
| | |  Ver en GitHub Ver en GitHub | | |
Este tutorial utiliza el aprendizaje profundo para componer una imagen con el estilo de otra imagen (¿alguna vez deseó poder pintar como Picasso o Van Gogh?). Esto se conoce como transferencia de estilo neural y la técnica se describe en A Neural Algorithm of Artistic Style (Gatys et al.).
Para obtener una aplicación simple de transferencia de estilo, consulte este tutorial para obtener más información sobre cómo usar el modelo de estilización de imagen arbitraria preentrenado de TensorFlow Hub o cómo usar un modelo de transferencia de estilo con TensorFlow Lite .
La transferencia de estilo neuronal es una técnica de optimización utilizada para tomar dos imágenes, una imagen de contenido y una imagen de referencia de estilo (como una obra de arte de un pintor famoso), y combinarlas para que la imagen de salida se vea como la imagen de contenido, pero "pintada". en el estilo de la imagen de referencia de estilo.
Esto se implementa mediante la optimización de la imagen de salida para que coincida con las estadísticas de contenido de la imagen de contenido y las estadísticas de estilo de la imagen de referencia de estilo. Estas estadísticas se extraen de las imágenes utilizando una red convolucional.
Por ejemplo, tomemos una imagen de este perro y la Composición 7 de Wassily Kandinsky:

Yellow Labrador Looking , de Wikimedia Commons por Elf . Licencia CC BY-SA 3.0
{kind=link}

Ahora, ¿cómo sería si Kandinsky decidiera pintar la imagen de este Perro exclusivamente con este estilo? ¿Algo como esto?

Configuración
Importar y configurar módulos
import os
import tensorflow as tf
# Load compressed models from tensorflow_hub
os.environ['TFHUB_MODEL_LOAD_FORMAT'] = 'COMPRESSED'
import IPython.display as display
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['figure.figsize'] = (12, 12)
mpl.rcParams['axes.grid'] = False
import numpy as np
import PIL.Image
import time
import functools
def tensor_to_image(tensor):
tensor = tensor*255
tensor = np.array(tensor, dtype=np.uint8)
if np.ndim(tensor)>3:
assert tensor.shape[0] == 1
tensor = tensor[0]
return PIL.Image.fromarray(tensor)
Descarga imágenes y elige una imagen de estilo y una imagen de contenido:
content_path = tf.keras.utils.get_file('YellowLabradorLooking_new.jpg', 'https://storage.googleapis.com/download.tensorflow.org/example_images/YellowLabradorLooking_new.jpg')
style_path = tf.keras.utils.get_file('kandinsky5.jpg','https://storage.googleapis.com/download.tensorflow.org/example_images/Vassily_Kandinsky%2C_1913_-_Composition_7.jpg')
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/Vassily_Kandinsky%2C_1913_-_Composition_7.jpg 196608/195196 [==============================] - 0s 0us/step 204800/195196 [===============================] - 0s 0us/step
Visualiza la entrada
Defina una función para cargar una imagen y limite su dimensión máxima a 512 píxeles.
def load_img(path_to_img):
max_dim = 512
img = tf.io.read_file(path_to_img)
img = tf.image.decode_image(img, channels=3)
img = tf.image.convert_image_dtype(img, tf.float32)
shape = tf.cast(tf.shape(img)[:-1], tf.float32)
long_dim = max(shape)
scale = max_dim / long_dim
new_shape = tf.cast(shape * scale, tf.int32)
img = tf.image.resize(img, new_shape)
img = img[tf.newaxis, :]
return img
Cree una función simple para mostrar una imagen:
def imshow(image, title=None):
if len(image.shape) > 3:
image = tf.squeeze(image, axis=0)
plt.imshow(image)
if title:
plt.title(title)
content_image = load_img(content_path)
style_image = load_img(style_path)
plt.subplot(1, 2, 1)
imshow(content_image, 'Content Image')
plt.subplot(1, 2, 2)
imshow(style_image, 'Style Image')

Transferencia de estilo rápido usando TF-Hub
Este tutorial demuestra el algoritmo de transferencia de estilo original, que optimiza el contenido de la imagen a un estilo particular. Antes de entrar en detalles, veamos cómo el modelo TensorFlow Hub hace esto:
import tensorflow_hub as hub
hub_model = hub.load('https://tfhub.dev/google/magenta/arbitrary-image-stylization-v1-256/2')
stylized_image = hub_model(tf.constant(content_image), tf.constant(style_image))[0]
tensor_to_image(stylized_image)
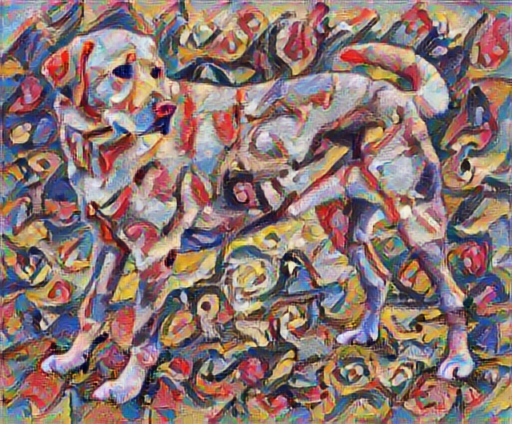
Definir representaciones de contenido y estilo.
