
| | |  ดูบน GitHub ดูบน GitHub | | |
YAMNet เป็นโครงข่าย Deep Neural ที่ได้รับการฝึกฝนมาล่วงหน้า ซึ่งสามารถทำนายเหตุการณ์ทางเสียงจาก 521 คลาส เช่น เสียงหัวเราะ เสียงเห่า หรือเสียงไซเรน
ในบทช่วยสอนนี้ คุณจะได้เรียนรู้วิธี:
- โหลดและใช้โมเดล YAMNet สำหรับการอนุมาน
- สร้างโมเดลใหม่โดยใช้การฝัง YAMNet เพื่อจำแนกเสียงแมวและสุนัข
- ประเมินและส่งออกแบบจำลองของคุณ
นำเข้า TensorFlow และไลบรารีอื่นๆ
เริ่มต้นด้วยการติดตั้ง TensorFlow I/O ซึ่งจะทำให้คุณสามารถโหลดไฟล์เสียงจากดิสก์ได้ง่ายขึ้น
pip install tensorflow_io
import os
from IPython import display
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_io as tfio
เกี่ยวกับ YAMNet
YAMNet เป็นโครงข่ายประสาทเทียมที่ผ่านการฝึกอบรมมาแล้วซึ่งใช้สถาปัตยกรรมการบิดแบบแยกส่วนเชิงลึกของ MobileNetV1 สามารถใช้รูปคลื่นเสียงเป็นอินพุต และทำการคาดการณ์อย่างอิสระสำหรับเหตุการณ์เสียง 521 รายการจากคลังข้อมูล AudioSet
ภายใน โมเดลจะแยก "เฟรม" ออกจากสัญญาณเสียงและประมวลผลแบทช์ของเฟรมเหล่านี้ โมเดลเวอร์ชันนี้ใช้เฟรมที่มีความยาว 0.96 วินาที และแยกหนึ่งเฟรมทุกๆ 0.48 วินาที
โมเดลยอมรับ 1-D float32 Tensor หรืออาร์เรย์ NumPy ที่มีรูปคลื่นของความยาวตามอำเภอใจ ซึ่งแสดงเป็นตัวอย่าง 16 kHz แบบช่องสัญญาณเดียว (โมโน) ในช่วง [-1.0, +1.0] บทช่วยสอนนี้มีโค้ดที่จะช่วยคุณแปลงไฟล์ WAV ให้อยู่ในรูปแบบที่รองรับ
โมเดลจะส่งคืนเอาต์พุต 3 รายการ รวมถึงคะแนนชั้นเรียน การฝัง (ซึ่งคุณจะใช้สำหรับการโอนย้ายการเรียนรู้) และ log mel spectrogram คุณสามารถดูรายละเอียดเพิ่มเติมได้ ที่นี่
การใช้งานเฉพาะของ YAMNet คือการเป็นตัวแยกคุณลักษณะระดับสูง - เอาต์พุตการฝัง 1,024 มิติ คุณจะใช้คุณสมบัติอินพุตของโมเดลฐาน (YAMNet) และป้อนลงในโมเดลที่ตื้นขึ้นของคุณซึ่งประกอบด้วยเลเยอร์ tf.keras.layers.Dense ที่ซ่อนอยู่หนึ่งเลเยอร์ จากนั้น คุณจะฝึกเครือข่ายโดยใช้ข้อมูลจำนวนเล็กน้อยสำหรับการจัดประเภทเสียง โดยไม่ ต้องใช้ข้อมูลที่มีป้ายกำกับจำนวนมากและฝึกอบรมตั้งแต่ต้นจนจบ (คล้ายกับการ ถ่ายโอนการเรียนรู้สำหรับการจัดประเภทรูปภาพด้วย TensorFlow Hub สำหรับข้อมูลเพิ่มเติม)
ขั้นแรก คุณจะทดสอบโมเดลและดูผลการจำแนกเสียง จากนั้นคุณจะสร้างไปป์ไลน์การประมวลผลข้อมูลล่วงหน้า
กำลังโหลด YAMNet จาก TensorFlow Hub
คุณจะใช้ YAMNet ที่ผ่านการฝึกอบรมล่วงหน้าจาก Tensorflow Hub เพื่อแยกการฝังออกจากไฟล์เสียง
การโหลดโมเดลจาก TensorFlow Hub นั้นตรงไปตรงมา: เลือกโมเดล คัดลอก URL และใช้ฟังก์ชัน load
yamnet_model_handle = 'https://tfhub.dev/google/yamnet/1'
