
| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub | |
Hướng dẫn này trình bày cách xử lý trước các tệp âm thanh ở định dạng WAV và xây dựng và đào tạo mô hình nhận dạng giọng nói tự động (ASR) cơ bản để nhận dạng mười từ khác nhau. Bạn sẽ sử dụng một phần của tập dữ liệu Speech Commands ( Warden, 2018 ), chứa các đoạn âm thanh ngắn (một giây trở xuống) của các lệnh, chẳng hạn như "xuống", "đi", "trái", "không", " phải "," dừng "," lên "và" có ".
Hệ thống nhận dạng âm thanh và giọng nói trong thế giới thực rất phức tạp. Tuy nhiên, giống như phân loại hình ảnh với bộ dữ liệu MNIST , hướng dẫn này sẽ cung cấp cho bạn hiểu biết cơ bản về các kỹ thuật liên quan.
Thành lập
Nhập các mô-đun và phụ thuộc cần thiết. Lưu ý rằng bạn sẽ sử dụng seaborn để hình dung trong hướng dẫn này.
import os
import pathlib
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import models
from IPython import display
# Set the seed value for experiment reproducibility.
seed = 42
tf.random.set_seed(seed)
np.random.seed(seed)
Nhập tập dữ liệu Lệnh nói nhỏ
Để tiết kiệm thời gian tải dữ liệu, bạn sẽ làm việc với một phiên bản nhỏ hơn của tập dữ liệu Speech Commands. Tập dữ liệu gốc bao gồm hơn 105.000 tệp âm thanh ở định dạng tệp âm thanh WAV (Dạng sóng) của những người nói 35 từ khác nhau. Dữ liệu này được Google thu thập và phát hành theo giấy phép CC BY.
Tải xuống và giải nén tệp mini_speech_commands.zip chứa bộ dữ liệu Speech Commands nhỏ hơn với tf.keras.utils.get_file :
DATASET_PATH = 'data/mini_speech_commands'
data_dir = pathlib.Path(DATASET_PATH)
if not data_dir.exists():
tf.keras.utils.get_file(
'mini_speech_commands.zip',
origin="http://storage.googleapis.com/download.tensorflow.org/data/mini_speech_commands.zip",
extract=True,
cache_dir='.', cache_subdir='data')
Downloading data from http://storage.googleapis.com/download.tensorflow.org/data/mini_speech_commands.zip 182083584/182082353 [==============================] - 1s 0us/step 182091776/182082353 [==============================] - 1s 0us/step
Các đoạn âm thanh của tập dữ liệu được lưu trữ trong tám thư mục tương ứng với mỗi lệnh thoại: no , yes , down , go , left , up , right và stop :
commands = np.array(tf.io.gfile.listdir(str(data_dir)))
commands = commands[commands != 'README.md']
print('Commands:', commands)
Commands: ['stop' 'left' 'no' 'go' 'yes' 'down' 'right' 'up']
Trích xuất các đoạn âm thanh thành một danh sách được gọi là filenames và trộn nó:
filenames = tf.io.gfile.glob(str(data_dir) + '/*/*')
filenames = tf.random.shuffle(filenames)
num_samples = len(filenames)
print('Number of total examples:', num_samples)
print('Number of examples per label:',
len(tf.io.gfile.listdir(str(data_dir/commands[0]))))
print('Example file tensor:', filenames[0])
Number of total examples: 8000 Number of examples per label: 1000 Example file tensor: tf.Tensor(b'data/mini_speech_commands/yes/db72a474_nohash_0.wav', shape=(), dtype=string)
Tách filenames thành các bộ đào tạo, xác thực và kiểm tra theo tỷ lệ 80:10:10, tương ứng:
train_files = filenames[:6400]
val_files = filenames[6400: 6400 + 800]
test_files = filenames[-800:]
print('Training set size', len(train_files))
print('Validation set size', len(val_files))
print('Test set size', len(test_files))
Training set size 6400 Validation set size 800 Test set size 800
Đọc các tệp âm thanh và nhãn của chúng
Trong phần này, bạn sẽ xử lý trước tập dữ liệu, tạo ra các tenxơ được giải mã cho các dạng sóng và các nhãn tương ứng. Lưu ý rằng:
- Mỗi tệp WAV chứa dữ liệu chuỗi thời gian với số lượng mẫu được đặt trên giây.
