
 GitHub에서 소스 보기 GitHub에서 소스 보기 |
개요
tf.distribute.Strategy API는 여러 처리 장치에 훈련을 배포하기 위한 추상화를 제공합니다. 이를 통해 최소한의 변경만으로 기존 모델 및 훈련 코드를 사용하여 분산 교육을 수행할 수 있습니다.
이 튜토리얼에서는 tf.distribute.MirroredStrategy를 사용하여 하나의 시스템에서 많은 GPU에 대한 동기식 훈련으로 그래프 내 복제를 수행하는 방법을 보여줍니다. 이 전략은 기본적으로 모델의 모든 변수를 각 프로세서에 복사합니다. 그런 다음 all-reduce를 사용하여 모든 프로세서의 그래디언트를 결합하고 결합된 값을 모델의 모든 복사본에 적용합니다.
tf.keras API를 사용하여 모델을 빌드하고 Model.fit을 이용해 이를 훈련합니다. 사용자 지정 훈련 루프와 MirroredStrategy를 사용한 분산 훈련에 대해 알아보려면 이 튜토리얼을 확인하세요.
MirroredStrategy는 단일 시스템의 여러 GPU에서 모델을 훈련합니다. 여러 작업자의 많은 GPU에 대한 동기식 훈련의 경우에는 Keras Model.fit 또는 사용자 지정 훈련 루프와 함께 tf.distribute.MultiWorkerMirroredStrategy를 사용합니다. 다른 옵션에 대해서는 분산형 훈련 가이드를 참조하세요.
다른 다양한 전략에 대해 알아보려면 TensorFlow를 사용한 분산 훈련 가이드가 있습니다.
설정
import tensorflow_datasets as tfds
import tensorflow as tf
import os
# Load the TensorBoard notebook extension.
%load_ext tensorboard
2022-12-15 02:08:39.298869: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory 2022-12-15 02:08:39.298991: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory 2022-12-15 02:08:39.299002: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
print(tf.__version__)
2.11.0
데이터세트 다운로드하기
TensorFlow Datasets에서 MNIST 데이터세트를 로드합니다. 그러면 tf.data 형식의 데이터세트가 반환됩니다.
with_info 인수를 True로 설정하면 전체 데이터세트에 대한 메타데이터 정보도 함께 불러옵니다. 이 정보는 info 변수에 저장됩니다. 무엇보다 이 메타데이터 개체에는 훈련 및 테스트 예제의 수가 포함됩니다.
datasets, info = tfds.load(name='mnist', with_info=True, as_supervised=True)
mnist_train, mnist_test = datasets['train'], datasets['test']
배포 전략 정의하기
MirroredStrategy 개체를 생성합니다. 이 개체는 배포를 처리하고 내부에 모델을 구축하기 위한 컨텍스트 관리자(MirroredStrategy.scope)를 제공합니다.
strategy = tf.distribute.MirroredStrategy()
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0', '/job:localhost/replica:0/task:0/device:GPU:1', '/job:localhost/replica:0/task:0/device:GPU:2', '/job:localhost/replica:0/task:0/device:GPU:3')
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0', '/job:localhost/replica:0/task:0/device:GPU:1', '/job:localhost/replica:0/task:0/device:GPU:2', '/job:localhost/replica:0/task:0/device:GPU:3')
print('Number of devices: {}'.format(strategy.num_replicas_in_sync))
Number of devices: 4
입력 파이프라인 설정하기
다중 GPU로 모델을 훈련할 때는 배치 크기를 늘려야 컴퓨팅 자원을 효과적으로 사용할 수 있습니다. 기본적으로는 GPU 메모리에 맞추어 가능한 가장 큰 배치 크기를 사용하세요. 이에 맞게 학습률도 조정해야 합니다.
# You can also do info.splits.total_num_examples to get the total
# number of examples in the dataset.
num_train_examples = info.splits['train'].num_examples
num_test_examples = info.splits['test'].num_examples
BUFFER_SIZE = 10000
BATCH_SIZE_PER_REPLICA = 64
BATCH_SIZE = BATCH_SIZE_PER_REPLICA * strategy.num_replicas_in_sync
[0, 255] 범위에서 [0, 1] 범위로 이미지 픽셀 값을 정규화하는 함수를 정의합니다(특성 스케일링).
