
| | |  عرض على جيثب عرض على جيثب | | |
YAMNet هي شبكة عصبية عميقة مدربة مسبقًا يمكنها التنبؤ بأحداث صوتية من 521 فئة ، مثل الضحك أو النباح أو صفارات الإنذار.
ستتعلم في هذا البرنامج التعليمي كيفية:
- تحميل واستخدام نموذج YAMNet للاستدلال.
- قم ببناء نموذج جديد باستخدام حفلات الزفاف YAMNet لتصنيف أصوات القطط والكلاب.
- تقييم وتصدير النموذج الخاص بك.
استيراد TensorFlow ومكتبات أخرى
ابدأ بتثبيت TensorFlow I / O ، مما سيسهل عليك تحميل الملفات الصوتية من القرص.
pip install tensorflow_io
import os
from IPython import display
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_io as tfio
حول YAMNet
YAMNet عبارة عن شبكة عصبية مُدرَّبة مسبقًا تستخدم بنية التفاف MobileNetV1 القابلة للفصل بعمق. يمكنه استخدام شكل موجة صوتية كمدخلات وإجراء تنبؤات مستقلة لكل من الأحداث الصوتية البالغ عددها 521 من مجموعة AudioSet .
داخليًا ، يستخرج النموذج "إطارات" من الإشارة الصوتية ويعالج دفعات من هذه الإطارات. يستخدم هذا الإصدار من النموذج إطارات يبلغ طولها 0.96 ثانية ويستخرج إطارًا واحدًا كل 0.48 ثانية.
يقبل النموذج مصفوفة Tensor أو NumPy عائمة 1-D تحتوي على شكل موجة من الطول التعسفي ، يتم تمثيله كعينات أحادية القناة (أحادية) 16 كيلو هرتز في النطاق [-1.0, +1.0] . يحتوي هذا البرنامج التعليمي على رمز لمساعدتك في تحويل ملفات WAV إلى التنسيق المدعوم.
يُرجع النموذج 3 مخرجات ، بما في ذلك درجات الفصل ، وحفلات الزفاف (التي ستستخدمها في نقل التعلم) ، والبرنامج الطيفي لوغارم ميل. يمكنك العثور على مزيد من التفاصيل هنا .
أحد الاستخدامات المحددة لـ YAMNet هو كمستخرج ميزة عالية المستوى - إخراج التضمين 1،024 بعدًا. ستستخدم ميزات إدخال النموذج الأساسي (YAMNet) وتغذيها في نموذجك الضحل الذي يتكون من طبقة tf.keras.layers.Dense المخفية. بعد ذلك ، ستقوم بتدريب الشبكة على كمية صغيرة من البيانات لتصنيف الصوت دون الحاجة إلى الكثير من البيانات المصنفة والتدريب الشامل. (هذا مشابه لنقل التعلم لتصنيف الصور باستخدام TensorFlow Hub لمزيد من المعلومات.)
أولاً ، ستختبر النموذج وترى نتائج تصنيف الصوت. ستقوم بعد ذلك بإنشاء خط أنابيب المعالجة المسبقة للبيانات.
تحميل YAMNet من TensorFlow Hub
ستستخدم YAMNet مُدرَّب مسبقًا من Tensorflow Hub لاستخراج التضمينات من ملفات الصوت.
يعد تحميل نموذج من TensorFlow Hub أمرًا سهلاً: اختر النموذج وانسخ عنوان URL الخاص به واستخدم وظيفة load .
yamnet_model_handle = 'https://tfhub.dev/google/yamnet/1'
yamnet_model = hub.load(yamnet_model_handle)
مع تحميل النموذج ، يمكنك اتباع دليل الاستخدام الأساسي لـ YAMNet وتنزيل نموذج ملف WAV لتشغيل الاستنتاج.
testing_wav_file_name = tf.keras.utils.get_file('miaow_16k.wav',
'https://storage.googleapis.com/audioset/miaow_16k.wav',
cache_dir='./',
cache_subdir='test_data')
print(testing_wav_file_name)
Downloading data from https://storage.googleapis.com/audioset/miaow_16k.wav 221184/215546 [==============================] - 0s 0us/step 229376/215546 [===============================] - 0s 0us/step ./test_data/miaow_16k.wav
ستحتاج إلى وظيفة لتحميل الملفات الصوتية ، والتي سيتم استخدامها أيضًا لاحقًا عند العمل مع بيانات التدريب. (تعرف على المزيد حول قراءة الملفات الصوتية وتسمياتها في التعرف على الصوت البسيط .
