
| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub | |
Przegląd
Interfejs API tf.distribute.Strategy zapewnia abstrakcję do dystrybucji szkolenia na wiele jednostek przetwarzania. Umożliwia przeprowadzanie rozproszonych szkoleń przy użyciu istniejących modeli i kodu szkoleniowego przy minimalnych zmianach.
W tym samouczku pokazano, jak używać tf.distribute.MirroredStrategy do wykonywania replikacji na wykresie z uczeniem synchronicznym na wielu procesorach graficznych na jednym komputerze . Strategia zasadniczo kopiuje wszystkie zmienne modelu do każdego procesora. Następnie używa all-reduce do połączenia gradientów ze wszystkich procesorów i stosuje połączoną wartość do wszystkich kopii modelu.
Użyjesz interfejsów API tf.keras do zbudowania modelu i Model.fit do jego uczenia. (Aby dowiedzieć się więcej o rozproszonym szkoleniu z niestandardową pętlą treningową i MirroredStrategy , zapoznaj się z tym samouczkiem ).
MirroredStrategy szkoli Twój model na wielu procesorach graficznych na jednej maszynie. Aby trenować synchronicznie na wielu procesorach graficznych na wielu procesach roboczych, użyj tf.distribute.MultiWorkerMirroredStrategy z Keras Model.fit lub niestandardowej pętli szkoleniowej . Aby poznać inne opcje, zapoznaj się z przewodnikiem dotyczącym szkoleń rozproszonych .
Aby dowiedzieć się więcej o różnych innych strategiach, zapoznaj się z przewodnikiem Szkolenie rozproszone z TensorFlow .
Ustawiać
import tensorflow_datasets as tfds
import tensorflow as tf
import os
# Load the TensorBoard notebook extension.
%load_ext tensorboard
print(tf.__version__)
2.8.0-rc1
Pobierz zbiór danych
Załaduj zestaw danych MNIST z zestawów danych TensorFlow . Zwraca zestaw danych w formacie tf.data .
Ustawienie argumentu with_info na True włącza metadane dla całego zestawu danych, który jest zapisywany tutaj w info . Ten obiekt metadanych zawiera między innymi liczbę pociągów i przykładów testowych.
datasets, info = tfds.load(name='mnist', with_info=True, as_supervised=True)
mnist_train, mnist_test = datasets['train'], datasets['test']
Zdefiniuj strategię dystrybucji
Utwórz obiekt MirroredStrategy . To obsłuży dystrybucję i zapewni menedżera kontekstu ( MirroredStrategy.scope ) do zbudowania twojego modelu wewnątrz.
strategy = tf.distribute.MirroredStrategy()
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
print('Number of devices: {}'.format(strategy.num_replicas_in_sync))
Number of devices: 1
Skonfiguruj potok wejściowy
Podczas trenowania modelu z wieloma procesorami GPU można efektywnie wykorzystać dodatkową moc obliczeniową, zwiększając rozmiar partii. Ogólnie rzecz biorąc, używaj największego rozmiaru partii, który pasuje do pamięci GPU i odpowiednio dostosuj szybkość uczenia się.
# You can also do info.splits.total_num_examples to get the total
# number of examples in the dataset.
num_train_examples = info.splits['train'].num_examples
num_test_examples = info.splits['test'].num_examples
BUFFER_SIZE = 10000
BATCH_SIZE_PER_REPLICA = 64
BATCH_SIZE = BATCH_SIZE_PER_REPLICA * strategy.num_replicas_in_sync
Zdefiniuj funkcję, która normalizuje wartości pikseli obrazu z zakresu [0, 255] do zakresu [0, 1] ( skalowanie cech ):
def scale(image, label):
image = tf.cast(image, tf.float32)
image /= 255
return image, label
Zastosuj tę funkcję scale do danych uczących i testowych, a następnie użyj interfejsów API tf.data.Dataset do przetasowania danych uczących ( Dataset.shuffle ) i wsadowych ( Dataset.batch ). Zwróć uwagę, że przechowujesz również pamięć podręczną danych treningowych, aby poprawić wydajność ( Dataset.cache ).
train_dataset = mnist_train.map(scale).cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
eval_dataset = mnist_test.map(scale).batch(BATCH_SIZE)
Stwórz model
Utwórz i skompiluj model Keras w kontekście Strategy.scope :
with strategy.scope():
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, 3, activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10)
])
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
Zdefiniuj wywołania zwrotne
Zdefiniuj następujące tf.keras.callbacks :
-
tf.keras.callbacks.TensorBoard: tworzy dziennik dla TensorBoard, który umożliwia wizualizację wykresów. -
tf.keras.callbacks.ModelCheckpoint: zapisuje model z określoną częstotliwością, na przykład po każdej epoce. -
tf.keras.callbacks.LearningRateScheduler: planuje zmianę szybkości uczenia się na przykład po każdej epoce/partii.
