
| | |  Voir la source sur GitHub Voir la source sur GitHub | |
Ce tutoriel se concentre sur la tâche de segmentation d'image, en utilisant un U-Net modifié.
Qu'est-ce que la segmentation d'images ?
Dans une tâche de classification d'images, le réseau attribue une étiquette (ou classe) à chaque image d'entrée. Cependant, supposons que vous vouliez connaître la forme de cet objet, quel pixel appartient à quel objet, etc. Dans ce cas, vous voudrez attribuer une classe à chaque pixel de l'image. Cette tâche est connue sous le nom de segmentation. Un modèle de segmentation renvoie des informations beaucoup plus détaillées sur l'image. La segmentation d'images a de nombreuses applications dans l'imagerie médicale, les voitures autonomes et l'imagerie par satellite, pour n'en nommer que quelques-unes.
Ce tutoriel utilise l' ensemble de données Oxford-IIIT Pet ( Parkhi et al, 2012 ). L'ensemble de données se compose d'images de 37 races d'animaux de compagnie, avec 200 images par race (~ 100 chacune dans les divisions d'entraînement et de test). Chaque image comprend les étiquettes correspondantes et les masques pixel par pixel. Les masques sont des étiquettes de classe pour chaque pixel. Chaque pixel se voit attribuer l'une des trois catégories suivantes :
- Classe 1 : Pixel appartenant à l'animal.
- Classe 2 : Pixel bordant l'animal.
- Classe 3 : aucune des réponses ci-dessus/un pixel environnant.
pip install git+https://github.com/tensorflow/examples.git
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow_examples.models.pix2pix import pix2pix
from IPython.display import clear_output
import matplotlib.pyplot as plt
Télécharger le jeu de données Oxford-IIIT Pets
L'ensemble de données est disponible à partir des ensembles de données TensorFlow . Les masques de segmentation sont inclus dans la version 3+.
dataset, info = tfds.load('oxford_iiit_pet:3.*.*', with_info=True)
De plus, les valeurs de couleur de l'image sont normalisées dans la plage [0,1] . Enfin, comme mentionné ci-dessus, les pixels du masque de segmentation sont étiquetés soit {1, 2, 3}. Par souci de commodité, soustrayez 1 du masque de segmentation, ce qui donne des étiquettes : {0, 1, 2}.
def normalize(input_image, input_mask):
input_image = tf.cast(input_image, tf.float32) / 255.0
input_mask -= 1
return input_image, input_mask
def load_image(datapoint):
input_image = tf.image.resize(datapoint['image'], (128, 128))
input_mask = tf.image.resize(datapoint['segmentation_mask'], (128, 128))
input_image, input_mask = normalize(input_image, input_mask)
return input_image, input_mask
L'ensemble de données contient déjà les fractionnements d'entraînement et de test requis, continuez donc à utiliser les mêmes fractionnements.
TRAIN_LENGTH = info.splits['train'].num_examples
BATCH_SIZE = 64
BUFFER_SIZE = 1000
STEPS_PER_EPOCH = TRAIN_LENGTH // BATCH_SIZE
train_images = dataset['train'].map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
test_images = dataset['test'].map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
La classe suivante effectue une augmentation simple en retournant une image de manière aléatoire. Accédez au didacticiel d' augmentation d'image pour en savoir plus.
class Augment(tf.keras.layers.Layer):
def __init__(self, seed=42):
super().__init__()
# both use the same seed, so they'll make the same random changes.
self.augment_inputs = tf.keras.layers.RandomFlip(mode="horizontal", seed=seed)
self.augment_labels = tf.keras.layers.RandomFlip(mode="horizontal", seed=seed)
def call(self, inputs, labels):
inputs = self.augment_inputs(inputs)
labels = self.augment_labels(labels)
return inputs, labels
Construisez le pipeline d'entrée, en appliquant l'augmentation après avoir regroupé les entrées.
train_batches = (
train_images
.cache()
.shuffle(BUFFER_SIZE)
.batch(BATCH_SIZE)
.repeat()
.map(Augment())
.prefetch(buffer_size=tf.data.AUTOTUNE))
test_batches = test_images.batch(BATCH_SIZE)
Visualisez un exemple d'image et son masque correspondant à partir du jeu de données.
