
| | |  Kaynağı GitHub'da görüntüleyin Kaynağı GitHub'da görüntüleyin | |
Bu öğretici, WAV formatındaki ses dosyalarının nasıl önceden işleneceğini ve on farklı kelimeyi tanımak için temel bir otomatik konuşma tanıma (ASR) modelinin nasıl oluşturulacağını ve eğitileceğini gösterir. "Aşağı", "git", "sol", "hayır", "gibi komutların kısa (bir saniye veya daha az) ses kliplerini içeren Konuşma Komutları veri kümesinin ( Warden, 2018 ) bir bölümünü kullanacaksınız. sağ", "dur", "yukarı" ve "evet".
Gerçek dünyadaki konuşma ve ses tanıma sistemleri karmaşıktır. Ancak, MNIST veri kümesiyle görüntü sınıflandırması gibi, bu eğitim size ilgili teknikler hakkında temel bir anlayış vermelidir.
Kurmak
Gerekli modülleri ve bağımlılıkları içe aktarın. Bu eğitimde görselleştirme için seaborn kullanacağınızı unutmayın.
import os
import pathlib
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import models
from IPython import display
# Set the seed value for experiment reproducibility.
seed = 42
tf.random.set_seed(seed)
np.random.seed(seed)
Mini Konuşma Komutları veri kümesini içe aktarın
Veri yüklemeyle zaman kazanmak için Konuşma Komutları veri kümesinin daha küçük bir sürümüyle çalışacaksınız. Orijinal veri seti , 35 farklı kelime söyleyen kişilerin WAV (Dalga formu) ses dosyası formatında 105.000'den fazla ses dosyasından oluşur. Bu veriler Google tarafından toplandı ve bir CC BY lisansı altında yayınlandı.
tf.keras.utils.get_file ile daha küçük Konuşma Komutları veri kümelerini içeren mini_speech_commands.zip dosyasını indirin ve tf.keras.utils.get_file :
DATASET_PATH = 'data/mini_speech_commands'
data_dir = pathlib.Path(DATASET_PATH)
if not data_dir.exists():
tf.keras.utils.get_file(
'mini_speech_commands.zip',
origin="http://storage.googleapis.com/download.tensorflow.org/data/mini_speech_commands.zip",
extract=True,
cache_dir='.', cache_subdir='data')
Downloading data from http://storage.googleapis.com/download.tensorflow.org/data/mini_speech_commands.zip 182083584/182082353 [==============================] - 1s 0us/step 182091776/182082353 [==============================] - 1s 0us/step
Veri kümesinin ses klipleri, her konuşma komutuna karşılık gelen sekiz klasörde depolanır: no , yes , down , go , left , up , right ve stop :
commands = np.array(tf.io.gfile.listdir(str(data_dir)))
commands = commands[commands != 'README.md']
print('Commands:', commands)
Commands: ['stop' 'left' 'no' 'go' 'yes' 'down' 'right' 'up']
Ses kliplerini filenames adlı bir listeye çıkarın ve karıştırın:
filenames = tf.io.gfile.glob(str(data_dir) + '/*/*')
filenames = tf.random.shuffle(filenames)
num_samples = len(filenames)
print('Number of total examples:', num_samples)
print('Number of examples per label:',
len(tf.io.gfile.listdir(str(data_dir/commands[0]))))
print('Example file tensor:', filenames[0])
Number of total examples: 8000 Number of examples per label: 1000 Example file tensor: tf.Tensor(b'data/mini_speech_commands/yes/db72a474_nohash_0.wav', shape=(), dtype=string)
filenames sırasıyla 80:10:10 oranını kullanarak eğitim, doğrulama ve test kümelerine ayırın:
train_files = filenames[:6400]
val_files = filenames[6400: 6400 + 800]
test_files = filenames[-800:]
print('Training set size', len(train_files))
print('Validation set size', len(val_files))
print('Test set size', len(test_files))
Training set size 6400 Validation set size 800 Test set size 800
Ses dosyalarını ve etiketlerini okuyun
Bu bölümde, dalga formları ve ilgili etiketler için kodu çözülmüş tensörler oluşturarak veri setini önceden işleyeceksiniz. Bunu not et:
- Her WAV dosyası, saniyede belirli sayıda örnek içeren zaman serisi verileri içerir.
