
 GitHub에서 소스 보기 GitHub에서 소스 보기 |
개요
이 노트북은 신경망과 TensorFlow Compression을 사용하여 손실 데이터 압축을 수행하는 방법을 보여줍니다.
손실 압축 시에는 샘플을 인코딩하는 데 필요한 예상 비트 수인 rate와 샘플 재구성에서 예상되는 오류인 왜곡 사이의 절충이 포함됩니다.
아래 예에서는 자동 인코더와 유사한 모델을 사용하여 MNIST 데이터세트의 이미지를 압축합니다. 이 방법은 End-to-end Optimized Image Compression 논문을 기초로 합니다.
학습된 데이터 압축에 대한 더 많은 배경 지식은 기존 데이터 압축에 익숙한 사람들을 대상으로 하는 이 백서 또는 머신 러닝에 관련된 사람들을 대상으로 하는 이 설문조사에서 찾을 수 있습니다.
설정
pip를 통해 Tensorflow Compression을 설치합니다.
# Installs the latest version of TFC compatible with the installed TF version.read MAJOR MINOR <<< "$(pip show tensorflow | perl -p -0777 -e 's/.*Version: (\d+)\.(\d+).*/\1 \2/sg')"pip install "tensorflow-compression<$MAJOR.$(($MINOR+1))"
라이브러리 종속성을 가져옵니다.
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow_compression as tfc
import tensorflow_datasets as tfds
2022-12-15 00:56:49.640329: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory 2022-12-15 00:56:49.640437: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory 2022-12-15 00:56:49.640448: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
트레이너 모델 정의하기
모델이 자동 인코더와 유사하고 훈련 및 추론 중에 다른 기능들을 수행해야 하기 때문에 설정은 예를 들어 분류자와 약간 다릅니다.
훈련 모델은 세 부분으로 구성됩니다.
- 분석(또는 인코더) 변환: 이미지에서 잠재 공간으로 변환
- 합성(또는 디코더) 변환: 잠재 공간에서 이미지 공간으로 다시 변환
- Prior 및 엔트로피 모델: 잠재 공간의 한계 확률 모델링
먼저 변환을 정의합니다.
def make_analysis_transform(latent_dims):
"""Creates the analysis (encoder) transform."""
return tf.keras.Sequential([
tf.keras.layers.Conv2D(
20, 5, use_bias=True, strides=2, padding="same",
activation="leaky_relu", name="conv_1"),
tf.keras.layers.Conv2D(
50, 5, use_bias=True, strides=2, padding="same",
activation="leaky_relu", name="conv_2"),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(
500, use_bias=True, activation="leaky_relu", name="fc_1"),
tf.keras.layers.Dense(
latent_dims, use_bias=True, activation=None, name="fc_2"),
], name="analysis_transform")
def make_synthesis_transform():
"""Creates the synthesis (decoder) transform."""
return tf.keras.Sequential([
tf.keras.layers.Dense(
500, use_bias=True, activation="leaky_relu", name="fc_1"),
tf.keras.layers.Dense(
2450, use_bias=True, activation="leaky_relu", name="fc_2"),
tf.keras.layers.Reshape((7, 7, 50)),
tf.keras.layers.Conv2DTranspose(
20, 5, use_bias=True, strides=2, padding="same",
activation="leaky_relu", name="conv_1"),
tf.keras.layers.Conv2DTranspose(
1, 5, use_bias=True, strides=2, padding="same",
activation="leaky_relu", name="conv_2"),
], name="synthesis_transform")
트레이너는 두 변환의 인스턴스와 이전의 매개변수를 모두 보유합니다.
call 메서드는 다음을 계산하도록 설정됩니다.
- 비율: 숫자 배치를 나타내는 데 필요한 비트 수에 대한 추정치
- 왜곡: 원래 숫자의 픽셀과 재구성된 픽셀 간의 평균 절대 차이
class MNISTCompressionTrainer(tf.keras.Model):
"""Model that trains a compressor/decompressor for MNIST."""
def __init__(self, latent_dims):
super().__init__()
self.analysis_transform = make_analysis_transform(latent_dims)
self.synthesis_transform = make_synthesis_transform()
self.prior_log_scales = tf.Variable(tf.zeros((latent_dims,)))
@property
def prior(self):
return tfc.NoisyLogistic(loc=0., scale=tf.exp(self.prior_log_scales))
def call(self, x, training):
"""Computes rate and distortion losses."""
# Ensure inputs are floats in the range (0, 1).
x = tf.cast(x, self.compute_dtype) / 255.
x = tf.reshape(x, (-1, 28, 28, 1))
# Compute latent space representation y, perturb it and model its entropy,
# then compute the reconstructed pixel-level representation x_hat.
y = self.analysis_transform(x)
entropy_model = tfc.ContinuousBatchedEntropyModel(
self.prior, coding_rank=1, compression=False)
y_tilde, rate = entropy_model(y, training=training)
x_tilde = self.synthesis_transform(y_tilde)
# Average number of bits per MNIST digit.
rate = tf.reduce_mean(rate)
# Mean absolute difference across pixels.
distortion = tf.reduce_mean(abs(x - x_tilde))
return dict(rate=rate, distortion=distortion)
비율과 왜곡 계산하기
훈련 세트의 이미지 하나를 사용하여 이를 단계별로 살펴보겠습니다. 훈련 및 검증을 위해 MNIST 데이터세트를 로드합니다.
training_dataset, validation_dataset = tfds.load(
"mnist",
split=["train", "test"],
shuffle_files=True,
as_supervised=True,
with_info=False,
)
그리고 하나의 이미지 \(x\)를 추출합니다.