Utilice las capas intermedias del modelo para obtener las representaciones de contenido y estilo de la imagen. A partir de la capa de entrada de la red, las primeras activaciones de capa representan características de bajo nivel como bordes y texturas. A medida que avanza por la red, las pocas capas finales representan características de nivel superior: partes de objetos como ruedas u ojos . En este caso, está utilizando la arquitectura de red VGG19, una red de clasificación de imágenes previamente entrenada. Estas capas intermedias son necesarias para definir la representación de contenido y estilo de las imágenes. Para una imagen de entrada, intente hacer coincidir las representaciones de destino de contenido y estilo correspondientes en estas capas intermedias.
Cargue un VGG19 y pruébelo en nuestra imagen para asegurarse de que se usa correctamente:
x = tf.keras.applications.vgg19.preprocess_input(content_image*255)
x = tf.image.resize(x, (224, 224))
vgg = tf.keras.applications.VGG19(include_top=True, weights='imagenet')
prediction_probabilities = vgg(x)
prediction_probabilities.shape
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg19/vgg19_weights_tf_dim_ordering_tf_kernels.h5 574717952/574710816 [==============================] - 17s 0us/step 574726144/574710816 [==============================] - 17s 0us/step TensorShape([1, 1000])
predicted_top_5 = tf.keras.applications.vgg19.decode_predictions(prediction_probabilities.numpy())[0]
[(class_name, prob) for (number, class_name, prob) in predicted_top_5]
[('Labrador_retriever', 0.493171),
('golden_retriever', 0.2366529),
('kuvasz', 0.036357544),
('Chesapeake_Bay_retriever', 0.024182785),
('Greater_Swiss_Mountain_dog', 0.0186461)]
Ahora cargue un VGG19 sin el cabezal de clasificación y enumere los nombres de las capas
vgg = tf.keras.applications.VGG19(include_top=False, weights='imagenet')
print()
for layer in vgg.layers:
print(layer.name)
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg19/vgg19_weights_tf_dim_ordering_tf_kernels_notop.h5 80142336/80134624 [==============================] - 2s 0us/step 80150528/80134624 [==============================] - 2s 0us/step input_2 block1_conv1 block1_conv2 block1_pool block2_conv1 block2_conv2 block2_pool block3_conv1 block3_conv2 block3_conv3 block3_conv4 block3_pool block4_conv1 block4_conv2 block4_conv3 block4_conv4 block4_pool block5_conv1 block5_conv2 block5_conv3 block5_conv4 block5_pool
Elija capas intermedias de la red para representar el estilo y el contenido de la imagen:
content_layers = ['block5_conv2']
style_layers = ['block1_conv1',
'block2_conv1',
'block3_conv1',
'block4_conv1',
'block5_conv1']
num_content_layers = len(content_layers)
num_style_layers = len(style_layers)
Capas intermedias para estilo y contenido.
Entonces, ¿por qué estas salidas intermedias dentro de nuestra red de clasificación de imágenes preentrenada nos permiten definir representaciones de estilo y contenido?
