
| | |  ดูแหล่งที่มาบน GitHub ดูแหล่งที่มาบน GitHub | |
คู่มือนี้ใช้แมชชีนเลิร์นนิงในการ จัดหมวดหมู่ ดอกไม้ไอริสตามสายพันธุ์ ใช้ TensorFlow เพื่อ:
- สร้างแบบจำลอง,
- ฝึกโมเดลนี้กับข้อมูลตัวอย่างและ
- ใช้แบบจำลองเพื่อคาดการณ์ข้อมูลที่ไม่รู้จัก
การเขียนโปรแกรม TensorFlow
คู่มือนี้ใช้แนวคิด TensorFlow ระดับสูงเหล่านี้:
- ใช้สภาพแวดล้อมการพัฒนาการ ดำเนินการที่กระตือรือร้น เริ่มต้นของ TensorFlow
- นำเข้าข้อมูลด้วย Datasets API
- สร้างโมเดลและเลเยอร์ด้วย Keras API ของ TensorFlow
บทช่วยสอนนี้มีโครงสร้างเหมือนกับโปรแกรม TensorFlow หลายโปรแกรม:
- นำเข้าและแยกวิเคราะห์ชุดข้อมูล
- เลือกประเภทของรุ่น
- ฝึกโมเดล.
- ประเมินประสิทธิภาพของแบบจำลอง
- ใช้แบบจำลองที่ได้รับการฝึกอบรมมาในการทำนาย
โปรแกรมติดตั้ง
กำหนดค่าการนำเข้า
นำเข้า TensorFlow และโมดูล Python ที่จำเป็นอื่นๆ โดยค่าเริ่มต้น TensorFlow จะใช้ การดำเนินการที่กระตือรือร้น เพื่อประเมินการดำเนินการทันที โดยคืนค่าที่เป็นรูปธรรมแทนที่จะสร้างกราฟการคำนวณที่ดำเนินการในภายหลัง หากคุณคุ้นเคยกับ REPL หรือคอนโซลแบบโต้ตอบของ python คุณจะรู้สึกคุ้นเคย
import os
import matplotlib.pyplot as plt
import tensorflow as tf
print("TensorFlow version: {}".format(tf.__version__))
print("Eager execution: {}".format(tf.executing_eagerly()))
TensorFlow version: 2.8.0-rc1 Eager execution: True
ปัญหาการจำแนกไอริส
ลองนึกภาพคุณเป็นนักพฤกษศาสตร์ที่กำลังมองหาวิธีอัตโนมัติในการจัดหมวดหมู่ดอกไม้ไอริสแต่ละชนิดที่คุณพบ แมชชีนเลิร์นนิงมีอัลกอริธึมมากมายในการจำแนกดอกไม้ตามสถิติ ตัวอย่างเช่น โปรแกรมแมชชีนเลิร์นนิงที่ซับซ้อนสามารถจำแนกดอกไม้ตามรูปถ่ายได้ ความทะเยอทะยานของเราค่อนข้างเรียบง่าย เราจะจำแนกดอกไม้ไอริสตามความยาวและความกว้างของ กลีบเลี้ยง และ กลีบดอก
สกุล Iris มีประมาณ 300 สปีชีส์ แต่โปรแกรมของเราจะจำแนกประเภทต่อไปนี้เท่านั้น:
- ไอริส เซโตซ่า
- Iris virginica
- ไอริส versicolor
 |
| รูปที่ 1 Iris setosa (โดย Radomil , CC BY-SA 3.0 ), Iris versicolor , (โดย Dlanglois , CC BY-SA 3.0) และ Iris virginica (โดย Frank Mayfield , CC BY-SA 2.0) |
โชคดีที่มีคนสร้าง ชุดข้อมูลดอกไอริส 120 ดอก พร้อมการวัดกลีบเลี้ยงและกลีบดอกแล้ว นี่คือชุดข้อมูลคลาสสิกที่เป็นที่นิยมสำหรับปัญหาการจำแนกประเภทการเรียนรู้ของเครื่องสำหรับผู้เริ่มต้น
นำเข้าและแยกวิเคราะห์ชุดข้อมูลการฝึกอบรม
ดาวน์โหลดไฟล์ชุดข้อมูลและแปลงเป็นโครงสร้างที่โปรแกรม Python นี้สามารถใช้ได้
ดาวน์โหลดชุดข้อมูล
ดาวน์โหลดไฟล์ชุดข้อมูลการฝึกโดยใช้ฟังก์ชัน tf.keras.utils.get_file ส่งคืนเส้นทางไฟล์ของไฟล์ที่ดาวน์โหลด:
train_dataset_url = "https://storage.googleapis.com/download.tensorflow.org/data/iris_training.csv"
train_dataset_fp = tf.keras.utils.get_file(fname=os.path.basename(train_dataset_url),
origin=train_dataset_url)
print("Local copy of the dataset file: {}".format(train_dataset_fp))
Local copy of the dataset file: /home/kbuilder/.keras/datasets/iris_training.csv
ตรวจสอบข้อมูล
