
| | |  צפה במקור ב-GitHub צפה במקור ב-GitHub | |
מדריך זה מכיל מבוא להטמעות מילים. אתה תאמן את הטבעות המילים שלך באמצעות מודל פשוט של Keras עבור משימת סיווג רגשות, ולאחר מכן תדמיין אותן במקרן ההטמעה (מוצג בתמונה למטה).

הצגת טקסט כמספרים
מודלים של למידת מכונה לוקחים וקטורים (מערכי מספרים) כקלט. כשעובדים עם טקסט, הדבר הראשון שעליך לעשות הוא להמציא אסטרטגיה להמרת מחרוזות למספרים (או ל"וקטוריז" את הטקסט) לפני הזנתו למודל. בחלק זה, תסתכל על שלוש אסטרטגיות לעשות זאת.
קידודים חמים אחד
כרעיון ראשון, אתה עשוי לקודד כל מילה באוצר המילים שלך. קחו בחשבון את המשפט "החתול ישב על המחצלת". אוצר המילים (או המילים הייחודיות) במשפט זה הוא (חתול, מחצלת, על, ישב, את). כדי לייצג כל מילה, תיצור וקטור אפס באורך שווה לאוצר המילים, ולאחר מכן שים אחד באינדקס המתאים למילה. גישה זו מוצגת בתרשים הבא.
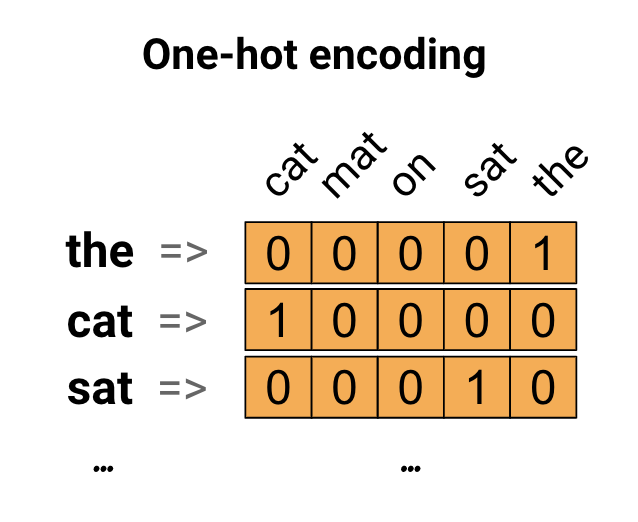
כדי ליצור וקטור המכיל את הקידוד של המשפט, תוכל לאחר מכן לשרשר את הוקטורים החמים לכל מילה.
יש לקודד כל מילה במספר ייחודי
גישה שנייה שאתה יכול לנסות היא לקודד כל מילה באמצעות מספר ייחודי. בהמשך לדוגמא למעלה, תוכל להקצות 1 ל"חתול", 2 ל"מחצלת" וכן הלאה. לאחר מכן תוכל לקודד את המשפט "החתול ישב על המחצלת" בתור וקטור צפוף כמו [5, 1, 4, 3, 5, 2]. גישה זו יעילה. במקום וקטור דליל, כעת יש לך וקטור צפוף (כאשר כל האלמנטים מלאים).
עם זאת, ישנם שני חסרונות לגישה זו:
קידוד המספרים השלמים הוא שרירותי (הוא לא לוכד שום קשר בין מילים).
קידוד של מספר שלם יכול להיות מאתגר עבור מודל לפרש. מסווג ליניארי, למשל, לומד משקל בודד עבור כל תכונה. מכיוון שאין קשר בין הדמיון של שתי מילים כלשהן לבין הדמיון של הקידוד שלהן, שילוב תכונה-משקל זה אינו בעל משמעות.
