
| | |  Visualizza l'origine su GitHub Visualizza l'origine su GitHub | |
Questa guida utilizza l'apprendimento automatico per classificare i fiori di Iris in base alla specie. Utilizza TensorFlow per:
- Costruisci un modello,
- Addestra questo modello su dati di esempio e
- Utilizzare il modello per fare previsioni su dati sconosciuti.
Programmazione TensorFlow
Questa guida utilizza questi concetti di TensorFlow di alto livello:
- Utilizzare l'ambiente di sviluppo dell'esecuzione desideroso predefinito di TensorFlow,
- Importa i dati con l' API dei set di dati,
- Crea modelli e livelli con l' API Keras di TensorFlow.
Questo tutorial è strutturato come molti programmi TensorFlow:
- Importa e analizza il set di dati.
- Seleziona il tipo di modello.
- Allena il modello.
- Valuta l'efficacia del modello.
- Usa il modello addestrato per fare previsioni.
Programma di installazione
Configura le importazioni
Importa TensorFlow e gli altri moduli Python richiesti. Per impostazione predefinita, TensorFlow utilizza l' esecuzione desiderosa per valutare immediatamente le operazioni, restituendo valori concreti invece di creare un grafico computazionale che viene eseguito in seguito. Se sei abituato a un REPL o alla console interattiva python , questo ti sembra familiare.
import os
import matplotlib.pyplot as plt
import tensorflow as tf
print("TensorFlow version: {}".format(tf.__version__))
print("Eager execution: {}".format(tf.executing_eagerly()))
TensorFlow version: 2.8.0-rc1 Eager execution: True
Il problema della classificazione dell'iride
Immagina di essere un botanico alla ricerca di un modo automatizzato per classificare ogni fiore di Iris che trovi. L'apprendimento automatico fornisce molti algoritmi per classificare statisticamente i fiori. Ad esempio, un sofisticato programma di apprendimento automatico potrebbe classificare i fiori in base a fotografie. Le nostre ambizioni sono più modeste: classificheremo i fiori di Iris in base alle misure di lunghezza e larghezza dei loro sepali e petali .
Il genere Iris comprende circa 300 specie, ma il nostro programma classificherà solo le tre seguenti:
- Iris setosa
- Iris virginica
- Iris versicolor
 |
| Figura 1. Iris setosa (di Radomil , CC BY-SA 3.0), Iris versicolor (di Dlanglois , CC BY-SA 3.0) e Iris virginica (di Frank Mayfield , CC BY-SA 2.0). |
Fortunatamente, qualcuno ha già creato un set di dati di 120 fiori di Iris con le misure del sepalo e del petalo. Questo è un set di dati classico che è popolare per i problemi di classificazione dell'apprendimento automatico per principianti.
Importa e analizza il set di dati di addestramento
Scarica il file del set di dati e convertilo in una struttura che può essere utilizzata da questo programma Python.
Scarica il dataset
Scarica il file del set di dati di addestramento utilizzando la funzione tf.keras.utils.get_file . Questo restituisce il percorso del file scaricato:
train_dataset_url = "https://storage.googleapis.com/download.tensorflow.org/data/iris_training.csv"
train_dataset_fp = tf.keras.utils.get_file(fname=os.path.basename(train_dataset_url),
origin=train_dataset_url)
print("Local copy of the dataset file: {}".format(train_dataset_fp))
Local copy of the dataset file: /home/kbuilder/.keras/datasets/iris_training.csv
Ispeziona i dati
Questo set di dati, iris_training.csv , è un file di testo normale che memorizza dati tabulari formattati come valori separati da virgole (CSV). Usa il comando head -n5 per dare un'occhiata alle prime cinque voci:
head -n5 {train_dataset_fp}
120,4,setosa,versicolor,virginica 6.4,2.8,5.6,2.2,2 5.0,2.3,3.3,1.0,1 4.9,2.5,4.5,1.7,2 4.9,3.1,1.5,0.1,0
Da questa visualizzazione del set di dati, notare quanto segue:
- La prima riga è un'intestazione contenente informazioni sul set di dati:
- Ci sono 120 esempi totali. Ogni esempio ha quattro caratteristiche e uno dei tre possibili nomi di etichetta.