ชุดข้อมูลนี้ iris_training.csv เป็นไฟล์ข้อความธรรมดาที่จัดเก็บข้อมูลแบบตารางซึ่งจัดรูปแบบเป็นค่าที่คั่นด้วยเครื่องหมายจุลภาค (CSV) ใช้คำสั่ง head -n5 เพื่อดูห้ารายการแรก:
head -n5 {train_dataset_fp}
120,4,setosa,versicolor,virginica 6.4,2.8,5.6,2.2,2 5.0,2.3,3.3,1.0,1 4.9,2.5,4.5,1.7,2 4.9,3.1,1.5,0.1,0
จากมุมมองของชุดข้อมูลนี้ ให้สังเกตสิ่งต่อไปนี้:
- บรรทัดแรกคือส่วนหัวที่มีข้อมูลเกี่ยวกับชุดข้อมูล:
- มีตัวอย่างทั้งหมด 120 ตัวอย่าง แต่ละตัวอย่างมีสี่คุณลักษณะและหนึ่งในสามชื่อป้ายกำกับที่เป็นไปได้
- แถวที่ตามมาคือบันทึกข้อมูล หนึ่ง ตัวอย่าง ต่อบรรทัด โดยที่:
ลองเขียนมันออกมาเป็นรหัส:
# column order in CSV file
column_names = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']
feature_names = column_names[:-1]
label_name = column_names[-1]
print("Features: {}".format(feature_names))
print("Label: {}".format(label_name))
Features: ['sepal_length', 'sepal_width', 'petal_length', 'petal_width'] Label: species
แต่ละป้ายกำกับเชื่อมโยงกับชื่อสตริง (เช่น "setosa") แต่การเรียนรู้ของเครื่องมักอาศัยค่าตัวเลข หมายเลขฉลากถูกแมปกับการแสดงชื่อ เช่น:
-
0: ไอริส เซโตซ่า -
1: ไอริส versicolor -
2: Iris virginica
สำหรับข้อมูลเพิ่มเติมเกี่ยวกับคุณลักษณะและป้ายกำกับ โปรดดู ส่วนคำศัพท์ ML ของ Machine Learning Crash Course
class_names = ['Iris setosa', 'Iris versicolor', 'Iris virginica']
สร้าง tf.data.Dataset
Dataset API ของ TensorFlow จัดการกรณีทั่วไปจำนวนมากสำหรับการโหลดข้อมูลลงในแบบจำลอง นี่คือ API ระดับสูงสำหรับการอ่านข้อมูลและแปลงเป็นรูปแบบที่ใช้สำหรับการฝึกอบรม
เนื่องจากชุดข้อมูลเป็นไฟล์ข้อความรูปแบบ CSV ให้ใช้ฟังก์ชัน tf.data.experimental.make_csv_dataset เพื่อแยกวิเคราะห์ข้อมูลให้อยู่ในรูปแบบที่เหมาะสม เนื่องจากฟังก์ชันนี้สร้างข้อมูลสำหรับโมเดลการฝึก พฤติกรรมเริ่มต้นคือการสับเปลี่ยนข้อมูล ( shuffle=True, shuffle_buffer_size=10000 ) และทำซ้ำชุดข้อมูลตลอดไป ( num_epochs=None ) เรายังตั้งค่าพารามิเตอร์ batch_size :
batch_size = 32
train_dataset = tf.data.experimental.make_csv_dataset(
train_dataset_fp,
batch_size,
column_names=column_names,
label_name=label_name,
num_epochs=1)
ฟังก์ชัน make_csv_dataset จะคืนค่า tf.data.Dataset ของคู่ (features, label) โดยที่ features คือพจนานุกรม: {'feature_name': value}
ออบเจ็กต์ Dataset เหล่านี้สามารถทำซ้ำได้ ลองดูที่ชุดของคุณสมบัติ:
features, labels = next(iter(train_dataset))
print(features)
OrderedDict([('sepal_length', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([5. , 7.4, 6. , 7.2, 5.9, 5.8, 5. , 5. , 7.7, 5.7, 6.3, 5.8, 5. ,
4.8, 6.6, 6.3, 5.4, 6.9, 4.8, 6.6, 5.8, 7.7, 6.7, 7.6, 5.5, 6.4,
5.6, 6.4, 4.4, 4.5, 6.5, 6.3], dtype=float32)>), ('sepal_width', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([3.5, 2.8, 2.7, 3.2, 3. , 2.6, 2. , 3.4, 3. , 2.8, 2.3, 2.7, 3.6,
3.1, 2.9, 3.3, 3. , 3.1, 3. , 3. , 4. , 2.6, 3. , 3. , 2.4, 2.7,
2.7, 2.8, 3. , 2.3, 2.8, 2.5], dtype=float32)>), ('petal_length', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([1.6, 6.1, 5.1, 6. , 5.1, 4. , 3.5, 1.6, 6.1, 4.5, 4.4, 5.1, 1.4,
