เครื่องมือประมวลผลข้อความสำหรับ TensorFlow
TensorFlow มีไลบรารีสองไลบรารีสำหรับการประมวลผลข้อความและภาษาธรรมชาติ ได้แก่ KerasNLP และ TensorFlow Text KerasNLP เป็นไลบรารีการประมวลผลภาษาธรรมชาติระดับสูง (NLP) ที่มีโมเดลที่ใช้หม้อแปลงไฟฟ้าที่ทันสมัย รวมถึงยูทิลิตีโทเค็นระดับล่าง เป็นวิธีแก้ปัญหาที่แนะนำสำหรับกรณีการใช้งาน NLP ส่วนใหญ่ KerasNLP สร้างขึ้นบน TensorFlow Text โดยแยกการดำเนินการประมวลผลข้อความระดับต่ำออกเป็น API ที่ออกแบบมาให้ใช้งานง่าย แต่ถ้าคุณไม่ต้องการทำงานกับ Keras API หรือต้องการเข้าถึง ops การประมวลผลข้อความระดับล่าง คุณสามารถใช้ TensorFlow Text ได้โดยตรง
KerasNLP
import keras_nlp import tensorflow_datasets as tfds imdb_train, imdb_test = tfds.load( "imdb_reviews", split=["train", "test"], as_supervised=True, batch_size=16, ) # Load a BERT model. classifier = keras_nlp.models.BertClassifier.from_preset("bert_base_en_uncased") # Fine-tune on IMDb movie reviews. classifier.fit(imdb_train, validation_data=imdb_test) # Predict two new examples. classifier.predict(["What an amazing movie!", "A total waste of my time."])
วิธีที่ง่ายที่สุดในการเริ่มประมวลผลข้อความใน TensorFlow คือการใช้ KerasNLP KerasNLP เป็นไลบรารีการประมวลผลภาษาธรรมชาติที่รองรับเวิร์กโฟลว์ที่สร้างขึ้นจากส่วนประกอบโมดูลาร์ที่มีน้ำหนักและสถาปัตยกรรมที่ตั้งไว้ล่วงหน้าล้ำสมัย คุณสามารถใช้ส่วนประกอบ KerasNLP กับการกำหนดค่าแบบสำเร็จรูปได้ หากคุณต้องการการควบคุมที่มากขึ้น คุณสามารถปรับแต่งส่วนประกอบได้อย่างง่ายดาย KerasNLP เน้นการคำนวณในกราฟสำหรับเวิร์กโฟลว์ทั้งหมด คุณจึงคาดหวังการผลิตที่ง่ายดายโดยใช้ระบบนิเวศ TensorFlow
KerasNLP เป็นส่วนขยายของ Keras API หลัก และโมดูล KerasNLP ระดับสูงทั้งหมดเป็นเลเยอร์หรือโมเดล หากคุณคุ้นเคยกับ Keras แสดงว่าคุณเข้าใจ KerasNLP ส่วนใหญ่แล้ว
หากต้องการเรียนรู้เพิ่มเติม โปรดดูที่ KerasNLP
ข้อความ TensorFlow