- Le righe successive sono record di dati, un esempio per riga, dove:
- I primi quattro campi sono caratteristiche : queste sono le caratteristiche di un esempio. Qui, i campi contengono numeri float che rappresentano le misure dei fiori.
- L'ultima colonna è l' etichetta : questo è il valore che vogliamo prevedere. Per questo set di dati, è un valore intero di 0, 1 o 2 che corrisponde al nome di un fiore.
Scriviamolo nel codice:
# column order in CSV file
column_names = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']
feature_names = column_names[:-1]
label_name = column_names[-1]
print("Features: {}".format(feature_names))
print("Label: {}".format(label_name))
Features: ['sepal_length', 'sepal_width', 'petal_length', 'petal_width'] Label: species
Ogni etichetta è associata al nome della stringa (ad esempio, "setosa"), ma l'apprendimento automatico si basa in genere su valori numerici. I numeri di etichetta vengono mappati su una rappresentazione denominata, ad esempio:
-
0: Iris setosa -
1: Iris versicolor -
2: Iris virginica
Per ulteriori informazioni su funzionalità ed etichette, vedere la sezione sulla terminologia ML del corso di arresto anomalo di Machine Learning .
class_names = ['Iris setosa', 'Iris versicolor', 'Iris virginica']
Creare un tf.data.Dataset
L' API Dataset di TensorFlow gestisce molti casi comuni per il caricamento di dati in un modello. Questa è un'API di alto livello per leggere i dati e trasformarli in un modulo utilizzato per la formazione.
Poiché il set di dati è un file di testo in formato CSV, utilizzare la funzione tf.data.experimental.make_csv_dataset per analizzare i dati in un formato adatto. Poiché questa funzione genera dati per i modelli di addestramento, il comportamento predefinito consiste nel mescolare i dati ( shuffle=True, shuffle_buffer_size=10000 ) e ripetere il set di dati per sempre ( num_epochs=None ). Impostiamo anche il parametro batch_size :
batch_size = 32
train_dataset = tf.data.experimental.make_csv_dataset(
train_dataset_fp,
batch_size,
column_names=column_names,
label_name=label_name,
num_epochs=1)
La funzione make_csv_dataset restituisce un tf.data.Dataset di coppie (features, label) , dove features è un dizionario: {'feature_name': value}
Questi oggetti Dataset sono iterabili. Diamo un'occhiata a una serie di funzionalità:
features, labels = next(iter(train_dataset))
print(features)
OrderedDict([('sepal_length', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([5. , 7.4, 6. , 7.2, 5.9, 5.8, 5. , 5. , 7.7, 5.7, 6.3, 5.8, 5. ,
4.8, 6.6, 6.3, 5.4, 6.9, 4.8, 6.6, 5.8, 7.7, 6.7, 7.6, 5.5, 6.4,
5.6, 6.4, 4.4, 4.5, 6.5, 6.3], dtype=float32)>), ('sepal_width', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([3.5, 2.8, 2.7, 3.2, 3. , 2.6, 2. , 3.4, 3. , 2.8, 2.3, 2.7, 3.6,
3.1, 2.9, 3.3, 3. , 3.1, 3. , 3. , 4. , 2.6, 3. , 3. , 2.4, 2.7,
2.7, 2.8, 3. , 2.3, 2.8, 2.5], dtype=float32)>), ('petal_length', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([1.6, 6.1, 5.1, 6. , 5.1, 4. , 3.5, 1.6, 6.1, 4.5, 4.4, 5.1, 1.4,
1.6, 4.6, 4.7, 4.5, 5.1, 1.4, 4.4, 1.2, 6.9, 5. , 6.6, 3.7, 5.3,
4.2, 5.6, 1.3, 1.3, 4.6, 5. ], dtype=float32)>), ('petal_width', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([0.6, 1.9, 1.6, 1.8, 1.8, 1.2, 1. , 0.4, 2.3, 1.3, 1.3, 1.9, 0.2,
0.2, 1.3, 1.6, 1.5, 2.3, 0.3, 1.4, 0.2, 2.3, 1.7, 2.1, 1. , 1.9,
1.3, 2.1, 0.2, 0.3, 1.5, 1.9], dtype=float32)>)])
Si noti che le funzioni simili sono raggruppate o raggruppate in batch . I campi di ogni riga di esempio vengono aggiunti all'array di funzioni corrispondente. Modificare batch_size per impostare il numero di esempi archiviati in questi array di funzionalità.
