
| |
|
 GitHub でソースを表示 GitHub でソースを表示
|
|
概要
このノートブックでは、ニューラルネットワークと TensorFlow Compression を使って非可逆データ圧縮を行う方法を説明します。
非可逆圧縮には、レート、サンプルの安藤かに必要な期待されるビット数、およびサンプルの再構築における期待誤差を示すひずみ間のトレードオフが伴います。
以下の例では、オートエンコーダのようなモデルを使用して、MNIST データセットの画像を圧縮します。この手法は、『End-to-end Optimized Image Compression』という論文を基としています。
学習データの圧縮に関する背景情報については、古典的なデータ圧縮に精通した人を対象としたこちらの論文か、機械学習分野のユーザーを対象としたこちらの調査をご覧ください。
セットアップ
pip で Tensorflow Compression をインストールします。
# Installs the latest version of TFC compatible with the installed TF version.read MAJOR MINOR <<< "$(pip show tensorflow | perl -p -0777 -e 's/.*Version: (\d+)\.(\d+).*/\1 \2/sg')"pip install "tensorflow-compression<$MAJOR.$(($MINOR+1))"
ライブラリ依存関係をインポートします。
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow_compression as tfc
import tensorflow_datasets as tfds
2022-12-14 20:45:16.609619: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory 2022-12-14 20:45:16.609721: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory 2022-12-14 20:45:16.609732: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
トレーナーモデルを定義する
このモデルはオートエンコーダに似ているため、またトレーニングと推論中に異なる機能を実行する必要があるため、このセットアップは、たとえば分類器などとは少し異なります。
トレーニングモデルは、以下の 3 つで構成されています。
- 分析(またはエンコーダ)変換: 画像を潜在空間に変換します。
- 合成(またはデコーダ)変換: 潜在空間から画像空間に変換します。
- 事前確率とエントロピーモデル: 潜在空間の周辺分布をモデル化します。
まず、変換を定義します。
def make_analysis_transform(latent_dims):
"""Creates the analysis (encoder) transform."""
return tf.keras.Sequential([
tf.keras.layers.Conv2D(
20, 5, use_bias=True, strides=2, padding="same",
activation="leaky_relu", name="conv_1"),
tf.keras.layers.Conv2D(
50, 5, use_bias=True, strides=2, padding="same",
activation="leaky_relu", name="conv_2"),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(
500, use_bias=True, activation="leaky_relu", name="fc_1"),
tf.keras.layers.Dense(
latent_dims, use_bias=True, activation=None, name="fc_2"),
], name="analysis_transform")
def make_synthesis_transform():
"""Creates the synthesis (decoder) transform."""
return tf.keras.Sequential([
tf.keras.layers.Dense(
500, use_bias=True, activation="leaky_relu", name="fc_1"),
tf.keras.layers.Dense(
2450, use_bias=True, activation="leaky_relu", name="fc_2"),
tf.keras.layers.Reshape((7, 7, 50)),
tf.keras.layers.Conv2DTranspose(
20, 5, use_bias=True, strides=2, padding="same",
activation="leaky_relu", name="conv_1"),
tf.keras.layers.Conv2DTranspose(
1, 5, use_bias=True, strides=2, padding="same",
activation="leaky_relu", name="conv_2"),
], name="synthesis_transform")
トレーナーは、両方の変換のインスタンスと事前確率のパラメータを保有します。
その call メソッドは、以下を計算するようにセットアップされます。
- レート: 数字のバッチを表現するために必要なビット数の推定
- ひずみ: 元の数字と再構築された数字のピクセルの平均絶対差
class MNISTCompressionTrainer(tf.keras.Model):
"""Model that trains a compressor/decompressor for MNIST."""
def __init__(self, latent_dims):
super().__init__()
self.analysis_transform = make_analysis_transform(latent_dims)
self.synthesis_transform = make_synthesis_transform()
self.prior_log_scales = tf.Variable(tf.zeros((latent_dims,)))
@property
def prior(self):
return tfc.NoisyLogistic(loc=0., scale=tf.exp(self.prior_log_scales))
def call(self, x, training):
"""Computes rate and distortion losses."""
# Ensure inputs are floats in the range (0, 1).
x = tf.cast(x, self.compute_dtype) / 255.
x = tf.reshape(x, (-1, 28, 28, 1))
# Compute latent space representation y, perturb it and model its entropy,
# then compute the reconstructed pixel-level representation x_hat.
y = self.analysis_transform(x)
entropy_model = tfc.ContinuousBatchedEntropyModel(
self.prior, coding_rank=1, compression=False)
y_tilde, rate = entropy_model(y, training=training)
x_tilde = self.synthesis_transform(y_tilde)
# Average number of bits per MNIST digit.
rate = tf.reduce_mean(rate)
# Mean absolute difference across pixels.
distortion = tf.reduce_mean(abs(x - x_tilde))
return dict(rate=rate, distortion=distortion)
レートとひずみを計算する
では、トレーニングセットの画像を 1 つ使用して、順を追って説明します。トレーニングと検証用の MNIST データセットを読み込みます。
training_dataset, validation_dataset = tfds.load(
"mnist",
split=["train", "test"],
shuffle_files=True,
as_supervised=True,
with_info=False,
)
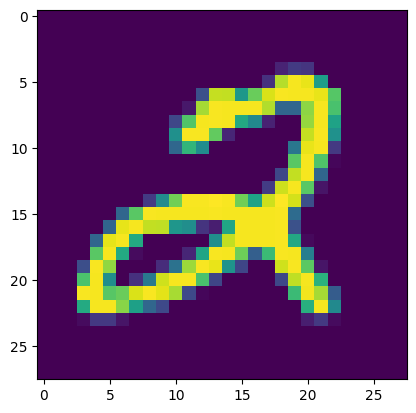
1 つの画像 \(x\) を抽出します。
(x, _), = validation_dataset.take(1)
plt.imshow(tf.squeeze(x))
print(f"Data type: {x.dtype}")
print(f"Shape: {x.shape}")
Data type: <dtype: 'uint8'> Shape: (28, 28, 1) 2022-12-14 20:45:23.216321: W tensorflow/core/kernels/data/cache_dataset_ops.cc:856] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
潜在の表現 \(y\) を取得するには、float32 にキャストして batch 次元を追加し、それを分析変換に通す必要があります。
x = tf.cast(x, tf.float32) / 255.
