
| | |  Voir la source sur GitHub Voir la source sur GitHub |
Ce didacticiel fournit des exemples d'utilisation de données CSV avec TensorFlow.
Il y a deux parties principales à cela :
- Chargement des données hors disque
- Le pré-traiter sous une forme adaptée à la formation.
Ce didacticiel se concentre sur le chargement et donne quelques exemples rapides de prétraitement. Pour un didacticiel axé sur l'aspect de prétraitement, consultez le guide et le didacticiel de prétraitement des couches .
Installer
import pandas as pd
import numpy as np
# Make numpy values easier to read.
np.set_printoptions(precision=3, suppress=True)
import tensorflow as tf
from tensorflow.keras import layers
Données en mémoire
Pour tout petit ensemble de données CSV, le moyen le plus simple de former un modèle TensorFlow est de le charger en mémoire en tant que dataframe pandas ou tableau NumPy.
Un exemple relativement simple est le jeu de données sur les ormeaux .
- L'ensemble de données est petit.
- Toutes les entités en entrée sont toutes des valeurs à virgule flottante à plage limitée.
Voici comment télécharger les données dans un Pandas DataFrame :
abalone_train = pd.read_csv(
"https://storage.googleapis.com/download.tensorflow.org/data/abalone_train.csv",
names=["Length", "Diameter", "Height", "Whole weight", "Shucked weight",
"Viscera weight", "Shell weight", "Age"])
abalone_train.head()
L'ensemble de données contient un ensemble de mesures d' ormeaux , un type d'escargot de mer.

"Coquille d'ormeau" (par Nicki Dugan Pogue , CC BY-SA 2.0)
La tâche nominale pour cet ensemble de données est de prédire l'âge à partir des autres mesures, alors séparez les caractéristiques et les étiquettes pour la formation :
abalone_features = abalone_train.copy()
abalone_labels = abalone_features.pop('Age')
Pour cet ensemble de données, vous traiterez toutes les entités de manière identique. Regroupez les fonctionnalités dans un seul tableau NumPy :
abalone_features = np.array(abalone_features)
abalone_features
array([[0.435, 0.335, 0.11 , ..., 0.136, 0.077, 0.097],
[0.585, 0.45 , 0.125, ..., 0.354, 0.207, 0.225],
[0.655, 0.51 , 0.16 , ..., 0.396, 0.282, 0.37 ],
...,
[0.53 , 0.42 , 0.13 , ..., 0.374, 0.167, 0.249],
[0.395, 0.315, 0.105, ..., 0.118, 0.091, 0.119],
[0.45 , 0.355, 0.12 , ..., 0.115, 0.067, 0.16 ]])
Faites ensuite un modèle de régression pour prédire l'âge. Puisqu'il n'y a qu'un seul tenseur d'entrée, un modèle keras.Sequential est suffisant ici.
abalone_model = tf.keras.Sequential([
layers.Dense(64),
layers.Dense(1)
])
abalone_model.compile(loss = tf.losses.MeanSquaredError(),
optimizer = tf.optimizers.Adam())
Pour former ce modèle, transmettez les fonctionnalités et les étiquettes à Model.fit :
abalone_model.fit(abalone_features, abalone_labels, epochs=10)
Epoch 1/10 104/104 [==============================] - 1s 2ms/step - loss: 63.0446 Epoch 2/10 104/104 [==============================] - 0s 2ms/step - loss: 11.9429 Epoch 3/10 104/104 [==============================] - 0s 2ms/step - loss: 8.4836 Epoch 4/10 104/104 [==============================] - 0s 2ms/step - loss: 8.0052 Epoch 5/10 104/104 [==============================] - 0s 2ms/step - loss: 7.6073 Epoch 6/10 104/104 [==============================] - 0s 2ms/step - loss: 7.2485 Epoch 7/10 104/104 [==============================] - 0s 2ms/step - loss: 6.9883 Epoch 8/10 104/104 [==============================] - 0s 2ms/step - loss: 6.7977 Epoch 9/10 104/104 [==============================] - 0s 2ms/step - loss: 6.6477 Epoch 10/10 104/104 [==============================] - 0s 2ms/step - loss: 6.5359 <keras.callbacks.History at 0x7f70543c7350>
Vous venez de voir la manière la plus simple de former un modèle à l'aide de données CSV. Ensuite, vous apprendrez à appliquer le prétraitement pour normaliser les colonnes numériques.
Prétraitement de base
Il est recommandé de normaliser les entrées de votre modèle. Les couches de prétraitement Keras offrent un moyen pratique d'intégrer cette normalisation dans votre modèle.
La couche précalculera la moyenne et la variance de chaque colonne et les utilisera pour normaliser les données.
