
| | |  Kaynağı GitHub'da görüntüleyin Kaynağı GitHub'da görüntüleyin | |
Bu kılavuz, İris çiçeklerini türlere göre sınıflandırmak için makine öğrenimini kullanır. TensorFlow'u şu amaçlarla kullanır:
- Bir model yapmak,
- Bu modeli örnek veriler üzerinde eğitin ve
- Bilinmeyen veriler hakkında tahminler yapmak için modeli kullanın.
TensorFlow programlama
Bu kılavuz, şu üst düzey TensorFlow kavramlarını kullanır:
- TensorFlow'un varsayılan istekli yürütme geliştirme ortamını kullanın,
- Datasets API ile verileri içe aktarın,
- TensorFlow'un Keras API'si ile modeller ve katmanlar oluşturun.
Bu öğretici, birçok TensorFlow programı gibi yapılandırılmıştır:
- Veri kümesini içe aktarın ve ayrıştırın.
- Modelin türünü seçin.
- Modeli eğitin.
- Modelin etkinliğini değerlendirin.
- Tahminlerde bulunmak için eğitilmiş modeli kullanın.
Kurulum programı
İçe aktarmayı yapılandır
TensorFlow ve diğer gerekli Python modüllerini içe aktarın. Varsayılan olarak, TensorFlow, işlemleri hemen değerlendirmek için istekli yürütmeyi kullanır ve daha sonra yürütülecek bir hesaplama grafiği oluşturmak yerine somut değerler döndürür. REPL veya python etkileşimli konsola alışkınsanız, bu size tanıdık geliyor.
import os
import matplotlib.pyplot as plt
import tensorflow as tf
print("TensorFlow version: {}".format(tf.__version__))
print("Eager execution: {}".format(tf.executing_eagerly()))
TensorFlow version: 2.8.0-rc1 Eager execution: True
İris sınıflandırma problemi
Bulduğunuz her İris çiçeğini kategorize etmenin otomatik bir yolunu arayan bir botanikçi olduğunuzu hayal edin. Makine öğrenimi, çiçekleri istatistiksel olarak sınıflandırmak için birçok algoritma sağlar. Örneğin, gelişmiş bir makine öğrenimi programı, çiçekleri fotoğraflara göre sınıflandırabilir. Hırslarımız daha mütevazı - İris çiçeklerini, çanak yapraklarının ve taç yapraklarının uzunluk ve genişlik ölçümlerine göre sınıflandıracağız.
Iris cinsi yaklaşık 300 tür içerir, ancak programımız yalnızca aşağıdaki üçünü sınıflandıracaktır:
- iris setozası
- iris virginica
- iris çok renkli
 |
| Şekil 1. İris setosa ( Radomil , CC BY-SA 3.0 tarafından), Iris versicolor , ( Dlanglois , CC BY-SA 3.0 tarafından) ve Iris virginica ( Frank Mayfield tarafından, CC BY-SA 2.0). |
Neyse ki, birisi çanak yaprağı ve taç yaprağı ölçümleriyle 120 İris çiçeğinden oluşan bir veri kümesi oluşturmuştur . Bu, yeni başlayan makine öğrenimi sınıflandırma sorunları için popüler olan klasik bir veri kümesidir.
Eğitim veri kümesini içe aktarın ve ayrıştırın
Veri kümesi dosyasını indirin ve bu Python programı tarafından kullanılabilecek bir yapıya dönüştürün.
Veri kümesini indirin
tf.keras.utils.get_file işlevini kullanarak eğitim veri kümesi dosyasını indirin. Bu, indirilen dosyanın dosya yolunu döndürür:
train_dataset_url = "https://storage.googleapis.com/download.tensorflow.org/data/iris_training.csv"
train_dataset_fp = tf.keras.utils.get_file(fname=os.path.basename(train_dataset_url),
origin=train_dataset_url)
print("Local copy of the dataset file: {}".format(train_dataset_fp))
Local copy of the dataset file: /home/kbuilder/.keras/datasets/iris_training.csv
Verileri inceleyin
Bu veri kümesi, iris_training.csv , virgülle ayrılmış değerler (CSV) olarak biçimlendirilmiş tablo verilerini depolayan bir düz metin dosyasıdır. İlk beş girişe göz atmak için head -n5 komutunu kullanın:
head -n5 {train_dataset_fp}
tutucu7 l10n-yer120,4,setosa,versicolor,virginica 6.4,2.8,5.6,2.2,2 5.0,2.3,3.3,1.0,1 4.9,2.5,4.5,1.7,2 4.9,3.1,1.5,0.1,0
Veri kümesinin bu görünümünden aşağıdakilere dikkat edin:
- İlk satır, veri kümesi hakkında bilgi içeren bir başlıktır:
- Toplam 120 örnek var. Her örneğin dört özelliği ve üç olası etiket adından biri vardır.