הטמעות מילים
הטבעות מילים נותנות לנו דרך להשתמש בייצוג יעיל וצפוף שבו למילים דומות יש קידוד דומה. חשוב לציין, אינך צריך לציין את הקידוד הזה ביד. הטבעה היא וקטור צפוף של ערכי נקודה צפה (אורך הווקטור הוא פרמטר שאתה מציין). במקום לציין את הערכים להטמעה באופן ידני, הם פרמטרים הניתנים לאימון (משקולות שנלמד על ידי המודל במהלך האימון, באותו אופן שבו דוגמנית לומדת משקלים לשכבה צפופה). נהוג לראות הטמעות מילים בעלות 8 מימד (עבור מערכי נתונים קטנים), עד 1024 ממדים כאשר עובדים עם מערכי נתונים גדולים. הטבעה בממדים גבוהים יותר יכולה ללכוד יחסים עדינים בין מילים, אך נדרשת יותר נתונים כדי ללמוד.
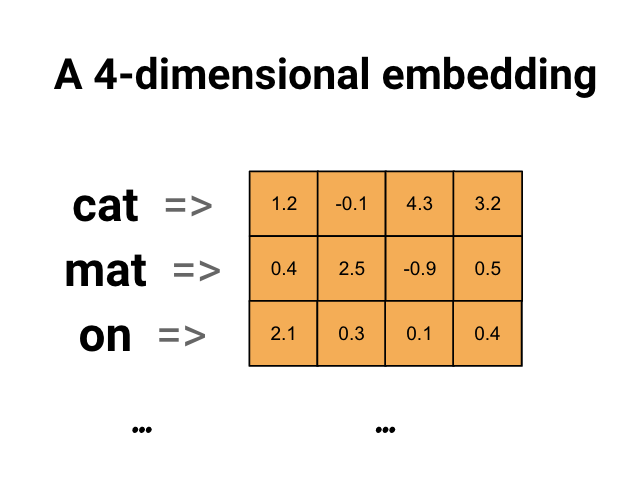
למעלה תרשים להטמעת מילה. כל מילה מיוצגת כווקטור 4 מימדי של ערכי נקודה צפה. דרך נוספת לחשוב על הטבעה היא כ"שולחן חיפוש". לאחר לימוד המשקולות הללו, תוכל לקודד כל מילה על ידי חיפוש הווקטור הצפוף שהוא מתאים לו בטבלה.
להכין
import io
import os
import re
import shutil
import string
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Embedding, GlobalAveragePooling1D
from tensorflow.keras.layers import TextVectorization
הורד את ערכת הנתונים של IMDb
אתה תשתמש בערכת סקירת הסרטים הגדולה דרך המדריך. אתה תאמן מודל סיווג סנטימנט על מערך הנתונים הזה ותוך כדי כך תלמד הטמעות מאפס. כדי לקרוא עוד על טעינת מערך נתונים מאפס, עיין במדריך לטעינת טקסט .
הורד את מערך הנתונים באמצעות כלי השירות של Keras והסתכל בספריות.
url = "https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
dataset = tf.keras.utils.get_file("aclImdb_v1.tar.gz", url,
untar=True, cache_dir='.',
cache_subdir='')
dataset_dir = os.path.join(os.path.dirname(dataset), 'aclImdb')
os.listdir(dataset_dir)
Downloading data from https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz 84131840/84125825 [==============================] - 7s 0us/step 84140032/84125825 [==============================] - 7s 0us/step ['test', 'imdb.vocab', 'imdbEr.txt', 'train', 'README']
תסתכל על train/ ספרייה. יש לו תיקיות pos ו- neg עם ביקורות סרטים המסומנות כחיוביות ושליליות בהתאמה. תשתמש בביקורות מתיקיות pos ו- neg כדי להכשיר מודל סיווג בינארי.
train_dir = os.path.join(dataset_dir, 'train')
os.listdir(train_dir)
['urls_pos.txt', 'urls_unsup.txt', 'urls_neg.txt', 'pos', 'unsup', 'unsupBow.feat', 'neg', 'labeledBow.feat']
בספריית train יש גם תיקיות נוספות שאותן יש להסיר לפני יצירת מערך הדרכה.
remove_dir = os.path.join(train_dir, 'unsup')
shutil.rmtree(remove_dir)
לאחר מכן, צור tf.data.Dataset באמצעות tf.keras.utils.text_dataset_from_directory . אתה יכול לקרוא עוד על השימוש בכלי זה במדריך זה לסיווג טקסט .