yamnet_model = hub.load(yamnet_model_handle)
เมื่อโหลดโมเดลแล้ว คุณสามารถทำตาม บทช่วยสอนการใช้งานพื้นฐานของ YAMNet และดาวน์โหลดไฟล์ WAV ตัวอย่างเพื่อเรียกใช้การอนุมานได้
testing_wav_file_name = tf.keras.utils.get_file('miaow_16k.wav',
'https://storage.googleapis.com/audioset/miaow_16k.wav',
cache_dir='./',
cache_subdir='test_data')
print(testing_wav_file_name)
Downloading data from https://storage.googleapis.com/audioset/miaow_16k.wav 221184/215546 [==============================] - 0s 0us/step 229376/215546 [===============================] - 0s 0us/step ./test_data/miaow_16k.wav
คุณจะต้องมีฟังก์ชันในการโหลดไฟล์เสียง ซึ่งจะใช้ในภายหลังเมื่อทำงานกับข้อมูลการฝึก (เรียนรู้เพิ่มเติมเกี่ยวกับการอ่านไฟล์เสียงและป้ายกำกับใน การรู้จำเสียงอย่างง่าย
# Utility functions for loading audio files and making sure the sample rate is correct.
@tf.function
def load_wav_16k_mono(filename):
""" Load a WAV file, convert it to a float tensor, resample to 16 kHz single-channel audio. """
file_contents = tf.io.read_file(filename)
wav, sample_rate = tf.audio.decode_wav(
file_contents,
desired_channels=1)
wav = tf.squeeze(wav, axis=-1)
sample_rate = tf.cast(sample_rate, dtype=tf.int64)
wav = tfio.audio.resample(wav, rate_in=sample_rate, rate_out=16000)
return wav
testing_wav_data = load_wav_16k_mono(testing_wav_file_name)
_ = plt.plot(testing_wav_data)
# Play the audio file.
display.Audio(testing_wav_data,rate=16000)
2022-01-26 08:07:19.084427: W tensorflow_io/core/kernels/audio_video_mp3_kernels.cc:271] libmp3lame.so.0 or lame functions are not available WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample

โหลด class mapping
สิ่งสำคัญคือต้องโหลดชื่อคลาสที่ YAMNet สามารถจดจำได้ ไฟล์การแมปมีอยู่ที่ yamnet_model.class_map_path() ในรูปแบบ CSV
class_map_path = yamnet_model.class_map_path().numpy().decode('utf-8')
class_names =list(pd.read_csv(class_map_path)['display_name'])
for name in class_names[:20]:
print(name)
print('...')
Speech Child speech, kid speaking Conversation Narration, monologue Babbling Speech synthesizer Shout Bellow Whoop Yell Children shouting Screaming Whispering Laughter Baby laughter Giggle Snicker Belly laugh Chuckle, chortle Crying, sobbing ...
