
| |
 GitHub でソースを表示 GitHub でソースを表示 |
このチュートリアルでは、転移学習を使用して、事前トレーニング済みネットワークから猫や犬の画像を分類する方法を紹介します。
事前トレーニング済みモデルは、通常は大規模な画像分類タスクなどの大規模なデータセットで事前トレーニング済みの保存されたネットワークです。事前トレーニング済みモデルをそのまま使用したり、転移学習を使用してこのモデルを任意のタスクにカスタマイズしたりすることができます。
画像分類のための転移学習の背後にある考え方は、モデルが大規模かつ十分に一般的なデータセットでトレーニングされていれば、そのモデルは視覚世界の一般的なモデルとして効果的に機能するというものです。それにより、最初から大規模なデータセット上で大規模なモデルをトレーニングを行わずに、これらの学習した特徴マップを活用することができます。
このノートブックでは、トレーニング済みモデルをカスタマイズする 2 つの方法を試します。
- 特徴抽出:前のネットワークで学習した表現を使用して、新しいサンプルから意味のある特徴を抽出します。事前トレーニング済みモデルの上に新規にトレーニングされる新しい分類器を追加するだけで、データセットで前に学習した特徴マップを再利用できるようになります。
モデル全体を(再)トレーニングする必要はありません。ベースとなる畳み込みネットワークには、画像分類に一般的に有用な特徴がすでに含まれています。ただし、事前トレーニング済みモデルの最後の分類部分は元の分類タスクに固有で、その後はモデルがトレーニングされたクラスのセットに固有です。
- ファインチューニング:凍結された基本モデルの最上位レイヤーのいくつかを解凍し、新たに追加された分類器レイヤーと解凍した基本モデルの最後のレイヤーの両方を合わせてトレーニングします。これにより、基本モデルの高次の特徴表現を「ファインチューニング」して、特定のタスクにより関連性を持たせることができます。
一般的な機械学習のワークフローに従います。
- データを調べ、理解する
- 入力パイプラインを構築し、この場合は Keras ImageDataGenerator を使用する
- モデルを作成する
- 事前トレーニング済みの基本モデル(および事前トレーニング済みの重み)を読み込む
- 分類レイヤーを上に重ねる
- モデルをトレーニングする
- モデルを評価する
import matplotlib.pyplot as plt
import numpy as np
import os
import tensorflow as tf
2024-01-11 22:22:38.312406: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2024-01-11 22:22:38.312449: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2024-01-11 22:22:38.314026: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
データの前処理をする
データをダウンロードする
このチュートリアルでは、数千枚の犬猫の画像を含むデータセットを使用します。画像を含む zip ファイルをダウンロードして解凍した後、tf.keras.utils.image_dataset_from_directory ユーティリティを使用して tf.data.Dataset を作成し、トレーニングと検証を行います。画像の読み込みに関する詳細は、このチュートリアルをご覧ください。
_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip'
path_to_zip = tf.keras.utils.get_file('cats_and_dogs.zip', origin=_URL, extract=True)
PATH = os.path.join(os.path.dirname(path_to_zip), 'cats_and_dogs_filtered')
train_dir = os.path.join(PATH, 'train')
validation_dir = os.path.join(PATH, 'validation')
BATCH_SIZE = 32
IMG_SIZE = (160, 160)
train_dataset = tf.keras.utils.image_dataset_from_directory(train_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
Downloading data from https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip 68606236/68606236 [==============================] - 0s 0us/step Found 2000 files belonging to 2 classes.
validation_dataset = tf.keras.utils.image_dataset_from_directory(validation_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
Found 1000 files belonging to 2 classes.
トレーニングセットの最初の 9 枚の画像とラベルを表示します。
class_names = train_dataset.class_names
plt.figure(figsize=(10, 10))
for images, labels in train_dataset.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")

元のデータセットにはテストセットが含まれていないので、テストセットを作成します。作成には、tf.data.experimental.cardinality を使用して検証セットで利用可能なデータのバッチ数を調べ、そのうちの 20% をテストセットに移動します。
val_batches = tf.data.experimental.cardinality(validation_dataset)
test_dataset = validation_dataset.take(val_batches // 5)
validation_dataset = validation_dataset.skip(val_batches // 5)
print('Number of validation batches: %d' % tf.data.experimental.cardinality(validation_dataset))
print('Number of test batches: %d' % tf.data.experimental.cardinality(test_dataset))
Number of validation batches: 26 Number of test batches: 6
パフォーマンスのためにデータセットを構成する
バッファ付きプリフェッチを使用して、I/O のブロッキングなしでディスクから画像を読み込みます。この手法の詳細についてはデータパフォーマンスガイドをご覧ください。
AUTOTUNE = tf.data.AUTOTUNE
train_dataset = train_dataset.prefetch(buffer_size=AUTOTUNE)
validation_dataset = validation_dataset.prefetch(buffer_size=AUTOTUNE)
test_dataset = test_dataset.prefetch(buffer_size=AUTOTUNE)
データ増強を使用する
大規模な画像データセットを持っていない場合には、回転や水平反転など、ランダムでありながら現実的な変換をトレーニング画像に適用し、サンプルを人為的に多様化することをお勧めします。これによって、トレーニングデータのさまざまな側面にモデルを露出させることができ、過適合を遅らせることができます。データ増強についての詳細は、このチュートリアルをご覧ください。
data_augmentation = tf.keras.Sequential([
tf.keras.layers.RandomFlip('horizontal'),
tf.keras.layers.RandomRotation(0.2),
])
注意: これらのレイヤーは、トレーニング中に Model.fit を呼び出した場合にのみアクティブです。モデルが Model.evaluate、Model.predict、または Model.call の推論モードで使用されている場合には非アクティブです。
これらのレイヤーを同じ画像に繰り返して適用し、結果を見てみましょう。