(x, _), = validation_dataset.take(1)
plt.imshow(tf.squeeze(x))
print(f"Data type: {x.dtype}")
print(f"Shape: {x.shape}")
Data type: <dtype: 'uint8'> Shape: (28, 28, 1) 2022-12-15 00:56:56.118315: W tensorflow/core/kernels/data/cache_dataset_ops.cc:856] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
잠재 표현 \(y\)를 얻으려면 float32로 캐스팅하고 배치 차원을 추가하고 분석 변환을 통해 전달해야 합니다.
x = tf.cast(x, tf.float32) / 255.
x = tf.reshape(x, (-1, 28, 28, 1))
y = make_analysis_transform(10)(x)
print("y:", y)
y: tf.Tensor( [[ 0.01478431 0.02893603 0.00145823 -0.02982171 0.06799135 -0.03586794 -0.09307513 -0.04457759 -0.06205807 -0.01483396]], shape=(1, 10), dtype=float32)
잠재 공간은 테스트 시간에 양자화됩니다. 훈련 중에 이를 미분 가능한 방식으로 모델링하기 위해 \((-.5, .5)\) 구간에 균일한 노이즈를 추가하고 결과를 \(\tilde y\)라고 합니다. 이 용어는 End-to-end Optimized Image Compression 논문에서 사용된 것과 동일합니다.
y_tilde = y + tf.random.uniform(y.shape, -.5, .5)
print("y_tilde:", y_tilde)
y_tilde: tf.Tensor( [[ 0.4774041 -0.36119235 0.03928024 0.03078275 0.44684288 -0.15601778 -0.27414104 0.08969212 -0.4416189 -0.10535315]], shape=(1, 10), dtype=float32)
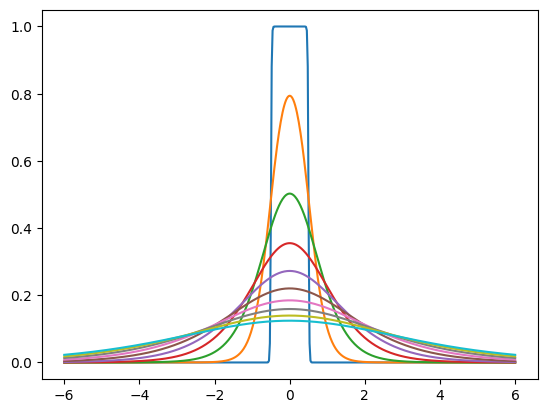
"Prior"는 노이즈가 많은 잠재 공간의 한계 분포를 모델링하기 위해 훈련하는 확률 밀도입니다. 예를 들어, 각 잠재 차원에 대해 다른 척도를 가진 독립적인 로지스틱 분포 세트일 수 있습니다. tfc.NoisyLogistic은 잠재 공간에 부가적인 노이즈가 있다는 사실을 설명합니다. 척도가 0에 가까워지면 로지스틱 분포가 dirac 델타(스파이크)에 접근하지만 추가된 노이즈로 인해 "노이즈가 많은" 분포가 대신 균일 분포에 접근합니다.
prior = tfc.NoisyLogistic(loc=0., scale=tf.linspace(.01, 2., 10))
_ = tf.linspace(-6., 6., 501)[:, None]
plt.plot(_, prior.prob(_));
훈련하는 동안 tfc.ContinuousBatchedEntropyModel은 균일한 노이즈를 추가하고 노이즈와 prior를 사용하여 비율(잠재 표현을 인코딩하는 데 필요한 평균 비트 수)에 대한 (미분 가능한) 상한을 계산합니다. 그 경계는 손실로 최소화할 수 있습니다.
entropy_model = tfc.ContinuousBatchedEntropyModel(
prior, coding_rank=1, compression=False)
y_tilde, rate = entropy_model(y, training=True)
print("rate:", rate)
print("y_tilde:", y_tilde)
rate: tf.Tensor([17.919106], shape=(1,), dtype=float32) y_tilde: tf.Tensor( [[-0.03474071 0.12052202 -0.09885961 -0.1385035 -0.04464987 -0.11050368 -0.03961596 0.23483062 -0.36167988 0.44339404]], shape=(1, 10), dtype=float32)
마지막으로, 노이즈가 많은 잠재 공간은 합성 변환을 통해 다시 전달되어 이미지 재구성 \(\tilde x\)를 생성합니다. 왜곡은 원본 이미지와 재구성 사이의 오차입니다. 훈련되지 않은 변환을 사용하면 재구성이 그다지 유용하지 않다는 것은 분명합니다.
x_tilde = make_synthesis_transform()(y_tilde)
# Mean absolute difference across pixels.
distortion = tf.reduce_mean(abs(x - x_tilde))
print("distortion:", distortion)
x_tilde = tf.saturate_cast(x_tilde[0] * 255, tf.uint8)
plt.imshow(tf.squeeze(x_tilde))
print(f"Data type: {x_tilde.dtype}")
print(f"Shape: {x_tilde.shape}")
distortion: tf.Tensor(0.17074007, shape=(), dtype=float32) Data type: <dtype: 'uint8'> Shape: (28, 28, 1)
모든 숫자 배치에 대해 MNISTCompressionTrainer를 호출하면 해당 배치에 대한 평균으로 비율과 왜곡이 생성됩니다.
(example_batch, _), = validation_dataset.batch(32).take(1)
trainer = MNISTCompressionTrainer(10)
example_output = trainer(example_batch)
print("rate: ", example_output["rate"])
print("distortion: ", example_output["distortion"])
2022-12-15 00:56:58.405038: W tensorflow/core/kernels/data/cache_dataset_ops.cc:856] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead. rate: tf.Tensor(20.296253, shape=(), dtype=float32) distortion: tf.Tensor(0.14659302, shape=(), dtype=float32)
다음 섹션에서는 이러한 두 손실에 대해 경사하강법을 수행하도록 모델을 설정합니다.
모델 훈련하기
비율-왜곡 Lagrangian, 즉 비율과 왜곡의 합을 최적화하는 방식으로 트레이너를 컴파일합니다. 여기서 한 가지 항은 Lagrange 매개변수 \(\lambda\)에 의해 가중됩니다.
