
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
Обзор
API tf.distribute.Strategy предоставляет абстракцию для распределения обучения между несколькими процессорами. Он позволяет проводить распределенное обучение с использованием существующих моделей и обучающего кода с минимальными изменениями.
В этом руководстве показано, как использовать tf.distribute.MirroredStrategy для выполнения репликации в графе с синхронным обучением на многих графических процессорах на одной машине . Стратегия по существу копирует все переменные модели в каждый процессор. Затем он использует all-reduce для объединения градиентов от всех процессоров и применяет объединенное значение ко всем копиям модели.
Вы будете использовать API-интерфейсы tf.keras для построения модели и Model.fit для ее обучения. (Чтобы узнать о распределенном обучении с пользовательским циклом обучения и MirroredStrategy , ознакомьтесь с этим руководством .)
MirroredStrategy обучает вашу модель на нескольких графических процессорах на одном компьютере. Для синхронного обучения на многих графических процессорах на нескольких рабочих процессах используйте tf.distribute.MultiWorkerMirroredStrategy с Keras Model.fit или пользовательский цикл обучения . Другие варианты см. в Руководстве по распределенному обучению .
Чтобы узнать о различных других стратегиях, существует руководство по распределенному обучению с помощью TensorFlow .
Настраивать
import tensorflow_datasets as tfds
import tensorflow as tf
import os
# Load the TensorBoard notebook extension.
%load_ext tensorboard
print(tf.__version__)
2.8.0-rc1
Скачать набор данных
Загрузите набор данных MNIST из TensorFlow Datasets . Это возвращает набор данных в формате tf.data .
Установка для аргумента with_info True включает метаданные для всего набора данных, которые сохраняются здесь в info . Помимо прочего, этот объект метаданных включает в себя количество обучающих и тестовых примеров.
datasets, info = tfds.load(name='mnist', with_info=True, as_supervised=True)
mnist_train, mnist_test = datasets['train'], datasets['test']
Определите стратегию распространения
Создайте объект MirroredStrategy . Это будет обрабатывать распространение и предоставлять диспетчер контекста ( MirroredStrategy.scope ) для построения вашей модели внутри.
strategy = tf.distribute.MirroredStrategy()
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
print('Number of devices: {}'.format(strategy.num_replicas_in_sync))
Number of devices: 1
Настройка входного конвейера
При обучении модели с несколькими графическими процессорами вы можете эффективно использовать дополнительную вычислительную мощность, увеличив размер пакета. Как правило, используйте самый большой размер пакета, который соответствует памяти графического процессора, и соответствующим образом настраивайте скорость обучения.
# You can also do info.splits.total_num_examples to get the total
# number of examples in the dataset.
num_train_examples = info.splits['train'].num_examples
num_test_examples = info.splits['test'].num_examples
BUFFER_SIZE = 10000
BATCH_SIZE_PER_REPLICA = 64
BATCH_SIZE = BATCH_SIZE_PER_REPLICA * strategy.num_replicas_in_sync
Определите функцию, которая нормализует значения пикселей изображения из диапазона [0, 255] в диапазон [0, 1] ( масштабирование признаков ):
def scale(image, label):
image = tf.cast(image, tf.float32)
image /= 255
return image, label
Примените эту функцию scale к обучающим и тестовым данным, а затем используйте API-интерфейсы tf.data.Dataset для перемешивания обучающих данных ( Dataset.shuffle ) и их пакетирования ( Dataset.batch ). Обратите внимание, что вы также храните в памяти кэш обучающих данных для повышения производительности ( Dataset.cache ).
train_dataset = mnist_train.map(scale).cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
eval_dataset = mnist_test.map(scale).batch(BATCH_SIZE)
Создайте модель
Создайте и скомпилируйте модель Keras в контексте Strategy.scope :
with strategy.scope():
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, 3, activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10)
])
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
Определите обратные вызовы
Определите следующие tf.keras.callbacks :
-
tf.keras.callbacks.TensorBoard: пишет лог для TensorBoard, что позволяет визуализировать графики. -
tf.keras.callbacks.ModelCheckpoint: сохраняет модель с определенной периодичностью, например, после каждой эпохи. -
tf.keras.callbacks.LearningRateScheduler: планирует изменение скорости обучения, например, после каждой эпохи/пакета.
В иллюстративных целях добавьте настраиваемый обратный вызов с именем PrintLR , чтобы отображать скорость обучения в записной книжке.
