
| | |  Voir la source sur GitHub Voir la source sur GitHub | |
Ce didacticiel contient une introduction aux incorporations de mots. Vous entraînerez vos propres intégrations de mots à l'aide d'un modèle Keras simple pour une tâche de classification des sentiments, puis les visualiserez dans le projecteur d'intégration (illustré dans l'image ci-dessous).

Représentation du texte sous forme de nombres
Les modèles d'apprentissage automatique prennent des vecteurs (tableaux de nombres) en entrée. Lorsque vous travaillez avec du texte, la première chose que vous devez faire est de trouver une stratégie pour convertir les chaînes en nombres (ou pour "vectoriser" le texte) avant de l'introduire dans le modèle. Dans cette section, vous examinerez trois stratégies pour y parvenir.
Encodages à chaud
Comme première idée, vous pourriez encoder "one-hot" chaque mot de votre vocabulaire. Considérez la phrase "Le chat s'est assis sur le tapis". Le vocabulaire (ou mots uniques) dans cette phrase est (chat, tapis, sur, assis, le). Pour représenter chaque mot, vous allez créer un vecteur nul de longueur égale au vocabulaire, puis en placer un dans l'index qui correspond au mot. Cette approche est illustrée dans le schéma suivant.
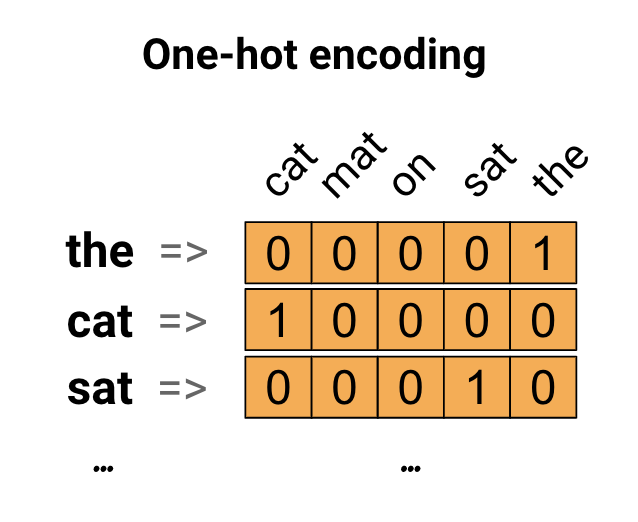
Pour créer un vecteur contenant l'encodage de la phrase, vous pouvez ensuite concaténer les vecteurs one-hot pour chaque mot.
Encoder chaque mot avec un numéro unique
Une deuxième approche que vous pourriez essayer consiste à encoder chaque mot à l'aide d'un numéro unique. En continuant l'exemple ci-dessus, vous pouvez attribuer 1 à "cat", 2 à "mat", etc. Vous pourriez alors encoder la phrase "Le chat s'est assis sur le tapis" sous la forme d'un vecteur dense comme [5, 1, 4, 3, 5, 2]. Cette approche est efficace. Au lieu d'un vecteur clairsemé, vous en avez maintenant un dense (où tous les éléments sont pleins).
Il y a cependant deux inconvénients à cette approche :
Le codage entier est arbitraire (il ne capture aucune relation entre les mots).
Un codage entier peut être difficile à interpréter pour un modèle. Un classificateur linéaire, par exemple, apprend un seul poids pour chaque caractéristique. Puisqu'il n'y a pas de relation entre la similarité de deux mots et la similarité de leurs codages, cette combinaison caractéristique-pondération n'est pas significative.
Incorporations de mots
Les incorporations de mots nous permettent d'utiliser une représentation efficace et dense dans laquelle des mots similaires ont un encodage similaire. Il est important de noter que vous n'avez pas à spécifier cet encodage à la main. Une incorporation est un vecteur dense de valeurs à virgule flottante (la longueur du vecteur est un paramètre que vous spécifiez). Au lieu de spécifier manuellement les valeurs pour l'intégration, ce sont des paramètres entraînables (poids appris par le modèle lors de l'entraînement, de la même manière qu'un modèle apprend des poids pour une couche dense). Il est courant de voir des incorporations de mots à 8 dimensions (pour les petits ensembles de données), jusqu'à 1024 dimensions lorsque vous travaillez avec de grands ensembles de données. Une intégration dimensionnelle plus élevée peut capturer des relations fines entre les mots, mais nécessite plus de données pour apprendre.
