GitHub에서 소스 보기 GitHub에서 소스 보기 |
경고: Estimator는 새 코드에 권장되지 않습니다. Estimator는
v1.Session스타일 코드를 실행하며, 이 코드는 올바르게 작성하기가 좀 더 어렵고 특히 TF 2 코드와 결합할 경우 예기치 않게 작동할 수 있습니다. Estimator는 호환성 보장이 적용되지만 보안 취약점 외에는 수정 사항이 제공되지 않습니다. 자세한 내용은 마이그레이션 가이드를 참조하세요.
개요
참고: Keras 로지스틱 회귀 예제를 사용할 수 있으며 이 튜토리얼보다 권장됩니다.
설정
pip install sklearnimport os
import sys
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from IPython.display import clear_output
from six.moves import urllib
타이타닉 데이터셋을 불러오기
타이타닉 데이터셋을 사용할 것입니다. 성별, 나이, 클래스, 기타 등 주어진 정보를 활용하여 승객이 살아남을 것인지 예측하는 것을 목표로 합니다.
import tensorflow.compat.v2.feature_column as fc
import tensorflow as tf
2022-12-14 22:33:29.380734: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory 2022-12-14 22:33:29.380865: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory 2022-12-14 22:33:29.380876: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
# Load dataset.
dftrain = pd.read_csv('https://storage.googleapis.com/tf-datasets/titanic/train.csv')
dfeval = pd.read_csv('https://storage.googleapis.com/tf-datasets/titanic/eval.csv')
y_train = dftrain.pop('survived')
y_eval = dfeval.pop('survived')
데이터 탐험하기
데이터셋은 다음의 특성을 가집니다
dftrain.head()
dftrain.describe()
훈련셋은 627개의 샘플로 평가셋은 264개의 샘플로 구성되어 있습니다.
dftrain.shape[0], dfeval.shape[0]
(627, 264)
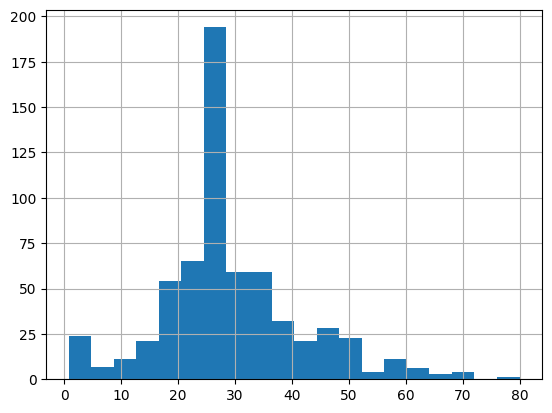
대부분의 승객은 20대와 30대 입니다.
dftrain.age.hist(bins=20)
<AxesSubplot: >
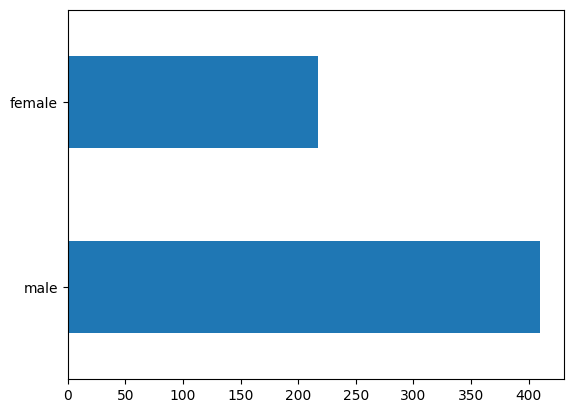
남자 승객이 여자 승객보다 대략 2배 많습니다.