x = tf.reshape(x, (-1, 28, 28, 1))
y = make_analysis_transform(10)(x)
print("y:", y)
y: tf.Tensor( [[ 0.03988452 -0.02631121 -0.05344866 -0.04364791 0.06735273 -0.00989169 -0.05671643 -0.01362787 -0.0330795 -0.03137782]], shape=(1, 10), dtype=float32)
潜在は、テスト時に量子化されます。これをトレーニング中に区別可能な方法でモデル化するために、\((-.5, .5)\) の間隔で一様ノイズを追加し、その結果を \(\tilde y\) をとします。これは、『End-to-end Optimized Image Compression』論文で使用されているのと同じです。
y_tilde = y + tf.random.uniform(y.shape, -.5, .5)
print("y_tilde:", y_tilde)
y_tilde: tf.Tensor( [[-0.00847201 -0.19141883 0.01641406 -0.3539529 0.10089394 0.23102134 0.12243177 0.16727103 0.22074556 0.08011779]], shape=(1, 10), dtype=float32)
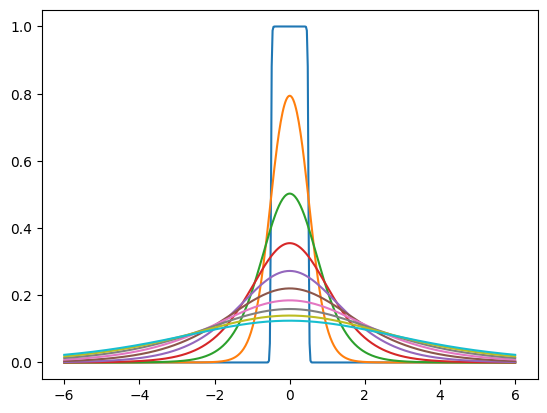
「事前確率」は、ノイズを含む潜在の周辺分布をモデル化するためにトレーニングする分布の密度です。たとえば、潜在次元ごとに異なるスケールを持つ独立した一連のロジスティック分布であることがあります。tfc.NoisyLogistic は、潜在には追加ノイズがあるという事実を考慮します。スケールがゼロに近づくにつれ、ロジスティック分布はディラックのデルタ(スパイク)に近づくものですが、追加ノイズにより、「ノイズの多い」分布は一様分布に近づきます。
prior = tfc.NoisyLogistic(loc=0., scale=tf.linspace(.01, 2., 10))
_ = tf.linspace(-6., 6., 501)[:, None]
plt.plot(_, prior.prob(_));
トレーニング中、tfc.ContinuousBatchedEntropyModel は一様ノイズを追加し、そのノイズと事前確率を使用して(区別可能な)レート(潜在表現をエンコードするために必要な平均ビット数)の上限を計算します。この上限は、損失として最小化できます。
entropy_model = tfc.ContinuousBatchedEntropyModel(
prior, coding_rank=1, compression=False)
y_tilde, rate = entropy_model(y, training=True)
print("rate:", rate)
print("y_tilde:", y_tilde)
rate: tf.Tensor([18.430876], shape=(1,), dtype=float32) y_tilde: tf.Tensor( [[ 0.00818415 0.4172811 -0.05954609 0.3539252 -0.02196757 0.2851495 -0.00319849 -0.15237509 -0.46015334 0.07735881]], shape=(1, 10), dtype=float32)
最後に、ノイズのある潜在が合成変換を通過し、画像の再構築 \(\tilde x\) が生成されます。明らかに、変換はトレーニングされていないため、この再構築にはあまり利用価値がありません。
x_tilde = make_synthesis_transform()(y_tilde)
# Mean absolute difference across pixels.
distortion = tf.reduce_mean(abs(x - x_tilde))
print("distortion:", distortion)
x_tilde = tf.saturate_cast(x_tilde[0] * 255, tf.uint8)
plt.imshow(tf.squeeze(x_tilde))
print(f"Data type: {x_tilde.dtype}")
print(f"Shape: {x_tilde.shape}")
distortion: tf.Tensor(0.17073585, shape=(), dtype=float32) Data type: <dtype: 'uint8'> Shape: (28, 28, 1)
数字のバッチごとに MNISTCompressionTrainer を呼び出すと、レートとそのバッチの平均としてのひずみが生成されます。
(example_batch, _), = validation_dataset.batch(32).take(1)
trainer = MNISTCompressionTrainer(10)
example_output = trainer(example_batch)
print("rate: ", example_output["rate"])
print("distortion: ", example_output["distortion"])
rate: tf.Tensor(20.296253, shape=(), dtype=float32) distortion: tf.Tensor(0.14659302, shape=(), dtype=float32) 2022-12-14 20:45:25.322149: W tensorflow/core/kernels/data/cache_dataset_ops.cc:856] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
次のセクションでは、これらの 2 つの損失で勾配降下を行うようにモデルをセットアップします。
モデルをトレーニングする
レートとひずみのラグアンジアン、つまりレートとひずみの和を最適化するようにトレーナーをコンパイルします。ここで、いずれかの項はラグランジュ関数パラメータ \(\lambda\) で重み付けされます。
この損失関数は、モデルのさまざまな箇所に異なる影響を与えます。
- 分析変換は、レートとひずみの目的のトレードオフを達成する潜在表現を生成するようにトレーニングされます。
- 合成変換は、特定の潜在表現でひずみを最小化するようにトレーニングされます。
- 事前確率のパラメータは、特定の潜在表現でレートを最小化するようにトレーニングされます。これは、事前確率を最大尤度において潜在の周辺分布に適合するのと同じです。
def pass_through_loss(_, x):