- Her örnek, o belirli zamandaki ses sinyalinin genliğini temsil eder.
- 16 bitlik bir sistemde, mini Konuşma Komutları veri setindeki WAV dosyaları gibi, genlik değerleri -32.768 ile 32.767 arasında değişir.
- Bu veri seti için örnekleme hızı 16kHz'dir.
tf.audio.decode_wav tarafından döndürülen tensörün şekli [samples, channels] şeklindedir, burada channels mono için 1 veya stereo için 2 . Mini Konuşma Komutları veri kümesi yalnızca mono kayıtları içerir.
test_file = tf.io.read_file(DATASET_PATH+'/down/0a9f9af7_nohash_0.wav')
test_audio, _ = tf.audio.decode_wav(contents=test_file)
test_audio.shape
TensorShape([13654, 1])
Şimdi, veri kümesinin ham WAV ses dosyalarını ses tensörlerine önişleyen bir işlev tanımlayalım:
def decode_audio(audio_binary):
# Decode WAV-encoded audio files to `float32` tensors, normalized
# to the [-1.0, 1.0] range. Return `float32` audio and a sample rate.
audio, _ = tf.audio.decode_wav(contents=audio_binary)
# Since all the data is single channel (mono), drop the `channels`
# axis from the array.
return tf.squeeze(audio, axis=-1)
Her dosya için üst dizinleri kullanarak etiketler oluşturan bir işlev tanımlayın:
- Dosya yollarını
tf.RaggedTensors'ye bölün (düzensiz boyutlara sahip tensörler - farklı uzunluklara sahip olabilen dilimlere sahip).
def get_label(file_path):
parts = tf.strings.split(
input=file_path,
sep=os.path.sep)
# Note: You'll use indexing here instead of tuple unpacking to enable this
# to work in a TensorFlow graph.
return parts[-2]
Hepsini bir araya getiren başka bir yardımcı işlev - get_waveform_and_label - tanımlayın:
- Giriş, WAV ses dosyası adıdır.
- Çıktı, denetimli öğrenmeye hazır ses ve etiket tensörlerini içeren bir demettir.
def get_waveform_and_label(file_path):
label = get_label(file_path)