dftrain.sex.value_counts().plot(kind='barh')
<AxesSubplot: >
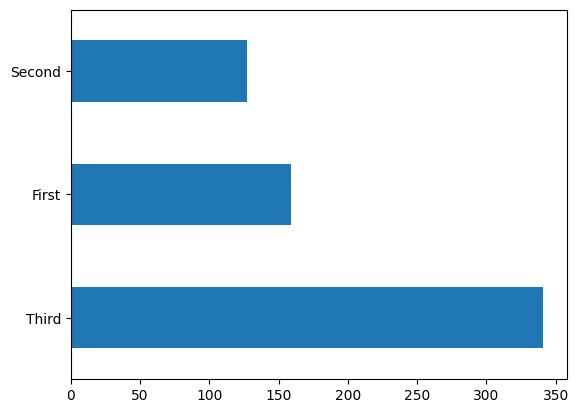
대부분의 승객은 "삼등석" 입니다.
dftrain['class'].value_counts().plot(kind='barh')
<AxesSubplot: >
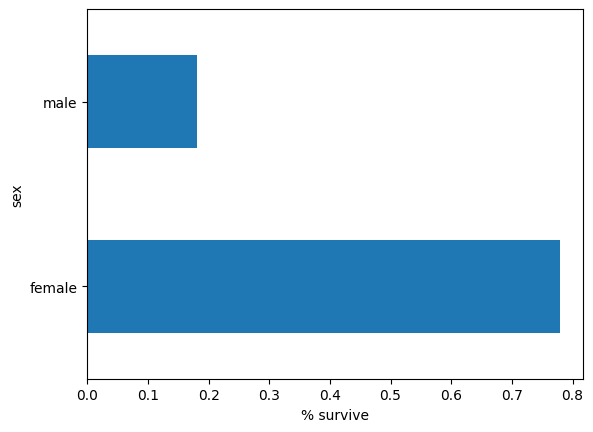
여자는 남자보다 살아남을 확률이 훨씬 높습니다. 이는 명확하게 모델에 유용한 특성입니다.
pd.concat([dftrain, y_train], axis=1).groupby('sex').survived.mean().plot(kind='barh').set_xlabel('% survive')
Text(0.5, 0, '% survive')
모델의 특성 엔지니어링
경고: 이 튜토리얼에 설명된
tf.feature_columns모듈은 새 코드에는 권장되지 않습니다. Keras 전처리 레이어에서 이 기능을 다룹니다. 마이그레이션 지침은 마이그레이션 특성 열 가이드를 참조하세요.tf.feature_columns모듈은 TF1Estimators와 함께 사용하도록 설계되었습니다. 이는 우리의 호환성 보장 대상에 해당하지만 보안 취약점 외에는 수정 사항이 제공되지 않습니다.
추정기는 특성 열이라는 시스템을 사용하여 모델이 각 원시 입력 특성을 해석하는 방식을 설명합니다. 추정기는 숫자 입력의 벡터를 예상하고 특성 열은 모델이 각 특성을 변환하는 방식을 설명합니다.
효과적인 모델 학습에서는 적절한 특성 열을 고르고 다듬는 것이 키포인트 입니다. 하나의 특성 열은 특성 딕셔너리(dict)의 원본 입력으로 만들어진 열(기본 특성 열)이거나 하나 이상의 기본 열(얻어진 특성 열)에 정의된 변환을 이용하여 새로 생성된 열입니다.
선형 추정기는 수치형, 범주형 특성을 모두 사용할 수 있습니다. 특성 열은 모든 텐서플로 추정기와 함께 작동하고 목적은 모델링에 사용되는 특성들을 정의하는 것입니다. 또한 원-핫-인코딩(one-hot-encoding), 정규화(normalization), 버킷화(bucketization)와 같은 특성 공학 방법을 지원합니다.
기본 특성 열
CATEGORICAL_COLUMNS = ['sex', 'n_siblings_spouses', 'parch', 'class', 'deck',
'embark_town', 'alone']
NUMERIC_COLUMNS = ['age', 'fare']
feature_columns = []
for feature_name in CATEGORICAL_COLUMNS:
vocabulary = dftrain[feature_name].unique()
feature_columns.append(tf.feature_column.categorical_column_with_vocabulary_list(feature_name, vocabulary))
for feature_name in NUMERIC_COLUMNS:
feature_columns.append(tf.feature_column.numeric_column(feature_name, dtype=tf.float32))
input_function은 입력 파이프라인을 스트리밍으로 공급하는 tf.data.Dataset으로 데이터를 변환하는 방법을 명시합니다. tf.data.Dataset은 데이터 프레임, CSV 형식 파일 등과 같은 여러 소스를 사용합니다.