# Since rate and distortion are unsupervised, the loss doesn't need a target.
return x
def make_mnist_compression_trainer(lmbda, latent_dims=50):
trainer = MNISTCompressionTrainer(latent_dims)
trainer.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3),
# Just pass through rate and distortion as losses/metrics.
loss=dict(rate=pass_through_loss, distortion=pass_through_loss),
metrics=dict(rate=pass_through_loss, distortion=pass_through_loss),
loss_weights=dict(rate=1., distortion=lmbda),
)
return trainer
次に、モデルをトレーニングします。ここでは、画像を圧縮するだけであるため、人間による注釈付けは必要ありません。そのため、map を使って注釈を削除し、レートとひずみの「ダミー」ターゲットを追加します。
def add_rd_targets(image, label):
# Training is unsupervised, so labels aren't necessary here. However, we
# need to add "dummy" targets for rate and distortion.
return image, dict(rate=0., distortion=0.)
def train_mnist_model(lmbda):
trainer = make_mnist_compression_trainer(lmbda)
trainer.fit(
training_dataset.map(add_rd_targets).batch(128).prefetch(8),
epochs=15,
validation_data=validation_dataset.map(add_rd_targets).batch(128).cache(),
validation_freq=1,
verbose=1,
)
return trainer
trainer = train_mnist_model(lmbda=2000)
Epoch 1/15 WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/autograph/pyct/static_analysis/liveness.py:83: Analyzer.lamba_check (from tensorflow.python.autograph.pyct.static_analysis.liveness) is deprecated and will be removed after 2023-09-23. Instructions for updating: Lambda fuctions will be no more assumed to be used in the statement where they are used, or at least in the same block. https://github.com/tensorflow/tensorflow/issues/56089 WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/autograph/pyct/static_analysis/liveness.py:83: Analyzer.lamba_check (from tensorflow.python.autograph.pyct.static_analysis.liveness) is deprecated and will be removed after 2023-09-23. Instructions for updating: Lambda fuctions will be no more assumed to be used in the statement where they are used, or at least in the same block. https://github.com/tensorflow/tensorflow/issues/56089 467/469 [============================>.] - ETA: 0s - loss: 217.8335 - distortion_loss: 0.0589 - rate_loss: 100.0286 - distortion_pass_through_loss: 0.0589 - rate_pass_through_loss: 100.0286 WARNING:absl:Computing quantization offsets using offset heuristic within a tf.function. Ideally, the offset heuristic should only be used to determine offsets once after training. Depending on the prior, estimating the offset might be computationally expensive. 469/469 [==============================] - 8s 8ms/step - loss: 217.6788 - distortion_loss: 0.0588 - rate_loss: 99.9971 - distortion_pass_through_loss: 0.0588 - rate_pass_through_loss: 99.9924 - val_loss: 178.6942 - val_distortion_loss: 0.0434 - val_rate_loss: 91.9543 - val_distortion_pass_through_loss: 0.0434 - val_rate_pass_through_loss: 91.9594 Epoch 2/15 469/469 [==============================] - 3s 6ms/step - loss: 166.7406 - distortion_loss: 0.0415 - rate_loss: 83.8010 - distortion_pass_through_loss: 0.0415 - rate_pass_through_loss: 83.7965 - val_loss: 157.1429 - val_distortion_loss: 0.0409 - val_rate_loss: 75.3245 - val_distortion_pass_through_loss: 0.0409 - val_rate_pass_through_loss: 75.3312 Epoch 3/15 469/469 [==============================] - 3s 6ms/step - loss: 151.3889 - distortion_loss: 0.0402 - rate_loss: 70.9442 - distortion_pass_through_loss: 0.0402 - rate_pass_through_loss: 70.9411 - val_loss: 144.4897 - val_distortion_loss: 0.0403 - val_rate_loss: 63.9764 - val_distortion_pass_through_loss: 0.0402 - val_rate_pass_through_loss: 63.9807 Epoch 4/15 469/469 [==============================] - 3s 6ms/step - loss: 142.9433 - distortion_loss: 0.0400 - rate_loss: 63.0224 - distortion_pass_through_loss: 0.0400 - rate_pass_through_loss: 63.0202 - val_loss: 137.4160 - val_distortion_loss: 0.0411 - val_rate_loss: 55.3039 - val_distortion_pass_through_loss: 0.0411 - val_rate_pass_through_loss: 55.2885 Epoch 5/15 469/469 [==============================] - 3s 6ms/step - loss: 137.3771 - distortion_loss: 0.0395 - rate_loss: 58.3224 - distortion_pass_through_loss: 0.0395 - rate_pass_through_loss: 58.3205 - val_loss: 132.2905 - val_distortion_loss: 0.0417 - val_rate_loss: 48.9274 - val_distortion_pass_through_loss: 0.0417 - val_rate_pass_through_loss: 48.9382 Epoch 6/15 469/469 [==============================] - 3s 6ms/step - loss: 133.5226 - distortion_loss: 0.0391 - rate_loss: 55.3185 - distortion_pass_through_loss: 0.0391 - rate_pass_through_loss: 55.3175 - val_loss: 127.0724 - val_distortion_loss: 0.0404 - val_rate_loss: 46.3232 - val_distortion_pass_through_loss: 0.0404 - val_rate_pass_through_loss: 46.3234 Epoch 7/15 469/469 [==============================] - 3s 6ms/step - loss: 130.3693 - distortion_loss: 0.0386 - rate_loss: 53.1581 - distortion_pass_through_loss: 0.0386 - rate_pass_through_loss: 53.1566 - val_loss: 123.5252 - val_distortion_loss: 0.0403 - val_rate_loss: 42.8875 - val_distortion_pass_through_loss: 0.0403 - val_rate_pass_through_loss: 42.8826 Epoch 8/15 469/469 [==============================] - 3s 6ms/step - loss: 128.0058 - distortion_loss: 0.0383 - rate_loss: 51.4280 - distortion_pass_through_loss: 0.0383 - rate_pass_through_loss: 51.4268 - val_loss: 121.3483 - val_distortion_loss: 0.0400 - val_rate_loss: 41.3487 - val_distortion_pass_through_loss: 0.0400 - val_rate_pass_through_loss: 41.3539 Epoch 9/15 469/469 [==============================] - 3s 6ms/step - loss: 125.6857 - distortion_loss: 0.0379 - rate_loss: 49.9369 - distortion_pass_through_loss: 0.0379 - rate_pass_through_loss: 49.9354 - val_loss: 119.4494 - val_distortion_loss: 0.0398 - val_rate_loss: 39.8691 - val_distortion_pass_through_loss: 0.0398 - val_rate_pass_through_loss: 39.8512 Epoch 10/15 469/469 [==============================] - 3s 6ms/step - loss: 123.4883 - distortion_loss: 0.0375 - rate_loss: 48.5796 - distortion_pass_through_loss: 0.0375 - rate_pass_through_loss: 48.5789 - val_loss: 118.5806 - val_distortion_loss: 0.0391 - val_rate_loss: 40.3094 - val_distortion_pass_through_loss: 0.0392 - val_rate_pass_through_loss: 40.3033 Epoch 11/15 469/469 [==============================] - 3s 6ms/step - loss: 121.5731 - distortion_loss: 0.0371 - rate_loss: 47.4418 - distortion_pass_through_loss: 0.0371 - rate_pass_through_loss: 47.4408 - val_loss: 115.8420 - val_distortion_loss: 0.0380 - val_rate_loss: 39.9038 - val_distortion_pass_through_loss: 0.0380 - val_rate_pass_through_loss: 39.8994 Epoch 12/15 469/469 [==============================] - 3s 6ms/step - loss: 119.7753 - distortion_loss: 0.0367 - rate_loss: 46.3968 - distortion_pass_through_loss: 0.0367 - rate_pass_through_loss: 46.3957 - val_loss: 114.8861 - val_distortion_loss: 0.0373 - val_rate_loss: 40.2797 - val_distortion_pass_through_loss: 0.0373 - val_rate_pass_through_loss: 40.2883 Epoch 13/15 469/469 [==============================] - 3s 6ms/step - loss: 118.1635 - distortion_loss: 0.0363 - rate_loss: 45.5972 - distortion_pass_through_loss: 0.0363 - rate_pass_through_loss: 45.5967 - val_loss: 114.0300 - val_distortion_loss: 0.0367 - val_rate_loss: 40.5612 - val_distortion_pass_through_loss: 0.0367 - val_rate_pass_through_loss: 40.5718 Epoch 14/15 469/469 [==============================] - 3s 6ms/step - loss: 116.8593 - distortion_loss: 0.0360 - rate_loss: 44.9107 - distortion_pass_through_loss: 0.0360 - rate_pass_through_loss: 44.9097 - val_loss: 112.6166 - val_distortion_loss: 0.0363 - val_rate_loss: 40.0470 - val_distortion_pass_through_loss: 0.0363 - val_rate_pass_through_loss: 40.0628 Epoch 15/15 469/469 [==============================] - 3s 6ms/step - loss: 115.6814 - distortion_loss: 0.0356 - rate_loss: 44.4095 - distortion_pass_through_loss: 0.0356 - rate_pass_through_loss: 44.4091 - val_loss: 112.2964 - val_distortion_loss: 0.0360 - val_rate_loss: 40.3579 - val_distortion_pass_through_loss: 0.0360 - val_rate_pass_through_loss: 40.3735
MNIST 画像を圧縮する
テスト時の圧縮と解凍用に、トレーニング済みのモデルを以下の 2 つに分割します。
- エンコーダ側には、分析変換とエントロピーモデルが含まれます。
- デコーダ側には、合成変換と同じエントロピーモデルが含まれます。
テスト時には、潜在に追加ノイズが含まれませんが、量子化されてから非可逆的に圧縮されるため、それらに新しい名前を指定します。それらと再構築の \(\hat x\) と \(\hat y\) をそれぞれに呼び出します(『End-to-end Optimized Image Compression』に従います)。
class MNISTCompressor(tf.keras.Model):
"""Compresses MNIST images to strings."""
def __init__(self, analysis_transform, entropy_model):
super().__init__()
self.analysis_transform = analysis_transform
self.entropy_model = entropy_model
def call(self, x):
# Ensure inputs are floats in the range (0, 1).
x = tf.cast(x, self.compute_dtype) / 255.
y = self.analysis_transform(x)
# Also return the exact information content of each digit.
_, bits = self.entropy_model(y, training=False)
return self.entropy_model.compress(y), bits
class MNISTDecompressor(tf.keras.Model):
"""Decompresses MNIST images from strings."""