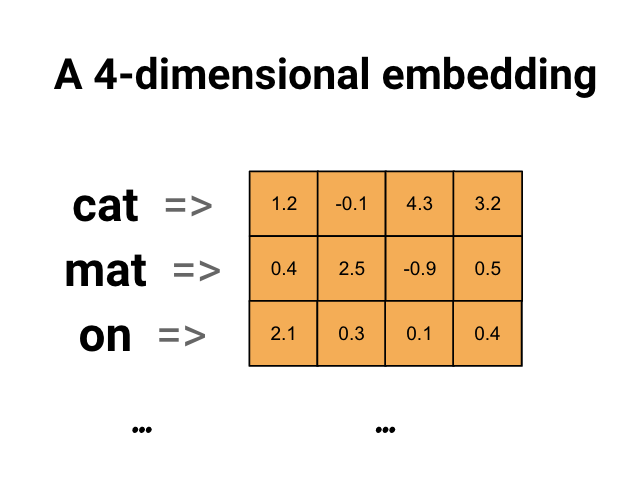
Ci-dessus, un diagramme pour un mot incorporé. Chaque mot est représenté comme un vecteur à 4 dimensions de valeurs à virgule flottante. Une autre façon de penser à une incorporation est comme une "table de recherche". Une fois ces poids appris, vous pouvez coder chaque mot en recherchant le vecteur dense auquel il correspond dans le tableau.
Installer
import io
import os
import re
import shutil
import string
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Embedding, GlobalAveragePooling1D
from tensorflow.keras.layers import TextVectorization
Télécharger l'ensemble de données IMDb
Vous utiliserez l' ensemble de données Large Movie Review tout au long du didacticiel. Vous entraînerez un modèle de classificateur de sentiments sur cet ensemble de données et, ce faisant, apprendrez les intégrations à partir de zéro. Pour en savoir plus sur le chargement d'un ensemble de données à partir de rien, consultez le didacticiel Chargement de texte .
Téléchargez l'ensemble de données à l'aide de l'utilitaire de fichiers Keras et examinez les répertoires.
url = "https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
dataset = tf.keras.utils.get_file("aclImdb_v1.tar.gz", url,
untar=True, cache_dir='.',
cache_subdir='')
dataset_dir = os.path.join(os.path.dirname(dataset), 'aclImdb')
os.listdir(dataset_dir)
Downloading data from https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz 84131840/84125825 [==============================] - 7s 0us/step 84140032/84125825 [==============================] - 7s 0us/step ['test', 'imdb.vocab', 'imdbEr.txt', 'train', 'README']
Jetez un oeil à l'annuaire train/ . Il contient des dossiers pos et neg avec des critiques de films étiquetées respectivement positives et négatives. Vous utiliserez les avis des dossiers pos et neg pour former un modèle de classification binaire.
train_dir = os.path.join(dataset_dir, 'train')
os.listdir(train_dir)
['urls_pos.txt', 'urls_unsup.txt', 'urls_neg.txt', 'pos', 'unsup', 'unsupBow.feat', 'neg', 'labeledBow.feat']
Le répertoire train contient également des dossiers supplémentaires qui doivent être supprimés avant de créer un jeu de données d'entraînement.
remove_dir = os.path.join(train_dir, 'unsup')
shutil.rmtree(remove_dir)
Ensuite, créez un tf.data.Dataset en utilisant tf.keras.utils.text_dataset_from_directory . Vous pouvez en savoir plus sur l'utilisation de cet utilitaire dans ce didacticiel de classification de texte .
Utilisez le répertoire train pour créer à la fois des ensembles de données de train et de validation avec une répartition de 20 % pour la validation.
batch_size = 1024
seed = 123
train_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train', batch_size=batch_size, validation_split=0.2,
subset='training', seed=seed)
val_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train', batch_size=batch_size, validation_split=0.2,
subset='validation', seed=seed)
Found 25000 files belonging to 2 classes. Using 20000 files for training. Found 25000 files belonging to 2 classes. Using 5000 files for validation.