השתמש בספריית train ליצירת מערכי נתונים של רכבת ואימות עם חלוקה של 20% לאימות.
batch_size = 1024
seed = 123
train_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train', batch_size=batch_size, validation_split=0.2,
subset='training', seed=seed)
val_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train', batch_size=batch_size, validation_split=0.2,
subset='validation', seed=seed)
Found 25000 files belonging to 2 classes. Using 20000 files for training. Found 25000 files belonging to 2 classes. Using 5000 files for validation.
תסתכל על כמה ביקורות סרטים והתוויות שלהם (1: positive, 0: negative) ממערך הנתונים של הרכבת.
for text_batch, label_batch in train_ds.take(1):
for i in range(5):
print(label_batch[i].numpy(), text_batch.numpy()[i])
0 b"Oh My God! Please, for the love of all that is holy, Do Not Watch This Movie! It it 82 minutes of my life I will never get back. Sure, I could have stopped watching half way through. But I thought it might get better. It Didn't. Anyone who actually enjoyed this movie is one seriously sick and twisted individual. No wonder us Australians/New Zealanders have a terrible reputation when it comes to making movies. Everything about this movie is horrible, from the acting to the editing. I don't even normally write reviews on here, but in this case I'll make an exception. I only wish someone had of warned me before I hired this catastrophe" 1 b'This movie is SOOOO funny!!! The acting is WONDERFUL, the Ramones are sexy, the jokes are subtle, and the plot is just what every high schooler dreams of doing to his/her school. I absolutely loved the soundtrack as well as the carefully placed cynicism. If you like monty python, You will love this film. This movie is a tad bit "grease"esk (without all the annoying songs). The songs that are sung are likable; you might even find yourself singing these songs once the movie is through. This musical ranks number two in musicals to me (second next to the blues brothers). But please, do not think of it as a musical per say; seeing as how the songs are so likable, it is hard to tell a carefully choreographed scene is taking place. I think of this movie as more of a comedy with undertones of romance. You will be reminded of what it was like to be a rebellious teenager; needless to say, you will be reminiscing of your old high school days after seeing this film. Highly recommended for both the family (since it is a very youthful but also for adults since there are many jokes that are funnier with age and experience.' 0 b"Alex D. Linz replaces Macaulay Culkin as the central figure in the third movie in the Home Alone empire. Four industrial spies acquire a missile guidance system computer chip and smuggle it through an airport inside a remote controlled toy car. Because of baggage confusion, grouchy Mrs. Hess (Marian Seldes) gets the car. She gives it to her neighbor, Alex (Linz), just before the spies turn up. The spies rent a house in order to burglarize each house in the neighborhood until they locate the car. Home alone with the chicken pox, Alex calls 911 each time he spots a theft in progress, but the spies always manage to elude the police while Alex is accused of making prank calls. The spies finally turn their attentions toward Alex, unaware that he has rigged devices to cleverly booby-trap his entire house. Home Alone 3 wasn't horrible, but probably shouldn't have been made, you can't just replace Macauley Culkin, Joe Pesci, or Daniel Stern. Home Alone 3 had some funny parts, but I don't like when characters are changed in a movie series, view at own risk." 0 b"There's a good movie lurking here, but this isn't it. The basic idea is good: to explore the moral issues that would face a group of young survivors of the apocalypse. But the logic is so muddled that it's impossible to get involved.