Puoi iniziare a vedere alcuni cluster tracciando alcune funzionalità dal batch:
plt.scatter(features['petal_length'],
features['sepal_length'],
c=labels,
cmap='viridis')
plt.xlabel("Petal length")
plt.ylabel("Sepal length")
plt.show()
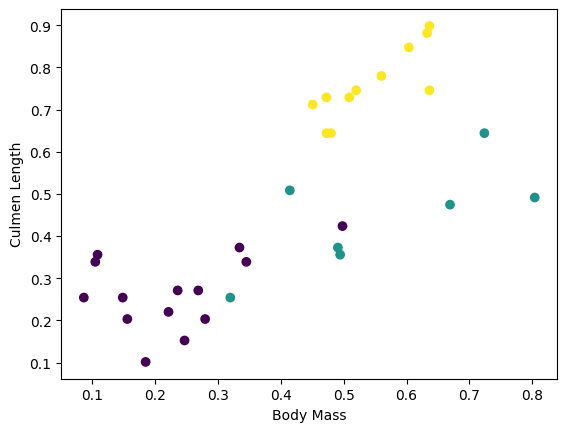
Per semplificare la fase di creazione del modello, creare una funzione per riconfezionare il dizionario delle caratteristiche in un unico array con forma: (batch_size, num_features) .
Questa funzione utilizza il metodo tf.stack che prende i valori da un elenco di tensori e crea un tensore combinato alla dimensione specificata:
def pack_features_vector(features, labels):
"""Pack the features into a single array."""
features = tf.stack(list(features.values()), axis=1)
return features, labels
Quindi usa il metodo tf.data.Dataset#map per impacchettare le features di ciascuna coppia (features,label) nel set di dati di addestramento:
train_dataset = train_dataset.map(pack_features_vector)
L'elemento delle funzionalità del set di dati ora sono matrici con forma ( Dataset (batch_size, num_features) . Vediamo i primi esempi:
features, labels = next(iter(train_dataset))
print(features[:5])
tf.Tensor( [[4.9 3. 1.4 0.2] [6.1 3. 4.9 1.8] [6.1 2.6 5.6 1.4] [6.9 3.2 5.7 2.3] [6.7 3.1 4.4 1.4]], shape=(5, 4), dtype=float32)
Seleziona il tipo di modello
Perché modellare?
Un modello è una relazione tra le caratteristiche e l'etichetta. Per il problema di classificazione dell'iride, il modello definisce la relazione tra le misurazioni del sepalo e del petalo e la specie prevista dell'iride. Alcuni modelli semplici possono essere descritti con poche righe di algebra, ma i modelli complessi di machine learning hanno un gran numero di parametri difficili da riassumere.
Potresti determinare la relazione tra le quattro caratteristiche e la specie Iris senza utilizzare l'apprendimento automatico? Cioè, potresti usare le tecniche di programmazione tradizionali (ad esempio, molte istruzioni condizionali) per creare un modello? Forse, se hai analizzato il set di dati abbastanza a lungo da determinare le relazioni tra le misurazioni dei petali e dei sepali in una specie particolare. E questo diventa difficile, forse impossibile, su set di dati più complicati. Un buon approccio di apprendimento automatico determina il modello per te . Se inserisci un numero sufficiente di esempi rappresentativi nel giusto tipo di modello di apprendimento automatico, il programma scoprirà le relazioni per te.