Commencez par créer le calque :
normalize = layers.Normalization()
Ensuite, vous utilisez la méthode Normalization.adapt() pour adapter la couche de normalisation à vos données.
normalize.adapt(abalone_features)
Utilisez ensuite la couche de normalisation dans votre modèle :
norm_abalone_model = tf.keras.Sequential([
normalize,
layers.Dense(64),
layers.Dense(1)
])
norm_abalone_model.compile(loss = tf.losses.MeanSquaredError(),
optimizer = tf.optimizers.Adam())
norm_abalone_model.fit(abalone_features, abalone_labels, epochs=10)
Epoch 1/10 104/104 [==============================] - 0s 2ms/step - loss: 92.5851 Epoch 2/10 104/104 [==============================] - 0s 2ms/step - loss: 55.1199 Epoch 3/10 104/104 [==============================] - 0s 2ms/step - loss: 18.2937 Epoch 4/10 104/104 [==============================] - 0s 2ms/step - loss: 6.2633 Epoch 5/10 104/104 [==============================] - 0s 2ms/step - loss: 5.1257 Epoch 6/10 104/104 [==============================] - 0s 2ms/step - loss: 5.0217 Epoch 7/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9775 Epoch 8/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9730 Epoch 9/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9348 Epoch 10/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9416 <keras.callbacks.History at 0x7f70541b2a50>
Types de données mixtes
L'ensemble de données "Titanic" contient des informations sur les passagers du Titanic. La tâche nominale sur cet ensemble de données est de prédire qui a survécu.

Image de Wikimédia
{kind=link}
Les données brutes peuvent facilement être chargées en tant que Pandas DataFrame , mais ne sont pas immédiatement utilisables comme entrée dans un modèle TensorFlow.
titanic = pd.read_csv("https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic.head()
titanic_features = titanic.copy()
titanic_labels = titanic_features.pop('survived')
En raison des différents types et plages de données, vous ne pouvez pas simplement empiler les fonctionnalités dans un tableau NumPy et le transmettre à un modèle keras.Sequential . Chaque colonne doit être traitée individuellement.
En tant qu'option, vous pouvez prétraiter vos données hors ligne (à l'aide de l'outil de votre choix) pour convertir les colonnes catégorielles en colonnes numériques, puis transmettre la sortie traitée à votre modèle TensorFlow. L'inconvénient de cette approche est que si vous enregistrez et exportez votre modèle, le prétraitement n'est pas enregistré avec celui-ci. Les couches de prétraitement Keras évitent ce problème car elles font partie du modèle.
Dans cet exemple, vous allez créer un modèle qui implémente la logique de prétraitement à l'aide de l'API fonctionnelle Keras . Vous pouvez également le faire en sous- classant .
L'API fonctionnelle opère sur des tenseurs "symboliques". Les tenseurs « impatients » normaux ont une valeur. En revanche, ces tenseurs "symboliques" ne le font pas. Au lieu de cela, ils gardent une trace des opérations qui sont exécutées sur eux et créent une représentation du calcul, que vous pouvez exécuter plus tard. Voici un exemple rapide :
# Create a symbolic input
input = tf.keras.Input(shape=(), dtype=tf.float32)
# Perform a calculation using the input
result = 2*input + 1
# the result doesn't have a value
result
<KerasTensor: shape=(None,) dtype=float32 (created by layer 'tf.__operators__.add')>
calc = tf.keras.Model(inputs=input, outputs=result)
print(calc(1).numpy())
print(calc(2).numpy())
3.0 5.0
Pour créer le modèle de prétraitement, commencez par créer un ensemble d'objets symboliques keras.Input , correspondant aux noms et aux types de données des colonnes CSV.
inputs = {}
for name, column in titanic_features.items():
dtype = column.dtype
if dtype == object:
dtype = tf.string
else:
dtype = tf.float32
inputs[name] = tf.keras.Input(shape=(1,), name=name, dtype=dtype)
inputs
{'sex': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'sex')>,
'age': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'age')>,
'n_siblings_spouses': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'n_siblings_spouses')>,
'parch': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'parch')>,
'fare': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'fare')>,
'class': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'class')>,
'deck': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'deck')>,
'embark_town': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'embark_town')>,
'alone': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'alone')>}
La première étape de votre logique de prétraitement consiste à concaténer les entrées numériques et à les faire passer par une couche de normalisation :
numeric_inputs = {name:input for name,input in inputs.items()
if input.dtype==tf.float32}
x = layers.Concatenate()(list(numeric_inputs.values()))
norm = layers.Normalization()
norm.adapt(np.array(titanic[numeric_inputs.keys()]))
all_numeric_inputs = norm(x)
all_numeric_inputs
<KerasTensor: shape=(None, 4) dtype=float32 (created by layer 'normalization_1')>
Collectez tous les résultats du prétraitement symbolique, pour les concaténer ultérieurement.
preprocessed_inputs = [all_numeric_inputs]
Pour les entrées de chaîne, utilisez la fonction tf.keras.layers.StringLookup pour mapper des chaînes à des indices entiers dans un vocabulaire. Ensuite, utilisez tf.keras.layers.CategoryEncoding pour convertir les index en données float32 appropriées pour le modèle.