<br /><br />For example, our four heroes are (understandably) paranoid about catching the mysterious airborne contagion that's wiped out virtually all of mankind. Yet they wear surgical masks some times, not others. Some times they're fanatical about wiping down with bleach any area touched by an infected person. Other times, they seem completely unconcerned.<br /><br />Worse, after apparently surviving some weeks or months in this new kill-or-be-killed world, these people constantly behave like total newbs. They don't bother accumulating proper equipment, or food. They're forever running out of fuel in the middle of nowhere. They don't take elementary precautions when meeting strangers. And after wading through the rotting corpses of the entire human race, they're as squeamish as sheltered debutantes. You have to constantly wonder how they could have survived this long... and even if they did, why anyone would want to make a movie about them.<br /><br />So when these dweebs stop to agonize over the moral dimensions of their actions, it's impossible to take their soul-searching seriously. Their actions would first have to make some kind of minimal sense.<br /><br />On top of all this, we must contend with the dubious acting abilities of Chris Pine. His portrayal of an arrogant young James T Kirk might have seemed shrewd, when viewed in isolation. But in Carriers he plays on exactly that same note: arrogant and boneheaded. It's impossible not to suspect that this constitutes his entire dramatic range.<br /><br />On the positive side, the film *looks* excellent. It's got an over-sharp, saturated look that really suits the southwestern US locale. But that can't save the truly feeble writing nor the paper-thin (and annoying) characters. Even if you're a fan of the end-of-the-world genre, you should save yourself the agony of watching Carriers." 0 b'I saw this movie at an actual movie theater (probably the \\(2.00 one) with my cousin and uncle. We were around 11 and 12, I guess, and really into scary movies. I remember being so excited to see it because my cool uncle let us pick the movie (and we probably never got to do that again!) and sooo disappointed afterwards!! Just boring and not scary. The only redeeming thing I can remember was Corky Pigeon from Silver Spoons, and that wasn\'t all that great, just someone I recognized. I\'ve seen bad movies before and this one has always stuck out in my mind as the worst. This was from what I can recall, one of the most boring, non-scary, waste of our collective \\)6, and a waste of film. I have read some of the reviews that say it is worth a watch and I say, "Too each his own", but I wouldn\'t even bother. Not even so bad it\'s good.'
הגדר את מערך הנתונים לביצועים
אלו הן שתי שיטות חשובות שבהן אתה צריך להשתמש בעת טעינת נתונים כדי לוודא שהקלט/פלט לא ייחסם.
.cache() שומר נתונים בזיכרון לאחר טעינתם מהדיסק. זה יבטיח שמערך הנתונים לא יהפוך לצוואר בקבוק בזמן אימון המודל שלך. אם מערך הנתונים שלך גדול מכדי להתאים לזיכרון, אתה יכול גם להשתמש בשיטה זו כדי ליצור מטמון בעל ביצועים בדיסק, שיותר יעיל לקריאה מקבצים קטנים רבים.
.prefetch() חופף לעיבוד מקדים של נתונים וביצוע מודלים בזמן האימון.
תוכל ללמוד עוד על שתי השיטות, כמו גם כיצד לשמר נתונים בדיסק במדריך ביצועי הנתונים .
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
שימוש בשכבת Embedding
Keras מקל על השימוש בהטמעות מילים. תסתכל על שכבת ההטמעה .
ניתן להבין את שכבת ההטמעה כטבלת חיפוש הממפה ממדדים שלמים (המייצגים מילים ספציפיות) לוקטורים צפופים (ההטבעות שלהם). הממדיות (או הרוחב) של ההטמעה היא פרמטר שאתה יכול להתנסות איתו כדי לראות מה עובד טוב עבור הבעיה שלך, בדיוק באותו אופן שבו הייתם מתנסים עם מספר הנוירונים בשכבה צפופה.
# Embed a 1,000 word vocabulary into 5 dimensions.
embedding_layer = tf.keras.layers.Embedding(1000, 5)
כאשר אתה יוצר שכבת Embedding, המשקולות להטמעה מאותחלות באופן אקראי (בדיוק כמו כל שכבה אחרת). במהלך האימון, הם מותאמים בהדרגה באמצעות התפשטות לאחור. לאחר הכשרה, הטמעות המילים הנלמדות יקודדו בערך קווי דמיון בין מילים (כפי שהן נלמדו עבור הבעיה הספציפית שעליה הוכשר המודל שלך).
