
| | |  GitHub पर स्रोत देखें GitHub पर स्रोत देखें | |
यह ट्यूटोरियल फास्ट ग्रेडिएंट साइन मेथड (FGSM) हमले का उपयोग करके एक प्रतिकूल उदाहरण बनाता है जैसा कि गुडफेलो एट अल द्वारा व्याख्या और प्रतिकूल उदाहरणों का उपयोग करने में वर्णित है। यह तंत्रिका नेटवर्क को मूर्ख बनाने वाले पहले और सबसे लोकप्रिय हमलों में से एक था।
एक प्रतिकूल उदाहरण क्या है?
प्रतिकूल उदाहरण एक तंत्रिका नेटवर्क को भ्रमित करने के उद्देश्य से बनाए गए विशेष इनपुट हैं, जिसके परिणामस्वरूप किसी दिए गए इनपुट का गलत वर्गीकरण होता है। ये कुख्यात इनपुट मानव आंख के लिए अप्रभेद्य हैं, लेकिन नेटवर्क को छवि की सामग्री की पहचान करने में विफल होने का कारण बनता है। इस तरह के हमले कई प्रकार के होते हैं, हालांकि, यहां फोकस फास्ट ग्रेडिएंट साइन मेथड अटैक पर है, जो एक व्हाइट बॉक्स अटैक है जिसका लक्ष्य गलत वर्गीकरण सुनिश्चित करना है। एक सफेद बॉक्स हमला वह जगह है जहां हमलावर के पास उस मॉडल तक पूरी पहुंच होती है जिस पर हमला किया जा रहा है। नीचे दिखाए गए प्रतिकूल छवि के सबसे प्रसिद्ध उदाहरणों में से एक उपरोक्त पेपर से लिया गया है।

यहां, एक पांडा की छवि से शुरू करते हुए, हमलावर मूल छवि में छोटे गड़बड़ी (विकृतियां) जोड़ता है, जिसके परिणामस्वरूप मॉडल इस छवि को एक गिब्बन के रूप में लेबल करता है, उच्च आत्मविश्वास के साथ। इन गड़बड़ियों को जोड़ने की प्रक्रिया को नीचे समझाया गया है।
तेजी से ढाल संकेत विधि
फास्ट ग्रेडिएंट साइन विधि एक प्रतिकूल उदाहरण बनाने के लिए तंत्रिका नेटवर्क के ग्रेडिएंट का उपयोग करके काम करती है। एक इनपुट छवि के लिए, विधि एक नई छवि बनाने के लिए इनपुट छवि के संबंध में नुकसान के ग्रेडिएंट का उपयोग करती है जो नुकसान को अधिकतम करती है। इस नई छवि को प्रतिकूल छवि कहा जाता है। इसे निम्नलिखित अभिव्यक्ति का उपयोग करके संक्षेप में प्रस्तुत किया जा सकता है:
\[adv\_x = x + \epsilon*\text{sign}(\nabla_xJ(\theta, x, y))\]
कहाँ पे
- adv_x : प्रतिकूल छवि।
- एक्स: मूल इनपुट छवि।
- y: मूल इनपुट लेबल।
- \(\epsilon\) : यह सुनिश्चित करने के लिए गुणक कि गड़बड़ी छोटी है।
- \(\theta\) : मॉडल पैरामीटर।
- \(J\) 4 : हानि।
यहां एक दिलचस्प संपत्ति यह है कि इनपुट छवि के संबंध में ग्रेडियेंट लिया जाता है। ऐसा इसलिए किया जाता है क्योंकि उद्देश्य एक ऐसी छवि बनाना है जो नुकसान को अधिकतम करे। इसे पूरा करने का एक तरीका यह पता लगाना है कि छवि में प्रत्येक पिक्सेल हानि मूल्य में कितना योगदान देता है, और तदनुसार एक गड़बड़ी जोड़ें। यह बहुत तेजी से काम करता है क्योंकि यह पता लगाना आसान है कि प्रत्येक इनपुट पिक्सेल चेन नियम का उपयोग करके और आवश्यक ग्रेडिएंट्स को ढूंढकर नुकसान में कैसे योगदान देता है। इसलिए, ग्रेडिएंट को छवि के संबंध में लिया जाता है। इसके अलावा, चूंकि मॉडल को अब प्रशिक्षित नहीं किया जा रहा है (इस प्रकार ग्रेडिएंट को प्रशिक्षित चर, यानी मॉडल मापदंडों के संबंध में नहीं लिया जाता है), और इसलिए मॉडल पैरामीटर स्थिर रहते हैं। एकमात्र लक्ष्य पहले से ही प्रशिक्षित मॉडल को बेवकूफ बनाना है।
तो चलिए कोशिश करते हैं और एक ढोंगी मॉडल को बेवकूफ बनाते हैं। इस ट्यूटोरियल में, मॉडल MobileNetV2 मॉडल है, जिसे ImageNet पर पूर्व-प्रशिक्षित किया गया है।
import tensorflow as tf
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rcParams['figure.figsize'] = (8, 8)