เรียกใช้การอนุมาน
YAMNet ให้คะแนนระดับเฟรม (เช่น 521 คะแนนสำหรับทุกเฟรม) เพื่อกำหนดการคาดการณ์ระดับคลิป สามารถรวมคะแนนต่อคลาสในเฟรมต่างๆ (เช่น ใช้ค่าเฉลี่ยหรือการรวมสูงสุด) ทำได้ด้านล่างโดย scores_np.mean(axis=0) สุดท้าย ในการหาชั้นเรียนที่มีคะแนนสูงสุดในระดับคลิป คุณใช้คะแนนรวมสูงสุด 521 คะแนน
scores, embeddings, spectrogram = yamnet_model(testing_wav_data)
class_scores = tf.reduce_mean(scores, axis=0)
top_class = tf.argmax(class_scores)
inferred_class = class_names[top_class]
print(f'The main sound is: {inferred_class}')
print(f'The embeddings shape: {embeddings.shape}')
The main sound is: Animal The embeddings shape: (13, 1024)
ชุดข้อมูล ESC-50
ชุดข้อมูล ESC-50 ( Piczak, 2015 ) เป็นคอลเล็กชันการบันทึกเสียงสิ่งแวดล้อมความยาว 5 วินาที 2,000 รายการ ชุดข้อมูลประกอบด้วย 50 คลาส โดยมี 40 ตัวอย่างต่อคลาส
ดาวน์โหลดชุดข้อมูลและแตกไฟล์
_ = tf.keras.utils.get_file('esc-50.zip',
'https://github.com/karoldvl/ESC-50/archive/master.zip',
cache_dir='./',
cache_subdir='datasets',
extract=True)
Downloading data from https://github.com/karoldvl/ESC-50/archive/master.zip 645103616/Unknown - 47s 0us/step
สำรวจข้อมูล
มีการระบุข้อมูลเมตาสำหรับแต่ละไฟล์ในไฟล์ csv ที่ ./datasets/ESC-50-master/meta/esc50.csv
และไฟล์เสียงทั้งหมดอยู่ใน . ./datasets/ESC-50-master/audio/
คุณจะสร้าง DataFrame แพนด้าด้วยการทำแผนที่และใช้สิ่งนั้นเพื่อให้มีมุมมองข้อมูลที่ชัดเจนยิ่งขึ้น
esc50_csv = './datasets/ESC-50-master/meta/esc50.csv'
base_data_path = './datasets/ESC-50-master/audio/'
pd_data = pd.read_csv(esc50_csv)
pd_data.head()
กรองข้อมูล
เมื่อข้อมูลถูกเก็บไว้ใน DataFrame แล้ว ให้ใช้การแปลงบางส่วน:
- กรองแถวและใช้เฉพาะคลาสที่เลือก -
dogandcatหากคุณต้องการใช้คลาสอื่นๆ คุณสามารถเลือกคลาสเหล่านี้ได้ - แก้ไขชื่อไฟล์ให้มีเส้นทางแบบเต็ม ซึ่งจะทำให้การโหลดง่ายขึ้นในภายหลัง
- เปลี่ยนเป้าหมายให้อยู่ในช่วงที่กำหนด ในตัวอย่างนี้
dogจะยังคงอยู่ที่0แต่catจะกลายเป็น1แทนที่จะเป็น5เดิม
my_classes = ['dog', 'cat']
map_class_to_id = {'dog':0, 'cat':1}
filtered_pd = pd_data[pd_data.category.isin(my_classes)]
class_id = filtered_pd['category'].apply(lambda name: map_class_to_id[name])
filtered_pd = filtered_pd.assign(target=class_id)
full_path = filtered_pd['filename'].apply(lambda row: os.path.join(base_data_path, row))
filtered_pd = filtered_pd.assign(filename=full_path)
filtered_pd.head(10)
โหลดไฟล์เสียงและรับการฝัง
ที่นี่ คุณจะใช้ load_wav_16k_mono และเตรียมข้อมูล WAV สำหรับโมเดล
เมื่อแยกการฝังจากข้อมูล WAV คุณจะได้รับอาร์เรย์ของรูปร่าง (N, 1024) โดยที่ N คือจำนวนเฟรมที่ YAMNet พบ (หนึ่งเฟรมต่อทุกๆ 0.48 วินาทีของเสียง)
โมเดลของคุณจะใช้แต่ละเฟรมเป็นอินพุตเดียว ดังนั้น คุณต้องสร้างคอลัมน์ใหม่ที่มีหนึ่งเฟรมต่อแถว คุณต้องขยายป้ายกำกับและคอลัมน์ fold เพื่อให้สะท้อนถึงแถวใหม่เหล่านี้อย่างเหมาะสม
คอลัมน์ fold ขยายจะคงค่าเดิมไว้ คุณไม่สามารถมิกซ์เฟรมได้ เนื่องจากเมื่อทำการแยก คุณอาจลงเอยด้วยส่วนของเสียงเดียวกันบนการแยกที่แตกต่างกัน ซึ่งจะทำให้ขั้นตอนการตรวจสอบและทดสอบของคุณมีประสิทธิภาพน้อยลง
filenames = filtered_pd['filename']
targets = filtered_pd['target']
folds = filtered_pd['fold']
main_ds = tf.data.Dataset.from_tensor_slices((filenames, targets, folds))
main_ds.element_spec