En un nivel alto, para que una red realice la clasificación de imágenes (para lo cual esta red ha sido entrenada), debe comprender la imagen. Esto requiere tomar la imagen sin procesar como píxeles de entrada y crear una representación interna que convierta los píxeles de la imagen sin procesar en una comprensión compleja de las características presentes en la imagen.
Esta es también una de las razones por las que las redes neuronales convolucionales pueden generalizar bien: pueden capturar las invariancias y definir características dentro de las clases (por ejemplo, gatos frente a perros) que son independientes del ruido de fondo y otras molestias. Por lo tanto, en algún lugar entre donde la imagen sin procesar se introduce en el modelo y la etiqueta de clasificación de salida, el modelo sirve como extractor de características complejas. Al acceder a las capas intermedias del modelo, puede describir el contenido y el estilo de las imágenes de entrada.
Construye el modelo
Las redes en tf.keras.applications están diseñadas para que pueda extraer fácilmente los valores de la capa intermedia utilizando la API funcional de Keras.
Para definir un modelo utilizando la API funcional, especifique las entradas y salidas:
model = Model(inputs, outputs)
La siguiente función crea un modelo VGG19 que devuelve una lista de salidas de capa intermedia:
def vgg_layers(layer_names):
""" Creates a vgg model that returns a list of intermediate output values."""
# Load our model. Load pretrained VGG, trained on imagenet data
vgg = tf.keras.applications.VGG19(include_top=False, weights='imagenet')
vgg.trainable = False
outputs = [vgg.get_layer(name).output for name in layer_names]
model = tf.keras.Model([vgg.input], outputs)
return model
Y para crear el modelo:
style_extractor = vgg_layers(style_layers)
style_outputs = style_extractor(style_image*255)
#Look at the statistics of each layer's output
for name, output in zip(style_layers, style_outputs):
print(name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
print()
block1_conv1 shape: (1, 336, 512, 64) min: 0.0 max: 835.5256 mean: 33.97525 block2_conv1 shape: (1, 168, 256, 128) min: 0.0 max: 4625.8857 mean: 199.82687 block3_conv1 shape: (1, 84, 128, 256) min: 0.0 max: 8789.239 mean: 230.78099 block4_conv1 shape: (1, 42, 64, 512) min: 0.0 max: 21566.135 mean: 791.24005 block5_conv1 shape: (1, 21, 32, 512) min: 0.0 max: 3189.2542 mean: 59.179478
Calcular estilo
El contenido de una imagen está representado por los valores de los mapas de características intermedias.
Resulta que el estilo de una imagen se puede describir por los medios y las correlaciones entre los diferentes mapas de características. Calcule una matriz de Gram que incluya esta información tomando el producto externo del vector de características consigo mismo en cada ubicación y promediando ese producto externo en todas las ubicaciones. Esta matriz de Gram se puede calcular para una capa en particular como:
\[G^l_{cd} = \frac{\sum_{ij} F^l_{ijc}(x)F^l_{ijd}(x)}{IJ}\]
Esto se puede implementar de manera concisa usando la función tf.linalg.einsum :
def gram_matrix(input_tensor):
result = tf.linalg.einsum('bijc,bijd->bcd', input_tensor, input_tensor)
input_shape = tf.shape(input_tensor)
num_locations = tf.cast(input_shape[1]*input_shape[2], tf.float32)
return result/(num_locations)
Extraer estilo y contenido
Cree un modelo que devuelva los tensores de estilo y contenido.