1.6, 4.6, 4.7, 4.5, 5.1, 1.4, 4.4, 1.2, 6.9, 5. , 6.6, 3.7, 5.3,
4.2, 5.6, 1.3, 1.3, 4.6, 5. ], dtype=float32)>), ('petal_width', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([0.6, 1.9, 1.6, 1.8, 1.8, 1.2, 1. , 0.4, 2.3, 1.3, 1.3, 1.9, 0.2,
0.2, 1.3, 1.6, 1.5, 2.3, 0.3, 1.4, 0.2, 2.3, 1.7, 2.1, 1. , 1.9,
1.3, 2.1, 0.2, 0.3, 1.5, 1.9], dtype=float32)>)])
สังเกตว่าคุณลักษณะที่ชอบถูกจัดกลุ่มเข้าด้วยกันหรือเป็น กลุ่ม ฟิลด์ของแถวตัวอย่างแต่ละแถวจะถูกผนวกเข้ากับอาร์เรย์คุณลักษณะที่เกี่ยวข้อง เปลี่ยน batch_size เพื่อกำหนดจำนวนตัวอย่างที่เก็บไว้ในอาร์เรย์คุณลักษณะเหล่านี้
คุณสามารถเริ่มเห็นบางคลัสเตอร์โดยพล็อตคุณลักษณะบางอย่างจากชุดงาน:
plt.scatter(features['petal_length'],
features['sepal_length'],
c=labels,
cmap='viridis')
plt.xlabel("Petal length")
plt.ylabel("Sepal length")
plt.show()
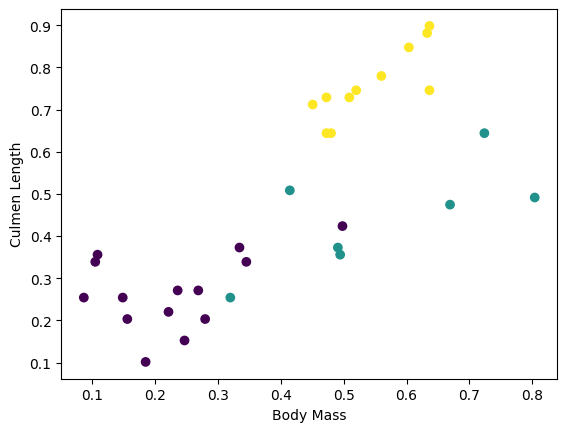
เพื่อทำให้ขั้นตอนการสร้างแบบจำลองง่ายขึ้น ให้สร้างฟังก์ชันเพื่อบรรจุพจนานุกรมคุณสมบัติใหม่ให้เป็นอาร์เรย์เดียวที่มีรูปร่าง: (batch_size, num_features)
ฟังก์ชันนี้ใช้เมธอด tf.stack ซึ่งรับค่าจากรายการเทนเซอร์ และสร้างเมตริกซ์รวมที่มิติที่ระบุ:
def pack_features_vector(features, labels):
"""Pack the features into a single array."""
features = tf.stack(list(features.values()), axis=1)
return features, labels
จากนั้นใช้ tf.data.Dataset#map เพื่อแพ็ค features ของแต่ละคู่ (features,label) ลงในชุดข้อมูลการฝึก:
train_dataset = train_dataset.map(pack_features_vector)
ตอนนี้องค์ประกอบคุณสมบัติของชุดข้อมูลเป็นอาร์เรย์ที่มีรูปร่าง (batch_size, num_features) Dataset ลองดูตัวอย่างสองสามตัวอย่างแรก:
features, labels = next(iter(train_dataset))
print(features[:5])
tf.Tensor( [[4.9 3. 1.4 0.2] [6.1 3. 4.9 1.8] [6.1 2.6 5.6 1.4] [6.9 3.2 5.7 2.3] [6.7 3.1 4.4 1.4]], shape=(5, 4), dtype=float32)
เลือกประเภทรุ่น
ทำไมต้องรุ่น?
โมเดล คือความสัมพันธ์ระหว่างคุณลักษณะและป้ายกำกับ สำหรับปัญหาการจำแนกประเภทม่านตา แบบจำลองกำหนดความสัมพันธ์ระหว่างการวัดกลีบเลี้ยงและกลีบดอกกับชนิดของม่านตาที่คาดการณ์ไว้ โมเดลอย่างง่ายบางตัวสามารถอธิบายได้ด้วยพีชคณิตสองสามบรรทัด แต่โมเดลการเรียนรู้ของเครื่องที่ซับซ้อนมีพารามิเตอร์จำนวนมากที่สรุปได้ยาก
คุณช่วยกำหนดความสัมพันธ์ระหว่างคุณสมบัติทั้งสี่กับสายพันธุ์ไอริส โดยไม่ต้อง ใช้แมชชีนเลิร์นนิงได้หรือไม่? นั่นคือ คุณสามารถใช้เทคนิคการเขียนโปรแกรมแบบดั้งเดิม (เช่น คำสั่งเงื่อนไขจำนวนมาก) เพื่อสร้างแบบจำลองได้หรือไม่ บางที—ถ้าคุณวิเคราะห์ชุดข้อมูลนานพอที่จะระบุความสัมพันธ์ระหว่างการวัดกลีบดอกและกลีบเลี้ยงกับสปีชีส์หนึ่งๆ และสิ่งนี้กลายเป็นเรื่องยาก—อาจเป็นไปไม่ได้—ในชุดข้อมูลที่ซับซ้อนยิ่งขึ้น แนวทางการเรียนรู้ของเครื่องที่ดีเป็น ตัวกำหนดรูปแบบสำหรับคุณ หากคุณป้อนตัวอย่างที่เป็นตัวแทนลงในประเภทโมเดลแมชชีนเลิร์นนิงที่เหมาะสม โปรแกรมจะค้นหาความสัมพันธ์สำหรับคุณ
เลือกรุ่น
