
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
В этом руководстве показано, как предварительно обрабатывать аудиофайлы в формате WAV, а также создавать и обучать базовую модель автоматического распознавания речи (ASR) для распознавания десяти разных слов. Вы будете использовать часть набора данных Speech Commands ( Warden, 2018 ), который содержит короткие (не более одной секунды) звуковые фрагменты команд, такие как «вниз», «идти», «влево», «нет», « вправо», «стоп», «вверх» и «да».
Реальные системы распознавания речи и звука сложны. Но, как и в случае с классификацией изображений с помощью набора данных MNIST , это руководство должно дать вам общее представление об используемых методах.
Настраивать
Импортируйте необходимые модули и зависимости. Обратите внимание, что в этом уроке вы будете использовать Seaborn для визуализации.
import os
import pathlib
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import models
from IPython import display
# Set the seed value for experiment reproducibility.
seed = 42
tf.random.set_seed(seed)
np.random.seed(seed)
Импорт мини-набора данных Speech Commands
Чтобы сэкономить время при загрузке данных, вы будете работать с уменьшенной версией набора данных Speech Commands. Исходный набор данных состоит из более чем 105 000 аудиофайлов в формате аудиофайлов WAV (Waveform), в которых люди произносят 35 разных слов. Эти данные были собраны Google и опубликованы под лицензией CC BY.
Загрузите и извлеките файл mini_speech_commands.zip , содержащий меньшие наборы данных Speech Commands, с помощью tf.keras.utils.get_file :
DATASET_PATH = 'data/mini_speech_commands'
data_dir = pathlib.Path(DATASET_PATH)
if not data_dir.exists():
tf.keras.utils.get_file(
'mini_speech_commands.zip',
origin="http://storage.googleapis.com/download.tensorflow.org/data/mini_speech_commands.zip",
extract=True,
cache_dir='.', cache_subdir='data')
Downloading data from http://storage.googleapis.com/download.tensorflow.org/data/mini_speech_commands.zip 182083584/182082353 [==============================] - 1s 0us/step 182091776/182082353 [==============================] - 1s 0us/step
Аудиоклипы набора данных хранятся в восьми папках, соответствующих каждой голосовой команде: no , yes , down , go , left , up , right и stop :
commands = np.array(tf.io.gfile.listdir(str(data_dir)))
commands = commands[commands != 'README.md']
print('Commands:', commands)
Commands: ['stop' 'left' 'no' 'go' 'yes' 'down' 'right' 'up']
Извлеките аудиоклипы в список filenames и перетасуйте его:
filenames = tf.io.gfile.glob(str(data_dir) + '/*/*')
filenames = tf.random.shuffle(filenames)
num_samples = len(filenames)
print('Number of total examples:', num_samples)
print('Number of examples per label:',
len(tf.io.gfile.listdir(str(data_dir/commands[0]))))
print('Example file tensor:', filenames[0])
Number of total examples: 8000 Number of examples per label: 1000 Example file tensor: tf.Tensor(b'data/mini_speech_commands/yes/db72a474_nohash_0.wav', shape=(), dtype=string)
Разделите filenames на обучающие, проверочные и тестовые наборы, используя соотношение 80:10:10 соответственно:
train_files = filenames[:6400]
val_files = filenames[6400: 6400 + 800]
test_files = filenames[-800:]
print('Training set size', len(train_files))
print('Validation set size', len(val_files))
print('Test set size', len(test_files))
Training set size 6400 Validation set size 800 Test set size 800
Чтение аудиофайлов и их меток
В этом разделе вы предварительно обработаете набор данных, создав декодированные тензоры для сигналов и соответствующие метки. Обратите внимание, что:
- Каждый файл WAV содержит данные временных рядов с заданным количеством выборок в секунду.
- Каждый образец представляет собой амплитуду звукового сигнала в это конкретное время.
- В 16-битной системе, такой как WAV-файлы в мини-наборе данных Speech Commands, значения амплитуд находятся в диапазоне от -32 768 до 32 767.
- Частота дискретизации для этого набора данных составляет 16 кГц.