이 손실 함수는 모델의 다른 부분에 다르게 영향을 줍니다.
- 분석 변환은 비율과 왜곡 사이의 원하는 절충을 실현하는 잠재 표현을 생성하도록 훈련됩니다.
- 합성 변환은 잠재적 표현이 주어지면 왜곡을 최소화하도록 훈련됩니다.
- Prior의 매개변수는 잠재 표현이 주어지면 비율을 최소화하도록 훈련됩니다. 이는 최대 가능성의 의미에서 잠재 공간의 한계 분포로 prior를 피팅하는 것과 동일합니다.
def pass_through_loss(_, x):
# Since rate and distortion are unsupervised, the loss doesn't need a target.
return x
def make_mnist_compression_trainer(lmbda, latent_dims=50):
trainer = MNISTCompressionTrainer(latent_dims)
trainer.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3),
# Just pass through rate and distortion as losses/metrics.
loss=dict(rate=pass_through_loss, distortion=pass_through_loss),
metrics=dict(rate=pass_through_loss, distortion=pass_through_loss),
loss_weights=dict(rate=1., distortion=lmbda),
)
return trainer
다음으로 모델을 훈련시킵니다. 사람의 주석은 여기에서 필요하지 않습니다. 우리는 단지 이미지를 압축하기를 원하기 때문에 map을 사용하여 이미지를 삭제하고 대신 비율과 왜곡에 대해 "더미" 타겟을 추가합니다.
def add_rd_targets(image, label):
# Training is unsupervised, so labels aren't necessary here. However, we
# need to add "dummy" targets for rate and distortion.
return image, dict(rate=0., distortion=0.)
def train_mnist_model(lmbda):
trainer = make_mnist_compression_trainer(lmbda)
trainer.fit(
training_dataset.map(add_rd_targets).batch(128).prefetch(8),
epochs=15,
validation_data=validation_dataset.map(add_rd_targets).batch(128).cache(),
validation_freq=1,
verbose=1,
)
return trainer
trainer = train_mnist_model(lmbda=2000)
Epoch 1/15 WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/autograph/pyct/static_analysis/liveness.py:83: Analyzer.lamba_check (from tensorflow.python.autograph.pyct.static_analysis.liveness) is deprecated and will be removed after 2023-09-23. Instructions for updating: Lambda fuctions will be no more assumed to be used in the statement where they are used, or at least in the same block. https://github.com/tensorflow/tensorflow/issues/56089 WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/autograph/pyct/static_analysis/liveness.py:83: Analyzer.lamba_check (from tensorflow.python.autograph.pyct.static_analysis.liveness) is deprecated and will be removed after 2023-09-23. Instructions for updating: Lambda fuctions will be no more assumed to be used in the statement where they are used, or at least in the same block. https://github.com/tensorflow/tensorflow/issues/56089 468/469 [============================>.] - ETA: 0s - loss: 219.3024 - distortion_loss: 0.0598 - rate_loss: 99.7866 - distortion_pass_through_loss: 0.0598 - rate_pass_through_loss: 99.7866 WARNING:absl:Computing quantization offsets using offset heuristic within a tf.function. Ideally, the offset heuristic should only be used to determine offsets once after training. Depending on the prior, estimating the offset might be computationally expensive. 469/469 [==============================] - 8s 8ms/step - loss: 219.2234 - distortion_loss: 0.0597 - rate_loss: 99.7729 - distortion_pass_through_loss: 0.0597 - rate_pass_through_loss: 99.7684 - val_loss: 178.1013 - val_distortion_loss: 0.0433 - val_rate_loss: 91.4364 - val_distortion_pass_through_loss: 0.0433 - val_rate_pass_through_loss: 91.4367 Epoch 2/15 469/469 [==============================] - 3s 6ms/step - loss: 166.7666 - distortion_loss: 0.0415 - rate_loss: 83.7638 - distortion_pass_through_loss: 0.0415 - rate_pass_through_loss: 83.7592 - val_loss: 158.0504 - val_distortion_loss: 0.0414 - val_rate_loss: 75.2229 - val_distortion_pass_through_loss: 0.0414 - val_rate_pass_through_loss: 75.2291 Epoch 3/15 469/469 [==============================] - 3s 6ms/step - loss: 151.4099 - distortion_loss: 0.0402 - rate_loss: 71.0500 - distortion_pass_through_loss: 0.0402 - rate_pass_through_loss: 71.0466 - val_loss: 145.2692 - val_distortion_loss: 0.0407 - val_rate_loss: 63.8706 - val_distortion_pass_through_loss: 0.0407 - val_rate_pass_through_loss: 63.8705 Epoch 4/15 469/469 [==============================] - 3s 6ms/step - loss: 142.8080 - distortion_loss: 0.0398 - rate_loss: 63.1513 - distortion_pass_through_loss: 0.0398 - rate_pass_through_loss: 63.1495 - val_loss: 137.0809 - val_distortion_loss: 0.0409 - val_rate_loss: 55.3460 - val_distortion_pass_through_loss: 0.0409 - val_rate_pass_through_loss: 55.3495 Epoch 5/15 469/469 [==============================] - 3s 6ms/step - loss: 137.2176 - distortion_loss: 0.0394 - rate_loss: 58.3984 - distortion_pass_through_loss: 0.0394 - rate_pass_through_loss: 58.3961 - val_loss: 131.5711 - val_distortion_loss: 0.0410 - val_rate_loss: 49.4951 - val_distortion_pass_through_loss: 0.0411 - val_rate_pass_through_loss: 49.4923 Epoch 6/15 469/469 [==============================] - 3s 6ms/step - loss: 133.3763 - distortion_loss: 0.0390 - rate_loss: 55.4508 - distortion_pass_through_loss: 0.0390 - rate_pass_through_loss: 55.4492 - val_loss: 127.2727 - val_distortion_loss: 0.0410 - val_rate_loss: 45.3366 - val_distortion_pass_through_loss: 0.0410 - val_rate_pass_through_loss: 45.3410 Epoch 7/15 469/469 [==============================] - 3s 6ms/step - loss: 130.5260 - distortion_loss: 0.0386 - rate_loss: 53.3047 - distortion_pass_through_loss: 0.0386 - rate_pass_through_loss: 53.3035 - val_loss: 124.2376 - val_distortion_loss: 0.0402 - val_rate_loss: 43.7708 - val_distortion_pass_through_loss: 0.0403 - val_rate_pass_through_loss: 43.7727 Epoch 8/15 469/469 [==============================] - 3s 6ms/step - loss: 127.9231 - distortion_loss: 0.0381 - rate_loss: 51.6259 - distortion_pass_through_loss: 0.0381 - rate_pass_through_loss: 51.6245 - val_loss: 121.2238 - val_distortion_loss: 0.0395 - val_rate_loss: 42.2377 - val_distortion_pass_through_loss: 0.0395 - val_rate_pass_through_loss: 42.2608 Epoch 9/15 469/469 [==============================] - 3s 6ms/step - loss: 125.7685 - distortion_loss: 0.0378 - rate_loss: 50.2331 - distortion_pass_through_loss: 0.0378 - rate_pass_through_loss: 50.2318 - val_loss: 118.5897 - val_distortion_loss: 0.0389 - val_rate_loss: 40.7310 - val_distortion_pass_through_loss: 0.0389 - val_rate_pass_through_loss: 40.7658 Epoch 10/15 469/469 [==============================] - 3s 6ms/step - loss: 123.4795 - distortion_loss: 0.0373 - rate_loss: 48.8856 - distortion_pass_through_loss: 0.0373 - rate_pass_through_loss: 48.8846 - val_loss: 117.2775 - val_distortion_loss: 0.0379 - val_rate_loss: 41.4386 - val_distortion_pass_through_loss: 0.0379 - val_rate_pass_through_loss: 41.4597 Epoch 11/15 469/469 [==============================] - 3s 6ms/step - loss: 121.5145 - distortion_loss: 0.0369 - rate_loss: 47.7324 - distortion_pass_through_loss: 0.0369 - rate_pass_through_loss: 47.7316 - val_loss: 115.6339 - val_distortion_loss: 0.0373 - val_rate_loss: 41.0963 - val_distortion_pass_through_loss: 0.0373 - val_rate_pass_through_loss: 41.0942 Epoch 12/15 469/469 [==============================] - 3s 6ms/step - loss: 119.6616 - distortion_loss: 0.0364 - rate_loss: 46.8124 - distortion_pass_through_loss: 0.0364 - rate_pass_through_loss: 46.8113 - val_loss: 114.3558 - val_distortion_loss: 0.0370 - val_rate_loss: 40.4141 - val_distortion_pass_through_loss: 0.0370 - val_rate_pass_through_loss: 40.4111 Epoch 13/15 469/469 [==============================] - 3s 6ms/step - loss: 118.2945 - distortion_loss: 0.0361 - rate_loss: 46.0180 - distortion_pass_through_loss: 0.0361 - rate_pass_through_loss: 46.0174 - val_loss: 113.9994 - val_distortion_loss: 0.0362 - val_rate_loss: 41.5707 - val_distortion_pass_through_loss: 0.0362 - val_rate_pass_through_loss: 41.5747 Epoch 14/15 469/469 [==============================] - 3s 6ms/step - loss: 117.0466 - distortion_loss: 0.0358 - rate_loss: 45.4409 - distortion_pass_through_loss: 0.0358 - rate_pass_through_loss: 45.4399 - val_loss: 114.7044 - val_distortion_loss: 0.0373 - val_rate_loss: 40.0477 - val_distortion_pass_through_loss: 0.0373 - val_rate_pass_through_loss: 40.0595 Epoch 15/15 469/469 [==============================] - 3s 6ms/step - loss: 115.9343 - distortion_loss: 0.0355 - rate_loss: 44.8576 - distortion_pass_through_loss: 0.0355 - rate_pass_through_loss: 44.8563 - val_loss: 112.2739 - val_distortion_loss: 0.0360 - val_rate_loss: 40.1838 - val_distortion_pass_through_loss: 0.0360 - val_rate_pass_through_loss: 40.2017
일부 MNIST 이미지 압축하기
테스트 시간에 압축 및 압축 해제를 위해 훈련된 모델을 두 부분으로 나눕니다.
- 인코더 쪽은 분석 변환과 엔트로피 모델로 구성됩니다.
- 디코더 쪽은 합성 변환과 동일한 엔트로피 모델로 구성됩니다.
테스트 시간에 잠재 공간에는 추가 노이즈가 없지만 양자화되고 손실 없이 압축되므로 새로운 이름을 지정합니다. 우리는 이것과 이미지 재구성을 각각 \(\hat x\) 및 \(\hat y\)라고 부릅니다(End-to-end Optimized Image Compression을 따름).
class MNISTCompressor(tf.keras.Model):
"""Compresses MNIST images to strings."""
def __init__(self, analysis_transform, entropy_model):
super().__init__()
self.analysis_transform = analysis_transform
self.entropy_model = entropy_model
def call(self, x):
# Ensure inputs are floats in the range (0, 1).
x = tf.cast(x, self.compute_dtype) / 255.
y = self.analysis_transform(x)
# Also return the exact information content of each digit.
_, bits = self.entropy_model(y, training=False)
return self.entropy_model.compress(y), bits
class MNISTDecompressor(tf.keras.Model):
"""Decompresses MNIST images from strings."""
def __init__(self, entropy_model, synthesis_transform):
super().__init__()
self.entropy_model = entropy_model
self.synthesis_transform = synthesis_transform
def call(self, string):
y_hat = self.entropy_model.decompress(string, ())
x_hat = self.synthesis_transform(y_hat)
# Scale and cast back to 8-bit integer.
return tf.saturate_cast(tf.round(x_hat * 255.), tf.uint8)
compression=True로 인스턴스화하면 엔트로피 모델은 훈련된 prior를 범위 코딩 알고리즘에 대한 테이블로 변환합니다. compress()를 호출할 때 이 알고리즘이 호출되어 잠재 공간 벡터를 비트 시퀀스로 변환합니다. 각 바이너리 문자열의 길이는 잠재 공간의 내용에 근사합니다(prior 아래 잠재 공간의 음의 로그 가능성).