for image, _ in train_dataset.take(1):
plt.figure(figsize=(10, 10))
first_image = image[0]
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
augmented_image = data_augmentation(tf.expand_dims(first_image, 0))
plt.imshow(augmented_image[0] / 255)
plt.axis('off')

ピクセル値をリスケールする
すぐに tf.keras.applications.MobileNetV2 をダウンロードして、基本モデルとして使用します。このモデルはピクセル値 [-1,1] を想定していますが、この時点での画像のピクセル値は [0, 255] です。ピクセル値のリスケールには、モデルに含まれる前処理のメソッドを使用します。
preprocess_input = tf.keras.applications.mobilenet_v2.preprocess_input
注意: 別の方法として、tf.keras.layers.Rescaling を使用して、ピクセル値を [0, 255] から [-1, 1] にリスケールすることも可能です。
rescale = tf.keras.layers.Rescaling(1./127.5, offset=-1)
注意: 他の tf.keras.applications を使用する場合は、API ドキュメントを確認してピクセル値が [-1,1] または [0,1] を要求しているか確かめるか、あるいは含まれている関数 preprocess_input を使用します。
事前トレーニング済み畳み込みニューラルネットワークから基本モデルを作成する
Google が開発した MobileNet V2 モデルから基本モデルを作成します。これは、140 万枚の画像と 1000 クラスで構成された大規模データセットである ImageNet データセットによる事前トレーニング済みのモデルです。ImageNet は、jackfruit や syringe のような多彩なカテゴリを持つ研究用トレーニングデータセットです。この知識の基盤が、特定のデータセットから猫と犬を分類するのに有用になります。
まず、特徴抽出に使用する MobileNet V2 のレイヤーを選択する必要があります。最後の分類レイヤー(ほとんどの機械学習モデルの図では、下から上に向かうため、「上」にあります)はあまり役には立ちません。 その代わりに、平坦化演算の前の最後のレイヤーに依存するのが一般的です。このレイヤーは「ボトルネックレイヤー」と呼ばれます。ボトルネックレイヤーの特徴には、最終/最上位レイヤーよりも一般性が保持されています。
はじめに、ImageNet でトレーニングした重みで事前に読み込んだ MobileNet V2 モデルをインスタンス化します。引数 include_top=False を指定して、上位の分類レイヤーを含まない、特徴抽出に理想的なネットワークを読み込みます。
# Create the base model from the pre-trained model MobileNet V2
IMG_SHAPE = IMG_SIZE + (3,)
base_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE,
include_top=False,
weights='imagenet')
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_160_no_top.h5 9406464/9406464 [==============================] - 0s 0us/step
この特徴抽出器は、各 160x160x3 の画像を 5x5x1280 の特徴ブロックに変換します。 これで画像のバッチ例がどうなるかを見てみましょう。
image_batch, label_batch = next(iter(train_dataset))
feature_batch = base_model(image_batch)
print(feature_batch.shape)
(32, 5, 5, 1280)
特徴を抽出する
このステップでは、前のステップで作成した畳み込みベースを凍結させ、特徴抽出器として使用します。さらに、その上に分類器を追加して、最上位の分類器のトレーニングを行います。
畳み込みベースを凍結させる
モデルをコンパイルしてトレーニングする前に、畳み込みベースを凍結させることは重要です。(layer.trainable = False と設定して) 凍結させると、トレーニング中に特定のレイヤーの重みは更新されなくなります。MobileNet V2 には多くのレイヤーがありますが、モデル全体の trainable フラグを False に設定すれば、すべてのレイヤーをまとめて凍結することができます。
base_model.trainable = False
BatchNormalization レイヤーに関する重要な注意事項
多くのモデルには tf.keras.layers.BatchNormalization レイヤーが含まれています。このレイヤーは特殊なケースで、ファインチューニングのコンテキストに注意を払う必要があります。このチュートリアルでも後ほど説明します。
layer.trainable = False と設定する場合、BatchNormalization レイヤーは推論モードで実行されるため、その平均と分散統計は更新されません。
ファインチューニングを行うために BatchNormalization(バッチ正規化)レイヤーを含んだモデルを解凍する場合には、基本モデルを呼び出す際に training = False を渡して BatchNormalization レイヤーを推論モードにしておく必要があります。そうしないと、トレーニング不可能な重みに更新が適用され、モデルが学習したものを破壊してしまいます。
詳細については、転移学習ガイドをご覧ください。
# Let's take a look at the base model architecture
base_model.summary()
Model: "mobilenetv2_1.00_160"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 160, 160, 3)] 0 []
Conv1 (Conv2D) (None, 80, 80, 32) 864 ['input_1[0][0]']
bn_Conv1 (BatchNormalizati (None, 80, 80, 32) 128 ['Conv1[0][0]']
on)
Conv1_relu (ReLU) (None, 80, 80, 32) 0 ['bn_Conv1[0][0]']
expanded_conv_depthwise (D (None, 80, 80, 32) 288 ['Conv1_relu[0][0]']
epthwiseConv2D)
expanded_conv_depthwise_BN (None, 80, 80, 32) 128 ['expanded_conv_depthwise[0][0
(BatchNormalization) ]']
expanded_conv_depthwise_re (None, 80, 80, 32) 0 ['expanded_conv_depthwise_BN[0
lu (ReLU) ][0]']
expanded_conv_project (Con (None, 80, 80, 16) 512 ['expanded_conv_depthwise_relu
v2D) [0][0]']
expanded_conv_project_BN ( (None, 80, 80, 16) 64 ['expanded_conv_project[0][0]'
BatchNormalization) ]
block_1_expand (Conv2D) (None, 80, 80, 96) 1536 ['expanded_conv_project_BN[0][
0]']
block_1_expand_BN (BatchNo (None, 80, 80, 96) 384 ['block_1_expand[0][0]']
rmalization)
block_1_expand_relu (ReLU) (None, 80, 80, 96) 0 ['block_1_expand_BN[0][0]']
block_1_pad (ZeroPadding2D (None, 81, 81, 96) 0 ['block_1_expand_relu[0][0]']
)
block_1_depthwise (Depthwi (None, 40, 40, 96) 864 ['block_1_pad[0][0]']
seConv2D)