audio_binary = tf.io.read_file(file_path)
waveform = decode_audio(audio_binary)
return waveform, label
Ses etiketi çiftlerini çıkarmak için eğitim setini oluşturun:
- Daha önce tanımlanan
get_waveform_and_labelkullanarakDataset.from_tensor_slicesveDataset.mapile birtf.data.Datasetoluşturun.
Daha sonra benzer bir prosedür kullanarak doğrulama ve test setlerini oluşturacaksınız.
AUTOTUNE = tf.data.AUTOTUNE
files_ds = tf.data.Dataset.from_tensor_slices(train_files)
waveform_ds = files_ds.map(
map_func=get_waveform_and_label,
num_parallel_calls=AUTOTUNE)
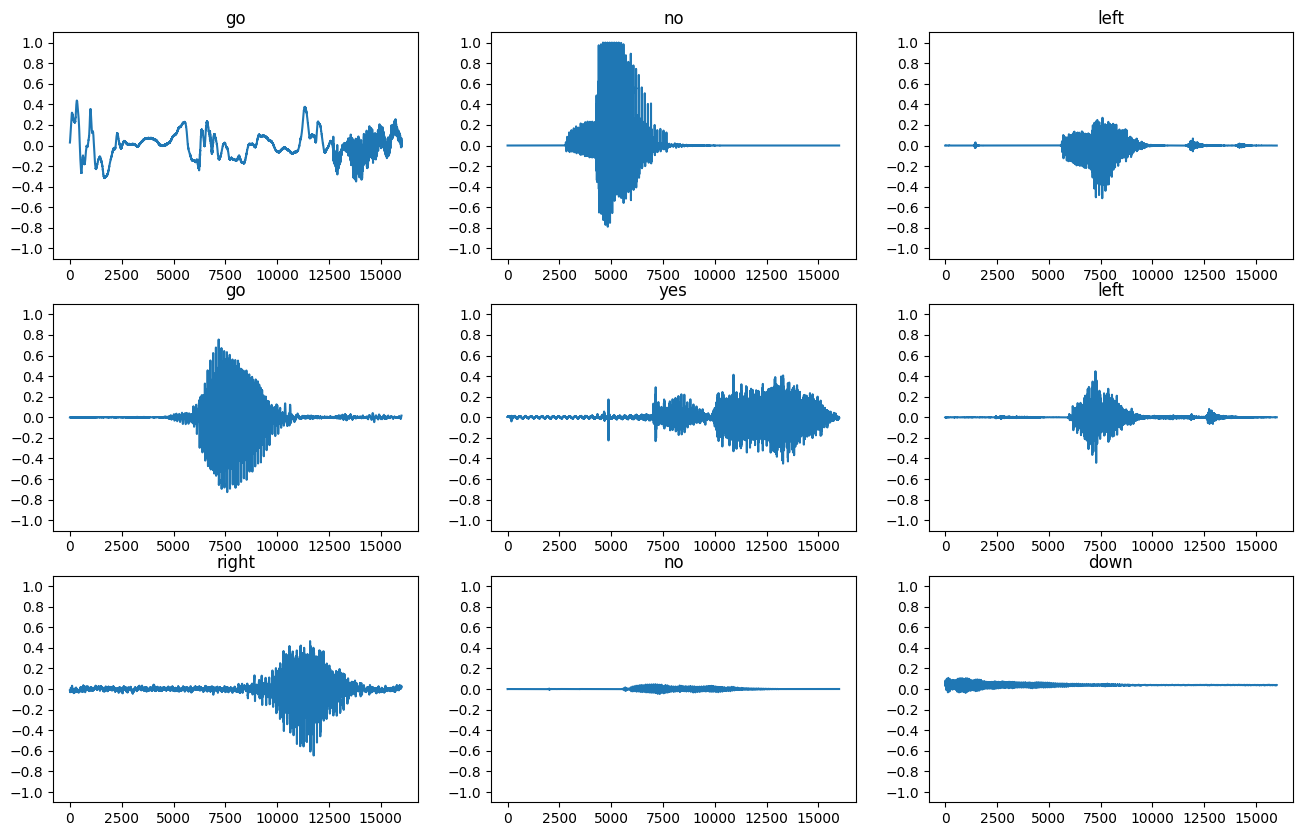
Birkaç ses dalga biçimi çizelim:
rows = 3
cols = 3
n = rows * cols
fig, axes = plt.subplots(rows, cols, figsize=(10, 12))
for i, (audio, label) in enumerate(waveform_ds.take(n)):
r = i // cols
c = i % cols
ax = axes[r][c]
ax.plot(audio.numpy())
ax.set_yticks(np.arange(-1.2, 1.2, 0.2))
label = label.numpy().decode('utf-8')
ax.set_title(label)
plt.show()
Dalga formlarını spektrogramlara dönüştürün
Veri kümesindeki dalga biçimleri zaman alanında temsil edilir. Ardından, dalga biçimlerini zaman içinde frekans değişikliklerini gösteren ve dalga biçimlerini spektrogramlara dönüştürmek için kısa süreli Fourier dönüşümünü (STFT) hesaplayarak dalga biçimlerini zaman etki alanı sinyallerinden zaman-frekans etki alanı sinyallerine dönüştüreceksiniz. 2D görüntüler olarak temsil edilir. Modeli eğitmek için spektrogram görüntülerini sinir ağınıza besleyeceksiniz.
Fourier dönüşümü ( tf.signal.fft ) bir sinyali bileşen frekanslarına dönüştürür, ancak tüm zaman bilgilerini kaybeder. Buna karşılık, STFT ( tf.signal.stft ) sinyali zaman pencerelerine böler ve her pencerede bir Fourier dönüşümü çalıştırarak zaman bilgisini korur ve üzerinde standart evrişimleri çalıştırabileceğiniz bir 2D tensörü döndürür.