# Define the checkpoint directory to store the checkpoints.
checkpoint_dir = './training_checkpoints'
# Define the name of the checkpoint files.
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt_{epoch}")
# Define a function for decaying the learning rate.
# You can define any decay function you need.
def decay(epoch):
if epoch < 3:
return 1e-3
elif epoch >= 3 and epoch < 7:
return 1e-4
else:
return 1e-5
# Define a callback for printing the learning rate at the end of each epoch.
class PrintLR(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
print('\nLearning rate for epoch {} is {}'.format(epoch + 1,
model.optimizer.lr.numpy()))
# Put all the callbacks together.
callbacks = [
tf.keras.callbacks.TensorBoard(log_dir='./logs'),
tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_prefix,
save_weights_only=True),
tf.keras.callbacks.LearningRateScheduler(decay),
PrintLR()
]
Тренируйтесь и оценивайте
Теперь обучите модель обычным способом, вызвав Model.fit для модели и передав набор данных, созданный в начале руководства. Этот шаг одинаков независимо от того, распространяете ли вы обучение или нет.
EPOCHS = 12
model.fit(train_dataset, epochs=EPOCHS, callbacks=callbacks)
2022-01-26 05:38:28.865380: W tensorflow/core/grappler/optimizers/data/auto_shard.cc:547] The `assert_cardinality` transformation is currently not handled by the auto-shard rewrite and will be removed.
Epoch 1/12
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
933/938 [============================>.] - ETA: 0s - loss: 0.2029 - accuracy: 0.9399
Learning rate for epoch 1 is 0.0010000000474974513
938/938 [==============================] - 10s 4ms/step - loss: 0.2022 - accuracy: 0.9401 - lr: 0.0010
Epoch 2/12
930/938 [============================>.] - ETA: 0s - loss: 0.0654 - accuracy: 0.9813
Learning rate for epoch 2 is 0.0010000000474974513
938/938 [==============================] - 3s 3ms/step - loss: 0.0652 - accuracy: 0.9813 - lr: 0.0010
Epoch 3/12
931/938 [============================>.] - ETA: 0s - loss: 0.0453 - accuracy: 0.9864
Learning rate for epoch 3 is 0.0010000000474974513
938/938 [==============================] - 3s 3ms/step - loss: 0.0453 - accuracy: 0.9864 - lr: 0.0010
Epoch 4/12
923/938 [============================>.] - ETA: 0s - loss: 0.0246 - accuracy: 0.9933
Learning rate for epoch 4 is 9.999999747378752e-05
938/938 [==============================] - 3s 3ms/step - loss: 0.0244 - accuracy: 0.9934 - lr: 1.0000e-04
Epoch 5/12
929/938 [============================>.] - ETA: 0s - loss: 0.0211 - accuracy: 0.9944
Learning rate for epoch 5 is 9.999999747378752e-05
938/938 [==============================] - 3s 3ms/step - loss: 0.0212 - accuracy: 0.9944 - lr: 1.0000e-04
Epoch 6/12
930/938 [============================>.] - ETA: 0s - loss: 0.0192 - accuracy: 0.9950
Learning rate for epoch 6 is 9.999999747378752e-05
938/938 [==============================] - 3s 3ms/step - loss: 0.0194 - accuracy: 0.9950 - lr: 1.0000e-04