block_1_depthwise_BN (Batc (None, 40, 40, 96) 384 ['block_1_depthwise[0][0]']
hNormalization)
block_1_depthwise_relu (Re (None, 40, 40, 96) 0 ['block_1_depthwise_BN[0][0]']
LU)
block_1_project (Conv2D) (None, 40, 40, 24) 2304 ['block_1_depthwise_relu[0][0]
']
block_1_project_BN (BatchN (None, 40, 40, 24) 96 ['block_1_project[0][0]']
ormalization)
block_2_expand (Conv2D) (None, 40, 40, 144) 3456 ['block_1_project_BN[0][0]']
block_2_expand_BN (BatchNo (None, 40, 40, 144) 576 ['block_2_expand[0][0]']
rmalization)
block_2_expand_relu (ReLU) (None, 40, 40, 144) 0 ['block_2_expand_BN[0][0]']
block_2_depthwise (Depthwi (None, 40, 40, 144) 1296 ['block_2_expand_relu[0][0]']
seConv2D)
block_2_depthwise_BN (Batc (None, 40, 40, 144) 576 ['block_2_depthwise[0][0]']
hNormalization)
block_2_depthwise_relu (Re (None, 40, 40, 144) 0 ['block_2_depthwise_BN[0][0]']
LU)
block_2_project (Conv2D) (None, 40, 40, 24) 3456 ['block_2_depthwise_relu[0][0]
']
block_2_project_BN (BatchN (None, 40, 40, 24) 96 ['block_2_project[0][0]']
ormalization)
block_2_add (Add) (None, 40, 40, 24) 0 ['block_1_project_BN[0][0]',
'block_2_project_BN[0][0]']
block_3_expand (Conv2D) (None, 40, 40, 144) 3456 ['block_2_add[0][0]']
block_3_expand_BN (BatchNo (None, 40, 40, 144) 576 ['block_3_expand[0][0]']
rmalization)
block_3_expand_relu (ReLU) (None, 40, 40, 144) 0 ['block_3_expand_BN[0][0]']
block_3_pad (ZeroPadding2D (None, 41, 41, 144) 0 ['block_3_expand_relu[0][0]']
)
block_3_depthwise (Depthwi (None, 20, 20, 144) 1296 ['block_3_pad[0][0]']
seConv2D)
block_3_depthwise_BN (Batc (None, 20, 20, 144) 576 ['block_3_depthwise[0][0]']
hNormalization)
block_3_depthwise_relu (Re (None, 20, 20, 144) 0 ['block_3_depthwise_BN[0][0]']
LU)
block_3_project (Conv2D) (None, 20, 20, 32) 4608 ['block_3_depthwise_relu[0][0]
']
block_3_project_BN (BatchN (None, 20, 20, 32) 128 ['block_3_project[0][0]']
ormalization)
block_4_expand (Conv2D) (None, 20, 20, 192) 6144 ['block_3_project_BN[0][0]']
block_4_expand_BN (BatchNo (None, 20, 20, 192) 768 ['block_4_expand[0][0]']
rmalization)
block_4_expand_relu (ReLU) (None, 20, 20, 192) 0 ['block_4_expand_BN[0][0]']
block_4_depthwise (Depthwi (None, 20, 20, 192) 1728 ['block_4_expand_relu[0][0]']
seConv2D)
block_4_depthwise_BN (Batc (None, 20, 20, 192) 768 ['block_4_depthwise[0][0]']
hNormalization)
block_4_depthwise_relu (Re (None, 20, 20, 192) 0 ['block_4_depthwise_BN[0][0]']
LU)
block_4_project (Conv2D) (None, 20, 20, 32) 6144 ['block_4_depthwise_relu[0][0]
']
block_4_project_BN (BatchN (None, 20, 20, 32) 128 ['block_4_project[0][0]']
ormalization)
block_4_add (Add) (None, 20, 20, 32) 0 ['block_3_project_BN[0][0]',
'block_4_project_BN[0][0]']
block_5_expand (Conv2D) (None, 20, 20, 192) 6144 ['block_4_add[0][0]']
block_5_expand_BN (BatchNo (None, 20, 20, 192) 768 ['block_5_expand[0][0]']
rmalization)
block_5_expand_relu (ReLU) (None, 20, 20, 192) 0 ['block_5_expand_BN[0][0]']
block_5_depthwise (Depthwi (None, 20, 20, 192) 1728 ['block_5_expand_relu[0][0]']
seConv2D)
block_5_depthwise_BN (Batc (None, 20, 20, 192) 768 ['block_5_depthwise[0][0]']
hNormalization)
block_5_depthwise_relu (Re (None, 20, 20, 192) 0 ['block_5_depthwise_BN[0][0]']
LU)
block_5_project (Conv2D) (None, 20, 20, 32) 6144 ['block_5_depthwise_relu[0][0]
']
block_5_project_BN (BatchN (None, 20, 20, 32) 128 ['block_5_project[0][0]']
ormalization)
block_5_add (Add) (None, 20, 20, 32) 0 ['block_4_add[0][0]',
'block_5_project_BN[0][0]']
block_6_expand (Conv2D) (None, 20, 20, 192) 6144 ['block_5_add[0][0]']
block_6_expand_BN (BatchNo (None, 20, 20, 192) 768 ['block_6_expand[0][0]']
rmalization)
block_6_expand_relu (ReLU) (None, 20, 20, 192) 0 ['block_6_expand_BN[0][0]']
block_6_pad (ZeroPadding2D (None, 21, 21, 192) 0 ['block_6_expand_relu[0][0]']
)
block_6_depthwise (Depthwi (None, 10, 10, 192) 1728 ['block_6_pad[0][0]']
seConv2D)
block_6_depthwise_BN (Batc (None, 10, 10, 192) 768 ['block_6_depthwise[0][0]']
hNormalization)
block_6_depthwise_relu (Re (None, 10, 10, 192) 0 ['block_6_depthwise_BN[0][0]']