W celach ilustracyjnych dodaj niestandardowe wywołanie zwrotne o nazwie PrintLR , aby wyświetlić szybkość uczenia się w notatniku.
# Define the checkpoint directory to store the checkpoints.
checkpoint_dir = './training_checkpoints'
# Define the name of the checkpoint files.
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt_{epoch}")
# Define a function for decaying the learning rate.
# You can define any decay function you need.
def decay(epoch):
if epoch < 3:
return 1e-3
elif epoch >= 3 and epoch < 7:
return 1e-4
else:
return 1e-5
# Define a callback for printing the learning rate at the end of each epoch.
class PrintLR(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
print('\nLearning rate for epoch {} is {}'.format(epoch + 1,
model.optimizer.lr.numpy()))
# Put all the callbacks together.
callbacks = [
tf.keras.callbacks.TensorBoard(log_dir='./logs'),
tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_prefix,
save_weights_only=True),
tf.keras.callbacks.LearningRateScheduler(decay),
PrintLR()
]
Trenuj i oceniaj
Teraz przeszkol model w zwykły sposób, wywołując Model.fit na modelu i przekazując zestaw danych utworzony na początku samouczka. Ten krok jest taki sam, niezależnie od tego, czy prowadzisz szkolenie, czy nie.
EPOCHS = 12
model.fit(train_dataset, epochs=EPOCHS, callbacks=callbacks)
2022-01-26 05:38:28.865380: W tensorflow/core/grappler/optimizers/data/auto_shard.cc:547] The `assert_cardinality` transformation is currently not handled by the auto-shard rewrite and will be removed.
Epoch 1/12
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
933/938 [============================>.] - ETA: 0s - loss: 0.2029 - accuracy: 0.9399
Learning rate for epoch 1 is 0.0010000000474974513
938/938 [==============================] - 10s 4ms/step - loss: 0.2022 - accuracy: 0.9401 - lr: 0.0010
Epoch 2/12
930/938 [============================>.] - ETA: 0s - loss: 0.0654 - accuracy: 0.9813
Learning rate for epoch 2 is 0.0010000000474974513
938/938 [==============================] - 3s 3ms/step - loss: 0.0652 - accuracy: 0.9813 - lr: 0.0010
Epoch 3/12
931/938 [============================>.] - ETA: 0s - loss: 0.0453 - accuracy: 0.9864
Learning rate for epoch 3 is 0.0010000000474974513
938/938 [==============================] - 3s 3ms/step - loss: 0.0453 - accuracy: 0.9864 - lr: 0.0010
Epoch 4/12
923/938 [============================>.] - ETA: 0s - loss: 0.0246 - accuracy: 0.9933
Learning rate for epoch 4 is 9.999999747378752e-05
938/938 [==============================] - 3s 3ms/step - loss: 0.0244 - accuracy: 0.9934 - lr: 1.0000e-04
Epoch 5/12
929/938 [============================>.] - ETA: 0s - loss: 0.0211 - accuracy: 0.9944
Learning rate for epoch 5 is 9.999999747378752e-05
938/938 [==============================] - 3s 3ms/step - loss: 0.0212 - accuracy: 0.9944 - lr: 1.0000e-04
Epoch 6/12
930/938 [============================>.] - ETA: 0s - loss: 0.0192 - accuracy: 0.9950