(TensorSpec(shape=(), dtype=tf.string, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
def load_wav_for_map(filename, label, fold):
return load_wav_16k_mono(filename), label, fold
main_ds = main_ds.map(load_wav_for_map)
main_ds.element_spec
WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample (TensorSpec(shape=<unknown>, dtype=tf.float32, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
# applies the embedding extraction model to a wav data
def extract_embedding(wav_data, label, fold):
''' run YAMNet to extract embedding from the wav data '''
scores, embeddings, spectrogram = yamnet_model(wav_data)
num_embeddings = tf.shape(embeddings)[0]
return (embeddings,
tf.repeat(label, num_embeddings),
tf.repeat(fold, num_embeddings))
# extract embedding
main_ds = main_ds.map(extract_embedding).unbatch()
main_ds.element_spec
(TensorSpec(shape=(1024,), dtype=tf.float32, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
แยกข้อมูล
คุณจะใช้คอลัมน์ fold เพื่อแยกชุดข้อมูลออกเป็นชุดฝึก การตรวจสอบความถูกต้อง และชุดทดสอบ
ESC-50 ถูกจัดเรียงเป็น fold ที่มีขนาดเท่ากันห้าเท่า เพื่อให้คลิปจากแหล่งต้นฉบับเดียวกันมักจะอยู่ใน fold เดียวกัน ดูข้อมูลเพิ่มเติมใน ESC: ชุดข้อมูลสำหรับกระดาษการจำแนกเสียงเพื่อสิ่งแวดล้อม
ขั้นตอนสุดท้ายคือการลบคอลัมน์การ fold ออกจากชุดข้อมูล เนื่องจากคุณจะไม่ใช้ระหว่างการฝึก
cached_ds = main_ds.cache()
train_ds = cached_ds.filter(lambda embedding, label, fold: fold < 4)
val_ds = cached_ds.filter(lambda embedding, label, fold: fold == 4)
test_ds = cached_ds.filter(lambda embedding, label, fold: fold == 5)
# remove the folds column now that it's not needed anymore
remove_fold_column = lambda embedding, label, fold: (embedding, label)
train_ds = train_ds.map(remove_fold_column)
val_ds = val_ds.map(remove_fold_column)
test_ds = test_ds.map(remove_fold_column)
train_ds = train_ds.cache().shuffle(1000).batch(32).prefetch(tf.data.AUTOTUNE)
val_ds = val_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
test_ds = test_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
สร้างแบบจำลองของคุณ
คุณทำงานส่วนใหญ่แล้ว! ถัดไป ให้กำหนดโมเดล Sequential ที่ง่ายมาก โดยมีเลเยอร์ที่ซ่อนอยู่ 1 เลเยอร์และเอาต์พุต 2 เอาต์พุตเพื่อจดจำแมวและสุนัขจากเสียง
my_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=(1024), dtype=tf.float32,
name='input_embedding'),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(len(my_classes))
], name='my_model')
my_model.summary()
Model: "my_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 512) 524800
dense_1 (Dense) (None, 2) 1026
=================================================================
Total params: 525,826
Trainable params: 525,826
Non-trainable params: 0
_________________________________________________________________
my_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer="adam",
metrics=['accuracy'])
callback = tf.keras.callbacks.EarlyStopping(monitor='loss',
patience=3,
restore_best_weights=True)
history = my_model.fit(train_ds,
epochs=20,
validation_data=val_ds,
callbacks=callback)