LU)
block_6_project (Conv2D) (None, 10, 10, 64) 12288 ['block_6_depthwise_relu[0][0]
']
block_6_project_BN (BatchN (None, 10, 10, 64) 256 ['block_6_project[0][0]']
ormalization)
block_7_expand (Conv2D) (None, 10, 10, 384) 24576 ['block_6_project_BN[0][0]']
block_7_expand_BN (BatchNo (None, 10, 10, 384) 1536 ['block_7_expand[0][0]']
rmalization)
block_7_expand_relu (ReLU) (None, 10, 10, 384) 0 ['block_7_expand_BN[0][0]']
block_7_depthwise (Depthwi (None, 10, 10, 384) 3456 ['block_7_expand_relu[0][0]']
seConv2D)
block_7_depthwise_BN (Batc (None, 10, 10, 384) 1536 ['block_7_depthwise[0][0]']
hNormalization)
block_7_depthwise_relu (Re (None, 10, 10, 384) 0 ['block_7_depthwise_BN[0][0]']
LU)
block_7_project (Conv2D) (None, 10, 10, 64) 24576 ['block_7_depthwise_relu[0][0]
']
block_7_project_BN (BatchN (None, 10, 10, 64) 256 ['block_7_project[0][0]']
ormalization)
block_7_add (Add) (None, 10, 10, 64) 0 ['block_6_project_BN[0][0]',
'block_7_project_BN[0][0]']
block_8_expand (Conv2D) (None, 10, 10, 384) 24576 ['block_7_add[0][0]']
block_8_expand_BN (BatchNo (None, 10, 10, 384) 1536 ['block_8_expand[0][0]']
rmalization)
block_8_expand_relu (ReLU) (None, 10, 10, 384) 0 ['block_8_expand_BN[0][0]']
block_8_depthwise (Depthwi (None, 10, 10, 384) 3456 ['block_8_expand_relu[0][0]']
seConv2D)
block_8_depthwise_BN (Batc (None, 10, 10, 384) 1536 ['block_8_depthwise[0][0]']
hNormalization)
block_8_depthwise_relu (Re (None, 10, 10, 384) 0 ['block_8_depthwise_BN[0][0]']
LU)
block_8_project (Conv2D) (None, 10, 10, 64) 24576 ['block_8_depthwise_relu[0][0]
']
block_8_project_BN (BatchN (None, 10, 10, 64) 256 ['block_8_project[0][0]']
ormalization)
block_8_add (Add) (None, 10, 10, 64) 0 ['block_7_add[0][0]',
'block_8_project_BN[0][0]']
block_9_expand (Conv2D) (None, 10, 10, 384) 24576 ['block_8_add[0][0]']
block_9_expand_BN (BatchNo (None, 10, 10, 384) 1536 ['block_9_expand[0][0]']
rmalization)
block_9_expand_relu (ReLU) (None, 10, 10, 384) 0 ['block_9_expand_BN[0][0]']
block_9_depthwise (Depthwi (None, 10, 10, 384) 3456 ['block_9_expand_relu[0][0]']
seConv2D)
block_9_depthwise_BN (Batc (None, 10, 10, 384) 1536 ['block_9_depthwise[0][0]']
hNormalization)
block_9_depthwise_relu (Re (None, 10, 10, 384) 0 ['block_9_depthwise_BN[0][0]']
LU)
block_9_project (Conv2D) (None, 10, 10, 64) 24576 ['block_9_depthwise_relu[0][0]
']
block_9_project_BN (BatchN (None, 10, 10, 64) 256 ['block_9_project[0][0]']
ormalization)
block_9_add (Add) (None, 10, 10, 64) 0 ['block_8_add[0][0]',
'block_9_project_BN[0][0]']
block_10_expand (Conv2D) (None, 10, 10, 384) 24576 ['block_9_add[0][0]']
block_10_expand_BN (BatchN (None, 10, 10, 384) 1536 ['block_10_expand[0][0]']
ormalization)
block_10_expand_relu (ReLU (None, 10, 10, 384) 0 ['block_10_expand_BN[0][0]']
)
block_10_depthwise (Depthw (None, 10, 10, 384) 3456 ['block_10_expand_relu[0][0]']
iseConv2D)
block_10_depthwise_BN (Bat (None, 10, 10, 384) 1536 ['block_10_depthwise[0][0]']
chNormalization)
block_10_depthwise_relu (R (None, 10, 10, 384) 0 ['block_10_depthwise_BN[0][0]'
eLU) ]
block_10_project (Conv2D) (None, 10, 10, 96) 36864 ['block_10_depthwise_relu[0][0
]']
block_10_project_BN (Batch (None, 10, 10, 96) 384 ['block_10_project[0][0]']
Normalization)
block_11_expand (Conv2D) (None, 10, 10, 576) 55296 ['block_10_project_BN[0][0]']
block_11_expand_BN (BatchN (None, 10, 10, 576) 2304 ['block_11_expand[0][0]']
ormalization)
block_11_expand_relu (ReLU (None, 10, 10, 576) 0 ['block_11_expand_BN[0][0]']
)
block_11_depthwise (Depthw (None, 10, 10, 576) 5184 ['block_11_expand_relu[0][0]']
iseConv2D)
block_11_depthwise_BN (Bat (None, 10, 10, 576) 2304 ['block_11_depthwise[0][0]']
chNormalization)
block_11_depthwise_relu (R (None, 10, 10, 576) 0 ['block_11_depthwise_BN[0][0]'
eLU) ]
block_11_project (Conv2D) (None, 10, 10, 96) 55296 ['block_11_depthwise_relu[0][0
]']
block_11_project_BN (Batch (None, 10, 10, 96) 384 ['block_11_project[0][0]']
Normalization)