Seleziona il modello
Dobbiamo selezionare il tipo di modello da addestrare. Esistono molti tipi di modelli e sceglierne uno buono richiede esperienza. Questo tutorial utilizza una rete neurale per risolvere il problema di classificazione dell'iride. Le reti neurali possono trovare relazioni complesse tra le caratteristiche e l'etichetta. È un grafico altamente strutturato, organizzato in uno o più livelli nascosti . Ogni strato nascosto è costituito da uno o più neuroni . Esistono diverse categorie di reti neurali e questo programma utilizza una rete neurale densa o completamente connessa : i neuroni in uno strato ricevono connessioni di input da ogni neurone nello strato precedente. Ad esempio, la Figura 2 illustra una fitta rete neurale costituita da un livello di input, due livelli nascosti e un livello di output:
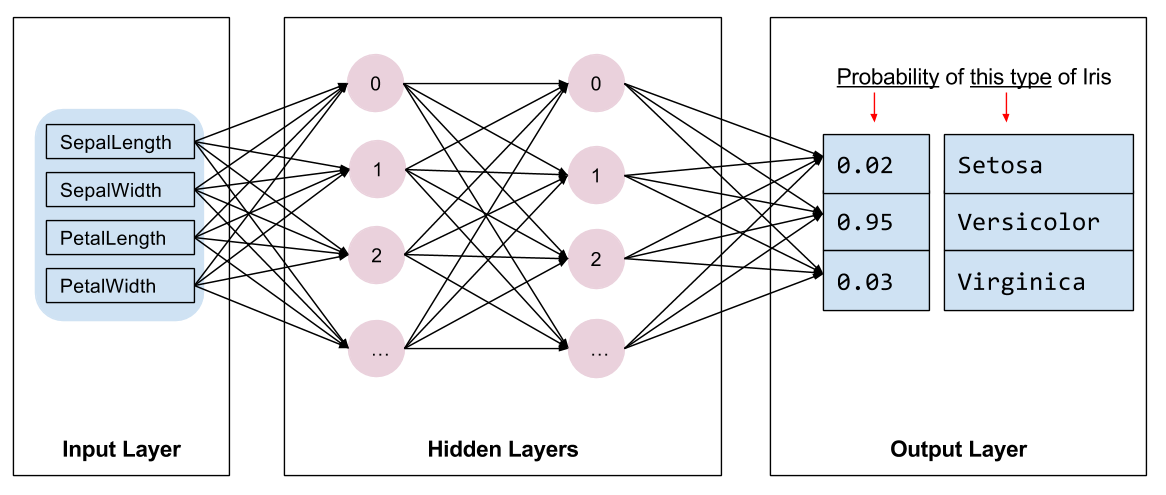 |
| Figura 2. Una rete neurale con funzionalità, livelli nascosti e previsioni. |
Quando il modello della Figura 2 viene addestrato e alimentato con un esempio senza etichetta, fornisce tre previsioni: la probabilità che questo fiore sia la specie di Iris indicata. Questa previsione è chiamata inferenza . Per questo esempio, la somma delle previsioni di output è 1,0. Nella Figura 2, questa previsione è suddivisa come: 0.02 per Iris setosa , 0.95 per Iris versicolor e 0.03 per Iris virginica . Ciò significa che il modello prevede, con una probabilità del 95%, che un fiore di esempio senza etichetta sia un Iris versicolor .
Crea un modello usando Keras
L'API TensorFlow tf.keras è il modo preferito per creare modelli e livelli. Ciò semplifica la creazione di modelli e gli esperimenti mentre Keras gestisce la complessità di collegare tutto insieme.
Il modello tf.keras.Sequential è una pila lineare di livelli. Il suo costruttore accetta un elenco di istanze di livello, in questo caso, due livelli tf.keras.layers.Dense con 10 nodi ciascuno e un livello di output con 3 nodi che rappresentano le nostre previsioni di etichetta. Il parametro input_shape del primo livello corrisponde al numero di funzioni del set di dati ed è obbligatorio:
model = tf.keras.Sequential([
tf.keras.layers.Dense(10, activation=tf.nn.relu, input_shape=(4,)), # input shape required
tf.keras.layers.Dense(10, activation=tf.nn.relu),
tf.keras.layers.Dense(3)
])
La funzione di attivazione determina la forma di output di ciascun nodo nel livello. Queste non linearità sono importanti: senza di esse il modello sarebbe equivalente a un singolo livello. Esistono molte tf.keras.activations , ma ReLU è comune per i livelli nascosti.