mpl.rcParams['axes.grid'] = False
आइए पहले से प्रशिक्षित MobileNetV2 मॉडल और ImageNet वर्ग के नाम लोड करें।
pretrained_model = tf.keras.applications.MobileNetV2(include_top=True,
weights='imagenet')
pretrained_model.trainable = False
# ImageNet labels
decode_predictions = tf.keras.applications.mobilenet_v2.decode_predictions
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_224.h5 14540800/14536120 [==============================] - 0s 0us/step 14548992/14536120 [==============================] - 0s 0us/step
# Helper function to preprocess the image so that it can be inputted in MobileNetV2
def preprocess(image):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, (224, 224))
image = tf.keras.applications.mobilenet_v2.preprocess_input(image)
image = image[None, ...]
return image
# Helper function to extract labels from probability vector
def get_imagenet_label(probs):
return decode_predictions(probs, top=1)[0][0]
मूल छवि
आइए विकिमीडिया कॉमन से मिर्को सीसी-बाय-एसए 3.0 द्वारा लैब्राडोर रिट्रीवर की एक नमूना छवि का उपयोग करें और इससे प्रतिकूल उदाहरण बनाएं। पहला कदम इसे प्रीप्रोसेस करना है ताकि इसे MobileNetV2 मॉडल में इनपुट के रूप में फीड किया जा सके।
{kind=link}
image_path = tf.keras.utils.get_file('YellowLabradorLooking_new.jpg', 'https://storage.googleapis.com/download.tensorflow.org/example_images/YellowLabradorLooking_new.jpg')
image_raw = tf.io.read_file(image_path)
image = tf.image.decode_image(image_raw)
image = preprocess(image)
image_probs = pretrained_model.predict(image)
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/YellowLabradorLooking_new.jpg 90112/83281 [================================] - 0s 0us/step 98304/83281 [===================================] - 0s 0us/step
आइए एक नजर डालते हैं छवि पर।
plt.figure()
plt.imshow(image[0] * 0.5 + 0.5) # To change [-1, 1] to [0,1]
_, image_class, class_confidence = get_imagenet_label(image_probs)
plt.title('{} : {:.2f}% Confidence'.format(image_class, class_confidence*100))
plt.show()
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/imagenet_class_index.json 40960/35363 [==================================] - 0s 0us/step 49152/35363 [=========================================] - 0s 0us/step

प्रतिकूल छवि बनाएं
तेजी से ढाल संकेत पद्धति को लागू करना
पहला कदम गड़बड़ी पैदा करना है जिसका उपयोग मूल छवि को विकृत करने के लिए किया जाएगा जिसके परिणामस्वरूप एक प्रतिकूल छवि होगी। जैसा कि उल्लेख किया गया है, इस कार्य के लिए, छवि के संबंध में ग्रेडिएंट्स लिए गए हैं।
loss_object = tf.keras.losses.CategoricalCrossentropy()
def create_adversarial_pattern(input_image, input_label):
with tf.GradientTape() as tape:
tape.watch(input_image)
prediction = pretrained_model(input_image)
loss = loss_object(input_label, prediction)
# Get the gradients of the loss w.r.t to the input image.
gradient = tape.gradient(loss, input_image)
# Get the sign of the gradients to create the perturbation
signed_grad = tf.sign(gradient)