# Utility functions for loading audio files and making sure the sample rate is correct.
@tf.function
def load_wav_16k_mono(filename):
""" Load a WAV file, convert it to a float tensor, resample to 16 kHz single-channel audio. """
file_contents = tf.io.read_file(filename)
wav, sample_rate = tf.audio.decode_wav(
file_contents,
desired_channels=1)
wav = tf.squeeze(wav, axis=-1)
sample_rate = tf.cast(sample_rate, dtype=tf.int64)
wav = tfio.audio.resample(wav, rate_in=sample_rate, rate_out=16000)
return wav
testing_wav_data = load_wav_16k_mono(testing_wav_file_name)
_ = plt.plot(testing_wav_data)
# Play the audio file.
display.Audio(testing_wav_data,rate=16000)
2022-01-26 08:07:19.084427: W tensorflow_io/core/kernels/audio_video_mp3_kernels.cc:271] libmp3lame.so.0 or lame functions are not available WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample

تحميل تعيين الفصل
من المهم تحميل أسماء الفئات التي تستطيع YAMNet التعرف عليها. ملف التعيين موجود في yamnet_model.class_map_path() بتنسيق CSV.
class_map_path = yamnet_model.class_map_path().numpy().decode('utf-8')
class_names =list(pd.read_csv(class_map_path)['display_name'])
for name in class_names[:20]:
print(name)
print('...')
Speech Child speech, kid speaking Conversation Narration, monologue Babbling Speech synthesizer Shout Bellow Whoop Yell Children shouting Screaming Whispering Laughter Baby laughter Giggle Snicker Belly laugh Chuckle, chortle Crying, sobbing ...
تشغيل الاستدلال
يوفر YAMNet درجات على مستوى الإطار (أي 521 درجة لكل إطار). من أجل تحديد تنبؤات مستوى القصاصة ، يمكن تجميع الدرجات لكل فئة عبر الإطارات (على سبيل المثال ، باستخدام متوسط أو أقصى تجميع). يتم ذلك أدناه بواسطة scores_np.mean(axis=0) . أخيرًا ، للعثور على فئة أعلى الدرجات على مستوى القصاصة ، تحصل على الحد الأقصى من مجموع الدرجات البالغ 521.
scores, embeddings, spectrogram = yamnet_model(testing_wav_data)
class_scores = tf.reduce_mean(scores, axis=0)
top_class = tf.argmax(class_scores)
inferred_class = class_names[top_class]
print(f'The main sound is: {inferred_class}')
print(f'The embeddings shape: {embeddings.shape}')
The main sound is: Animal The embeddings shape: (13, 1024)
مجموعة بيانات ESC-50
مجموعة البيانات ESC-50 ( Piczak ، 2015 ) عبارة عن مجموعة مصنفة من 2000 تسجيل صوتي بيئي طويل مدته خمس ثوانٍ. تتكون مجموعة البيانات من 50 فئة ، مع 40 مثالًا لكل فصل.
قم بتنزيل مجموعة البيانات واستخرجها.
_ = tf.keras.utils.get_file('esc-50.zip',
'https://github.com/karoldvl/ESC-50/archive/master.zip',
cache_dir='./',
cache_subdir='datasets',
extract=True)
Downloading data from https://github.com/karoldvl/ESC-50/archive/master.zip 645103616/Unknown - 47s 0us/step
استكشف البيانات
يتم تحديد البيانات الأولية لكل ملف في ملف csv على ./datasets/ESC-50-master/meta/esc50.csv
وجميع الملفات الصوتية موجودة في ./datasets/ESC-50-master/audio/
ستقوم بإنشاء DataFrame مع التعيين واستخدام ذلك للحصول على عرض أوضح للبيانات.
esc50_csv = './datasets/ESC-50-master/meta/esc50.csv'
base_data_path = './datasets/ESC-50-master/audio/'
pd_data = pd.read_csv(esc50_csv)
pd_data.head()
تصفية البيانات
الآن بعد أن تم تخزين البيانات في DataFrame ، قم بتطبيق بعض التحويلات:
- قم بتصفية الصفوف واستخدام الفئات المحددة فقط -
dogcat. إذا كنت ترغب في استخدام أي فئات أخرى ، فهذا هو المكان الذي يمكنك اختيارهم فيه. - قم بتعديل اسم الملف ليحصل على المسار الكامل. هذا سيجعل التحميل أسهل لاحقًا.