Форма тензора, возвращаемого tf.audio.decode_wav , имеет вид [samples, channels] , где channels равен 1 для моно или 2 для стерео. Мини-набор данных Speech Commands содержит только монозаписи.
test_file = tf.io.read_file(DATASET_PATH+'/down/0a9f9af7_nohash_0.wav')
test_audio, _ = tf.audio.decode_wav(contents=test_file)
test_audio.shape
TensorShape([13654, 1])
Теперь давайте определим функцию, которая предварительно обрабатывает необработанные аудиофайлы WAV набора данных в аудиотензоры:
def decode_audio(audio_binary):
# Decode WAV-encoded audio files to `float32` tensors, normalized
# to the [-1.0, 1.0] range. Return `float32` audio and a sample rate.
audio, _ = tf.audio.decode_wav(contents=audio_binary)
# Since all the data is single channel (mono), drop the `channels`
# axis from the array.
return tf.squeeze(audio, axis=-1)
Определите функцию, которая создает метки, используя родительские каталоги для каждого файла:
- Разделите пути к файлам на
tf.RaggedTensors (тензоры с рваными размерами — с кусочками, которые могут иметь разную длину).
def get_label(file_path):
parts = tf.strings.split(
input=file_path,
sep=os.path.sep)
# Note: You'll use indexing here instead of tuple unpacking to enable this
# to work in a TensorFlow graph.
return parts[-2]
Определите еще одну вспомогательную функцию — get_waveform_and_label — которая объединяет все это:
- В качестве входных данных используется имя аудиофайла WAV.
- Выходные данные представляют собой кортеж, содержащий тензоры аудио и меток, готовые к обучению с учителем.
def get_waveform_and_label(file_path):
label = get_label(file_path)
audio_binary = tf.io.read_file(file_path)
waveform = decode_audio(audio_binary)
return waveform, label
Создайте обучающий набор для извлечения пар аудио-меток:
- Создайте
tf.data.DatasetсDataset.from_tensor_slicesиDataset.map, используяget_waveform_and_label, определенный ранее.
Позже вы создадите наборы для проверки и тестирования, используя аналогичную процедуру.
AUTOTUNE = tf.data.AUTOTUNE
files_ds = tf.data.Dataset.from_tensor_slices(train_files)
waveform_ds = files_ds.map(
map_func=get_waveform_and_label,
num_parallel_calls=AUTOTUNE)
Давайте построим несколько звуковых сигналов:
rows = 3
cols = 3
n = rows * cols
fig, axes = plt.subplots(rows, cols, figsize=(10, 12))
for i, (audio, label) in enumerate(waveform_ds.take(n)):
r = i // cols
c = i % cols
ax = axes[r][c]
ax.plot(audio.numpy())
ax.set_yticks(np.arange(-1.2, 1.2, 0.2))
label = label.numpy().decode('utf-8')
ax.set_title(label)
plt.show()
Преобразование сигналов в спектрограммы
Сигналы в наборе данных представлены во временной области. Далее вы преобразуете формы сигналов из сигналов во временной области в сигналы в частотно-временной области путем вычисления кратковременного преобразования Фурье (STFT) для преобразования сигналов в виде спектрограмм , которые показывают изменения частоты во времени и могут быть представлены в виде 2D-изображений. Вы будете передавать изображения спектрограммы в свою нейронную сеть для обучения модели.
Преобразование Фурье ( tf.signal.fft ) преобразует сигнал в его составляющие частоты, но теряет всю информацию о времени. Для сравнения, STFT ( tf.signal.stft ) разбивает сигнал на окна времени и выполняет преобразование Фурье в каждом окне, сохраняя некоторую информацию о времени и возвращая двумерный тензор, на котором вы можете выполнять стандартные свертки.