def make_input_fn(data_df, label_df, num_epochs=10, shuffle=True, batch_size=32):
def input_function():
ds = tf.data.Dataset.from_tensor_slices((dict(data_df), label_df))
if shuffle:
ds = ds.shuffle(1000)
ds = ds.batch(batch_size).repeat(num_epochs)
return ds
return input_function
train_input_fn = make_input_fn(dftrain, y_train)
eval_input_fn = make_input_fn(dfeval, y_eval, num_epochs=1, shuffle=False)
다음과 같이 데이터셋을 점검할 수 있습니다:
ds = make_input_fn(dftrain, y_train, batch_size=10)()
for feature_batch, label_batch in ds.take(1):
print('Some feature keys:', list(feature_batch.keys()))
print()
print('A batch of class:', feature_batch['class'].numpy())
print()
print('A batch of Labels:', label_batch.numpy())
Some feature keys: ['sex', 'age', 'n_siblings_spouses', 'parch', 'fare', 'class', 'deck', 'embark_town', 'alone'] A batch of class: [b'Third' b'Third' b'First' b'Third' b'Third' b'Third' b'First' b'Third' b'Second' b'First'] A batch of Labels: [0 0 1 0 1 0 0 0 1 1]
또한 tf.keras.layers.DenseFeatures 층을 사용하여 특정한 특성 열의 결과를 점검할 수 있습니다:
age_column = feature_columns[7]
tf.keras.layers.DenseFeatures([age_column])(feature_batch).numpy()
array([[29.],
[51.],
[28.],
[30.],
[ 4.],
[ 4.],
[31.],
[30.],
[21.],
[58.]], dtype=float32)
DenseFeatures는 조밀한(dense) 텐서만 허용합니다. 범주형 데이터를 점검하려면 우선 범주형 열에 indicator_column 함수를 적용해야 합니다:
gender_column = feature_columns[0]
tf.keras.layers.DenseFeatures([tf.feature_column.indicator_column(gender_column)])(feature_batch).numpy()
array([[0., 1.],
[1., 0.],
[1., 0.],
[1., 0.],
[0., 1.],
[1., 0.],
[1., 0.],
[1., 0.],
[0., 1.],
[0., 1.]], dtype=float32)
모든 기본 특성을 모델에 추가한 다음에 모델을 훈련해 봅시다. 모델을 훈련하려면 tf.estimator API를 이용한 메서드 호출 한번이면 충분합니다:
linear_est = tf.estimator.LinearClassifier(feature_columns=feature_columns)
linear_est.train(train_input_fn)
result = linear_est.evaluate(eval_input_fn)
clear_output()
print(result)
{'accuracy': 0.7462121, 'accuracy_baseline': 0.625, 'auc': 0.8314049, 'auc_precision_recall': 0.7929586, 'average_loss': 0.4918203, 'label/mean': 0.375, 'loss': 0.48571348, 'precision': 0.64285713, 'prediction/mean': 0.4394845, 'recall': 0.72727275, 'global_step': 200}
도출된 특성 열
이제 정확도 75%에 도달했습니다. 별도로 각 기본 특성 열을 사용하면 데이터를 설명하기에는 충분치 않을 수 있습니다. 예를 들면, 성별과 레이블간의 상관관계는 성별에 따라 다를 수 있습니다. 따라서 gender="Male"과 'gender="Female"의 단일 모델가중치만 배우면 모든 나이-성별 조합(이를테면gender="Male" 그리고 'age="30"그리고gender="Male"그리고age="40"`을 구별하는 것)을 포함시킬 수 없습니다.
