
| | |  Kaynağı GitHub'da görüntüleyin Kaynağı GitHub'da görüntüleyin | |
Bu öğretici, sözcük yerleştirmelerine bir giriş içerir. Duygu sınıflandırma görevi için basit bir Keras modeli kullanarak kendi sözcük yerleştirmelerinizi eğitecek ve ardından bunları Gömme Projektöründe (aşağıdaki resimde gösterilmiştir) görselleştireceksiniz.

Metni sayılarla temsil etme
Makine öğrenimi modelleri, girdi olarak vektörleri (sayı dizileri) alır. Metinle çalışırken, yapmanız gereken ilk şey, modele beslemeden önce dizeleri sayılara dönüştürmek (veya metni "vektörleştirmek") için bir strateji bulmaktır. Bu bölümde, bunu yapmak için üç stratejiye bakacaksınız.
Tek sıcak kodlamalar
İlk fikir olarak, kelime dağarcığınızdaki her kelimeyi "tek-sıcak" olarak kodlayabilirsiniz. "Kedi mindere oturdu" cümlesini düşünün. Bu cümledeki kelime (veya benzersiz kelimeler) (cat, mat, on, sat, the). Her bir kelimeyi temsil etmek için, kelime dağarcığına eşit uzunlukta bir sıfır vektör oluşturacaksınız, ardından kelimeye karşılık gelen dizine bir tane yerleştireceksiniz. Bu yaklaşım aşağıdaki şemada gösterilmiştir.
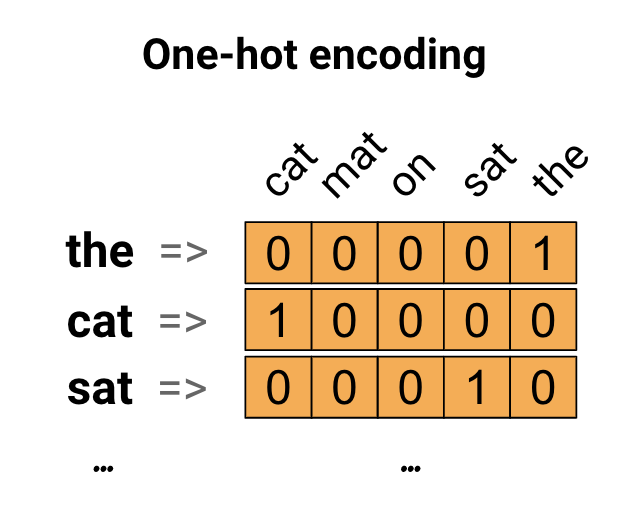
Cümlenin kodlamasını içeren bir vektör oluşturmak için, her bir kelime için tek-sıcak vektörleri birleştirebilirsiniz.
Her kelimeyi benzersiz bir sayı ile kodlayın
Deneyebileceğiniz ikinci bir yaklaşım, her kelimeyi benzersiz bir sayı kullanarak kodlamaktır. Yukarıdaki örneğe devam ederek, 1'i "kedi"ye, 2'yi "mat"a vb. atayabilirsiniz. Daha sonra "Kedi mindere oturdu" cümlesini [5, 1, 4, 3, 5, 2] gibi yoğun bir vektör olarak kodlayabilirsiniz. Bu yaklaşım verimlidir. Seyrek bir vektör yerine, artık yoğun bir vektörünüz var (tüm öğelerin dolu olduğu).
Ancak bu yaklaşımın iki dezavantajı vardır:
Tamsayı kodlaması keyfidir (kelimeler arasında herhangi bir ilişki yakalamaz).
Bir tamsayı kodlaması, bir modelin yorumlanması için zor olabilir. Örneğin doğrusal bir sınıflandırıcı, her özellik için tek bir ağırlık öğrenir. Herhangi iki kelimenin benzerliği ile kodlamalarının benzerliği arasında bir ilişki olmadığı için bu özellik-ağırlık kombinasyonu anlamlı değildir.
