
| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub | |
Phân biệt và Gradients tự động
Sự khác biệt tự động rất hữu ích cho việc triển khai các thuật toán học máy, chẳng hạn như backpropagation để đào tạo mạng nơ-ron.
Trong hướng dẫn này, bạn sẽ khám phá các cách tính toán độ dốc bằng TensorFlow, đặc biệt là trong quá trình thực thi nhanh chóng.
Thành lập
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
Tính toán gradient
Để tự động phân biệt, TensorFlow cần nhớ những thao tác nào xảy ra theo thứ tự trong quá trình chuyển tiếp . Sau đó, trong quá trình chuyển lùi , TensorFlow duyệt qua danh sách các thao tác này theo thứ tự ngược lại để tính toán độ dốc.
Băng Gradient
TensorFlow cung cấp API tf.GradientTape để phân biệt tự động; nghĩa là tính toán gradient của một phép tính đối với một số đầu vào, thường là tf.Variable s. TensorFlow "ghi lại" các hoạt động liên quan được thực thi bên trong ngữ cảnh của tf.GradientTape vào một "băng". Sau đó, TensorFlow sử dụng băng đó để tính toán độ dốc của một phép tính "được ghi lại" bằng cách sử dụng phân biệt chế độ đảo ngược .
Đây là một ví dụ đơn giản:
x = tf.Variable(3.0)
with tf.GradientTape() as tape:
y = x**2
Khi bạn đã ghi lại một số hoạt động, hãy sử dụng GradientTape.gradient(target, sources) để tính toán gradient của một số mục tiêu (thường là mất mát) liên quan đến một số nguồn (thường là các biến của mô hình):
# dy = 2x * dx
dy_dx = tape.gradient(y, x)
dy_dx.numpy()
6.0
Ví dụ trên sử dụng vô hướng, nhưng tf.GradientTape hoạt động dễ dàng trên bất kỳ tensor nào:
w = tf.Variable(tf.random.normal((3, 2)), name='w')
b = tf.Variable(tf.zeros(2, dtype=tf.float32), name='b')
x = [[1., 2., 3.]]
with tf.GradientTape(persistent=True) as tape:
y = x @ w + b
loss = tf.reduce_mean(y**2)
Để nhận được gradient loss liên quan đến cả hai biến, bạn có thể chuyển cả hai dưới dạng nguồn cho phương thức gradient . Băng rất linh hoạt về cách các nguồn được truyền và sẽ chấp nhận bất kỳ tổ hợp danh sách hoặc từ điển nào được lồng vào nhau và trả về gradient có cấu trúc theo cùng một cách (xem tf.nest ).
[dl_dw, dl_db] = tape.gradient(loss, [w, b])
Gradient đối với mỗi nguồn có hình dạng của nguồn:
print(w.shape)
print(dl_dw.shape)
(3, 2) (3, 2)
Đây là phép tính gradient một lần nữa, lần này là chuyển từ điển các biến:
my_vars = {
'w': w,
'b': b
}
grad = tape.gradient(loss, my_vars)
grad['b']
<tf.Tensor: shape=(2,), dtype=float32, numpy=array([-1.6920902, -3.2363236], dtype=float32)>
Gradients đối với một người mẫu
Thông thường, thu thập tf.Variables vào một tf.Module hoặc một trong các lớp con của nó ( layers.Layer , keras.Model ) để kiểm tra và xuất .
Trong hầu hết các trường hợp, bạn sẽ muốn tính toán độ dốc liên quan đến các biến có thể đào tạo của mô hình. Vì tất cả các lớp con của tf.Module tổng hợp các biến của chúng trong thuộc tính Module.trainable_variables , bạn có thể tính toán các độ dốc này trong một vài dòng mã:
layer = tf.keras.layers.Dense(2, activation='relu')
x = tf.constant([[1., 2., 3.]])
with tf.GradientTape() as tape:
# Forward pass
y = layer(x)
loss = tf.reduce_mean(y**2)
# Calculate gradients with respect to every trainable variable
grad = tape.gradient(loss, layer.trainable_variables)
for var, g in zip(layer.trainable_variables, grad):
print(f'{var.name}, shape: {g.shape}')
dense/kernel:0, shape: (3, 2) dense/bias:0, shape: (2,)
Kiểm soát những gì băng xem
Hành vi mặc định là ghi lại tất cả các hoạt động sau khi truy cập một tf.Variable . Lý do cho điều này là:
- Băng cần biết những phép toán nào cần ghi trong đường chuyền tiến để tính toán độ dốc trong đường chuyền ngược.