def __init__(self, entropy_model, synthesis_transform):
super().__init__()
self.entropy_model = entropy_model
self.synthesis_transform = synthesis_transform
def call(self, string):
y_hat = self.entropy_model.decompress(string, ())
x_hat = self.synthesis_transform(y_hat)
# Scale and cast back to 8-bit integer.
return tf.saturate_cast(tf.round(x_hat * 255.), tf.uint8)
compression=True でインスタンス化すると、エントロピーモデルは、学習した事前確率をレンジコーディングアルゴリズムのテーブルに変換します。compress() を呼び出すと、このアルゴリズムが呼び出され、潜在空間ベクトルをビットシーケンスに変換します。各バイナリ文字列の長さは、潜在の情報コンテンツに近似します(事前確率の下の潜在の負の対数尤度)。
圧縮と解凍のエントロピーモデルは、同じインスタンスである必要があります。これは、レンジコーディングテーブルが両側でまったく同じである必要があるためです。そうでない場合、解凍エラーが発生します。
def make_mnist_codec(trainer, **kwargs):
# The entropy model must be created with `compression=True` and the same
# instance must be shared between compressor and decompressor.
entropy_model = tfc.ContinuousBatchedEntropyModel(
trainer.prior, coding_rank=1, compression=True, **kwargs)
compressor = MNISTCompressor(trainer.analysis_transform, entropy_model)
decompressor = MNISTDecompressor(entropy_model, trainer.synthesis_transform)
return compressor, decompressor
compressor, decompressor = make_mnist_codec(trainer)
検証データセットから 16 個の画像を取得します。skip の引数を変えることで、さまざまなサブセットを選択できます。
(originals, _), = validation_dataset.batch(16).skip(3).take(1)
これらを文字列に圧縮し、それぞれの情報コンテンツをビットで追跡します。
strings, entropies = compressor(originals)
print(f"String representation of first digit in hexadecimal: 0x{strings[0].numpy().hex()}")
print(f"Number of bits actually needed to represent it: {entropies[0]:0.2f}")
String representation of first digit in hexadecimal: 0x39c3f87dec58 Number of bits actually needed to represent it: 44.04
画像を文字列から解凍します。
reconstructions = decompressor(strings)
各 16 個の元の数字を圧縮されたバイナリ表現と再構築された数字と共に表示します。
def display_digits(originals, strings, entropies, reconstructions):
"""Visualizes 16 digits together with their reconstructions."""
fig, axes = plt.subplots(4, 4, sharex=True, sharey=True, figsize=(12.5, 5))
axes = axes.ravel()
for i in range(len(axes)):
image = tf.concat([
tf.squeeze(originals[i]),
tf.zeros((28, 14), tf.uint8),
tf.squeeze(reconstructions[i]),
], 1)
axes[i].imshow(image)
axes[i].text(
.5, .5, f"→ 0x{strings[i].numpy().hex()} →\n{entropies[i]:0.2f} bits",
ha="center", va="top", color="white", fontsize="small",
transform=axes[i].transAxes)
axes[i].axis("off")
plt.subplots_adjust(wspace=0, hspace=0, left=0, right=1, bottom=0, top=1)
display_digits(originals, strings, entropies, reconstructions)

エンコードされた文字列の長さが各数字の情報コンテンツと異なることに注目してください。
これは、レンジコーディングプロセスが離散確率を使用し、少量のオーバーヘッドがあるためです。そのため、特に短い文字列の場合、対応するものは近似でしかありません。ただし、レンジコーディングは漸近的に最適です。限界では、予想されるビット数は、トレーニングモデルのレート項が上限であるクロスエントロピー(予想される情報コンテンツ)に近づきます。
レートとひずみのトレードオフ
上記では、モデルは、各数字を表現するために使用されるビットの平均数と再構築で発生した誤差の間の特定のトレードオフのためにトレーニングされました(lmbda=2000 で指定)。
異なる値でこの実験を繰り返した場合はどうなるでしょうか?
まずは、\(\lambda\) を 500 に減らしてみましょう。
def train_and_visualize_model(lmbda):
trainer = train_mnist_model(lmbda=lmbda)
compressor, decompressor = make_mnist_codec(trainer)
strings, entropies = compressor(originals)
reconstructions = decompressor(strings)
display_digits(originals, strings, entropies, reconstructions)
train_and_visualize_model(lmbda=500)
Epoch 1/15 465/469 [============================>.] - ETA: 0s - loss: 127.4447 - distortion_loss: 0.0695 - rate_loss: 92.6941 - distortion_pass_through_loss: 0.0695 - rate_pass_through_loss: 92.6941 WARNING:absl:Computing quantization offsets using offset heuristic within a tf.function. Ideally, the offset heuristic should only be used to determine offsets once after training. Depending on the prior, estimating the offset might be computationally expensive. 