Epoch 1/20 15/15 [==============================] - 6s 49ms/step - loss: 0.7811 - accuracy: 0.8229 - val_loss: 0.4866 - val_accuracy: 0.9125 Epoch 2/20 15/15 [==============================] - 0s 18ms/step - loss: 0.3385 - accuracy: 0.8938 - val_loss: 0.2185 - val_accuracy: 0.8813 Epoch 3/20 15/15 [==============================] - 0s 18ms/step - loss: 0.3091 - accuracy: 0.9021 - val_loss: 0.4290 - val_accuracy: 0.8813 Epoch 4/20 15/15 [==============================] - 0s 18ms/step - loss: 0.5354 - accuracy: 0.9062 - val_loss: 0.2074 - val_accuracy: 0.9125 Epoch 5/20 15/15 [==============================] - 0s 18ms/step - loss: 0.4651 - accuracy: 0.9333 - val_loss: 0.6857 - val_accuracy: 0.8813 Epoch 6/20 15/15 [==============================] - 0s 18ms/step - loss: 0.2489 - accuracy: 0.9167 - val_loss: 0.3640 - val_accuracy: 0.8750 Epoch 7/20 15/15 [==============================] - 0s 17ms/step - loss: 0.2020 - accuracy: 0.9292 - val_loss: 0.2158 - val_accuracy: 0.9125 Epoch 8/20 15/15 [==============================] - 0s 16ms/step - loss: 0.4550 - accuracy: 0.9208 - val_loss: 0.9893 - val_accuracy: 0.8750 Epoch 9/20 15/15 [==============================] - 0s 17ms/step - loss: 0.3434 - accuracy: 0.9354 - val_loss: 0.2670 - val_accuracy: 0.8813 Epoch 10/20 15/15 [==============================] - 0s 17ms/step - loss: 0.2864 - accuracy: 0.9208 - val_loss: 0.5122 - val_accuracy: 0.8813
ลองใช้วิธีการ evaluate กับข้อมูลการทดสอบเพื่อให้แน่ใจว่าไม่มีการโอเวอร์โหลด
loss, accuracy = my_model.evaluate(test_ds)
print("Loss: ", loss)
print("Accuracy: ", accuracy)
5/5 [==============================] - 0s 9ms/step - loss: 0.2526 - accuracy: 0.9000 Loss: 0.25257644057273865 Accuracy: 0.8999999761581421
คุณทำได้!
ทดสอบโมเดลของคุณ
ถัดไป ลองใช้โมเดลของคุณในการฝังจากการทดสอบครั้งก่อนโดยใช้ YAMNet เท่านั้น
scores, embeddings, spectrogram = yamnet_model(testing_wav_data)
result = my_model(embeddings).numpy()
inferred_class = my_classes[result.mean(axis=0).argmax()]
print(f'The main sound is: {inferred_class}')
The main sound is: catตัวยึดตำแหน่ง32
บันทึกโมเดลที่สามารถนำไฟล์ WAV เป็นอินพุตได้โดยตรง
โมเดลของคุณใช้งานได้เมื่อคุณให้การฝังเป็นอินพุต
ในสถานการณ์จริง คุณจะต้องใช้ข้อมูลเสียงเป็นอินพุตโดยตรง
ในการทำเช่นนั้น คุณจะต้องรวม YAMNet กับโมเดลของคุณเป็นโมเดลเดียวที่คุณสามารถส่งออกไปยังแอปพลิเคชันอื่นได้
เพื่อให้ใช้ผลลัพธ์ของโมเดลได้ง่ายขึ้น เลเยอร์สุดท้ายจะเป็นการดำเนินการ reduce_mean เมื่อใช้โมเดลนี้สำหรับเสิร์ฟ (ซึ่งคุณจะได้เรียนรู้ในภายหลังในบทช่วยสอน) คุณจะต้องใช้ชื่อของเลเยอร์สุดท้าย หากคุณไม่ได้กำหนดไว้ TensorFlow จะกำหนดส่วนที่เพิ่มขึ้นโดยอัตโนมัติซึ่งทำให้ยากต่อการทดสอบ เนื่องจากจะมีการเปลี่ยนแปลงทุกครั้งที่คุณฝึกโมเดล เมื่อใช้การดำเนินการ TensorFlow แบบดิบ คุณไม่สามารถกำหนดชื่อให้กับการดำเนินการได้ ในการแก้ไขปัญหานี้ คุณจะต้องสร้างเลเยอร์ที่กำหนดเองซึ่งใช้ reduce_mean และเรียกมันว่า 'classifier'
class ReduceMeanLayer(tf.keras.layers.Layer):
def __init__(self, axis=0, **kwargs):
super(ReduceMeanLayer, self).__init__(**kwargs)
self.axis = axis
def call(self, input):
return tf.math.reduce_mean(input, axis=self.axis)
saved_model_path = './dogs_and_cats_yamnet'