Les paramètres par défaut de la couche tf.keras.layers.CategoryEncoding créent un vecteur unique pour chaque entrée. Un layers.Embedding fonctionnerait également. Consultez le guide et le didacticiel de prétraitement des couches pour en savoir plus sur ce sujet.
for name, input in inputs.items():
if input.dtype == tf.float32:
continue
lookup = layers.StringLookup(vocabulary=np.unique(titanic_features[name]))
one_hot = layers.CategoryEncoding(max_tokens=lookup.vocab_size())
x = lookup(input)
x = one_hot(x)
preprocessed_inputs.append(x)
WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead.
Avec la collection d' inputs et processed_inputs , vous pouvez concaténer toutes les entrées prétraitées et créer un modèle qui gère le prétraitement :
preprocessed_inputs_cat = layers.Concatenate()(preprocessed_inputs)
titanic_preprocessing = tf.keras.Model(inputs, preprocessed_inputs_cat)
tf.keras.utils.plot_model(model = titanic_preprocessing , rankdir="LR", dpi=72, show_shapes=True)
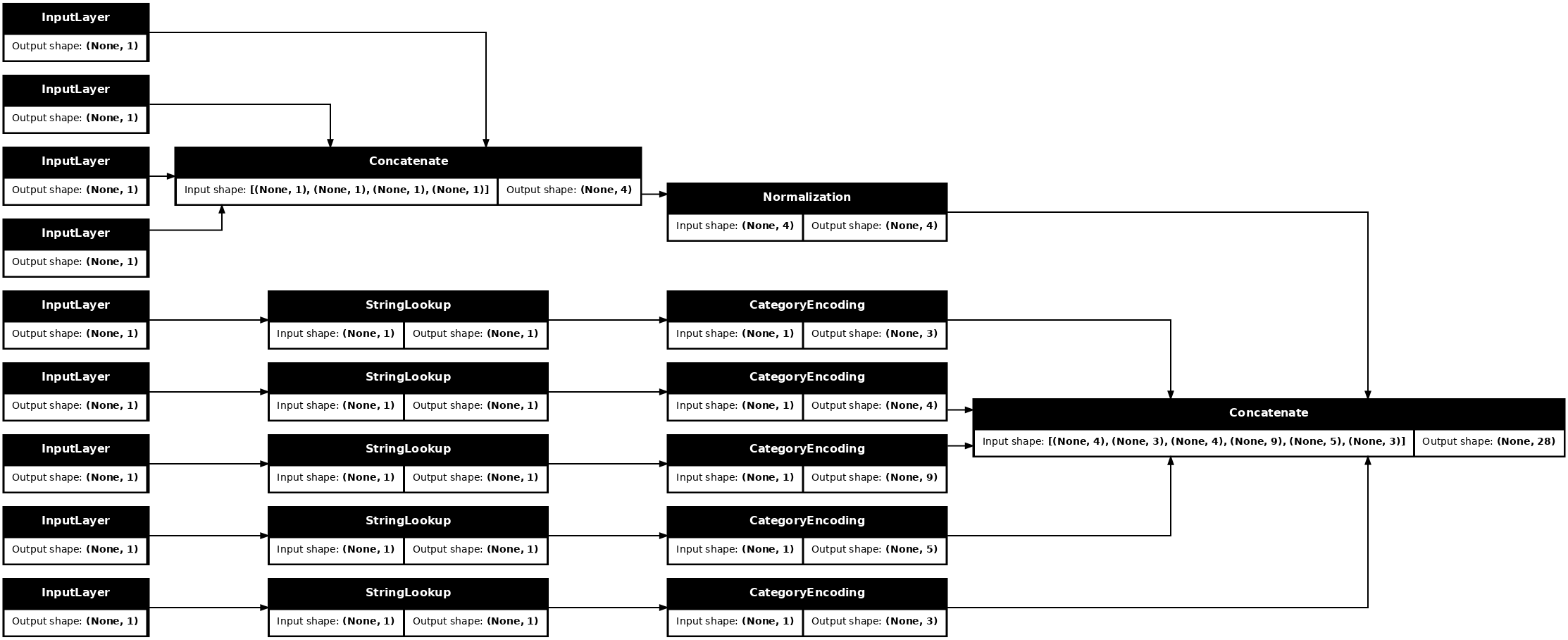
Ce model ne contient que le prétraitement des entrées. Vous pouvez l'exécuter pour voir ce qu'il fait à vos données. Les modèles Keras ne convertissent pas automatiquement les Pandas DataFrames car il n'est pas clair s'il doit être converti en un tenseur ou en un dictionnaire de tenseurs. Alors convertissez-le en un dictionnaire de tenseurs :
titanic_features_dict = {name: np.array(value)
for name, value in titanic_features.items()}
Découpez le premier exemple de formation et transmettez-le à ce modèle de prétraitement, vous voyez les caractéristiques numériques et la chaîne one-hots toutes concaténées :
features_dict = {name:values[:1] for name, values in titanic_features_dict.items()}
titanic_preprocessing(features_dict)
<tf.Tensor: shape=(1, 28), dtype=float32, numpy=
array([[-0.61 , 0.395, -0.479, -0.497, 0. , 0. , 1. , 0. ,
0. , 0. , 1. , 0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 1. , 0. , 0. , 0. , 1. ,
0. , 0. , 1. , 0. ]], dtype=float32)>
Construisez maintenant le modèle par-dessus ceci :
def titanic_model(preprocessing_head, inputs):
body = tf.keras.Sequential([
layers.Dense(64),
layers.Dense(1)
])
preprocessed_inputs = preprocessing_head(inputs)
result = body(preprocessed_inputs)
model = tf.keras.Model(inputs, result)
model.compile(loss=tf.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.optimizers.Adam())
return model
titanic_model = titanic_model(titanic_preprocessing, inputs)
Lorsque vous entraînez le modèle, transmettez le dictionnaire des fonctionnalités en tant que x et l'étiquette en tant que y .
