
|
|
|
 View source on GitHub
View source on GitHub
|
|
このチュートリアルでは、単語埋め込みを紹介します。このチュートリアルには、小さいデータセットを使って単語埋め込みを最初から学習させ、その埋め込みベクトルを Embedding Projector (下図参照)を使って可視化するためのプログラムがすべて含まれています。

テキストを数値で表す
機械学習モデルは、ベクトル(数値の配列)を入力として受け取ります。テキストを扱う際、最初に決めなければならないのは、文字列を機械学習モデルに入力する前に、数値に変換する(あるいはテキストを「ベクトル化」する)ための戦略です。このセクションでは、これを行う3つの戦略を見てみます。
ワンホット・エンコーディング
最初のアイデアとして、ボキャブラリの中の単語それぞれを「ワンホット」エンコードするというのがあります。 "The cat sat on the mat" という文を考えてみましょう。この文に含まれるボキャブラリ(ユニークな単語)は、 (cat, mat, on, sat, the) です。それぞれの単語を表現するため、ボキャブラリの長さに等しいゼロベクトルを作り、その単語に対応するインデックスの場所に 1 を立てます。これを下図で示します。

文をエンコードしたベクトルを作成するには、その後、それぞれの単語のワンホット・ベクトルをつなげればよいのです。
それぞれの単語をユニークな数値としてエンコードする
2つ目のアプローチとして、それぞれの単語をユニークな数値でエンコードするというのがあります。上記の例をとれば、"cat" に 1、"mat" に 2、というふうに番号を割り当てることができます。そうすれば、 "The cat sat on the mat" という文は、 [5, 1, 4, 3, 5, 2] という密なベクトルで表すことができます。この手法は効率的です。疎なベクトルの代わりに、密な(すべての要素が入っている)ベクトルが得られます。
しかしながら、このアプローチには 2つの欠点があります。
整数エンコーディングは勝手に決めたものです(単語間のいかなる関係性も含んでいません)。
整数エンコーディングはモデルにとっては解釈しにくいものです。たとえば、線形分類器はそれぞれの特徴量について単一の重みしか学習しません。したがって、2つの単語が似かよっていることと、それらのエンコーディングが似かよっていることの間には、なんの関係もありません。この特徴と重みの組み合わせには意味がありません。
単語埋め込み
単語埋め込みを使うと、似たような単語が似たようにエンコードされる、効率的で密な表現が得られます。重要なのは、このエンコーディングを手動で行う必要がないということです。埋め込みは浮動小数点数の密なベクトルです(そのベクトルの長さはあなたが指定するパラメータです)。埋め込みベクトルの値は指定するものではなく、学習されるパラメータです(モデルが密結合レイヤーの重みを学習するように、訓練をとおしてモデルが学習する重みです)。一般的には、(小さいデータセットの場合の)8次元の埋め込みベクトルから、大きなデータセットを扱う 1024次元のものまで見られます。高次元の埋め込みは単語間の細かな関係を取得できますが、学習にはよりたくさんのデータが必要です。

上図は単語埋め込みを図示したものです。それぞれの単語が 4次元の浮動小数点数のベクトルで表されています。埋め込みは「参照テーブル」と考えることもできます。重みが学習された後では、テーブルを参照して、それぞれの単語を対応する密ベクトルにエンコードできます。
設定
!pip install tf-nightly
import tensorflow as tf
2022-12-15 00:03:31.456191: E tensorflow/tsl/lib/monitoring/collection_registry.cc:81] Cannot register 2 metrics with the same name: /tensorflow/core/bfc_allocator_delay
from tensorflow import keras
from tensorflow.keras import layers
import tensorflow_datasets as tfds
tfds.disable_progress_bar()
Embedding レイヤーを使う
Keras では単語埋め込みを使うのも簡単です。Embedding レイヤーを見てみましょう。