Dalga biçimlerini spektrogramlara dönüştürmek için bir yardımcı program işlevi oluşturun:
- Dalga biçimlerinin aynı uzunlukta olması gerekir, böylece onları spektrogramlara dönüştürdüğünüzde sonuçlar benzer boyutlara sahip olur. Bu, bir saniyeden kısa olan ses kliplerini sıfırlayarak yapılabilir (
tf.zeroskullanılarak). -
tf.signal.stft,frame_lengthveframe_stepparametrelerini, oluşturulan spektrogram "görüntü" neredeyse kare olacak şekilde seçin. STFT parametreleri seçimi hakkında daha fazla bilgi için, ses sinyali işleme ve STFT ile ilgili bu Coursera videosuna bakın. - STFT, büyüklük ve fazı temsil eden bir dizi karmaşık sayı üretir. Ancak, bu öğreticide yalnızca
tf.absçıktısınatf.signal.stftuygulayarak türetebileceğiniz büyüklüğü kullanacaksınız.
def get_spectrogram(waveform):
# Zero-padding for an audio waveform with less than 16,000 samples.
input_len = 16000
waveform = waveform[:input_len]
zero_padding = tf.zeros(
[16000] - tf.shape(waveform),
dtype=tf.float32)
# Cast the waveform tensors' dtype to float32.
waveform = tf.cast(waveform, dtype=tf.float32)
# Concatenate the waveform with `zero_padding`, which ensures all audio
# clips are of the same length.
equal_length = tf.concat([waveform, zero_padding], 0)
# Convert the waveform to a spectrogram via a STFT.
spectrogram = tf.signal.stft(
equal_length, frame_length=255, frame_step=128)
# Obtain the magnitude of the STFT.
spectrogram = tf.abs(spectrogram)
# Add a `channels` dimension, so that the spectrogram can be used
# as image-like input data with convolution layers (which expect
# shape (`batch_size`, `height`, `width`, `channels`).
spectrogram = spectrogram[..., tf.newaxis]
return spectrogram
Ardından, verileri keşfetmeye başlayın. Bir örneğin gerginleştirilmiş dalga formunun ve ilgili spektrogramın şekillerini yazdırın ve orijinal sesi çalın:
for waveform, label in waveform_ds.take(1):
