Ferramentas de processamento de texto para TensorFlow
O TensorFlow fornece duas bibliotecas para processamento de texto e linguagem natural: KerasNLP e TensorFlow Text. KerasNLP é uma biblioteca de processamento de linguagem natural (NLP) de alto nível que inclui modelos modernos baseados em transformadores, bem como utilitários de tokenização de nível inferior. É a solução recomendada para a maioria dos casos de uso de PNL. Construído no TensorFlow Text, o KerasNLP abstrai as operações de processamento de texto de baixo nível em uma API projetada para facilitar o uso. Mas se você preferir não trabalhar com a API Keras ou precisar de acesso às operações de processamento de texto de nível inferior, poderá usar o TensorFlow Text diretamente.
KerasNLP
import keras_nlp import tensorflow_datasets as tfds imdb_train, imdb_test = tfds.load( "imdb_reviews", split=["train", "test"], as_supervised=True, batch_size=16, ) # Load a BERT model. classifier = keras_nlp.models.BertClassifier.from_preset("bert_base_en_uncased") # Fine-tune on IMDb movie reviews. classifier.fit(imdb_train, validation_data=imdb_test) # Predict two new examples. classifier.predict(["What an amazing movie!", "A total waste of my time."])
A maneira mais fácil de começar a processar texto no TensorFlow é usar o KerasNLP. KerasNLP é uma biblioteca de processamento de linguagem natural que oferece suporte a fluxos de trabalho criados a partir de componentes modulares com pesos e arquiteturas predefinidos de última geração. Você pode usar os componentes do KerasNLP com sua configuração pronta para uso. Se precisar de mais controle, você pode personalizar facilmente os componentes. O KerasNLP enfatiza a computação em gráficos para todos os fluxos de trabalho, para que você possa esperar uma fácil produção usando o ecossistema TensorFlow.
O KerasNLP é uma extensão da API central do Keras, e todos os módulos KerasNLP de alto nível são Camadas ou Modelos. Se você está familiarizado com o Keras, já entende a maior parte do KerasNLP.
Para saber mais, consulte KerasNLP .
Texto do TensorFlow
import tensorflow as tf import tensorflow_text as tf_text def preprocess(vocab_lookup_table, example_text): # Normalize text tf_text.normalize_utf8(example_text) # Tokenize into words word_tokenizer = tf_text.WhitespaceTokenizer() tokens = word_tokenizer.tokenize(example_text) # Tokenize into subwords subword_tokenizer = tf_text.WordpieceTokenizer( vocab_lookup_table, token_out_type=tf.int64) subtokens = subword_tokenizer.tokenize(tokens).merge_dims(1, -1) # Apply padding padded_inputs = tf_text.pad_model_inputs(subtokens, max_seq_length=16) return padded_inputs
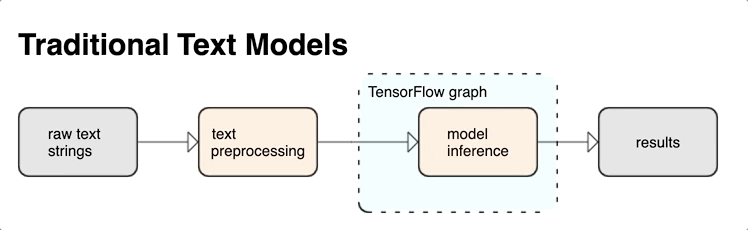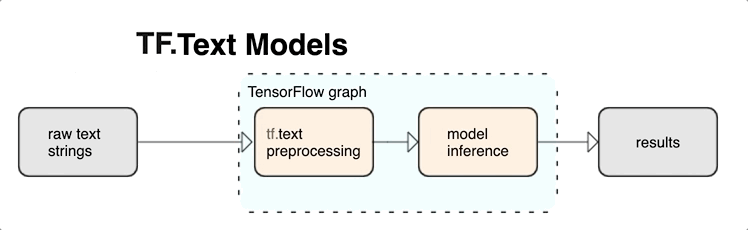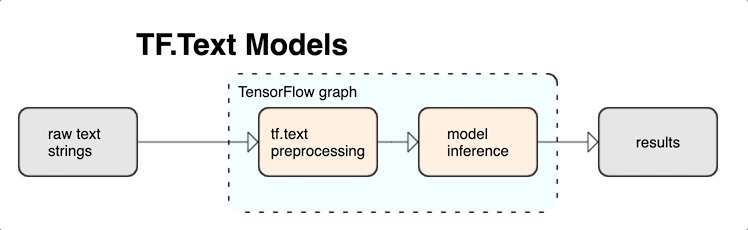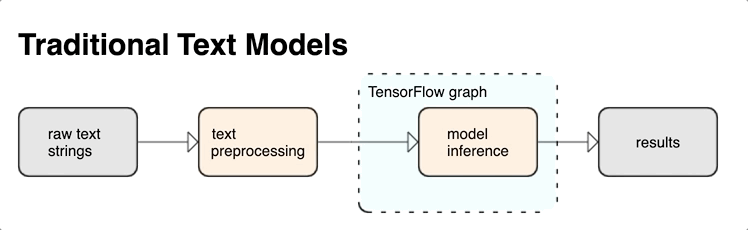
KerasNLP fornece módulos de processamento de texto de alto nível que estão disponíveis como camadas ou modelos. Se precisar de acesso a ferramentas de nível inferior, você pode usar o TensorFlow Text. O TensorFlow Text fornece uma rica coleção de operações e bibliotecas para ajudá-lo a trabalhar com entrada em formato de texto, como strings de texto bruto ou documentos. Essas bibliotecas podem executar o pré-processamento regularmente exigido por modelos baseados em texto e incluir outros recursos úteis para modelagem de sequência.
Você pode extrair poderosos recursos de texto sintático e semântico de dentro do gráfico do TensorFlow como entrada para sua rede neural.
A integração do pré-processamento com o gráfico do TensorFlow oferece os seguintes benefícios:
- Facilita um grande kit de ferramentas para trabalhar com texto
- Permite a integração com um grande conjunto de ferramentas do TensorFlow para dar suporte a projetos desde a definição do problema até o treinamento, avaliação e lançamento
- Reduz a complexidade no tempo de veiculação e evita desvios entre treinamento e veiculação
Além do que foi dito acima, você não precisa se preocupar com a tokenização no treinamento ser diferente da tokenização na inferência ou no gerenciamento de scripts de pré-processamento.