Embedding レイヤーは、(特定の単語を示す)整数のインデックスに(その埋め込みである)密なベクトルを対応させる参照テーブルとして理解することができます。埋め込みの次元数(あるいはその幅)は、取り組んでいる問題に適した値を実験して求めるパラメータです。これは、Dense レイヤーの中のニューロンの数を実験で求めるのとまったくおなじです。
embedding_layer = layers.Embedding(1000, 5)
Embedding レイヤーを作成するとき、埋め込みの重みは(ほかのレイヤーとおなじように)ランダムに初期化されます。訓練を通じて、これらの重みはバックプロパゲーションによって徐々に調整されます。いったん訓練が行われると、学習された単語埋め込みは、(モデルを訓練した特定の問題のために学習された結果)単語の間の類似性をおおまかにコード化しています。
Embedding レイヤーに整数を渡すと、結果はそれぞれの整数が埋め込みテーブルのベクトルに置き換えられます。
result = embedding_layer(tf.constant([1,2,3]))
result.numpy()
array([[ 0.02754073, 0.00108051, 0.00939176, 0.03160578, -0.03954845],
[ 0.04228118, -0.02339267, -0.04349839, 0.03668585, -0.04151051],
[-0.01336784, -0.02095198, -0.03206657, 0.0201977 , 0.03490832]],
dtype=float32)
テキストあるいはシーケンスの問題では、入力として、Embedding レイヤーは shape が (samples, sequence_length) の2次元整数テンソルを取ります。ここで、各エントリは整数のシーケンスです。このレイヤーは、可変長のシーケンスを埋め込みベクトルにすることができます。上記のバッチでは、 (32, 10) (長さ10のシーケンス32個のバッチ)や、 (64, 15) (長さ15のシーケンス64個のバッチ)を埋め込みレイヤーに投入可能です。
返されたテンソルは入力より 1つ軸が多くなっており、埋め込みベクトルはその最後の新しい軸に沿って並べられます。(2, 3) の入力バッチを渡すと、出力は (2, 3, N) となります。
result = embedding_layer(tf.constant([[0,1,2],[3,4,5]]))
result.shape
TensorShape([2, 3, 5])
シーケンスのバッチを入力されると、Embedding レイヤーは shape が (samples, sequence_length, embedding_dimensionality) の3次元浮動小数点数テンソルを返します。この可変長のシーケンスを、固定長の表現に変換するには、さまざまな標準的なアプローチが存在します。Dense レイヤーに渡す前に、RNNやアテンション、プーリングレイヤーを使うことができます。ここでは、一番単純なのでプーリングを使用します。RNN
を使ったテキスト分類 は次のステップとしてよいチュートリアルでしょう。
埋め込みを最初から学習する
IMDB の映画レビューの感情分析器を訓練しようと思います。そのプロセスを通じて、埋め込みを最初から学習します。ここでは、前処理済みのデータセットを使用します。
テキストデータセットを最初からロードする方法については、テキスト読み込みのチュートリアルを参照してください。
(train_data, test_data), info = tfds.load(
'imdb_reviews/subwords8k',
split = (tfds.Split.TRAIN, tfds.Split.TEST),
with_info=True, as_supervised=True)
WARNING:absl:TFDS datasets with text encoding are deprecated and will be removed in a future version. Instead, you should use the plain text version and tokenize the text using `tensorflow_text` (See: https://www.tensorflow.org/tutorials/tensorflow_text/intro#tfdata_example)