label = label.numpy().decode('utf-8')
spectrogram = get_spectrogram(waveform)
print('Label:', label)
print('Waveform shape:', waveform.shape)
print('Spectrogram shape:', spectrogram.shape)
print('Audio playback')
display.display(display.Audio(waveform, rate=16000))
Label: yes Waveform shape: (16000,) Spectrogram shape: (124, 129, 1) Audio playback
Şimdi, bir spektrogramı görüntülemek için bir fonksiyon tanımlayın:
def plot_spectrogram(spectrogram, ax):
if len(spectrogram.shape) > 2:
assert len(spectrogram.shape) == 3
spectrogram = np.squeeze(spectrogram, axis=-1)
# Convert the frequencies to log scale and transpose, so that the time is
# represented on the x-axis (columns).
# Add an epsilon to avoid taking a log of zero.
log_spec = np.log(spectrogram.T + np.finfo(float).eps)
height = log_spec.shape[0]
width = log_spec.shape[1]
X = np.linspace(0, np.size(spectrogram), num=width, dtype=int)
Y = range(height)
ax.pcolormesh(X, Y, log_spec)
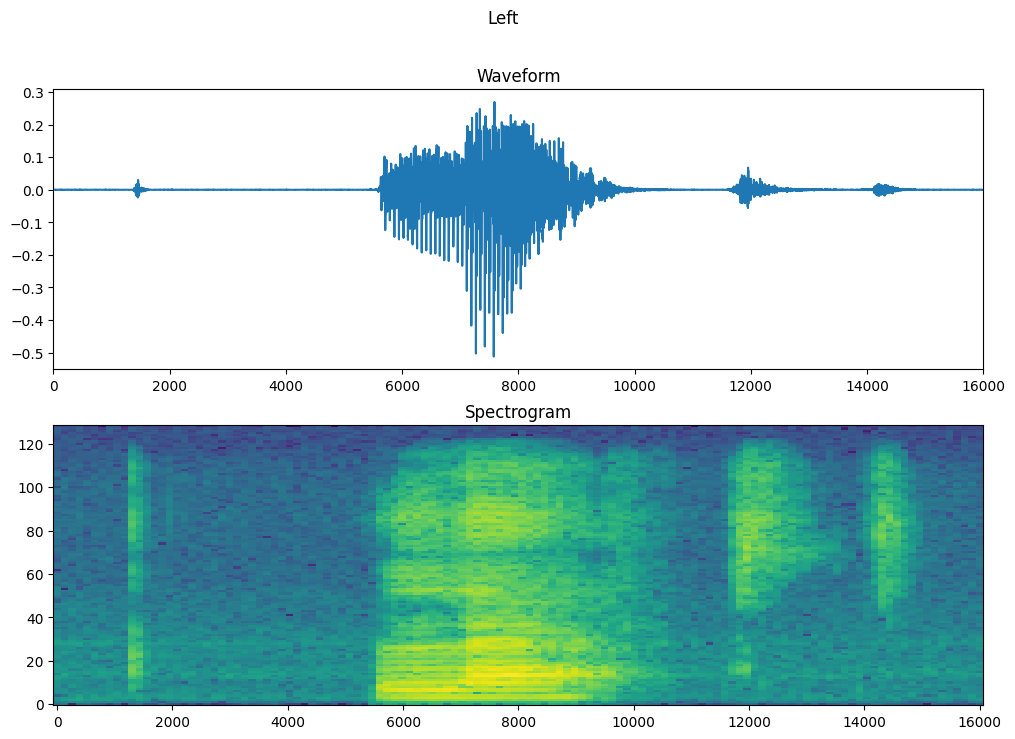
Örneğin zaman içindeki dalga biçimini ve karşılık gelen spektrogramı (zaman içindeki frekanslar) çizin:
fig, axes = plt.subplots(2, figsize=(12, 8))
timescale = np.arange(waveform.shape[0])
axes[0].plot(timescale, waveform.numpy())
axes[0].set_title('Waveform')
axes[0].set_xlim([0, 16000])
plot_spectrogram(spectrogram.numpy(), axes[1])
axes[1].set_title('Spectrogram')
plt.show()
Şimdi, dalga biçimi veri kümesini spektrogramlara ve bunlara karşılık gelen etiketleri tamsayı kimlikleri olarak dönüştüren bir işlev tanımlayın:
def get_spectrogram_and_label_id(audio, label):
spectrogram = get_spectrogram(audio)
label_id = tf.argmax(label == commands)
return spectrogram, label_id
get_spectrogram_and_label_id ile Dataset.map veri kümesinin öğeleri arasında eşleyin:
spectrogram_ds = waveform_ds.map(
map_func=get_spectrogram_and_label_id,
num_parallel_calls=AUTOTUNE)