Kelime yerleştirmeleri
Kelime yerleştirmeleri, benzer kelimelerin benzer bir kodlamaya sahip olduğu verimli, yoğun bir temsil kullanmanın bir yolunu sunar. Daha da önemlisi, bu kodlamayı elle belirtmeniz gerekmez. Gömme, kayan nokta değerlerinin yoğun bir vektörüdür (vektörün uzunluğu, belirttiğiniz bir parametredir). Gömme için değerleri manuel olarak belirtmek yerine, bunlar eğitilebilir parametrelerdir (eğitim sırasında model tarafından öğrenilen ağırlıklar, aynı şekilde bir modelin yoğun bir katman için ağırlıkları öğrenmesi gibi). Büyük veri kümeleriyle çalışırken 1024 boyuta kadar 8 boyutlu (küçük veri kümeleri için) sözcük yerleştirmelerini görmek yaygındır. Daha yüksek boyutlu bir yerleştirme, kelimeler arasındaki ince taneli ilişkileri yakalayabilir, ancak öğrenmek için daha fazla veri gerekir.
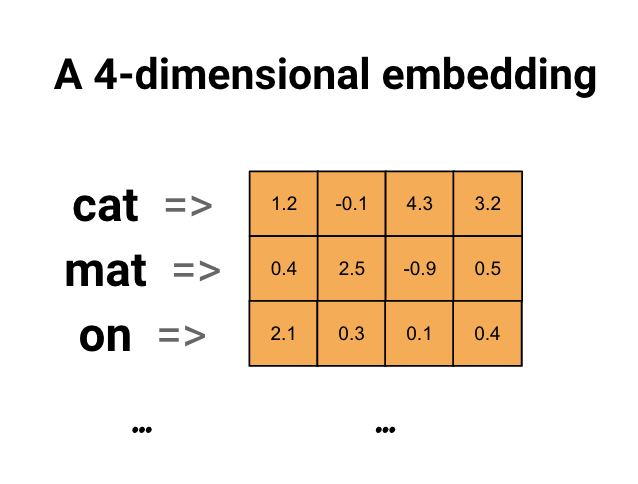
Yukarıda bir kelime gömme için bir diyagramdır. Her kelime, kayan nokta değerlerinin 4 boyutlu bir vektörü olarak temsil edilir. Gömmeyi düşünmenin başka bir yolu da "arama tablosu"dur. Bu ağırlıklar öğrenildikten sonra tabloda karşılık gelen yoğun vektöre bakarak her bir kelimeyi kodlayabilirsiniz.
Kurmak
import io
import os
import re
import shutil
import string
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Embedding, GlobalAveragePooling1D
from tensorflow.keras.layers import TextVectorization
IMDb Veri Kümesini İndirin
Eğitim boyunca Büyük Film İnceleme Veri Kümesini kullanacaksınız. Bu veri kümesinde bir duyarlılık sınıflandırıcı modeli eğitecek ve bu süreçte yerleştirmeleri sıfırdan öğreneceksiniz. Bir veri kümesini sıfırdan yükleme hakkında daha fazla bilgi için Metin yükleme öğreticisine bakın.
Keras dosya yardımcı programını kullanarak veri setini indirin ve dizinlere bir göz atın.
url = "https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
dataset = tf.keras.utils.get_file("aclImdb_v1.tar.gz", url,
untar=True, cache_dir='.',
cache_subdir='')
dataset_dir = os.path.join(os.path.dirname(dataset), 'aclImdb')
os.listdir(dataset_dir)
Downloading data from https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz 84131840/84125825 [==============================] - 7s 0us/step 84140032/84125825 [==============================] - 7s 0us/step ['test', 'imdb.vocab', 'imdbEr.txt', 'train', 'README']
train/ dizinine bir göz atın. Sırasıyla olumlu ve olumsuz olarak etiketlenmiş film incelemeleri içeren pos ve neg klasörleri vardır. İkili sınıflandırma modelini eğitmek için pos ve neg klasörlerindeki incelemeleri kullanacaksınız.