- Sonraki satırlar, her satıra bir örnek olacak şekilde veri kayıtlarıdır, burada:
- İlk dört alan özelliklerdir : bunlar bir örneğin özellikleridir. Burada alanlar, çiçek ölçümlerini temsil eden kayan sayıları tutar.
- Son sütun etikettir : bu, tahmin etmek istediğimiz değerdir. Bu veri kümesi için bir çiçek adına karşılık gelen 0, 1 veya 2 tamsayı değeridir.
Bunu kod halinde yazalım:
# column order in CSV file
column_names = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']
feature_names = column_names[:-1]
label_name = column_names[-1]
print("Features: {}".format(feature_names))
print("Label: {}".format(label_name))
Features: ['sepal_length', 'sepal_width', 'petal_length', 'petal_width'] Label: species
Her etiket, dize adıyla ilişkilendirilir (örneğin, "setosa"), ancak makine öğrenimi tipik olarak sayısal değerlere dayanır. Etiket numaraları, aşağıdakiler gibi adlandırılmış bir temsile eşlenir:
-
0: İris setozası -
1: İris çok renkli -
2: İris virginica
Özellikler ve etiketler hakkında daha fazla bilgi için Machine Learning Crash Course'un ML Terminolojisi bölümüne bakın .
class_names = ['Iris setosa', 'Iris versicolor', 'Iris virginica']
Bir tf.data.Dataset oluşturun
TensorFlow'un Veri Kümesi API'si , bir modele veri yüklemek için birçok yaygın durumu ele alır. Bu, verileri okumak ve bunları eğitim için kullanılan bir forma dönüştürmek için üst düzey bir API'dir.
Veri kümesi CSV biçimli bir metin dosyası olduğundan, verileri uygun bir biçime ayrıştırmak için tf.data.experimental.make_csv_dataset işlevini kullanın. Bu işlev eğitim modelleri için veri oluşturduğundan, varsayılan davranış verileri karıştırmak ( shuffle=True, shuffle_buffer_size=10000 ) ve veri kümesini sonsuza kadar tekrarlamaktır ( num_epochs=None ). Ayrıca batch_size parametresini de ayarladık:
batch_size = 32
train_dataset = tf.data.experimental.make_csv_dataset(
train_dataset_fp,
batch_size,
column_names=column_names,
label_name=label_name,
num_epochs=1)
make_csv_dataset işlevi, (features, label) çiftlerinden oluşan bir tf.data.Dataset döndürür; burada features bir sözlüktür: {'feature_name': value}
Bu Dataset nesneleri yinelenebilir. Bir dizi özelliğe bakalım:
features, labels = next(iter(train_dataset))
print(features)
OrderedDict([('sepal_length', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([5. , 7.4, 6. , 7.2, 5.9, 5.8, 5. , 5. , 7.7, 5.7, 6.3, 5.8, 5. ,
4.8, 6.6, 6.3, 5.4, 6.9, 4.8, 6.6, 5.8, 7.7, 6.7, 7.6, 5.5, 6.4,
5.6, 6.4, 4.4, 4.5, 6.5, 6.3], dtype=float32)>), ('sepal_width', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([3.5, 2.8, 2.7, 3.2, 3. , 2.6, 2. , 3.4, 3. , 2.8, 2.3, 2.7, 3.6,
3.1, 2.9, 3.3, 3. , 3.1, 3. , 3. , 4. , 2.6, 3. , 3. , 2.4, 2.7,
2.7, 2.8, 3. , 2.3, 2.8, 2.5], dtype=float32)>), ('petal_length', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([1.6, 6.1, 5.1, 6. , 5.1, 4. , 3.5, 1.6, 6.1, 4.5, 4.4, 5.1, 1.4,
1.6, 4.6, 4.7, 4.5, 5.1, 1.4, 4.4, 1.2, 6.9, 5. , 6.6, 3.7, 5.3,
4.2, 5.6, 1.3, 1.3, 4.6, 5. ], dtype=float32)>), ('petal_width', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([0.6, 1.9, 1.6, 1.8, 1.8, 1.2, 1. , 0.4, 2.3, 1.3, 1.3, 1.9, 0.2,
0.2, 1.3, 1.6, 1.5, 2.3, 0.3, 1.4, 0.2, 2.3, 1.7, 2.1, 1. , 1.9,
1.3, 2.1, 0.2, 0.3, 1.5, 1.9], dtype=float32)>)])
Benzer özelliklerin birlikte gruplandırıldığına veya toplu işlendiğine dikkat edin. Her örnek satırın alanları, karşılık gelen özellik dizisine eklenir. Bu özellik dizilerinde saklanan örneklerin sayısını ayarlamak için batch_size değerini değiştirin.