เราต้องเลือกชนิดของแบบจำลองที่จะฝึก มีหลายประเภทและการเลือกรุ่นที่ดีต้องอาศัยประสบการณ์ บทช่วยสอนนี้ใช้โครงข่ายประสาทเทียมเพื่อแก้ปัญหาการจำแนกประเภทม่านตา โครงข่ายประสาทเทียม สามารถค้นหาความสัมพันธ์ที่ซับซ้อนระหว่างคุณลักษณะและป้ายกำกับได้ เป็นกราฟที่มีโครงสร้างสูง ซึ่งจัดเป็น เลเยอร์ที่ซ่อนอยู่อย่างน้อยหนึ่งชั้น แต่ละชั้นที่ซ่อนอยู่ประกอบด้วยเซลล์ประสาทอย่างน้อยหนึ่ง เซลล์ โครงข่ายประสาทมีหลายประเภท และโปรแกรมนี้ใช้โครงข่ายประสาทเทียมแบบหนาแน่นหรือ เชื่อมต่ออย่างเต็มที่ : เซลล์ประสาทในชั้นเดียวจะได้รับการเชื่อมต่ออินพุตจาก ทุก เซลล์ประสาทในชั้นก่อนหน้า ตัวอย่างเช่น รูปที่ 2 แสดงโครงข่ายประสาทเทียมหนาแน่นซึ่งประกอบด้วยเลเยอร์อินพุต เลเยอร์ที่ซ่อนอยู่ 2 ชั้น และเลเยอร์เอาต์พุต:
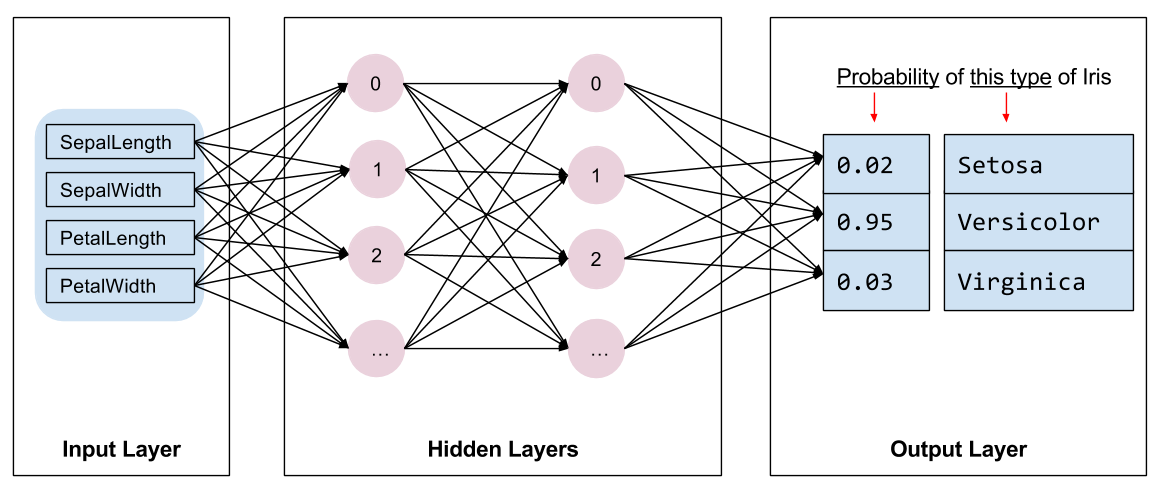 |
| รูปที่ 2 โครงข่ายประสาทเทียมที่มีคุณสมบัติ เลเยอร์ที่ซ่อนอยู่ และการคาดคะเน |
เมื่อแบบจำลองจากรูปที่ 2 ได้รับการฝึกฝนและป้อนตัวอย่างที่ไม่มีป้ายกำกับ จะให้ผลการคาดการณ์สามประการ: โอกาสที่ดอกไม้นี้จะเป็นสายพันธุ์ไอริสที่กำหนด การคาดคะเนนี้เรียกว่าการ อนุมาน สำหรับตัวอย่างนี้ ผลรวมของการทำนายผลลัพธ์คือ 1.0 ในรูปที่ 2 การคาดคะเนนี้แบ่งออกเป็น: 0.02 สำหรับ Iris setosa , 0.95 สำหรับ Iris versicolor และ 0.03 สำหรับ Iris virginica ซึ่งหมายความว่าแบบจำลองคาดการณ์—ด้วยความน่าจะเป็น 95%—ว่าตัวอย่างดอกไม้ที่ไม่มีป้ายกำกับคือ ไอริสหลากสี
สร้างแบบจำลองโดยใช้ Keras
TensorFlow tf.keras API เป็นวิธีที่แนะนำในการสร้างแบบจำลองและเลเยอร์ สิ่งนี้ทำให้ง่ายต่อการสร้างแบบจำลองและการทดลอง ในขณะที่ Keras จัดการกับความซับซ้อนของการเชื่อมต่อทุกอย่างเข้าด้วยกัน
โมเดล tf.keras.Sequential คือสแต็กเชิงเส้นของเลเยอร์ ตัวสร้างจะใช้รายการของอินสแตนซ์เลเยอร์ ในกรณีนี้คือ tf.keras.layers.Dense สองเลเยอร์โดยแต่ละโหนด 10 โหนด และเลเยอร์เอาต์พุตที่มี 3 โหนดที่แสดงถึงการคาดการณ์ป้ายกำกับของเรา พารามิเตอร์ input_shape ของเลเยอร์แรกสอดคล้องกับจำนวนคุณลักษณะจากชุดข้อมูล และจำเป็น:
model = tf.keras.Sequential([
tf.keras.layers.Dense(10, activation=tf.nn.relu, input_shape=(4,)), # input shape required
tf.keras.layers.Dense(10, activation=tf.nn.relu),
tf.keras.layers.Dense(3)
])
ฟังก์ชันการเปิดใช้งาน จะกำหนดรูปร่างเอาต์พุตของแต่ละโหนดในเลเยอร์ ความไม่เป็นเชิงเส้นเหล่านี้มีความสำคัญ—หากไม่มีพวกมัน โมเดลจะเทียบเท่ากับเลเยอร์เดียว มี tf.keras.activations มากมาย แต่ ReLU เป็นเรื่องปกติสำหรับเลเยอร์ที่ซ่อนอยู่
จำนวนชั้นและเซลล์ประสาทที่ซ่อนอยู่ในอุดมคตินั้นขึ้นอยู่กับปัญหาและชุดข้อมูล เช่นเดียวกับหลายๆ แง่มุมของแมชชีนเลิร์นนิง การเลือกรูปร่างที่ดีที่สุดของโครงข่ายประสาทเทียมนั้นต้องการการผสมผสานระหว่างความรู้และการทดลอง ตามหลักการทั่วไป การเพิ่มจำนวนเลเยอร์และเซลล์ประสาทที่ซ่อนอยู่มักจะสร้างแบบจำลองที่มีประสิทธิภาพมากขึ้น ซึ่งต้องใช้ข้อมูลมากขึ้นในการฝึกอย่างมีประสิทธิภาพ
การใช้โมเดล
มาดูกันสั้นๆ ว่าโมเดลนี้ทำอะไรกับฟีเจอร์ต่างๆ มากมาย:
predictions = model(features)
predictions[:5]
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[-4.0874639e+00, 1.5199981e-03, -9.9991310e-01],