- Mỗi mẫu đại diện cho biên độ của tín hiệu âm thanh tại thời điểm cụ thể đó.
- Trong hệ thống 16 bit , giống như các tệp WAV trong tập dữ liệu mini Speech Commands, các giá trị biên độ nằm trong khoảng từ -32,768 đến 32,767.
- Tốc độ mẫu cho tập dữ liệu này là 16kHz.
Hình dạng của tensor được trả về bởi tf.audio.decode_wav là [samples, channels] , trong đó channels là 1 đối với đơn âm hoặc 2 đối với âm thanh nổi. Tập dữ liệu mini Speech Commands chỉ chứa các bản ghi đơn âm.
test_file = tf.io.read_file(DATASET_PATH+'/down/0a9f9af7_nohash_0.wav')
test_audio, _ = tf.audio.decode_wav(contents=test_file)
test_audio.shape
TensorShape([13654, 1])
Bây giờ, hãy xác định một chức năng xử lý trước các tệp âm thanh WAV thô của tập dữ liệu thành bộ căng âm thanh:
def decode_audio(audio_binary):
# Decode WAV-encoded audio files to `float32` tensors, normalized
# to the [-1.0, 1.0] range. Return `float32` audio and a sample rate.
audio, _ = tf.audio.decode_wav(contents=audio_binary)
# Since all the data is single channel (mono), drop the `channels`
# axis from the array.
return tf.squeeze(audio, axis=-1)
Xác định một hàm tạo nhãn bằng cách sử dụng các thư mục mẹ cho mỗi tệp:
- Chia các đường dẫn tệp thành các
tf.RaggedTensor(tensor có kích thước rách nát — với các lát cắt có thể có độ dài khác nhau).
def get_label(file_path):
parts = tf.strings.split(
input=file_path,
sep=os.path.sep)
# Note: You'll use indexing here instead of tuple unpacking to enable this
# to work in a TensorFlow graph.
return parts[-2]
Xác định một chức năng trợ giúp get_waveform_and_label hợp tất cả lại với nhau:
- Đầu vào là tên tệp âm thanh WAV.
- Đầu ra là một bộ tuple chứa bộ căng âm thanh và nhãn sẵn sàng cho việc học có giám sát.
def get_waveform_and_label(file_path):
label = get_label(file_path)