범위 코딩 테이블이 양쪽에서 정확히 동일해야 하기 때문에 압축 및 압축 해제를 위한 엔트로피 모델은 동일한 인스턴스여야 합니다. 그렇지 않으면 디코딩 오류가 발생할 수 있습니다.
def make_mnist_codec(trainer, **kwargs):
# The entropy model must be created with `compression=True` and the same
# instance must be shared between compressor and decompressor.
entropy_model = tfc.ContinuousBatchedEntropyModel(
trainer.prior, coding_rank=1, compression=True, **kwargs)
compressor = MNISTCompressor(trainer.analysis_transform, entropy_model)
decompressor = MNISTDecompressor(entropy_model, trainer.synthesis_transform)
return compressor, decompressor
compressor, decompressor = make_mnist_codec(trainer)
검증 데이터세트에서 16개의 이미지를 가져옵니다. 인수를 skip으로 변경하여 다른 하위 집합을 선택할 수 있습니다.
(originals, _), = validation_dataset.batch(16).skip(3).take(1)
이를 문자열로 압축하고 각 내용을 비트 단위로 추적합니다.
strings, entropies = compressor(originals)
print(f"String representation of first digit in hexadecimal: 0x{strings[0].numpy().hex()}")
print(f"Number of bits actually needed to represent it: {entropies[0]:0.2f}")
String representation of first digit in hexadecimal: 0x995117110e Number of bits actually needed to represent it: 39.02
문자열에서 이미지를 다시 압축 해제합니다.
reconstructions = decompressor(strings)
압축된 바이너리 표현 및 재구성된 숫자와 함께 16개의 원래 숫자를 각각 표시합니다.
def display_digits(originals, strings, entropies, reconstructions):
"""Visualizes 16 digits together with their reconstructions."""
fig, axes = plt.subplots(4, 4, sharex=True, sharey=True, figsize=(12.5, 5))
axes = axes.ravel()
for i in range(len(axes)):
image = tf.concat([
tf.squeeze(originals[i]),
tf.zeros((28, 14), tf.uint8),
tf.squeeze(reconstructions[i]),
], 1)
axes[i].imshow(image)
axes[i].text(
.5, .5, f"→ 0x{strings[i].numpy().hex()} →\n{entropies[i]:0.2f} bits",
ha="center", va="top", color="white", fontsize="small",
transform=axes[i].transAxes)
axes[i].axis("off")
plt.subplots_adjust(wspace=0, hspace=0, left=0, right=1, bottom=0, top=1)
display_digits(originals, strings, entropies, reconstructions)

인코딩된 문자열의 길이는 각 숫자의 내용과 다릅니다.
이는 범위 코딩 프로세스가 이산 확률로 작동하고 약간의 오버헤드가 있기 때문입니다. 따라서 특히 짧은 문자열의 경우 해당 일치는 대략적인 것입니다. 그러나 범위 코딩은 점근적으로 최적입니다. 한도 내에서 예상 비트 수는 교차 엔트로피(예상되는 내용)에 접근하며, 이에 대한 훈련 모델의 비율 항은 상한입니다.
비율-왜곡 절충
위의 모델은 각 숫자를 나타내는 데 사용된 평균 비트 수와 재구성 시 발생한 오차 사이의 특정 절충(lmbda=2000으로 지정)을 찾도록 훈련되었습니다.
다른 값으로 실험을 반복하면 어떻게 될까요?
우선 \(\lambda\)를 500으로 줄여보겠습니다.