[-5.3246369e+00, -1.8366380e-01, -1.3161827e+00],
[-5.1154275e+00, -2.8129923e-01, -1.3305402e+00],
[-6.0694785e+00, -2.1251860e-01, -1.5091233e+00],
[-5.6730523e+00, -1.4321266e-01, -1.4437559e+00]], dtype=float32)>
ตัวยึดตำแหน่ง22ที่นี่ แต่ละตัวอย่างส่งคืน logit สำหรับแต่ละคลาส
ในการแปลงบันทึกเหล่านี้เป็นความน่าจะเป็นสำหรับแต่ละคลาส ให้ใช้ฟังก์ชัน softmax :
tf.nn.softmax(predictions[:5])
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[0.01210616, 0.7224865 , 0.26540732],
[0.00440638, 0.75297093, 0.24262273],
[0.00585618, 0.7362918 , 0.25785193],
[0.00224076, 0.7835035 , 0.21425581],
[0.00310779, 0.7834839 , 0.21340834]], dtype=float32)>
การนำ tf.argmax ข้ามคลาสทำให้เราได้รับดัชนีคลาสที่คาดการณ์ไว้ แต่โมเดลยังไม่ได้รับการฝึกอบรม ดังนั้นจึงไม่ใช่การคาดการณ์ที่ดี:
print("Prediction: {}".format(tf.argmax(predictions, axis=1)))
print(" Labels: {}".format(labels))
Prediction: [1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]
Labels: [0 2 2 2 1 1 0 1 1 2 2 1 0 2 2 2 1 0 2 2 1 0 2 1 2 0 1 1 2 2 1 2]
ฝึกโมเดล
การฝึกอบรม เป็นขั้นตอนของการเรียนรู้ของเครื่องเมื่อโมเดลได้รับการปรับให้เหมาะสมทีละน้อย หรือโมเดล เรียนรู้ ชุดข้อมูล เป้าหมายคือการเรียนรู้โครงสร้างของชุดข้อมูลการฝึกอบรมให้เพียงพอเพื่อคาดการณ์ข้อมูลที่มองไม่เห็น หากคุณเรียนรู้ มากเกินไป เกี่ยวกับชุดข้อมูลการฝึก การคาดคะเนจะใช้ได้เฉพาะกับข้อมูลที่เห็นและไม่สามารถสรุปได้ ปัญหานี้เรียกว่า การใส่มากเกินไป — มันเหมือนกับการท่องจำคำตอบแทนที่จะเข้าใจวิธีแก้ปัญหา
ปัญหาการจำแนก Iris เป็นตัวอย่างหนึ่งของ การเรียนรู้ของเครื่องภายใต้การดูแล : โมเดลได้รับการฝึกฝนจากตัวอย่างที่มีป้ายกำกับ ใน แมชชีนเลิ ร์นนิงแบบไม่มีผู้ดูแล ตัวอย่างไม่มีป้ายกำกับ โดยปกติแล้ว โมเดลจะค้นหารูปแบบระหว่างคุณลักษณะต่างๆ แทน
กำหนดฟังก์ชันการสูญเสียและการไล่ระดับสี
ทั้งขั้นตอนการฝึกอบรมและการประเมินผลจำเป็นต้องคำนวณการ สูญเสีย ของแบบจำลอง นี่เป็นการวัดว่าการคาดคะเนของแบบจำลองนั้นมาจากป้ายกำกับที่ต้องการมากน้อยเพียงใด กล่าวคือ แบบจำลองมีประสิทธิภาพการทำงานแย่เพียงใด เราต้องการย่อหรือเพิ่มประสิทธิภาพค่านี้
โมเดลของเราจะคำนวณการสูญเสียโดยใช้ฟังก์ชัน tf.keras.losses.SparseCategoricalCrossentropy ซึ่งใช้การคาดคะเนความน่าจะเป็นของคลาสของโมเดลและป้ายกำกับที่ต้องการ และคืนค่าการสูญเสียเฉลี่ยจากตัวอย่าง
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
def loss(model, x, y, training):
# training=training is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
y_ = model(x, training=training)
return loss_object(y_true=y, y_pred=y_)
l = loss(model, features, labels, training=False)
print("Loss test: {}".format(l))
Loss test: 1.6059828996658325
ใช้บริบท tf.GradientTape เพื่อคำนวณการ ไล่ระดับสี ที่ใช้ในการปรับโมเดลของคุณให้เหมาะสม:
def grad(model, inputs, targets):
with tf.GradientTape() as tape:
loss_value = loss(model, inputs, targets, training=True)
