
| |
|
 깃허브(GitHub) 소스 보기 깃허브(GitHub) 소스 보기 |
|
이 튜토리얼은 MNIST 숫자를 분류하기 위해 간단한 합성곱 신경망(Convolutional Neural Network, CNN)을 훈련합니다. 간단한 이 네트워크는 MNIST 테스트 세트에서 99% 정확도를 달성할 것입니다. 이 튜토리얼은 케라스 Sequential API를 사용하기 때문에 몇 줄의 코드만으로 모델을 만들고 훈련할 수 있습니다.
텐서플로 임포트하기
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
2022-12-15 01:20:57.839164: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory 2022-12-15 01:20:57.839284: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory 2022-12-15 01:20:57.839295: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
MNIST 데이터셋 다운로드하고 준비하기
CIFAR10 데이터세트에는 10개 클래스에 60,000개의 컬러 이미지가 포함되어 있으며 각 클래스에는 6,000개의 이미지가 있습니다. 이 데이터세트는 50,000개의 훈련 이미지와 10,000개의 테스트 이미지로 나뉩니다. 클래스는 상호 배타적이며 서로 겹치지 않습니다.
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
# Normalize pixel values to be between 0 and 1
train_images, test_images = train_images / 255.0, test_images / 255.0
Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz 170498071/170498071 [==============================] - 2s 0us/step
데이터 확인하기
데이터세트가 올바른지 확인하기 위해 훈련 세트의 처음 25개 이미지를 플로팅하고 각 이미지 아래에 클래스 이름을 표시해 보겠습니다.
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i])
# The CIFAR labels happen to be arrays,
# which is why you need the extra index
plt.xlabel(class_names[train_labels[i][0]])
plt.show()

합성곱 층 만들기
아래 6줄의 코드에서 Conv2D와 MaxPooling2D 층을 쌓는 일반적인 패턴으로 합성곱 층을 정의합니다.
입력으로 CNN은 배치 크기를 무시하고 형상(image_height, image_width, color_channels)의 텐서를 사용합니다. 이러한 차원을 처음 접하는 경우 color_channels는 (R,G,B)를 나타냅니다. 이 예에서는 CIFAR 이미지 형식인 형상(32, 32, 3)의 입력을 처리하도록 CNN을 구성합니다. input_shape 인수를 첫 번째 레이어에 전달하여 이를 수행할 수 있습니다.
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
지금까지 모델의 아키텍처를 표시해 보겠습니다.
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 30, 30, 32) 896
max_pooling2d (MaxPooling2D (None, 15, 15, 32) 0
)
conv2d_1 (Conv2D) (None, 13, 13, 64) 18496
max_pooling2d_1 (MaxPooling (None, 6, 6, 64) 0
2D)
conv2d_2 (Conv2D) (None, 4, 4, 64) 36928
=================================================================
Total params: 56,320
Trainable params: 56,320
Non-trainable params: 0
_________________________________________________________________
위에서 Conv2D와 MaxPooling2D 층의 출력은 (높이, 너비, 채널) 크기의 3D 텐서입니다. 높이와 너비 차원은 네트워크가 깊어질수록 감소하는 경향을 가집니다. Conv2D 층에서 출력 채널의 수는 첫 번째 매개변수에 의해 결정됩니다(예를 들면, 32 또는 64). 일반적으로 높이와 너비가 줄어듦에 따라 (계산 비용 측면에서) Conv2D 층의 출력 채널을 늘릴 수 있습니다.
마지막에 Dense 층 추가하기
모델을 완성하려면 마지막 합성곱 층의 출력 텐서(크기 (4, 4, 64))를 하나 이상의 Dense 층에 주입하여 분류를 수행합니다. Dense 층은 벡터(1D)를 입력으로 받는데 현재 출력은 3D 텐서입니다. 먼저 3D 출력을 1D로 펼치겠습니다. 그다음 하나 이상의 Dense 층을 그 위에 추가하겠습니다. MNIST 데이터는 10개의 클래스가 있으므로 마지막에 Dense 층에 10개의 출력과 소프트맥스 활성화 함수를 사용합니다.
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10))
다음은 모델의 전체 아키텍처입니다.