def scale(image, label):
image = tf.cast(image, tf.float32)
image /= 255
return image, label
이 scale 함수를 훈련 및 테스트 데이터에 적용한 다음, tf.data.Dataset API를 사용하여 훈련 데이터(Dataset.shuffle)를 섞고 이를 일괄 처리(Dataset.batch)합니다. 성능 향상을 위해 훈련 데이터의 메모리 내 캐시도 유지한다는 점에 주목하세요(Dataset.cache).
train_dataset = mnist_train.map(scale).cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
eval_dataset = mnist_test.map(scale).batch(BATCH_SIZE)
모델 만들기
Strategy.scope 컨텍스트 내에서 Keras API를 사용하여 모델을 만들고 컴파일합니다.
with strategy.scope():
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, 3, activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10)
])
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
콜백 정의하기
다음 Keras 콜백을 정의하세요.
tf.keras.callbacks.TensorBoard: 그래프를 시각화할 수 있게 해주는 TensorBoard에 대한 로그를 작성합니다.tf.keras.callbacks.ModelCheckpoint: 매 epoch 후와 같이 특정 빈도로 모델을 저장합니다.tf.keras.callbacks.BackupAndRestore: 모델과 현재 epoch 수를 백업하여 내결함성 기능을 제공합니다. Keras를 사용한 다중 작업자 훈련 튜토리얼의 내결함성 섹션에서 자세히 알아보세요.tf.keras.callbacks.LearningRateScheduler: schedules the learning rate to change after, for example, every epoch/batch.
설명 목적으로 노트북에 학습률을 표시하기 위한 PrintLR이라는 사용자 정의 콜백을 추가합니다.
참고: ModelCheckpoint 대신 BackupAndRestore 콜백을 작업 실패 시 다시 시작할 때 훈련 상태를 복원하는 기본 메커니즘으로 사용하세요. BackupAndRestore는 즉시 실행 모드만 지원하므로 그래프 모드에서는 ModelCheckpoint를 사용하는 것이 좋습니다.
# Define the checkpoint directory to store the checkpoints.
checkpoint_dir = './training_checkpoints'
# Define the name of the checkpoint files.
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt_{epoch}")
# Define a function for decaying the learning rate.
# You can define any decay function you need.
def decay(epoch):
if epoch < 3:
return 1e-3
elif epoch >= 3 and epoch < 7:
return 1e-4
else:
return 1e-5
# Define a callback for printing the learning rate at the end of each epoch.
class PrintLR(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
print('\nLearning rate for epoch {} is {}'.format( epoch + 1, model.optimizer.lr.numpy()))
# Put all the callbacks together.
callbacks = [
tf.keras.callbacks.TensorBoard(log_dir='./logs'),
tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_prefix,
save_weights_only=True),
tf.keras.callbacks.LearningRateScheduler(decay),
PrintLR()
]
훈련과 평가
이제 평소처럼 모델을 훈련합니다. 이를 위해 모델에서 Model.fit을 호출하고 튜토리얼의 시작 부분에서 만든 데이터세트에 전달합니다. 이 단계는 훈련을 배포하는지 여부에 상관없이 동일합니다.
EPOCHS = 12
model.fit(train_dataset, epochs=EPOCHS, callbacks=callbacks)
2022-12-15 02:08:46.837870: W tensorflow/core/grappler/optimizers/data/auto_shard.cc:549] The `assert_cardinality` transformation is currently not handled by the auto-shard rewrite and will be removed.
Epoch 1/12
INFO:tensorflow:batch_all_reduce: 6 all-reduces with algorithm = nccl, num_packs = 1
INFO:tensorflow:batch_all_reduce: 6 all-reduces with algorithm = nccl, num_packs = 1
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:batch_all_reduce: 6 all-reduces with algorithm = nccl, num_packs = 1
INFO:tensorflow:batch_all_reduce: 6 all-reduces with algorithm = nccl, num_packs = 1
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
1/235 [..............................] - ETA: 36:28 - loss: 2.2908 - accuracy: 0.1016WARNING:tensorflow:Callback method `on_train_batch_end` is slow compared to the batch time (batch time: 0.0072s vs `on_train_batch_end` time: 0.0146s). Check your callbacks.
WARNING:tensorflow:Callback method `on_train_batch_end` is slow compared to the batch time (batch time: 0.0072s vs `on_train_batch_end` time: 0.0146s). Check your callbacks.