block_11_add (Add) (None, 10, 10, 96) 0 ['block_10_project_BN[0][0]',
'block_11_project_BN[0][0]']
block_12_expand (Conv2D) (None, 10, 10, 576) 55296 ['block_11_add[0][0]']
block_12_expand_BN (BatchN (None, 10, 10, 576) 2304 ['block_12_expand[0][0]']
ormalization)
block_12_expand_relu (ReLU (None, 10, 10, 576) 0 ['block_12_expand_BN[0][0]']
)
block_12_depthwise (Depthw (None, 10, 10, 576) 5184 ['block_12_expand_relu[0][0]']
iseConv2D)
block_12_depthwise_BN (Bat (None, 10, 10, 576) 2304 ['block_12_depthwise[0][0]']
chNormalization)
block_12_depthwise_relu (R (None, 10, 10, 576) 0 ['block_12_depthwise_BN[0][0]'
eLU) ]
block_12_project (Conv2D) (None, 10, 10, 96) 55296 ['block_12_depthwise_relu[0][0
]']
block_12_project_BN (Batch (None, 10, 10, 96) 384 ['block_12_project[0][0]']
Normalization)
block_12_add (Add) (None, 10, 10, 96) 0 ['block_11_add[0][0]',
'block_12_project_BN[0][0]']
block_13_expand (Conv2D) (None, 10, 10, 576) 55296 ['block_12_add[0][0]']
block_13_expand_BN (BatchN (None, 10, 10, 576) 2304 ['block_13_expand[0][0]']
ormalization)
block_13_expand_relu (ReLU (None, 10, 10, 576) 0 ['block_13_expand_BN[0][0]']
)
block_13_pad (ZeroPadding2 (None, 11, 11, 576) 0 ['block_13_expand_relu[0][0]']
D)
block_13_depthwise (Depthw (None, 5, 5, 576) 5184 ['block_13_pad[0][0]']
iseConv2D)
block_13_depthwise_BN (Bat (None, 5, 5, 576) 2304 ['block_13_depthwise[0][0]']
chNormalization)
block_13_depthwise_relu (R (None, 5, 5, 576) 0 ['block_13_depthwise_BN[0][0]'
eLU) ]
block_13_project (Conv2D) (None, 5, 5, 160) 92160 ['block_13_depthwise_relu[0][0
]']
block_13_project_BN (Batch (None, 5, 5, 160) 640 ['block_13_project[0][0]']
Normalization)
block_14_expand (Conv2D) (None, 5, 5, 960) 153600 ['block_13_project_BN[0][0]']
block_14_expand_BN (BatchN (None, 5, 5, 960) 3840 ['block_14_expand[0][0]']
ormalization)
block_14_expand_relu (ReLU (None, 5, 5, 960) 0 ['block_14_expand_BN[0][0]']
)
block_14_depthwise (Depthw (None, 5, 5, 960) 8640 ['block_14_expand_relu[0][0]']
iseConv2D)
block_14_depthwise_BN (Bat (None, 5, 5, 960) 3840 ['block_14_depthwise[0][0]']
chNormalization)
block_14_depthwise_relu (R (None, 5, 5, 960) 0 ['block_14_depthwise_BN[0][0]'
eLU) ]
block_14_project (Conv2D) (None, 5, 5, 160) 153600 ['block_14_depthwise_relu[0][0
]']
block_14_project_BN (Batch (None, 5, 5, 160) 640 ['block_14_project[0][0]']
Normalization)
block_14_add (Add) (None, 5, 5, 160) 0 ['block_13_project_BN[0][0]',
'block_14_project_BN[0][0]']
block_15_expand (Conv2D) (None, 5, 5, 960) 153600 ['block_14_add[0][0]']
block_15_expand_BN (BatchN (None, 5, 5, 960) 3840 ['block_15_expand[0][0]']
ormalization)
block_15_expand_relu (ReLU (None, 5, 5, 960) 0 ['block_15_expand_BN[0][0]']
)
block_15_depthwise (Depthw (None, 5, 5, 960) 8640 ['block_15_expand_relu[0][0]']
iseConv2D)
block_15_depthwise_BN (Bat (None, 5, 5, 960) 3840 ['block_15_depthwise[0][0]']
chNormalization)
block_15_depthwise_relu (R (None, 5, 5, 960) 0 ['block_15_depthwise_BN[0][0]'
eLU) ]
block_15_project (Conv2D) (None, 5, 5, 160) 153600 ['block_15_depthwise_relu[0][0
]']
block_15_project_BN (Batch (None, 5, 5, 160) 640 ['block_15_project[0][0]']
Normalization)
block_15_add (Add) (None, 5, 5, 160) 0 ['block_14_add[0][0]',
'block_15_project_BN[0][0]']
block_16_expand (Conv2D) (None, 5, 5, 960) 153600 ['block_15_add[0][0]']
block_16_expand_BN (BatchN (None, 5, 5, 960) 3840 ['block_16_expand[0][0]']
ormalization)
block_16_expand_relu (ReLU (None, 5, 5, 960) 0 ['block_16_expand_BN[0][0]']
)
block_16_depthwise (Depthw (None, 5, 5, 960) 8640 ['block_16_expand_relu[0][0]']
iseConv2D)
block_16_depthwise_BN (Bat (None, 5, 5, 960) 3840 ['block_16_depthwise[0][0]']
chNormalization)
block_16_depthwise_relu (R (None, 5, 5, 960) 0 ['block_16_depthwise_BN[0][0]'
eLU) ]
block_16_project (Conv2D) (None, 5, 5, 320) 307200 ['block_16_depthwise_relu[0][0
]']
block_16_project_BN (Batch (None, 5, 5, 320) 1280 ['block_16_project[0][0]']
Normalization)
Conv_1 (Conv2D) (None, 5, 5, 1280) 409600 ['block_16_project_BN[0][0]']