エンコーダー(tfds.features.text.SubwordTextEncoder)を取得し、すこしボキャブラリを見てみましょう。
ボキャブラリ中の "_" は空白を表しています。ボキャブラリの中にどんなふうに("_")で終わる単語全体と、長い単語を構成する単語の一部が含まれているかに注目してください。
encoder = info.features['text'].encoder
encoder.subwords[:20]
['the_', ', ', '. ', 'a_', 'and_', 'of_', 'to_', 's_', 'is_', 'br', 'in_', 'I_', 'that_', 'this_', 'it_', ' /><', ' />', 'was_', 'The_', 'as_']
映画のレビューはそれぞれ長さが異なっているはずです。padded_batch メソッドを使ってレビューの長さを標準化します。
train_data
<_PrefetchDataset element_spec=(TensorSpec(shape=(None,), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))>
train_batches = train_data.shuffle(1000).padded_batch(10, padded_shapes=([None],[]))
test_batches = test_data.shuffle(1000).padded_batch(10, padded_shapes=([None],[]))
train_batches = train_data.shuffle(1000).padded_batch(10)
test_batches = test_data.shuffle(1000).padded_batch(10)
インポートした状態では、レビューのテキストは整数エンコードされています(それぞれの整数がボキャブラリ中の特定の単語あるいは部分単語を表しています)。
あとの方のゼロに注目してください。これは、バッチが一番長いサンプルに合わせてパディングされた結果です。
train_batch, train_labels = next(iter(train_batches))
train_batch.numpy()
array([[ 62, 18, 4, ..., 0, 0, 0],
[7963, 69, 1214, ..., 0, 0, 0],
[ 12, 788, 1918, ..., 0, 0, 0],
...,
[ 12, 742, 14, ..., 0, 0, 0],
[ 173, 9, 4, ..., 0, 0, 0],
[2947, 7692, 7961, ..., 2470, 2946, 7975]])
単純なモデルの構築
Keras Sequential API を使ってモデルを定義することにします。今回の場合、モデルは「連続した Bag of Words」スタイルのモデルです。
次のレイヤーは Embedding レイヤーです。このレイヤーは整数エンコードされた語彙を受け取り、それぞれの単語のインデックスに対応する埋め込みベクトルをみつけて取り出します。これらのベクトルはモデルの訓練により学習されます。このベクトルは出力配列に次元を追加します。その結果次元は
(batch, sequence, embedding)となります。次に、GlobalAveragePooling1D レイヤーが、それぞれのサンプルについて、シーケンスの次元で平均を取り、固定長の出力ベクトルを返します。これにより、モデルは可変長の入力を最も簡単な方法で扱えるようになります。
この固定長のベクトルは、16個の隠れユニットを持つ全結合(Dense)レイヤーに接続されます。
最後のレイヤーは、1個の出力ノードを持つ Dense レイヤーです。シグモイド活性化関数を使うことで、値は 0 と 1 の間の値を取り、レビューがポジティブ(好意的)であるかどうかの確率(または確信度)を表します。
embedding_dim=16
model = keras.Sequential([
layers.Embedding(encoder.vocab_size, embedding_dim),
layers.GlobalAveragePooling1D(),
layers.Dense(16, activation='relu'),
layers.Dense(1)
])