def train_and_visualize_model(lmbda):
trainer = train_mnist_model(lmbda=lmbda)
compressor, decompressor = make_mnist_codec(trainer)
strings, entropies = compressor(originals)
reconstructions = decompressor(strings)
display_digits(originals, strings, entropies, reconstructions)
train_and_visualize_model(lmbda=500)
Epoch 1/15 469/469 [==============================] - ETA: 0s - loss: 127.7211 - distortion_loss: 0.0703 - rate_loss: 92.5614 - distortion_pass_through_loss: 0.0703 - rate_pass_through_loss: 92.5550 WARNING:absl:Computing quantization offsets using offset heuristic within a tf.function. Ideally, the offset heuristic should only be used to determine offsets once after training. Depending on the prior, estimating the offset might be computationally expensive. 469/469 [==============================] - 7s 7ms/step - loss: 127.7211 - distortion_loss: 0.0703 - rate_loss: 92.5614 - distortion_pass_through_loss: 0.0703 - rate_pass_through_loss: 92.5550 - val_loss: 107.7169 - val_distortion_loss: 0.0554 - val_rate_loss: 80.0336 - val_distortion_pass_through_loss: 0.0554 - val_rate_pass_through_loss: 80.0346 Epoch 2/15 469/469 [==============================] - 3s 6ms/step - loss: 97.1141 - distortion_loss: 0.0536 - rate_loss: 70.3117 - distortion_pass_through_loss: 0.0536 - rate_pass_through_loss: 70.3063 - val_loss: 86.3358 - val_distortion_loss: 0.0605 - val_rate_loss: 56.0857 - val_distortion_pass_through_loss: 0.0605 - val_rate_pass_through_loss: 56.0972 Epoch 3/15 469/469 [==============================] - 3s 6ms/step - loss: 81.0667 - distortion_loss: 0.0557 - rate_loss: 53.1939 - distortion_pass_through_loss: 0.0557 - rate_pass_through_loss: 53.1902 - val_loss: 72.0267 - val_distortion_loss: 0.0695 - val_rate_loss: 37.2858 - val_distortion_pass_through_loss: 0.0695 - val_rate_pass_through_loss: 37.2948 Epoch 4/15 469/469 [==============================] - 3s 6ms/step - loss: 71.3676 - distortion_loss: 0.0588 - rate_loss: 41.9522 - distortion_pass_through_loss: 0.0588 - rate_pass_through_loss: 41.9493 - val_loss: 64.2627 - val_distortion_loss: 0.0808 - val_rate_loss: 23.8397 - val_distortion_pass_through_loss: 0.0808 - val_rate_pass_through_loss: 23.8458 Epoch 5/15 469/469 [==============================] - 3s 6ms/step - loss: 65.7319 - distortion_loss: 0.0616 - rate_loss: 34.9273 - distortion_pass_through_loss: 0.0616 - rate_pass_through_loss: 34.9259 - val_loss: 57.5249 - val_distortion_loss: 0.0785 - val_rate_loss: 18.2721 - val_distortion_pass_through_loss: 0.0785 - val_rate_pass_through_loss: 18.2881 Epoch 6/15 469/469 [==============================] - 3s 6ms/step - loss: 62.1928 - distortion_loss: 0.0637 - rate_loss: 30.3486 - distortion_pass_through_loss: 0.0637 - rate_pass_through_loss: 30.3475 - val_loss: 53.8765 - val_distortion_loss: 0.0793 - val_rate_loss: 14.2345 - val_distortion_pass_through_loss: 0.0793 - val_rate_pass_through_loss: 14.2380 Epoch 7/15 469/469 [==============================] - 3s 6ms/step - loss: 59.5825 - distortion_loss: 0.0649 - rate_loss: 27.1434 - distortion_pass_through_loss: 0.0649 - rate_pass_through_loss: 27.1427 - val_loss: 51.4462 - val_distortion_loss: 0.0776 - val_rate_loss: 12.6316 - val_distortion_pass_through_loss: 0.0777 - val_rate_pass_through_loss: 12.6328 Epoch 8/15 469/469 [==============================] - 3s 6ms/step - loss: 57.4954 - distortion_loss: 0.0655 - rate_loss: 24.7307 - distortion_pass_through_loss: 0.0655 - rate_pass_through_loss: 24.7294 - val_loss: 49.1382 - val_distortion_loss: 0.0735 - val_rate_loss: 12.3989 - val_distortion_pass_through_loss: 0.0735 - val_rate_pass_through_loss: 12.4138 Epoch 9/15 469/469 [==============================] - 3s 6ms/step - loss: 55.5513 - distortion_loss: 0.0655 - rate_loss: 22.7976 - distortion_pass_through_loss: 0.0655 - rate_pass_through_loss: 22.7965 - val_loss: 47.9578 - val_distortion_loss: 0.0704 - val_rate_loss: 12.7480 - val_distortion_pass_through_loss: 0.0704 - val_rate_pass_through_loss: 12.7566 Epoch 10/15 469/469 [==============================] - 3s 6ms/step - loss: 53.6906 - distortion_loss: 0.0647 - rate_loss: 21.3294 - distortion_pass_through_loss: 0.0647 - rate_pass_through_loss: 21.3287 - val_loss: 46.9613 - val_distortion_loss: 0.0666 - val_rate_loss: 13.6815 - val_distortion_pass_through_loss: 0.0665 - val_rate_pass_through_loss: 13.6938 Epoch 11/15 469/469 [==============================] - 3s 6ms/step - loss: 52.0359 - distortion_loss: 0.0638 - rate_loss: 20.1476 - distortion_pass_through_loss: 0.0638 - rate_pass_through_loss: 20.1471 - val_loss: 46.3577 - val_distortion_loss: 0.0655 - val_rate_loss: 13.6141 - val_distortion_pass_through_loss: 0.0655 - val_rate_pass_through_loss: 13.6147 Epoch 12/15 469/469 [==============================] - 3s 6ms/step - loss: 50.6146 - distortion_loss: 0.0628 - rate_loss: 19.2177 - distortion_pass_through_loss: 0.0628 - rate_pass_through_loss: 19.2173 - val_loss: 45.9381 - val_distortion_loss: 0.0633 - val_rate_loss: 14.3002 - val_distortion_pass_through_loss: 0.0633 - val_rate_pass_through_loss: 14.3018 Epoch 13/15 469/469 [==============================] - 3s 6ms/step - loss: 49.4504 - distortion_loss: 0.0618 - rate_loss: 18.5263 - distortion_pass_through_loss: 0.0618 - rate_pass_through_loss: 18.5258 - val_loss: 45.6526 - val_distortion_loss: 0.0617 - val_rate_loss: 14.7904 - val_distortion_pass_through_loss: 0.0617 - val_rate_pass_through_loss: 14.7903 Epoch 14/15 469/469 [==============================] - 3s 6ms/step - loss: 48.5549 - distortion_loss: 0.0612 - rate_loss: 17.9641 - distortion_pass_through_loss: 0.0612 - rate_pass_through_loss: 17.9640 - val_loss: 45.3351 - val_distortion_loss: 0.0591 - val_rate_loss: 15.8013 - val_distortion_pass_through_loss: 0.0591 - val_rate_pass_through_loss: 15.7989 Epoch 15/15 469/469 [==============================] - 3s 6ms/step - loss: 47.8094 - distortion_loss: 0.0605 - rate_loss: 17.5814 - distortion_pass_through_loss: 0.0605 - rate_pass_through_loss: 17.5813 - val_loss: 45.0795 - val_distortion_loss: 0.0596 - val_rate_loss: 15.2743 - val_distortion_pass_through_loss: 0.0596 - val_rate_pass_through_loss: 15.2709

숫자의 충실도와 마찬가지로 코드의 비트 전송률이 낮아집니다. 그러나 대부분의 숫자는 여전히 인식할 수 있습니다.
