
| | |  Ver no GitHub Ver no GitHub | | |
O YAMNet é uma rede neural profunda pré-treinada que pode prever eventos de áudio de 521 classes , como risos, latidos ou uma sirene.
Neste tutorial você aprenderá como:
- Carregue e use o modelo YAMNet para inferência.
- Construa um novo modelo usando os embeddings do YAMNet para classificar sons de cães e gatos.
- Avalie e exporte seu modelo.
Importar TensorFlow e outras bibliotecas
Comece instalando o TensorFlow I/O , o que facilitará o carregamento de arquivos de áudio do disco.
pip install tensorflow_io
import os
from IPython import display
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_io as tfio
Sobre o YAMNet
YAMNet é uma rede neural pré-treinada que emprega a arquitetura de convolução separável em profundidade MobileNetV1 . Ele pode usar uma forma de onda de áudio como entrada e fazer previsões independentes para cada um dos 521 eventos de áudio do corpus AudioSet .
Internamente, o modelo extrai "quadros" do sinal de áudio e processa lotes desses quadros. Esta versão do modelo usa quadros com 0,96 segundos de duração e extrai um quadro a cada 0,48 segundos.
O modelo aceita uma matriz de Tensor ou NumPy float32 1-D contendo uma forma de onda de comprimento arbitrário, representada como amostras de canal único (mono) de 16 kHz na faixa [-1.0, +1.0] . Este tutorial contém código para ajudá-lo a converter arquivos WAV no formato compatível.
O modelo retorna 3 saídas, incluindo as pontuações da classe, os embeddings (que você usará para o aprendizado de transferência) e o espectrograma log mel . Você pode encontrar mais detalhes aqui .
Um uso específico do YAMNet é como um extrator de recursos de alto nível - a saída de incorporação de 1.024 dimensões. Você usará os recursos de entrada do modelo base (YAMNet) e os alimentará em seu modelo mais raso que consiste em uma camada tf.keras.layers.Dense oculta. Em seguida, você treinará a rede em uma pequena quantidade de dados para classificação de áudio sem exigir muitos dados rotulados e treinamento de ponta a ponta. (Isso é semelhante ao aprendizado de transferência para classificação de imagens com o TensorFlow Hub para obter mais informações.)
Primeiro, você testará o modelo e verá os resultados da classificação do áudio. Em seguida, você construirá o pipeline de pré-processamento de dados.
Carregando o YAMNet do TensorFlow Hub
Você usará um YAMNet pré-treinado do Tensorflow Hub para extrair os embeddings dos arquivos de som.
Carregar um modelo do TensorFlow Hub é simples: escolha o modelo, copie seu URL e use a função de load .
yamnet_model_handle = 'https://tfhub.dev/google/yamnet/1'
yamnet_model = hub.load(yamnet_model_handle)
Com o modelo carregado, você pode seguir o tutorial de uso básico do YAMNet e baixar um arquivo WAV de amostra para executar a inferência.
testing_wav_file_name = tf.keras.utils.get_file('miaow_16k.wav',
'https://storage.googleapis.com/audioset/miaow_16k.wav',
cache_dir='./',
cache_subdir='test_data')
print(testing_wav_file_name)
Downloading data from https://storage.googleapis.com/audioset/miaow_16k.wav 221184/215546 [==============================] - 0s 0us/step 229376/215546 [===============================] - 0s 0us/step ./test_data/miaow_16k.wav
Você precisará de uma função para carregar arquivos de áudio, que também será usada posteriormente ao trabalhar com os dados de treinamento. (Saiba mais sobre como ler arquivos de áudio e seus rótulos em Reconhecimento de áudio simples .