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, None, 16) 130960
global_average_pooling1d (G (None, 16) 0
lobalAveragePooling1D)
dense (Dense) (None, 16) 272
dense_1 (Dense) (None, 1) 17
=================================================================
Total params: 131,249
Trainable params: 131,249
Non-trainable params: 0
_________________________________________________________________
モデルのコンパイルと訓練
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
history = model.fit(
train_batches,
epochs=10,
validation_data=test_batches, validation_steps=20)
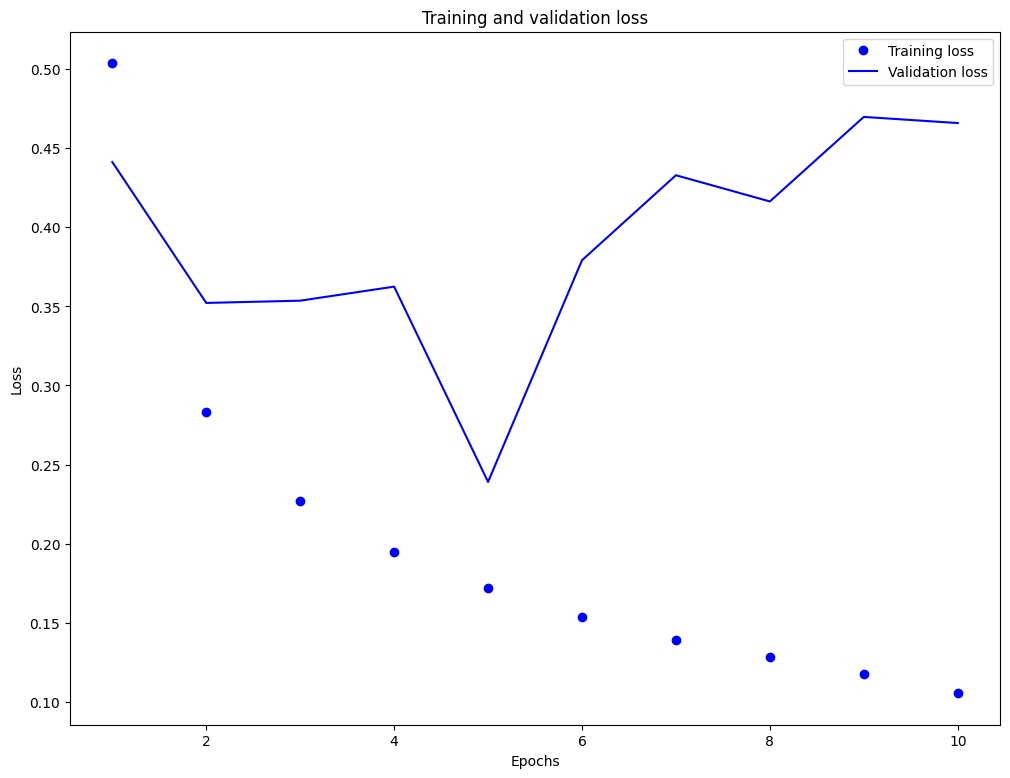
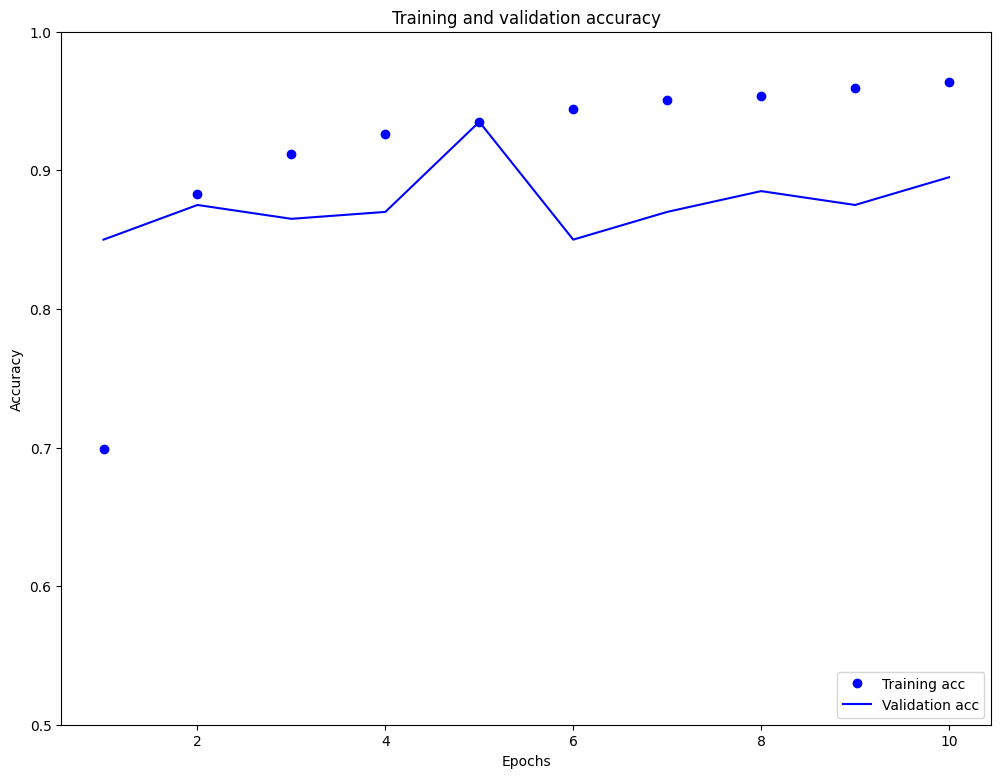
Epoch 1/10 2500/2500 [==============================] - 173s 68ms/step - loss: 0.5038 - accuracy: 0.6989 - val_loss: 0.4413 - val_accuracy: 0.8500 Epoch 2/10 2500/2500 [==============================] - 38s 15ms/step - loss: 0.2831 - accuracy: 0.8826 - val_loss: 0.3522 - val_accuracy: 0.8750 Epoch 3/10 2500/2500 [==============================] - 23s 9ms/step - loss: 0.2271 - accuracy: 0.9120 - val_loss: 0.3536 - val_accuracy: 0.8650 Epoch 4/10 2500/2500 [==============================] - 17s 7ms/step - loss: 0.1945 - accuracy: 0.9264 - val_loss: 0.3625 - val_accuracy: 0.8700 Epoch 5/10 2500/2500 [==============================] - 16s 6ms/step - loss: 0.1718 - accuracy: 0.9346 - val_loss: 0.2390 - val_accuracy: 0.9350 Epoch 6/10 2500/2500 [==============================] - 14s 6ms/step - loss: 0.1539 - accuracy: 0.9439 - val_loss: 0.3792 - val_accuracy: 0.8500 Epoch 7/10 2500/2500 [==============================] - 13s 5ms/step - loss: 0.1388 - accuracy: 0.9506 - val_loss: 0.4329 - val_accuracy: 0.8700 Epoch 8/10 2500/2500 [==============================] - 12s 5ms/step - loss: 0.1281 - accuracy: 0.9540 - val_loss: 0.4164 - val_accuracy: 0.8850 Epoch 9/10 2500/2500 [==============================] - 12s 5ms/step - loss: 0.1173 - accuracy: 0.9597 - val_loss: 0.4698 - val_accuracy: 0.8750 Epoch 10/10 2500/2500 [==============================] - 11s 4ms/step - loss: 0.1054 - accuracy: 0.9639 - val_loss: 0.4659 - val_accuracy: 0.8950