Создайте служебную функцию для преобразования сигналов в спектрограммы:
- Сигналы должны быть одинаковой длины, чтобы при преобразовании их в спектрограммы результаты имели одинаковые размеры. Это можно сделать, просто заполнив нулями аудиоклипы, которые короче одной секунды (используя
tf.zeros). - При вызове
tf.signal.stftвыберите параметрыframe_lengthиframe_step, чтобы сгенерированное «изображение» спектрограммы было почти квадратным. Для получения дополнительной информации о выборе параметров STFT обратитесь к этому видео Coursera об обработке аудиосигнала и STFT. - STFT создает массив комплексных чисел, представляющих величину и фазу. Однако в этом руководстве вы будете использовать только величину, которую можно получить, применив
tf.absк выходным даннымtf.signal.stft.
def get_spectrogram(waveform):
# Zero-padding for an audio waveform with less than 16,000 samples.
input_len = 16000
waveform = waveform[:input_len]
zero_padding = tf.zeros(
[16000] - tf.shape(waveform),
dtype=tf.float32)
# Cast the waveform tensors' dtype to float32.
waveform = tf.cast(waveform, dtype=tf.float32)
# Concatenate the waveform with `zero_padding`, which ensures all audio
# clips are of the same length.
equal_length = tf.concat([waveform, zero_padding], 0)
# Convert the waveform to a spectrogram via a STFT.
spectrogram = tf.signal.stft(
equal_length, frame_length=255, frame_step=128)
# Obtain the magnitude of the STFT.
spectrogram = tf.abs(spectrogram)
# Add a `channels` dimension, so that the spectrogram can be used
# as image-like input data with convolution layers (which expect
# shape (`batch_size`, `height`, `width`, `channels`).
spectrogram = spectrogram[..., tf.newaxis]
return spectrogram
Далее приступайте к изучению данных. Распечатайте формы тензоризованной формы волны одного примера и соответствующую спектрограмму и воспроизведите исходный звук:
for waveform, label in waveform_ds.take(1):
label = label.numpy().decode('utf-8')
spectrogram = get_spectrogram(waveform)
print('Label:', label)
print('Waveform shape:', waveform.shape)
print('Spectrogram shape:', spectrogram.shape)
print('Audio playback')
display.display(display.Audio(waveform, rate=16000))
Label: yes Waveform shape: (16000,) Spectrogram shape: (124, 129, 1) Audio playback
Теперь определите функцию для отображения спектрограммы:
def plot_spectrogram(spectrogram, ax):
if len(spectrogram.shape) > 2:
assert len(spectrogram.shape) == 3
spectrogram = np.squeeze(spectrogram, axis=-1)
# Convert the frequencies to log scale and transpose, so that the time is
# represented on the x-axis (columns).
# Add an epsilon to avoid taking a log of zero.
log_spec = np.log(spectrogram.T + np.finfo(float).eps)
height = log_spec.shape[0]
width = log_spec.shape[1]