train_dir = os.path.join(dataset_dir, 'train')
os.listdir(train_dir)
['urls_pos.txt', 'urls_unsup.txt', 'urls_neg.txt', 'pos', 'unsup', 'unsupBow.feat', 'neg', 'labeledBow.feat']
train dizini ayrıca eğitim veri kümesi oluşturmadan önce kaldırılması gereken ek klasörlere sahiptir.
remove_dir = os.path.join(train_dir, 'unsup')
shutil.rmtree(remove_dir)
Ardından, tf.data.Dataset kullanarak bir tf.keras.utils.text_dataset_from_directory oluşturun. Bu metin sınıflandırma eğitiminde bu yardımcı programı kullanma hakkında daha fazla bilgi edinebilirsiniz.
Doğrulama için %20'lik bir bölmeyle hem tren hem de doğrulama veri kümeleri oluşturmak için train dizinini kullanın.
batch_size = 1024
seed = 123
train_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train', batch_size=batch_size, validation_split=0.2,
subset='training', seed=seed)
val_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train', batch_size=batch_size, validation_split=0.2,
subset='validation', seed=seed)
Found 25000 files belonging to 2 classes. Using 20000 files for training. Found 25000 files belonging to 2 classes. Using 5000 files for validation.
Tren veri setinden birkaç film incelemesine ve etiketlerine (1: positive, 0: negative) bir göz atın.
for text_batch, label_batch in train_ds.take(1):
for i in range(5):
print(label_batch[i].numpy(), text_batch.numpy()[i])
0 b"Oh My God! Please, for the love of all that is holy, Do Not Watch This Movie! It it 82 minutes of my life I will never get back. Sure, I could have stopped watching half way through. But I thought it might get better. It Didn't. Anyone who actually enjoyed this movie is one seriously sick and twisted individual. No wonder us Australians/New Zealanders have a terrible reputation when it comes to making movies. Everything about this movie is horrible, from the acting to the editing. I don't even normally write reviews on here, but in this case I'll make an exception. I only wish someone had of warned me before I hired this catastrophe" 1 b'This movie is SOOOO funny!!! The acting is WONDERFUL, the Ramones are sexy, the jokes are subtle, and the plot is just what every high schooler dreams of doing to his/her school. I absolutely loved the soundtrack as well as the carefully placed cynicism. If you like monty python, You will love this film. This movie is a tad bit "grease"esk (without all the annoying songs). The songs that are sung are likable; you might even find yourself singing these songs once the movie is through. This musical ranks number two in musicals to me (second next to the blues brothers). But please, do not think of it as a musical per say; seeing as how the songs are so likable, it is hard to tell a carefully choreographed scene is taking place. I think of this movie as more of a comedy with undertones of romance. You will be reminded of what it was like to be a rebellious teenager; needless to say, you will be reminiscing of your old high school days after seeing this film. Highly recommended for both the family (since it is a very youthful but also for adults since there are many jokes that are funnier with age and experience.' 0 b"Alex D. Linz replaces Macaulay Culkin as the central figure in the third movie in the Home Alone empire. Four industrial spies acquire a missile guidance system computer chip and smuggle it through an airport inside a remote controlled toy car. Because of baggage confusion, grouchy Mrs. Hess (Marian Seldes) gets the car. She gives it to her neighbor, Alex (Linz), just before the spies turn up. The spies rent a house in order to burglarize each house in the neighborhood until they locate the car. Home alone with the chicken pox, Alex calls 911 each time he spots a theft in progress, but the spies always manage to elude the police while Alex is accused of making prank calls. The spies finally turn their attentions toward Alex, unaware that he has rigged devices to cleverly booby-trap his entire house. Home Alone 3 wasn't horrible, but probably shouldn't have been made, you can't just replace Macauley Culkin, Joe Pesci, or Daniel Stern. Home Alone 3 had some funny parts, but I don't like when characters are changed in a movie series, view at own risk." 0 b"There's a good movie lurking here, but this isn't it. The basic idea is good: to explore the moral issues that would face a group of young survivors of the apocalypse. But the logic is so muddled that it's impossible to get involved.