Epoch 7/12
927/938 [============================>.] - ETA: 0s - loss: 0.0179 - accuracy: 0.9953
Learning rate for epoch 7 is 9.999999747378752e-05
938/938 [==============================] - 3s 3ms/step - loss: 0.0179 - accuracy: 0.9953 - lr: 1.0000e-04
Epoch 8/12
938/938 [==============================] - ETA: 0s - loss: 0.0153 - accuracy: 0.9966
Learning rate for epoch 8 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0153 - accuracy: 0.9966 - lr: 1.0000e-05
Epoch 9/12
927/938 [============================>.] - ETA: 0s - loss: 0.0151 - accuracy: 0.9966
Learning rate for epoch 9 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0150 - accuracy: 0.9966 - lr: 1.0000e-05
Epoch 10/12
935/938 [============================>.] - ETA: 0s - loss: 0.0148 - accuracy: 0.9966
Learning rate for epoch 10 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0148 - accuracy: 0.9966 - lr: 1.0000e-05
Epoch 11/12
937/938 [============================>.] - ETA: 0s - loss: 0.0146 - accuracy: 0.9967
Learning rate for epoch 11 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0146 - accuracy: 0.9967 - lr: 1.0000e-05
Epoch 12/12
926/938 [============================>.] - ETA: 0s - loss: 0.0145 - accuracy: 0.9967
Learning rate for epoch 12 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0144 - accuracy: 0.9967 - lr: 1.0000e-05
<keras.callbacks.History at 0x7fad70067c10>
Проверить наличие сохраненных контрольных точек:
# Check the checkpoint directory.ls {checkpoint_dir}
checkpoint ckpt_4.data-00000-of-00001 ckpt_1.data-00000-of-00001 ckpt_4.index ckpt_1.index ckpt_5.data-00000-of-00001 ckpt_10.data-00000-of-00001 ckpt_5.index ckpt_10.index ckpt_6.data-00000-of-00001 ckpt_11.data-00000-of-00001 ckpt_6.index ckpt_11.index ckpt_7.data-00000-of-00001 ckpt_12.data-00000-of-00001 ckpt_7.index ckpt_12.index ckpt_8.data-00000-of-00001 ckpt_2.data-00000-of-00001 ckpt_8.index ckpt_2.index ckpt_9.data-00000-of-00001 ckpt_3.data-00000-of-00001 ckpt_9.index ckpt_3.index
Чтобы проверить, насколько хорошо работает модель, загрузите последнюю контрольную точку и вызовите Model.evaluate для тестовых данных:
model.load_weights(tf.train.latest_checkpoint(checkpoint_dir))
eval_loss, eval_acc = model.evaluate(eval_dataset)
print('Eval loss: {}, Eval accuracy: {}'.format(eval_loss, eval_acc))
2022-01-26 05:39:15.260539: W tensorflow/core/grappler/optimizers/data/auto_shard.cc:547] The `assert_cardinality` transformation is currently not handled by the auto-shard rewrite and will be removed. 157/157 [==============================] - 2s 4ms/step - loss: 0.0373 - accuracy: 0.9879 Eval loss: 0.03732967749238014, Eval accuracy: 0.9879000186920166
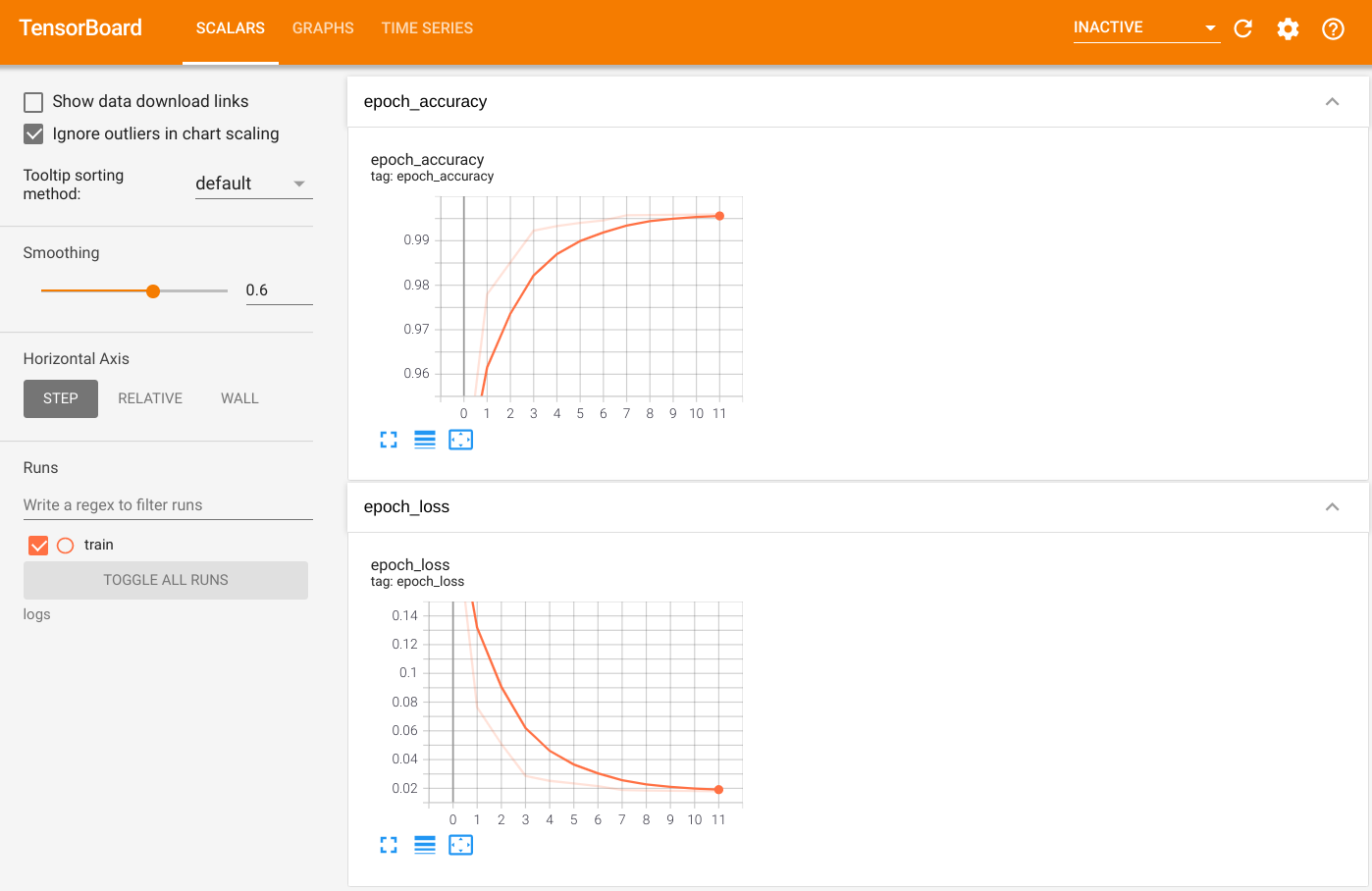
Чтобы визуализировать вывод, запустите TensorBoard и просмотрите журналы:
%tensorboard --logdir=logs
ls -sh ./logs
total 4.0K 4.0K train
Экспорт в SavedModel