audio_binary = tf.io.read_file(file_path)
waveform = decode_audio(audio_binary)
return waveform, label
Xây dựng bộ đào tạo để trích xuất các cặp nhãn âm thanh:
- Tạo
tf.data.DatasetvớiDataset.from_tensor_slicesvàDataset.map, sử dụngget_waveform_and_labelxác định trước đó.
Sau này, bạn sẽ xây dựng bộ xác thực và kiểm tra bằng quy trình tương tự.
AUTOTUNE = tf.data.AUTOTUNE
files_ds = tf.data.Dataset.from_tensor_slices(train_files)
waveform_ds = files_ds.map(
map_func=get_waveform_and_label,
num_parallel_calls=AUTOTUNE)
Hãy vẽ một vài dạng sóng âm thanh:
rows = 3
cols = 3
n = rows * cols
fig, axes = plt.subplots(rows, cols, figsize=(10, 12))
for i, (audio, label) in enumerate(waveform_ds.take(n)):
r = i // cols
c = i % cols
ax = axes[r][c]
ax.plot(audio.numpy())
ax.set_yticks(np.arange(-1.2, 1.2, 0.2))
label = label.numpy().decode('utf-8')
ax.set_title(label)
plt.show()
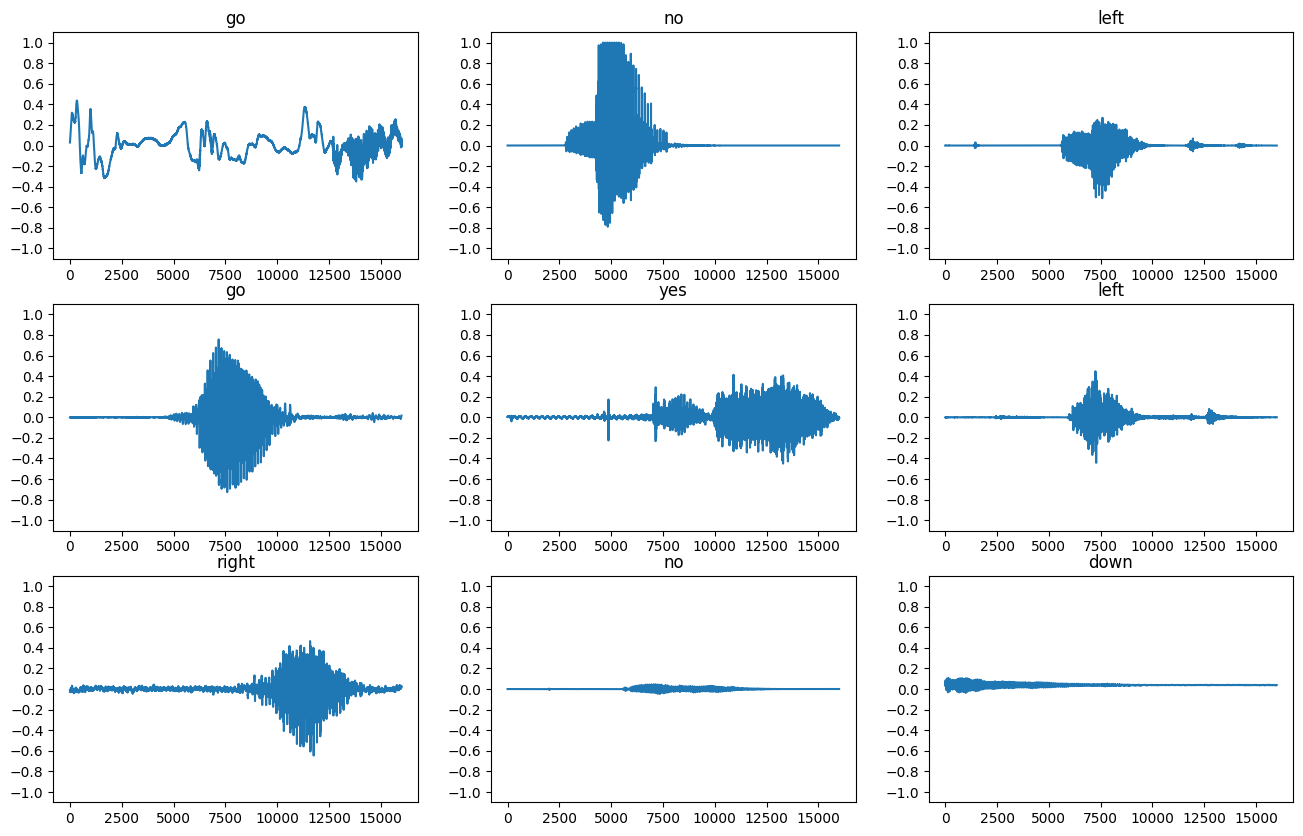
Chuyển đổi dạng sóng thành quang phổ
Các dạng sóng trong tập dữ liệu được biểu diễn trong miền thời gian. Tiếp theo, bạn sẽ biến đổi các dạng sóng từ tín hiệu miền thời gian thành tín hiệu miền tần số thời gian bằng cách tính toán phép biến đổi Fourier trong thời gian ngắn (STFT) để chuyển đổi các dạng sóng thành dạng quang phổ , hiển thị các thay đổi tần số theo thời gian và có thể được biểu diễn dưới dạng hình ảnh 2D. Bạn sẽ cung cấp các hình ảnh quang phổ vào mạng nơ-ron của mình để huấn luyện mô hình.
Một phép biến đổi Fourier ( tf.signal.fft ) chuyển đổi một tín hiệu thành các tần số thành phần của nó, nhưng mất tất cả thông tin thời gian. Trong khi đó, STFT ( tf.signal.stft ) chia tín hiệu thành các cửa sổ thời gian và chạy một biến đổi Fourier trên mỗi cửa sổ, lưu giữ một số thông tin thời gian và trả về một tensor 2D mà bạn có thể chạy tích chập tiêu chuẩn.