<br /><br />For example, our four heroes are (understandably) paranoid about catching the mysterious airborne contagion that's wiped out virtually all of mankind. Yet they wear surgical masks some times, not others. Some times they're fanatical about wiping down with bleach any area touched by an infected person. Other times, they seem completely unconcerned.<br /><br />Worse, after apparently surviving some weeks or months in this new kill-or-be-killed world, these people constantly behave like total newbs. They don't bother accumulating proper equipment, or food. They're forever running out of fuel in the middle of nowhere. They don't take elementary precautions when meeting strangers. And after wading through the rotting corpses of the entire human race, they're as squeamish as sheltered debutantes. You have to constantly wonder how they could have survived this long... and even if they did, why anyone would want to make a movie about them.<br /><br />So when these dweebs stop to agonize over the moral dimensions of their actions, it's impossible to take their soul-searching seriously. Their actions would first have to make some kind of minimal sense.<br /><br />On top of all this, we must contend with the dubious acting abilities of Chris Pine. His portrayal of an arrogant young James T Kirk might have seemed shrewd, when viewed in isolation. But in Carriers he plays on exactly that same note: arrogant and boneheaded. It's impossible not to suspect that this constitutes his entire dramatic range.<br /><br />On the positive side, the film *looks* excellent. It's got an over-sharp, saturated look that really suits the southwestern US locale. But that can't save the truly feeble writing nor the paper-thin (and annoying) characters. Even if you're a fan of the end-of-the-world genre, you should save yourself the agony of watching Carriers." 0 b'I saw this movie at an actual movie theater (probably the \\(2.00 one) with my cousin and uncle. We were around 11 and 12, I guess, and really into scary movies. I remember being so excited to see it because my cool uncle let us pick the movie (and we probably never got to do that again!) and sooo disappointed afterwards!! Just boring and not scary. The only redeeming thing I can remember was Corky Pigeon from Silver Spoons, and that wasn\'t all that great, just someone I recognized. I\'ve seen bad movies before and this one has always stuck out in my mind as the worst. This was from what I can recall, one of the most boring, non-scary, waste of our collective \\)6, and a waste of film. I have read some of the reviews that say it is worth a watch and I say, "Too each his own", but I wouldn\'t even bother. Not even so bad it\'s good.'
Performans için veri kümesini yapılandırın
Bunlar, G/Ç'nin bloke olmadığından emin olmak için veri yüklerken kullanmanız gereken iki önemli yöntemdir.
.cache() , diskten yüklendikten sonra verileri bellekte tutar. Bu, modelinizi eğitirken veri setinin bir darboğaz haline gelmemesini sağlayacaktır. Veri kümeniz belleğe sığmayacak kadar büyükse, bu yöntemi, okuması birçok küçük dosyadan daha verimli olan, performanslı bir disk önbelleği oluşturmak için de kullanabilirsiniz.
.prefetch() , eğitim sırasında veri ön işleme ve model yürütme ile çakışır.
Veri performans kılavuzunda her iki yöntem hakkında ve ayrıca verilerin diske nasıl önbelleğe alınacağı hakkında daha fazla bilgi edinebilirsiniz.
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
Gömme katmanını kullanma
Keras, sözcük yerleştirmelerini kullanmayı kolaylaştırır. Gömme katmanına bir göz atın.
Gömme katmanı, tamsayı endekslerinden (belirli sözcükleri temsil eden) yoğun vektörlere (gömmelerine) eşlenen bir arama tablosu olarak anlaşılabilir. Gömmenin boyutluluğu (veya genişliği), probleminiz için neyin işe yaradığını görmek için deneyebileceğiniz bir parametredir, tıpkı Yoğun bir katmandaki nöronların sayısıyla yaptığınız deneylerle aynı şekilde.
# Embed a 1,000 word vocabulary into 5 dimensions.
embedding_layer = tf.keras.layers.Embedding(1000, 5)
Bir Gömme katmanı oluşturduğunuzda, gömme ağırlıkları rastgele başlatılır (tıpkı diğer katmanlar gibi). Eğitim sırasında, geri yayılım yoluyla kademeli olarak ayarlanırlar. Bir kez eğitildikten sonra, öğrenilen kelime yerleştirmeleri, kelimeler arasındaki benzerlikleri kabaca kodlayacaktır (modelinizin üzerinde eğitim aldığı belirli problem için öğrenildikleri gibi).