Conv_1_bn (BatchNormalizat (None, 5, 5, 1280) 5120 ['Conv_1[0][0]']
ion)
out_relu (ReLU) (None, 5, 5, 1280) 0 ['Conv_1_bn[0][0]']
==================================================================================================
Total params: 2257984 (8.61 MB)
Trainable params: 0 (0.00 Byte)
Non-trainable params: 2257984 (8.61 MB)
__________________________________________________________________________________________________
分類ヘッドを追加する
特徴ブロックから予測値を生成するには、f.keras.layers.GlobalAveragePooling2D レイヤーを使用して 5x5 空間の空間位置を平均化し、特徴を画像ごとに単一の1280要素ベクトルに変換します。
global_average_layer = tf.keras.layers.GlobalAveragePooling2D()
feature_batch_average = global_average_layer(feature_batch)
print(feature_batch_average.shape)
(32, 1280)
tf.keras.layers.Dense レイヤーを適用して、これらの特徴を画像ごとに単一の予測値に変換します。この予測は logit または未加工の予測値として扱われるため、ここで活性化関数は必要ありません。 正の数はクラス 1 を予測し、負の数はクラス 0 を予測します。
prediction_layer = tf.keras.layers.Dense(1)
prediction_batch = prediction_layer(feature_batch_average)
print(prediction_batch.shape)
(32, 1)
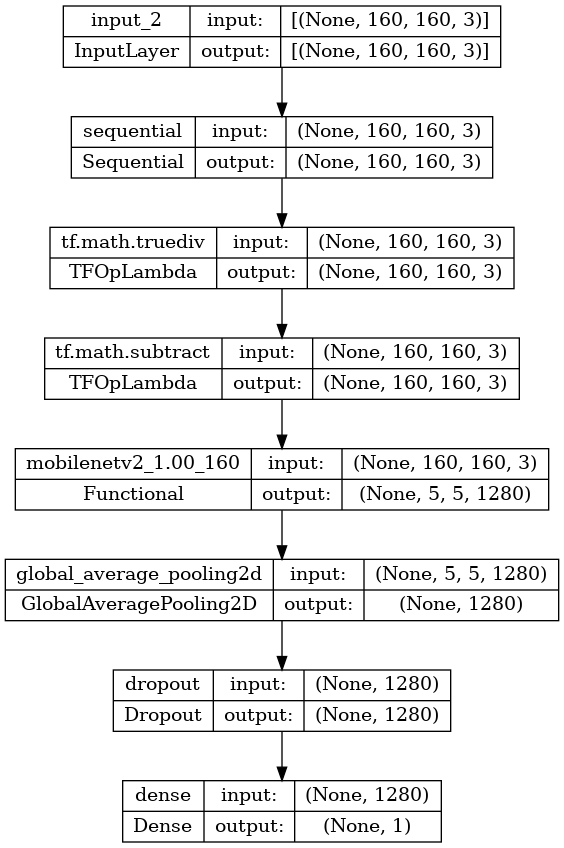
Keras Functional API を使用して、データ増強、リスケール、base_model、特徴抽出レイヤーを連結してモデルを構築します。前に触れたように、モデルには BatchNormalization レイヤーが含まれているため、training=False を使用します。
inputs = tf.keras.Input(shape=(160, 160, 3))
x = data_augmentation(inputs)
x = preprocess_input(x)
x = base_model(x, training=False)
x = global_average_layer(x)
x = tf.keras.layers.Dropout(0.2)(x)
outputs = prediction_layer(x)
model = tf.keras.Model(inputs, outputs)
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 160, 160, 3)] 0
sequential (Sequential) (None, 160, 160, 3) 0
tf.math.truediv (TFOpLambd (None, 160, 160, 3) 0
a)
tf.math.subtract (TFOpLamb (None, 160, 160, 3) 0
da)
mobilenetv2_1.00_160 (Func (None, 5, 5, 1280) 2257984
tional)
global_average_pooling2d ( (None, 1280) 0
GlobalAveragePooling2D)
dropout (Dropout) (None, 1280) 0
dense (Dense) (None, 1) 1281
=================================================================
Total params: 2259265 (8.62 MB)
Trainable params: 1281 (5.00 KB)
Non-trainable params: 2257984 (8.61 MB)
_________________________________________________________________
MobileNet の 800 万個以上のパラメータは凍結されていますが、Dense レイヤーには 1200 個のトレーニング可能なパラメータがあります。これらは 2 つの tf.Variable オブジェクトである、重みとバイアスに分割されます。
len(model.trainable_variables)
2
tf.keras.utils.plot_model(model, show_shapes=True)
モデルをコンパイルする
トレーニングする前にモデルをコンパイルします。2 つのクラスがあり、モデルが線形出力を提供するので、from_logits=True で tf.keras.losses.BinaryCrossentropy を使用します。
base_learning_rate = 0.0001
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=base_learning_rate),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.BinaryAccuracy(threshold=0, name='accuracy')])
モデルをトレーニングする
10 エポックのトレーニング後は、検証セットの精度が最大 96%になります。
initial_epochs = 10
loss0, accuracy0 = model.evaluate(validation_dataset)
26/26 [==============================] - 4s 56ms/step - loss: 0.8743 - accuracy: 0.4864
print("initial loss: {:.2f}".format(loss0))
print("initial accuracy: {:.2f}".format(accuracy0))
initial loss: 0.87 initial accuracy: 0.49
history = model.fit(train_dataset,
epochs=initial_epochs,
validation_data=validation_dataset)
Epoch 1/10 3/63 [>.............................] - ETA: 1s - loss: 0.9637 - accuracy: 0.5000 WARNING: All log messages before absl::InitializeLog() is called are written to STDERR I0000 00:00:1705011777.657639 1019028 device_compiler.h:186] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process. 