import tensorflow as tf import tensorflow_text as tf_text def preprocess(vocab_lookup_table, example_text): # Normalize text tf_text.normalize_utf8(example_text) # Tokenize into words word_tokenizer = tf_text.WhitespaceTokenizer() tokens = word_tokenizer.tokenize(example_text) # Tokenize into subwords subword_tokenizer = tf_text.WordpieceTokenizer( vocab_lookup_table, token_out_type=tf.int64) subtokens = subword_tokenizer.tokenize(tokens).merge_dims(1, -1) # Apply padding padded_inputs = tf_text.pad_model_inputs(subtokens, max_seq_length=16) return padded_inputs
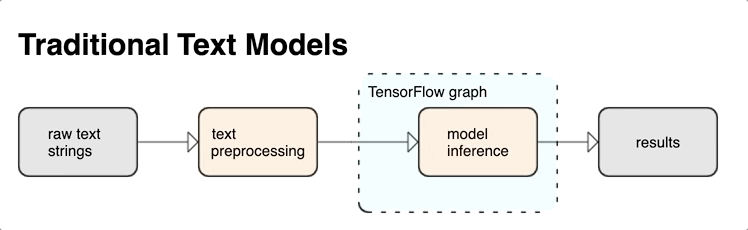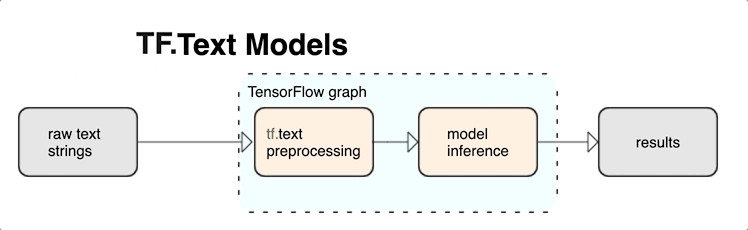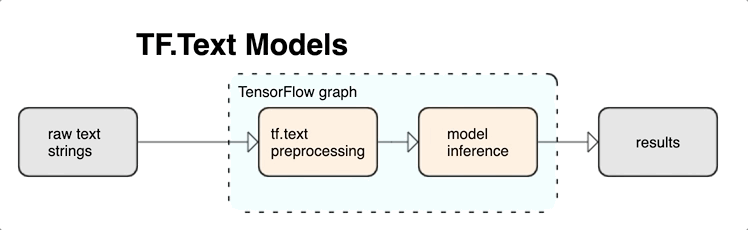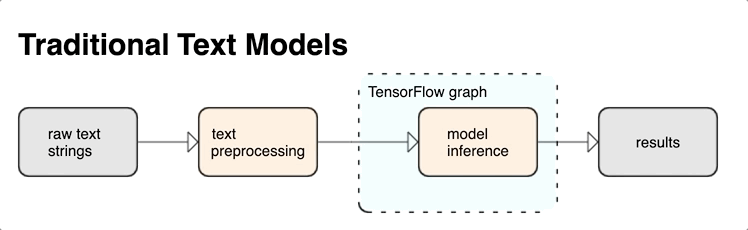
KerasNLP นำเสนอโมดูลการประมวลผลข้อความระดับสูงที่พร้อมใช้งานในรูปแบบเลเยอร์หรือโมเดล หากคุณต้องการเข้าถึงเครื่องมือระดับล่าง คุณสามารถใช้ TensorFlow Text ได้ TensorFlow Text มอบคอลเลคชัน ops และไลบรารีมากมายเพื่อช่วยให้คุณทำงานกับอินพุตในรูปแบบข้อความ เช่น สตริงข้อความดิบหรือเอกสาร ไลบรารีเหล่านี้สามารถทำการประมวลผลล่วงหน้าซึ่งจำเป็นสำหรับโมเดลแบบข้อความอย่างสม่ำเสมอ และรวมคุณสมบัติอื่นๆ ที่เป็นประโยชน์สำหรับการสร้างโมเดลแบบลำดับ
คุณสามารถแยกคุณสมบัติข้อความเชิงวากยสัมพันธ์และความหมายอันทรงพลังจากภายในกราฟ TensorFlow เป็นอินพุตไปยังนิวรอลเน็ตของคุณ
การรวมการประมวลผลล่วงหน้าเข้ากับกราฟ TensorFlow ให้ประโยชน์ดังต่อไปนี้:
- อำนวยความสะดวกชุดเครื่องมือขนาดใหญ่สำหรับการทำงานกับข้อความ
- อนุญาตให้ผสานรวมกับชุดเครื่องมือ TensorFlow ขนาดใหญ่เพื่อสนับสนุนโครงการตั้งแต่การกำหนดปัญหาไปจนถึงการฝึกอบรม การประเมินผล และการเปิดตัว
- ลดความซับซ้อนในเวลาเสิร์ฟและป้องกันการเสิร์ฟแบบเบ้
นอกเหนือจากข้างต้น คุณไม่จำเป็นต้องกังวลว่าโทเค็นในการฝึกอบรมจะแตกต่างจากโทเค็นที่อนุมาน หรือจัดการสคริปต์การประมวลผลล่วงหน้า