# Utility functions for loading audio files and making sure the sample rate is correct.
@tf.function
def load_wav_16k_mono(filename):
""" Load a WAV file, convert it to a float tensor, resample to 16 kHz single-channel audio. """
file_contents = tf.io.read_file(filename)
wav, sample_rate = tf.audio.decode_wav(
file_contents,
desired_channels=1)
wav = tf.squeeze(wav, axis=-1)
sample_rate = tf.cast(sample_rate, dtype=tf.int64)
wav = tfio.audio.resample(wav, rate_in=sample_rate, rate_out=16000)
return wav
testing_wav_data = load_wav_16k_mono(testing_wav_file_name)
_ = plt.plot(testing_wav_data)
# Play the audio file.
display.Audio(testing_wav_data,rate=16000)
2022-01-26 08:07:19.084427: W tensorflow_io/core/kernels/audio_video_mp3_kernels.cc:271] libmp3lame.so.0 or lame functions are not available WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample

Carregar o mapeamento de classe
É importante carregar os nomes de classe que o YAMNet é capaz de reconhecer. O arquivo de mapeamento está presente em yamnet_model.class_map_path() no formato CSV.
class_map_path = yamnet_model.class_map_path().numpy().decode('utf-8')
class_names =list(pd.read_csv(class_map_path)['display_name'])
for name in class_names[:20]:
print(name)
print('...')
Speech Child speech, kid speaking Conversation Narration, monologue Babbling Speech synthesizer Shout Bellow Whoop Yell Children shouting Screaming Whispering Laughter Baby laughter Giggle Snicker Belly laugh Chuckle, chortle Crying, sobbing ...
Executar inferência
O YAMNet fornece pontuações de classe em nível de quadro (ou seja, 521 pontuações para cada quadro). Para determinar as previsões no nível do clipe, as pontuações podem ser agregadas por classe nos quadros (por exemplo, usando agregação média ou máxima). Isso é feito abaixo por scores_np.mean(axis=0) . Por fim, para encontrar a classe com maior pontuação no nível do clipe, você obtém o máximo das 521 pontuações agregadas.
scores, embeddings, spectrogram = yamnet_model(testing_wav_data)
class_scores = tf.reduce_mean(scores, axis=0)
top_class = tf.argmax(class_scores)
inferred_class = class_names[top_class]
print(f'The main sound is: {inferred_class}')
print(f'The embeddings shape: {embeddings.shape}')
The main sound is: Animal The embeddings shape: (13, 1024)
Conjunto de dados ESC-50
O conjunto de dados ESC-50 ( Piczak, 2015 ) é uma coleção rotulada de 2.000 gravações de áudio ambientais de cinco segundos de duração. O conjunto de dados consiste em 50 classes, com 40 exemplos por classe.
Baixe o conjunto de dados e extraia-o.
_ = tf.keras.utils.get_file('esc-50.zip',
'https://github.com/karoldvl/ESC-50/archive/master.zip',
cache_dir='./',
cache_subdir='datasets',
extract=True)
Downloading data from https://github.com/karoldvl/ESC-50/archive/master.zip 645103616/Unknown - 47s 0us/step
Explorar os dados
Os metadados de cada arquivo são especificados no arquivo csv em ./datasets/ESC-50-master/meta/esc50.csv
e todos os arquivos de áudio estão em ./datasets/ESC-50-master/audio/
Você criará um DataFrame pandas com o mapeamento e o usará para ter uma visão mais clara dos dados.
esc50_csv = './datasets/ESC-50-master/meta/esc50.csv'
base_data_path = './datasets/ESC-50-master/audio/'
pd_data = pd.read_csv(esc50_csv)
pd_data.head()
Filtre os dados
Agora que os dados estão armazenados no DataFrame , aplique algumas transformações:
- Filtre as linhas e use apenas as classes selecionadas -
dogecat. Se você quiser usar outras classes, é aqui que você pode escolhê-las. - Altere o nome do arquivo para ter o caminho completo. Isso facilitará o carregamento mais tarde.