Partiden birkaç özelliği çizerek bazı kümeleri görmeye başlayabilirsiniz:
plt.scatter(features['petal_length'],
features['sepal_length'],
c=labels,
cmap='viridis')
plt.xlabel("Petal length")
plt.ylabel("Sepal length")
plt.show()
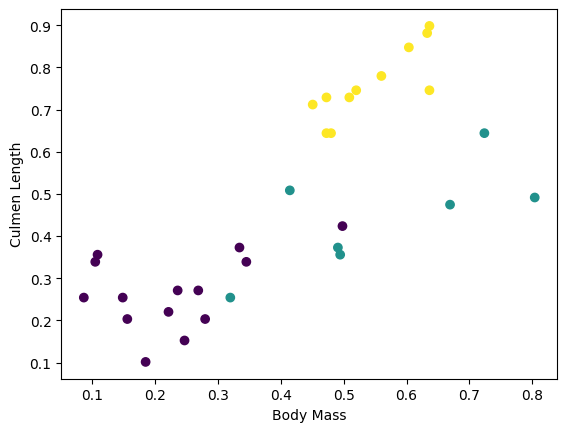
Model oluşturma adımını basitleştirmek için, özellikler sözlüğünü şu şekle sahip tek bir dizide yeniden paketlemek için bir işlev oluşturun: (batch_size, num_features) .
Bu işlev, bir tensör listesinden değerler alan ve belirtilen boyutta birleşik bir tensör oluşturan tf.stack yöntemini kullanır:
def pack_features_vector(features, labels):
"""Pack the features into a single array."""
features = tf.stack(list(features.values()), axis=1)
return features, labels
Ardından, her (features,label) çiftinin features eğitim veri kümesine paketlemek için tf.data.Dataset#map yöntemini kullanın:
train_dataset = train_dataset.map(pack_features_vector)
Dataset Kümesinin özellikler öğesi artık şekilli dizilerdir (batch_size, num_features) . İlk birkaç örneğe bakalım:
features, labels = next(iter(train_dataset))
print(features[:5])
tf.Tensor( [[4.9 3. 1.4 0.2] [6.1 3. 4.9 1.8] [6.1 2.6 5.6 1.4] [6.9 3.2 5.7 2.3] [6.7 3.1 4.4 1.4]], shape=(5, 4), dtype=float32)
Modelin türünü seçin
Neden modeli?
Model , özellikler ve etiket arasındaki ilişkidir. İris sınıflandırma problemi için model, çanak yaprağı ve taç yaprağı ölçümleri ile tahmin edilen İris türleri arasındaki ilişkiyi tanımlar. Bazı basit modeller birkaç satır cebir ile açıklanabilir, ancak karmaşık makine öğrenimi modellerinin özetlemesi zor olan çok sayıda parametresi vardır.
Makine öğrenimini kullanmadan dört özellik ile İris türleri arasındaki ilişkiyi belirleyebilir misiniz? Yani, bir model oluşturmak için geleneksel programlama tekniklerini (örneğin, birçok koşullu ifadeyi) kullanabilir misiniz? Belki de veri setini belirli bir türün taç yaprağı ve çanak yaprağı ölçümleri arasındaki ilişkileri belirlemeye yetecek kadar uzun süre analiz ettiyseniz. Ve bu, daha karmaşık veri kümelerinde zor, hatta imkansız hale gelir. İyi bir makine öğrenimi yaklaşımı sizin için modeli belirler . Yeterli temsili örneği doğru makine öğrenimi modeli türüne beslerseniz, program ilişkileri sizin için çözecektir.
