
| | |  ดูแหล่งที่มาบน GitHub ดูแหล่งที่มาบน GitHub | |
ภาพรวม
tf.distribute.Strategy API จัดเตรียมสิ่งที่เป็นนามธรรมสำหรับการกระจายการฝึกอบรมของคุณในหน่วยประมวลผลหลายหน่วย ช่วยให้คุณสามารถดำเนินการฝึกอบรมแบบกระจายโดยใช้แบบจำลองที่มีอยู่และรหัสการฝึกอบรมโดยมีการเปลี่ยนแปลงเพียงเล็กน้อย
บทช่วยสอนนี้สาธิตวิธีใช้ tf.distribute.MirroredStrategy เพื่อทำการจำลองแบบในกราฟด้วย การฝึกแบบซิงโครนัสบน GPU จำนวนมากในเครื่อง เดียว กลยุทธ์จะคัดลอกตัวแปรของโมเดลทั้งหมดไปยังโปรเซสเซอร์แต่ละตัว จากนั้น ใช้ การลดทั้งหมด เพื่อรวมการไล่ระดับสีจากโปรเซสเซอร์ทั้งหมด และใช้ค่าที่รวมกันกับสำเนาทั้งหมดของโมเดล
คุณจะใช้ tf.keras APIs เพื่อสร้าง model และ Model.fit สำหรับการฝึก (หากต้องการเรียนรู้เกี่ยวกับการฝึกอบรมแบบกระจายด้วยลูปการฝึกแบบกำหนดเองและ MirroredStrategy โปรดดูบทช่วย สอน นี้ )
MirroredStrategy ฝึกโมเดลของคุณบน GPU หลายตัวในเครื่องเดียว สำหรับ การฝึกอบรมแบบซิงโครนัสบน GPU จำนวนมากกับผู้ปฏิบัติงานหลายคน ให้ใช้ tf.distribute.MultiWorkerMirroredStrategy กับ Keras Model.fit หรือ ลูปการฝึกแบบกำหนดเอง สำหรับตัวเลือกอื่นๆ โปรดดู คู่มือการฝึกอบรมแบบกระจาย
หากต้องการเรียนรู้เกี่ยวกับกลยุทธ์อื่นๆ มีคู่มือ การฝึกอบรมแบบกระจายด้วย TensorFlow
ติดตั้ง
import tensorflow_datasets as tfds
import tensorflow as tf
import os
# Load the TensorBoard notebook extension.
%load_ext tensorboard
print(tf.__version__)
2.8.0-rc1
ดาวน์โหลดชุดข้อมูล
โหลดชุดข้อมูล MNIST จากชุดข้อมูล TensorFlow ส่งคืนชุดข้อมูลในรูปแบบ tf.data
การตั้งค่าอาร์กิวเมนต์ with_info เป็น True จะรวมข้อมูลเมตาสำหรับชุดข้อมูลทั้งหมด ซึ่งจะถูกบันทึกไว้ที่นี่เพื่อ info เหนือสิ่งอื่นใด ออบเจ็กต์ข้อมูลเมตานี้รวมถึงจำนวนรถไฟและตัวอย่างการทดสอบ
datasets, info = tfds.load(name='mnist', with_info=True, as_supervised=True)
mnist_train, mnist_test = datasets['train'], datasets['test']
กำหนดกลยุทธ์การกระจายสินค้า
สร้างวัตถุ MirroredStrategy สิ่งนี้จะจัดการการแจกจ่ายและจัดเตรียมตัวจัดการบริบท ( MirroredStrategy.scope ) เพื่อสร้างแบบจำลองของคุณภายใน
strategy = tf.distribute.MirroredStrategy()
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
print('Number of devices: {}'.format(strategy.num_replicas_in_sync))
Number of devices: 1
ตั้งค่าไปป์ไลน์อินพุต
เมื่อฝึกโมเดลที่มี GPU หลายตัว คุณสามารถใช้พลังการประมวลผลพิเศษได้อย่างมีประสิทธิภาพโดยการเพิ่มขนาดแบทช์ โดยทั่วไป ให้ใช้ขนาดชุดใหญ่ที่สุดที่เหมาะกับหน่วยความจำ GPU และปรับอัตราการเรียนรู้ตามนั้น