class StyleContentModel(tf.keras.models.Model):
def __init__(self, style_layers, content_layers):
super(StyleContentModel, self).__init__()
self.vgg = vgg_layers(style_layers + content_layers)
self.style_layers = style_layers
self.content_layers = content_layers
self.num_style_layers = len(style_layers)
self.vgg.trainable = False
def call(self, inputs):
"Expects float input in [0,1]"
inputs = inputs*255.0
preprocessed_input = tf.keras.applications.vgg19.preprocess_input(inputs)
outputs = self.vgg(preprocessed_input)
style_outputs, content_outputs = (outputs[:self.num_style_layers],
outputs[self.num_style_layers:])
style_outputs = [gram_matrix(style_output)
for style_output in style_outputs]
content_dict = {content_name: value
for content_name, value
in zip(self.content_layers, content_outputs)}
style_dict = {style_name: value
for style_name, value
in zip(self.style_layers, style_outputs)}
return {'content': content_dict, 'style': style_dict}
Cuando se llama a una imagen, este modelo devuelve la matriz de gramo (estilo) de las style_layers de estilo y el contenido de las content_layers de contenido:
extractor = StyleContentModel(style_layers, content_layers)
results = extractor(tf.constant(content_image))
print('Styles:')
for name, output in sorted(results['style'].items()):
print(" ", name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
print()
print("Contents:")
for name, output in sorted(results['content'].items()):
print(" ", name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
Styles:
block1_conv1
shape: (1, 64, 64)
min: 0.0055228462
max: 28014.557
mean: 263.79022
block2_conv1
shape: (1, 128, 128)
min: 0.0
max: 61479.496
mean: 9100.949
block3_conv1
shape: (1, 256, 256)
min: 0.0
max: 545623.44
mean: 7660.976
block4_conv1
shape: (1, 512, 512)
min: 0.0
max: 4320502.0
mean: 134288.84
block5_conv1
shape: (1, 512, 512)
min: 0.0
max: 110005.37
mean: 1487.0378
Contents:
block5_conv2
shape: (1, 26, 32, 512)
min: 0.0
max: 2410.8796
mean: 13.764149
Ejecutar descenso de gradiente
Con este extractor de estilo y contenido, ahora puede implementar el algoritmo de transferencia de estilo. Haga esto calculando el error cuadrático medio para la salida de su imagen en relación con cada objetivo, luego tome la suma ponderada de estas pérdidas.
Establezca sus valores objetivo de estilo y contenido:
style_targets = extractor(style_image)['style']
content_targets = extractor(content_image)['content']
Defina una tf.Variable para contener la imagen a optimizar. Para hacerlo rápido, inicialícelo con la imagen de contenido (la tf.Variable debe tener la misma forma que la imagen de contenido):
image = tf.Variable(content_image)
Dado que esta es una imagen flotante, defina una función para mantener los valores de píxel entre 0 y 1:
def clip_0_1(image):
return tf.clip_by_value(image, clip_value_min=0.0, clip_value_max=1.0)
Crear un optimizador. El documento recomienda LBFGS, pero Adam también funciona bien:
opt = tf.optimizers.Adam(learning_rate=0.02, beta_1=0.99, epsilon=1e-1)
Para optimizar esto, use una combinación ponderada de las dos pérdidas para obtener la pérdida total:
style_weight=1e-2
content_weight=1e4
def style_content_loss(outputs):
style_outputs = outputs['style']
content_outputs = outputs['content']
style_loss = tf.add_n([tf.reduce_mean((style_outputs[name]-style_targets[name])**2)
for name in style_outputs.keys()])
style_loss *= style_weight / num_style_layers
content_loss = tf.add_n([tf.reduce_mean((content_outputs[name]-content_targets[name])**2)
for name in content_outputs.keys()])
content_loss *= content_weight / num_content_layers
loss = style_loss + content_loss
return loss
Use tf.GradientTape para actualizar la imagen.