titanic_model.fit(x=titanic_features_dict, y=titanic_labels, epochs=10)
Epoch 1/10 20/20 [==============================] - 1s 4ms/step - loss: 0.8017 Epoch 2/10 20/20 [==============================] - 0s 4ms/step - loss: 0.5913 Epoch 3/10 20/20 [==============================] - 0s 5ms/step - loss: 0.5212 Epoch 4/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4841 Epoch 5/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4615 Epoch 6/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4470 Epoch 7/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4367 Epoch 8/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4304 Epoch 9/10 20/20 [==============================] - 0s 4ms/step - loss: 0.4265 Epoch 10/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4239 <keras.callbacks.History at 0x7f70b1f82a50>
Étant donné que le prétraitement fait partie du modèle, vous pouvez enregistrer le modèle et le recharger ailleurs et obtenir des résultats identiques :
titanic_model.save('test')
reloaded = tf.keras.models.load_model('test')
2022-01-26 06:36:18.822459: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: test/assets
features_dict = {name:values[:1] for name, values in titanic_features_dict.items()}
before = titanic_model(features_dict)
after = reloaded(features_dict)
assert (before-after)<1e-3
print(before)
print(after)
tf.Tensor([[-1.791]], shape=(1, 1), dtype=float32) tf.Tensor([[-1.791]], shape=(1, 1), dtype=float32)
Utilisation de tf.data
Dans la section précédente, vous vous êtes appuyé sur le brassage et le traitement par lots des données intégrés du modèle lors de la formation du modèle.
Si vous avez besoin de plus de contrôle sur le pipeline de données d'entrée ou si vous avez besoin d'utiliser des données qui ne rentrent pas facilement dans la mémoire : utilisez tf.data .
Pour plus d'exemples, consultez le guide tf.data .
Activé dans les données de la mémoire
Comme premier exemple d'application de tf.data aux données CSV, considérez le code suivant pour découper manuellement le dictionnaire des fonctionnalités de la section précédente. Pour chaque index, il prend cet index pour chaque fonctionnalité :
import itertools
def slices(features):
for i in itertools.count():
# For each feature take index `i`
example = {name:values[i] for name, values in features.items()}
yield example
Exécutez ceci et imprimez le premier exemple :
for example in slices(titanic_features_dict):
for name, value in example.items():
print(f"{name:19s}: {value}")
break
sex : male age : 22.0 n_siblings_spouses : 1 parch : 0 fare : 7.25 class : Third deck : unknown embark_town : Southampton alone : n
Le chargeur de données tf.data.Dataset le plus basique dans la mémoire est le constructeur Dataset.from_tensor_slices . Cela renvoie un tf.data.Dataset qui implémente une version généralisée de la fonction slices ci-dessus, dans TensorFlow.
features_ds = tf.data.Dataset.from_tensor_slices(titanic_features_dict)
Vous pouvez itérer sur un tf.data.Dataset comme n'importe quel autre python itérable :
for example in features_ds:
for name, value in example.items():
print(f"{name:19s}: {value}")
break
sex : b'male' age : 22.0 n_siblings_spouses : 1 parch : 0 fare : 7.25 class : b'Third' deck : b'unknown' embark_town : b'Southampton' alone : b'n'
La fonction from_tensor_slices peut gérer n'importe quelle structure de dictionnaires imbriqués ou de tuples. Le code suivant crée un ensemble de données de paires (features_dict, labels) :
titanic_ds = tf.data.Dataset.from_tensor_slices((titanic_features_dict, titanic_labels))
Pour former un modèle à l'aide de cet ensemble de Dataset , vous devez au moins shuffle et batch les données.
titanic_batches = titanic_ds.shuffle(len(titanic_labels)).batch(32)
Au lieu de transmettre des features et des labels à Model.fit , vous transmettez l'ensemble de données :
titanic_model.fit(titanic_batches, epochs=5)
Epoch 1/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4230 Epoch 2/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4216 Epoch 3/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4203 Epoch 4/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4198 Epoch 5/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4194 <keras.callbacks.History at 0x7f70b12485d0>
A partir d'un seul fichier
Jusqu'à présent, ce didacticiel a fonctionné avec des données en mémoire. tf.data est une boîte à outils hautement évolutive pour la création de pipelines de données et fournit quelques fonctions pour gérer le chargement des fichiers CSV.
titanic_file_path = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
Downloading data from https://storage.googleapis.com/tf-datasets/titanic/train.csv 32768/30874 [===============================] - 0s 0us/step 40960/30874 [=======================================] - 0s 0us/step
Lisez maintenant les données CSV du fichier et créez un tf.data.Dataset .