modeli seçin
Eğitmek için model türünü seçmemiz gerekiyor. Birçok model çeşidi vardır ve iyi bir model seçmek tecrübe ister. Bu öğretici, Iris sınıflandırma problemini çözmek için bir sinir ağı kullanır. Sinir ağları , özellikler ve etiket arasında karmaşık ilişkiler bulabilir. Bir veya daha fazla gizli katman halinde düzenlenmiş, yüksek düzeyde yapılandırılmış bir grafiktir. Her gizli katman bir veya daha fazla nörondan oluşur. Sinir ağlarının birkaç kategorisi vardır ve bu program yoğun veya tam bağlantılı bir sinir ağı kullanır: bir katmandaki nöronlar, önceki katmandaki her nörondan girdi bağlantıları alır. Örneğin, Şekil 2 bir girdi katmanı, iki gizli katman ve bir çıktı katmanından oluşan yoğun bir sinir ağını göstermektedir:
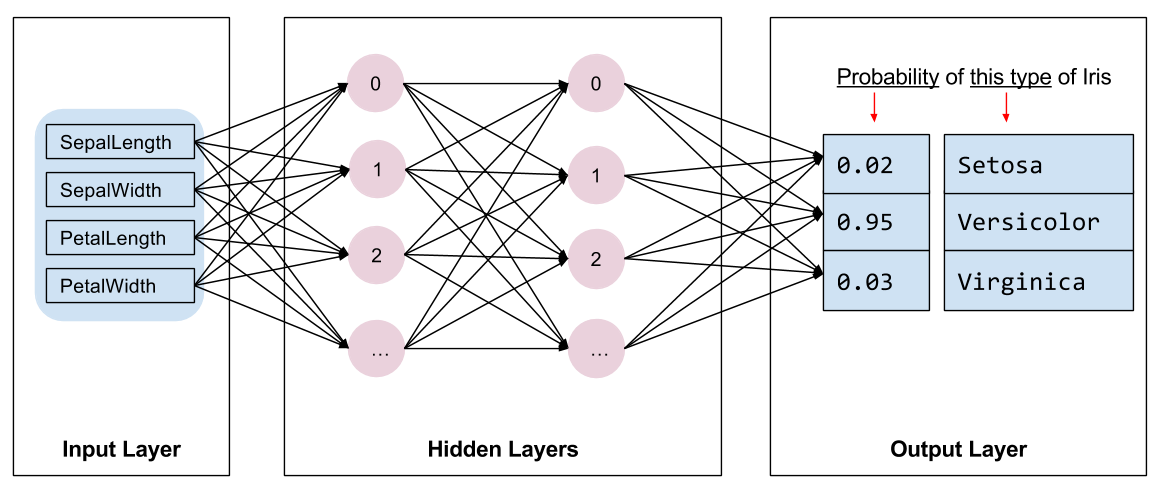 |
| Şekil 2. Özellikleri, gizli katmanları ve tahminleri olan bir sinir ağı. |
Şekil 2'deki model eğitildiğinde ve etiketlenmemiş bir örnekle beslendiğinde, üç tahmin verir: Bu çiçeğin verilen İris türü olma olasılığı. Bu tahmine çıkarım denir. Bu örnek için, çıktı tahminlerinin toplamı 1.0'dır. Şekil 2'de bu tahmin şu şekildedir: İris setosa için 0.02 , İris versicolor için 0.95 ve İris virginica için 0.03 . Bu, modelin %95 olasılıkla, etiketlenmemiş bir örnek çiçeğin bir İris versicolor olduğunu tahmin ettiği anlamına gelir.
Keras kullanarak bir model oluşturun
TensorFlow tf.keras API, modeller ve katmanlar oluşturmanın tercih edilen yoludur. Bu, model oluşturmayı ve denemeyi kolaylaştırırken, Keras her şeyi birbirine bağlamanın karmaşıklığını halleder.
tf.keras.Sequential modeli, doğrusal bir katman yığınıdır. Yapıcısı, katman örneklerinin bir listesini alır; bu durumda, her biri 10 düğümlü iki tf.keras.layers.Dense katmanı ve etiket tahminlerimizi temsil eden 3 düğümlü bir çıktı katmanı. İlk katmanın input_shape parametresi, veri kümesindeki özelliklerin sayısına karşılık gelir ve gereklidir:
model = tf.keras.Sequential([
tf.keras.layers.Dense(10, activation=tf.nn.relu, input_shape=(4,)), # input shape required
tf.keras.layers.Dense(10, activation=tf.nn.relu),
tf.keras.layers.Dense(3)
])
Aktivasyon işlevi , katmandaki her bir düğümün çıktı şeklini belirler. Bu doğrusal olmama durumları önemlidir - onlar olmadan model tek bir katmana eşdeğer olacaktır. Birçok tf.keras.activations vardır, ancak ReLU gizli katmanlar için ortaktır.