Bir gömme katmanına bir tamsayı iletirseniz, sonuç her tamsayıyı gömme tablosundaki vektörle değiştirir:
result = embedding_layer(tf.constant([1, 2, 3]))
result.numpy()
array([[ 0.01318491, -0.02219239, 0.024673 , -0.03208025, 0.02297195],
[-0.00726584, 0.03731754, -0.01209557, -0.03887399, -0.02407478],
[ 0.04477594, 0.04504738, -0.02220147, -0.03642888, -0.04688282]],
dtype=float32)
Metin veya dizi sorunları için, Gömme katmanı, her girişin bir tamsayı dizisi olduğu şekilde (samples, sequence_length) tamsayılardan oluşan bir 2B tensör alır. Değişken uzunluktaki dizileri gömebilir. Gömme katmanını (32, 10) (32 dizi uzunluğunda 10 dizi) veya (64, 15) (64 uzunlukta 15 diziden oluşan toplu) şekillerle toplu işlerin üzerine besleyebilirsiniz.
Döndürülen tensör, girişten bir eksene daha sahiptir, gömme vektörleri yeni son eksen boyunca hizalanır. Bir (2, 3) giriş partisi iletin ve çıktı (2, 3, N)
result = embedding_layer(tf.constant([[0, 1, 2], [3, 4, 5]]))
result.shape
TensorShape([2, 3, 5])
Girdi olarak bir dizi dizisi verildiğinde, bir gömme katmanı, şekle (samples, sequence_length, embedding_dimensionality) sahip bir 3B kayan nokta tensörü döndürür. Bu değişken uzunluk dizisinden sabit bir gösterime dönüştürmek için çeşitli standart yaklaşımlar vardır. Yoğun bir katmana geçirmeden önce bir RNN, Dikkat veya havuz katmanı kullanabilirsiniz. Bu öğretici, en basiti olduğu için havuzlamayı kullanır. Bir RNN öğreticisiyle Metin Sınıflandırması, sonraki iyi bir adımdır.
Metin ön işleme
Ardından, yaklaşım sınıflandırma modeliniz için gereken veri kümesi ön işleme adımlarını tanımlayın. Film incelemelerini vektörleştirmek için istenen parametrelerle bir TextVectorization katmanı başlatın. Metin Sınıflandırma eğitiminde bu katmanı kullanma hakkında daha fazla bilgi edinebilirsiniz.
# Create a custom standardization function to strip HTML break tags '<br />'.
def custom_standardization(input_data):
lowercase = tf.strings.lower(input_data)
stripped_html = tf.strings.regex_replace(lowercase, '<br />', ' ')
return tf.strings.regex_replace(stripped_html,
'[%s]' % re.escape(string.punctuation), '')
# Vocabulary size and number of words in a sequence.
vocab_size = 10000
sequence_length = 100
# Use the text vectorization layer to normalize, split, and map strings to
# integers. Note that the layer uses the custom standardization defined above.
# Set maximum_sequence length as all samples are not of the same length.
vectorize_layer = TextVectorization(
standardize=custom_standardization,
max_tokens=vocab_size,
output_mode='int',
output_sequence_length=sequence_length)
# Make a text-only dataset (no labels) and call adapt to build the vocabulary.
text_ds = train_ds.map(lambda x, y: x)
vectorize_layer.adapt(text_ds)
Bir sınıflandırma modeli oluşturun
Duygu sınıflandırma modelini tanımlamak için Keras Sıralı API'sini kullanın. Bu durumda "Sürekli kelime çantası" tarzı bir modeldir.