אם תעביר מספר שלם לשכבת הטבעה, התוצאה מחליפה כל מספר שלם בוקטור מטבלת ההטמעה:
result = embedding_layer(tf.constant([1, 2, 3]))
result.numpy()
array([[ 0.01318491, -0.02219239, 0.024673 , -0.03208025, 0.02297195],
[-0.00726584, 0.03731754, -0.01209557, -0.03887399, -0.02407478],
[ 0.04477594, 0.04504738, -0.02220147, -0.03642888, -0.04688282]],
dtype=float32)
עבור בעיות טקסט או רצף, שכבת Embedding לוקחת טנזור דו-ממדי של מספרים שלמים, של צורה (samples, sequence_length) , כאשר כל ערך הוא רצף של מספרים שלמים. זה יכול להטביע רצפים באורכים משתנים. אתה יכול להזין את שכבת ההטבעה מעל אצווה עם צורות (32, 10) (אצווה של 32 רצפים באורך 10) או (64, 15) (אצווה של 64 רצפים באורך 15).
לטנזור המוחזר יש ציר אחד יותר מהקלט, הוקטורים המוטבעים מיושרים לאורך הציר האחרון החדש. העבירו לו אצווה (2, 3) קלט והפלט הוא (2, 3, N)
result = embedding_layer(tf.constant([[0, 1, 2], [3, 4, 5]]))
result.shape
TensorShape([2, 3, 5])
כאשר ניתנת אצווה של רצפים כקלט, שכבת הטבעה מחזירה טנזור נקודה צפה תלת מימדית, בעלת צורה (samples, sequence_length, embedding_dimensionality) . כדי להמיר מרצף זה של אורך משתנה לייצוג קבוע יש מגוון גישות סטנדרטיות. אתה יכול להשתמש בשכבת RNN, Attention או Pooling לפני שתעביר אותה לשכבה צפופה. הדרכה זו משתמשת ב-pooling כי זה הפשוט ביותר. סיווג הטקסט עם מדריך RNN הוא השלב הבא טוב.
עיבוד מקדים של טקסט
לאחר מכן, הגדר את שלבי העיבוד המקדים של מערך הנתונים הנדרשים עבור מודל סיווג הסנטימנט שלך. אתחול שכבת TextVectorization עם הפרמטרים הרצויים כדי לעצב ביקורות סרטים. תוכל ללמוד עוד על השימוש בשכבה זו במדריך סיווג טקסט .
# Create a custom standardization function to strip HTML break tags '<br />'.
def custom_standardization(input_data):
lowercase = tf.strings.lower(input_data)
stripped_html = tf.strings.regex_replace(lowercase, '<br />', ' ')
return tf.strings.regex_replace(stripped_html,
'[%s]' % re.escape(string.punctuation), '')
# Vocabulary size and number of words in a sequence.
vocab_size = 10000
sequence_length = 100
# Use the text vectorization layer to normalize, split, and map strings to
# integers. Note that the layer uses the custom standardization defined above.
# Set maximum_sequence length as all samples are not of the same length.
vectorize_layer = TextVectorization(
standardize=custom_standardization,
max_tokens=vocab_size,
output_mode='int',
output_sequence_length=sequence_length)
# Make a text-only dataset (no labels) and call adapt to build the vocabulary.
text_ds = train_ds.map(lambda x, y: x)
vectorize_layer.adapt(text_ds)
צור מודל סיווג
השתמש ב- Keras Sequential API כדי להגדיר את מודל סיווג הסנטימנט. במקרה זה מדובר בדגם בסגנון "שק רציף של מילים".
