
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
این آموزش نحوه پیش پردازش فایل های صوتی در فرمت WAV و ساخت و آموزش یک مدل اصلی تشخیص گفتار خودکار (ASR) برای تشخیص ده کلمه مختلف را نشان می دهد. شما از بخشی از مجموعه دستورات گفتار استفاده خواهید کرد ( واردن، 2018 )، که شامل کلیپ های صوتی کوتاه (یک ثانیه یا کمتر) از دستورات، مانند "پایین"، "برو"، "چپ"، "نه"، "است. راست، «ایست»، «بالا» و «بله».
سیستم های تشخیص گفتار و صدا در دنیای واقعی پیچیده هستند. اما، مانند طبقهبندی تصویر با مجموعه دادههای MNIST ، این آموزش باید به شما درک اساسی از تکنیکهای مربوطه بدهد.
برپایی
ماژول ها و وابستگی های لازم را وارد کنید. توجه داشته باشید که در این آموزش از seaborn برای تجسم استفاده خواهید کرد.
import os
import pathlib
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import models
from IPython import display
# Set the seed value for experiment reproducibility.
seed = 42
tf.random.set_seed(seed)
np.random.seed(seed)
مجموعه داده دستورات گفتار کوچک را وارد کنید
برای صرفه جویی در زمان با بارگیری داده ها، با نسخه کوچکتری از مجموعه داده دستورات گفتار کار خواهید کرد. مجموعه داده اصلی شامل بیش از 105000 فایل صوتی در فرمت فایل صوتی WAV (شکل موج) از افرادی است که 35 کلمه مختلف می گویند. این داده ها توسط Google جمع آوری شده و تحت مجوز CC BY منتشر شده است.
فایل mini_speech_commands.zip حاوی مجموعه داده های کوچکتر Speech Commands را با tf.keras.utils.get_file دانلود و استخراج کنید:
DATASET_PATH = 'data/mini_speech_commands'
data_dir = pathlib.Path(DATASET_PATH)
if not data_dir.exists():
tf.keras.utils.get_file(
'mini_speech_commands.zip',
origin="http://storage.googleapis.com/download.tensorflow.org/data/mini_speech_commands.zip",
extract=True,
cache_dir='.', cache_subdir='data')
Downloading data from http://storage.googleapis.com/download.tensorflow.org/data/mini_speech_commands.zip 182083584/182082353 [==============================] - 1s 0us/step 182091776/182082353 [==============================] - 1s 0us/step
کلیپهای صوتی مجموعه داده در هشت پوشه مربوط به هر فرمان گفتاری ذخیره میشوند: no ، yes ، down ، go ، left ، up ، right و stop :
commands = np.array(tf.io.gfile.listdir(str(data_dir)))
commands = commands[commands != 'README.md']
print('Commands:', commands)
Commands: ['stop' 'left' 'no' 'go' 'yes' 'down' 'right' 'up']
کلیپ های صوتی را در لیستی به نام نام filenames ها استخراج کنید و آن را به هم بزنید:
filenames = tf.io.gfile.glob(str(data_dir) + '/*/*')
filenames = tf.random.shuffle(filenames)
num_samples = len(filenames)
print('Number of total examples:', num_samples)
print('Number of examples per label:',
len(tf.io.gfile.listdir(str(data_dir/commands[0]))))
print('Example file tensor:', filenames[0])
Number of total examples: 8000 Number of examples per label: 1000 Example file tensor: tf.Tensor(b'data/mini_speech_commands/yes/db72a474_nohash_0.wav', shape=(), dtype=string)
با استفاده از نسبت 80:10:10، filenames را به مجموعههای آموزشی، اعتبارسنجی و آزمایشی تقسیم کنید:
train_files = filenames[:6400]
val_files = filenames[6400: 6400 + 800]
test_files = filenames[-800:]
print('Training set size', len(train_files))
print('Validation set size', len(val_files))
print('Test set size', len(test_files))
Training set size 6400 Validation set size 800 Test set size 800
فایل های صوتی و برچسب های آنها را بخوانید
در این بخش، مجموعه داده را از قبل پردازش میکنید و تانسورهای رمزگشایی شده برای شکلهای موج و برچسبهای مربوطه ایجاد میکنید. توجه داشته باشید که:
- هر فایل WAV حاوی داده های سری زمانی با تعدادی نمونه در ثانیه است.
- هر نمونه نشان دهنده دامنه سیگنال صوتی در آن زمان خاص است.