input_segment = tf.keras.layers.Input(shape=(), dtype=tf.float32, name='audio')
embedding_extraction_layer = hub.KerasLayer(yamnet_model_handle,
trainable=False, name='yamnet')
_, embeddings_output, _ = embedding_extraction_layer(input_segment)
serving_outputs = my_model(embeddings_output)
serving_outputs = ReduceMeanLayer(axis=0, name='classifier')(serving_outputs)
serving_model = tf.keras.Model(input_segment, serving_outputs)
serving_model.save(saved_model_path, include_optimizer=False)
WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. 2022-01-26 08:08:33.807036: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: ./dogs_and_cats_yamnet/assets INFO:tensorflow:Assets written to: ./dogs_and_cats_yamnet/assets
tf.keras.utils.plot_model(serving_model)
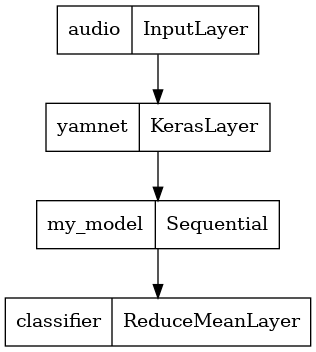
โหลดโมเดลที่บันทึกไว้เพื่อตรวจสอบว่าใช้งานได้ตามที่คาดไว้
reloaded_model = tf.saved_model.load(saved_model_path)
และสำหรับการทดสอบครั้งสุดท้าย: จากข้อมูลเสียง แบบจำลองของคุณให้ผลลัพธ์ที่ถูกต้องหรือไม่
reloaded_results = reloaded_model(testing_wav_data)
cat_or_dog = my_classes[tf.argmax(reloaded_results)]
print(f'The main sound is: {cat_or_dog}')
The main sound is: catตัวยึดตำแหน่ง39
หากคุณต้องการลองใช้โมเดลใหม่ในการตั้งค่าการแสดงผล คุณสามารถใช้ลายเซ็น "serving_default" ได้
serving_results = reloaded_model.signatures['serving_default'](testing_wav_data)
cat_or_dog = my_classes[tf.argmax(serving_results['classifier'])]
print(f'The main sound is: {cat_or_dog}')
The main sound is: catตัวยึดตำแหน่ง41
(ไม่บังคับ) การทดสอบเพิ่มเติมบางส่วน
โมเดลพร้อมแล้ว
ลองเปรียบเทียบกับ YAMNet ในชุดข้อมูลทดสอบ
test_pd = filtered_pd.loc[filtered_pd['fold'] == 5]
row = test_pd.sample(1)
filename = row['filename'].item()
print(filename)
waveform = load_wav_16k_mono(filename)
print(f'Waveform values: {waveform}')
_ = plt.plot(waveform)
display.Audio(waveform, rate=16000)
./datasets/ESC-50-master/audio/5-214759-A-5.wav WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample Waveform values: [ 3.2084468e-09 -7.7704687e-09 -1.2222010e-08 ... 2.2788899e-02 1.0315948e-02 -3.4766860e-02]ตัวยึดตำแหน่ง43
# Run the model, check the output.
scores, embeddings, spectrogram = yamnet_model(waveform)
class_scores = tf.reduce_mean(scores, axis=0)
top_class = tf.argmax(class_scores)
inferred_class = class_names[top_class]
top_score = class_scores[top_class]
print(f'[YAMNet] The main sound is: {inferred_class} ({top_score})')
reloaded_results = reloaded_model(waveform)
your_top_class = tf.argmax(reloaded_results)
your_inferred_class = my_classes[your_top_class]
class_probabilities = tf.nn.softmax(reloaded_results, axis=-1)
your_top_score = class_probabilities[your_top_class]
print(f'[Your model] The main sound is: {your_inferred_class} ({your_top_score})')
[YAMNet] The main sound is: Silence (0.500638484954834) [Your model] The main sound is: cat (0.9981643557548523)
ขั้นตอนถัดไป
คุณได้สร้างแบบจำลองที่สามารถจำแนกเสียงจากสุนัขหรือแมวได้ ด้วยแนวคิดเดียวกันและชุดข้อมูลที่แตกต่างกัน คุณสามารถลองสร้าง ตัวระบุเสียงของนก ตามเสียงร้องของพวกมัน
แบ่งปันโครงการของคุณกับทีม TensorFlow บนโซเชียลมีเดีย!