Jetez un œil à quelques critiques de films et à leurs étiquettes (1: positive, 0: negative) à partir de l'ensemble de données de train.
for text_batch, label_batch in train_ds.take(1):
for i in range(5):
print(label_batch[i].numpy(), text_batch.numpy()[i])
0 b"Oh My God! Please, for the love of all that is holy, Do Not Watch This Movie! It it 82 minutes of my life I will never get back. Sure, I could have stopped watching half way through. But I thought it might get better. It Didn't. Anyone who actually enjoyed this movie is one seriously sick and twisted individual. No wonder us Australians/New Zealanders have a terrible reputation when it comes to making movies. Everything about this movie is horrible, from the acting to the editing. I don't even normally write reviews on here, but in this case I'll make an exception. I only wish someone had of warned me before I hired this catastrophe" 1 b'This movie is SOOOO funny!!! The acting is WONDERFUL, the Ramones are sexy, the jokes are subtle, and the plot is just what every high schooler dreams of doing to his/her school. I absolutely loved the soundtrack as well as the carefully placed cynicism. If you like monty python, You will love this film. This movie is a tad bit "grease"esk (without all the annoying songs). The songs that are sung are likable; you might even find yourself singing these songs once the movie is through. This musical ranks number two in musicals to me (second next to the blues brothers). But please, do not think of it as a musical per say; seeing as how the songs are so likable, it is hard to tell a carefully choreographed scene is taking place. I think of this movie as more of a comedy with undertones of romance. You will be reminded of what it was like to be a rebellious teenager; needless to say, you will be reminiscing of your old high school days after seeing this film. Highly recommended for both the family (since it is a very youthful but also for adults since there are many jokes that are funnier with age and experience.' 0 b"Alex D. Linz replaces Macaulay Culkin as the central figure in the third movie in the Home Alone empire. Four industrial spies acquire a missile guidance system computer chip and smuggle it through an airport inside a remote controlled toy car. Because of baggage confusion, grouchy Mrs. Hess (Marian Seldes) gets the car. She gives it to her neighbor, Alex (Linz), just before the spies turn up. The spies rent a house in order to burglarize each house in the neighborhood until they locate the car. Home alone with the chicken pox, Alex calls 911 each time he spots a theft in progress, but the spies always manage to elude the police while Alex is accused of making prank calls. The spies finally turn their attentions toward Alex, unaware that he has rigged devices to cleverly booby-trap his entire house. Home Alone 3 wasn't horrible, but probably shouldn't have been made, you can't just replace Macauley Culkin, Joe Pesci, or Daniel Stern. Home Alone 3 had some funny parts, but I don't like when characters are changed in a movie series, view at own risk." 0 b"There's a good movie lurking here, but this isn't it. The basic idea is good: to explore the moral issues that would face a group of young survivors of the apocalypse. But the logic is so muddled that it's impossible to get involved.<br /><br />For example, our four heroes are (understandably) paranoid about catching the mysterious airborne contagion that's wiped out virtually all of mankind. Yet they wear surgical masks some times, not others. Some times they're fanatical about wiping down with bleach any area touched by an infected person. Other times, they seem completely unconcerned.<br /><br />Worse, after apparently surviving some weeks or months in this new kill-or-be-killed world, these people constantly behave like total newbs. They don't bother accumulating proper equipment, or food. They're forever running out of fuel in the middle of nowhere. They don't take elementary precautions when meeting strangers. And after wading through the rotting corpses of the entire human race, they're as squeamish as sheltered debutantes. You have to constantly wonder how they could have survived this long... and even if they did, why anyone would want to make a movie about them.<br /><br />So when these dweebs stop to agonize over the moral dimensions of their actions, it's impossible to take their soul-searching seriously. Their actions would first have to make some kind of minimal sense.<br /><br />On top of all this, we must contend with the dubious acting abilities of Chris Pine. His portrayal of an arrogant young James T Kirk might have seemed shrewd, when viewed in isolation. But in Carriers he plays on exactly that same note: arrogant and boneheaded. It's impossible not to suspect that this constitutes his entire dramatic range.<br /><br />On the positive side, the film *looks* excellent. It's got an over-sharp, saturated look that really suits the southwestern US locale. But that can't save the truly feeble writing nor the paper-thin (and annoying) characters. Even if you're a fan of the end-of-the-world genre, you should save yourself the agony of watching Carriers." 0 b'I saw this movie at an actual movie theater (probably the \\(2.00 one) with my cousin and uncle. We were around 11 and 12, I guess, and really into scary movies. I remember being so excited to see it because my cool uncle let us pick the movie (and we probably never got to do that again!) and sooo disappointed afterwards!! Just boring and not scary. The only redeeming thing I can remember was Corky Pigeon from Silver Spoons, and that wasn\'t all that great, just someone I recognized. I\'ve seen bad movies before and this one has always stuck out in my mind as the worst. This was from what I can recall, one of the most boring, non-scary, waste of our collective \\)6, and a waste of film. I have read some of the reviews that say it is worth a watch and I say, "Too each his own", but I wouldn\'t even bother. Not even so bad it\'s good.'