# You can also do info.splits.total_num_examples to get the total
# number of examples in the dataset.
num_train_examples = info.splits['train'].num_examples
num_test_examples = info.splits['test'].num_examples
BUFFER_SIZE = 10000
BATCH_SIZE_PER_REPLICA = 64
BATCH_SIZE = BATCH_SIZE_PER_REPLICA * strategy.num_replicas_in_sync
กำหนดฟังก์ชันที่ปรับค่าพิกเซลของรูปภาพให้เป็นมาตรฐานจากช่วง [0, 255] เป็นช่วง [0, 1] (การ ปรับขนาดคุณลักษณะ ):
def scale(image, label):
image = tf.cast(image, tf.float32)
image /= 255
return image, label
ใช้ฟังก์ชัน scale นี้กับข้อมูลการฝึกและทดสอบ จากนั้นใช้ tf.data.Dataset API เพื่อสับเปลี่ยนข้อมูลการฝึก ( Dataset.shuffle ) และแบทช์ ( Dataset.batch ) ขอให้สังเกตว่าคุณกำลังเก็บแคชในหน่วยความจำของข้อมูลการฝึกไว้เพื่อปรับปรุงประสิทธิภาพ ( Dataset.cache )
train_dataset = mnist_train.map(scale).cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
eval_dataset = mnist_test.map(scale).batch(BATCH_SIZE)
สร้างแบบจำลอง
สร้างและรวบรวมโมเดล Keras ในบริบทของ Strategy.scope :
with strategy.scope():
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, 3, activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10)
])
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
กำหนดการโทรกลับ
กำหนด tf.keras.callbacks ต่อไปนี้:
-
tf.keras.callbacks.TensorBoard: เขียนบันทึกสำหรับ TensorBoard ซึ่งช่วยให้คุณเห็นภาพกราฟได้ -
tf.keras.callbacks.ModelCheckpoint: บันทึกโมเดลที่ความถี่ที่แน่นอน เช่น หลังจากทุกๆ ยุค -
tf.keras.callbacks.LearningRateScheduler: กำหนดเวลาอัตราการเรียนรู้ที่จะเปลี่ยนแปลงหลังจากนั้น ตัวอย่างเช่น ทุกยุค/แบทช์
เพื่อจุดประสงค์ในการอธิบาย ให้เพิ่มการเรียกกลับแบบกำหนดเองที่เรียกว่า PrintLR เพื่อแสดง อัตราการเรียนรู้ ในโน้ตบุ๊ก
# Define the checkpoint directory to store the checkpoints.
checkpoint_dir = './training_checkpoints'
# Define the name of the checkpoint files.
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt_{epoch}")
# Define a function for decaying the learning rate.
# You can define any decay function you need.
def decay(epoch):
if epoch < 3:
return 1e-3
elif epoch >= 3 and epoch < 7:
return 1e-4
else:
return 1e-5
# Define a callback for printing the learning rate at the end of each epoch.
class PrintLR(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
print('\nLearning rate for epoch {} is {}'.format(epoch + 1,
model.optimizer.lr.numpy()))
# Put all the callbacks together.
callbacks = [
tf.keras.callbacks.TensorBoard(log_dir='./logs'),
tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_prefix,
save_weights_only=True),
tf.keras.callbacks.LearningRateScheduler(decay),
PrintLR()
]
ฝึกฝนและประเมินผล
ตอนนี้ ฝึกโมเดลด้วยวิธีปกติโดยเรียก Model.fit บนโมเดล และส่งผ่านชุดข้อมูลที่สร้างขึ้นเมื่อเริ่มต้นบทช่วยสอน ขั้นตอนนี้เหมือนกันไม่ว่าคุณจะแจกจ่ายการฝึกอบรมหรือไม่
EPOCHS = 12
model.fit(train_dataset, epochs=EPOCHS, callbacks=callbacks)
2022-01-26 05:38:28.865380: W tensorflow/core/grappler/optimizers/data/auto_shard.cc:547] The `assert_cardinality` transformation is currently not handled by the auto-shard rewrite and will be removed.