63/63 [==============================] - 7s 51ms/step - loss: 0.8416 - accuracy: 0.5060 - val_loss: 0.5686 - val_accuracy: 0.7463 Epoch 2/10 63/63 [==============================] - 2s 35ms/step - loss: 0.5992 - accuracy: 0.6820 - val_loss: 0.4105 - val_accuracy: 0.8639 Epoch 3/10 63/63 [==============================] - 2s 35ms/step - loss: 0.4676 - accuracy: 0.7955 - val_loss: 0.3094 - val_accuracy: 0.9307 Epoch 4/10 63/63 [==============================] - 2s 35ms/step - loss: 0.3896 - accuracy: 0.8445 - val_loss: 0.2481 - val_accuracy: 0.9493 Epoch 5/10 63/63 [==============================] - 2s 35ms/step - loss: 0.3386 - accuracy: 0.8685 - val_loss: 0.2063 - val_accuracy: 0.9592 Epoch 6/10 63/63 [==============================] - 2s 35ms/step - loss: 0.2937 - accuracy: 0.8975 - val_loss: 0.1786 - val_accuracy: 0.9604 Epoch 7/10 63/63 [==============================] - 2s 35ms/step - loss: 0.2765 - accuracy: 0.8925 - val_loss: 0.1558 - val_accuracy: 0.9666 Epoch 8/10 63/63 [==============================] - 2s 35ms/step - loss: 0.2504 - accuracy: 0.9100 - val_loss: 0.1457 - val_accuracy: 0.9641 Epoch 9/10 63/63 [==============================] - 2s 35ms/step - loss: 0.2356 - accuracy: 0.9115 - val_loss: 0.1304 - val_accuracy: 0.9678 Epoch 10/10 63/63 [==============================] - 2s 35ms/step - loss: 0.2202 - accuracy: 0.9235 - val_loss: 0.1222 - val_accuracy: 0.9715
学習曲線
MobileNet V2 基本モデルを固定の特徴抽出器として使用する場合の、トレーニングと検証それぞれの精度と損失の学習曲線を見てみましょう。
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.ylabel('Accuracy')
plt.ylim([min(plt.ylim()),1])
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.ylabel('Cross Entropy')
plt.ylim([0,1.0])
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()
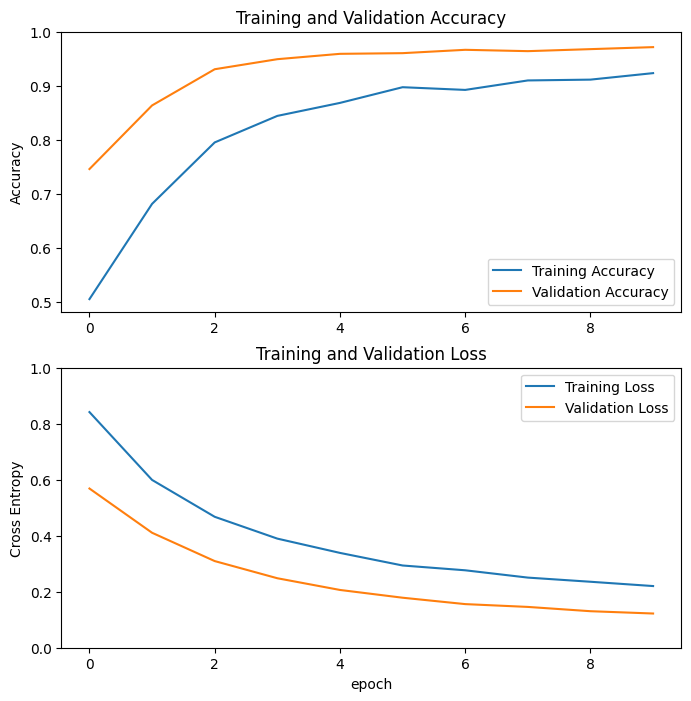
注意: 明らかに検証指標がトレーニング指標よりも優れていることを疑問に思われるかもしれませんが、それはトレーニング中に tf.keras.layer.BatchNormalization や tf.keras.layer.Dropout などのレイヤーが精度に影響を与えていることが主な要因です。検証損失の計算時には、これらのレイヤーはオフになっています。
また、上記の要因ほどではないにせよトレーニング指標がエポックの平均を報告する一方で検証指標がエポック後に評価されるため、検証指標の方が少しだけ長い時間トレーニングされたモデルを参照しているという理由もあります。
ファインチューニング
特徴抽出の実験では、MobileNet V2 基本モデル上に少数のレイヤーを重ねてトレーニングをしたに過ぎませんでした。事前トレーニング済みネットワークの重みはトレーニング中に更新されません。
パフォーマンスをさらに向上させる方法の 1 つに、追加した分類器のトレーニングと並行して、事前トレーニング済みモデルの最上位レイヤーの重みをトレーニング(または「ファインチューニング」)するというものがあります。トレーニングのプロセスでは、一般的な特徴マップから特にデータセットに関連付けられた特徴に、強制的に重みをチューニングします。
注意: これは必ず、事前トレーニング済みモデルをトレーニング不可に設定し、最上位の分類器をトレーニングした後に行うようにしてください。事前トレーニング済みモデルの上にランダムに初期化された分類器を追加してすべてのレイヤーを結合トレーニングしようとすると、(分類器からのランダムな重みにより)勾配の更新規模が大きすぎて、事前トレーニング済みモデルが学習したことを忘れてしまいます。
また、MobileNet モデル全体ではなく、少数の最上位レイヤーをファインチューニングしてみることをお勧めします。大部分の畳み込みネットワークでは、上位のレイヤーに行くほど専門性が高くなります。最初の数レイヤーは、ほとんどすべてのタイプの画像に一般化する、非常に単純かつ一般的な特徴を学習します。上位のレイヤーに行くに従って、特徴はモデルがトレーニングされたデータセットに対してもっと固有なものになっていきます。ファインチューニングの目的は、一般的な学習を上書きするのではなく、これらの特殊な特徴に適応させて新しいデータセットで作業ができるようにすることです。
モデルの最上位レイヤーを解凍する
ここでは base_model を解凍して、最下位レイヤーをトレーニング不可設定にするだけです。その後、モデルを再コンパイルして(これは行った変更を有効化するために必要)、トレーニングを再開します。
base_model.trainable = True
# Let's take a look to see how many layers are in the base model
print("Number of layers in the base model: ", len(base_model.layers))
# Fine-tune from this layer onwards
fine_tune_at = 100
# Freeze all the layers before the `fine_tune_at` layer
for layer in base_model.layers[:fine_tune_at]:
layer.trainable = False
Number of layers in the base model: 154
モデルをコンパイルする
かなり大規模なモデルをトレーニングしているため、事前トレーニング済みの重みを再適用する場合は、この段階では低い学習率を使用することが重要です。そうしなければ、モデルがすぐに過適合を起こす可能性があります。
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer = tf.keras.optimizers.RMSprop(learning_rate=base_learning_rate/10),
metrics=[tf.keras.metrics.BinaryAccuracy(threshold=0, name='accuracy')])
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 160, 160, 3)] 0
sequential (Sequential) (None, 160, 160, 3) 0
tf.math.truediv (TFOpLambd (None, 160, 160, 3) 0
a)
tf.math.subtract (TFOpLamb (None, 160, 160, 3) 0
da)
mobilenetv2_1.00_160 (Func (None, 5, 5, 1280) 2257984
tional)
global_average_pooling2d ( (None, 1280) 0
GlobalAveragePooling2D)
dropout (Dropout) (None, 1280) 0
dense (Dense) (None, 1) 1281
=================================================================
Total params: 2259265 (8.62 MB)
Trainable params: 1862721 (7.11 MB)
Non-trainable params: 396544 (1.51 MB)
_________________________________________________________________
len(model.trainable_variables)
56
モデルのトレーニングを続ける
前に収束するようにトレーニングをした場合は、このステップを踏むと精度が数ポイント向上します。
fine_tune_epochs = 10
total_epochs = initial_epochs + fine_tune_epochs
history_fine = model.fit(train_dataset,
epochs=total_epochs,
initial_epoch=history.epoch[-1],