X = np.linspace(0, np.size(spectrogram), num=width, dtype=int)
Y = range(height)
ax.pcolormesh(X, Y, log_spec)
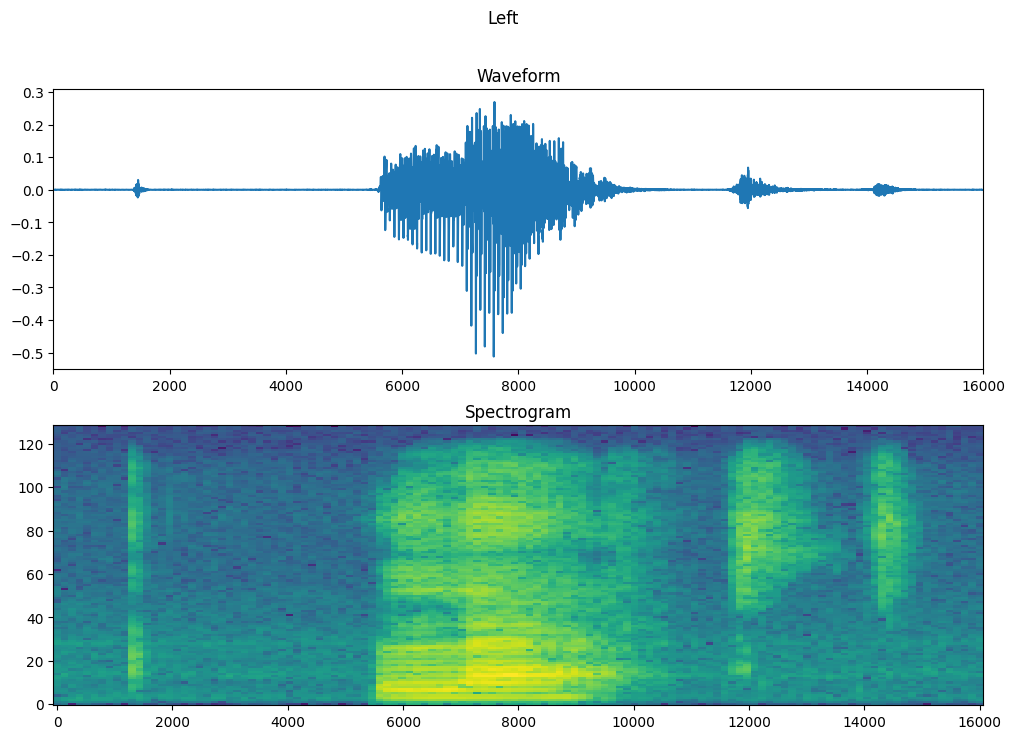
Постройте форму сигнала примера с течением времени и соответствующую спектрограмму (частоты с течением времени):
fig, axes = plt.subplots(2, figsize=(12, 8))
timescale = np.arange(waveform.shape[0])
axes[0].plot(timescale, waveform.numpy())
axes[0].set_title('Waveform')
axes[0].set_xlim([0, 16000])
plot_spectrogram(spectrogram.numpy(), axes[1])
axes[1].set_title('Spectrogram')
plt.show()
Теперь определите функцию, которая преобразует набор данных сигнала в спектрограммы и соответствующие им метки в виде целочисленных идентификаторов:
def get_spectrogram_and_label_id(audio, label):
spectrogram = get_spectrogram(audio)
label_id = tf.argmax(label == commands)
return spectrogram, label_id
Сопоставьте get_spectrogram_and_label_id с элементами набора данных с помощью Dataset.map :
spectrogram_ds = waveform_ds.map(
map_func=get_spectrogram_and_label_id,
num_parallel_calls=AUTOTUNE)
Изучите спектрограммы для различных примеров набора данных:
rows = 3
cols = 3
n = rows*cols
fig, axes = plt.subplots(rows, cols, figsize=(10, 10))
for i, (spectrogram, label_id) in enumerate(spectrogram_ds.take(n)):
r = i // cols
c = i % cols
ax = axes[r][c]
plot_spectrogram(spectrogram.numpy(), ax)
ax.set_title(commands[label_id.numpy()])
ax.axis('off')
plt.show()
Построить и обучить модель
Повторите предварительную обработку обучающего набора для проверочного и тестового наборов:
def preprocess_dataset(files):
files_ds = tf.data.Dataset.from_tensor_slices(files)
output_ds = files_ds.map(
map_func=get_waveform_and_label,
num_parallel_calls=AUTOTUNE)
output_ds = output_ds.map(
map_func=get_spectrogram_and_label_id,
num_parallel_calls=AUTOTUNE)
return output_ds
train_ds = spectrogram_ds
val_ds = preprocess_dataset(val_files)
test_ds = preprocess_dataset(test_files)
Пакетное обучение и наборы проверки для обучения модели:
batch_size = 64
train_ds = train_ds.batch(batch_size)
val_ds = val_ds.batch(batch_size)
Добавьте Dataset.cache и Dataset.prefetch , чтобы уменьшить задержку чтения при обучении модели:
train_ds = train_ds.cache().prefetch(AUTOTUNE)
val_ds = val_ds.cache().prefetch(AUTOTUNE)
Для модели вы будете использовать простую сверточную нейронную сеть (CNN), поскольку вы преобразовали аудиофайлы в изображения спектрограмм.
Ваша модель tf.keras.Sequential будет использовать следующие слои предварительной обработки Keras:
-
tf.keras.layers.Resizing: для уменьшения входных данных, чтобы модель могла обучаться быстрее. -
tf.keras.layers.Normalization: нормализовать каждый пиксель изображения на основе его среднего значения и стандартного отклонения.