Tạo một chức năng tiện ích để chuyển đổi dạng sóng thành quang phổ:
- Các dạng sóng cần phải có cùng độ dài để khi bạn chuyển đổi chúng thành quang phổ, các kết quả có kích thước tương tự. Điều này có thể được thực hiện bằng cách không đệm các đoạn âm thanh ngắn hơn một giây (sử dụng
tf.zeros). - Khi gọi
tf.signal.stft, hãy chọn các tham sốframe_stepframe_lengthcho "hình ảnh" quang phổ được tạo ra gần như là hình vuông. Để biết thêm thông tin về lựa chọn tham số STFT, hãy tham khảo video Coursera này về xử lý tín hiệu âm thanh và STFT. - STFT tạo ra một mảng các số phức biểu thị độ lớn và pha. Tuy nhiên, trong hướng dẫn này, bạn sẽ chỉ sử dụng độ lớn mà bạn có thể lấy được bằng cách áp dụng
tf.abstrên đầu ra củatf.signal.stft.
def get_spectrogram(waveform):
# Zero-padding for an audio waveform with less than 16,000 samples.
input_len = 16000
waveform = waveform[:input_len]
zero_padding = tf.zeros(
[16000] - tf.shape(waveform),
dtype=tf.float32)
# Cast the waveform tensors' dtype to float32.
waveform = tf.cast(waveform, dtype=tf.float32)
# Concatenate the waveform with `zero_padding`, which ensures all audio
# clips are of the same length.
equal_length = tf.concat([waveform, zero_padding], 0)
# Convert the waveform to a spectrogram via a STFT.
spectrogram = tf.signal.stft(
equal_length, frame_length=255, frame_step=128)
# Obtain the magnitude of the STFT.
spectrogram = tf.abs(spectrogram)
# Add a `channels` dimension, so that the spectrogram can be used
# as image-like input data with convolution layers (which expect
# shape (`batch_size`, `height`, `width`, `channels`).
spectrogram = spectrogram[..., tf.newaxis]
return spectrogram
Tiếp theo, bắt đầu khám phá dữ liệu. In các hình dạng của dạng sóng căng thẳng của một ví dụ và biểu đồ quang phổ tương ứng, và phát âm thanh gốc:
for waveform, label in waveform_ds.take(1):