Epoch 1/12
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
933/938 [============================>.] - ETA: 0s - loss: 0.2029 - accuracy: 0.9399
Learning rate for epoch 1 is 0.0010000000474974513
938/938 [==============================] - 10s 4ms/step - loss: 0.2022 - accuracy: 0.9401 - lr: 0.0010
Epoch 2/12
930/938 [============================>.] - ETA: 0s - loss: 0.0654 - accuracy: 0.9813
Learning rate for epoch 2 is 0.0010000000474974513
938/938 [==============================] - 3s 3ms/step - loss: 0.0652 - accuracy: 0.9813 - lr: 0.0010
Epoch 3/12
931/938 [============================>.] - ETA: 0s - loss: 0.0453 - accuracy: 0.9864
Learning rate for epoch 3 is 0.0010000000474974513
938/938 [==============================] - 3s 3ms/step - loss: 0.0453 - accuracy: 0.9864 - lr: 0.0010
Epoch 4/12
923/938 [============================>.] - ETA: 0s - loss: 0.0246 - accuracy: 0.9933
Learning rate for epoch 4 is 9.999999747378752e-05
938/938 [==============================] - 3s 3ms/step - loss: 0.0244 - accuracy: 0.9934 - lr: 1.0000e-04
Epoch 5/12
929/938 [============================>.] - ETA: 0s - loss: 0.0211 - accuracy: 0.9944
Learning rate for epoch 5 is 9.999999747378752e-05
938/938 [==============================] - 3s 3ms/step - loss: 0.0212 - accuracy: 0.9944 - lr: 1.0000e-04
Epoch 6/12
930/938 [============================>.] - ETA: 0s - loss: 0.0192 - accuracy: 0.9950
Learning rate for epoch 6 is 9.999999747378752e-05
938/938 [==============================] - 3s 3ms/step - loss: 0.0194 - accuracy: 0.9950 - lr: 1.0000e-04
Epoch 7/12
927/938 [============================>.] - ETA: 0s - loss: 0.0179 - accuracy: 0.9953
Learning rate for epoch 7 is 9.999999747378752e-05
938/938 [==============================] - 3s 3ms/step - loss: 0.0179 - accuracy: 0.9953 - lr: 1.0000e-04
Epoch 8/12
938/938 [==============================] - ETA: 0s - loss: 0.0153 - accuracy: 0.9966
Learning rate for epoch 8 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0153 - accuracy: 0.9966 - lr: 1.0000e-05
Epoch 9/12
927/938 [============================>.] - ETA: 0s - loss: 0.0151 - accuracy: 0.9966
Learning rate for epoch 9 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0150 - accuracy: 0.9966 - lr: 1.0000e-05
Epoch 10/12
935/938 [============================>.] - ETA: 0s - loss: 0.0148 - accuracy: 0.9966