validation_data=validation_dataset)
Epoch 10/20 63/63 [==============================] - 12s 65ms/step - loss: 0.1529 - accuracy: 0.9415 - val_loss: 0.0578 - val_accuracy: 0.9802 Epoch 11/20 63/63 [==============================] - 3s 45ms/step - loss: 0.1044 - accuracy: 0.9555 - val_loss: 0.0521 - val_accuracy: 0.9802 Epoch 12/20 63/63 [==============================] - 3s 45ms/step - loss: 0.1369 - accuracy: 0.9470 - val_loss: 0.0438 - val_accuracy: 0.9827 Epoch 13/20 63/63 [==============================] - 3s 45ms/step - loss: 0.0976 - accuracy: 0.9635 - val_loss: 0.0412 - val_accuracy: 0.9827 Epoch 14/20 63/63 [==============================] - 3s 45ms/step - loss: 0.1046 - accuracy: 0.9585 - val_loss: 0.0548 - val_accuracy: 0.9777 Epoch 15/20 63/63 [==============================] - 3s 45ms/step - loss: 0.0783 - accuracy: 0.9715 - val_loss: 0.0370 - val_accuracy: 0.9864 Epoch 16/20 63/63 [==============================] - 3s 45ms/step - loss: 0.0801 - accuracy: 0.9695 - val_loss: 0.0335 - val_accuracy: 0.9876 Epoch 17/20 63/63 [==============================] - 3s 45ms/step - loss: 0.0689 - accuracy: 0.9715 - val_loss: 0.0350 - val_accuracy: 0.9876 Epoch 18/20 63/63 [==============================] - 3s 45ms/step - loss: 0.0643 - accuracy: 0.9745 - val_loss: 0.0322 - val_accuracy: 0.9876 Epoch 19/20 63/63 [==============================] - 3s 45ms/step - loss: 0.0586 - accuracy: 0.9740 - val_loss: 0.0462 - val_accuracy: 0.9827 Epoch 20/20 63/63 [==============================] - 3s 45ms/step - loss: 0.0738 - accuracy: 0.9725 - val_loss: 0.0381 - val_accuracy: 0.9839
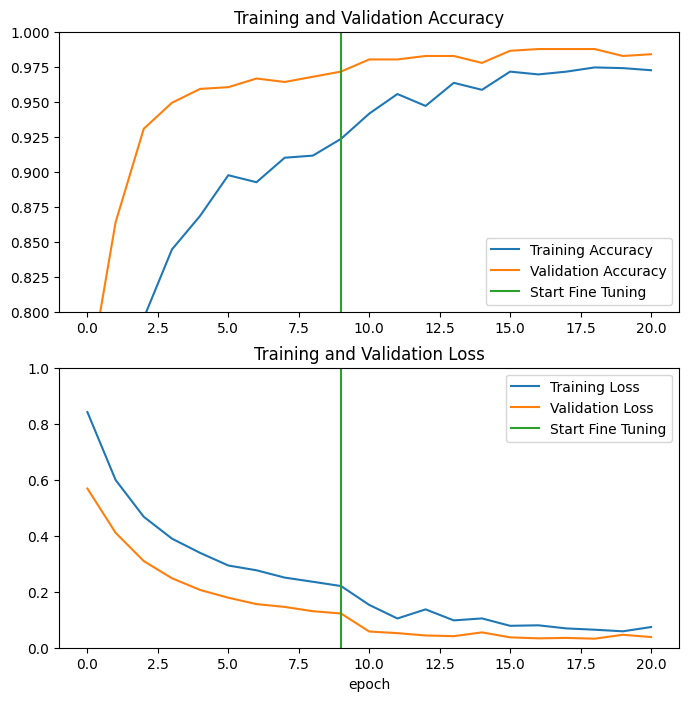
MobileNet V2 基本モデルの最後の数レイヤーをファインチューニングし、その上で分類器をトレーニングした場合の、トレーニングと検証それぞれの精度と損失の学習曲線を見てみましょう。検証損失の曲線がトレーニング損失よりもはるかに高いため、多少の過適合が発生する可能性があります。
また、新しいトレーニングセットが比較的小規模で、元の MobileNet V2 データセットに似ているために、過適合が発生する場合があります。
モデルをファインチューニングした後は、検証セットの精度はほぼ 98%に達します。
acc += history_fine.history['accuracy']
val_acc += history_fine.history['val_accuracy']
loss += history_fine.history['loss']
val_loss += history_fine.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.ylim([0.8, 1])
plt.plot([initial_epochs-1,initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.ylim([0, 1.0])
plt.plot([initial_epochs-1,initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()
評価と予測をする
最後に、テストセットを使用して、新しいデータでモデルの性能を検証することができます。
loss, accuracy = model.evaluate(test_dataset)
print('Test accuracy :', accuracy)
6/6 [==============================] - 0s 24ms/step - loss: 0.0398 - accuracy: 0.9844 Test accuracy : 0.984375
これで、このモデルを使用してペットが猫か犬かを予測する準備がすべて整いました。
# Retrieve a batch of images from the test set
image_batch, label_batch = test_dataset.as_numpy_iterator().next()
predictions = model.predict_on_batch(image_batch).flatten()
# Apply a sigmoid since our model returns logits
predictions = tf.nn.sigmoid(predictions)
predictions = tf.where(predictions < 0.5, 0, 1)
print('Predictions:\n', predictions.numpy())
print('Labels:\n', label_batch)
plt.figure(figsize=(10, 10))
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(image_batch[i].astype("uint8"))
plt.title(class_names[predictions[i]])
plt.axis("off")
Predictions: [0 1 1 1 1 1 1 0 0 0 0 1 0 0 1 0 0 0 1 1 0 0 0 1 1 0 0 0 1 0 1 1] Labels: [0 1 1 0 1 1 0 0 0 0 0 1 0 0 1 0 0 0 1 1 0 0 0 1 1 0 0 0 1 0 1 1]

要約
特徴抽出に事前トレーニング済みモデルを使用する: 小さなデータセットで作業する場合は、より大規模な同じドメインのデータセットでトレーニングされたモデルが学習した特徴を利用するのが一般的です。これは、事前トレーニング済みモデルをインスタンス化し、その上に完全に接続された分類器を追加して行います。事前トレーニング済みモデルは「凍結」されているため、トレーニング中は分類器の重みだけを更新します。この場合、畳み込みベースは各画像に関連付けられたすべての特徴を抽出し、抽出された特徴量のセットから画像クラスを決定する分類器をトレーニングします。
事前トレーニング済みモデルをファインチューニングする: 性能をさらに向上させるために、事前トレーニング済みモデルの最上位レイヤーをファインチューニングして、新しいデータセットに再利用することができます。この場合は、データセット固有の高レベルの特徴をモデルが学習するように重みをチューニングします。この手法は、通常はトレーニングデータセットが大規模で、事前トレーニング済みモデルがトレーニングされた元のデータセットによく似ている場合に推奨されます。
さらに詳しくは転移学習ガイドをご覧ください。
# MIT License
#
# Copyright (c) 2017 François Chollet # IGNORE_COPYRIGHT: cleared by OSS licensing
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.