(Pour la documentation complète, voir tf.data.experimental.make_csv_dataset )
titanic_csv_ds = tf.data.experimental.make_csv_dataset(
titanic_file_path,
batch_size=5, # Artificially small to make examples easier to show.
label_name='survived',
num_epochs=1,
ignore_errors=True,)
Cette fonction comprend de nombreuses fonctions pratiques pour faciliter l'utilisation des données. Ceci comprend:
- Utilisation des en-têtes de colonne comme clés de dictionnaire.
- Détermination automatique du type de chaque colonne.
for batch, label in titanic_csv_ds.take(1):
for key, value in batch.items():
print(f"{key:20s}: {value}")
print()
print(f"{'label':20s}: {label}")
sex : [b'male' b'male' b'female' b'male' b'male'] age : [27. 18. 15. 46. 50.] n_siblings_spouses : [0 0 0 1 0] parch : [0 0 0 0 0] fare : [ 7.896 7.796 7.225 61.175 13. ] class : [b'Third' b'Third' b'Third' b'First' b'Second'] deck : [b'unknown' b'unknown' b'unknown' b'E' b'unknown'] embark_town : [b'Southampton' b'Southampton' b'Cherbourg' b'Southampton' b'Southampton'] alone : [b'y' b'y' b'y' b'n' b'y'] label : [0 0 1 0 0]
Il peut également décompresser les données à la volée. Voici un fichier CSV compressé contenant l' ensemble de données sur le trafic inter-États du métro

Image de Wikimédia
{kind=link}
traffic_volume_csv_gz = tf.keras.utils.get_file(
'Metro_Interstate_Traffic_Volume.csv.gz',
"https://archive.ics.uci.edu/ml/machine-learning-databases/00492/Metro_Interstate_Traffic_Volume.csv.gz",
cache_dir='.', cache_subdir='traffic')
Downloading data from https://archive.ics.uci.edu/ml/machine-learning-databases/00492/Metro_Interstate_Traffic_Volume.csv.gz 409600/405373 [==============================] - 1s 1us/step 417792/405373 [==============================] - 1s 1us/step
Définissez l'argument compression_type pour lire directement à partir du fichier compressé :
traffic_volume_csv_gz_ds = tf.data.experimental.make_csv_dataset(
traffic_volume_csv_gz,
batch_size=256,
label_name='traffic_volume',
num_epochs=1,
compression_type="GZIP")
for batch, label in traffic_volume_csv_gz_ds.take(1):
for key, value in batch.items():
print(f"{key:20s}: {value[:5]}")
print()
print(f"{'label':20s}: {label[:5]}")
holiday : [b'None' b'None' b'None' b'None' b'None'] temp : [280.56 266.79 281.64 292.71 270.48] rain_1h : [0. 0. 0. 0. 0.] snow_1h : [0. 0. 0. 0. 0.] clouds_all : [46 90 90 0 64] weather_main : [b'Clear' b'Clouds' b'Mist' b'Clear' b'Clouds'] weather_description : [b'sky is clear' b'overcast clouds' b'mist' b'Sky is Clear' b'broken clouds'] date_time : [b'2012-11-05 20:00:00' b'2012-12-17 23:00:00' b'2013-10-06 19:00:00' b'2013-08-23 22:00:00' b'2013-11-11 05:00:00'] label : [2415 966 3459 2633 2576]
Mise en cache
L'analyse des données csv entraîne une surcharge. Pour les petits modèles, cela peut être le goulot d'étranglement de la formation.
Selon votre cas d'utilisation, il peut être judicieux d'utiliser Dataset.cache ou data.experimental.snapshot afin que les données csv ne soient analysées qu'à la première époque.
La principale différence entre les méthodes de cache et d' snapshot est que les fichiers de cache ne peuvent être utilisés que par le processus TensorFlow qui les a créés, mais les fichiers d' snapshot peuvent être lus par d'autres processus.
Par exemple, l'itération sur le traffic_volume_csv_gz_ds 20 fois prend environ 15 secondes sans mise en cache ou environ 2 secondes avec mise en cache.