Learning rate for epoch 10 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0148 - accuracy: 0.9966 - lr: 1.0000e-05
Epoch 11/12
937/938 [============================>.] - ETA: 0s - loss: 0.0146 - accuracy: 0.9967
Learning rate for epoch 11 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0146 - accuracy: 0.9967 - lr: 1.0000e-05
Epoch 12/12
926/938 [============================>.] - ETA: 0s - loss: 0.0145 - accuracy: 0.9967
Learning rate for epoch 12 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0144 - accuracy: 0.9967 - lr: 1.0000e-05
<keras.callbacks.History at 0x7fad70067c10>
ตรวจสอบจุดตรวจที่บันทึกไว้:
# Check the checkpoint directory.ls {checkpoint_dir}
checkpoint ckpt_4.data-00000-of-00001 ckpt_1.data-00000-of-00001 ckpt_4.index ckpt_1.index ckpt_5.data-00000-of-00001 ckpt_10.data-00000-of-00001 ckpt_5.index ckpt_10.index ckpt_6.data-00000-of-00001 ckpt_11.data-00000-of-00001 ckpt_6.index ckpt_11.index ckpt_7.data-00000-of-00001 ckpt_12.data-00000-of-00001 ckpt_7.index ckpt_12.index ckpt_8.data-00000-of-00001 ckpt_2.data-00000-of-00001 ckpt_8.index ckpt_2.index ckpt_9.data-00000-of-00001 ckpt_3.data-00000-of-00001 ckpt_9.index ckpt_3.index
ในการตรวจสอบว่าแบบจำลองทำงานได้ดีเพียงใด ให้โหลดจุดตรวจสอบล่าสุดและเรียก Model.evaluate กับข้อมูลการทดสอบ:
model.load_weights(tf.train.latest_checkpoint(checkpoint_dir))
eval_loss, eval_acc = model.evaluate(eval_dataset)
print('Eval loss: {}, Eval accuracy: {}'.format(eval_loss, eval_acc))
2022-01-26 05:39:15.260539: W tensorflow/core/grappler/optimizers/data/auto_shard.cc:547] The `assert_cardinality` transformation is currently not handled by the auto-shard rewrite and will be removed. 157/157 [==============================] - 2s 4ms/step - loss: 0.0373 - accuracy: 0.9879 Eval loss: 0.03732967749238014, Eval accuracy: 0.9879000186920166ตัวยึดตำแหน่ง23
หากต้องการแสดงภาพเอาต์พุต ให้เรียกใช้ TensorBoard และดูบันทึก:
%tensorboard --logdir=logs
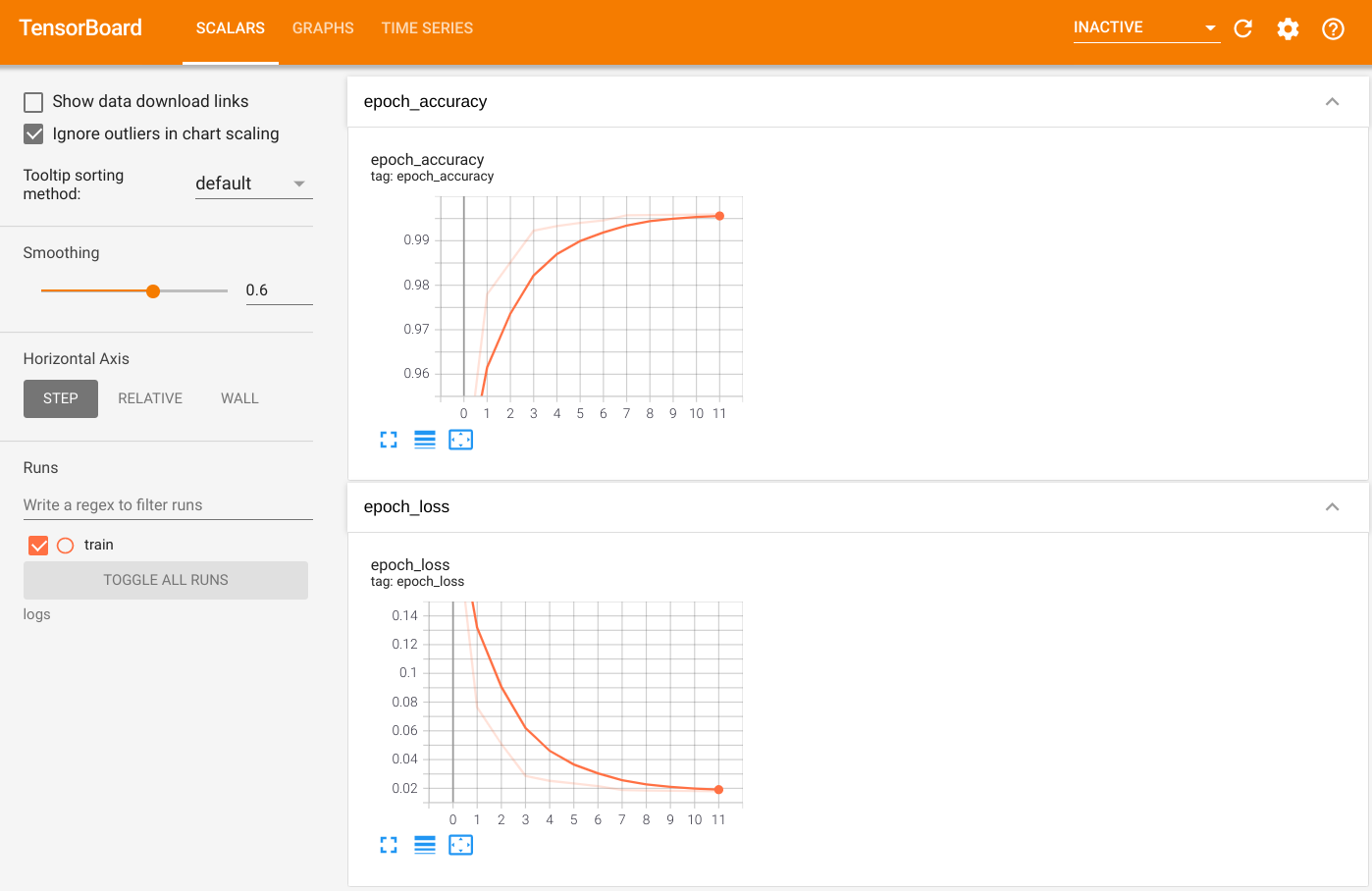
ls -sh ./logs
total 4.0K 4.0K train
ส่งออกไปยัง SavedModel
ส่งออกกราฟและตัวแปรไปยังรูปแบบ SavedModel ที่ไม่เชื่อเรื่องพระเจ้าบนแพลตฟอร์มโดยใช้ Model.save หลังจากที่แบบจำลองของคุณได้รับการบันทึกแล้ว คุณสามารถโหลดได้โดยมีหรือไม่มี Strategy.scope
path = 'saved_model/'
model.save(path, save_format='tf')
2022-01-26 05:39:18.012847: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: saved_model/assets INFO:tensorflow:Assets written to: saved_model/assets