- در یک سیستم 16 بیتی ، مانند فایل های WAV در مجموعه داده دستورات گفتاری کوچک، مقادیر دامنه از 32768- تا 32767 متغیر است.
- نرخ نمونه برای این مجموعه داده 16 کیلوهرتز است.
شکل تانسور بازگردانده شده توسط tf.audio.decode_wav [samples, channels] است، که در آن channels 1 برای مونو یا 2 برای استریو است. مجموعه داده دستورات گفتار کوچک فقط شامل ضبطهای تک است.
test_file = tf.io.read_file(DATASET_PATH+'/down/0a9f9af7_nohash_0.wav')
test_audio, _ = tf.audio.decode_wav(contents=test_file)
test_audio.shape
TensorShape([13654, 1])
اکنون، بیایید تابعی را تعریف کنیم که فایل های صوتی WAV خام مجموعه داده را به تانسورهای صوتی از قبل پردازش می کند:
def decode_audio(audio_binary):
# Decode WAV-encoded audio files to `float32` tensors, normalized
# to the [-1.0, 1.0] range. Return `float32` audio and a sample rate.
audio, _ = tf.audio.decode_wav(contents=audio_binary)
# Since all the data is single channel (mono), drop the `channels`
# axis from the array.
return tf.squeeze(audio, axis=-1)
تابعی را تعریف کنید که با استفاده از دایرکتوری های والد برای هر فایل برچسب ایجاد می کند:
- مسیرهای فایل را به
tf.RaggedTensors (تانسورهایی با ابعاد ناهموار - با برش هایی که ممکن است طول های متفاوتی داشته باشند) تقسیم کنید.
def get_label(file_path):
parts = tf.strings.split(
input=file_path,
sep=os.path.sep)
# Note: You'll use indexing here instead of tuple unpacking to enable this
# to work in a TensorFlow graph.
return parts[-2]
تابع کمکی دیگری را تعریف کنید - get_waveform_and_label - که همه را با هم جمع می کند:
- ورودی نام فایل صوتی WAV است.
- خروجی یک تاپل حاوی تانسورهای صوتی و برچسب آماده برای یادگیری تحت نظارت است.
def get_waveform_and_label(file_path):
label = get_label(file_path)
audio_binary = tf.io.read_file(file_path)