469/469 [==============================] - 6s 6ms/step - loss: 127.2831 - distortion_loss: 0.0694 - rate_loss: 92.5993 - distortion_pass_through_loss: 0.0694 - rate_pass_through_loss: 92.5930 - val_loss: 107.4028 - val_distortion_loss: 0.0549 - val_rate_loss: 79.9750 - val_distortion_pass_through_loss: 0.0549 - val_rate_pass_through_loss: 79.9802 Epoch 2/15 469/469 [==============================] - 3s 6ms/step - loss: 97.1724 - distortion_loss: 0.0538 - rate_loss: 70.2783 - distortion_pass_through_loss: 0.0538 - rate_pass_through_loss: 70.2729 - val_loss: 86.0219 - val_distortion_loss: 0.0594 - val_rate_loss: 56.3162 - val_distortion_pass_through_loss: 0.0594 - val_rate_pass_through_loss: 56.3187 Epoch 3/15 469/469 [==============================] - 3s 6ms/step - loss: 81.1227 - distortion_loss: 0.0560 - rate_loss: 53.1034 - distortion_pass_through_loss: 0.0560 - rate_pass_through_loss: 53.0995 - val_loss: 71.9202 - val_distortion_loss: 0.0686 - val_rate_loss: 37.5965 - val_distortion_pass_through_loss: 0.0687 - val_rate_pass_through_loss: 37.5954 Epoch 4/15 469/469 [==============================] - 3s 6ms/step - loss: 71.5995 - distortion_loss: 0.0595 - rate_loss: 41.8626 - distortion_pass_through_loss: 0.0595 - rate_pass_through_loss: 41.8596 - val_loss: 64.1463 - val_distortion_loss: 0.0786 - val_rate_loss: 24.8592 - val_distortion_pass_through_loss: 0.0786 - val_rate_pass_through_loss: 24.8602 Epoch 5/15 469/469 [==============================] - 3s 6ms/step - loss: 66.1026 - distortion_loss: 0.0624 - rate_loss: 34.8940 - distortion_pass_through_loss: 0.0624 - rate_pass_through_loss: 34.8927 - val_loss: 58.4913 - val_distortion_loss: 0.0795 - val_rate_loss: 18.7568 - val_distortion_pass_through_loss: 0.0795 - val_rate_pass_through_loss: 18.7560 Epoch 6/15 469/469 [==============================] - 3s 6ms/step - loss: 62.6672 - distortion_loss: 0.0646 - rate_loss: 30.3623 - distortion_pass_through_loss: 0.0646 - rate_pass_through_loss: 30.3613 - val_loss: 54.9740 - val_distortion_loss: 0.0818 - val_rate_loss: 14.0641 - val_distortion_pass_through_loss: 0.0818 - val_rate_pass_through_loss: 14.0646 Epoch 7/15 469/469 [==============================] - 3s 6ms/step - loss: 60.1863 - distortion_loss: 0.0660 - rate_loss: 27.2017 - distortion_pass_through_loss: 0.0660 - rate_pass_through_loss: 27.2010 - val_loss: 52.4609 - val_distortion_loss: 0.0806 - val_rate_loss: 12.1524 - val_distortion_pass_through_loss: 0.0806 - val_rate_pass_through_loss: 12.1531 Epoch 8/15 469/469 [==============================] - 3s 6ms/step - loss: 58.0571 - distortion_loss: 0.0665 - rate_loss: 24.8082 - distortion_pass_through_loss: 0.0665 - rate_pass_through_loss: 24.8073 - val_loss: 49.9638 - val_distortion_loss: 0.0771 - val_rate_loss: 11.4078 - val_distortion_pass_through_loss: 0.0771 - val_rate_pass_through_loss: 11.4103 Epoch 9/15 469/469 [==============================] - 3s 6ms/step - loss: 56.1462 - distortion_loss: 0.0665 - rate_loss: 22.8890 - distortion_pass_through_loss: 0.0665 - rate_pass_through_loss: 22.8888 - val_loss: 48.1192 - val_distortion_loss: 0.0704 - val_rate_loss: 12.9410 - val_distortion_pass_through_loss: 0.0704 - val_rate_pass_through_loss: 12.9476 Epoch 10/15 469/469 [==============================] - 3s 6ms/step - loss: 54.1863 - distortion_loss: 0.0657 - rate_loss: 21.3211 - distortion_pass_through_loss: 0.0657 - rate_pass_through_loss: 21.3206 - val_loss: 47.0492 - val_distortion_loss: 0.0674 - val_rate_loss: 13.3331 - val_distortion_pass_through_loss: 0.0674 - val_rate_pass_through_loss: 13.3350 Epoch 11/15 469/469 [==============================] - 3s 6ms/step - loss: 52.4151 - distortion_loss: 0.0647 - rate_loss: 20.0704 - distortion_pass_through_loss: 0.0647 - rate_pass_through_loss: 20.0700 - val_loss: 46.5608 - val_distortion_loss: 0.0665 - val_rate_loss: 13.2897 - val_distortion_pass_through_loss: 0.0665 - val_rate_pass_through_loss: 13.2926 Epoch 12/15 469/469 [==============================] - 3s 6ms/step - loss: 50.9138 - distortion_loss: 0.0636 - rate_loss: 19.1121 - distortion_pass_through_loss: 0.0636 - rate_pass_through_loss: 19.1114 - val_loss: 45.9211 - val_distortion_loss: 0.0645 - val_rate_loss: 13.6699 - val_distortion_pass_through_loss: 0.0645 - val_rate_pass_through_loss: 