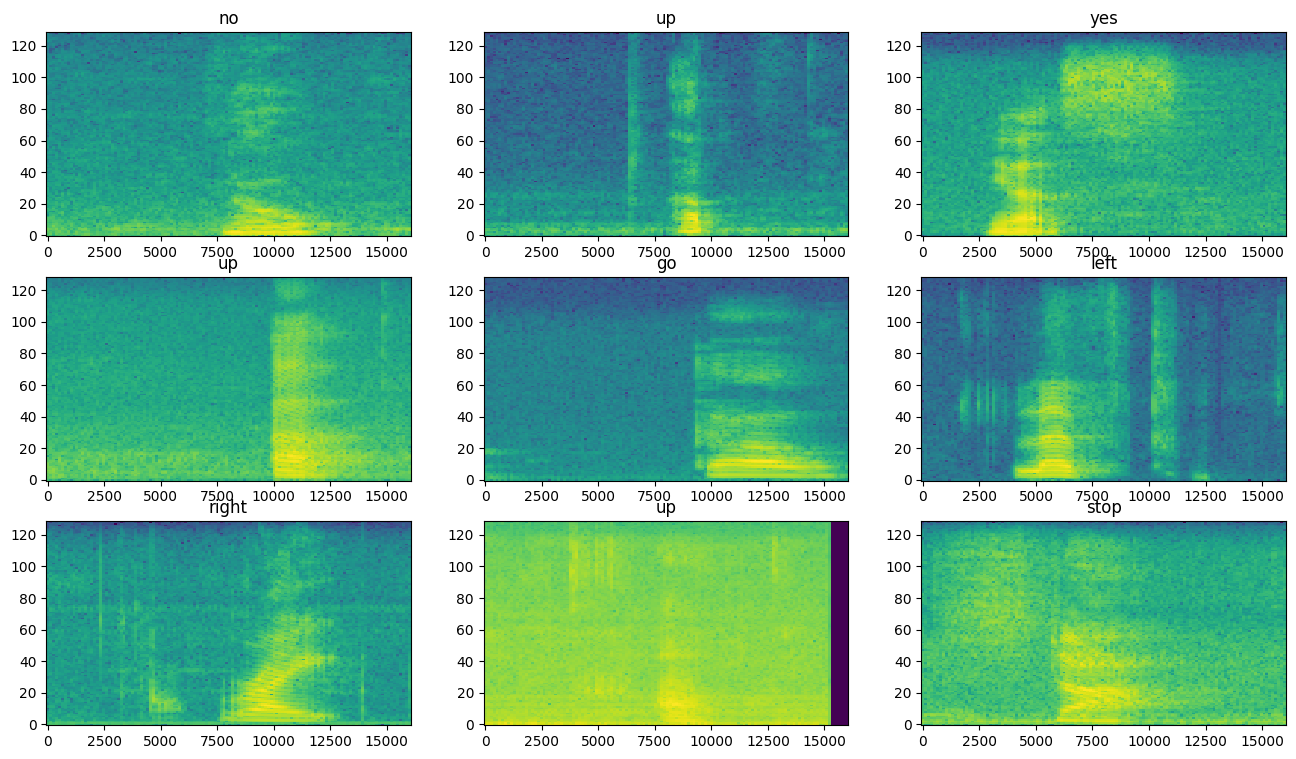
Veri kümesinin farklı örnekleri için spektrogramları inceleyin:
rows = 3
cols = 3
n = rows*cols
fig, axes = plt.subplots(rows, cols, figsize=(10, 10))
for i, (spectrogram, label_id) in enumerate(spectrogram_ds.take(n)):
r = i // cols
c = i % cols
ax = axes[r][c]
plot_spectrogram(spectrogram.numpy(), ax)
ax.set_title(commands[label_id.numpy()])
ax.axis('off')
plt.show()
Modeli oluşturun ve eğitin
Doğrulama ve test setlerinde eğitim seti ön işlemesini tekrarlayın:
def preprocess_dataset(files):
files_ds = tf.data.Dataset.from_tensor_slices(files)
output_ds = files_ds.map(
map_func=get_waveform_and_label,
num_parallel_calls=AUTOTUNE)
output_ds = output_ds.map(
map_func=get_spectrogram_and_label_id,
num_parallel_calls=AUTOTUNE)
return output_ds
train_ds = spectrogram_ds
val_ds = preprocess_dataset(val_files)
test_ds = preprocess_dataset(test_files)
Model eğitimi için eğitim ve doğrulama kümelerini toplu olarak oluşturun:
batch_size = 64
train_ds = train_ds.batch(batch_size)
val_ds = val_ds.batch(batch_size)
Modeli eğitirken okuma gecikmesini azaltmak için Dataset.cache ve Dataset.prefetch işlemlerini ekleyin:
train_ds = train_ds.cache().prefetch(AUTOTUNE)
val_ds = val_ds.cache().prefetch(AUTOTUNE)
Ses dosyalarını spektrogram görüntülerine dönüştürdüğünüz için model için basit bir evrişimli sinir ağı (CNN) kullanacaksınız.
tf.keras.Sequential modeliniz aşağıdaki Keras ön işleme katmanlarını kullanacaktır:
-
tf.keras.layers.Resizing: modelin daha hızlı çalışmasını sağlamak için girdiyi aşağı örneklemek için. -
tf.keras.layers.Normalization: görüntüdeki her pikseli ortalama ve standart sapmaya göre normalleştirmek için.
Normalization katmanı için, toplama istatistiklerini (yani ortalama ve standart sapmayı) hesaplamak için ilk olarak eğitim verilerinde adapt yönteminin çağrılması gerekir.