waveform = decode_audio(audio_binary)
return waveform, label
مجموعه آموزشی را برای استخراج جفتهای برچسب صوتی بسازید:
- یک
tf.data.DatasetباDataset.from_tensor_slicesوDataset.mapبا استفاده ازget_waveform_and_labelکه قبلاً تعریف شده بود ایجاد کنید.
بعداً با استفاده از روشی مشابه، مجموعههای اعتبارسنجی و آزمایش را خواهید ساخت.
AUTOTUNE = tf.data.AUTOTUNE
files_ds = tf.data.Dataset.from_tensor_slices(train_files)
waveform_ds = files_ds.map(
map_func=get_waveform_and_label,
num_parallel_calls=AUTOTUNE)
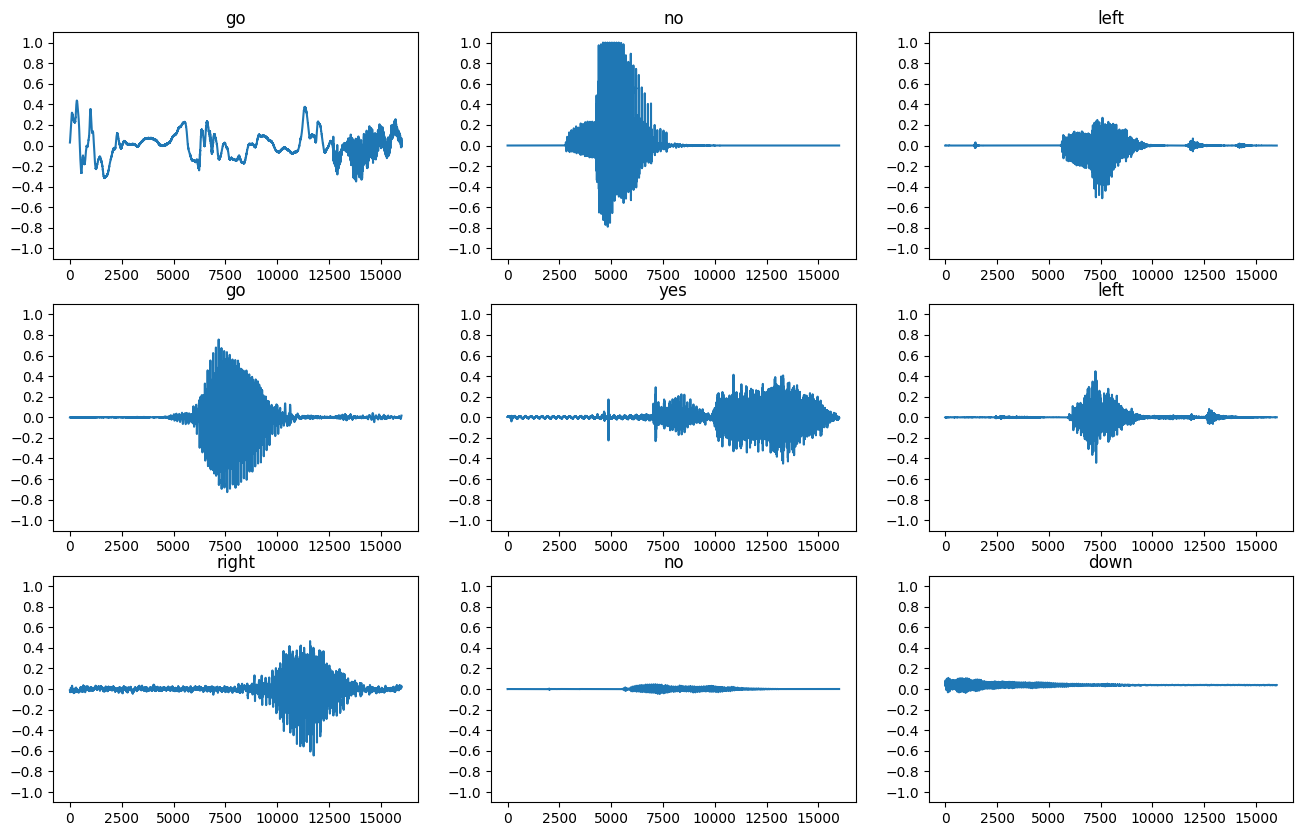
بیایید چند شکل موج صوتی را ترسیم کنیم:
rows = 3
cols = 3
n = rows * cols
fig, axes = plt.subplots(rows, cols, figsize=(10, 12))
for i, (audio, label) in enumerate(waveform_ds.take(n)):
r = i // cols
c = i % cols
ax = axes[r][c]
ax.plot(audio.numpy())
ax.set_yticks(np.arange(-1.2, 1.2, 0.2))
label = label.numpy().decode('utf-8')
ax.set_title(label)
plt.show()
تبدیل شکل موج به طیف نگار
شکل موج در مجموعه داده در حوزه زمان نمایش داده می شود. در مرحله بعد، با محاسبه تبدیل فوریه کوتاه مدت (STFT) شکل موج ها را از سیگنال های حوزه زمان به سیگنال های حوزه فرکانس زمانی تبدیل می کنید تا شکل موج ها را به طیف نگار تبدیل کنید، که تغییرات فرکانس را در طول زمان نشان می دهد و می تواند به صورت تصاویر دو بعدی نمایش داده می شود. برای آموزش مدل، تصاویر طیفگرام را وارد شبکه عصبی خود میکنید.
تبدیل فوریه ( tf.signal.fft ) یک سیگنال را به فرکانس های جزء آن تبدیل می کند، اما تمام اطلاعات زمانی را از دست می دهد. در مقایسه، STFT ( tf.signal.stft ) سیگنال را به پنجرههای زمان تقسیم میکند و یک تبدیل فوریه را روی هر پنجره اجرا میکند، مقداری اطلاعات زمانی را حفظ میکند و یک تانسور دو بعدی را برمیگرداند که میتوانید کانولوشنهای استاندارد را روی آن اجرا کنید.