Il numero ideale di strati e neuroni nascosti dipende dal problema e dal set di dati. Come molti aspetti dell'apprendimento automatico, scegliere la forma migliore della rete neurale richiede un mix di conoscenza e sperimentazione. Come regola generale, l'aumento del numero di strati e neuroni nascosti crea in genere un modello più potente, che richiede più dati per allenarsi in modo efficace.
Usando il modello
Diamo una rapida occhiata a ciò che questo modello fa a una serie di funzionalità:
predictions = model(features)
predictions[:5]
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[-4.0874639e+00, 1.5199981e-03, -9.9991310e-01],
[-5.3246369e+00, -1.8366380e-01, -1.3161827e+00],
[-5.1154275e+00, -2.8129923e-01, -1.3305402e+00],
[-6.0694785e+00, -2.1251860e-01, -1.5091233e+00],
[-5.6730523e+00, -1.4321266e-01, -1.4437559e+00]], dtype=float32)>
Qui, ogni esempio restituisce un logit per ogni classe.
Per convertire questi logit in una probabilità per ciascuna classe, utilizzare la funzione softmax :
tf.nn.softmax(predictions[:5])
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[0.01210616, 0.7224865 , 0.26540732],
[0.00440638, 0.75297093, 0.24262273],
[0.00585618, 0.7362918 , 0.25785193],
[0.00224076, 0.7835035 , 0.21425581],
[0.00310779, 0.7834839 , 0.21340834]], dtype=float32)>
Prendendo tf.argmax tra le classi si ottiene l'indice di classe previsto. Ma il modello non è stato ancora addestrato, quindi queste non sono buone previsioni:
print("Prediction: {}".format(tf.argmax(predictions, axis=1)))
print(" Labels: {}".format(labels))
Prediction: [1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]
Labels: [0 2 2 2 1 1 0 1 1 2 2 1 0 2 2 2 1 0 2 2 1 0 2 1 2 0 1 1 2 2 1 2]
Allena il modello
La formazione è la fase dell'apprendimento automatico in cui il modello viene gradualmente ottimizzato o il modello apprende il set di dati. L'obiettivo è imparare abbastanza sulla struttura del set di dati di addestramento per fare previsioni sui dati invisibili. Se impari troppo sul set di dati di addestramento, le previsioni funzionano solo per i dati che ha visto e non saranno generalizzabili. Questo problema è chiamato overfitting : è come memorizzare le risposte invece di capire come risolvere un problema.
Il problema di classificazione di Iris è un esempio di apprendimento automatico supervisionato : il modello viene addestrato da esempi che contengono etichette. Nell'apprendimento automatico non supervisionato , gli esempi non contengono etichette. Al contrario, il modello in genere trova modelli tra le funzionalità.
Definire la funzione di perdita e gradiente
Sia la fase di formazione che quella di valutazione devono calcolare la perdita del modello. Questo misura quanto le previsioni di un modello si discostano dall'etichetta desiderata, in altre parole, quanto male sta funzionando il modello. Vogliamo ridurre al minimo o ottimizzare questo valore.
Il nostro modello calcolerà la sua perdita utilizzando la funzione tf.keras.losses.SparseCategoricalCrossentropy che prende le previsioni di probabilità della classe del modello e l'etichetta desiderata e restituisce la perdita media attraverso gli esempi.
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
def loss(model, x, y, training):
# training=training is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
y_ = model(x, training=training)
return loss_object(y_true=y, y_pred=y_)
l = loss(model, features, labels, training=False)
print("Loss test: {}".format(l))
Loss test: 1.6059828996658325
Usa il contesto tf.GradientTape per calcolare i gradienti utilizzati per ottimizzare il tuo modello:
def grad(model, inputs, targets):
with tf.GradientTape() as tape:
loss_value = loss(model, inputs, targets, training=True)
return loss_value, tape.gradient(loss_value, model.trainable_variables)
Crea un ottimizzatore
Un ottimizzatore applica i gradienti calcolati alle variabili del modello per ridurre al minimo la funzione di loss . Puoi pensare alla funzione di perdita come a una superficie curva (vedi Figura 3) e vogliamo trovare il suo punto più basso camminando. Le pendenze puntano nella direzione della salita più ripida, quindi viaggeremo nella direzione opposta e ci sposteremo giù per la collina. Calcolando in modo iterativo la perdita e il gradiente per ogni batch, regoleremo il modello durante l'allenamento. A poco a poco, il modello troverà la migliore combinazione di pesi e bias per ridurre al minimo la perdita. E minore è la perdita, migliori sono le previsioni del modello.