- تغيير الأهداف لتكون ضمن نطاق معين. في هذا المثال ، سيبقى
dogعند0، لكنcatستصبح1بدلاً من قيمتها الأصلية وهي5.
my_classes = ['dog', 'cat']
map_class_to_id = {'dog':0, 'cat':1}
filtered_pd = pd_data[pd_data.category.isin(my_classes)]
class_id = filtered_pd['category'].apply(lambda name: map_class_to_id[name])
filtered_pd = filtered_pd.assign(target=class_id)
full_path = filtered_pd['filename'].apply(lambda row: os.path.join(base_data_path, row))
filtered_pd = filtered_pd.assign(filename=full_path)
filtered_pd.head(10)
قم بتحميل الملفات الصوتية واسترجاع حفلات الزفاف
هنا ستقوم بتطبيق load_wav_16k_mono وإعداد بيانات WAV للنموذج.
عند استخراج التضمينات من بيانات WAV ، تحصل على مجموعة من الأشكال (N, 1024) حيث N هو عدد الإطارات التي وجدها YAMNet (واحد لكل 0.48 ثانية من الصوت).
سيستخدم نموذجك كل إطار كمدخل واحد. لذلك ، تحتاج إلى إنشاء عمود جديد يحتوي على إطار واحد لكل صف. تحتاج أيضًا إلى توسيع التسميات وعمود fold لعكس هذه الصفوف الجديدة بشكل مناسب.
يحافظ عمود fold الموسع على القيم الأصلية. لا يمكنك مزج الإطارات لأنه عند إجراء الانقسامات ، قد ينتهي بك الأمر إلى وجود أجزاء من نفس الصوت على تقسيمات مختلفة ، مما يجعل خطوات التحقق من الصحة والاختبار أقل فعالية.
filenames = filtered_pd['filename']
targets = filtered_pd['target']
folds = filtered_pd['fold']
main_ds = tf.data.Dataset.from_tensor_slices((filenames, targets, folds))
main_ds.element_spec
(TensorSpec(shape=(), dtype=tf.string, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
def load_wav_for_map(filename, label, fold):
return load_wav_16k_mono(filename), label, fold
main_ds = main_ds.map(load_wav_for_map)
main_ds.element_spec
WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample (TensorSpec(shape=<unknown>, dtype=tf.float32, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
# applies the embedding extraction model to a wav data
def extract_embedding(wav_data, label, fold):
''' run YAMNet to extract embedding from the wav data '''
scores, embeddings, spectrogram = yamnet_model(wav_data)
num_embeddings = tf.shape(embeddings)[0]
return (embeddings,
tf.repeat(label, num_embeddings),
tf.repeat(fold, num_embeddings))
# extract embedding
main_ds = main_ds.map(extract_embedding).unbatch()
main_ds.element_spec
(TensorSpec(shape=(1024,), dtype=tf.float32, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
تقسيم البيانات
ستستخدم عمود fold لتقسيم مجموعة البيانات إلى مجموعات تدريب وتحقق واختبار.
يتم ترتيب ESC-50 في خمس fold تحقق من الصحة ذات حجم موحد ، بحيث تكون المقاطع من نفس المصدر الأصلي دائمًا في نفس fold - اكتشف المزيد في ESC: Dataset for Environmental Sound Classification paper.
الخطوة الأخيرة هي إزالة عمود fold من مجموعة البيانات لأنك لن تستخدمه أثناء التدريب.
cached_ds = main_ds.cache()
train_ds = cached_ds.filter(lambda embedding, label, fold: fold < 4)
val_ds = cached_ds.filter(lambda embedding, label, fold: fold == 4)
test_ds = cached_ds.filter(lambda embedding, label, fold: fold == 5)
# remove the folds column now that it's not needed anymore
remove_fold_column = lambda embedding, label, fold: (embedding, label)
train_ds = train_ds.map(remove_fold_column)
val_ds = val_ds.map(remove_fold_column)
test_ds = test_ds.map(remove_fold_column)
train_ds = train_ds.cache().shuffle(1000).batch(32).prefetch(tf.data.AUTOTUNE)
val_ds = val_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
test_ds = test_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
قم بإنشاء نموذجك
لقد قمت بمعظم العمل! بعد ذلك ، حدد نموذجًا متسلسلًا بسيطًا للغاية بطبقة واحدة مخفية ومخرجين للتعرف على القطط والكلاب من الأصوات.