- Altere os alvos para que estejam dentro de um intervalo específico. Neste exemplo,
dogpermanecerá em0, mascatse tornará1em vez de seu valor original de5.
my_classes = ['dog', 'cat']
map_class_to_id = {'dog':0, 'cat':1}
filtered_pd = pd_data[pd_data.category.isin(my_classes)]
class_id = filtered_pd['category'].apply(lambda name: map_class_to_id[name])
filtered_pd = filtered_pd.assign(target=class_id)
full_path = filtered_pd['filename'].apply(lambda row: os.path.join(base_data_path, row))
filtered_pd = filtered_pd.assign(filename=full_path)
filtered_pd.head(10)
Carregue os arquivos de áudio e recupere os embeddings
Aqui você aplicará o load_wav_16k_mono e preparará os dados WAV para o modelo.
Ao extrair embeddings dos dados WAV, você obtém uma matriz de forma (N, 1024) onde N é o número de quadros que o YAMNet encontrou (um para cada 0,48 segundos de áudio).
Seu modelo usará cada quadro como uma entrada. Portanto, você precisa criar uma nova coluna que tenha um quadro por linha. Você também precisa expandir os rótulos e a coluna de fold para refletir adequadamente essas novas linhas.
A coluna de fold expandida mantém os valores originais. Você não pode misturar quadros porque, ao realizar as divisões, pode acabar tendo partes do mesmo áudio em divisões diferentes, o que tornaria suas etapas de validação e teste menos eficazes.
filenames = filtered_pd['filename']
targets = filtered_pd['target']
folds = filtered_pd['fold']
main_ds = tf.data.Dataset.from_tensor_slices((filenames, targets, folds))
main_ds.element_spec
(TensorSpec(shape=(), dtype=tf.string, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
def load_wav_for_map(filename, label, fold):
return load_wav_16k_mono(filename), label, fold
main_ds = main_ds.map(load_wav_for_map)
main_ds.element_spec
WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample (TensorSpec(shape=<unknown>, dtype=tf.float32, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
# applies the embedding extraction model to a wav data
def extract_embedding(wav_data, label, fold):
''' run YAMNet to extract embedding from the wav data '''
scores, embeddings, spectrogram = yamnet_model(wav_data)
num_embeddings = tf.shape(embeddings)[0]
return (embeddings,
tf.repeat(label, num_embeddings),
tf.repeat(fold, num_embeddings))
# extract embedding
main_ds = main_ds.map(extract_embedding).unbatch()
main_ds.element_spec
(TensorSpec(shape=(1024,), dtype=tf.float32, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
Dividir os dados
Você usará a coluna de fold para dividir o conjunto de dados em conjuntos de treinamento, validação e teste.
O ESC-50 está organizado em cinco fold de validação cruzada de tamanho uniforme, de modo que os clipes da mesma fonte original estejam sempre na mesma fold - saiba mais no documento ESC: Dataset for Environmental Sound Classification .
A última etapa é remover a coluna de fold do conjunto de dados, pois você não a usará durante o treinamento.
cached_ds = main_ds.cache()
train_ds = cached_ds.filter(lambda embedding, label, fold: fold < 4)
val_ds = cached_ds.filter(lambda embedding, label, fold: fold == 4)
test_ds = cached_ds.filter(lambda embedding, label, fold: fold == 5)
# remove the folds column now that it's not needed anymore
remove_fold_column = lambda embedding, label, fold: (embedding, label)
train_ds = train_ds.map(remove_fold_column)
val_ds = val_ds.map(remove_fold_column)
test_ds = test_ds.map(remove_fold_column)
train_ds = train_ds.cache().shuffle(1000).batch(32).prefetch(tf.data.AUTOTUNE)
val_ds = val_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
test_ds = test_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
Crie seu modelo
Você fez a maior parte do trabalho! Em seguida, defina um modelo Sequencial muito simples com uma camada oculta e duas saídas para reconhecer gatos e cães a partir de sons.