return loss_value, tape.gradient(loss_value, model.trainable_variables)
สร้างเครื่องมือเพิ่มประสิทธิภาพ
เครื่องมือเพิ่มประสิทธิภาพ ใช้การไล่ระดับสีที่คำนวณกับตัวแปรของแบบจำลองเพื่อลดฟังก์ชัน loss คุณสามารถนึกถึงฟังก์ชันการสูญเสียเป็นพื้นผิวโค้ง (ดูรูปที่ 3) และเราต้องการหาจุดต่ำสุดโดยเดินไปรอบๆ ความลาดชันชี้ไปในทิศทางของการขึ้นเขาที่ชันที่สุด ดังนั้นเราจะเดินทางตรงกันข้ามและเคลื่อนลงเนิน โดยการคำนวณความสูญเสียและการไล่ระดับสีซ้ำๆ สำหรับแต่ละชุดงาน เราจะปรับแบบจำลองระหว่างการฝึก โมเดลจะค่อยๆ หาส่วนผสมที่ดีที่สุดของตุ้มน้ำหนักและอคติเพื่อลดการสูญเสีย และยิ่งสูญเสียน้อยเท่าไร การคาดการณ์ของแบบจำลองก็จะยิ่งดีขึ้นเท่านั้น
 |
| รูปที่ 3 อัลกอริธึมการเพิ่มประสิทธิภาพแสดงภาพเมื่อเวลาผ่านไปในพื้นที่ 3 มิติ (ที่มา: Stanford class CS231n , MIT License, เครดิตรูปภาพ: Alec Radford ) |
TensorFlow มีอัลกอริธึมการเพิ่มประสิทธิภาพมากมายสำหรับการฝึกอบรม โมเดลนี้ใช้ tf.keras.optimizers.SGD ที่ใช้อัลกอริทึมการ ไล่ระดับสีสุ่ม (SGD) learning_rate กำหนดขนาดขั้นตอนที่จะใช้สำหรับการวนซ้ำแต่ละครั้งจากเนินเขา นี่คือ ไฮเปอร์พารามิเตอร์ ที่คุณมักจะปรับเพื่อให้ได้ผลลัพธ์ที่ดีขึ้น
มาตั้งค่าเครื่องมือเพิ่มประสิทธิภาพกัน:
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
เราจะใช้ข้อมูลนี้ในการคำนวณขั้นตอนการเพิ่มประสิทธิภาพขั้นตอนเดียว:
loss_value, grads = grad(model, features, labels)
print("Step: {}, Initial Loss: {}".format(optimizer.iterations.numpy(),
loss_value.numpy()))
optimizer.apply_gradients(zip(grads, model.trainable_variables))
print("Step: {}, Loss: {}".format(optimizer.iterations.numpy(),
loss(model, features, labels, training=True).numpy()))
Step: 0, Initial Loss: 1.6059828996658325 Step: 1, Loss: 1.3759253025054932ตัวยึดตำแหน่ง33
วงการฝึก
เมื่อทุกชิ้นส่วนเข้าที่ โมเดลก็พร้อมสำหรับการฝึก! วงจรการฝึกจะดึงตัวอย่างชุดข้อมูลเข้าสู่โมเดลเพื่อช่วยให้คาดการณ์ได้ดีขึ้น บล็อกรหัสต่อไปนี้ตั้งค่าขั้นตอนการฝึกอบรมเหล่านี้:
- ทำซ้ำแต่ละ ยุค ยุคคือหนึ่งผ่านชุดข้อมูล
- ในช่วงเวลาหนึ่ง ให้ทำซ้ำแต่ละตัวอย่างใน
Datasetการฝึกอบรมซึ่งใช้ คุณลักษณะ (x) และ ป้ายกำกับ (y) - ใช้คุณลักษณะของตัวอย่าง ทำการคาดคะเนและเปรียบเทียบกับป้ายกำกับ วัดความไม่ถูกต้องของการทำนายและใช้เพื่อคำนวณการสูญเสียและการไล่ระดับสีของแบบจำลอง
- ใช้เครื่องมือ
optimizerเพื่ออัปเดตตัวแปรของโมเดล - ติดตามสถิติบางอย่างสำหรับการแสดงภาพ
- ทำซ้ำสำหรับแต่ละยุค
ตัวแปร num_epochs คือจำนวนครั้งที่วนรอบคอลเล็กชันชุดข้อมูล ตามสัญชาตญาณ การฝึกโมเดลอีกต่อไปไม่ได้รับประกันว่าโมเดลจะดีกว่า num_epochs เป็นไฮเปอร์ พารามิเตอร์ ที่คุณปรับแต่งได้ การเลือกหมายเลขที่เหมาะสมมักต้องใช้ทั้งประสบการณ์และการทดลอง:
## Note: Rerunning this cell uses the same model variables
# Keep results for plotting
train_loss_results = []
train_accuracy_results = []
num_epochs = 201
for epoch in range(num_epochs):
epoch_loss_avg = tf.keras.metrics.Mean()
epoch_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