İdeal gizli katman ve nöron sayısı, soruna ve veri kümesine bağlıdır. Makine öğreniminin birçok yönü gibi, sinir ağının en iyi şeklini seçmek de bilgi ve deney karışımı gerektirir. Genel bir kural olarak, gizli katmanların ve nöronların sayısını artırmak tipik olarak daha güçlü bir model oluşturur ve bu da etkili bir şekilde eğitmek için daha fazla veri gerektirir.
modeli kullanma
Bu modelin bir dizi özelliğe ne yaptığına hızlıca bir göz atalım:
predictions = model(features)
predictions[:5]
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[-4.0874639e+00, 1.5199981e-03, -9.9991310e-01],
[-5.3246369e+00, -1.8366380e-01, -1.3161827e+00],
[-5.1154275e+00, -2.8129923e-01, -1.3305402e+00],
[-6.0694785e+00, -2.1251860e-01, -1.5091233e+00],
[-5.6730523e+00, -1.4321266e-01, -1.4437559e+00]], dtype=float32)>
Burada her örnek, her sınıf için bir logit döndürür.
Bu logitleri her sınıf için bir olasılığa dönüştürmek için softmax işlevini kullanın:
tf.nn.softmax(predictions[:5])
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[0.01210616, 0.7224865 , 0.26540732],
[0.00440638, 0.75297093, 0.24262273],
[0.00585618, 0.7362918 , 0.25785193],
[0.00224076, 0.7835035 , 0.21425581],
[0.00310779, 0.7834839 , 0.21340834]], dtype=float32)>
tf.argmax sınıflar arasında almak bize tahmin edilen sınıf indeksini verir. Ancak model henüz eğitilmedi, bu nedenle bunlar iyi tahminler değil:
print("Prediction: {}".format(tf.argmax(predictions, axis=1)))
print(" Labels: {}".format(labels))
Prediction: [1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]
Labels: [0 2 2 2 1 1 0 1 1 2 2 1 0 2 2 2 1 0 2 2 1 0 2 1 2 0 1 1 2 2 1 2]
Modeli eğit
Eğitim , model kademeli olarak optimize edildiğinde veya model veri kümesini öğrendiğinde makine öğreniminin aşamasıdır. Amaç, görünmeyen veriler hakkında tahminler yapmak için eğitim veri kümesinin yapısı hakkında yeterince bilgi edinmektir. Eğitim veri kümesi hakkında çok fazla şey öğrenirseniz, tahminler yalnızca gördüğü veriler için çalışır ve genelleştirilemez. Bu soruna fazla uydurma denir - bir sorunun nasıl çözüleceğini anlamak yerine cevapları ezberlemek gibidir.
Iris sınıflandırma sorunu, denetimli makine öğreniminin bir örneğidir: model, etiketler içeren örneklerden eğitilmiştir. Denetimsiz makine öğreniminde örnekler etiket içermez. Bunun yerine, model tipik olarak özellikler arasında desenler bulur.
Kayıp ve gradyan işlevini tanımlayın
Hem eğitim hem de değerlendirme aşamalarının modelin kaybını hesaplaması gerekir. Bu, bir modelin tahminlerinin istenen etiketten ne kadar uzak olduğunu, başka bir deyişle modelin ne kadar kötü performans gösterdiğini ölçer. Bu değeri en aza indirmek veya optimize etmek istiyoruz.
Modelimiz, modelin sınıf olasılık tahminlerini ve istenen etiketi alan tf.keras.losses.SparseCategoricalCrossentropy işlevini kullanarak kaybını hesaplayacak ve örnekler arasında ortalama kaybı döndürecektir.
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
def loss(model, x, y, training):
# training=training is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
y_ = model(x, training=training)
return loss_object(y_true=y, y_pred=y_)
l = loss(model, features, labels, training=False)
print("Loss test: {}".format(l))
Loss test: 1.6059828996658325
Modelinizi optimize etmek için kullanılan degradeleri hesaplamak için tf.GradientTape bağlamını kullanın:
def grad(model, inputs, targets):
with tf.GradientTape() as tape:
loss_value = loss(model, inputs, targets, training=True)
return loss_value, tape.gradient(loss_value, model.trainable_variables)
Optimize edici oluşturun
Bir optimize edici, loss fonksiyonunu en aza indirmek için hesaplanan gradyanları modelin değişkenlerine uygular. Kayıp fonksiyonunu eğri bir yüzey olarak düşünebilirsiniz (bkz. Şekil 3) ve biz onun en alt noktasını etrafta dolaşarak bulmak istiyoruz. Eğimler en dik çıkış yönünü gösteriyor - bu yüzden ters yöne gideceğiz ve tepeden aşağı ineceğiz. Her parti için kayıp ve gradyanı yinelemeli olarak hesaplayarak, eğitim sırasında modeli ayarlayacağız. Yavaş yavaş, model, kaybı en aza indirmek için en iyi ağırlık ve sapma kombinasyonunu bulacaktır. Ve kayıp ne kadar düşükse, modelin tahminleri o kadar iyi olur.