label = label.numpy().decode('utf-8')
spectrogram = get_spectrogram(waveform)
print('Label:', label)
print('Waveform shape:', waveform.shape)
print('Spectrogram shape:', spectrogram.shape)
print('Audio playback')
display.display(display.Audio(waveform, rate=16000))
Label: yes Waveform shape: (16000,) Spectrogram shape: (124, 129, 1) Audio playback
Bây giờ, hãy xác định một hàm để hiển thị một biểu đồ quang phổ:
def plot_spectrogram(spectrogram, ax):
if len(spectrogram.shape) > 2:
assert len(spectrogram.shape) == 3
spectrogram = np.squeeze(spectrogram, axis=-1)
# Convert the frequencies to log scale and transpose, so that the time is
# represented on the x-axis (columns).
# Add an epsilon to avoid taking a log of zero.
log_spec = np.log(spectrogram.T + np.finfo(float).eps)
height = log_spec.shape[0]
width = log_spec.shape[1]
X = np.linspace(0, np.size(spectrogram), num=width, dtype=int)
Y = range(height)
ax.pcolormesh(X, Y, log_spec)
Vẽ biểu đồ dạng sóng của ví dụ theo thời gian và biểu đồ quang phổ tương ứng (tần số theo thời gian):
fig, axes = plt.subplots(2, figsize=(12, 8))
timescale = np.arange(waveform.shape[0])
axes[0].plot(timescale, waveform.numpy())
axes[0].set_title('Waveform')
axes[0].set_xlim([0, 16000])
plot_spectrogram(spectrogram.numpy(), axes[1])
axes[1].set_title('Spectrogram')
plt.show()
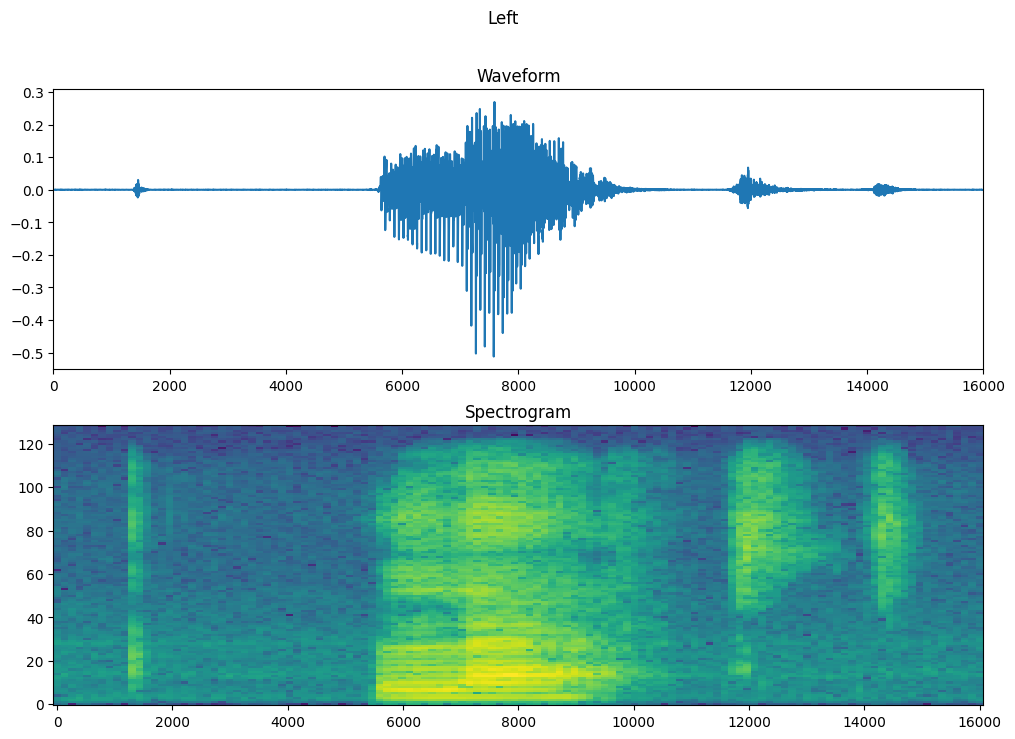
Bây giờ, hãy xác định một hàm biến đổi tập dữ liệu dạng sóng thành các biểu đồ quang phổ và các nhãn tương ứng của chúng dưới dạng ID số nguyên:
def get_spectrogram_and_label_id(audio, label):
spectrogram = get_spectrogram(audio)
label_id = tf.argmax(label == commands)
return spectrogram, label_id
Ánh get_spectrogram_and_label_id qua các phần tử của tập dữ liệu với Dataset.map :
spectrogram_ds = waveform_ds.map(
map_func=get_spectrogram_and_label_id,
num_parallel_calls=AUTOTUNE)