- שכבת
TextVectorizationהופכת מחרוזות למדדי אוצר מילים. כבר אתחולת אתvectorize_layerכשכבת TextVectorization ובנית את אוצר המילים שלה על ידי קריאהadaptontext_ds. כעת, vectorize_layer יכול לשמש כשכבה הראשונה של מודל הסיווג מקצה לקצה שלך, להזין מחרוזות שעברו טרנספורמציה לשכבת Embedding. שכבת
Embeddingלוקחת את אוצר המילים המקודד במספרים שלמים ומחפשת את וקטור ההטמעה עבור כל אינדקס מילים. וקטורים אלה נלמדים כאשר המודל מתאמן. הוקטורים מוסיפים מימד למערך הפלט. הממדים המתקבלים הם:(batch, sequence, embedding).שכבת
GlobalAveragePooling1Dמחזירה וקטור פלט באורך קבוע עבור כל דוגמה על ידי ממוצע על ממד הרצף. זה מאפשר למודל לטפל בקלט באורך משתנה, בצורה הפשוטה ביותר.וקטור הפלט באורך קבוע עובר דרך שכבה מחוברת מלאה (
Dense) עם 16 יחידות נסתרות.השכבה האחרונה מחוברת בצפיפות עם צומת פלט יחיד.
embedding_dim=16
model = Sequential([
vectorize_layer,
Embedding(vocab_size, embedding_dim, name="embedding"),
GlobalAveragePooling1D(),
Dense(16, activation='relu'),
Dense(1)
])
הרכיבו והכשירו את המודל
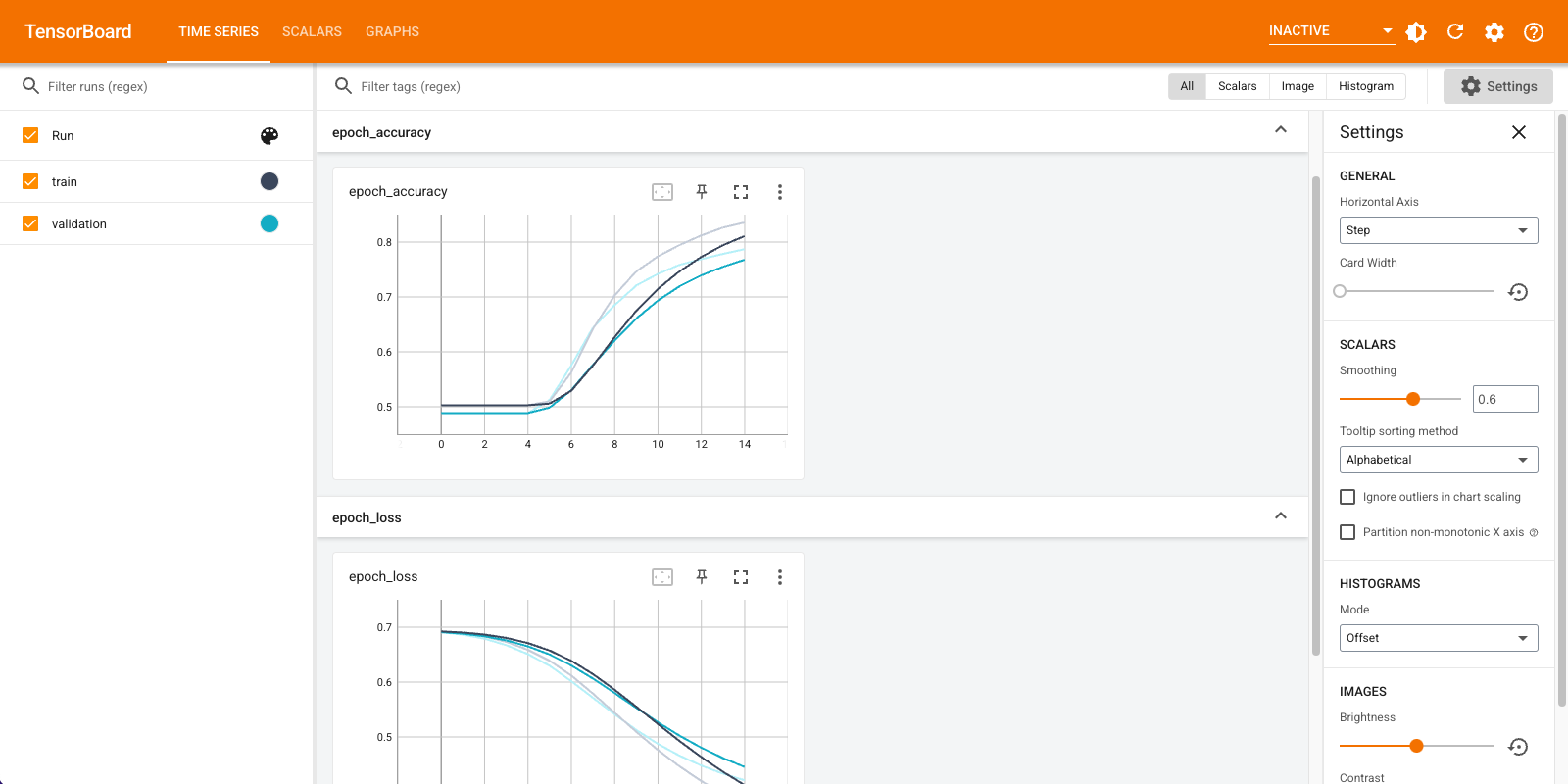
אתה תשתמש ב- TensorBoard כדי להמחיש מדדים כולל אובדן ודיוק. צור tf.keras.callbacks.TensorBoard .
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir="logs")
הידור ואימון המודל באמצעות ה- Adam Optimizer ואובדן BinaryCrossentropy .
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(
train_ds,
validation_data=val_ds,
epochs=15,
callbacks=[tensorboard_callback])
Epoch 1/15 20/20 [==============================] - 2s 71ms/step - loss: 0.6910 - accuracy: 0.5028 - val_loss: 0.6878 - val_accuracy: 0.4886 Epoch 2/15 20/20 [==============================] - 1s 57ms/step - loss: 0.6838 - accuracy: 0.5028 - val_loss: 0.6791 - val_accuracy: 0.4886 Epoch 3/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6726 - accuracy: 0.5028 - val_loss: 0.6661 - val_accuracy: 0.4886 Epoch 