- Băng giữ các tham chiếu đến đầu ra trung gian, vì vậy bạn không muốn ghi lại các thao tác không cần thiết.
- Trường hợp sử dụng phổ biến nhất liên quan đến việc tính toán độ dốc của tổn thất đối với tất cả các biến có thể đào tạo của mô hình.
Ví dụ: phần sau không tính được gradient vì tf.Tensor không được "theo dõi" theo mặc định và tf.Variable không thể đào tạo:
# A trainable variable
x0 = tf.Variable(3.0, name='x0')
# Not trainable
x1 = tf.Variable(3.0, name='x1', trainable=False)
# Not a Variable: A variable + tensor returns a tensor.
x2 = tf.Variable(2.0, name='x2') + 1.0
# Not a variable
x3 = tf.constant(3.0, name='x3')
with tf.GradientTape() as tape:
y = (x0**2) + (x1**2) + (x2**2)
grad = tape.gradient(y, [x0, x1, x2, x3])
for g in grad:
print(g)
tf.Tensor(6.0, shape=(), dtype=float32) None None None
Bạn có thể liệt kê các biến đang được xem bởi băng bằng cách sử dụng phương thức GradientTape.watched_variables :
[var.name for var in tape.watched_variables()]
['x0:0']
tf.GradientTape cung cấp các hook cho phép người dùng kiểm soát những gì được xem hoặc không được xem.
Để ghi lại các gradient liên quan đến tf.Tensor , bạn cần gọi GradientTape.watch(x) :
x = tf.constant(3.0)
with tf.GradientTape() as tape:
tape.watch(x)
y = x**2
# dy = 2x * dx
dy_dx = tape.gradient(y, x)
print(dy_dx.numpy())
6.0
Ngược lại, để vô hiệu hóa hành vi mặc định của việc xem tất cả tf.Variables , hãy đặt watch_accessed_variables=False khi tạo băng gradient. Phép tính này sử dụng hai biến, nhưng chỉ kết nối gradient cho một trong các biến:
x0 = tf.Variable(0.0)
x1 = tf.Variable(10.0)
with tf.GradientTape(watch_accessed_variables=False) as tape:
tape.watch(x1)
y0 = tf.math.sin(x0)
y1 = tf.nn.softplus(x1)
y = y0 + y1
ys = tf.reduce_sum(y)
Vì GradientTape.watch không được gọi trên x0 , không có gradient nào được tính liên quan đến nó:
# dys/dx1 = exp(x1) / (1 + exp(x1)) = sigmoid(x1)
grad = tape.gradient(ys, {'x0': x0, 'x1': x1})
print('dy/dx0:', grad['x0'])
print('dy/dx1:', grad['x1'].numpy())
dy/dx0: None dy/dx1: 0.9999546
Kết quả trung gian
Bạn cũng có thể yêu cầu độ dốc của đầu ra liên quan đến các giá trị trung gian được tính bên trong ngữ cảnh tf.GradientTape .