ตอนนี้ โหลดโมเดลที่ไม่มี Strategy.scope :
unreplicated_model = tf.keras.models.load_model(path)
unreplicated_model.compile(
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
eval_loss, eval_acc = unreplicated_model.evaluate(eval_dataset)
print('Eval loss: {}, Eval Accuracy: {}'.format(eval_loss, eval_acc))
157/157 [==============================] - 1s 2ms/step - loss: 0.0373 - accuracy: 0.9879 Eval loss: 0.03732967749238014, Eval Accuracy: 0.9879000186920166
โหลดโมเดลด้วย Strategy.scope :
with strategy.scope():
replicated_model = tf.keras.models.load_model(path)
replicated_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
eval_loss, eval_acc = replicated_model.evaluate(eval_dataset)
print ('Eval loss: {}, Eval Accuracy: {}'.format(eval_loss, eval_acc))
2022-01-26 05:39:19.489971: W tensorflow/core/grappler/optimizers/data/auto_shard.cc:547] The `assert_cardinality` transformation is currently not handled by the auto-shard rewrite and will be removed. 157/157 [==============================] - 3s 3ms/step - loss: 0.0373 - accuracy: 0.9879 Eval loss: 0.03732967749238014, Eval Accuracy: 0.9879000186920166ตัวยึดตำแหน่ง33
แหล่งข้อมูลเพิ่มเติม
ตัวอย่างเพิ่มเติมที่ใช้กลยุทธ์การจัดจำหน่ายที่แตกต่างกันด้วย Keras Model.fit API:
- งาน Solve GLUE โดยใช้ BERT บนบทช่วยสอน TPU ใช้
tf.distribute.MirroredStrategyสำหรับการฝึกอบรมเกี่ยวกับ GPU และtf.distribute.TPUStrategy— บน TPU - บันทึกและโหลดโมเดลโดยใช้บทช่วยสอนกลยุทธ์การแจกจ่าย จะสาธิตวิธีใช้ SavedModel API ด้วย
tf.distribute.Strategy - โมเดล TensorFlow อย่างเป็นทางการ สามารถกำหนดค่าให้รันกลยุทธ์การกระจายได้หลายแบบ
หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับกลยุทธ์การกระจาย TensorFlow:
- การ ฝึกอบรมแบบกำหนดเองด้วย tf.distribute.Strategy จะแสดงวิธีใช้
tf.distribute.MirroredStrategyสำหรับการฝึกอบรมผู้ปฏิบัติงานคนเดียวด้วยลูปการฝึกแบบกำหนดเอง - การ ฝึกอบรม Multi-worker ด้วย Keras แสดงวิธีใช้
MultiWorkerMirroredStrategyกับModel.fit - ลูปการฝึกแบบกำหนดเองด้วย Keras และ บทช่วยสอน MultiWorkerMirroredStrategy จะแสดงวิธีใช้
MultiWorkerMirroredStrategyกับ Keras และลูปการฝึกแบบกำหนดเอง - คู่มือ การฝึกอบรมแบบกระจายใน TensorFlow จะให้ภาพรวมของกลยุทธ์การจัดจำหน่ายที่มีอยู่
- คู่มือประสิทธิภาพที่ ดีขึ้นด้วย tf.function ให้ข้อมูลเกี่ยวกับกลยุทธ์และเครื่องมืออื่นๆ เช่น TensorFlow Profiler ที่คุณสามารถใช้เพื่อเพิ่มประสิทธิภาพการทำงานของโมเดล TensorFlow ของคุณ