یک تابع کاربردی برای تبدیل شکل موج به طیف نگار ایجاد کنید:
- طول شکل موج ها باید یکسان باشد، به طوری که وقتی آنها را به طیف نگار تبدیل می کنید، نتایج دارای ابعاد مشابه باشند. این کار را میتوان با صفر کردن کلیپهای صوتی کوتاهتر از یک ثانیه (با استفاده از
tf.zeros) انجام داد. - هنگام فراخوانی
tf.signal.stft، پارامترهایframe_lengthوframe_stepرا طوری انتخاب کنید که طیفگرام ایجاد شده "تصویر" تقریباً مربع باشد. برای اطلاعات بیشتر در مورد انتخاب پارامترهای STFT، به این ویدیوی Coursera در مورد پردازش سیگنال صوتی و STFT مراجعه کنید. - STFT آرایه ای از اعداد مختلط را تولید می کند که نشان دهنده قدر و فاز است. با این حال، در این آموزش شما فقط از مقدار استفاده می کنید که می توانید با اعمال
tf.absدر خروجیtf.signal.stftبه دست آورید.
def get_spectrogram(waveform):
# Zero-padding for an audio waveform with less than 16,000 samples.
input_len = 16000
waveform = waveform[:input_len]
zero_padding = tf.zeros(
[16000] - tf.shape(waveform),
dtype=tf.float32)
# Cast the waveform tensors' dtype to float32.
waveform = tf.cast(waveform, dtype=tf.float32)
# Concatenate the waveform with `zero_padding`, which ensures all audio
# clips are of the same length.
equal_length = tf.concat([waveform, zero_padding], 0)
# Convert the waveform to a spectrogram via a STFT.
spectrogram = tf.signal.stft(
equal_length, frame_length=255, frame_step=128)
# Obtain the magnitude of the STFT.
spectrogram = tf.abs(spectrogram)
# Add a `channels` dimension, so that the spectrogram can be used
# as image-like input data with convolution layers (which expect
# shape (`batch_size`, `height`, `width`, `channels`).
spectrogram = spectrogram[..., tf.newaxis]
return spectrogram
در مرحله بعد، کاوش داده ها را شروع کنید. اشکال شکل موج تانسور شده یک مثال و طیف نگار مربوطه را چاپ کنید و صدای اصلی را پخش کنید:
for waveform, label in waveform_ds.take(1):
label = label.numpy().decode('utf-8')
spectrogram = get_spectrogram(waveform)
print('Label:', label)