%%time
for i, (batch, label) in enumerate(traffic_volume_csv_gz_ds.repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
............................................................................................... CPU times: user 14.9 s, sys: 3.7 s, total: 18.6 s Wall time: 11.2 s
%%time
caching = traffic_volume_csv_gz_ds.cache().shuffle(1000)
for i, (batch, label) in enumerate(caching.shuffle(1000).repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
............................................................................................... CPU times: user 1.43 s, sys: 173 ms, total: 1.6 s Wall time: 1.28 s
%%time
snapshot = tf.data.experimental.snapshot('titanic.tfsnap')
snapshotting = traffic_volume_csv_gz_ds.apply(snapshot).shuffle(1000)
for i, (batch, label) in enumerate(snapshotting.shuffle(1000).repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
WARNING:tensorflow:From <timed exec>:1: snapshot (from tensorflow.python.data.experimental.ops.snapshot) is deprecated and will be removed in a future version. Instructions for updating: Use `tf.data.Dataset.snapshot(...)`. ............................................................................................... CPU times: user 2.17 s, sys: 460 ms, total: 2.63 s Wall time: 1.6 s
Si le chargement de vos données est ralenti par le chargement de fichiers CSV et que le cache et l' snapshot sont insuffisants pour votre cas d'utilisation, envisagez de réencoder vos données dans un format plus simple.
Plusieurs fichiers
Tous les exemples de cette section pourraient facilement être réalisés sans tf.data . Un endroit où tf.data peut vraiment simplifier les choses est lorsqu'il s'agit de collections de fichiers.
Par exemple, le jeu de données des images de polices de caractères est distribué sous la forme d'une collection de fichiers csv, un par police.

Image parWilli Heidelbach de Pixabay
Téléchargez l'ensemble de données et consultez les fichiers qu'il contient :
fonts_zip = tf.keras.utils.get_file(
'fonts.zip', "https://archive.ics.uci.edu/ml/machine-learning-databases/00417/fonts.zip",
cache_dir='.', cache_subdir='fonts',
extract=True)
Downloading data from https://archive.ics.uci.edu/ml/machine-learning-databases/00417/fonts.zip 160317440/160313983 [==============================] - 8s 0us/step 160325632/160313983 [==============================] - 8s 0us/step
import pathlib
font_csvs = sorted(str(p) for p in pathlib.Path('fonts').glob("*.csv"))
font_csvs[:10]
['fonts/AGENCY.csv', 'fonts/ARIAL.csv', 'fonts/BAITI.csv', 'fonts/BANKGOTHIC.csv', 'fonts/BASKERVILLE.csv', 'fonts/BAUHAUS.csv', 'fonts/BELL.csv', 'fonts/BERLIN.csv', 'fonts/BERNARD.csv', 'fonts/BITSTREAMVERA.csv']
len(font_csvs)
153
Lorsque vous traitez un groupe de fichiers, vous pouvez passer un file_pattern de style glob à la fonction experimental.make_csv_dataset . L'ordre des fichiers est mélangé à chaque itération.
Utilisez l'argument num_parallel_reads pour définir le nombre de fichiers lus en parallèle et entrelacés.
fonts_ds = tf.data.experimental.make_csv_dataset(
file_pattern = "fonts/*.csv",
batch_size=10, num_epochs=1,
num_parallel_reads=20,
shuffle_buffer_size=10000)
Ces fichiers csv ont les images aplaties en une seule ligne. Les noms de colonne sont au format r{row}c{column} . Voici le premier lot :
for features in fonts_ds.take(1):
for i, (name, value) in enumerate(features.items()):
if i>15:
break
print(f"{name:20s}: {value}")
print('...')
print(f"[total: {len(features)} features]")
font : [b'HANDPRINT' b'NIAGARA' b'EUROROMAN' b'NIAGARA' b'CENTAUR' b'NINA' b'GOUDY' b'SITKA' b'BELL' b'SITKA'] fontVariant : [b'scanned' b'NIAGARA SOLID' b'EUROROMAN' b'NIAGARA SOLID' b'CENTAUR' b'NINA' b'GOUDY STOUT' b'SITKA TEXT' b'BELL MT' b'SITKA TEXT'] m_label : [ 49 8482 245 88 174 9643 77 974 117 339] strength : [0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4] italic : [0 0 0 1 0 0 1 0 1 0] orientation : [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] m_top : [ 0 32 24 32 28 57 38 48 51 64] m_left : [ 0 20 24 20 22 24 27 23 25 23] originalH : [20 27 55 47 50 15 51 50 27 34] originalW : [ 4 33 25 33 50 15 116 43 28 53] h : [20 20 20 20 20 20 20 20 20 20] w : [20 20 20 20 20 20 20 20 20 20] r0c0 : [ 1 255 255 1 1 255 1 1 1 1] r0c1 : [ 1 255 255 1 1 255 1 1 1 1] r0c2 : [ 1 217 255 1 1 255 54 1 1 1] r0c3 : [ 1 213 255 1 1 255 255 1 1 64] ... [total: 412 features]
Facultatif : Champs d'emballage
Vous ne voulez probablement pas travailler avec chaque pixel dans des colonnes séparées comme celle-ci. Avant d'essayer d'utiliser cet ensemble de données, assurez-vous de regrouper les pixels dans un tenseur d'image.