my_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=(1024), dtype=tf.float32,
name='input_embedding'),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(len(my_classes))
], name='my_model')
my_model.summary()
Model: "my_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 512) 524800
dense_1 (Dense) (None, 2) 1026
=================================================================
Total params: 525,826
Trainable params: 525,826
Non-trainable params: 0
_________________________________________________________________
my_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer="adam",
metrics=['accuracy'])
callback = tf.keras.callbacks.EarlyStopping(monitor='loss',
patience=3,
restore_best_weights=True)
history = my_model.fit(train_ds,
epochs=20,
validation_data=val_ds,
callbacks=callback)
Epoch 1/20 15/15 [==============================] - 6s 49ms/step - loss: 0.7811 - accuracy: 0.8229 - val_loss: 0.4866 - val_accuracy: 0.9125 Epoch 2/20 15/15 [==============================] - 0s 18ms/step - loss: 0.3385 - accuracy: 0.8938 - val_loss: 0.2185 - val_accuracy: 0.8813 Epoch 3/20 15/15 [==============================] - 0s 18ms/step - loss: 0.3091 - accuracy: 0.9021 - val_loss: 0.4290 - val_accuracy: 0.8813 Epoch 4/20 15/15 [==============================] - 0s 18ms/step - loss: 0.5354 - accuracy: 0.9062 - val_loss: 0.2074 - val_accuracy: 0.9125 Epoch 5/20 15/15 [==============================] - 0s 18ms/step - loss: 0.4651 - accuracy: 0.9333 - val_loss: 0.6857 - val_accuracy: 0.8813 Epoch 6/20 15/15 [==============================] - 0s 18ms/step - loss: 0.2489 - accuracy: 0.9167 - val_loss: 0.3640 - val_accuracy: 0.8750 Epoch 7/20 15/15 [==============================] - 0s 17ms/step - loss: 0.2020 - accuracy: 0.9292 - val_loss: 0.2158 - val_accuracy: 0.9125 Epoch 8/20 15/15 [==============================] - 0s 16ms/step - loss: 0.4550 - accuracy: 0.9208 - val_loss: 0.9893 - val_accuracy: 0.8750 Epoch 9/20 15/15 [==============================] - 0s 17ms/step - loss: 0.3434 - accuracy: 0.9354 - val_loss: 0.2670 - val_accuracy: 0.8813 Epoch 10/20 15/15 [==============================] - 0s 17ms/step - loss: 0.2864 - accuracy: 0.9208 - val_loss: 0.5122 - val_accuracy: 0.8813
Vamos executar o método de evaluate nos dados de teste apenas para ter certeza de que não há overfitting.
loss, accuracy = my_model.evaluate(test_ds)
print("Loss: ", loss)
print("Accuracy: ", accuracy)
5/5 [==============================] - 0s 9ms/step - loss: 0.2526 - accuracy: 0.9000 Loss: 0.25257644057273865 Accuracy: 0.8999999761581421
Você fez isso!
Teste seu modelo
Em seguida, experimente seu modelo na incorporação do teste anterior usando apenas o YAMNet.
scores, embeddings, spectrogram = yamnet_model(testing_wav_data)
result = my_model(embeddings).numpy()
inferred_class = my_classes[result.mean(axis=0).argmax()]
print(f'The main sound is: {inferred_class}')
The main sound is: cat
Salve um modelo que possa receber diretamente um arquivo WAV como entrada
Seu modelo funciona quando você fornece os embeddings como entrada.
Em um cenário do mundo real, você desejará usar dados de áudio como entrada direta.
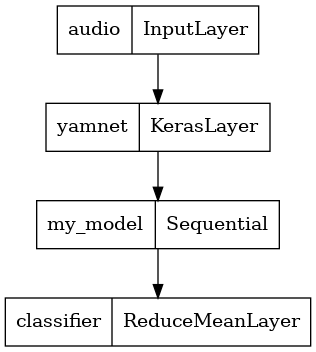
Para fazer isso, você combinará o YAMNet com seu modelo em um único modelo que poderá exportar para outros aplicativos.