Kiểm tra các biểu đồ quang phổ để biết các ví dụ khác nhau của tập dữ liệu:
rows = 3
cols = 3
n = rows*cols
fig, axes = plt.subplots(rows, cols, figsize=(10, 10))
for i, (spectrogram, label_id) in enumerate(spectrogram_ds.take(n)):
r = i // cols
c = i % cols
ax = axes[r][c]
plot_spectrogram(spectrogram.numpy(), ax)
ax.set_title(commands[label_id.numpy()])
ax.axis('off')
plt.show()
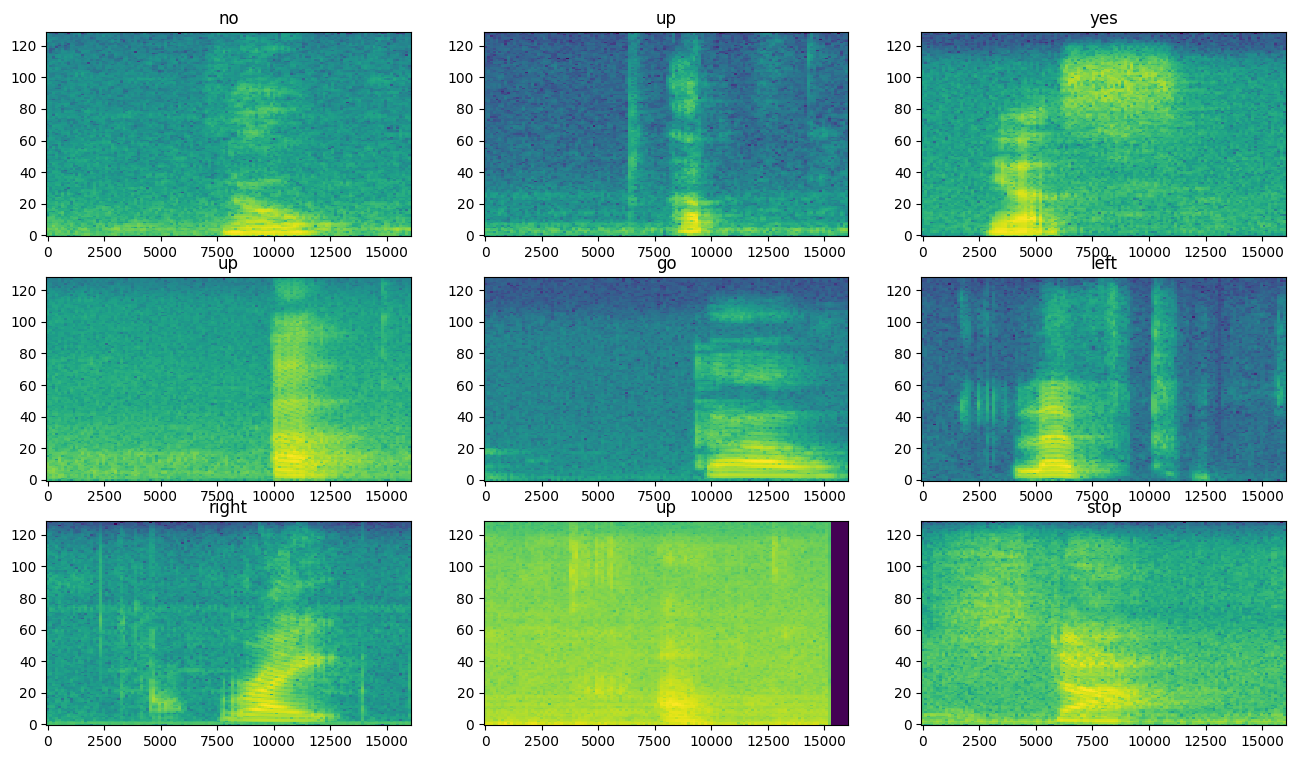
Xây dựng và đào tạo mô hình
Lặp lại quá trình xử lý trước tập huấn luyện trên các tập xác thực và thử nghiệm:
def preprocess_dataset(files):
files_ds = tf.data.Dataset.from_tensor_slices(files)
output_ds = files_ds.map(
map_func=get_waveform_and_label,
num_parallel_calls=AUTOTUNE)
output_ds = output_ds.map(
map_func=get_spectrogram_and_label_id,
num_parallel_calls=AUTOTUNE)
return output_ds
train_ds = spectrogram_ds
val_ds = preprocess_dataset(val_files)
test_ds = preprocess_dataset(test_files)
Hàng loạt các bộ đào tạo và xác nhận cho đào tạo mô hình:
batch_size = 64
train_ds = train_ds.batch(batch_size)
val_ds = val_ds.batch(batch_size)
Thêm các hoạt động Dataset.cache và Dataset.prefetch để giảm độ trễ đọc trong khi đào tạo mô hình:
train_ds = train_ds.cache().prefetch(AUTOTUNE)
val_ds = val_ds.cache().prefetch(AUTOTUNE)
Đối với mô hình, bạn sẽ sử dụng một mạng nơ-ron phức hợp đơn giản (CNN), vì bạn đã chuyển đổi các tệp âm thanh thành hình ảnh quang phổ.
Mô hình tf.keras.Sequential của bạn sẽ sử dụng các lớp tiền xử lý Keras sau:
-
tf.keras.layers.Resizing: để giảm đầu vào mẫu để cho phép mô hình đào tạo nhanh hơn. -
tf.keras.layers.Normalization: để chuẩn hóa từng pixel trong hình ảnh dựa trên giá trị trung bình và độ lệch chuẩn của nó.
Đối với lớp Normalization , phương pháp adapt của nó trước tiên cần được gọi trên dữ liệu huấn luyện để tính toán thống kê tổng hợp (nghĩa là giá trị trung bình và độ lệch chuẩn).