print('Waveform shape:', waveform.shape)
print('Spectrogram shape:', spectrogram.shape)
print('Audio playback')
display.display(display.Audio(waveform, rate=16000))
Label: yes Waveform shape: (16000,) Spectrogram shape: (124, 129, 1) Audio playback
حالا تابعی را برای نمایش یک طیف نگار تعریف کنید:
def plot_spectrogram(spectrogram, ax):
if len(spectrogram.shape) > 2:
assert len(spectrogram.shape) == 3
spectrogram = np.squeeze(spectrogram, axis=-1)
# Convert the frequencies to log scale and transpose, so that the time is
# represented on the x-axis (columns).
# Add an epsilon to avoid taking a log of zero.
log_spec = np.log(spectrogram.T + np.finfo(float).eps)
height = log_spec.shape[0]
width = log_spec.shape[1]
X = np.linspace(0, np.size(spectrogram), num=width, dtype=int)
Y = range(height)
ax.pcolormesh(X, Y, log_spec)
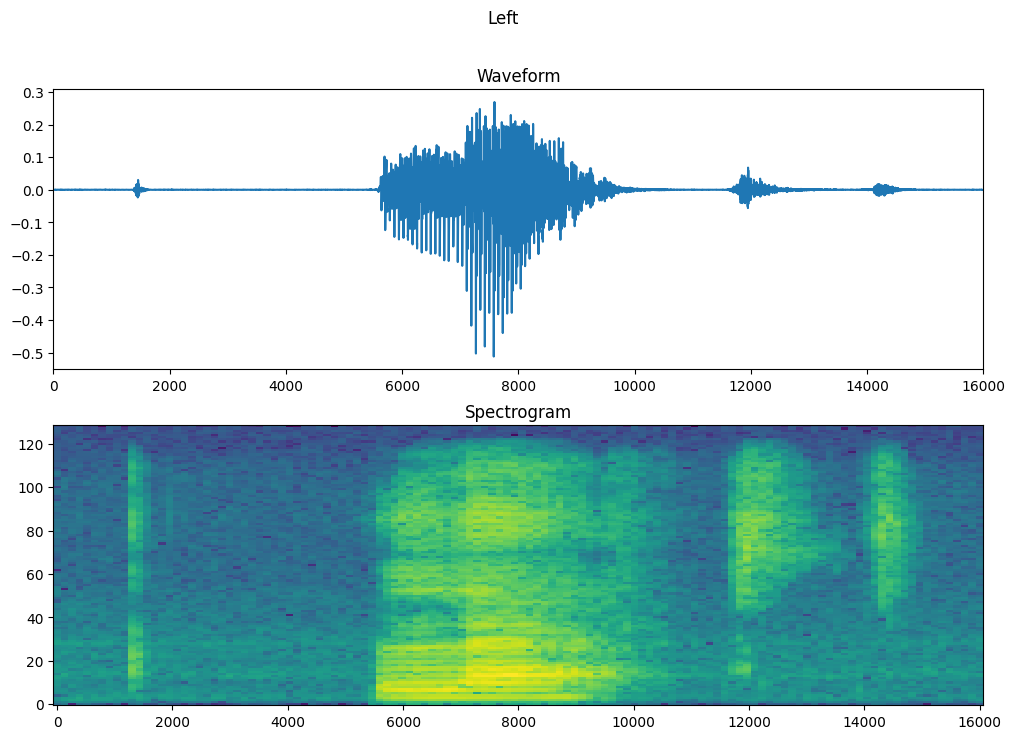
شکل موج مثال را در طول زمان و طیف نگار مربوطه (فرکانس ها در طول زمان) را رسم کنید:
fig, axes = plt.subplots(2, figsize=(12, 8))
timescale = np.arange(waveform.shape[0])
axes[0].plot(timescale, waveform.numpy())
axes[0].set_title('Waveform')
axes[0].set_xlim([0, 16000])
plot_spectrogram(spectrogram.numpy(), axes[1])
axes[1].set_title('Spectrogram')
plt.show()
اکنون، تابعی را تعریف کنید که مجموعه داده شکل موج را به طیفنگارها و برچسبهای مربوط به آنها به عنوان شناسههای عدد صحیح تبدیل میکند:
def get_spectrogram_and_label_id(audio, label):
spectrogram = get_spectrogram(audio)
label_id = tf.argmax(label == commands)
return spectrogram, label_id
نقشه get_spectrogram_and_label_id در عناصر مجموعه داده با Dataset.map :
spectrogram_ds = waveform_ds.map(
map_func=get_spectrogram_and_label_id,
num_parallel_calls=AUTOTUNE)
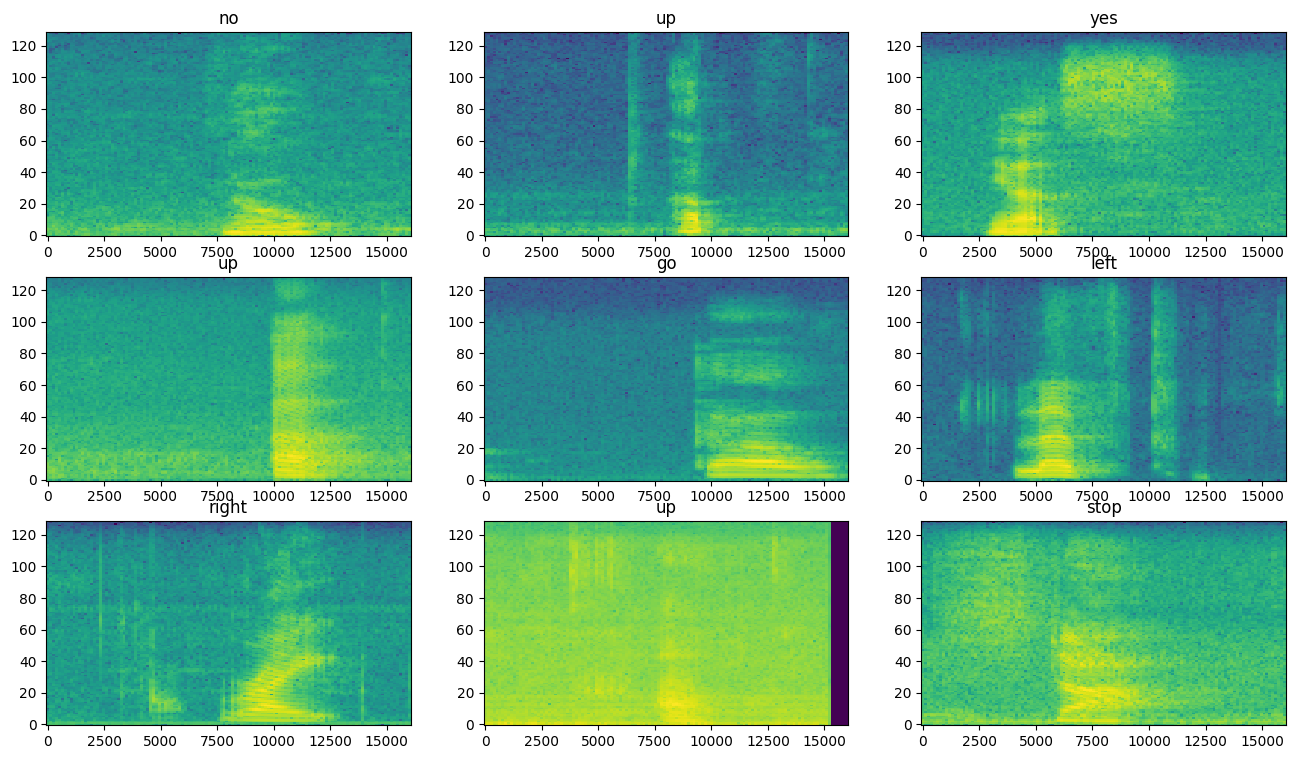
طیفنگارها را برای نمونههای مختلف مجموعه دادهها بررسی کنید:
rows = 3
cols = 3
n = rows*cols
fig, axes = plt.subplots(rows, cols, figsize=(10, 10))
for i, (spectrogram, label_id) in enumerate(spectrogram_ds.take(n)):