Configurer l'ensemble de données pour les performances
Ce sont deux méthodes importantes que vous devez utiliser lors du chargement des données pour vous assurer que les E/S ne deviennent pas bloquantes.
.cache() conserve les données en mémoire après leur chargement sur le disque. Cela garantira que l'ensemble de données ne devienne pas un goulot d'étranglement lors de la formation de votre modèle. Si votre jeu de données est trop volumineux pour tenir en mémoire, vous pouvez également utiliser cette méthode pour créer un cache sur disque performant, plus efficace à lire que de nombreux petits fichiers.
.prefetch() chevauche le prétraitement des données et l'exécution du modèle pendant la formation.
Vous pouvez en savoir plus sur les deux méthodes, ainsi que sur la mise en cache des données sur le disque dans le guide des performances des données .
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
Utilisation de la couche Incorporation
Keras facilite l'utilisation des incorporations de mots. Jetez un œil à la couche Embedding .
La couche Embedding peut être comprise comme une table de correspondance qui mappe des indices entiers (qui représentent des mots spécifiques) à des vecteurs denses (leurs incorporations). La dimensionnalité (ou largeur) de l'incorporation est un paramètre que vous pouvez expérimenter pour voir ce qui fonctionne bien pour votre problème, de la même manière que vous expérimenteriez avec le nombre de neurones dans une couche Dense.
# Embed a 1,000 word vocabulary into 5 dimensions.
embedding_layer = tf.keras.layers.Embedding(1000, 5)
Lorsque vous créez un calque d'intégration, les poids de l'intégration sont initialisés de manière aléatoire (comme n'importe quel autre calque). Au cours de la formation, ils sont progressivement ajustés par rétropropagation. Une fois formés, les incorporations de mots apprises encoderont approximativement les similitudes entre les mots (comme ils ont été appris pour le problème spécifique sur lequel votre modèle est formé).
Si vous transmettez un entier à une couche d'intégration, le résultat remplace chaque entier par le vecteur de la table d'intégration :
result = embedding_layer(tf.constant([1, 2, 3]))
result.numpy()
array([[ 0.01318491, -0.02219239, 0.024673 , -0.03208025, 0.02297195],
[-0.00726584, 0.03731754, -0.01209557, -0.03887399, -0.02407478],
[ 0.04477594, 0.04504738, -0.02220147, -0.03642888, -0.04688282]],
dtype=float32)
Pour les problèmes de texte ou de séquence, la couche Embedding prend un tenseur 2D d'entiers, de forme (samples, sequence_length) , où chaque entrée est une séquence d'entiers. Il peut embarquer des séquences de longueurs variables. Vous pouvez alimenter la couche d'intégration au-dessus des lots avec des formes (32, 10) (lot de 32 séquences de longueur 10) ou (64, 15) (lot de 64 séquences de longueur 15).
Le tenseur renvoyé a un axe de plus que l'entrée, les vecteurs d'intégration sont alignés le long du nouveau dernier axe. Passez-lui un lot d'entrée (2, 3) et la sortie est (2, 3, N)
result = embedding_layer(tf.constant([[0, 1, 2], [3, 4, 5]]))
result.shape
TensorShape([2, 3, 5])
Lorsqu'on lui donne un lot de séquences en entrée, une couche d'intégration renvoie un tenseur à virgule flottante 3D, de forme (samples, sequence_length, embedding_dimensionality) . Pour convertir cette séquence de longueur variable en une représentation fixe, il existe une variété d'approches standard. Vous pouvez utiliser une couche RNN, Attention ou de regroupement avant de la transmettre à une couche Dense. Ce tutoriel utilise le pooling car c'est le plus simple. Le didacticiel Classification de texte avec un RNN est une bonne étape suivante.
Prétraitement du texte
Ensuite, définissez les étapes de prétraitement de l'ensemble de données requises pour votre modèle de classification des sentiments. Initialisez une couche TextVectorization avec les paramètres souhaités pour vectoriser les critiques de films. Vous pouvez en savoir plus sur l'utilisation de cette couche dans le didacticiel Classification de texte .