4/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6563 - accuracy: 0.5028 - val_loss: 0.6481 - val_accuracy: 0.4886 Epoch 5/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6343 - accuracy: 0.5061 - val_loss: 0.6251 - val_accuracy: 0.5066 Epoch 6/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6068 - accuracy: 0.5634 - val_loss: 0.5982 - val_accuracy: 0.5762 Epoch 7/15 20/20 [==============================] - 1s 58ms/step - loss: 0.5752 - accuracy: 0.6405 - val_loss: 0.5690 - val_accuracy: 0.6386 Epoch 8/15 20/20 [==============================] - 1s 58ms/step - loss: 0.5412 - accuracy: 0.7036 - val_loss: 0.5390 - val_accuracy: 0.6850 Epoch 9/15 20/20 [==============================] - 1s 59ms/step - loss: 0.5064 - accuracy: 0.7479 - val_loss: 0.5106 - val_accuracy: 0.7222 Epoch 10/15 20/20 [==============================] - 1s 59ms/step - loss: 0.4734 - accuracy: 0.7774 - val_loss: 0.4855 - val_accuracy: 0.7430 Epoch 11/15 20/20 [==============================] - 1s 59ms/step - loss: 0.4432 - accuracy: 0.7971 - val_loss: 0.4636 - val_accuracy: 0.7570 Epoch 12/15 20/20 [==============================] - 1s 58ms/step - loss: 0.4161 - accuracy: 0.8155 - val_loss: 0.4453 - val_accuracy: 0.7674 Epoch 13/15 20/20 [==============================] - 1s 59ms/step - loss: 0.3921 - accuracy: 0.8304 - val_loss: 0.4303 - val_accuracy: 0.7780 Epoch 14/15 20/20 [==============================] - 1s 61ms/step - loss: 0.3711 - accuracy: 0.8398 - val_loss: 0.4181 - val_accuracy: 0.7884 Epoch 15/15 20/20 [==============================] - 1s 58ms/step - loss: 0.3524 - accuracy: 0.8493 - val_loss: 0.4082 - val_accuracy: 0.7948 <keras.callbacks.History at 0x7fca579745d0>
בגישה זו המודל מגיע לדיוק אימות של בסביבות 78% (שימו לב שהמודל מתאים יתר על המידה שכן דיוק האימון גבוה יותר).