Learning rate for epoch 6 is 9.999999747378752e-05
938/938 [==============================] - 3s 3ms/step - loss: 0.0194 - accuracy: 0.9950 - lr: 1.0000e-04
Epoch 7/12
927/938 [============================>.] - ETA: 0s - loss: 0.0179 - accuracy: 0.9953
Learning rate for epoch 7 is 9.999999747378752e-05
938/938 [==============================] - 3s 3ms/step - loss: 0.0179 - accuracy: 0.9953 - lr: 1.0000e-04
Epoch 8/12
938/938 [==============================] - ETA: 0s - loss: 0.0153 - accuracy: 0.9966
Learning rate for epoch 8 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0153 - accuracy: 0.9966 - lr: 1.0000e-05
Epoch 9/12
927/938 [============================>.] - ETA: 0s - loss: 0.0151 - accuracy: 0.9966
Learning rate for epoch 9 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0150 - accuracy: 0.9966 - lr: 1.0000e-05
Epoch 10/12
935/938 [============================>.] - ETA: 0s - loss: 0.0148 - accuracy: 0.9966
Learning rate for epoch 10 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0148 - accuracy: 0.9966 - lr: 1.0000e-05
Epoch 11/12
937/938 [============================>.] - ETA: 0s - loss: 0.0146 - accuracy: 0.9967
Learning rate for epoch 11 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0146 - accuracy: 0.9967 - lr: 1.0000e-05
Epoch 12/12
926/938 [============================>.] - ETA: 0s - loss: 0.0145 - accuracy: 0.9967
Learning rate for epoch 12 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0144 - accuracy: 0.9967 - lr: 1.0000e-05
<keras.callbacks.History at 0x7fad70067c10>
Sprawdź zapisane punkty kontrolne:
# Check the checkpoint directory.ls {checkpoint_dir}
checkpoint ckpt_4.data-00000-of-00001 ckpt_1.data-00000-of-00001 ckpt_4.index ckpt_1.index ckpt_5.data-00000-of-00001 ckpt_10.data-00000-of-00001 ckpt_5.index ckpt_10.index ckpt_6.data-00000-of-00001 ckpt_11.data-00000-of-00001 ckpt_6.index ckpt_11.index ckpt_7.data-00000-of-00001 ckpt_12.data-00000-of-00001 ckpt_7.index ckpt_12.index ckpt_8.data-00000-of-00001 ckpt_2.data-00000-of-00001 ckpt_8.index ckpt_2.index ckpt_9.data-00000-of-00001 ckpt_3.data-00000-of-00001 ckpt_9.index ckpt_3.index
Aby sprawdzić, jak dobrze model działa, załaduj najnowszy punkt kontrolny i wywołaj Model.evaluate na danych testowych:
model.load_weights(tf.train.latest_checkpoint(checkpoint_dir))
eval_loss, eval_acc = model.evaluate(eval_dataset)
print('Eval loss: {}, Eval accuracy: {}'.format(eval_loss, eval_acc))
2022-01-26 05:39:15.260539: W tensorflow/core/grappler/optimizers/data/auto_shard.cc:547] The `assert_cardinality` transformation is currently not handled by the auto-shard rewrite and will be removed. 157/157 [==============================] - 2s 4ms/step - loss: 0.0373 - accuracy: 0.9879 Eval loss: 0.03732967749238014, Eval accuracy: 0.9879000186920166
Aby zwizualizować wyniki, uruchom TensorBoard i przejrzyj logi:
%tensorboard --logdir=logs
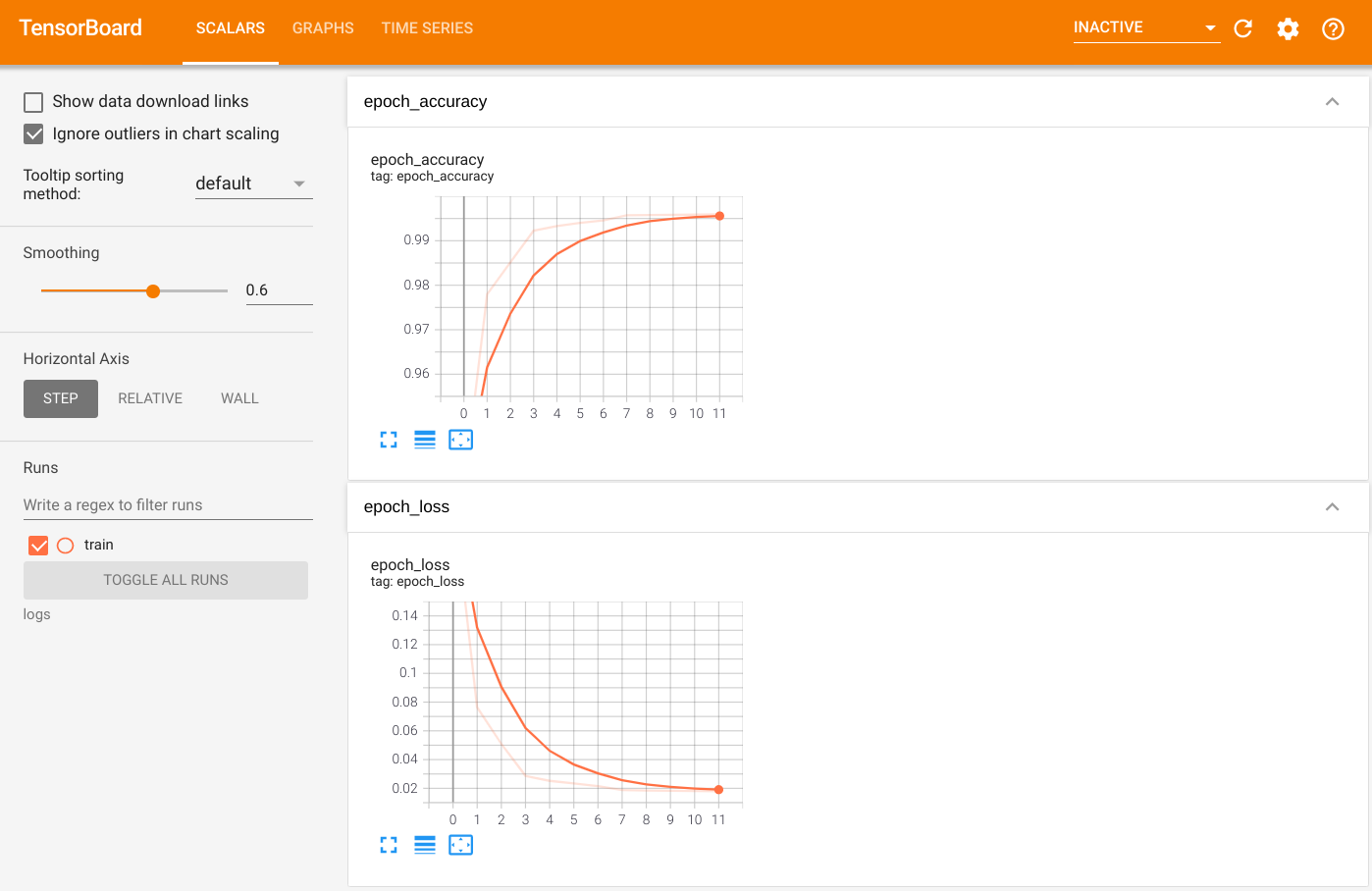
ls -sh ./logs