# Create a custom standardization function to strip HTML break tags '<br />'.
def custom_standardization(input_data):
lowercase = tf.strings.lower(input_data)
stripped_html = tf.strings.regex_replace(lowercase, '<br />', ' ')
return tf.strings.regex_replace(stripped_html,
'[%s]' % re.escape(string.punctuation), '')
# Vocabulary size and number of words in a sequence.
vocab_size = 10000
sequence_length = 100
# Use the text vectorization layer to normalize, split, and map strings to
# integers. Note that the layer uses the custom standardization defined above.
# Set maximum_sequence length as all samples are not of the same length.
vectorize_layer = TextVectorization(
standardize=custom_standardization,
max_tokens=vocab_size,
output_mode='int',
output_sequence_length=sequence_length)
# Make a text-only dataset (no labels) and call adapt to build the vocabulary.
text_ds = train_ds.map(lambda x, y: x)
vectorize_layer.adapt(text_ds)
Créer un modèle de classement
Utilisez l' API Keras Sequential pour définir le modèle de classification des sentiments. Dans ce cas, il s'agit d'un modèle de style "sac continu de mots".
- La couche
TextVectorizationtransforme les chaînes en indices de vocabulaire. Vous avez déjà initialisévectorize_layeren tant que couche TextVectorization et construit son vocabulaire en appelantadaptontext_ds. Vectorize_layer peut désormais être utilisé comme première couche de votre modèle de classification de bout en bout, en alimentant les chaînes transformées dans la couche Embedding. La couche
Embeddingprend le vocabulaire codé en nombres entiers et recherche le vecteur d'incorporation pour chaque mot-index. Ces vecteurs sont appris au fur et à mesure que le modèle s'entraîne. Les vecteurs ajoutent une dimension au tableau de sortie. Les dimensions résultantes sont :(batch, sequence, embedding).La couche
GlobalAveragePooling1Drenvoie un vecteur de sortie de longueur fixe pour chaque exemple en faisant la moyenne sur la dimension de la séquence. Cela permet au modèle de gérer des entrées de longueur variable, de la manière la plus simple possible.Le vecteur de sortie de longueur fixe est acheminé via une couche entièrement connectée (
Dense) avec 16 unités cachées.La dernière couche est densément connectée à un seul nœud de sortie.
embedding_dim=16
model = Sequential([
vectorize_layer,
Embedding(vocab_size, embedding_dim, name="embedding"),
GlobalAveragePooling1D(),
Dense(16, activation='relu'),
Dense(1)
])
Compiler et entraîner le modèle
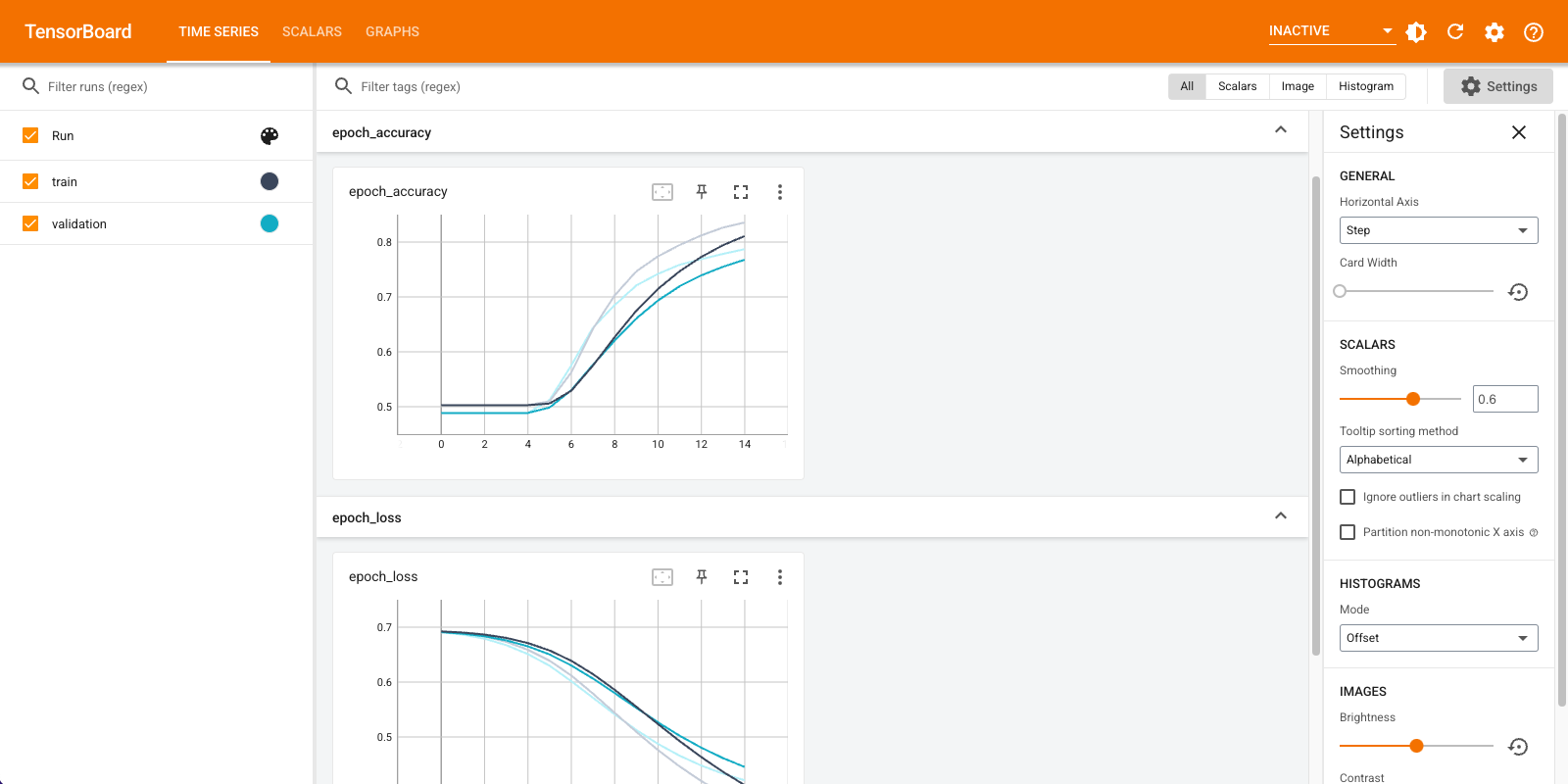
Vous utiliserez TensorBoard pour visualiser les métriques, y compris la perte et la précision. Créez un tf.keras.callbacks.TensorBoard .