 |
| Şekil 3. 3B uzayda zaman içinde görselleştirilen optimizasyon algoritmaları. (Kaynak: Stanford class CS231n , MIT Lisansı, Resim kredisi: Alec Radford ) |
TensorFlow, eğitim için birçok optimizasyon algoritmasına sahiptir. Bu model, stokastik gradyan iniş (SGD) algoritmasını uygulayan tf.keras.optimizers.SGD kullanır. learning_rate , tepeden aşağı her yineleme için atılacak adım boyutunu ayarlar. Bu, daha iyi sonuçlar elde etmek için genellikle ayarlayacağınız bir hiperparametredir .
Optimize ediciyi ayarlayalım:
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
Bunu, tek bir optimizasyon adımını hesaplamak için kullanacağız:
loss_value, grads = grad(model, features, labels)
print("Step: {}, Initial Loss: {}".format(optimizer.iterations.numpy(),
loss_value.numpy()))
optimizer.apply_gradients(zip(grads, model.trainable_variables))
print("Step: {}, Loss: {}".format(optimizer.iterations.numpy(),
loss(model, features, labels, training=True).numpy()))
Step: 0, Initial Loss: 1.6059828996658325 Step: 1, Loss: 1.3759253025054932
Eğitim döngüsü
Tüm parçalar yerine oturduğunda, model eğitime hazır! Bir eğitim döngüsü, daha iyi tahminler yapmasına yardımcı olmak için veri kümesi örneklerini modele besler. Aşağıdaki kod bloğu, bu eğitim adımlarını ayarlar:
- Her dönemi yineleyin. Bir dönem, veri kümesinden bir geçiştir.
- Bir çağda, eğitim
Datasetözelliklerini (x) ve etiketini (y) alarak her bir örnek üzerinde yineleyin. - Örneğin özelliklerini kullanarak bir tahmin yapın ve bunu etiketle karşılaştırın. Tahminin yanlışlığını ölçün ve bunu modelin kaybını ve eğimlerini hesaplamak için kullanın.
- Modelin değişkenlerini güncellemek için bir
optimizerkullanın. - Görselleştirme için bazı istatistikleri takip edin.
- Her dönem için tekrarlayın.
num_epochs değişkeni, veri kümesi koleksiyonu üzerinde döngü sayısıdır. Sezgisel olarak, bir modeli daha uzun süre eğitmek daha iyi bir modeli garanti etmez. num_epochs , ayarlayabileceğiniz bir hiperparametredir . Doğru numarayı seçmek genellikle hem deneyim hem de deneyim gerektirir:
## Note: Rerunning this cell uses the same model variables
# Keep results for plotting
train_loss_results = []
train_accuracy_results = []
num_epochs = 201
for epoch in range(num_epochs):
epoch_loss_avg = tf.keras.metrics.Mean()
epoch_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
# Training loop - using batches of 32
for x, y in train_dataset:
# Optimize the model
loss_value, grads = grad(model, x, y)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# Track progress
epoch_loss_avg.update_state(loss_value) # Add current batch loss
# Compare predicted label to actual label
# training=True is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
epoch_accuracy.update_state(y, model(x, training=True))
# End epoch
train_loss_results.append(epoch_loss_avg.result())
train_accuracy_results.append(epoch_accuracy.result())
if epoch % 50 == 0:
print("Epoch {:03d}: Loss: {:.3f}, Accuracy: {:.3%}".format(epoch,
epoch_loss_avg.result(),
epoch_accuracy.result()))
Epoch 000: Loss: 1.766, Accuracy: 43.333% Epoch 050: Loss: 0.579, Accuracy: 71.667% Epoch 100: Loss: 0.398, Accuracy: 82.500% Epoch 150: Loss: 0.307, Accuracy: 92.500% Epoch 200: Loss: 0.224, Accuracy: 95.833%
Zaman içinde kayıp işlevini görselleştirin
Modelin eğitim ilerlemesini yazdırmak yararlı olsa da, bu ilerlemeyi görmek genellikle daha yararlıdır. TensorBoard , TensorFlow ile paketlenmiş güzel bir görselleştirme aracıdır, ancak matplotlib modülünü kullanarak temel grafikler oluşturabiliriz.