Для уровня Normalization его метод adapt сначала необходимо вызвать для обучающих данных, чтобы вычислить совокупную статистику (то есть среднее значение и стандартное отклонение).
for spectrogram, _ in spectrogram_ds.take(1):
input_shape = spectrogram.shape
print('Input shape:', input_shape)
num_labels = len(commands)
# Instantiate the `tf.keras.layers.Normalization` layer.
norm_layer = layers.Normalization()
# Fit the state of the layer to the spectrograms
# with `Normalization.adapt`.
norm_layer.adapt(data=spectrogram_ds.map(map_func=lambda spec, label: spec))
model = models.Sequential([
layers.Input(shape=input_shape),
# Downsample the input.
layers.Resizing(32, 32),
# Normalize.
norm_layer,
layers.Conv2D(32, 3, activation='relu'),
layers.Conv2D(64, 3, activation='relu'),
layers.MaxPooling2D(),
layers.Dropout(0.25),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dropout(0.5),
layers.Dense(num_labels),
])
model.summary()
Input shape: (124, 129, 1)
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
resizing (Resizing) (None, 32, 32, 1) 0
normalization (Normalizatio (None, 32, 32, 1) 3
n)
conv2d (Conv2D) (None, 30, 30, 32) 320
conv2d_1 (Conv2D) (None, 28, 28, 64) 18496
max_pooling2d (MaxPooling2D (None, 14, 14, 64) 0
)
dropout (Dropout) (None, 14, 14, 64) 0
flatten (Flatten) (None, 12544) 0
dense (Dense) (None, 128) 1605760
dropout_1 (Dropout) (None, 128) 0
dense_1 (Dense) (None, 8) 1032
=================================================================
Total params: 1,625,611
Trainable params: 1,625,608
Non-trainable params: 3
_________________________________________________________________
Настройте модель Keras с помощью оптимизатора Adam и кросс-энтропийной потери:
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'],
)
Обучите модель более 10 эпох в демонстрационных целях:
EPOCHS = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=EPOCHS,
callbacks=tf.keras.callbacks.EarlyStopping(verbose=1, patience=2),
)
Epoch 1/10 100/100 [==============================] - 6s 41ms/step - loss: 1.7503 - accuracy: 0.3630 - val_loss: 1.2850 - val_accuracy: 0.5763 Epoch 2/10 100/100 [==============================] - 0s 5ms/step - loss: 1.2101 - accuracy: 0.5698 - val_loss: 0.9314 - val_accuracy: 0.6913 Epoch 3/10 100/100 [==============================] - 0s 5ms/step - loss: 0.9336 - accuracy: 0.6703 - val_loss: 0.7529 - val_accuracy: 0.7325 Epoch 4/10 100/100 [==============================] - 0s 5ms/step - loss: 0.7503 - accuracy: 0.7397 - val_loss: 0.6721 - val_accuracy: 0.7713 Epoch 5/10 100/100 [==============================] - 0s 5ms/step - loss: 0.6367 - accuracy: 0.7741 - val_loss: 0.6061 - val_accuracy: 0.7975 Epoch 6/10 100/100 [==============================] - 0s 5ms/step - loss: 0.5650 - accuracy: 0.7987 - val_loss: 0.5489 - val_accuracy: 0.8125 Epoch 7/10 100/100 [==============================] - 0s 5ms/step - loss: 0.5099 - accuracy: 0.8183 - val_loss: 0.5344 - val_accuracy: 0.8238 Epoch 8/10 100/100 [==============================] - 0s 5ms/step - loss: 0.4560 - accuracy: 0.8392 - val_loss: 0.5194 - val_accuracy: 0.8288 Epoch 9/10 100/100 [==============================] - 0s 5ms/step - loss: 0.4101 - accuracy: 0.8547 - val_loss: 0.4809 - val_accuracy: 0.8388 Epoch 10/10 100/100 [==============================] - 0s 5ms/step - loss: 0.3905 - accuracy: 0.8589 - val_loss: 0.4973 - val_accuracy: 0.8363