 |
| Figura 3. Algoritmi di ottimizzazione visualizzati nel tempo nello spazio 3D. (Fonte: Stanford classe CS231n , licenza MIT, credito immagine: Alec Radford ) |
TensorFlow ha molti algoritmi di ottimizzazione disponibili per l'allenamento. Questo modello utilizza tf.keras.optimizers.SGD che implementa l'algoritmo di discesa del gradiente stocastico (SGD). learning_rate imposta la dimensione del passo da prendere per ogni iterazione in discesa. Questo è un iperparametro che regolerai comunemente per ottenere risultati migliori.
Impostiamo l'ottimizzatore:
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
Utilizzeremo questo per calcolare un singolo passaggio di ottimizzazione:
loss_value, grads = grad(model, features, labels)
print("Step: {}, Initial Loss: {}".format(optimizer.iterations.numpy(),
loss_value.numpy()))
optimizer.apply_gradients(zip(grads, model.trainable_variables))
print("Step: {}, Loss: {}".format(optimizer.iterations.numpy(),
loss(model, features, labels, training=True).numpy()))
Step: 0, Initial Loss: 1.6059828996658325 Step: 1, Loss: 1.3759253025054932
Ciclo di formazione
Con tutti i pezzi a posto, il modello è pronto per l'allenamento! Un ciclo di addestramento alimenta gli esempi di set di dati nel modello per aiutarlo a fare previsioni migliori. Il blocco di codice seguente imposta questi passaggi di formazione:
- Iterare ogni epoca . Un'epoca è un passaggio attraverso il set di dati.
- Entro un'epoca, scorrere ogni esempio nel
Datasetdi dati di addestramento afferrandone le caratteristiche (x) e l' etichetta (y). - Usando le caratteristiche dell'esempio, fai una previsione e confrontala con l'etichetta. Misurare l'imprecisione della previsione e utilizzarla per calcolare la perdita e i gradienti del modello.
- Utilizzare un
optimizerper aggiornare le variabili del modello. - Tieni traccia di alcune statistiche per la visualizzazione.
- Ripetere per ogni epoca.
La variabile num_epochs è il numero di volte in cui eseguire il ciclo della raccolta del set di dati. Controintuitivamente, addestrare un modello più a lungo non garantisce un modello migliore. num_epochs è un iperparametro che puoi regolare. La scelta del numero giusto richiede solitamente sia esperienza che sperimentazione:
## Note: Rerunning this cell uses the same model variables
# Keep results for plotting
train_loss_results = []
train_accuracy_results = []
num_epochs = 201
for epoch in range(num_epochs):
epoch_loss_avg = tf.keras.metrics.Mean()
epoch_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
# Training loop - using batches of 32
for x, y in train_dataset:
# Optimize the model
loss_value, grads = grad(model, x, y)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# Track progress
epoch_loss_avg.update_state(loss_value) # Add current batch loss
# Compare predicted label to actual label
# training=True is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
epoch_accuracy.update_state(y, model(x, training=True))
# End epoch
train_loss_results.append(epoch_loss_avg.result())
train_accuracy_results.append(epoch_accuracy.result())
if epoch % 50 == 0:
print("Epoch {:03d}: Loss: {:.3f}, Accuracy: {:.3%}".format(epoch,
epoch_loss_avg.result(),
epoch_accuracy.result()))
Epoch 000: Loss: 1.766, Accuracy: 43.333% Epoch 050: Loss: 0.579, Accuracy: 71.667% Epoch 100: Loss: 0.398, Accuracy: 82.500% Epoch 150: Loss: 0.307, Accuracy: 92.500% Epoch 200: Loss: 0.224, Accuracy: 95.833%
Visualizza la funzione di perdita nel tempo
Sebbene sia utile stampare l'avanzamento dell'addestramento del modello, spesso è più utile vedere questo progresso. TensorBoard è un bel strumento di visualizzazione che è incluso in TensorFlow, ma possiamo creare grafici di base usando il modulo matplotlib .