-
TextVectorizationkatmanı, dizeleri kelime dizinlerine dönüştürür. Vectorize_layer'ı birvectorize_layerkatmanı olarak zaten başlattınız veadaptontext_dsçağırarak onun kelime dağarcığını oluşturdunuz. Şimdi vectorize_layer, dönüştürülmüş dizeleri Gömme katmanına besleyerek uçtan uca sınıflandırma modelinizin ilk katmanı olarak kullanılabilir. Embeddingkatmanı, tamsayı olarak kodlanmış sözcükleri alır ve her sözcük dizini için gömme vektörünü arar. Bu vektörler model trenler olarak öğrenilir. Vektörler, çıktı dizisine bir boyut ekler. Ortaya çıkan boyutlar:(batch, sequence, embedding).GlobalAveragePooling1Dkatmanı, sıra boyutu üzerinden ortalama alarak her örnek için sabit uzunlukta bir çıktı vektörü döndürür. Bu, modelin değişken uzunluktaki girdileri mümkün olan en basit şekilde işlemesini sağlar.Sabit uzunluktaki çıktı vektörü, 16 gizli birim ile tam bağlantılı (
Dense) bir katmandan geçirilir.Son katman, tek bir çıkış düğümü ile yoğun bir şekilde bağlantılıdır.
embedding_dim=16
model = Sequential([
vectorize_layer,
Embedding(vocab_size, embedding_dim, name="embedding"),
GlobalAveragePooling1D(),
Dense(16, activation='relu'),
Dense(1)
])
Modeli derleyin ve eğitin
Kayıp ve doğruluk dahil olmak üzere ölçümleri görselleştirmek için TensorBoard'u kullanacaksınız. Bir tf.keras.callbacks.TensorBoard oluşturun.
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir="logs")
Adam optimizer ve BinaryCrossentropy kaybını kullanarak modeli derleyin ve eğitin.
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(
train_ds,
validation_data=val_ds,
epochs=15,
callbacks=[tensorboard_callback])
Epoch 1/15 20/20 [==============================] - 2s 71ms/step - loss: 0.6910 - accuracy: 0.5028 - val_loss: 0.6878 - val_accuracy: 0.4886 Epoch 2/15 20/20 [==============================] - 1s 57ms/step - loss: 0.6838 - accuracy: 0.5028 - val_loss: 0.6791 - val_accuracy: 0.4886 Epoch 3/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6726 - accuracy: 0.5028 - val_loss: 0.6661 - val_accuracy: 0.4886 Epoch 4/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6563 - accuracy: 0.5028 - val_loss: 0.6481 - val_accuracy: 0.4886 Epoch 5/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6343 - accuracy: 0.5061 - val_loss: 0.6251 - val_accuracy: 0.5066 Epoch 6/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6068 - accuracy: 0.5634 - val_loss: 0.5982 - val_accuracy: 0.5762 Epoch 7/15 20/20 [==============================] - 1s 58ms/step - loss: 0.5752 - accuracy: 0.6405 - val_loss: 0.5690 - val_accuracy: 0.6386 Epoch 8/15 20/20 [==============================] - 1s 58ms/step - loss: 0.5412 - accuracy: 0.7036 - val_loss: 0.5390 - val_accuracy: 0.6850 Epoch 9/15 20/20 [==============================] - 1s 59ms/step - loss: 0.5064 - accuracy: 0.7479 - val_loss: 0.5106 - val_accuracy: 0.7222 Epoch 10/15 20/20 [==============================] - 1s 59ms/step - loss: 0.4734 - accuracy: 0.7774 - val_loss: 0.4855 - val_accuracy: 0.7430 Epoch 11/15 20/20 [==============================] - 1s 59ms/step - loss: 0.4432 - accuracy: 0.7971 - val_loss: 0.4636 - val_accuracy: 0.7570 Epoch 12/15 20/20 [==============================] - 1s 58ms/step - loss: 0.4161 - accuracy: 0.8155 - val_loss: 0.4453 - val_accuracy: 0.7674 Epoch 13/15 20/20 [==============================] - 1s 59ms/step - loss: 0.3921 - accuracy: 0.8304 - val_loss: 0.4303 - val_accuracy: 0.7780 Epoch 14/15 20/20 [==============================] - 1s 61ms/step - loss: 0.3711 - accuracy: 0.8398 - val_loss: 0.4181 - val_accuracy: 0.7884 Epoch 15/15 20/20 [==============================] - 1s 58ms/step - loss: 0.3524 - accuracy: 0.8493 - val_loss: 0.4082 - val_accuracy: 0.7948 <keras.callbacks.History at 0x7fca579745d0>
Bu yaklaşımla model, yaklaşık %78'lik bir doğrulama doğruluğuna ulaşır (eğitim doğruluğu daha yüksek olduğu için modelin fazla uyumlu olduğunu unutmayın).