Давайте построим кривые потерь при обучении и проверке, чтобы проверить, как ваша модель улучшилась во время обучения:
metrics = history.history
plt.plot(history.epoch, metrics['loss'], metrics['val_loss'])
plt.legend(['loss', 'val_loss'])
plt.show()

Оцените производительность модели
Запустите модель на тестовом наборе и проверьте производительность модели:
test_audio = []
test_labels = []
for audio, label in test_ds:
test_audio.append(audio.numpy())
test_labels.append(label.numpy())
test_audio = np.array(test_audio)
test_labels = np.array(test_labels)
y_pred = np.argmax(model.predict(test_audio), axis=1)
y_true = test_labels
test_acc = sum(y_pred == y_true) / len(y_true)
print(f'Test set accuracy: {test_acc:.0%}')
Test set accuracy: 85%
Показать матрицу путаницы
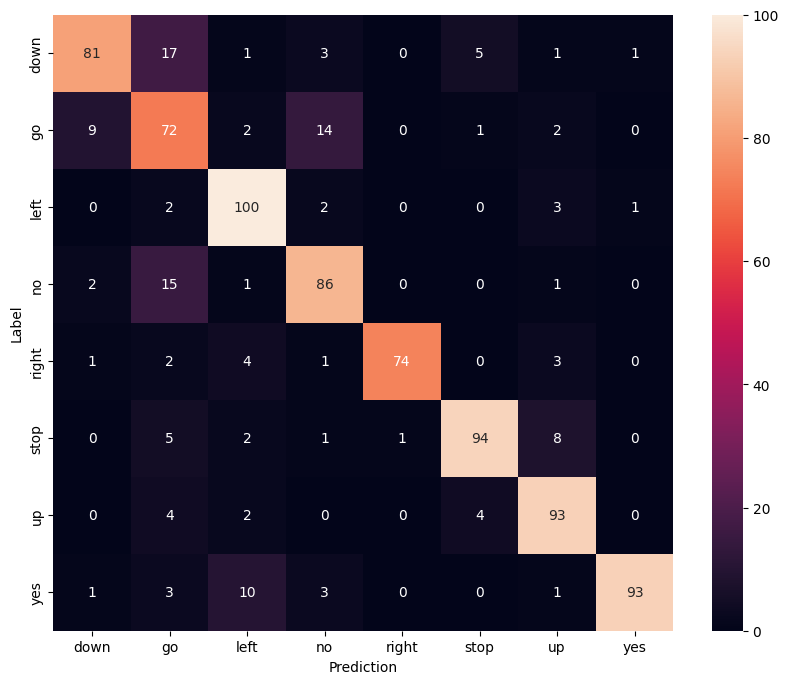
Используйте матрицу путаницы, чтобы проверить, насколько хорошо модель справилась с классификацией каждой из команд в тестовом наборе:
confusion_mtx = tf.math.confusion_matrix(y_true, y_pred)
plt.figure(figsize=(10, 8))
sns.heatmap(confusion_mtx,
xticklabels=commands,
yticklabels=commands,
annot=True, fmt='g')
plt.xlabel('Prediction')
plt.ylabel('Label')
plt.show()
Выполнение логического вывода по аудиофайлу
Наконец, проверьте вывод прогноза модели, используя входной аудиофайл, в котором кто-то говорит «нет». Насколько хорошо работает ваша модель?
sample_file = data_dir/'no/01bb6a2a_nohash_0.wav'
sample_ds = preprocess_dataset([str(sample_file)])
for spectrogram, label in sample_ds.batch(1):
prediction = model(spectrogram)
plt.bar(commands, tf.nn.softmax(prediction[0]))
plt.title(f'Predictions for "{commands[label[0]]}"')
plt.show()

Как следует из вывода, ваша модель должна была распознать аудиокоманду как «нет».
Следующие шаги
В этом руководстве показано, как выполнить простую аудиоклассификацию/автоматическое распознавание речи с помощью сверточной нейронной сети с TensorFlow и Python. Чтобы узнать больше, рассмотрите следующие ресурсы:
- В учебном пособии по классификации звука с помощью YAMNet показано, как использовать трансферное обучение для классификации звука.
- Блокноты из конкурса распознавания речи TensorFlow от Kaggle .
- Лаборатория кода TensorFlow.js — Распознавание звука с использованием трансфертного обучения учит, как создать собственное интерактивное веб-приложение для классификации звука.
- Учебник по глубокому обучению для поиска музыкальной информации (Чой и др., 2017) на arXiv.
- TensorFlow также имеет дополнительную поддержку для подготовки и дополнения аудиоданных, чтобы помочь с вашими собственными проектами на основе аудио.
- Рассмотрите возможность использования библиотеки librosa — пакета Python для анализа музыки и звука.