L'interpretazione di questi grafici richiede un po' di esperienza, ma vuoi davvero vedere la perdita diminuire e la precisione aumentare:
fig, axes = plt.subplots(2, sharex=True, figsize=(12, 8))
fig.suptitle('Training Metrics')
axes[0].set_ylabel("Loss", fontsize=14)
axes[0].plot(train_loss_results)
axes[1].set_ylabel("Accuracy", fontsize=14)
axes[1].set_xlabel("Epoch", fontsize=14)
axes[1].plot(train_accuracy_results)
plt.show()
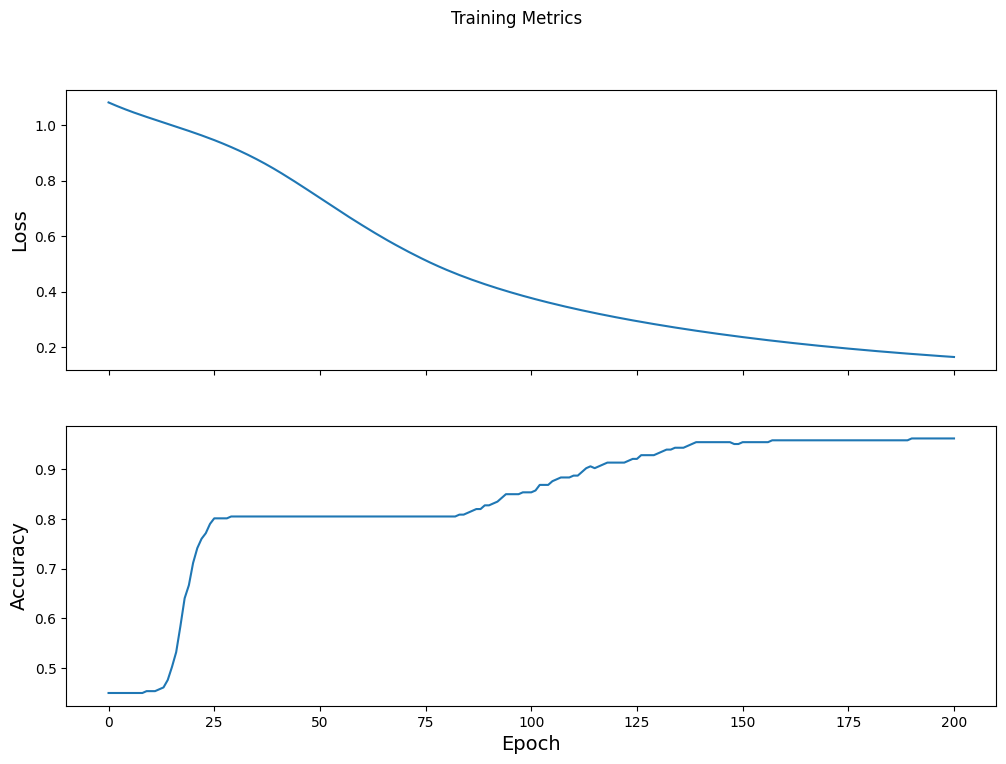
Valuta l'efficacia del modello
Ora che il modello è stato addestrato, possiamo ottenere alcune statistiche sulle sue prestazioni.
Valutare significa determinare l'efficacia con cui il modello effettua le previsioni. Per determinare l'efficacia del modello nella classificazione dell'iride, passare alcune misurazioni del sepalo e del petalo al modello e chiedere al modello di prevedere quali specie di iris rappresentano. Quindi confrontare le previsioni del modello con l'etichetta effettiva. Ad esempio, un modello che ha selezionato la specie corretta su metà degli esempi di input ha un'accuratezza di 0.5 . La figura 4 mostra un modello leggermente più efficace, che ottiene 4 previsioni su 5 corrette con una precisione dell'80%:
| Caratteristiche di esempio | Etichetta | Previsione del modello | |||
|---|---|---|---|---|---|
| 5.9 | 3.0 | 4.3 | 1.5 | 1 | 1 |
| 6.9 | 3.1 | 5.4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1.7 | 0,5 | 0 | 0 |
| 6.0 | 3.4 | 4.5 | 1.6 | 1 | 2 |
| 5.5 | 2.5 | 4.0 | 1.3 | 1 | 1 |
| Figura 4. Un classificatore di diaframma accurato all'80%. | |||||
Imposta il set di dati di prova
La valutazione del modello è simile all'addestramento del modello. La differenza più grande è che gli esempi provengono da un set di test separato piuttosto che dal set di addestramento. Per valutare equamente l'efficacia di un modello, gli esempi utilizzati per valutare un modello devono essere diversi dagli esempi utilizzati per addestrare il modello.