Voici le code qui analyse les noms de colonne pour créer des images pour chaque exemple :
import re
def make_images(features):
image = [None]*400
new_feats = {}
for name, value in features.items():
match = re.match('r(\d+)c(\d+)', name)
if match:
image[int(match.group(1))*20+int(match.group(2))] = value
else:
new_feats[name] = value
image = tf.stack(image, axis=0)
image = tf.reshape(image, [20, 20, -1])
new_feats['image'] = image
return new_feats
Appliquez cette fonction à chaque lot de l'ensemble de données :
fonts_image_ds = fonts_ds.map(make_images)
for features in fonts_image_ds.take(1):
break
Tracez les images résultantes :
from matplotlib import pyplot as plt
plt.figure(figsize=(6,6), dpi=120)
for n in range(9):
plt.subplot(3,3,n+1)
plt.imshow(features['image'][..., n])
plt.title(chr(features['m_label'][n]))
plt.axis('off')

Fonctions de niveau inférieur
Jusqu'à présent, ce didacticiel s'est concentré sur les utilitaires de plus haut niveau pour la lecture de données csv. Il existe deux autres API qui peuvent être utiles pour les utilisateurs avancés si votre cas d'utilisation ne correspond pas aux modèles de base.
-
tf.io.decode_csv- une fonction pour analyser des lignes de texte dans une liste de tenseurs de colonne CSV. -
tf.data.experimental.CsvDataset- un constructeur d'ensemble de données csv de niveau inférieur.
Cette section recrée la fonctionnalité fournie par make_csv_dataset , pour montrer comment cette fonctionnalité de niveau inférieur peut être utilisée.
tf.io.decode_csv
Cette fonction décode une chaîne ou une liste de chaînes en une liste de colonnes.
Contrairement à make_csv_dataset , cette fonction n'essaie pas de deviner les types de données des colonnes. Vous spécifiez les types de colonne en fournissant une liste de record_defaults contenant une valeur du type correct, pour chaque colonne.
Pour lire les données du Titanic sous forme de chaînes à l'aide de decode_csv , vous diriez :
text = pathlib.Path(titanic_file_path).read_text()
lines = text.split('\n')[1:-1]
all_strings = [str()]*10
all_strings
['', '', '', '', '', '', '', '', '', '']
features = tf.io.decode_csv(lines, record_defaults=all_strings)
for f in features:
print(f"type: {f.dtype.name}, shape: {f.shape}")
type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,)
Pour les analyser avec leurs types réels, créez une liste de record_defaults des types correspondants :
print(lines[0])
0,male,22.0,1,0,7.25,Third,unknown,Southampton,n
titanic_types = [int(), str(), float(), int(), int(), float(), str(), str(), str(), str()]
titanic_types
[0, '', 0.0, 0, 0, 0.0, '', '', '', '']
features = tf.io.decode_csv(lines, record_defaults=titanic_types)
for f in features:
print(f"type: {f.dtype.name}, shape: {f.shape}")
type: int32, shape: (627,) type: string, shape: (627,) type: float32, shape: (627,) type: int32, shape: (627,) type: int32, shape: (627,) type: float32, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,)
tf.data.experimental.CsvDataset
La classe tf.data.experimental.CsvDataset fournit une interface de jeu de Dataset CSV minimale sans les fonctionnalités pratiques de la fonction make_csv_dataset : analyse d'en-tête de colonne, inférence de type de colonne, mélange automatique, entrelacement de fichiers.
Ce constructeur suit utilise record_defaults de la même manière que io.parse_csv :
simple_titanic = tf.data.experimental.CsvDataset(titanic_file_path, record_defaults=titanic_types, header=True)
for example in simple_titanic.take(1):
print([e.numpy() for e in example])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n']
Le code ci-dessus est fondamentalement équivalent à :
def decode_titanic_line(line):
return tf.io.decode_csv(line, titanic_types)
manual_titanic = (
# Load the lines of text
tf.data.TextLineDataset(titanic_file_path)
# Skip the header row.
.skip(1)