Bu çizelgeleri yorumlamak biraz deneyim gerektirir, ancak gerçekten kaybın azaldığını ve doğruluğun arttığını görmek istersiniz:
fig, axes = plt.subplots(2, sharex=True, figsize=(12, 8))
fig.suptitle('Training Metrics')
axes[0].set_ylabel("Loss", fontsize=14)
axes[0].plot(train_loss_results)
axes[1].set_ylabel("Accuracy", fontsize=14)
axes[1].set_xlabel("Epoch", fontsize=14)
axes[1].plot(train_accuracy_results)
plt.show()
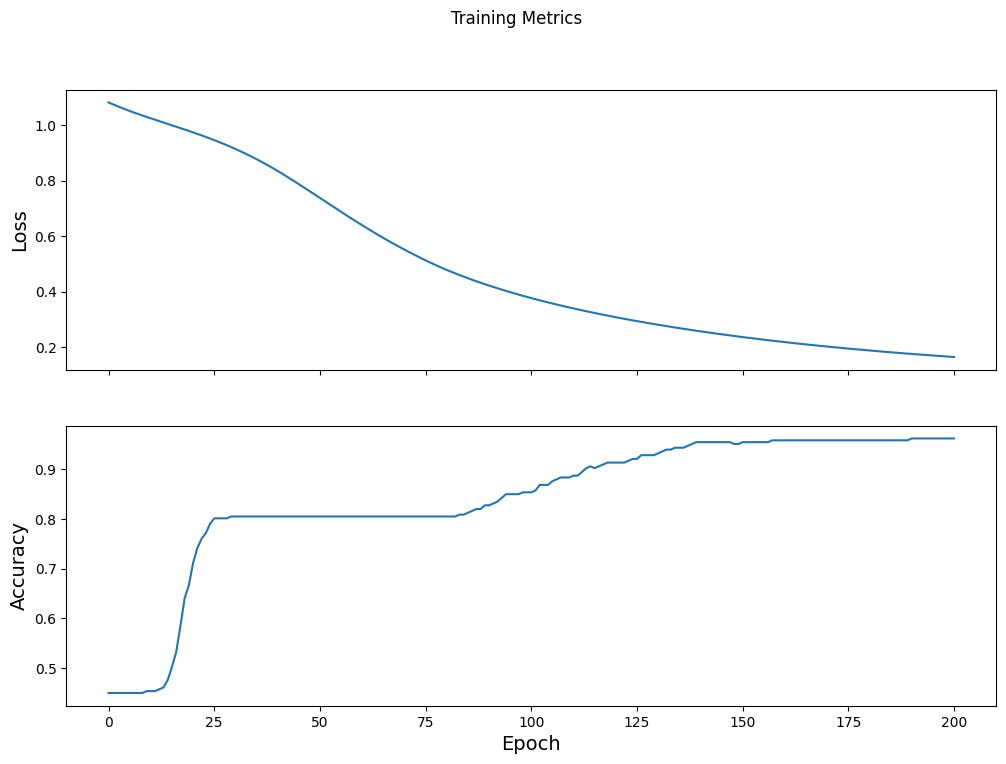
Modelin etkinliğini değerlendirin
Artık model eğitildiğine göre, performansı hakkında bazı istatistikler elde edebiliriz.
Değerlendirme , modelin ne kadar etkili tahminler yaptığını belirlemek anlamına gelir. Modelin İris sınıflandırmasındaki etkinliğini belirlemek için, bazı sepal ve petal ölçümlerini modele aktarın ve modelden hangi İris türlerini temsil ettiklerini tahmin etmesini isteyin. Ardından modelin tahminlerini gerçek etiketle karşılaştırın. Örneğin, girdi örneklerinin yarısında doğru türü seçen bir modelin doğruluğu 0.5 . Şekil 4, 5 tahminden 4'ünü %80 doğrulukla doğru yapan biraz daha etkili bir modeli göstermektedir:
| Örnek özellikler | Etiket | Model tahmini | |||
|---|---|---|---|---|---|
| 5.9 | 3.0 | 4.3 | 1.5 | 1 | 1 |
| 6.9 | 3.1 | 5.4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1.7 | 0,5 | 0 | 0 |
| 6.0 | 3.4 | 4.5 | 1.6 | 1 | 2 |
| 5.5 | 2.5 | 4.0 | 1.3 | 1 | 1 |
| Şekil 4. %80 doğru olan bir Iris sınıflandırıcısı. | |||||
Test veri setini kurun
Modeli değerlendirmek, modeli eğitmeye benzer. En büyük fark, örneklerin eğitim setinden ziyade ayrı bir test setinden gelmesidir. Bir modelin etkinliğini adil bir şekilde değerlendirmek için, bir modeli değerlendirmek için kullanılan örnekler, modeli eğitmek için kullanılan örneklerden farklı olmalıdır.