r = i // cols
c = i % cols
ax = axes[r][c]
plot_spectrogram(spectrogram.numpy(), ax)
ax.set_title(commands[label_id.numpy()])
ax.axis('off')
plt.show()
مدل را بسازید و آموزش دهید
پیش پردازش مجموعه آموزشی را در مجموعه های اعتبار سنجی و آزمایش تکرار کنید:
def preprocess_dataset(files):
files_ds = tf.data.Dataset.from_tensor_slices(files)
output_ds = files_ds.map(
map_func=get_waveform_and_label,
num_parallel_calls=AUTOTUNE)
output_ds = output_ds.map(
map_func=get_spectrogram_and_label_id,
num_parallel_calls=AUTOTUNE)
return output_ds
train_ds = spectrogram_ds
val_ds = preprocess_dataset(val_files)
test_ds = preprocess_dataset(test_files)
مجموعه های آموزشی و اعتبارسنجی را برای آموزش مدل دسته بندی کنید:
batch_size = 64
train_ds = train_ds.batch(batch_size)
val_ds = val_ds.batch(batch_size)
عملیات Dataset.cache و Dataset.prefetch را برای کاهش تأخیر خواندن در حین آموزش مدل اضافه کنید:
train_ds = train_ds.cache().prefetch(AUTOTUNE)
val_ds = val_ds.cache().prefetch(AUTOTUNE)
برای مدل، از یک شبکه عصبی کانولوشنال ساده (CNN) استفاده خواهید کرد، زیرا فایلهای صوتی را به تصاویر طیفنگاری تبدیل کردهاید.
مدل tf.keras.Sequential شما از لایه های پیش پردازش Keras زیر استفاده می کند:
-
tf.keras.layers.Resizing: برای پایین آوردن نمونه ورودی برای فعال کردن مدل برای آموزش سریعتر. -
tf.keras.layers.Normalization: برای عادی سازی هر پیکسل در تصویر بر اساس میانگین و انحراف استاندارد آن.
برای لایه Normalization ، روش adapt آن ابتدا باید روی داده های آموزشی فراخوانی شود تا آمار کل (یعنی میانگین و انحراف استاندارد) محاسبه شود.
for spectrogram, _ in spectrogram_ds.take(1):
input_shape = spectrogram.shape
print('Input shape:', input_shape)
num_labels = len(commands)
# Instantiate the `tf.keras.layers.Normalization` layer.
norm_layer = layers.Normalization()
# Fit the state of the layer to the spectrograms
# with `Normalization.adapt`.
norm_layer.adapt(data=spectrogram_ds.map(map_func=lambda spec, label: spec))