230/235 [============================>.] - ETA: 0s - loss: 0.3467 - accuracy: 0.9016
Learning rate for epoch 1 is 0.0010000000474974513
235/235 [==============================] - 11s 8ms/step - loss: 0.3430 - accuracy: 0.9027 - lr: 0.0010
Epoch 2/12
233/235 [============================>.] - ETA: 0s - loss: 0.1121 - accuracy: 0.9680
Learning rate for epoch 2 is 0.0010000000474974513
235/235 [==============================] - 2s 7ms/step - loss: 0.1119 - accuracy: 0.9681 - lr: 0.0010
Epoch 3/12
233/235 [============================>.] - ETA: 0s - loss: 0.0745 - accuracy: 0.9786
Learning rate for epoch 3 is 0.0010000000474974513
235/235 [==============================] - 2s 7ms/step - loss: 0.0745 - accuracy: 0.9786 - lr: 0.0010
Epoch 4/12
233/235 [============================>.] - ETA: 0s - loss: 0.0527 - accuracy: 0.9852
Learning rate for epoch 4 is 9.999999747378752e-05
235/235 [==============================] - 2s 7ms/step - loss: 0.0527 - accuracy: 0.9852 - lr: 1.0000e-04
Epoch 5/12
233/235 [============================>.] - ETA: 0s - loss: 0.0499 - accuracy: 0.9867
Learning rate for epoch 5 is 9.999999747378752e-05
235/235 [==============================] - 2s 7ms/step - loss: 0.0499 - accuracy: 0.9867 - lr: 1.0000e-04
Epoch 6/12
233/235 [============================>.] - ETA: 0s - loss: 0.0480 - accuracy: 0.9870
Learning rate for epoch 6 is 9.999999747378752e-05
235/235 [==============================] - 2s 7ms/step - loss: 0.0480 - accuracy: 0.9870 - lr: 1.0000e-04
Epoch 7/12
233/235 [============================>.] - ETA: 0s - loss: 0.0464 - accuracy: 0.9870
Learning rate for epoch 7 is 9.999999747378752e-05
235/235 [==============================] - 2s 7ms/step - loss: 0.0465 - accuracy: 0.9869 - lr: 1.0000e-04
Epoch 8/12
233/235 [============================>.] - ETA: 0s - loss: 0.0439 - accuracy: 0.9879
Learning rate for epoch 8 is 9.999999747378752e-06
235/235 [==============================] - 2s 7ms/step - loss: 0.0440 - accuracy: 0.9879 - lr: 1.0000e-05
Epoch 9/12
233/235 [============================>.] - ETA: 0s - loss: 0.0438 - accuracy: 0.9881
Learning rate for epoch 9 is 9.999999747378752e-06
235/235 [==============================] - 2s 7ms/step - loss: 0.0437 - accuracy: 0.9881 - lr: 1.0000e-05
Epoch 10/12
234/235 [============================>.] - ETA: 0s - loss: 0.0435 - accuracy: 0.9881
Learning rate for epoch 10 is 9.999999747378752e-06
235/235 [==============================] - 2s 7ms/step - loss: 0.0435 - accuracy: 0.9881 - lr: 1.0000e-05
Epoch 11/12
233/235 [============================>.] - ETA: 0s - loss: 0.0433 - accuracy: 0.9882
Learning rate for epoch 11 is 9.999999747378752e-06
235/235 [==============================] - 2s 7ms/step - loss: 0.0433 - accuracy: 0.9882 - lr: 1.0000e-05
Epoch 12/12
233/235 [============================>.] - ETA: 0s - loss: 0.0432 - accuracy: 0.9882
Learning rate for epoch 12 is 9.999999747378752e-06
235/235 [==============================] - 2s 7ms/step - loss: 0.0431 - accuracy: 0.9882 - lr: 1.0000e-05
<keras.callbacks.History at 0x7fa2587c2c40>
저장된 체크포인트를 확인합니다.
# Check the checkpoint directory.ls {checkpoint_dir}
checkpoint ckpt_4.data-00000-of-00001 ckpt_1.data-00000-of-00001 ckpt_4.index ckpt_1.index ckpt_5.data-00000-of-00001 ckpt_10.data-00000-of-00001 ckpt_5.index ckpt_10.index ckpt_6.data-00000-of-00001 ckpt_11.data-00000-of-00001 ckpt_6.index ckpt_11.index ckpt_7.data-00000-of-00001 ckpt_12.data-00000-of-00001 ckpt_7.index ckpt_12.index ckpt_8.data-00000-of-00001 ckpt_2.data-00000-of-00001 ckpt_8.index ckpt_2.index ckpt_9.data-00000-of-00001 ckpt_3.data-00000-of-00001 ckpt_9.index ckpt_3.index
모델 성능이 얼마나 좋은지 확인하기 위해 최신 체크포인트를 로드하고 테스트 데이터에서 Model.evaluate를 호출합니다.