@tf.function()
def train_step(image):
with tf.GradientTape() as tape:
outputs = extractor(image)
loss = style_content_loss(outputs)
grad = tape.gradient(loss, image)
opt.apply_gradients([(grad, image)])
image.assign(clip_0_1(image))
Ahora ejecute algunos pasos para probar:
train_step(image)
train_step(image)
train_step(image)
tensor_to_image(image)

Ya que está funcionando, realice una optimización más larga:
import time
start = time.time()
epochs = 10
steps_per_epoch = 100
step = 0
for n in range(epochs):
for m in range(steps_per_epoch):
step += 1
train_step(image)
print(".", end='', flush=True)
display.clear_output(wait=True)
display.display(tensor_to_image(image))
print("Train step: {}".format(step))
end = time.time()
print("Total time: {:.1f}".format(end-start))

Train step: 1000 Total time: 21.3
Pérdida de variación total
Una desventaja de esta implementación básica es que produce muchos artefactos de alta frecuencia. Disminuya estos utilizando un término de regularización explícito en los componentes de alta frecuencia de la imagen. En la transferencia de estilo, esto a menudo se denomina pérdida de variación total :
def high_pass_x_y(image):
x_var = image[:, :, 1:, :] - image[:, :, :-1, :]
y_var = image[:, 1:, :, :] - image[:, :-1, :, :]
return x_var, y_var
x_deltas, y_deltas = high_pass_x_y(content_image)
plt.figure(figsize=(14, 10))
plt.subplot(2, 2, 1)
imshow(clip_0_1(2*y_deltas+0.5), "Horizontal Deltas: Original")
plt.subplot(2, 2, 2)
imshow(clip_0_1(2*x_deltas+0.5), "Vertical Deltas: Original")
x_deltas, y_deltas = high_pass_x_y(image)
plt.subplot(2, 2, 3)
imshow(clip_0_1(2*y_deltas+0.5), "Horizontal Deltas: Styled")
plt.subplot(2, 2, 4)
imshow(clip_0_1(2*x_deltas+0.5), "Vertical Deltas: Styled")
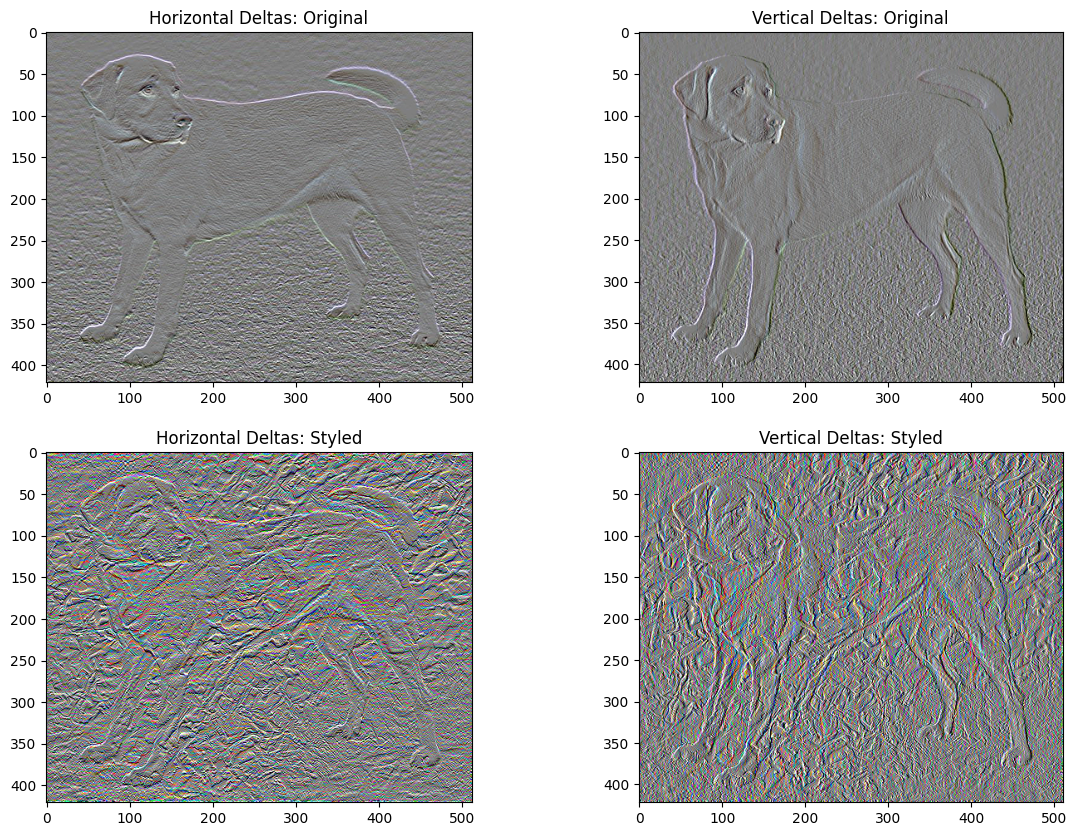
Esto muestra cómo han aumentado los componentes de alta frecuencia.