return signed_grad
परिणामी विक्षोभों को भी देखा जा सकता है।
# Get the input label of the image.
labrador_retriever_index = 208
label = tf.one_hot(labrador_retriever_index, image_probs.shape[-1])
label = tf.reshape(label, (1, image_probs.shape[-1]))
perturbations = create_adversarial_pattern(image, label)
plt.imshow(perturbations[0] * 0.5 + 0.5); # To change [-1, 1] to [0,1]

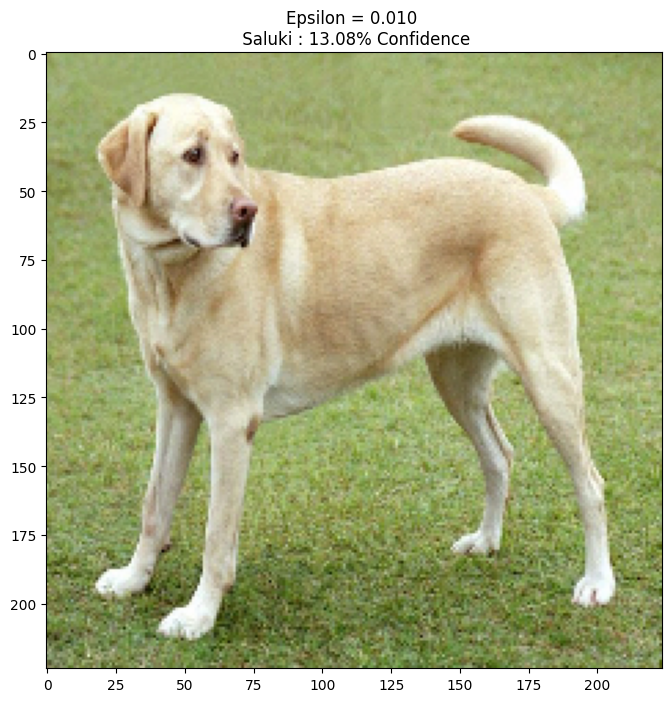
आइए इसे एप्सिलॉन के विभिन्न मूल्यों के लिए आजमाएं और परिणामी छवि का निरीक्षण करें। आप देखेंगे कि जैसे-जैसे एप्सिलॉन का मूल्य बढ़ता है, नेटवर्क को बेवकूफ बनाना आसान होता जाता है। हालाँकि, यह एक व्यापार-बंद के रूप में आता है जिसके परिणामस्वरूप गड़बड़ी अधिक पहचान योग्य हो जाती है।
def display_images(image, description):
_, label, confidence = get_imagenet_label(pretrained_model.predict(image))
plt.figure()
plt.imshow(image[0]*0.5+0.5)
plt.title('{} \n {} : {:.2f}% Confidence'.format(description,
label, confidence*100))
plt.show()
epsilons = [0, 0.01, 0.1, 0.15]
descriptions = [('Epsilon = {:0.3f}'.format(eps) if eps else 'Input')
for eps in epsilons]
for i, eps in enumerate(epsilons):
adv_x = image + eps*perturbations
adv_x = tf.clip_by_value(adv_x, -1, 1)
display_images(adv_x, descriptions[i])



अगले कदम
अब जब आप प्रतिकूल हमलों के बारे में जानते हैं, तो इसे विभिन्न डेटासेट और विभिन्न आर्किटेक्चर पर आज़माएं। आप अपना खुद का मॉडल भी बना सकते हैं और प्रशिक्षित कर सकते हैं, और फिर उसी विधि का उपयोग करके इसे मूर्ख बनाने का प्रयास कर सकते हैं। आप यह भी कोशिश कर सकते हैं और देख सकते हैं कि जैसे-जैसे आप एप्सिलॉन बदलते हैं, भविष्यवाणियों में विश्वास कैसे बदलता है।
हालांकि शक्तिशाली, इस ट्यूटोरियल में दिखाया गया हमला प्रतिकूल हमलों में अनुसंधान की शुरुआत थी, और तब से अधिक शक्तिशाली हमले बनाने वाले कई पेपर हैं। प्रतिकूल हमलों के अलावा, अनुसंधान ने रक्षा के निर्माण को भी प्रेरित किया है, जिसका उद्देश्य मजबूत मशीन लर्निंग मॉडल बनाना है। प्रतिकूल हमलों और बचाव की विस्तृत सूची के लिए आप इस सर्वेक्षण पत्र की समीक्षा कर सकते हैं।
प्रतिकूल हमलों और बचाव के कई और कार्यान्वयन के लिए, आप प्रतिकूल उदाहरण पुस्तकालय CleverHans देखना चाह सकते हैं।