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 30, 30, 32) 896
max_pooling2d (MaxPooling2D (None, 15, 15, 32) 0
)
conv2d_1 (Conv2D) (None, 13, 13, 64) 18496
max_pooling2d_1 (MaxPooling (None, 6, 6, 64) 0
2D)
conv2d_2 (Conv2D) (None, 4, 4, 64) 36928
flatten (Flatten) (None, 1024) 0
dense (Dense) (None, 64) 65600
dense_1 (Dense) (None, 10) 650
=================================================================
Total params: 122,570
Trainable params: 122,570
Non-trainable params: 0
_________________________________________________________________
네트워크 요약은 (4, 4, 64) 출력이 두 개의 Dense 레이어를 거치기 전에 (1024) 형상의 벡터로 평면화되었음을 보여줍니다.
모델 컴파일과 훈련하기
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
history = model.fit(train_images, train_labels, epochs=10,
validation_data=(test_images, test_labels))
Epoch 1/10 1563/1563 [==============================] - 11s 5ms/step - loss: 1.5189 - accuracy: 0.4442 - val_loss: 1.2819 - val_accuracy: 0.5381 Epoch 2/10 1563/1563 [==============================] - 7s 4ms/step - loss: 1.1463 - accuracy: 0.5945 - val_loss: 1.0690 - val_accuracy: 0.6251 Epoch 3/10 1563/1563 [==============================] - 7s 4ms/step - loss: 1.0011 - accuracy: 0.6477 - val_loss: 0.9954 - val_accuracy: 0.6492 Epoch 4/10 1563/1563 [==============================] - 7s 4ms/step - loss: 0.9019 - accuracy: 0.6856 - val_loss: 0.9277 - val_accuracy: 0.6760 Epoch 5/10 1563/1563 [==============================] - 7s 4ms/step - loss: 0.8332 - accuracy: 0.7089 - val_loss: 0.9078 - val_accuracy: 0.6856 Epoch 6/10 1563/1563 [==============================] - 7s 4ms/step - loss: 0.7806 - accuracy: 0.7262 - val_loss: 0.8720 - val_accuracy: 0.7027 Epoch 7/10 1563/1563 [==============================] - 7s 5ms/step - loss: 0.7345 - accuracy: 0.7435 - val_loss: 0.8202 - val_accuracy: 0.7193 Epoch 8/10 1563/1563 [==============================] - 7s 4ms/step - loss: 0.6927 - accuracy: 0.7567 - val_loss: 0.8642 - val_accuracy: 0.7056 Epoch 9/10 1563/1563 [==============================] - 7s 4ms/step - loss: 0.6549 - accuracy: 0.7708 - val_loss: 0.8438 - val_accuracy: 0.7184 Epoch 10/10 1563/1563 [==============================] - 7s 4ms/step - loss: 0.6182 - accuracy: 0.7808 - val_loss: 0.8554 - val_accuracy: 0.7209
모델 평가
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.5, 1])
plt.legend(loc='lower right')
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
313/313 - 1s - loss: 0.8554 - accuracy: 0.7209 - 703ms/epoch - 2ms/step
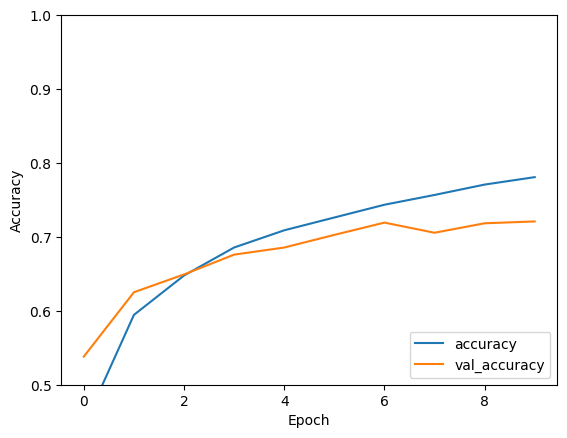
print(test_acc)
0.7208999991416931
이 간단한 CNN은 70% 이상의 테스트 정확도를 달성했습니다. 몇 줄의 코드로는 나쁘지 않습니다! 다른 CNN 스타일은 Keras 서브클래싱 API 및 tf.GradientTape를 사용하는 전문가를 위한 TensorFlow 2 빠른 시작 예제를 확인하세요.