total 4.0K 4.0K train
Eksportuj do zapisanego modelu
Wyeksportuj wykres i zmienne do formatu SavedModel niezależnego od platformy przy użyciu Model.save . Po zapisaniu modelu możesz go załadować z lub bez Strategy.scope .
path = 'saved_model/'
model.save(path, save_format='tf')
2022-01-26 05:39:18.012847: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: saved_model/assets INFO:tensorflow:Assets written to: saved_model/assets
Teraz załaduj model bez Strategy.scope :
unreplicated_model = tf.keras.models.load_model(path)
unreplicated_model.compile(
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
eval_loss, eval_acc = unreplicated_model.evaluate(eval_dataset)
print('Eval loss: {}, Eval Accuracy: {}'.format(eval_loss, eval_acc))
157/157 [==============================] - 1s 2ms/step - loss: 0.0373 - accuracy: 0.9879 Eval loss: 0.03732967749238014, Eval Accuracy: 0.9879000186920166
Załaduj model za pomocą Strategy.scope :
with strategy.scope():
replicated_model = tf.keras.models.load_model(path)
replicated_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
eval_loss, eval_acc = replicated_model.evaluate(eval_dataset)
print ('Eval loss: {}, Eval Accuracy: {}'.format(eval_loss, eval_acc))
2022-01-26 05:39:19.489971: W tensorflow/core/grappler/optimizers/data/auto_shard.cc:547] The `assert_cardinality` transformation is currently not handled by the auto-shard rewrite and will be removed. 157/157 [==============================] - 3s 3ms/step - loss: 0.0373 - accuracy: 0.9879 Eval loss: 0.03732967749238014, Eval Accuracy: 0.9879000186920166
Dodatkowe zasoby
Więcej przykładów wykorzystujących różne strategie dystrybucji z API Keras Model.fit :
- Samouczek Rozwiązywanie zadań GLUE przy użyciu BERT na TPU wykorzystuje
tf.distribute.MirroredStrategydo uczenia na GPU itf.distribute.TPUStrategy— na TPU. - Samouczek dotyczący zapisywania i ładowania modelu przy użyciu strategii dystrybucji pokazuje, jak używać interfejsów API SavedModel z
tf.distribute.Strategy. - Oficjalne modele TensorFlow można skonfigurować do obsługi wielu strategii dystrybucji.
Aby dowiedzieć się więcej o strategiach dystrybucji TensorFlow:
- Szkolenie niestandardowe za pomocą samouczka tf.distribute.Strategy pokazuje, jak używać
tf.distribute.MirroredStrategydo szkolenia pojedynczego pracownika z niestandardową pętlą treningową. - Szkolenie dla wielu pracowników przy użyciu samouczka Keras pokazuje, jak korzystać z
MultiWorkerMirroredStrategyzModel.fit. - Samouczek Niestandardowa pętla szkoleniowa z Keras i MultiWorkerMirroredStrategy pokazuje, jak używać
MultiWorkerMirroredStrategyz Keras i niestandardową pętlą szkoleniową. - Szkolenie rozproszone w przewodniku TensorFlow zawiera przegląd dostępnych strategii dystrybucji.
- Przewodnik Lepsza wydajność dzięki tf.function zawiera informacje o innych strategiach i narzędziach, takich jak TensorFlow Profiler , których można użyć do optymalizacji wydajności modeli TensorFlow.