Test Dataset kurulumu, eğitim Dataset kurulumuna benzer. CSV metin dosyasını indirin ve bu değerleri ayrıştırın, ardından biraz karıştırın:
test_url = "https://storage.googleapis.com/download.tensorflow.org/data/iris_test.csv"
test_fp = tf.keras.utils.get_file(fname=os.path.basename(test_url),
origin=test_url)
test_dataset = tf.data.experimental.make_csv_dataset(
test_fp,
batch_size,
column_names=column_names,
label_name='species',
num_epochs=1,
shuffle=False)
test_dataset = test_dataset.map(pack_features_vector)
Modeli test veri setinde değerlendirin
Eğitim aşamasından farklı olarak model, test verilerinin yalnızca tek bir dönemini değerlendirir. Aşağıdaki kod hücresinde, test setindeki her örnek üzerinde yinelenir ve modelin tahminini gerçek etiketle karşılaştırırız. Bu, tüm test setinde modelin doğruluğunu ölçmek için kullanılır:
test_accuracy = tf.keras.metrics.Accuracy()
for (x, y) in test_dataset:
# training=False is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
logits = model(x, training=False)
prediction = tf.argmax(logits, axis=1, output_type=tf.int32)
test_accuracy(prediction, y)
print("Test set accuracy: {:.3%}".format(test_accuracy.result()))
Test set accuracy: 96.667%
Son partide görebiliriz, örneğin model genellikle doğrudur:
tf.stack([y,prediction],axis=1)
<tf.Tensor: shape=(30, 2), dtype=int32, numpy=
array([[1, 1],
[2, 2],
[0, 0],
[1, 1],
[1, 1],
[1, 1],
[0, 0],
[2, 2],
[1, 1],
[2, 2],
[2, 2],
[0, 0],
[2, 2],
[1, 1],
[1, 1],
[0, 0],
[1, 1],
[0, 0],
[0, 0],
[2, 2],
[0, 0],
[1, 1],
[2, 2],
[1, 2],
[1, 1],
[1, 1],
[0, 0],
[1, 1],
[2, 2],
[1, 1]], dtype=int32)>
Tahmin yapmak için eğitilmiş modeli kullanın
Bir model eğittik ve Iris türlerini sınıflandırmada iyi olduğunu - ama mükemmel olmadığını - "kanıtladık". Şimdi etiketlenmemiş örnekler üzerinde bazı tahminler yapmak için eğitilmiş modeli kullanalım; yani, özellikler içeren ancak etiket içermeyen örneklerde.
Gerçek hayatta, etiketlenmemiş örnekler uygulamalar, CSV dosyaları ve veri akışları dahil olmak üzere birçok farklı kaynaktan gelebilir. Şimdilik, etiketlerini tahmin etmek için manuel olarak üç etiketlenmemiş örnek sağlayacağız. Hatırlayın, etiket numaraları şu şekilde adlandırılmış bir temsile eşlenir:
-
0: İris setozası -
1: İris çok renkli -
2: İris virginica
predict_dataset = tf.convert_to_tensor([
[5.1, 3.3, 1.7, 0.5,],
[5.9, 3.0, 4.2, 1.5,],
[6.9, 3.1, 5.4, 2.1]
])
# training=False is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
predictions = model(predict_dataset, training=False)
for i, logits in enumerate(predictions):
class_idx = tf.argmax(logits).numpy()
p = tf.nn.softmax(logits)[class_idx]
name = class_names[class_idx]
print("Example {} prediction: {} ({:4.1f}%)".format(i, name, 100*p))
Example 0 prediction: Iris setosa (97.6%) Example 1 prediction: Iris versicolor (82.0%) Example 2 prediction: Iris virginica (56.4%)