Modelin her katmanı hakkında daha fazla bilgi edinmek için model özetine bakabilirsiniz.
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
text_vectorization (TextVec (None, 100) 0
torization)
embedding (Embedding) (None, 100, 16) 160000
global_average_pooling1d (G (None, 16) 0
lobalAveragePooling1D)
dense (Dense) (None, 16) 272
dense_1 (Dense) (None, 1) 17
=================================================================
Total params: 160,289
Trainable params: 160,289
Non-trainable params: 0
_________________________________________________________________
Model ölçümlerini TensorBoard'da görselleştirin.
#docs_infra: no_execute
%load_ext tensorboard
%tensorboard --logdir logs
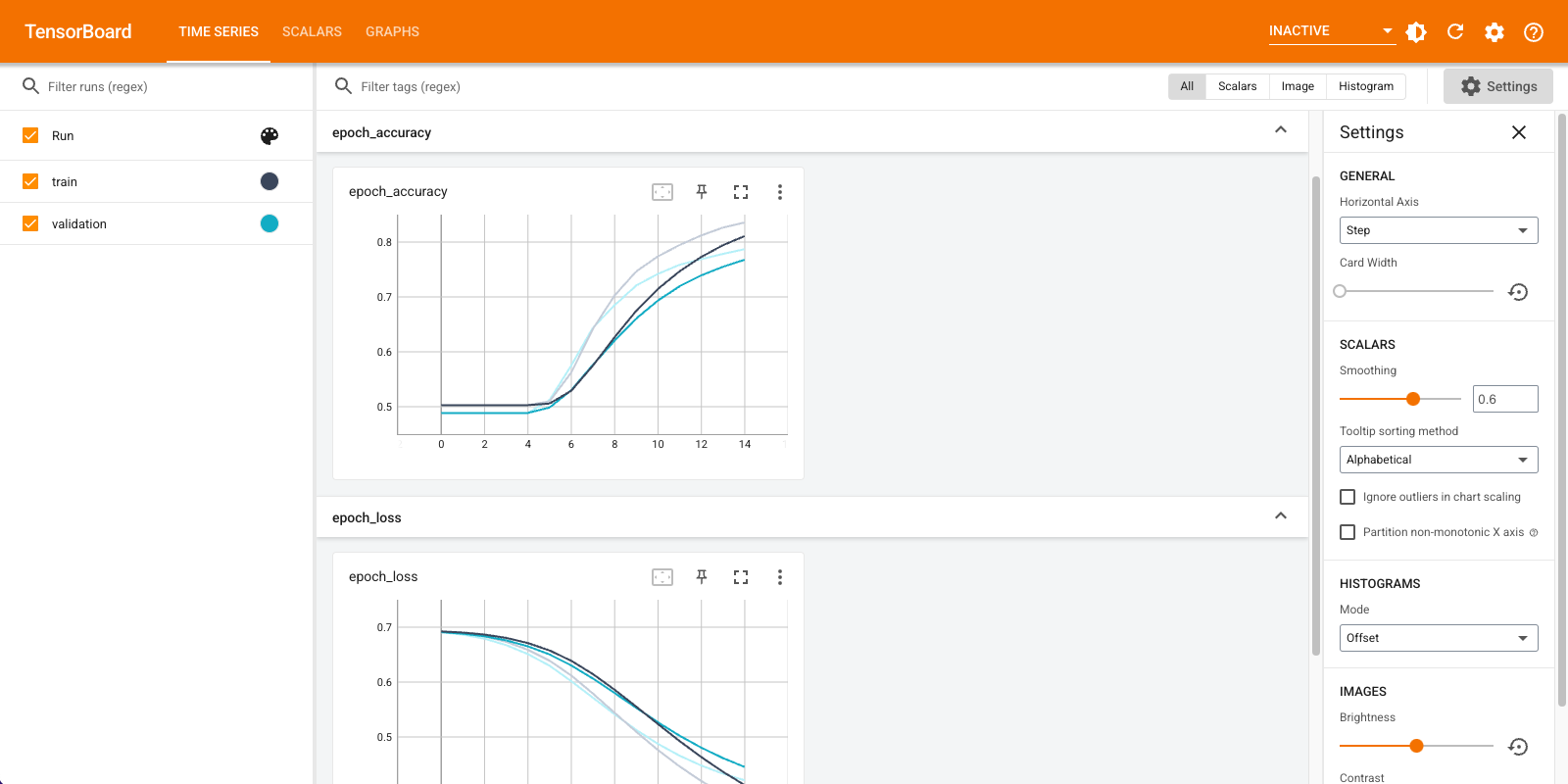
Eğitilmiş sözcük yerleştirmelerini alın ve diske kaydedin
Ardından, eğitim sırasında öğrenilen sözcük yerleştirmelerini alın. Gömmeler, modeldeki Gömme katmanının ağırlıklarıdır. Ağırlık matrisi şeklindedir (vocab_size, embedding_dimension) .
get_layer() ve get_weights() kullanarak modelden ağırlıkları alın. get_vocabulary() işlevi, her satırda bir belirteç içeren bir meta veri dosyası oluşturmak için sözcük dağarcığı sağlar.
weights = model.get_layer('embedding').get_weights()[0]
vocab = vectorize_layer.get_vocabulary()
Ağırlıkları diske yazın. Gömme Projektörünü kullanmak için sekmeyle ayrılmış biçimde iki dosya yükleyeceksiniz: bir vektör dosyası (gömmeyi içeren) ve bir meta veri dosyası (kelimeleri içeren).