my_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=(1024), dtype=tf.float32,
name='input_embedding'),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(len(my_classes))
], name='my_model')
my_model.summary()
Model: "my_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 512) 524800
dense_1 (Dense) (None, 2) 1026
=================================================================
Total params: 525,826
Trainable params: 525,826
Non-trainable params: 0
_________________________________________________________________
my_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer="adam",
metrics=['accuracy'])
callback = tf.keras.callbacks.EarlyStopping(monitor='loss',
patience=3,
restore_best_weights=True)
history = my_model.fit(train_ds,
epochs=20,
validation_data=val_ds,
callbacks=callback)
Epoch 1/20 15/15 [==============================] - 6s 49ms/step - loss: 0.7811 - accuracy: 0.8229 - val_loss: 0.4866 - val_accuracy: 0.9125 Epoch 2/20 15/15 [==============================] - 0s 18ms/step - loss: 0.3385 - accuracy: 0.8938 - val_loss: 0.2185 - val_accuracy: 0.8813 Epoch 3/20 15/15 [==============================] - 0s 18ms/step - loss: 0.3091 - accuracy: 0.9021 - val_loss: 0.4290 - val_accuracy: 0.8813 Epoch 4/20 15/15 [==============================] - 0s 18ms/step - loss: 0.5354 - accuracy: 0.9062 - val_loss: 0.2074 - val_accuracy: 0.9125 Epoch 5/20 15/15 [==============================] - 0s 18ms/step - loss: 0.4651 - accuracy: 0.9333 - val_loss: 0.6857 - val_accuracy: 0.8813 Epoch 6/20 15/15 [==============================] - 0s 18ms/step - loss: 0.2489 - accuracy: 0.9167 - val_loss: 0.3640 - val_accuracy: 0.8750 Epoch 7/20 15/15 [==============================] - 0s 17ms/step - loss: 0.2020 - accuracy: 0.9292 - val_loss: 0.2158 - val_accuracy: 0.9125 Epoch 8/20 15/15 [==============================] - 0s 16ms/step - loss: 0.4550 - accuracy: 0.9208 - val_loss: 0.9893 - val_accuracy: 0.8750 Epoch 9/20 15/15 [==============================] - 0s 17ms/step - loss: 0.3434 - accuracy: 0.9354 - val_loss: 0.2670 - val_accuracy: 0.8813 Epoch 10/20 15/15 [==============================] - 0s 17ms/step - loss: 0.2864 - accuracy: 0.9208 - val_loss: 0.5122 - val_accuracy: 0.8813
لنقم بتشغيل طريقة evaluate على بيانات الاختبار فقط للتأكد من عدم وجود فرط في التجهيز.
loss, accuracy = my_model.evaluate(test_ds)
print("Loss: ", loss)
print("Accuracy: ", accuracy)
5/5 [==============================] - 0s 9ms/step - loss: 0.2526 - accuracy: 0.9000 Loss: 0.25257644057273865 Accuracy: 0.8999999761581421
أنت فعلت ذلك!
اختبر نموذجك
بعد ذلك ، جرب النموذج الخاص بك على التضمين من الاختبار السابق باستخدام YAMNet فقط.
scores, embeddings, spectrogram = yamnet_model(testing_wav_data)
result = my_model(embeddings).numpy()
inferred_class = my_classes[result.mean(axis=0).argmax()]
print(f'The main sound is: {inferred_class}')
The main sound is: cat
احفظ نموذجًا يمكنه أخذ ملف WAV كمدخلات مباشرة
يعمل نموذجك عندما تقدم له الزخارف كمدخلات.
في سيناريو العالم الحقيقي ، سترغب في استخدام البيانات الصوتية كمدخل مباشر.
للقيام بذلك ، ستقوم بدمج YAMNet مع النموذج الخاص بك في نموذج واحد يمكنك تصديره لتطبيقات أخرى.
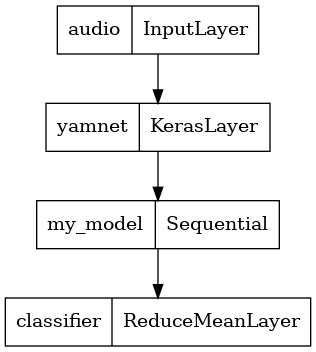
لتسهيل استخدام نتيجة النموذج ، ستكون الطبقة النهائية عبارة عن عملية reduce_mean . عند استخدام هذا النموذج للخدمة (والذي ستتعرف عليه لاحقًا في البرنامج التعليمي) ، ستحتاج إلى اسم الطبقة النهائية. إذا لم تحدد واحدًا ، فسيقوم TensorFlow تلقائيًا بتحديد تعريف تدريجي يجعل من الصعب اختباره ، حيث سيستمر التغيير في كل مرة تقوم فيها بتدريب النموذج. عند استخدام عملية TensorFlow خام ، لا يمكنك تعيين اسم لها. لمعالجة هذه المشكلة ، ستنشئ طبقة مخصصة تطبق reduce_mean 'classifier' .