# Training loop - using batches of 32
for x, y in train_dataset:
# Optimize the model
loss_value, grads = grad(model, x, y)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# Track progress
epoch_loss_avg.update_state(loss_value) # Add current batch loss
# Compare predicted label to actual label
# training=True is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
epoch_accuracy.update_state(y, model(x, training=True))
# End epoch
train_loss_results.append(epoch_loss_avg.result())
train_accuracy_results.append(epoch_accuracy.result())
if epoch % 50 == 0:
print("Epoch {:03d}: Loss: {:.3f}, Accuracy: {:.3%}".format(epoch,
epoch_loss_avg.result(),
epoch_accuracy.result()))
Epoch 000: Loss: 1.766, Accuracy: 43.333% Epoch 050: Loss: 0.579, Accuracy: 71.667% Epoch 100: Loss: 0.398, Accuracy: 82.500% Epoch 150: Loss: 0.307, Accuracy: 92.500% Epoch 200: Loss: 0.224, Accuracy: 95.833%
เห็นภาพฟังก์ชันการสูญเสียเมื่อเวลาผ่านไป
แม้ว่าการพิมพ์ความคืบหน้าในการฝึกโมเดลจะเป็นประโยชน์ แต่การดูความคืบหน้านี้มักจะเป็นประโยชน์ มากกว่า TensorBoard เป็นเครื่องมือสร้างภาพข้อมูลที่ดีที่มาพร้อมกับ TensorFlow แต่เราสามารถสร้างแผนภูมิพื้นฐานได้โดยใช้โมดูล matplotlib
การตีความแผนภูมิเหล่านี้ต้องใช้ประสบการณ์บางอย่าง แต่คุณต้องการเห็นการ สูญเสีย ลดลงและ ความแม่นยำ เพิ่มขึ้น:
fig, axes = plt.subplots(2, sharex=True, figsize=(12, 8))
fig.suptitle('Training Metrics')
axes[0].set_ylabel("Loss", fontsize=14)
axes[0].plot(train_loss_results)
axes[1].set_ylabel("Accuracy", fontsize=14)
axes[1].set_xlabel("Epoch", fontsize=14)
axes[1].plot(train_accuracy_results)
plt.show()
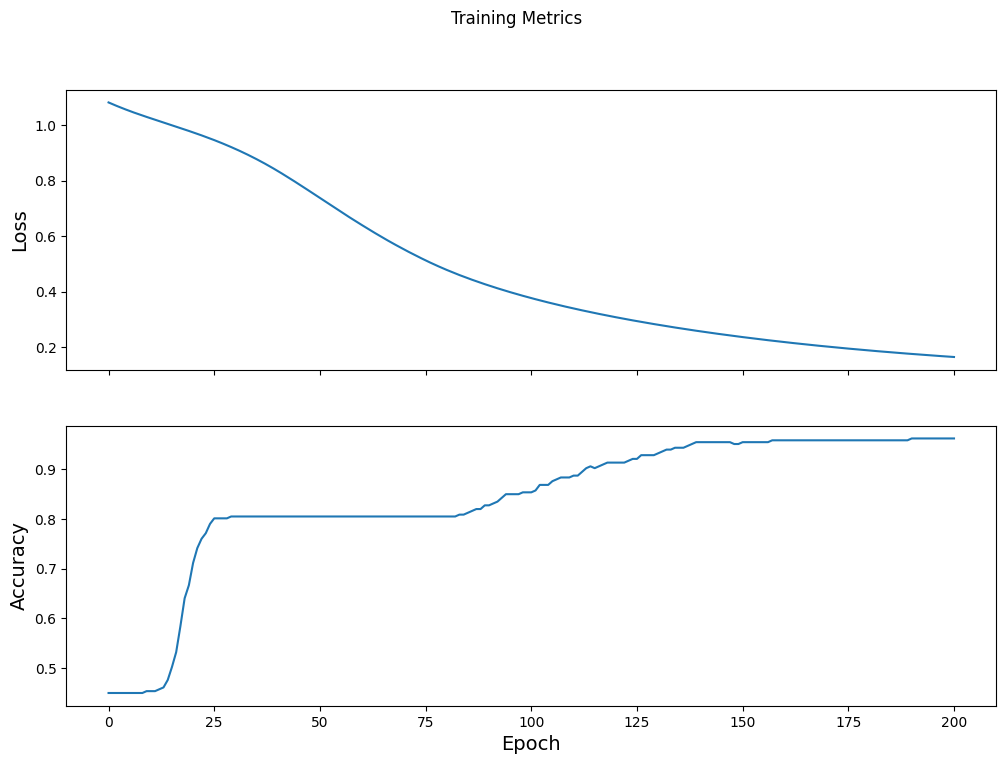
ประเมินประสิทธิภาพของตัวแบบ
เมื่อโมเดลได้รับการฝึกอบรมแล้ว เราก็สามารถรับสถิติเกี่ยวกับประสิทธิภาพของโมเดลได้
การ ประเมิน หมายถึงการกำหนดว่าตัวแบบสามารถคาดการณ์ได้อย่างมีประสิทธิภาพเพียงใด ในการพิจารณาประสิทธิภาพของแบบจำลองในการจำแนกประเภทม่านตา ให้ส่งการวัดกลีบเลี้ยงและกลีบดอกไปยังแบบจำลอง และขอให้แบบจำลองทำนายว่าม่านตาเป็นตัวแทนของชนิดใด จากนั้นเปรียบเทียบการคาดการณ์ของโมเดลกับป้ายกำกับจริง ตัวอย่างเช่น แบบจำลองที่เลือกสปีชีส์ที่ถูกต้องจากตัวอย่างอินพุตครึ่งหนึ่งมี ความแม่นยำ 0.5 รูปที่ 4 แสดงแบบจำลองที่มีประสิทธิภาพมากขึ้นเล็กน้อย โดยได้รับ 4 ใน 5 การคาดการณ์ถูกต้องที่ความแม่นยำ 80%:
| ตัวอย่างคุณสมบัติ | ฉลาก | การทำนายแบบจำลอง | |||
|---|---|---|---|---|---|
| 5.9 | 3.0 | 4.3 | 1.5 | 1 | 1 |
| 6.9 | 3.1 | 5.4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1.7 | 0.5 | 0 | 0 |
| 6.0 | 3.4 | 4.5 | 1.6 | 1 | 2 |
| 5.5 | 2.5 | 4.0 | 1.3 | 1 | 1 |
| รูปที่ 4 ลักษณนามม่านตาที่มีความแม่นยำ 80% | |||||
ตั้งค่าชุดข้อมูลทดสอบ
การประเมินแบบจำลองนั้นคล้ายกับการฝึกแบบจำลอง ความแตกต่างที่ใหญ่ที่สุดคือตัวอย่างที่มาจาก ชุดทดสอบ แยกต่างหากแทนที่จะเป็นชุดฝึก ในการประเมินประสิทธิภาพของแบบจำลองอย่างเป็นธรรม ตัวอย่างที่ใช้ในการประเมินแบบจำลองต้องแตกต่างจากตัวอย่างที่ใช้ในการฝึกอบรมแบบจำลอง