\(\lambda\)를 더 줄여보겠습니다.
train_and_visualize_model(lmbda=300)
Epoch 1/15 469/469 [==============================] - ETA: 0s - loss: 113.7527 - distortion_loss: 0.0757 - rate_loss: 91.0347 - distortion_pass_through_loss: 0.0757 - rate_pass_through_loss: 91.0279 WARNING:absl:Computing quantization offsets using offset heuristic within a tf.function. Ideally, the offset heuristic should only be used to determine offsets once after training. Depending on the prior, estimating the offset might be computationally expensive. 469/469 [==============================] - 6s 7ms/step - loss: 113.7527 - distortion_loss: 0.0757 - rate_loss: 91.0347 - distortion_pass_through_loss: 0.0757 - rate_pass_through_loss: 91.0279 - val_loss: 96.1912 - val_distortion_loss: 0.0658 - val_rate_loss: 76.4551 - val_distortion_pass_through_loss: 0.0658 - val_rate_pass_through_loss: 76.4576 Epoch 2/15 469/469 [==============================] - 3s 6ms/step - loss: 85.8713 - distortion_loss: 0.0613 - rate_loss: 67.4876 - distortion_pass_through_loss: 0.0613 - rate_pass_through_loss: 67.4821 - val_loss: 74.3407 - val_distortion_loss: 0.0784 - val_rate_loss: 50.8062 - val_distortion_pass_through_loss: 0.0785 - val_rate_pass_through_loss: 50.8093 Epoch 3/15 469/469 [==============================] - 3s 6ms/step - loss: 68.8692 - distortion_loss: 0.0648 - rate_loss: 49.4267 - distortion_pass_through_loss: 0.0648 - rate_pass_through_loss: 49.4226 - val_loss: 58.4936 - val_distortion_loss: 0.0902 - val_rate_loss: 31.4254 - val_distortion_pass_through_loss: 0.0902 - val_rate_pass_through_loss: 31.4267 Epoch 4/15 469/469 [==============================] - 3s 6ms/step - loss: 58.2612 - distortion_loss: 0.0693 - rate_loss: 37.4669 - distortion_pass_through_loss: 0.0693 - rate_pass_through_loss: 37.4643 - val_loss: 48.9512 - val_distortion_loss: 0.1030 - val_rate_loss: 18.0481 - val_distortion_pass_through_loss: 0.1030 - val_rate_pass_through_loss: 18.0520 Epoch 5/15 469/469 [==============================] - 3s 6ms/step - loss: 51.8885 - distortion_loss: 0.0734 - rate_loss: 29.8797 - distortion_pass_through_loss: 0.0734 - rate_pass_through_loss: 29.8780 - val_loss: 41.8500 - val_distortion_loss: 0.1007 - val_rate_loss: 11.6434 - val_distortion_pass_through_loss: 0.1007 - val_rate_pass_through_loss: 11.6437 Epoch 6/15 469/469 [==============================] - 3s 6ms/step - loss: 47.8944 - distortion_loss: 0.0766 - rate_loss: 24.9026 - distortion_pass_through_loss: 0.0766 - rate_pass_through_loss: 24.9017 - val_loss: 38.1315 - val_distortion_loss: 0.1013 - val_rate_loss: 7.7404 - val_distortion_pass_through_loss: 0.1013 - val_rate_pass_through_loss: 7.7467 Epoch 7/15 469/469 [==============================] - 3s 6ms/step - loss: 45.1956 - distortion_loss: 0.0794 - rate_loss: 21.3729 - distortion_pass_through_loss: 0.0794 - rate_pass_through_loss: 21.3719 - val_loss: 35.8302 - val_distortion_loss: 0.0988 - val_rate_loss: 6.2020 - val_distortion_pass_through_loss: 0.0988 - val_rate_pass_through_loss: 6.2014 Epoch 8/15 469/469 [==============================] - 3s 6ms/step - loss: 43.0160 - distortion_loss: 0.0812 - rate_loss: 18.6677 - distortion_pass_through_loss: 0.0812 - rate_pass_through_loss: 18.6669 - val_loss: 34.4190 - val_distortion_loss: 0.0960 - val_rate_loss: 5.6311 - val_distortion_pass_through_loss: 0.0960 - val_rate_pass_through_loss: 