model = models.Sequential([
layers.Input(shape=input_shape),
# Downsample the input.
layers.Resizing(32, 32),
# Normalize.
norm_layer,
layers.Conv2D(32, 3, activation='relu'),
layers.Conv2D(64, 3, activation='relu'),
layers.MaxPooling2D(),
layers.Dropout(0.25),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dropout(0.5),
layers.Dense(num_labels),
])
model.summary()
Input shape: (124, 129, 1)
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
resizing (Resizing) (None, 32, 32, 1) 0
normalization (Normalizatio (None, 32, 32, 1) 3
n)
conv2d (Conv2D) (None, 30, 30, 32) 320
conv2d_1 (Conv2D) (None, 28, 28, 64) 18496
max_pooling2d (MaxPooling2D (None, 14, 14, 64) 0
)
dropout (Dropout) (None, 14, 14, 64) 0
flatten (Flatten) (None, 12544) 0
dense (Dense) (None, 128) 1605760
dropout_1 (Dropout) (None, 128) 0
dense_1 (Dense) (None, 8) 1032
=================================================================
Total params: 1,625,611
Trainable params: 1,625,608
Non-trainable params: 3
_________________________________________________________________
مدل Keras را با بهینه ساز Adam و از دست دادن آنتروپی متقابل پیکربندی کنید:
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'],
)
این مدل را بیش از 10 دوره برای اهداف نمایشی آموزش دهید:
EPOCHS = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=EPOCHS,
callbacks=tf.keras.callbacks.EarlyStopping(verbose=1, patience=2),
)
Epoch 1/10 100/100 [==============================] - 6s 41ms/step - loss: 1.7503 - accuracy: 0.3630 - val_loss: 1.2850 - val_accuracy: 0.5763 Epoch 2/10 100/100 [==============================] - 0s 5ms/step - loss: 1.2101 - accuracy: 0.5698 - val_loss: 0.9314 - val_accuracy: 0.6913 Epoch 3/10 100/100 [==============================] - 0s 5ms/step - loss: 0.9336 - accuracy: 0.6703 - val_loss: 0.7529 - val_accuracy: 0.7325 Epoch 4/10 100/100 [==============================] - 0s 5ms/step - loss: 0.7503 - accuracy: 0.7397 - val_loss: 0.6721 - val_accuracy: 0.7713 Epoch 5/10 100/100 [==============================] - 0s 5ms/step - loss: 0.6367 - accuracy: 0.7741 - val_loss: 0.6061 - val_accuracy: 0.7975 Epoch 6/10 100/100 [==============================] - 0s 5ms/step - loss: 0.5650 - accuracy: 0.7987 - val_loss: 0.5489 - val_accuracy: 0.8125 Epoch 7/10 100/100 [==============================] - 0s 5ms/step - loss: 0.5099 - accuracy: 0.8183 - val_loss: 0.5344 - val_accuracy: 0.8238 Epoch 8/10 100/100 [==============================] - 0s 5ms/step - loss: 0.4560 - accuracy: 0.8392 - val_loss: 0.5194 - val_accuracy: 0.8288 Epoch 9/10 100/100 [==============================] - 0s 5ms/step - loss: 0.4101 - accuracy: 0.8547 - val_loss: 0.4809 - val_accuracy: 0.8388 Epoch 10/10 100/100 [==============================] - 0s 5ms/step - loss: 0.3905 - accuracy: 0.8589 - val_loss: 0.4973 - val_accuracy: 0.8363