x = tf.constant(3.0)
with tf.GradientTape() as tape:
tape.watch(x)
y = x * x
z = y * y
# Use the tape to compute the gradient of z with respect to the
# intermediate value y.
# dz_dy = 2 * y and y = x ** 2 = 9
print(tape.gradient(z, y).numpy())
18.0
Theo mặc định, các tài nguyên do GradientTape nắm giữ được giải phóng ngay sau khi phương thức GradientTape.gradient được gọi. Để tính toán nhiều gradient trên cùng một phép tính, hãy tạo một dải gradient có persistent=True . Điều này cho phép nhiều cuộc gọi đến phương thức gradient khi tài nguyên được giải phóng khi đối tượng băng được thu thập rác. Ví dụ:
x = tf.constant([1, 3.0])
with tf.GradientTape(persistent=True) as tape:
tape.watch(x)
y = x * x
z = y * y
print(tape.gradient(z, x).numpy()) # [4.0, 108.0] (4 * x**3 at x = [1.0, 3.0])
print(tape.gradient(y, x).numpy()) # [2.0, 6.0] (2 * x at x = [1.0, 3.0])
[ 4. 108.] [2. 6.]
del tape # Drop the reference to the tape
Ghi chú về hiệu suất
Có một chi phí nhỏ liên quan đến việc thực hiện các hoạt động bên trong ngữ cảnh băng gradient. Đối với hầu hết các hoạt động háo hức, đây sẽ không phải là một chi phí đáng chú ý, nhưng bạn vẫn nên sử dụng ngữ cảnh băng chỉ xung quanh các khu vực được yêu cầu.
Băng Gradient sử dụng bộ nhớ để lưu trữ các kết quả trung gian, bao gồm cả đầu vào và đầu ra, để sử dụng trong quá trình chuyển ngược.
Để có hiệu quả, một số hoạt động (như
ReLU) không cần phải giữ lại các kết quả trung gian của chúng và chúng được lược bớt trong quá trình chuyền về phía trước. Tuy nhiên, nếu bạn sử dụngpersistent=Truetrên băng của mình, thì không có gì bị loại bỏ và mức sử dụng bộ nhớ tối đa của bạn sẽ cao hơn.
Trọng lượng của mục tiêu không vô hướng
Một gradient về cơ bản là một phép toán trên đại lượng vô hướng.
x = tf.Variable(2.0)
with tf.GradientTape(persistent=True) as tape:
y0 = x**2
y1 = 1 / x
print(tape.gradient(y0, x).numpy())
print(tape.gradient(y1, x).numpy())
4.0 -0.25
Do đó, nếu bạn yêu cầu gradient của nhiều mục tiêu, kết quả cho mỗi nguồn là:
- Gradient của tổng các mục tiêu, hoặc tương đương
- Tổng các độ dốc của từng mục tiêu.
x = tf.Variable(2.0)
with tf.GradientTape() as tape:
y0 = x**2
y1 = 1 / x
print(tape.gradient({'y0': y0, 'y1': y1}, x).numpy())
3.75
Tương tự, nếu (các) mục tiêu không vô hướng thì gradient của tổng được tính:
x = tf.Variable(2.)
with tf.GradientTape() as tape:
y = x * [3., 4.]
print(tape.gradient(y, x).numpy())
7.0
Điều này làm cho nó trở nên đơn giản để lấy gradient của tổng của một tập hợp các tổn thất, hoặc gradient của tổng của một phép tính tổn thất khôn ngoan.
Nếu bạn cần một gradient riêng biệt cho từng mục, hãy tham khảo Jacobians .
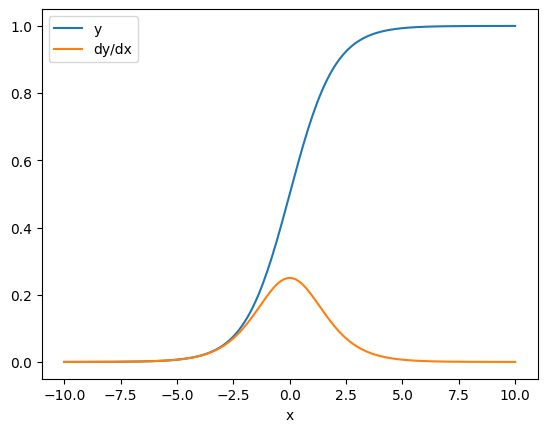
Trong một số trường hợp, bạn có thể bỏ qua Jacobian. Đối với một phép tính theo phần tử, gradient của tổng cung cấp đạo hàm của mỗi phần tử đối với phần tử đầu vào của nó, vì mỗi phần tử là độc lập:
x = tf.linspace(-10.0, 10.0, 200+1)
with tf.GradientTape() as tape:
tape.watch(x)
y = tf.nn.sigmoid(x)
dy_dx = tape.gradient(y, x)
plt.plot(x, y, label='y')
plt.plot(x, dy_dx, label='dy/dx')
plt.legend()
_ = plt.xlabel('x')
Kiểm soát dòng chảy
Bởi vì một băng gradient ghi lại các hoạt động khi chúng được thực thi, luồng điều khiển Python được xử lý một cách tự nhiên (ví dụ: các câu lệnh if và while ).