Para facilitar o uso do resultado do modelo, a camada final será uma operação reduce_mean . Ao usar esse modelo para veiculação (sobre o qual você aprenderá mais adiante no tutorial), precisará do nome da camada final. Se você não definir um, o TensorFlow definirá automaticamente um incremental que dificulta o teste, pois continuará mudando toda vez que você treinar o modelo. Ao usar uma operação bruta do TensorFlow, você não pode atribuir um nome a ela. Para resolver esse problema, você criará uma camada personalizada que aplicará reduce_mean e a chamará de 'classifier' .
class ReduceMeanLayer(tf.keras.layers.Layer):
def __init__(self, axis=0, **kwargs):
super(ReduceMeanLayer, self).__init__(**kwargs)
self.axis = axis
def call(self, input):
return tf.math.reduce_mean(input, axis=self.axis)
saved_model_path = './dogs_and_cats_yamnet'
input_segment = tf.keras.layers.Input(shape=(), dtype=tf.float32, name='audio')
embedding_extraction_layer = hub.KerasLayer(yamnet_model_handle,
trainable=False, name='yamnet')
_, embeddings_output, _ = embedding_extraction_layer(input_segment)
serving_outputs = my_model(embeddings_output)
serving_outputs = ReduceMeanLayer(axis=0, name='classifier')(serving_outputs)
serving_model = tf.keras.Model(input_segment, serving_outputs)
serving_model.save(saved_model_path, include_optimizer=False)
WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. 2022-01-26 08:08:33.807036: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: ./dogs_and_cats_yamnet/assets INFO:tensorflow:Assets written to: ./dogs_and_cats_yamnet/assets
tf.keras.utils.plot_model(serving_model)
Carregue seu modelo salvo para verificar se ele funciona conforme o esperado.
reloaded_model = tf.saved_model.load(saved_model_path)
E para o teste final: dados alguns dados de som, seu modelo retorna o resultado correto?
reloaded_results = reloaded_model(testing_wav_data)
cat_or_dog = my_classes[tf.argmax(reloaded_results)]
print(f'The main sound is: {cat_or_dog}')
The main sound is: cat
Se você quiser testar seu novo modelo em uma configuração de veiculação, use a assinatura 'serving_default'.
serving_results = reloaded_model.signatures['serving_default'](testing_wav_data)
cat_or_dog = my_classes[tf.argmax(serving_results['classifier'])]
print(f'The main sound is: {cat_or_dog}')
The main sound is: cat
(Opcional) Mais alguns testes
O modelo está pronto.
Vamos compará-lo ao YAMNet no conjunto de dados de teste.
test_pd = filtered_pd.loc[filtered_pd['fold'] == 5]
row = test_pd.sample(1)
filename = row['filename'].item()
print(filename)
waveform = load_wav_16k_mono(filename)
print(f'Waveform values: {waveform}')
_ = plt.plot(waveform)
display.Audio(waveform, rate=16000)
./datasets/ESC-50-master/audio/5-214759-A-5.wav WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample Waveform values: [ 3.2084468e-09 -7.7704687e-09 -1.2222010e-08 ... 2.2788899e-02 1.0315948e-02 -3.4766860e-02]
# Run the model, check the output.
scores, embeddings, spectrogram = yamnet_model(waveform)
class_scores = tf.reduce_mean(scores, axis=0)
top_class = tf.argmax(class_scores)
inferred_class = class_names[top_class]
top_score = class_scores[top_class]
print(f'[YAMNet] The main sound is: {inferred_class} ({top_score})')
reloaded_results = reloaded_model(waveform)
your_top_class = tf.argmax(reloaded_results)
your_inferred_class = my_classes[your_top_class]
class_probabilities = tf.nn.softmax(reloaded_results, axis=-1)
your_top_score = class_probabilities[your_top_class]
print(f'[Your model] The main sound is: {your_inferred_class} ({your_top_score})')
[YAMNet] The main sound is: Silence (0.500638484954834) [Your model] The main sound is: cat (0.9981643557548523)
Próximos passos
Você criou um modelo que pode classificar sons de cães ou gatos. Com a mesma ideia e um conjunto de dados diferente, você pode tentar, por exemplo, construir um identificador acústico de pássaros com base em seu canto.
Compartilhe seu projeto com a equipe do TensorFlow nas mídias sociais!