بیایید منحنیهای از دست دادن آموزش و اعتبارسنجی را ترسیم کنیم تا بررسی کنیم که مدل شما در طول آموزش چگونه بهبود یافته است:
metrics = history.history
plt.plot(history.epoch, metrics['loss'], metrics['val_loss'])
plt.legend(['loss', 'val_loss'])
plt.show()

عملکرد مدل را ارزیابی کنید
مدل را روی مجموعه تست اجرا کنید و عملکرد مدل را بررسی کنید:
test_audio = []
test_labels = []
for audio, label in test_ds:
test_audio.append(audio.numpy())
test_labels.append(label.numpy())
test_audio = np.array(test_audio)
test_labels = np.array(test_labels)
y_pred = np.argmax(model.predict(test_audio), axis=1)
y_true = test_labels
test_acc = sum(y_pred == y_true) / len(y_true)
print(f'Test set accuracy: {test_acc:.0%}')
Test set accuracy: 85%
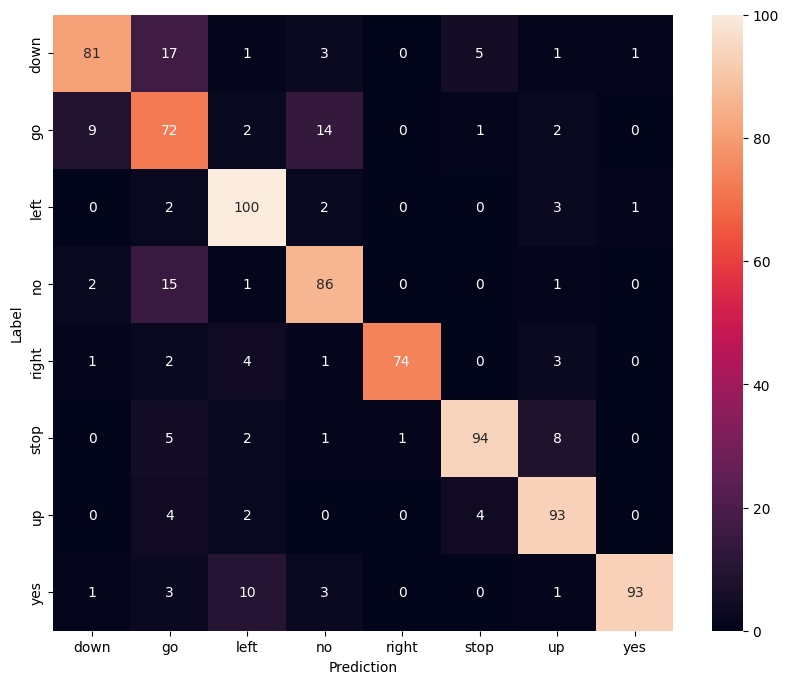
نمایش یک ماتریس سردرگمی
از یک ماتریس سردرگمی استفاده کنید تا بررسی کنید که مدل در طبقه بندی هر یک از دستورات در مجموعه آزمایشی چقدر خوب عمل کرده است:
confusion_mtx = tf.math.confusion_matrix(y_true, y_pred)
plt.figure(figsize=(10, 8))
sns.heatmap(confusion_mtx,
xticklabels=commands,
yticklabels=commands,
annot=True, fmt='g')
plt.xlabel('Prediction')
plt.ylabel('Label')
plt.show()
استنتاج را روی یک فایل صوتی اجرا کنید
در نهایت، خروجی پیشبینی مدل را با استفاده از فایل صوتی ورودی فردی که «نه» میگوید تأیید کنید. مدل شما چقدر خوب عمل می کند؟
sample_file = data_dir/'no/01bb6a2a_nohash_0.wav'
sample_ds = preprocess_dataset([str(sample_file)])
for spectrogram, label in sample_ds.batch(1):
prediction = model(spectrogram)
plt.bar(commands, tf.nn.softmax(prediction[0]))
plt.title(f'Predictions for "{commands[label[0]]}"')
plt.show()
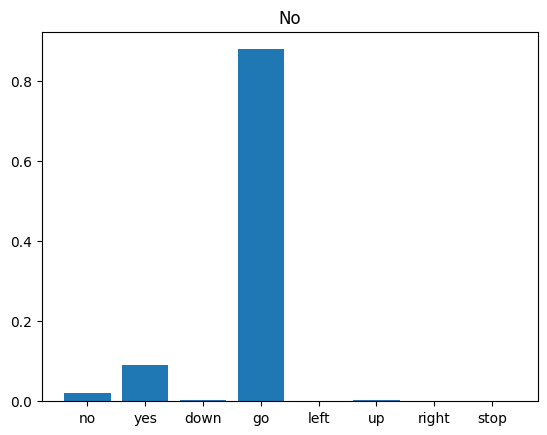
همانطور که خروجی نشان می دهد، مدل شما باید فرمان صوتی را به عنوان "نه" تشخیص می داد.
مراحل بعدی
این آموزش نحوه انجام طبقهبندی صوتی/تشخیص خودکار گفتار ساده را با استفاده از یک شبکه عصبی کانولوشن با TensorFlow و Python نشان میدهد. برای کسب اطلاعات بیشتر، منابع زیر را در نظر بگیرید:
- آموزش طبقه بندی صدا با YAMNet نحوه استفاده از آموزش انتقال را برای طبقه بندی صدا نشان می دهد.
- نوتبوکهای چالش تشخیص گفتار TensorFlow Kaggle .
- TensorFlow.js - تشخیص صدا با استفاده از لبه کد یادگیری انتقالی به شما آموزش می دهد که چگونه برنامه وب تعاملی خود را برای طبقه بندی صدا بسازید.
- آموزش یادگیری عمیق برای بازیابی اطلاعات موسیقی (چوی و همکاران، 2017) در arXiv.
- TensorFlow همچنین دارای پشتیبانی اضافی برای آماده سازی و تقویت داده های صوتی برای کمک به پروژه های مبتنی بر صوتی شما است.
- استفاده از کتابخانه librosa را در نظر بگیرید - یک بسته پایتون برای تجزیه و تحلیل موسیقی و صدا.