L'impostazione per il set di dati di test è simile Dataset per il set di dati di Dataset . Scarica il file di testo CSV e analizza quei valori, quindi mescolalo leggermente:
test_url = "https://storage.googleapis.com/download.tensorflow.org/data/iris_test.csv"
test_fp = tf.keras.utils.get_file(fname=os.path.basename(test_url),
origin=test_url)
test_dataset = tf.data.experimental.make_csv_dataset(
test_fp,
batch_size,
column_names=column_names,
label_name='species',
num_epochs=1,
shuffle=False)
test_dataset = test_dataset.map(pack_features_vector)
Valutare il modello sul set di dati di test
A differenza della fase di addestramento, il modello valuta solo una singola epoca dei dati del test. Nella cella di codice seguente, ripetiamo ogni esempio nel set di test e confrontiamo la previsione del modello con l'etichetta effettiva. Viene utilizzato per misurare l'accuratezza del modello nell'intero set di test:
test_accuracy = tf.keras.metrics.Accuracy()
for (x, y) in test_dataset:
# training=False is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
logits = model(x, training=False)
prediction = tf.argmax(logits, axis=1, output_type=tf.int32)
test_accuracy(prediction, y)
print("Test set accuracy: {:.3%}".format(test_accuracy.result()))
Test set accuracy: 96.667%
Possiamo vedere sull'ultimo lotto, ad esempio, il modello è solitamente corretto:
tf.stack([y,prediction],axis=1)
<tf.Tensor: shape=(30, 2), dtype=int32, numpy=
array([[1, 1],
[2, 2],
[0, 0],
[1, 1],
[1, 1],
[1, 1],
[0, 0],
[2, 2],
[1, 1],
[2, 2],
[2, 2],
[0, 0],
[2, 2],
[1, 1],
[1, 1],
[0, 0],
[1, 1],
[0, 0],
[0, 0],
[2, 2],
[0, 0],
[1, 1],
[2, 2],
[1, 2],
[1, 1],
[1, 1],
[0, 0],
[1, 1],
[2, 2],
[1, 1]], dtype=int32)>
Usa il modello addestrato per fare previsioni
Abbiamo addestrato un modello e "dimostrato" che è buono, ma non perfetto, nella classificazione delle specie di Iris. Ora usiamo il modello addestrato per fare alcune previsioni su esempi senza etichetta ; ovvero su esempi che contengono caratteristiche ma non un'etichetta.
Nella vita reale, gli esempi senza etichetta potrebbero provenire da molte fonti diverse tra cui app, file CSV e feed di dati. Per ora, forniremo manualmente tre esempi senza etichetta per prevedere le loro etichette. Ricordiamo, i numeri di etichetta sono mappati su una rappresentazione denominata come:
-
0: Iris setosa -
1: Iris versicolor -
2: Iris virginica
predict_dataset = tf.convert_to_tensor([
[5.1, 3.3, 1.7, 0.5,],
[5.9, 3.0, 4.2, 1.5,],
[6.9, 3.1, 5.4, 2.1]
])
# training=False is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
predictions = model(predict_dataset, training=False)
for i, logits in enumerate(predictions):
class_idx = tf.argmax(logits).numpy()
p = tf.nn.softmax(logits)[class_idx]
name = class_names[class_idx]
print("Example {} prediction: {} ({:4.1f}%)".format(i, name, 100*p))
Example 0 prediction: Iris setosa (97.6%) Example 1 prediction: Iris versicolor (82.0%) Example 2 prediction: Iris virginica (56.4%)