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir="logs")
Compilez et entraînez le modèle à l'aide de l'optimiseur Adam et de la perte BinaryCrossentropy .
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(
train_ds,
validation_data=val_ds,
epochs=15,
callbacks=[tensorboard_callback])
Epoch 1/15 20/20 [==============================] - 2s 71ms/step - loss: 0.6910 - accuracy: 0.5028 - val_loss: 0.6878 - val_accuracy: 0.4886 Epoch 2/15 20/20 [==============================] - 1s 57ms/step - loss: 0.6838 - accuracy: 0.5028 - val_loss: 0.6791 - val_accuracy: 0.4886 Epoch 3/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6726 - accuracy: 0.5028 - val_loss: 0.6661 - val_accuracy: 0.4886 Epoch 4/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6563 - accuracy: 0.5028 - val_loss: 0.6481 - val_accuracy: 0.4886 Epoch 5/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6343 - accuracy: 0.5061 - val_loss: 0.6251 - val_accuracy: 0.5066 Epoch 6/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6068 - accuracy: 0.5634 - val_loss: 0.5982 - val_accuracy: 0.5762 Epoch 7/15 20/20 [==============================] - 1s 58ms/step - loss: 0.5752 - accuracy: 0.6405 - val_loss: 0.5690 - val_accuracy: 0.6386 Epoch 8/15 20/20 [==============================] - 1s 58ms/step - loss: 0.5412 - accuracy: 0.7036 - val_loss: 0.5390 - val_accuracy: 0.6850 Epoch 9/15 20/20 [==============================] - 1s 59ms/step - loss: 0.5064 - accuracy: 0.7479 - val_loss: 0.5106 - val_accuracy: 0.7222 Epoch 10/15 20/20 [==============================] - 1s 59ms/step - loss: 0.4734 - accuracy: 0.7774 - val_loss: 0.4855 - val_accuracy: 0.7430 Epoch 11/15 20/20 [==============================] - 1s 59ms/step - loss: 0.4432 - accuracy: 0.7971 - val_loss: 0.4636 - val_accuracy: 0.7570 Epoch 12/15 20/20 [==============================] - 1s 58ms/step - loss: 0.4161 - accuracy: 0.8155 - val_loss: 0.4453 - val_accuracy: 0.7674 Epoch 13/15 20/20 [==============================] - 1s 59ms/step - loss: 0.3921 - accuracy: 0.8304 - val_loss: 0.4303 - val_accuracy: 0.7780 Epoch 14/15 20/20 [==============================] - 1s 61ms/step - loss: 0.3711 - accuracy: 0.8398 - val_loss: 0.4181 - val_accuracy: 0.7884 Epoch 15/15 20/20 [==============================] - 1s 58ms/step - loss: 0.3524 - accuracy: 0.8493 - val_loss: 0.4082 - val_accuracy: 0.7948 <keras.callbacks.History at 0x7fca579745d0>
Avec cette approche, le modèle atteint une précision de validation d'environ 78 % (notez que le modèle est surajusté puisque la précision de la formation est plus élevée).