서로 다른 특성 조합들 간의 차이를 학습하기 위해서 모델에 교차 특성 열을 추가할 수 있습니다(또한 교차 열 이전에 나이 열을 버킷화할 수 있습니다):
age_x_gender = tf.feature_column.crossed_column(['age', 'sex'], hash_bucket_size=100)
조합 특성을 모델에 추가하고 모델을 다시 훈련합니다:
derived_feature_columns = [age_x_gender]
linear_est = tf.estimator.LinearClassifier(feature_columns=feature_columns+derived_feature_columns)
linear_est.train(train_input_fn)
result = linear_est.evaluate(eval_input_fn)
clear_output()
print(result)
{'accuracy': 0.7537879, 'accuracy_baseline': 0.625, 'auc': 0.84459746, 'auc_precision_recall': 0.79323035, 'average_loss': 0.4729848, 'label/mean': 0.375, 'loss': 0.46476856, 'precision': 0.6666667, 'prediction/mean': 0.41475508, 'recall': 0.68686867, 'global_step': 200}
이제 정확도 77.6%에 도달했습니다. 기본 특성만 이용한 학습보다는 약간 더 좋았습니다. 더 많은 특성과 변환을 사용해서 더 잘할 수 있다는 것을 보여주세요!
이제 훈련 모델을 이용해서 평가셋에서 승객에 대해 예측을 할 수 있습니다. 텐서플로 모델은 한번에 샘플의 배치 또는 일부에 대한 예측을 하도록 최적화되어있습니다. 앞서, eval_input_fn은 모든 평가셋을 사용하도록 정의되어 있었습니다.
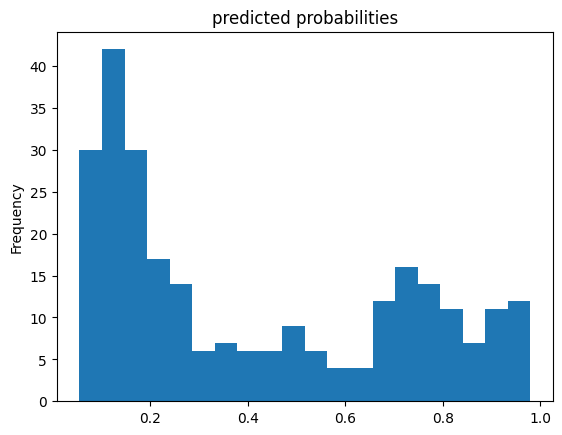
pred_dicts = list(linear_est.predict(eval_input_fn))
probs = pd.Series([pred['probabilities'][1] for pred in pred_dicts])
probs.plot(kind='hist', bins=20, title='predicted probabilities')
INFO:tensorflow:Calling model_fn.
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Restoring parameters from /tmpfs/tmp/tmps9yhceth/model.ckpt-200
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
<AxesSubplot: title={'center': 'predicted probabilities'}, ylabel='Frequency'>
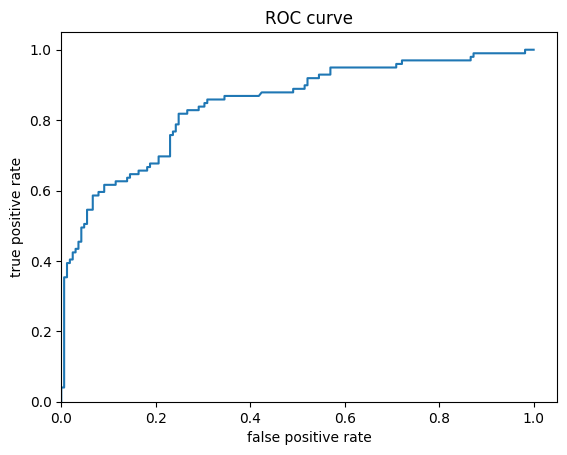
마지막으로, 수신자 조작 특성(receiver operating characteristic, ROC)을 살펴보면 정탐률(true positive rate)과 오탐률(false positive rate)의 상충관계에 대해 더 잘 이해할 수 있습니다.
from sklearn.metrics import roc_curve
from matplotlib import pyplot as plt
fpr, tpr, _ = roc_curve(y_eval, probs)
plt.plot(fpr, tpr)
plt.title('ROC curve')
plt.xlabel('false positive rate')
plt.ylabel('true positive rate')
plt.xlim(0,)
plt.ylim(0,)
(0.0, 1.05)