def display(display_list):
plt.figure(figsize=(15, 15))
title = ['Input Image', 'True Mask', 'Predicted Mask']
for i in range(len(display_list)):
plt.subplot(1, len(display_list), i+1)
plt.title(title[i])
plt.imshow(tf.keras.utils.array_to_img(display_list[i]))
plt.axis('off')
plt.show()
for images, masks in train_batches.take(2):
sample_image, sample_mask = images[0], masks[0]
display([sample_image, sample_mask])
Corrupt JPEG data: 240 extraneous bytes before marker 0xd9 Corrupt JPEG data: premature end of data segment


2022-01-26 05:14:45.972101: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
Définir le modèle
Le modèle utilisé ici est un U-Net modifié. Un U-Net se compose d'un encodeur (downsampler) et d'un décodeur (upsampler). Afin d'apprendre des fonctionnalités robustes et de réduire le nombre de paramètres pouvant être formés, vous utiliserez un modèle pré-formé - MobileNetV2 - comme encodeur. Pour le décodeur, vous utiliserez le bloc upsample, qui est déjà implémenté dans l'exemple pix2pix du référentiel TensorFlow Examples. (Découvrez le pix2pix : Traduction d'image à image avec un didacticiel GAN conditionnel dans un bloc-notes.)
Comme mentionné, l'encodeur sera un modèle MobileNetV2 pré-entraîné qui est préparé et prêt à être utilisé dans tf.keras.applications . L'encodeur se compose de sorties spécifiques des couches intermédiaires du modèle. Notez que l'encodeur ne sera pas formé pendant le processus de formation.
base_model = tf.keras.applications.MobileNetV2(input_shape=[128, 128, 3], include_top=False)
# Use the activations of these layers
layer_names = [
'block_1_expand_relu', # 64x64
'block_3_expand_relu', # 32x32
'block_6_expand_relu', # 16x16
'block_13_expand_relu', # 8x8
'block_16_project', # 4x4
]
base_model_outputs = [base_model.get_layer(name).output for name in layer_names]
# Create the feature extraction model
down_stack = tf.keras.Model(inputs=base_model.input, outputs=base_model_outputs)
down_stack.trainable = False
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_128_no_top.h5 9412608/9406464 [==============================] - 0s 0us/step 9420800/9406464 [==============================] - 0s 0us/step
Le décodeur/suréchantillonneur est simplement une série de blocs de suréchantillonnage implémentés dans des exemples TensorFlow.
up_stack = [
pix2pix.upsample(512, 3), # 4x4 -> 8x8
pix2pix.upsample(256, 3), # 8x8 -> 16x16
pix2pix.upsample(128, 3), # 16x16 -> 32x32
pix2pix.upsample(64, 3), # 32x32 -> 64x64
]
def unet_model(output_channels:int):
inputs = tf.keras.layers.Input(shape=[128, 128, 3])
# Downsampling through the model
skips = down_stack(inputs)
x = skips[-1]
skips = reversed(skips[:-1])
# Upsampling and establishing the skip connections
for up, skip in zip(up_stack, skips):
x = up(x)
concat = tf.keras.layers.Concatenate()
x = concat([x, skip])
# This is the last layer of the model
last = tf.keras.layers.Conv2DTranspose(
filters=output_channels, kernel_size=3, strides=2,
padding='same') #64x64 -> 128x128
x = last(x)
return tf.keras.Model(inputs=inputs, outputs=x)
Notez que le nombre de filtres sur la dernière couche est défini sur le nombre de output_channels . Ce sera un canal de sortie par classe.
Former le modèle
Maintenant, il ne reste plus qu'à compiler et former le modèle.
Puisqu'il s'agit d'un problème de classification multiclasse, utilisez la fonction de perte tf.keras.losses.CategoricalCrossentropy avec l'argument from_logits défini sur True , car les étiquettes sont des entiers scalaires au lieu de vecteurs de scores pour chaque pixel de chaque classe.
Lors de l'exécution de l'inférence, l'étiquette attribuée au pixel est le canal avec la valeur la plus élevée. C'est ce que fait la fonction create_mask .