5.6288 Epoch 9/15 469/469 [==============================] - 3s 6ms/step - loss: 41.1234 - distortion_loss: 0.0819 - rate_loss: 16.5565 - distortion_pass_through_loss: 0.0819 - rate_pass_through_loss: 16.5562 - val_loss: 33.2192 - val_distortion_loss: 0.0895 - val_rate_loss: 6.3666 - val_distortion_pass_through_loss: 0.0896 - val_rate_pass_through_loss: 6.3628 Epoch 10/15 469/469 [==============================] - 3s 6ms/step - loss: 39.3408 - distortion_loss: 0.0814 - rate_loss: 14.9278 - distortion_pass_through_loss: 0.0814 - rate_pass_through_loss: 14.9273 - val_loss: 32.5666 - val_distortion_loss: 0.0858 - val_rate_loss: 6.8195 - val_distortion_pass_through_loss: 0.0859 - val_rate_pass_through_loss: 6.8124 Epoch 11/15 469/469 [==============================] - 3s 6ms/step - loss: 37.7915 - distortion_loss: 0.0800 - rate_loss: 13.7923 - distortion_pass_through_loss: 0.0800 - rate_pass_through_loss: 13.7921 - val_loss: 31.9921 - val_distortion_loss: 0.0813 - val_rate_loss: 7.5990 - val_distortion_pass_through_loss: 0.0814 - val_rate_pass_through_loss: 7.5925 Epoch 12/15 469/469 [==============================] - 3s 6ms/step - loss: 36.4893 - distortion_loss: 0.0785 - rate_loss: 12.9308 - distortion_pass_through_loss: 0.0785 - rate_pass_through_loss: 12.9303 - val_loss: 31.7597 - val_distortion_loss: 0.0793 - val_rate_loss: 7.9666 - val_distortion_pass_through_loss: 0.0794 - val_rate_pass_through_loss: 7.9654 Epoch 13/15 469/469 [==============================] - 3s 6ms/step - loss: 35.4507 - distortion_loss: 0.0773 - rate_loss: 12.2523 - distortion_pass_through_loss: 0.0773 - rate_pass_through_loss: 12.2522 - val_loss: 31.6973 - val_distortion_loss: 0.0770 - val_rate_loss: 8.5972 - val_distortion_pass_through_loss: 0.0770 - val_rate_pass_through_loss: 8.6022 Epoch 14/15 469/469 [==============================] - 3s 6ms/step - loss: 34.6540 - distortion_loss: 0.0765 - rate_loss: 11.7079 - distortion_pass_through_loss: 0.0765 - rate_pass_through_loss: 11.7075 - val_loss: 31.6539 - val_distortion_loss: 0.0787 - val_rate_loss: 8.0483 - val_distortion_pass_through_loss: 0.0787 - val_rate_pass_through_loss: 8.0458 Epoch 15/15 469/469 [==============================] - 3s 6ms/step - loss: 34.0230 - distortion_loss: 0.0759 - rate_loss: 11.2448 - distortion_pass_through_loss: 0.0759 - rate_pass_through_loss: 11.2444 - val_loss: 31.3993 - val_distortion_loss: 0.0767 - val_rate_loss: 8.3976 - val_distortion_pass_through_loss: 0.0767 - val_rate_pass_through_loss: 8.3964
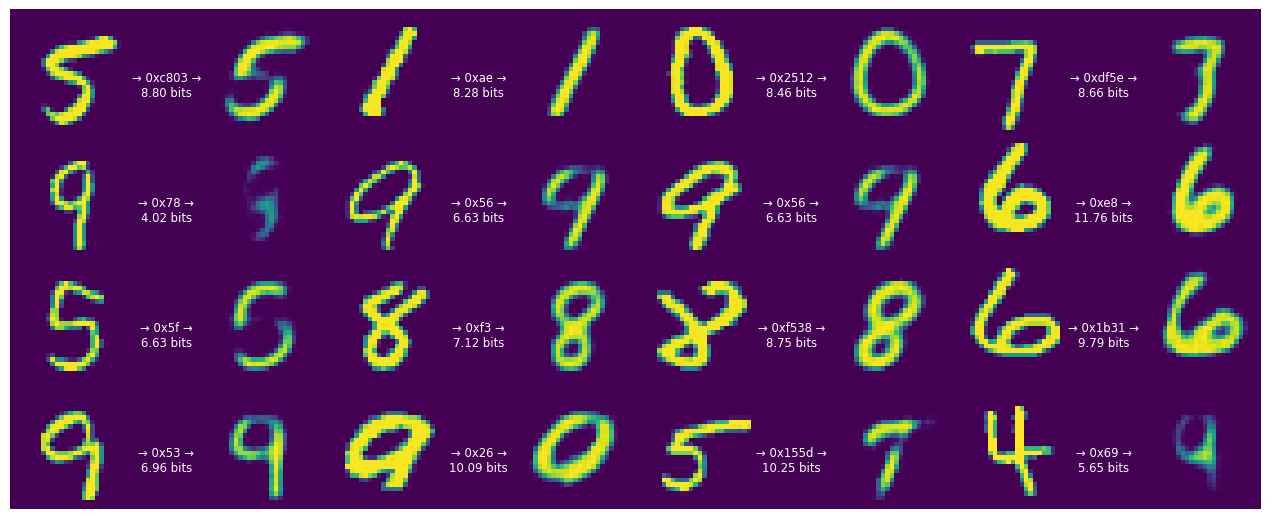
문자열은 이제 숫자당 1바이트 정도로 훨씬 짧아지기 시작합니다. 그러나 여기에는 대가가 따릅니다. 더 많은 숫자가 인식할 수 없게 됩니다.
이것은 이 모델이 오류에 대한 인간의 인식을 고려하지 않으며 픽셀 값의 관점에서 절대 편차만 측정한다는 것을 보여줍니다. 더 잘 인식되는 이미지 품질을 얻으려면 픽셀 손실을 인지 손실로 대체해야 합니다.
디코더를 생성 모델로 사용하기
디코더에 임의의 비트를 공급하면 모델이 숫자를 나타내도록 학습한 분포에서 효과적으로 샘플링됩니다.
먼저, 입력 문자열이 완전히 디코딩되지 않았는지 감지하는 온전성 검사 없이 압축기/압축 해제기를 다시 인스턴스화합니다.
compressor, decompressor = make_mnist_codec(trainer, decode_sanity_check=False)
이제 충분히 긴 임의의 문자열을 압축 해제기에 공급하여 숫자를 디코딩/샘플링할 수 있도록 합니다.
import os
strings = tf.constant([os.urandom(8) for _ in range(16)])
samples = decompressor(strings)
fig, axes = plt.subplots(4, 4, sharex=True, sharey=True, figsize=(5, 5))
axes = axes.ravel()
for i in range(len(axes)):
axes[i].imshow(tf.squeeze(samples[i]))
axes[i].axis("off")
plt.subplots_adjust(wspace=0, hspace=0, left=0, right=1, bottom=0, top=1)