for spectrogram, _ in spectrogram_ds.take(1):
input_shape = spectrogram.shape
print('Input shape:', input_shape)
num_labels = len(commands)
# Instantiate the `tf.keras.layers.Normalization` layer.
norm_layer = layers.Normalization()
# Fit the state of the layer to the spectrograms
# with `Normalization.adapt`.
norm_layer.adapt(data=spectrogram_ds.map(map_func=lambda spec, label: spec))
model = models.Sequential([
layers.Input(shape=input_shape),
# Downsample the input.
layers.Resizing(32, 32),
# Normalize.
norm_layer,
layers.Conv2D(32, 3, activation='relu'),
layers.Conv2D(64, 3, activation='relu'),
layers.MaxPooling2D(),
layers.Dropout(0.25),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dropout(0.5),
layers.Dense(num_labels),
])
model.summary()
Input shape: (124, 129, 1)
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
resizing (Resizing) (None, 32, 32, 1) 0
normalization (Normalizatio (None, 32, 32, 1) 3
n)
conv2d (Conv2D) (None, 30, 30, 32) 320
conv2d_1 (Conv2D) (None, 28, 28, 64) 18496
max_pooling2d (MaxPooling2D (None, 14, 14, 64) 0
)
dropout (Dropout) (None, 14, 14, 64) 0
flatten (Flatten) (None, 12544) 0
dense (Dense) (None, 128) 1605760
dropout_1 (Dropout) (None, 128) 0
dense_1 (Dense) (None, 8) 1032
=================================================================
Total params: 1,625,611
Trainable params: 1,625,608
Non-trainable params: 3
_________________________________________________________________
Keras modelini Adam optimize edici ve çapraz entropi kaybıyla yapılandırın:
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'],
)
Gösteri amacıyla modeli 10 çağdan fazla eğitin:
EPOCHS = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=EPOCHS,
callbacks=tf.keras.callbacks.EarlyStopping(verbose=1, patience=2),
)
Epoch 1/10 100/100 [==============================] - 6s 41ms/step - loss: 1.7503 - accuracy: 0.3630 - val_loss: 1.2850 - val_accuracy: 0.5763 Epoch 2/10 100/100 [==============================] - 0s 5ms/step - loss: 1.2101 - accuracy: 0.5698 - val_loss: 0.9314 - val_accuracy: 0.6913 Epoch 3/10 100/100 [==============================] - 0s 5ms/step - loss: 0.9336 - accuracy: 0.6703 - val_loss: 0.7529 - val_accuracy: 0.7325 Epoch 4/10 100/100 [==============================] - 0s 5ms/step - loss: 0.7503 - accuracy: 0.7397 - val_loss: 0.6721 - val_accuracy: 0.7713 Epoch 5/10 100/100 [==============================] - 0s 5ms/step - loss: 0.6367 - accuracy: 0.7741 - val_loss: 0.6061 - val_accuracy: 0.7975 Epoch 6/10 100/100 [==============================] - 0s 5ms/step - loss: 0.5650 - accuracy: 0.7987 - val_loss: 0.5489 - val_accuracy: 0.8125 Epoch 7/10 100/100 [==============================] - 0s 5ms/step - loss: 0.5099 - accuracy: 0.8183 - val_loss: 0.5344 - val_accuracy: 0.8238 Epoch 8/10 100/100 [==============================] - 0s 5ms/step - loss: 0.4560 - accuracy: 0.8392 - val_loss: 0.5194 - val_accuracy: 0.8288 Epoch 9/10 100/100 [==============================] - 0s 5ms/step - loss: 0.4101 - accuracy: 0.8547 - val_loss: 0.4809 - val_accuracy: 0.8388 Epoch 10/10 100/100 [==============================] - 0s 5ms/step - loss: 0.3905 - accuracy: 0.8589 - val_loss: 0.4973 - val_accuracy: 0.8363