OUTPUT_CLASSES = 3
model = unet_model(output_channels=OUTPUT_CLASSES)
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Jetez un coup d'œil à l'architecture du modèle résultant :
tf.keras.utils.plot_model(model, show_shapes=True)

Essayez le modèle pour vérifier ce qu'il prédit avant l'entraînement.
def create_mask(pred_mask):
pred_mask = tf.argmax(pred_mask, axis=-1)
pred_mask = pred_mask[..., tf.newaxis]
return pred_mask[0]
def show_predictions(dataset=None, num=1):
if dataset:
for image, mask in dataset.take(num):
pred_mask = model.predict(image)
display([image[0], mask[0], create_mask(pred_mask)])
else:
display([sample_image, sample_mask,
create_mask(model.predict(sample_image[tf.newaxis, ...]))])
show_predictions()

Le rappel défini ci-dessous est utilisé pour observer comment le modèle s'améliore pendant sa formation.
class DisplayCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
clear_output(wait=True)
show_predictions()
print ('\nSample Prediction after epoch {}\n'.format(epoch+1))
EPOCHS = 20
VAL_SUBSPLITS = 5
VALIDATION_STEPS = info.splits['test'].num_examples//BATCH_SIZE//VAL_SUBSPLITS
model_history = model.fit(train_batches, epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
validation_steps=VALIDATION_STEPS,
validation_data=test_batches,
callbacks=[DisplayCallback()])

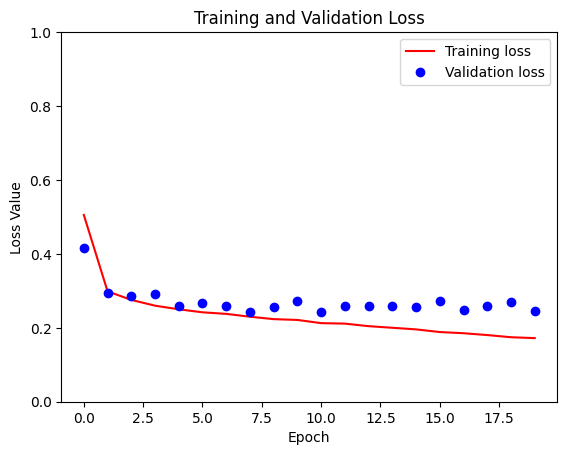
Sample Prediction after epoch 20 57/57 [==============================] - 4s 62ms/step - loss: 0.1838 - accuracy: 0.9187 - val_loss: 0.2797 - val_accuracy: 0.8955
loss = model_history.history['loss']
val_loss = model_history.history['val_loss']
plt.figure()
plt.plot(model_history.epoch, loss, 'r', label='Training loss')
plt.plot(model_history.epoch, val_loss, 'bo', label='Validation loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss Value')
plt.ylim([0, 1])
plt.legend()
plt.show()
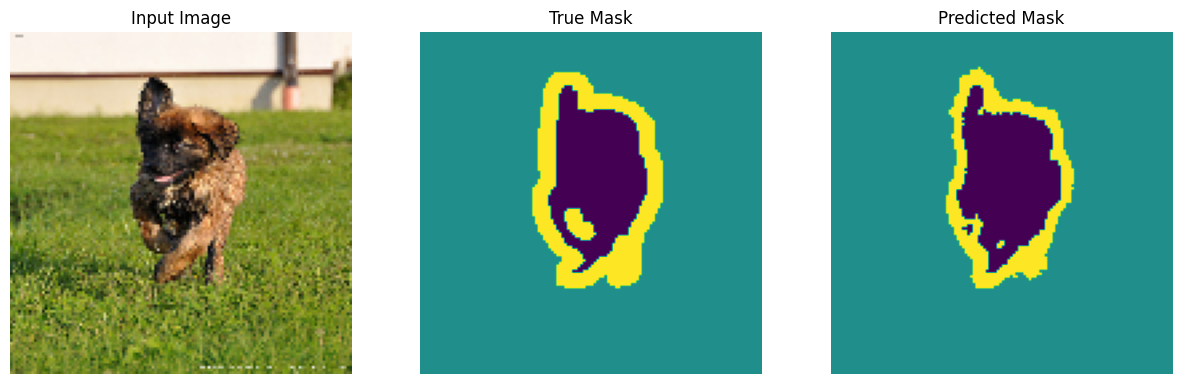
Faire des prédictions
Maintenant, faites des prédictions. Afin de gagner du temps, le nombre d'époques a été réduit, mais vous pouvez le définir plus haut pour obtenir des résultats plus précis.
