input_label, prediction)
# Get the gradients of the loss w.r.t to the input image.
gradient = tape.gradient(loss, input_image)
# Get the sign of the gradients to create the perturbation
signed_grad = tf.sign(gradient)
return signed_grad
Można również wizualizować powstałe perturbacje.
# Get the input label of the image.
labrador_retriever_index = 208
label = tf.one_hot(labrador_retriever_index, image_probs.shape[-1])
label = tf.reshape(label, (1, image_probs.shape[-1]))
perturbations = create_adversarial_pattern(image, label)
plt.imshow(perturbations[0] * 0.5 + 0.5); # To change [-1, 1] to [0,1]

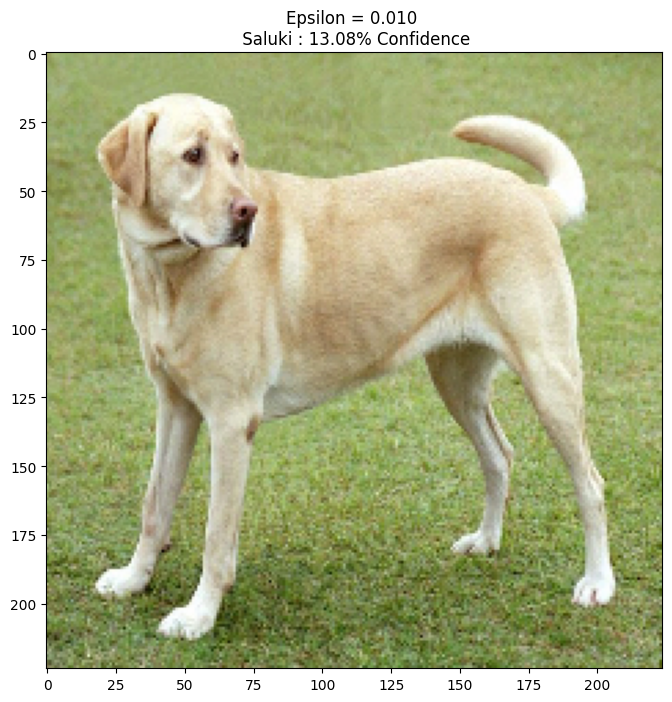
Wypróbujmy to dla różnych wartości epsilon i obserwujmy wynikowy obraz. Zauważysz, że wraz ze wzrostem wartości epsilon łatwiej jest oszukać sieć. Jest to jednak kompromis, który powoduje, że perturbacje stają się bardziej rozpoznawalne.
def display_images(image, description):
_, label, confidence = get_imagenet_label(pretrained_model.predict(image))
plt.figure()
plt.imshow(image[0]*0.5+0.5)
plt.title('{} \n {} : {:.2f}% Confidence'.format(description,
label, confidence*100))
plt.show()
epsilons = [0, 0.01, 0.1, 0.15]
descriptions = [('Epsilon = {:0.3f}'.format(eps) if eps else 'Input')
for eps in epsilons]
for i, eps in enumerate(epsilons):
adv_x = image + eps*perturbations
adv_x = tf.clip_by_value(adv_x, -1, 1)
display_images(adv_x, descriptions[i])



Następne kroki
Teraz, gdy wiesz już o atakach adwersarzy, wypróbuj to na różnych zestawach danych i na różnych architekturach. Możesz także stworzyć i wytrenować własny model, a następnie spróbować go oszukać przy użyciu tej samej metody. Możesz także spróbować i zobaczyć, jak zmienia się zaufanie do przewidywań, gdy zmieniasz epsilon.
Choć potężny, atak pokazany w tym samouczku był dopiero początkiem badań nad atakami przeciwnika i od tego czasu pojawiło się wiele artykułów tworzących potężniejsze ataki. Oprócz ataków kontradyktoryjnych badania doprowadziły również do stworzenia mechanizmów obronnych, których celem jest stworzenie solidnych modeli uczenia maszynowego. Możesz przejrzeć ten dokument ankietowy, aby uzyskać pełną listę ataków i środków obronnych przeciwnika.
W przypadku wielu innych implementacji ataków adwersarzy i mechanizmów obronnych warto zapoznać się z przykładową biblioteką adwersarzy CleverHans .