# Decode the line.
.map(decode_titanic_line)
)
for example in manual_titanic.take(1):
print([e.numpy() for e in example])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n']
Plusieurs fichiers
Pour analyser le jeu de données des polices à l'aide experimental.CsvDataset , vous devez d'abord déterminer les types de colonne pour le record_defaults . Commencez par inspecter la première ligne d'un fichier :
font_line = pathlib.Path(font_csvs[0]).read_text().splitlines()[1]
print(font_line)
AGENCY,AGENCY FB,64258,0.400000,0,0.000000,35,21,51,22,20,20,1,1,1,21,101,210,255,255,255,255,255,255,255,255,255,255,255,255,255,255,1,1,1,93,255,255,255,176,146,146,146,146,146,146,146,146,216,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,141,141,141,182,255,255,255,172,141,141,141,115,1,1,1,1,163,255,255,255,255,255,255,255,255,255,255,255,255,255,255,209,1,1,1,1,163,255,255,255,6,6,6,96,255,255,255,74,6,6,6,5,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255
Seuls les deux premiers champs sont des chaînes, les autres sont des entiers ou des flottants, et vous pouvez obtenir le nombre total de fonctionnalités en comptant les virgules :
num_font_features = font_line.count(',')+1
font_column_types = [str(), str()] + [float()]*(num_font_features-2)
Le constructeur CsvDatasaet peut prendre une liste de fichiers d'entrée, mais les lit de manière séquentielle. Le premier fichier de la liste des CSV est AGENCY.csv :
font_csvs[0]
'fonts/AGENCY.csv'
Ainsi, lorsque vous transmettez la liste des fichiers à CsvDataaset , les enregistrements de AGENCY.csv sont lus en premier :
simple_font_ds = tf.data.experimental.CsvDataset(
font_csvs,
record_defaults=font_column_types,
header=True)
for row in simple_font_ds.take(10):
print(row[0].numpy())
b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY'
Pour entrelacer plusieurs fichiers, utilisez Dataset.interleave .
Voici un ensemble de données initial contenant les noms de fichiers CSV :
font_files = tf.data.Dataset.list_files("fonts/*.csv")
Cela mélange les noms de fichiers à chaque époque :
print('Epoch 1:')
for f in list(font_files)[:5]:
print(" ", f.numpy())
print(' ...')
print()
print('Epoch 2:')
for f in list(font_files)[:5]:
print(" ", f.numpy())
print(' ...')
Epoch 1:
b'fonts/CORBEL.csv'
b'fonts/GLOUCESTER.csv'
b'fonts/GABRIOLA.csv'
b'fonts/FORTE.csv'
b'fonts/GILL.csv'
...
Epoch 2:
b'fonts/MONEY.csv'
b'fonts/ISOC.csv'
b'fonts/DUTCH801.csv'
b'fonts/CALIBRI.csv'
b'fonts/ROMANTIC.csv'
...
La méthode interleave prend un map_func qui crée un enfant- Dataset pour chaque élément du parent- Dataset .
Ici, vous souhaitez créer un CsvDataset à partir de chaque élément du jeu de données de fichiers :
def make_font_csv_ds(path):
return tf.data.experimental.CsvDataset(
path,
record_defaults=font_column_types,
header=True)
L'ensemble de Dataset renvoyé par entrelacement renvoie des éléments en parcourant un certain nombre d'ensembles de Dataset enfants. Notez, ci-dessous, comment le jeu de données parcourt cycle_length=3 trois fichiers de police :
font_rows = font_files.interleave(make_font_csv_ds,
cycle_length=3)
fonts_dict = {'font_name':[], 'character':[]}
for row in font_rows.take(10):
fonts_dict['font_name'].append(row[0].numpy().decode())
fonts_dict['character'].append(chr(row[2].numpy()))
pd.DataFrame(fonts_dict)
Performance
Plus tôt, il a été noté que io.decode_csv est plus efficace lorsqu'il est exécuté sur un lot de chaînes.
Il est possible de tirer parti de ce fait, lors de l'utilisation de lots de grande taille, pour améliorer les performances de chargement CSV (mais essayez d'abord la mise en cache ).
Avec le chargeur intégré 20, les lots de 2048 exemples prennent environ 17 s.
BATCH_SIZE=2048
fonts_ds = tf.data.experimental.make_csv_dataset(
file_pattern = "fonts/*.csv",
batch_size=BATCH_SIZE, num_epochs=1,
num_parallel_reads=100)
%%time
for i,batch in enumerate(fonts_ds.take(20)):
print('.',end='')
print()
.................... CPU times: user 24.3 s, sys: 1.46 s, total: 25.7 s Wall time: 10.9 s
La transmission de lots de lignes de texte à decode_csv s'exécute plus rapidement, en 5 s environ :
fonts_files = tf.data.Dataset.list_files("fonts/*.csv")
fonts_lines = fonts_files.interleave(
lambda fname:tf.data.TextLineDataset(fname).skip(1),
cycle_length=100).batch(BATCH_SIZE)
fonts_fast = fonts_lines.map(lambda x: tf.io.decode_csv(x, record_defaults=font_column_types))
%%time
for i,batch in enumerate(fonts_fast.take(20)):
print('.',end='')
print()
.................... CPU times: user 8.77 s, sys: 0 ns, total: 8.77 s Wall time: 1.57 s
Pour un autre exemple d'augmentation des performances csv en utilisant des lots volumineux, consultez le didacticiel surajustement et sous-ajustement .
Ce type d'approche peut fonctionner, mais envisagez d'autres options comme le cache et l' snapshot , ou le réencodage de vos données dans un format plus simple.