13.6701 Epoch 13/15 469/469 [==============================] - 3s 6ms/step - loss: 49.7118 - distortion_loss: 0.0626 - rate_loss: 18.4105 - distortion_pass_through_loss: 0.0626 - rate_pass_through_loss: 18.4100 - val_loss: 45.6058 - val_distortion_loss: 0.0628 - val_rate_loss: 14.1970 - val_distortion_pass_through_loss: 0.0628 - val_rate_pass_through_loss: 14.1988 Epoch 14/15 469/469 [==============================] - 3s 6ms/step - loss: 48.7698 - distortion_loss: 0.0617 - rate_loss: 17.9120 - distortion_pass_through_loss: 0.0617 - rate_pass_through_loss: 17.9119 - val_loss: 45.1903 - val_distortion_loss: 0.0612 - val_rate_loss: 14.5991 - val_distortion_pass_through_loss: 0.0612 - val_rate_pass_through_loss: 14.6004 Epoch 15/15 469/469 [==============================] - 3s 6ms/step - loss: 48.0780 - distortion_loss: 0.0611 - rate_loss: 17.5208 - distortion_pass_through_loss: 0.0611 - rate_pass_through_loss: 17.5206 - val_loss: 45.0955 - val_distortion_loss: 0.0615 - val_rate_loss: 14.3562 - val_distortion_pass_through_loss: 0.0615 - val_rate_pass_through_loss: 14.3626

コードのビットレートが下がり、数字の信頼性も下がります。ただし、ほとんどの数字は認識可能のままです。
さらに \(\lambda\) を減らしてみましょう。
train_and_visualize_model(lmbda=300)
Epoch 1/15 466/469 [============================>.] - ETA: 0s - loss: 113.7090 - distortion_loss: 0.0753 - rate_loss: 91.1310 - distortion_pass_through_loss: 0.0753 - rate_pass_through_loss: 91.1310 WARNING:absl:Computing quantization offsets using offset heuristic within a tf.function. Ideally, the offset heuristic should only be used to determine offsets once after training. Depending on the prior, estimating the offset might be computationally expensive. 469/469 [==============================] - 6s 6ms/step - loss: 113.6090 - distortion_loss: 0.0752 - rate_loss: 91.0583 - distortion_pass_through_loss: 0.0752 - rate_pass_through_loss: 91.0516 - val_loss: 96.5233 - val_distortion_loss: 0.0679 - val_rate_loss: 76.1659 - val_distortion_pass_through_loss: 0.0679 - val_rate_pass_through_loss: 76.1617 Epoch 2/15 469/469 [==============================] - 3s 6ms/step - loss: 85.8572 - distortion_loss: 0.0613 - rate_loss: 67.4572 - distortion_pass_through_loss: 0.0613 - rate_pass_through_loss: 67.4516 - val_loss: 74.5242 - val_distortion_loss: 0.0793 - val_rate_loss: 50.7241 - val_distortion_pass_through_loss: 0.0793 - val_rate_pass_through_loss: 50.7321 Epoch 3/15 469/469 [==============================] - 3s 6ms/step - loss: 68.9031 - distortion_loss: 0.0650 - rate_loss: 49.4174 - distortion_pass_through_loss: 0.0650 - rate_pass_through_loss: 49.4135 - val_loss: 59.5138 - val_distortion_loss: 0.0954 - val_rate_loss: 30.8864 - val_distortion_pass_through_loss: 0.0954 - val_rate_pass_through_loss: 30.8949 Epoch 4/15 469/469 [==============================] - 3s 6ms/step - loss: 58.3479 - distortion_loss: 0.0696 - rate_loss: 37.4610 - distortion_pass_through_loss: 0.0696 - rate_pass_through_loss: 37.4585 - val_loss: 49.3487 - val_distortion_loss: 0.1029 - val_rate_loss: 18.4801 - val_distortion_pass_through_loss: 0.1028 - val_rate_pass_through_loss: 18.4910 Epoch 5/15 469/469 [==============================] - 3s 6ms/step - loss: 52.0953 - distortion_loss: 0.0740 - rate_loss: 29.8993 - distortion_pass_through_loss: 0.0740 - rate_pass_through_loss: 29.8978 - val_loss: 42.9612 - val_distortion_loss: 0.1054 - val_rate_loss: 11.3369 - val_distortion_pass_through_loss: 0.1054 - val_rate_pass_through_loss: 11.3445 Epoch 6/15 469/469 [==============================] - 3s 6ms/step - loss: 48.1743 - distortion_loss: 0.0775 - rate_loss: 24.9172 - distortion_pass_through_loss: 0.0775 - rate_pass_through_loss: 24.9160 - val_loss: 38.8429 - val_distortion_loss: 0.1035 - val_rate_loss: 7.7809 - val_distortion_pass_through_loss: 0.1035 - val_rate_pass_through_loss: 7.7837 Epoch 7/15 469/469 [==============================] - 3s 6ms/step - loss: 45.4033 - distortion_loss: 0.0800 - rate_loss: 21.4013 - distortion_pass_through_loss: 