for spectrogram, _ in spectrogram_ds.take(1):
input_shape = spectrogram.shape
print('Input shape:', input_shape)
num_labels = len(commands)
# Instantiate the `tf.keras.layers.Normalization` layer.
norm_layer = layers.Normalization()
# Fit the state of the layer to the spectrograms
# with `Normalization.adapt`.
norm_layer.adapt(data=spectrogram_ds.map(map_func=lambda spec, label: spec))
model = models.Sequential([
layers.Input(shape=input_shape),
# Downsample the input.
layers.Resizing(32, 32),
# Normalize.
norm_layer,
layers.Conv2D(32, 3, activation='relu'),
layers.Conv2D(64, 3, activation='relu'),
layers.MaxPooling2D(),
layers.Dropout(0.25),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dropout(0.5),
layers.Dense(num_labels),
])
model.summary()
Input shape: (124, 129, 1)
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
resizing (Resizing) (None, 32, 32, 1) 0
normalization (Normalizatio (None, 32, 32, 1) 3
n)
conv2d (Conv2D) (None, 30, 30, 32) 320
conv2d_1 (Conv2D) (None, 28, 28, 64) 18496
max_pooling2d (MaxPooling2D (None, 14, 14, 64) 0
)
dropout (Dropout) (None, 14, 14, 64) 0
flatten (Flatten) (None, 12544) 0
dense (Dense) (None, 128) 1605760
dropout_1 (Dropout) (None, 128) 0
dense_1 (Dense) (None, 8) 1032
=================================================================
Total params: 1,625,611
Trainable params: 1,625,608
Non-trainable params: 3
_________________________________________________________________
Định cấu hình mô hình Keras với trình tối ưu hóa Adam và sự mất mát entropy chéo:
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'],
)
Huấn luyện mô hình hơn 10 kỷ nguyên cho mục đích trình diễn:
EPOCHS = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=EPOCHS,
callbacks=tf.keras.callbacks.EarlyStopping(verbose=1, patience=2),
)
Epoch 1/10 100/100 [==============================] - 6s 41ms/step - loss: 1.7503 - accuracy: 0.3630 - val_loss: 1.2850 - val_accuracy: 0.5763 Epoch 2/10 100/100 [==============================] - 0s 5ms/step - loss: 1.2101 - accuracy: 0.5698 - val_loss: 0.9314 - val_accuracy: 0.6913 Epoch 3/10 100/100 [==============================] - 0s 5ms/step - loss: 0.9336 - accuracy: 0.6703 - val_loss: 0.7529 - val_accuracy: 0.7325 Epoch 4/10 100/100 [==============================] - 0s 5ms/step - loss: 0.7503 - accuracy: 0.7397 - val_loss: 0.6721 - val_accuracy: 0.7713 Epoch 5/10 100/100 [==============================] - 0s 5ms/step - loss: 0.6367 - accuracy: 0.7741 - val_loss: 0.6061 - val_accuracy: 0.7975 Epoch 6/10 100/100 [==============================] - 0s 5ms/step - loss: 0.5650 - accuracy: 0.7987 - val_loss: 0.5489 - val_accuracy: 0.8125 Epoch 7/10 100/100 [==============================] - 0s 5ms/step - loss: 0.5099 - accuracy: 0.8183 - val_loss: 0.5344 - val_accuracy: 0.8238 Epoch 8/10 100/100 [==============================] - 0s 5ms/step - loss: 0.4560 - accuracy: 0.8392 - val_loss: 0.5194 - val_accuracy: 0.8288 Epoch 9/10 100/100 [==============================] - 0s 5ms/step - loss: 0.4101 - accuracy: 0.8547 - val_loss: 0.4809 - val_accuracy: 0.8388 Epoch 10/10 100/100 [==============================] - 0s 5ms/step - loss: 0.3905 - accuracy: 0.8589 - val_loss: 0.4973 - val_accuracy: 0.8363