Ở đây, một biến khác nhau được sử dụng trên mỗi nhánh của if . Gradient chỉ kết nối với biến đã được sử dụng:
x = tf.constant(1.0)
v0 = tf.Variable(2.0)
v1 = tf.Variable(2.0)
with tf.GradientTape(persistent=True) as tape:
tape.watch(x)
if x > 0.0:
result = v0
else:
result = v1**2
dv0, dv1 = tape.gradient(result, [v0, v1])
print(dv0)
print(dv1)
tf.Tensor(1.0, shape=(), dtype=float32) None
Chỉ cần nhớ rằng bản thân các câu lệnh điều khiển không thể phân biệt được, vì vậy chúng vô hình đối với các trình tối ưu hóa dựa trên gradient.
Tùy thuộc vào giá trị của x trong ví dụ trên, băng ghi result = v0 hoặc result = v1**2 . Gradient đối với x luôn luôn là None .
dx = tape.gradient(result, x)
print(dx)
None
Nhận một gradient của None
Khi một mục tiêu không được kết nối với một nguồn, bạn sẽ nhận được một gradient là None .
x = tf.Variable(2.)
y = tf.Variable(3.)
with tf.GradientTape() as tape:
z = y * y
print(tape.gradient(z, x))
None
Ở đây, z rõ ràng là không được kết nối với x , nhưng có một số cách ít rõ ràng hơn mà một gradient có thể bị ngắt kết nối.
1. Đã thay thế một biến bằng một tensor
Trong phần "kiểm soát những gì băng xem" bạn đã thấy rằng băng sẽ tự động xem một tf.Variable nhưng không phải là một tf.Tensor .
Một lỗi phổ biến là vô tình thay thế tf.Variable bằng tf.Tensor , thay vì sử dụng Variable.assign để cập nhật tf.Variable . Đây là một ví dụ:
x = tf.Variable(2.0)
for epoch in range(2):
with tf.GradientTape() as tape:
y = x+1
print(type(x).__name__, ":", tape.gradient(y, x))
x = x + 1 # This should be `x.assign_add(1)`
ResourceVariable : tf.Tensor(1.0, shape=(), dtype=float32) EagerTensor : None
2. Đã thực hiện các phép tính bên ngoài TensorFlow
Băng không thể ghi lại đường dẫn gradient nếu phép tính thoát khỏi TensorFlow. Ví dụ:
x = tf.Variable([[1.0, 2.0],
[3.0, 4.0]], dtype=tf.float32)
with tf.GradientTape() as tape:
x2 = x**2
# This step is calculated with NumPy
y = np.mean(x2, axis=0)
# Like most ops, reduce_mean will cast the NumPy array to a constant tensor
# using `tf.convert_to_tensor`.
y = tf.reduce_mean(y, axis=0)
print(tape.gradient(y, x))
None
3. Chuyển gradient qua một số nguyên hoặc chuỗi
Số nguyên và chuỗi không phân biệt được. Nếu một đường dẫn tính toán sử dụng các kiểu dữ liệu này sẽ không có gradient.