0.0800 - rate_pass_through_loss: 21.4004 - val_loss: 36.4476 - val_distortion_loss: 0.1025 - val_rate_loss: 5.7000 - val_distortion_pass_through_loss: 0.1025 - val_rate_pass_through_loss: 5.7030 Epoch 8/15 469/469 [==============================] - 3s 6ms/step - loss: 43.1902 - distortion_loss: 0.0815 - rate_loss: 18.7450 - distortion_pass_through_loss: 0.0815 - rate_pass_through_loss: 18.7442 - val_loss: 34.4560 - val_distortion_loss: 0.0938 - val_rate_loss: 6.3266 - val_distortion_pass_through_loss: 0.0938 - val_rate_pass_through_loss: 6.3243 Epoch 9/15 469/469 [==============================] - 3s 6ms/step - loss: 41.1994 - distortion_loss: 0.0816 - rate_loss: 16.7293 - distortion_pass_through_loss: 0.0816 - rate_pass_through_loss: 16.7284 - val_loss: 33.6424 - val_distortion_loss: 0.0906 - val_rate_loss: 6.4604 - val_distortion_pass_through_loss: 0.0906 - val_rate_pass_through_loss: 6.4591 Epoch 10/15 469/469 [==============================] - 3s 6ms/step - loss: 39.5689 - distortion_loss: 0.0811 - rate_loss: 15.2472 - distortion_pass_through_loss: 0.0811 - rate_pass_through_loss: 15.2467 - val_loss: 32.8275 - val_distortion_loss: 0.0851 - val_rate_loss: 7.3065 - val_distortion_pass_through_loss: 0.0851 - val_rate_pass_through_loss: 7.3087 Epoch 11/15 469/469 [==============================] - 3s 6ms/step - loss: 38.1226 - distortion_loss: 0.0800 - rate_loss: 14.1267 - distortion_pass_through_loss: 0.0800 - rate_pass_through_loss: 14.1260 - val_loss: 32.5285 - val_distortion_loss: 0.0841 - val_rate_loss: 7.2859 - val_distortion_pass_through_loss: 0.0841 - val_rate_pass_through_loss: 7.2903 Epoch 12/15 469/469 [==============================] - 3s 6ms/step - loss: 36.8895 - distortion_loss: 0.0786 - rate_loss: 13.3042 - distortion_pass_through_loss: 0.0786 - rate_pass_through_loss: 13.3038 - val_loss: 32.3595 - val_distortion_loss: 0.0830 - val_rate_loss: 7.4672 - val_distortion_pass_through_loss: 0.0830 - val_rate_pass_through_loss: 7.4686 Epoch 13/15 469/469 [==============================] - 3s 6ms/step - loss: 35.9890 - distortion_loss: 0.0778 - rate_loss: 12.6432 - distortion_pass_through_loss: 0.0778 - rate_pass_through_loss: 12.6427 - val_loss: 32.1735 - val_distortion_loss: 0.0807 - val_rate_loss: 7.9718 - val_distortion_pass_through_loss: 0.0807 - val_rate_pass_through_loss: 7.9728 Epoch 14/15 469/469 [==============================] - 3s 6ms/step - loss: 35.2725 - distortion_loss: 0.0771 - rate_loss: 12.1506 - distortion_pass_through_loss: 0.0771 - rate_pass_through_loss: 12.1504 - val_loss: 31.8718 - val_distortion_loss: 0.0777 - val_rate_loss: 8.5510 - val_distortion_pass_through_loss: 0.0778 - val_rate_pass_through_loss: 8.5569 Epoch 15/15 469/469 [==============================] - 3s 6ms/step - loss: 34.6280 - distortion_loss: 0.0764 - rate_loss: 11.6954 - distortion_pass_through_loss: 0.0764 - rate_pass_through_loss: 11.6957 - val_loss: 31.8556 - val_distortion_loss: 0.0772 - val_rate_loss: 8.7024 - val_distortion_pass_through_loss: 0.0772 - val_rate_pass_through_loss: 8.7201
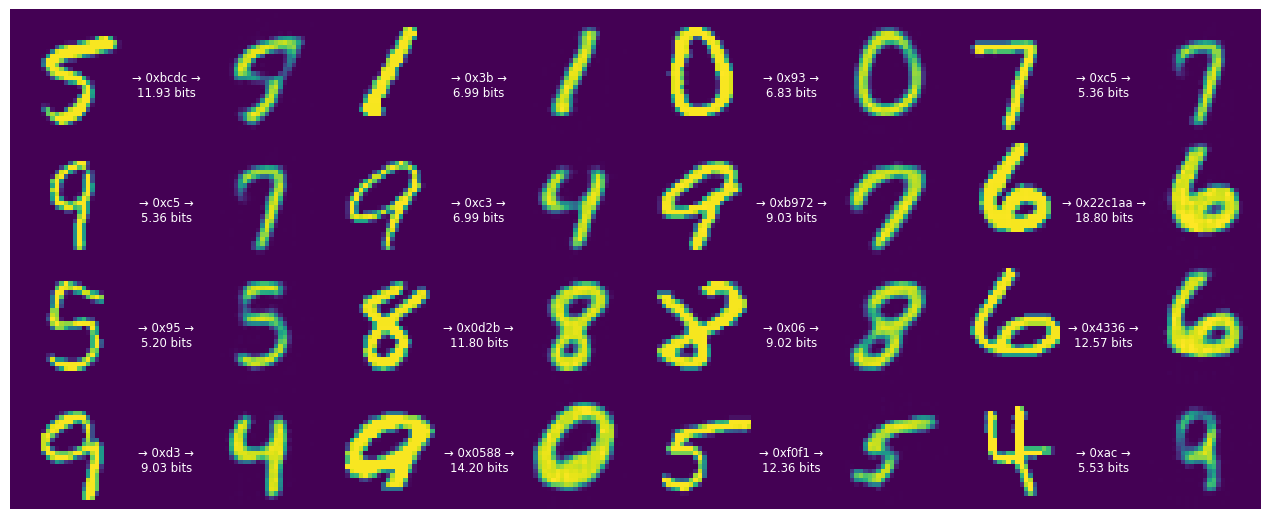
数字当たり 1 バイトの順に、文字列がさらに短くなり始めました。ただし、これにはコストが伴い、さらに多くの数字が認識できなくなってしまいました。
これは、このモデルが人間による誤差の認識に左右されず、ピクセル値の観点で絶対偏差を測定していることを示します。画像の品質をさらに高めるには、ピクセル損失を知覚損失に置き換える必要があります。
デコーダーを生成モデルとして使用する
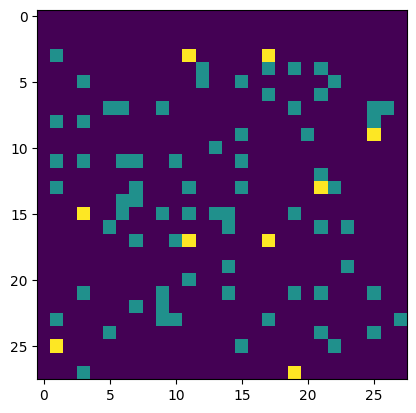
デコーダーにランダムなビットを供給すると、これは、モデルが数字を表すことを学習した分布から効果的にサンプリングされます。
まず、入力文字列が完全にデコードされていないかどうかを検出するサニティチェックを行わずに、コンプレッサー/デコンプレッサーを再インスタンス化します。
compressor, decompressor = make_mnist_codec(trainer, decode_sanity_check=False)
次に、十分な長さのランダムな文字列をデコンプレッサに入力して、それらから数字をデコード/サンプリングできるようにします。
import os
strings = tf.constant([os.urandom(8) for _ in range(16)])
samples = decompressor(strings)
fig, axes = plt.subplots(4, 4, sharex=True, sharey=True, figsize=(5, 5))
axes = axes.ravel()
for i in range(len(axes)):
axes[i].imshow(tf.squeeze(samples[i]))
axes[i].axis("off")
plt.subplots_adjust(wspace=0, hspace=0, left=0, right=1, bottom=0, top=1)