Además, este componente de alta frecuencia es básicamente un detector de bordes. Puede obtener un resultado similar del detector de bordes Sobel, por ejemplo:
plt.figure(figsize=(14, 10))
sobel = tf.image.sobel_edges(content_image)
plt.subplot(1, 2, 1)
imshow(clip_0_1(sobel[..., 0]/4+0.5), "Horizontal Sobel-edges")
plt.subplot(1, 2, 2)
imshow(clip_0_1(sobel[..., 1]/4+0.5), "Vertical Sobel-edges")
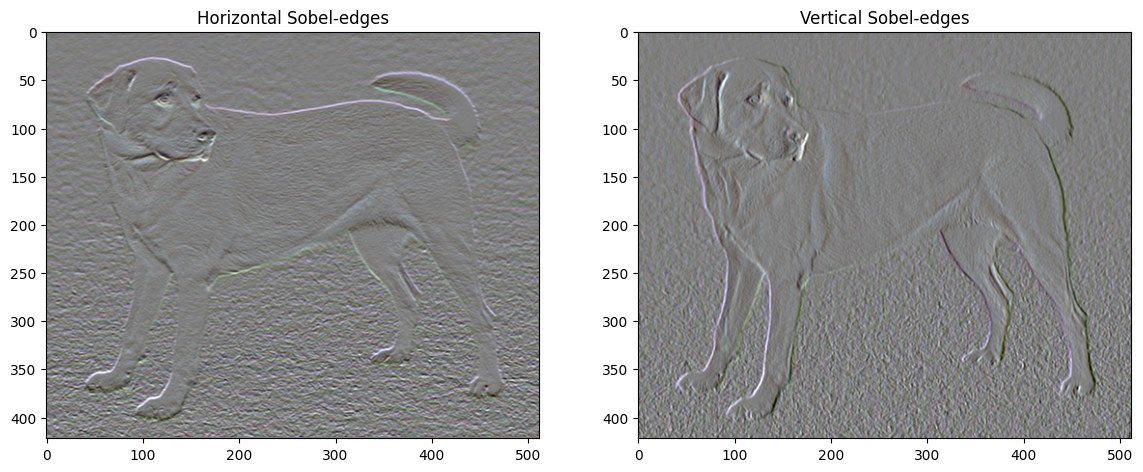
La pérdida de regularización asociada a esto es la suma de los cuadrados de los valores:
def total_variation_loss(image):
x_deltas, y_deltas = high_pass_x_y(image)
return tf.reduce_sum(tf.abs(x_deltas)) + tf.reduce_sum(tf.abs(y_deltas))
total_variation_loss(image).numpy()
149402.94
Eso demostró lo que hace. Pero no es necesario que lo implementes tú mismo, TensorFlow incluye una implementación estándar:
tf.image.total_variation(image).numpy()
array([149402.94], dtype=float32)
Vuelva a ejecutar la optimización
Elija un peso para total_variation_loss :
total_variation_weight=30
Ahora inclúyelo en la función train_step :
@tf.function()
def train_step(image):
with tf.GradientTape() as tape:
outputs = extractor(image)
loss = style_content_loss(outputs)
loss += total_variation_weight*tf.image.total_variation(image)
grad = tape.gradient(loss, image)
opt.apply_gradients([(grad, image)])
image.assign(clip_0_1(image))
Reinicialice la variable de optimización:
image = tf.Variable(content_image)
Y ejecuta la optimización:
import time
start = time.time()
epochs = 10
steps_per_epoch = 100
step = 0
for n in range(epochs):
for m in range(steps_per_epoch):
step += 1
train_step(image)
print(".", end='', flush=True)
display.clear_output(wait=True)
display.display(tensor_to_image(image))
print("Train step: {}".format(step))
end = time.time()
print("Total time: {:.1f}".format(end-start))

Train step: 1000 Total time: 22.4
Finalmente, guarde el resultado:
file_name = 'stylized-image.png'
tensor_to_image(image).save(file_name)
try:
from google.colab import files
except ImportError:
pass
else:
files.download(file_name)
Aprende más
Este tutorial demuestra el algoritmo de transferencia de estilo original. Para obtener una aplicación simple de transferencia de estilo, consulte este tutorial para obtener más información sobre cómo usar el modelo de transferencia de estilo de imagen arbitrario de TensorFlow Hub .