class ReduceMeanLayer(tf.keras.layers.Layer):
def __init__(self, axis=0, **kwargs):
super(ReduceMeanLayer, self).__init__(**kwargs)
self.axis = axis
def call(self, input):
return tf.math.reduce_mean(input, axis=self.axis)
saved_model_path = './dogs_and_cats_yamnet'
input_segment = tf.keras.layers.Input(shape=(), dtype=tf.float32, name='audio')
embedding_extraction_layer = hub.KerasLayer(yamnet_model_handle,
trainable=False, name='yamnet')
_, embeddings_output, _ = embedding_extraction_layer(input_segment)
serving_outputs = my_model(embeddings_output)
serving_outputs = ReduceMeanLayer(axis=0, name='classifier')(serving_outputs)
serving_model = tf.keras.Model(input_segment, serving_outputs)
serving_model.save(saved_model_path, include_optimizer=False)
WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. 2022-01-26 08:08:33.807036: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: ./dogs_and_cats_yamnet/assets INFO:tensorflow:Assets written to: ./dogs_and_cats_yamnet/assets
tf.keras.utils.plot_model(serving_model)
قم بتحميل النموذج المحفوظ للتحقق من أنه يعمل على النحو المتوقع.
reloaded_model = tf.saved_model.load(saved_model_path)
وللحصول على الاختبار النهائي: بالنظر إلى بعض البيانات الصوتية ، هل يُرجع نموذجك النتيجة الصحيحة؟
reloaded_results = reloaded_model(testing_wav_data)
cat_or_dog = my_classes[tf.argmax(reloaded_results)]
print(f'The main sound is: {cat_or_dog}')
The main sound is: cat
إذا كنت ترغب في تجربة نموذجك الجديد على إعداد تقديم ، يمكنك استخدام توقيع "serve_default".
serving_results = reloaded_model.signatures['serving_default'](testing_wav_data)
cat_or_dog = my_classes[tf.argmax(serving_results['classifier'])]
print(f'The main sound is: {cat_or_dog}')
The main sound is: cat
(اختياري) بعض الاختبارات الأخرى
النموذج جاهز.
دعنا نقارنها بـ YAMNet في مجموعة بيانات الاختبار.
test_pd = filtered_pd.loc[filtered_pd['fold'] == 5]
row = test_pd.sample(1)
filename = row['filename'].item()
print(filename)
waveform = load_wav_16k_mono(filename)
print(f'Waveform values: {waveform}')
_ = plt.plot(waveform)
display.Audio(waveform, rate=16000)
./datasets/ESC-50-master/audio/5-214759-A-5.wav WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample Waveform values: [ 3.2084468e-09 -7.7704687e-09 -1.2222010e-08 ... 2.2788899e-02 1.0315948e-02 -3.4766860e-02]
# Run the model, check the output.
scores, embeddings, spectrogram = yamnet_model(waveform)
class_scores = tf.reduce_mean(scores, axis=0)
top_class = tf.argmax(class_scores)
inferred_class = class_names[top_class]
top_score = class_scores[top_class]
print(f'[YAMNet] The main sound is: {inferred_class} ({top_score})')
reloaded_results = reloaded_model(waveform)
your_top_class = tf.argmax(reloaded_results)
your_inferred_class = my_classes[your_top_class]
class_probabilities = tf.nn.softmax(reloaded_results, axis=-1)
your_top_score = class_probabilities[your_top_class]
print(f'[Your model] The main sound is: {your_inferred_class} ({your_top_score})')
[YAMNet] The main sound is: Silence (0.500638484954834) [Your model] The main sound is: cat (0.9981643557548523)
الخطوات التالية
لقد أنشأت نموذجًا يمكنه تصنيف الأصوات من الكلاب أو القطط. باستخدام نفس الفكرة ومجموعة بيانات مختلفة ، يمكنك تجربة ، على سبيل المثال ، إنشاء معرف صوتي للطيور بناءً على غنائها.
شارك مشروعك مع فريق TensorFlow على وسائل التواصل الاجتماعي!