out_v = io.open('vectors.tsv', 'w', encoding='utf-8')
out_m = io.open('metadata.tsv', 'w', encoding='utf-8')
for index, word in enumerate(vocab):
if index == 0:
continue # skip 0, it's padding.
vec = weights[index]
out_v.write('\t'.join([str(x) for x in vec]) + "\n")
out_m.write(word + "\n")
out_v.close()
out_m.close()
Bu öğreticiyi Colaboratory'de çalıştırıyorsanız, bu dosyaları yerel makinenize indirmek için aşağıdaki parçacığı kullanabilirsiniz (veya dosya tarayıcısını, Görünüm -> İçindekiler -> Dosya tarayıcısını kullanın).
try:
from google.colab import files
files.download('vectors.tsv')
files.download('metadata.tsv')
except Exception:
pass
Gömmeleri görselleştirin
Gömmeleri görselleştirmek için gömme projektörüne yükleyin.
Gömme Projektörünü açın (bu, yerel bir TensorBoard örneğinde de çalışabilir).
"Veri yükle" ye tıklayın.
Yukarıda oluşturduğunuz iki dosyayı yükleyin:
vecs.tsvvemeta.tsv.
Eğittiğiniz yerleştirmeler şimdi görüntülenecektir. En yakın komşularını bulmak için kelimeleri arayabilirsiniz. Örneğin, "güzel" kelimesini aramayı deneyin. "Harika" gibi komşular görebilirsiniz.
Sonraki adımlar
Bu öğretici, küçük bir veri kümesinde sıfırdan sözcük yerleştirmelerini nasıl eğiteceğinizi ve görselleştireceğinizi göstermiştir.
Word2Vec algoritmasını kullanarak sözcük yerleştirmelerini eğitmek için Word2Vec öğreticisini deneyin.
Gelişmiş metin işleme hakkında daha fazla bilgi edinmek için dili anlamak için Transformer modelini okuyun.