אתה יכול לעיין בסיכום המודל כדי ללמוד עוד על כל שכבה של המודל.
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
text_vectorization (TextVec (None, 100) 0
torization)
embedding (Embedding) (None, 100, 16) 160000
global_average_pooling1d (G (None, 16) 0
lobalAveragePooling1D)
dense (Dense) (None, 16) 272
dense_1 (Dense) (None, 1) 17
=================================================================
Total params: 160,289
Trainable params: 160,289
Non-trainable params: 0
_________________________________________________________________
דמיין את מדדי המודל ב-TensorBoard.
#docs_infra: no_execute
%load_ext tensorboard
%tensorboard --logdir logs
אחזר את הטמעות המילים המאומנות ושמור אותן בדיסק
לאחר מכן, אחזר את המילה הטמעות שנלמדו במהלך האימון. ההטבעות הן משקלים של שכבת ה- Embedding בדגם. מטריצת המשקולות היא בעלת צורה (vocab_size, embedding_dimension) .
השג את המשקולות מהמודל באמצעות get_layer() ו- get_weights() . get_vocabulary() מספקת את אוצר המילים לבניית קובץ מטא נתונים עם אסימון אחד בכל שורה.
weights = model.get_layer('embedding').get_weights()[0]
vocab = vectorize_layer.get_vocabulary()
כתוב את המשקולות לדיסק. כדי להשתמש ב- Embedding Projector , תעלה שני קבצים בפורמט מופרד באמצעות כרטיסיות: קובץ וקטורים (המכיל את ההטמעה), וקובץ מטא נתונים (המכיל את המילים).
out_v = io.open('vectors.tsv', 'w', encoding='utf-8')
out_m = io.open('metadata.tsv', 'w', encoding='utf-8')
for index, word in enumerate(vocab):
if index == 0:
continue # skip 0, it's padding.
vec = weights[index]
out_v.write('\t'.join([str(x) for x in vec]) + "\n")
out_m.write(word + "\n")
out_v.close()
out_m.close()
אם אתה מפעיל מדריך זה ב- Colaboratory , אתה יכול להשתמש בקטע הבא כדי להוריד קבצים אלה למחשב המקומי שלך (או השתמש בדפדפן הקבצים, תצוגה -> תוכן העניינים -> דפדפן קבצים ).
try:
from google.colab import files
files.download('vectors.tsv')
files.download('metadata.tsv')
except Exception:
pass
דמיינו את ההטבעות
כדי לדמיין את ההטבעות, העלה אותן למקרן ההטמעה.
פתח את מקרן הטבעה (זה יכול לפעול גם במופע של TensorBoard מקומי).
לחץ על "טען נתונים".
העלה את שני הקבצים שיצרת למעלה:
vecs.tsvו-meta.tsv.
ההטבעות שאימנת יוצגו כעת. אתה יכול לחפש מילים כדי למצוא את שכניהם הקרובים ביותר. לדוגמה, נסה לחפש "יפה". אתה עשוי לראות שכנים כמו "נפלא".
הצעדים הבאים
מדריך זה הראה לך כיצד לאמן ולהמחיש הטמעת מילים מאפס על מערך נתונים קטן.
כדי לאמן הטבעת מילים באמצעות אלגוריתם Word2Vec, נסה את המדריך של Word2Vec .
למידע נוסף על עיבוד טקסט מתקדם, קרא את מודל Transformer להבנת שפה .