Modelinizin eğitim sırasında nasıl geliştiğini kontrol etmek için eğitim ve doğrulama kaybı eğrilerini çizelim:
metrics = history.history
plt.plot(history.epoch, metrics['loss'], metrics['val_loss'])
plt.legend(['loss', 'val_loss'])
plt.show()

Model performansını değerlendirin
Modeli test setinde çalıştırın ve modelin performansını kontrol edin:
test_audio = []
test_labels = []
for audio, label in test_ds:
test_audio.append(audio.numpy())
test_labels.append(label.numpy())
test_audio = np.array(test_audio)
test_labels = np.array(test_labels)
y_pred = np.argmax(model.predict(test_audio), axis=1)
y_true = test_labels
test_acc = sum(y_pred == y_true) / len(y_true)
print(f'Test set accuracy: {test_acc:.0%}')
Test set accuracy: 85%
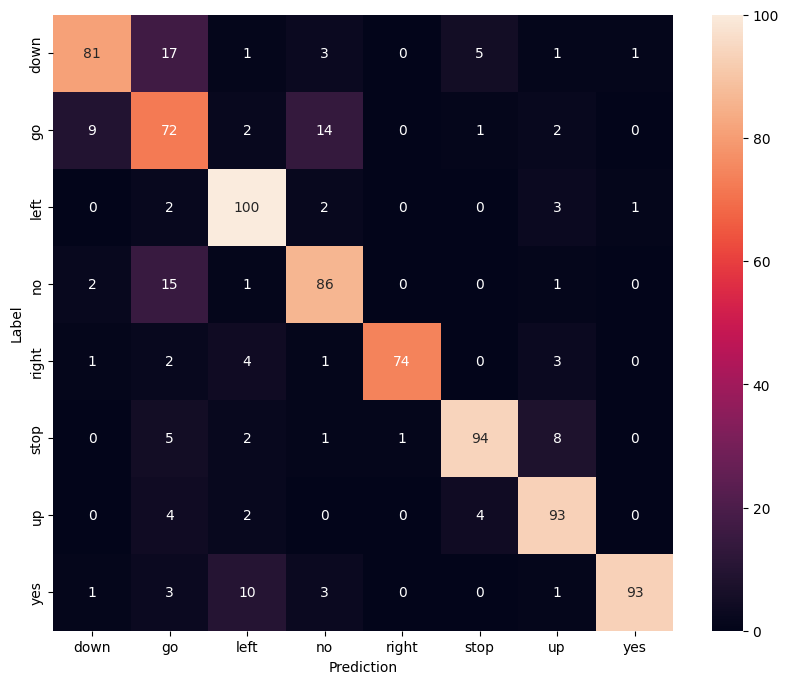
Bir karışıklık matrisi göster
Modelin test setindeki komutların her birini ne kadar iyi sınıflandırdığını kontrol etmek için bir karışıklık matrisi kullanın:
confusion_mtx = tf.math.confusion_matrix(y_true, y_pred)
plt.figure(figsize=(10, 8))
sns.heatmap(confusion_mtx,
xticklabels=commands,
yticklabels=commands,
annot=True, fmt='g')
plt.xlabel('Prediction')
plt.ylabel('Label')
plt.show()
Bir ses dosyasında çıkarımı çalıştır
Son olarak, "hayır" diyen birinin giriş ses dosyasını kullanarak modelin tahmin çıktısını doğrulayın. Modeliniz ne kadar iyi performans gösteriyor?
sample_file = data_dir/'no/01bb6a2a_nohash_0.wav'
sample_ds = preprocess_dataset([str(sample_file)])
for spectrogram, label in sample_ds.batch(1):
prediction = model(spectrogram)
plt.bar(commands, tf.nn.softmax(prediction[0]))
plt.title(f'Predictions for "{commands[label[0]]}"')
plt.show()

Çıktının önerdiği gibi, modelinizin sesli komutu "hayır" olarak tanıması gerekir.
Sonraki adımlar
Bu öğretici, TensorFlow ve Python ile evrişimli bir sinir ağı kullanarak basit ses sınıflandırmasının/otomatik konuşma tanımanın nasıl gerçekleştirileceğini gösterdi. Daha fazla bilgi edinmek için aşağıdaki kaynakları göz önünde bulundurun:
- YAMNet öğreticisiyle Ses sınıflandırması, ses sınıflandırması için aktarım öğreniminin nasıl kullanılacağını gösterir.
- Kaggle'ın TensorFlow konuşma tanıma yarışmasındaki not defterleri.
- TensorFlow.js - Aktarım öğrenme kod laboratuvarını kullanan ses tanıma , ses sınıflandırması için kendi etkileşimli web uygulamanızı nasıl oluşturacağınızı öğretir.
- arXiv'de müzik bilgisi alımı için derin öğrenme üzerine bir eğitim (Choi ve diğerleri, 2017).
- TensorFlow ayrıca, kendi ses tabanlı projelerinizde yardımcı olmak için ses verilerinin hazırlanması ve büyütülmesi için ek desteğe sahiptir.
- Müzik ve ses analizi için bir Python paketi olan librosa kitaplığını kullanmayı düşünün.