Không ai mong đợi các chuỗi có thể phân biệt được, nhưng rất dễ vô tình tạo ra một hằng số hoặc biến int nếu bạn không chỉ định loại dtype .
x = tf.constant(10)
with tf.GradientTape() as g:
g.watch(x)
y = x * x
print(g.gradient(y, x))
WARNING:tensorflow:The dtype of the watched tensor must be floating (e.g. tf.float32), got tf.int32 WARNING:tensorflow:The dtype of the target tensor must be floating (e.g. tf.float32) when calling GradientTape.gradient, got tf.int32 WARNING:tensorflow:The dtype of the source tensor must be floating (e.g. tf.float32) when calling GradientTape.gradient, got tf.int32 None
TensorFlow không tự động truyền giữa các kiểu, vì vậy, trong thực tế, bạn sẽ thường gặp lỗi kiểu thay vì thiếu gradient.
4. Chuyển gradient qua một đối tượng trạng thái
Trạng thái dừng gradient. Khi bạn đọc từ một đối tượng trạng thái, cuộn băng chỉ có thể quan sát trạng thái hiện tại, không phải lịch sử dẫn đến nó.
Một tf.Tensor là bất biến. Bạn không thể thay đổi tensor sau khi nó được tạo. Nó có một giá trị , nhưng không có trạng thái . Tất cả các hoạt động được thảo luận cho đến nay cũng không có trạng thái: đầu ra của tf.matmul chỉ phụ thuộc vào đầu vào của nó.
Một tf.Variable có trạng thái bên trong — giá trị của nó. Khi bạn sử dụng biến, trạng thái được đọc. Việc tính toán gradient đối với một biến là điều bình thường, nhưng trạng thái của biến đó ngăn các phép tính gradient quay trở lại xa hơn. Ví dụ:
x0 = tf.Variable(3.0)
x1 = tf.Variable(0.0)
with tf.GradientTape() as tape:
# Update x1 = x1 + x0.
x1.assign_add(x0)
# The tape starts recording from x1.
y = x1**2 # y = (x1 + x0)**2
# This doesn't work.
print(tape.gradient(y, x0)) #dy/dx0 = 2*(x1 + x0)
None
Tương tự, các trình vòng lặp tf.data.Dataset và tf.queue s là trạng thái và sẽ dừng tất cả các gradient trên tensor đi qua chúng.
Không có gradient nào được đăng ký
Một số tf.Operation được đăng ký là không thể phân biệt và sẽ trả về None . Những người khác không có gradient được đăng ký .
Trang tf.raw_ops hiển thị các hoạt động cấp thấp nào có độ dốc được đăng ký.
Nếu bạn cố gắng lấy một gradient thông qua một op float mà không có gradient nào được đăng ký, băng sẽ xuất hiện một lỗi thay vì im lặng trả về None . Bằng cách này, bạn biết có điều gì đó không ổn.
Ví dụ: hàm tf.image.adjust_contrast bao bọc raw_ops.AdjustContrastv2 , có thể có một gradient nhưng gradient không được triển khai:
image = tf.Variable([[[0.5, 0.0, 0.0]]])
delta = tf.Variable(0.1)
with tf.GradientTape() as tape:
new_image = tf.image.adjust_contrast(image, delta)
try:
print(tape.gradient(new_image, [image, delta]))
assert False # This should not happen.
except LookupError as e:
print(f'{type(e).__name__}: {e}')
LookupError: gradient registry has no entry for: AdjustContrastv2
Nếu bạn cần phân biệt thông qua tùy chọn này, bạn sẽ cần triển khai gradient và đăng ký nó (sử dụng tf.RegisterGradient ) hoặc triển khai lại chức năng bằng các hoạt động khác.
Zeros thay vì Không có
Trong một số trường hợp, sẽ thuận tiện để lấy 0 thay vì None đối với các gradient không được kết nối. Bạn có thể quyết định những gì sẽ trả lại khi bạn có các gradient không được kết unconnected_gradients bằng cách sử dụng đối số Unconnected_gradients:
x = tf.Variable([2., 2.])
y = tf.Variable(3.)
with tf.GradientTape() as tape:
z = y**2
print(tape.gradient(z, x, unconnected_gradients=tf.UnconnectedGradients.ZERO))
tf.Tensor([0. 0.], shape=(2,), dtype=float32)