model.load_weights(tf.train.latest_checkpoint(checkpoint_dir))
eval_loss, eval_acc = model.evaluate(eval_dataset)
print('Eval loss: {}, Eval accuracy: {}'.format(eval_loss, eval_acc))
2022-12-15 02:09:19.925330: W tensorflow/core/grappler/optimizers/data/auto_shard.cc:549] The `assert_cardinality` transformation is currently not handled by the auto-shard rewrite and will be removed. 40/40 [==============================] - 3s 14ms/step - loss: 0.0526 - accuracy: 0.9820 Eval loss: 0.05255807936191559, Eval accuracy: 0.9819999933242798
출력을 시각화하려면 TensorBoard를 시작하고 로그를 봅니다.
%tensorboard --logdir=logs
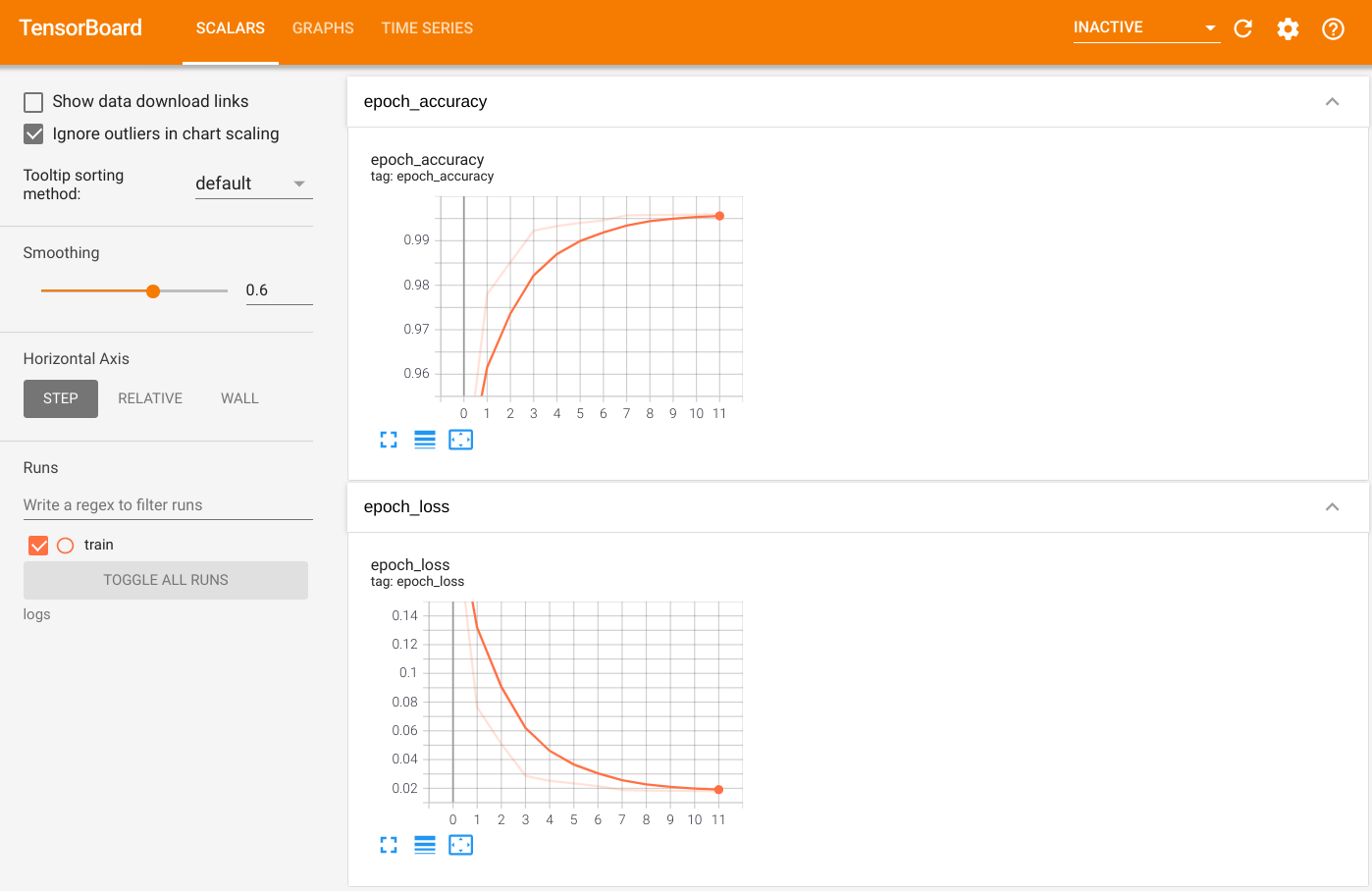
ls -sh ./logstotal 4.0K 4.0K train
SavedModel로 내보내기
Keras Model.save를 사용하여 그래프와 변수를 플랫폼에 구애받지 않는 SavedModel 형식으로 내보냅니다. 모델이 저장되면 Strategy.scope를 사용하거나 사용하지 않고 모델을 로드할 수 있습니다.