Hãy vẽ biểu đồ các đường cong mất mát trong quá trình đào tạo và xác thực để kiểm tra xem mô hình của bạn đã được cải thiện như thế nào trong quá trình đào tạo:
metrics = history.history
plt.plot(history.epoch, metrics['loss'], metrics['val_loss'])
plt.legend(['loss', 'val_loss'])
plt.show()

Đánh giá hiệu suất mô hình
Chạy mô hình trên bộ thử nghiệm và kiểm tra hoạt động của mô hình:
test_audio = []
test_labels = []
for audio, label in test_ds:
test_audio.append(audio.numpy())
test_labels.append(label.numpy())
test_audio = np.array(test_audio)
test_labels = np.array(test_labels)
y_pred = np.argmax(model.predict(test_audio), axis=1)
y_true = test_labels
test_acc = sum(y_pred == y_true) / len(y_true)
print(f'Test set accuracy: {test_acc:.0%}')
Test set accuracy: 85%
Hiển thị một ma trận nhầm lẫn
Sử dụng ma trận nhầm lẫn để kiểm tra xem mô hình đã phân loại từng lệnh trong bộ kiểm tra tốt như thế nào:
confusion_mtx = tf.math.confusion_matrix(y_true, y_pred)
plt.figure(figsize=(10, 8))
sns.heatmap(confusion_mtx,
xticklabels=commands,
yticklabels=commands,
annot=True, fmt='g')
plt.xlabel('Prediction')
plt.ylabel('Label')
plt.show()
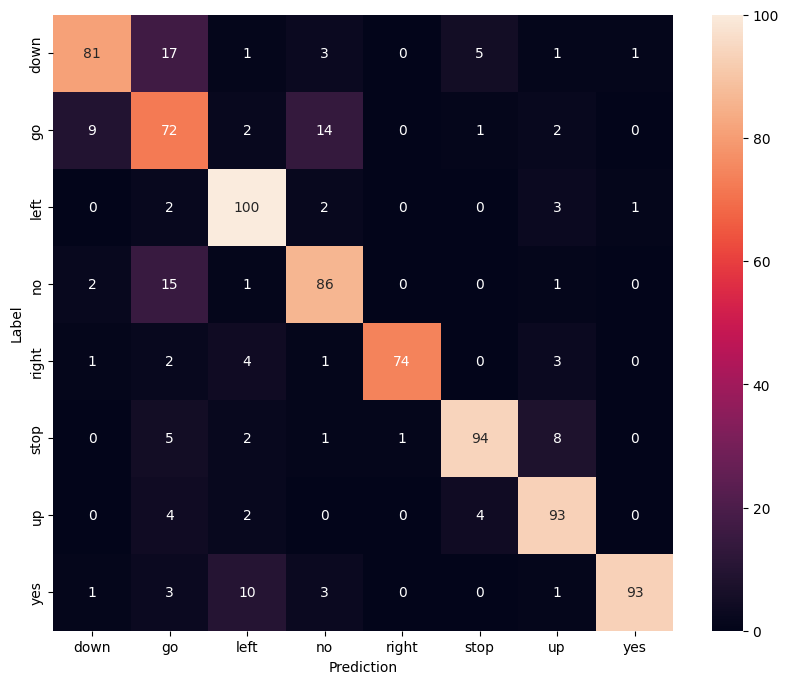
Chạy suy luận trên tệp âm thanh
Cuối cùng, xác minh kết quả dự đoán của mô hình bằng cách sử dụng tệp âm thanh đầu vào của người nào đó nói "không". Mô hình của bạn hoạt động tốt như thế nào?
sample_file = data_dir/'no/01bb6a2a_nohash_0.wav'
sample_ds = preprocess_dataset([str(sample_file)])
for spectrogram, label in sample_ds.batch(1):
prediction = model(spectrogram)
plt.bar(commands, tf.nn.softmax(prediction[0]))
plt.title(f'Predictions for "{commands[label[0]]}"')
plt.show()

Như đầu ra gợi ý, mô hình của bạn phải nhận ra lệnh âm thanh là "không".
Bước tiếp theo
Hướng dẫn này đã trình bày cách thực hiện phân loại âm thanh đơn giản / nhận dạng giọng nói tự động bằng cách sử dụng mạng nơ-ron phức hợp với TensorFlow và Python. Để tìm hiểu thêm, hãy xem xét các tài nguyên sau:
- Hướng dẫn phân loại âm thanh với YAMNet cho thấy cách sử dụng tính năng học truyền để phân loại âm thanh.
- Các sổ ghi chép từ thử thách nhận dạng giọng nói TensorFlow của Kaggle .
- TensorFlow.js - Nhận dạng âm thanh bằng cách sử dụng codelab học truyền dạy cách xây dựng ứng dụng web tương tác của riêng bạn để phân loại âm thanh.
- Hướng dẫn về học sâu để truy xuất thông tin âm nhạc (Choi và cộng sự, 2017) trên arXiv.
- TensorFlow cũng có hỗ trợ bổ sung cho việc chuẩn bị và tăng cường dữ liệu âm thanh để giúp thực hiện các dự án dựa trên âm thanh của riêng bạn.
- Cân nhắc sử dụng thư viện librosa — một gói Python để phân tích âm thanh và nhạc.