show_predictions(test_batches, 3)


Facultatif : Classes et pondérations de classe déséquilibrées
Les ensembles de données de segmentation sémantique peuvent être très déséquilibrés, ce qui signifie que des pixels de classe particuliers peuvent être plus présents à l'intérieur des images que dans d'autres classes. Étant donné que les problèmes de segmentation peuvent être traités comme des problèmes de classification par pixel, vous pouvez traiter le problème de déséquilibre en pondérant la fonction de perte pour en tenir compte. C'est une façon simple et élégante de régler ce problème. Consultez le didacticiel Classification sur données déséquilibrées pour en savoir plus.
Pour éviter toute ambiguïté , Model.fit ne prend pas en charge l'argument class_weight pour les entrées avec plus de 3 dimensions.
try:
model_history = model.fit(train_batches, epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
class_weight = {0:2.0, 1:2.0, 2:1.0})
assert False
except Exception as e:
print(f"Expected {type(e).__name__}: {e}")
Expected ValueError: `class_weight` not supported for 3+ dimensional targets.
Donc, dans ce cas, vous devez mettre en œuvre la pondération vous-même. Pour ce faire, vous utiliserez des exemples de poids : en plus des paires (data, label) , Model.fit accepte également les triplets (data, label, sample_weight) .
Model.fit propage le sample_weight aux pertes et aux métriques, qui acceptent également un argument sample_weight . Le poids de l'échantillon est multiplié par la valeur de l'échantillon avant l'étape de réduction. Par example:
label = [0,0]
prediction = [[-3., 0], [-3, 0]]
sample_weight = [1, 10]
loss = tf.losses.SparseCategoricalCrossentropy(from_logits=True,
reduction=tf.losses.Reduction.NONE)
loss(label, prediction, sample_weight).numpy()
array([ 3.0485873, 30.485874 ], dtype=float32)
Donc, pour créer des exemples de poids pour ce didacticiel, vous avez besoin d'une fonction qui prend une paire (data, label) et renvoie un (data, label, sample_weight) . Où sample_weight est une image à 1 canal contenant le poids de classe pour chaque pixel.
L'implémentation la plus simple possible consiste à utiliser l'étiquette comme index dans une liste class_weight :
def add_sample_weights(image, label):
# The weights for each class, with the constraint that:
# sum(class_weights) == 1.0
class_weights = tf.constant([2.0, 2.0, 1.0])
class_weights = class_weights/tf.reduce_sum(class_weights)
# Create an image of `sample_weights` by using the label at each pixel as an
# index into the `class weights` .
sample_weights = tf.gather(class_weights, indices=tf.cast(label, tf.int32))
return image, label, sample_weights
Les éléments de l'ensemble de données résultant contiennent 3 images chacun :
train_batches.map(add_sample_weights).element_spec
(TensorSpec(shape=(None, 128, 128, 3), dtype=tf.float32, name=None), TensorSpec(shape=(None, 128, 128, 1), dtype=tf.float32, name=None), TensorSpec(shape=(None, 128, 128, 1), dtype=tf.float32, name=None))
Vous pouvez maintenant entraîner un modèle sur cet ensemble de données pondéré :
weighted_model = unet_model(OUTPUT_CLASSES)
weighted_model.compile(
optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
weighted_model.fit(
train_batches.map(add_sample_weights),
epochs=1,
steps_per_epoch=10)
10/10 [==============================] - 3s 44ms/step - loss: 0.3099 - accuracy: 0.6063 <keras.callbacks.History at 0x7fa75d0f3e50>
Prochaines étapes
Maintenant que vous comprenez ce qu'est la segmentation d'image et comment elle fonctionne, vous pouvez essayer ce didacticiel avec différentes sorties de couche intermédiaire, ou même différents modèles pré-entraînés. Vous pouvez également vous mettre au défi en essayant le défi de masquage d'image Carvana hébergé sur Kaggle.
Vous pouvez également consulter l' API de détection d'objets Tensorflow pour un autre modèle que vous pouvez recycler sur vos propres données. Des modèles pré-entraînés sont disponibles sur TensorFlow Hub