path = 'saved_model/'
model.save(path, save_format='tf')
WARNING:absl:Found untraced functions such as _jit_compiled_convolution_op while saving (showing 1 of 1). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: saved_model/assets INFO:tensorflow:Assets written to: saved_model/assets
이제 Strategy.scope 없이 모델을 로드합니다.
unreplicated_model = tf.keras.models.load_model(path)
unreplicated_model.compile(
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
eval_loss, eval_acc = unreplicated_model.evaluate(eval_dataset)
print('Eval loss: {}, Eval Accuracy: {}'.format(eval_loss, eval_acc))
40/40 [==============================] - 0s 4ms/step - loss: 0.0526 - accuracy: 0.9820 Eval loss: 0.05255807563662529, Eval Accuracy: 0.9819999933242798
Strategy.scope로 모델을 로드합니다.
with strategy.scope():
replicated_model = tf.keras.models.load_model(path)
replicated_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
eval_loss, eval_acc = replicated_model.evaluate(eval_dataset)
print ('Eval loss: {}, Eval Accuracy: {}'.format(eval_loss, eval_acc))
2022-12-15 02:09:25.654247: W tensorflow/core/grappler/optimizers/data/auto_shard.cc:549] The `assert_cardinality` transformation is currently not handled by the auto-shard rewrite and will be removed. 40/40 [==============================] - 4s 5ms/step - loss: 0.0526 - accuracy: 0.9820 Eval loss: 0.05255807936191559, Eval Accuracy: 0.9819999933242798
추가 자료
Model.fit API로 다양한 배포 전략을 사용하는 더 많은 예:
- TPU에서 BERT를 사용하여 GLUE 작업 해결 튜토리얼은 GPU에서 훈련을 위해
tf.distribute.MirroredStrategy를 사용하고 TPU에서 훈련을 위해tf.distribute.TPUStrategy를 사용합니다. - 배포 전략을 사용하여 모델 저장 및 로드 튜토리얼은
tf.distribute.Strategy와 함께 SavedModel API를 사용하는 방법을 보여줍니다. - 여러 배포 전략을 실행하도록 공식 TensorFlow 모델을 구성할 수 있습니다.
TensorFlow 배포 전략에 대해 자세히 알아보려면:
- tf.distribute.Strategy를 사용한 사용자 지정 훈련 튜토리얼은 사용자 지정 훈련 루프가 있는 단일 작업자 훈련에
tf.distribute.MirroredStrategy를 사용하는 방법을 보여줍니다. - Keras를 사용한 다중 작업자 훈련 튜토리얼에는
Model.fit과 함께MultiWorkerMirroredStrategy를 사용하는 방법이 나와 있습니다. - Keras 및 MultiWorkerMirroredStrategy를 이용한 사용자 지정 훈련 루프 튜토리얼은 Keras 및 사용자 지정 훈련 루프와 함께
MultiWorkerMirroredStrategy를 이용하는 방법을 보여줍니다. - TensorFlow에서 분산 훈련하기 가이드는 사용 가능한 분산 전략을 간략히 소개합니다.
- tf.function으로 성능 향상 가이드는 TensorFlow 모델의 성능을 최적화하는 데 사용할 수 있는 TensorFlow 프로파일러와 같은 다른 전략 및 도구에 대한 정보를 제공합니다.
참고: tf.distribute.Strategy는 활발히 개발 중이며 TensorFlow는 조만간 더 많은 예제와 튜토리얼을 추가할 예정입니다. 사용해 보고 의견을 보내주세요. GitHub의 이슈를 통해 자유롭게 제출하시면 됩니다.