このアプローチにより、モデルの評価時の正解率は 88% 前後に達します(モデルは過学習しており、訓練時の正解率の方が際立って高いことに注意してください)。
import matplotlib.pyplot as plt
history_dict = history.history
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
loss=history_dict['loss']
val_loss=history_dict['val_loss']
epochs = range(1, len(acc) + 1)
plt.figure(figsize=(12,9))
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
plt.figure(figsize=(12,9))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.ylim((0.5,1))
plt.show()
学習した埋め込みの取得
次に、訓練によって学習された単語埋め込みを取得してみます。これは、shape が (vocab_size, embedding-dimension) の行列になります。
e = model.layers[0]
weights = e.get_weights()[0]
print(weights.shape) # shape: (vocab_size, embedding_dim)
(8185, 16)
この重みをディスクに出力します。Embedding Projector を使うため、タブ区切り形式の2つのファイルをアップロードします。(埋め込みを含む)ベクトルのファイルと、(単語を含む)メタデータファイルです。
import io
encoder = info.features['text'].encoder
out_v = io.open('vecs.tsv', 'w', encoding='utf-8')
out_m = io.open('meta.tsv', 'w', encoding='utf-8')
for num, word in enumerate(encoder.subwords):
vec = weights[num+1] # 0 はパディングのためスキップ
out_m.write(word + "\n")
out_v.write('\t'.join([str(x) for x in vec]) + "\n")
out_v.close()
out_m.close()
このチュートリアルを Colaboratory で実行している場合には、下記のコードを使ってこれらのファイルをローカルマシンにダウンロードすることができます(あるいは、ファイルブラウザを使います。表示 -> 目次 -> ファイル )。
try:
from google.colab import files
except ImportError:
pass
else:
files.download('vecs.tsv')
files.download('meta.tsv')
埋め込みを可視化する
埋め込みを可視化するため、これらのファイルを Embedding Projector にアップロードします。
Embedding Projector を開きます(あるいはローカルの TensorBoard でも実行できます)。
"Load data" をクリックします
上記で作成した
vecs.tsvとmeta.tsvの 2つのファイルをアップロードします
学習させた埋め込みが表示されます。単語を探し、最も近い単語を見つけることができます。たとえば、"beautiful" という単語を探してみてください。近くに、 "wonderful" のような単語が見つかると思います。
次のステップ
このチュートリアルでは、小さなデータセットを使い、単語埋め込みを最初から訓練し、可視化する方法を見てきました。
リカレントネットワークについて学ぶには、Keras RNN ガイド を参照してください。
テキスト分類について更に学ぶには、(全体のワークフローや、どういうときに埋め込みあるいはワンホットエンコーディングを使うべきかについて興味があれば)この実践的なテキスト分類の ガイド を推奨します。