การตั้งค่าสำหรับ Dataset การทดสอบจะคล้ายกับการตั้งค่าสำหรับ Dataset การฝึกอบรม ดาวน์โหลดไฟล์ข้อความ CSV และแยกวิเคราะห์ค่านั้น จากนั้นให้สับเปลี่ยนเล็กน้อย:
test_url = "https://storage.googleapis.com/download.tensorflow.org/data/iris_test.csv"
test_fp = tf.keras.utils.get_file(fname=os.path.basename(test_url),
origin=test_url)
test_dataset = tf.data.experimental.make_csv_dataset(
test_fp,
batch_size,
column_names=column_names,
label_name='species',
num_epochs=1,
shuffle=False)
test_dataset = test_dataset.map(pack_features_vector)
ประเมินแบบจำลองในชุดข้อมูลทดสอบ
ต่างจากขั้นตอนการฝึกอบรม โมเดลจะประเมินข้อมูลการทดสอบเพียงช่วงเดียว เท่านั้น ในเซลล์โค้ดต่อไปนี้ เราทำซ้ำแต่ละตัวอย่างในชุดทดสอบและเปรียบเทียบการคาดการณ์ของโมเดลกับป้ายกำกับจริง ใช้สำหรับวัดความแม่นยำของแบบจำลองทั่วทั้งชุดทดสอบ:
test_accuracy = tf.keras.metrics.Accuracy()
for (x, y) in test_dataset:
# training=False is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
logits = model(x, training=False)
prediction = tf.argmax(logits, axis=1, output_type=tf.int32)
test_accuracy(prediction, y)
print("Test set accuracy: {:.3%}".format(test_accuracy.result()))
Test set accuracy: 96.667%
เราเห็นในชุดสุดท้าย เช่น โมเดลมักจะถูกต้อง:
tf.stack([y,prediction],axis=1)
<tf.Tensor: shape=(30, 2), dtype=int32, numpy=
array([[1, 1],
[2, 2],
[0, 0],
[1, 1],
[1, 1],
[1, 1],
[0, 0],
[2, 2],
[1, 1],
[2, 2],
[2, 2],
[0, 0],
[2, 2],
[1, 1],
[1, 1],
[0, 0],
[1, 1],
[0, 0],
[0, 0],
[2, 2],
[0, 0],
[1, 1],
[2, 2],
[1, 2],
[1, 1],
[1, 1],
[0, 0],
[1, 1],
[2, 2],
[1, 1]], dtype=int32)>
ตัวยึดตำแหน่ง42ใช้แบบจำลองที่ได้รับการฝึกฝนมาในการทำนาย
เราได้ฝึกแบบจำลองและ "พิสูจน์แล้ว" ว่าดี—แต่ยังไม่สมบูรณ์—ในการจำแนกสายพันธุ์ไอริส ตอนนี้ ลองใช้แบบจำลองที่ได้รับการฝึกมาเพื่อคาดการณ์ ตัวอย่างที่ไม่มีป้ายกำกับ นั่นคือ ในตัวอย่างที่มีคุณลักษณะแต่ไม่มีป้ายกำกับ
ในชีวิตจริง ตัวอย่างที่ไม่มีป้ายกำกับอาจมาจากแหล่งที่มาต่างๆ มากมาย รวมถึงแอป ไฟล์ CSV และฟีดข้อมูล สำหรับตอนนี้ เราจะนำเสนอตัวอย่างที่ไม่มีป้ายกำกับสามตัวอย่างด้วยตนเองเพื่อคาดการณ์ป้ายกำกับ จำได้ว่าหมายเลขป้ายกำกับถูกจับคู่กับการแสดงชื่อเป็น:
-
0: ไอริส เซโตซ่า -
1: ไอริส versicolor -
2: Iris virginica
predict_dataset = tf.convert_to_tensor([
[5.1, 3.3, 1.7, 0.5,],
[5.9, 3.0, 4.2, 1.5,],
[6.9, 3.1, 5.4, 2.1]
])
# training=False is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
predictions = model(predict_dataset, training=False)
for i, logits in enumerate(predictions):
class_idx = tf.argmax(logits).numpy()
p = tf.nn.softmax(logits)[class_idx]
name = class_names[class_idx]
print("Example {} prediction: {} ({:4.1f}%)".format(i, name, 100*p))
Example 0 prediction: Iris setosa (97.6%) Example 1 prediction: Iris versicolor (82.0%) Example 2 prediction: Iris virginica (56.4%)