Экспортируйте график и переменные в независимый от платформы формат SavedModel с помощью Model.save . После того, как ваша модель сохранена, вы можете загрузить ее с или без Strategy.scope .
path = 'saved_model/'
model.save(path, save_format='tf')
2022-01-26 05:39:18.012847: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: saved_model/assets INFO:tensorflow:Assets written to: saved_model/assets
Теперь загрузите модель без Strategy.scope :
unreplicated_model = tf.keras.models.load_model(path)
unreplicated_model.compile(
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
eval_loss, eval_acc = unreplicated_model.evaluate(eval_dataset)
print('Eval loss: {}, Eval Accuracy: {}'.format(eval_loss, eval_acc))
157/157 [==============================] - 1s 2ms/step - loss: 0.0373 - accuracy: 0.9879 Eval loss: 0.03732967749238014, Eval Accuracy: 0.9879000186920166
Загрузите модель с помощью Strategy.scope :
with strategy.scope():
replicated_model = tf.keras.models.load_model(path)
replicated_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
eval_loss, eval_acc = replicated_model.evaluate(eval_dataset)
print ('Eval loss: {}, Eval Accuracy: {}'.format(eval_loss, eval_acc))
2022-01-26 05:39:19.489971: W tensorflow/core/grappler/optimizers/data/auto_shard.cc:547] The `assert_cardinality` transformation is currently not handled by the auto-shard rewrite and will be removed. 157/157 [==============================] - 3s 3ms/step - loss: 0.0373 - accuracy: 0.9879 Eval loss: 0.03732967749238014, Eval Accuracy: 0.9879000186920166
Дополнительные ресурсы
Дополнительные примеры, в которых используются разные стратегии распространения с API Model.fit :
- В учебнике « Решение задач GLUE с помощью BERT на TPU » используется
tf.distribute.MirroredStrategyдля обучения на графических процессорах иtf.distribute.TPUStrategy— на TPU. - В руководстве по сохранению и загрузке модели с использованием стратегии распределения показано, как использовать API-интерфейсы SavedModel с
tf.distribute.Strategy. - Официальные модели TensorFlow можно настроить для запуска нескольких стратегий распространения.
Чтобы узнать больше о стратегиях распространения TensorFlow:
- В учебнике Custom training with tf.distribute.Strategy показано, как использовать
tf.distribute.MirroredStrategyдля обучения одного работника с пользовательским циклом обучения. - В учебном пособии по работе с несколькими работниками с помощью Keras показано, как использовать
MultiWorkerMirroredStrategyсModel.fit. - В учебном пособии « Пользовательский цикл обучения с Keras и MultiWorkerMirroredStrategy» показано, как использовать
MultiWorkerMirroredStrategyс Keras и пользовательским циклом обучения. - Руководство по распределенному обучению в TensorFlow содержит обзор доступных стратегий распространения.
- Руководство Повышение производительности с помощью tf.function содержит информацию о других стратегиях и инструментах, таких как профилировщик TensorFlow , который вы можете использовать для оптимизации производительности своих моделей TensorFlow.