Vous pouvez consulter le résumé du modèle pour en savoir plus sur chaque couche du modèle.
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
text_vectorization (TextVec (None, 100) 0
torization)
embedding (Embedding) (None, 100, 16) 160000
global_average_pooling1d (G (None, 16) 0
lobalAveragePooling1D)
dense (Dense) (None, 16) 272
dense_1 (Dense) (None, 1) 17
=================================================================
Total params: 160,289
Trainable params: 160,289
Non-trainable params: 0
_________________________________________________________________
Visualisez les métriques du modèle dans TensorBoard.
#docs_infra: no_execute
%load_ext tensorboard
%tensorboard --logdir logs
Récupérer les incorporations de mots formés et les enregistrer sur le disque
Ensuite, récupérez les incorporations de mots apprises pendant la formation. Les embeddings sont les poids de la couche Embedding dans le modèle. La matrice des poids est de forme (vocab_size, embedding_dimension) .
Obtenez les poids du modèle en utilisant get_layer() et get_weights() . La fonction get_vocabulary() fournit le vocabulaire pour construire un fichier de métadonnées avec un jeton par ligne.
weights = model.get_layer('embedding').get_weights()[0]
vocab = vectorize_layer.get_vocabulary()
Écrivez les poids sur le disque. Pour utiliser le projecteur d'intégration , vous allez télécharger deux fichiers au format séparé par des tabulations : un fichier de vecteurs (contenant l'intégration) et un fichier de métadonnées (contenant les mots).
out_v = io.open('vectors.tsv', 'w', encoding='utf-8')
out_m = io.open('metadata.tsv', 'w', encoding='utf-8')
for index, word in enumerate(vocab):
if index == 0:
continue # skip 0, it's padding.
vec = weights[index]
out_v.write('\t'.join([str(x) for x in vec]) + "\n")
out_m.write(word + "\n")
out_v.close()
out_m.close()
Si vous exécutez ce didacticiel dans Colaboratory , vous pouvez utiliser l'extrait de code suivant pour télécharger ces fichiers sur votre ordinateur local (ou utiliser le navigateur de fichiers, Affichage -> Table des matières -> Navigateur de fichiers ).
try:
from google.colab import files
files.download('vectors.tsv')
files.download('metadata.tsv')
except Exception:
pass
Visualisez les encastrements
Pour visualiser les intégrations, téléchargez-les sur le projecteur d'intégration.
Ouvrez le projecteur d'intégration (cela peut également s'exécuter dans une instance locale de TensorBoard).
Cliquez sur "Charger les données".
Téléchargez les deux fichiers que vous avez créés ci-dessus :
vecs.tsvetmeta.tsv.
Les représentations incorporées que vous avez formées seront maintenant affichées. Vous pouvez rechercher des mots pour trouver leurs voisins les plus proches. Par exemple, essayez de rechercher "magnifique". Vous pouvez voir des voisins comme "merveilleux".
Prochaines étapes
Ce didacticiel vous a montré comment former et visualiser des incorporations de mots à partir de zéro sur un petit ensemble de données.
Pour entraîner les incorporations de mots à l'aide de l'algorithme Word2Vec, essayez le didacticiel Word2Vec .
Pour en savoir plus sur le traitement de texte avancé, lisez le modèle Transformer pour la compréhension du langage .