
| | |  Voir la source sur GitHub Voir la source sur GitHub | |
Ce guide utilise l'apprentissage automatique pour classer les fleurs d'iris par espèce. Il utilise TensorFlow pour :
- Construire un modèle,
- Entraînez ce modèle sur des exemples de données, et
- Utilisez le modèle pour faire des prédictions sur des données inconnues.
Programmation TensorFlow
Ce guide utilise ces concepts TensorFlow de haut niveau :
- Utilisez l'environnement de développement d' exécution rapide par défaut de TensorFlow,
- Importer des données avec l' API Datasets ,
- Créez des modèles et des calques avec l' API Keras de TensorFlow.
Ce tutoriel est structuré comme de nombreux programmes TensorFlow :
- Importez et analysez l'ensemble de données.
- Sélectionnez le type de modèle.
- Entraînez le modèle.
- Évaluer l'efficacité du modèle.
- Utilisez le modèle formé pour faire des prédictions.
Programme d'installation
Configurer les importations
Importez TensorFlow et les autres modules Python requis. Par défaut, TensorFlow utilise une exécution rapide pour évaluer immédiatement les opérations, en renvoyant des valeurs concrètes au lieu de créer un graphique de calcul qui est exécuté ultérieurement. Si vous êtes habitué à un REPL ou à la console interactive python , cela vous semble familier.
import os
import matplotlib.pyplot as plt
import tensorflow as tf
print("TensorFlow version: {}".format(tf.__version__))
print("Eager execution: {}".format(tf.executing_eagerly()))
TensorFlow version: 2.8.0-rc1 Eager execution: True
Le problème de classification d'Iris
Imaginez que vous êtes un botaniste à la recherche d'un moyen automatisé de catégoriser chaque fleur d'iris que vous trouvez. L'apprentissage automatique fournit de nombreux algorithmes pour classer statistiquement les fleurs. Par exemple, un programme d'apprentissage automatique sophistiqué pourrait classer les fleurs en fonction de photographies. Nos ambitions sont plus modestes : nous allons classer les fleurs d'iris en fonction de la longueur et de la largeur de leurs sépales et pétales .
Le genre Iris comprend environ 300 espèces, mais notre programme ne classera que les trois suivantes :
- Iris setosa
- Iris virginica
- Iris versicolore
 |
| Figure 1. Iris setosa (par Radomil , CC BY-SA 3.0), Iris versicolor , (par Dlanglois , CC BY-SA 3.0) et Iris virginica (par Frank Mayfield , CC BY-SA 2.0). |
Heureusement, quelqu'un a déjà créé un ensemble de données de 120 fleurs d'iris avec les mesures des sépales et des pétales. Il s'agit d'un ensemble de données classique qui est populaire pour les problèmes de classification d'apprentissage automatique pour débutants.
Importer et analyser l'ensemble de données d'entraînement
Téléchargez le fichier de jeu de données et convertissez-le en une structure pouvant être utilisée par ce programme Python.
Télécharger le jeu de données
Téléchargez le fichier d'ensemble de données d'entraînement à l'aide de la fonction tf.keras.utils.get_file . Cela renvoie le chemin du fichier téléchargé :
train_dataset_url = "https://storage.googleapis.com/download.tensorflow.org/data/iris_training.csv"
train_dataset_fp = tf.keras.utils.get_file(fname=os.path.basename(train_dataset_url),
origin=train_dataset_url)
print("Local copy of the dataset file: {}".format(train_dataset_fp))
Local copy of the dataset file: /home/kbuilder/.keras/datasets/iris_training.csv
Inspectez les données
Cet ensemble de données, iris_training.csv , est un fichier texte brut qui stocke des données tabulaires au format CSV (valeurs séparées par des virgules). Utilisez la commande head -n5 pour jeter un coup d'œil aux cinq premières entrées :
head -n5 {train_dataset_fp}
120,4,setosa,versicolor,virginica 6.4,2.8,5.6,2.2,2 5.0,2.3,3.3,1.0,1 4.9,2.5,4.5,1.7,2 4.9,3.1,1.5,0.1,0
À partir de cette vue de l'ensemble de données, notez ce qui suit :
- La première ligne est un en-tête contenant des informations sur l'ensemble de données :
- Il y a 120 exemples au total. Chaque exemple a quatre caractéristiques et l'un des trois noms d'étiquette possibles.
- Les lignes suivantes sont des enregistrements de données, un exemple par ligne, où :
- Les quatre premiers champs sont des traits : ce sont les caractéristiques d'un exemple. Ici, les champs contiennent des nombres flottants représentant les mesures des fleurs.
- La dernière colonne est le label : c'est la valeur que l'on veut prédire. Pour cet ensemble de données, c'est une valeur entière de 0, 1 ou 2 qui correspond à un nom de fleur.
Écrivons cela en code :
# column order in CSV file
column_names = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']
feature_names = column_names[:-1]
label_name = column_names[-1]
print("Features: {}".format(feature_names))
print("Label: {}".format(label_name))
Features: ['sepal_length', 'sepal_width', 'petal_length', 'petal_width'] Label: species
Chaque étiquette est associée à un nom de chaîne (par exemple, "setosa"), mais l'apprentissage automatique repose généralement sur des valeurs numériques. Les numéros d'étiquette sont mappés à une représentation nommée, telle que :
-
0: Iris setosa -
1: Iris versicolore -
2: Iris virginica
Pour plus d'informations sur les fonctionnalités et les étiquettes, consultez la section Terminologie ML du cours d'initiation au machine learning .
class_names = ['Iris setosa', 'Iris versicolor', 'Iris virginica']
Créer un tf.data.Dataset
L' API Dataset de TensorFlow gère de nombreux cas courants de chargement de données dans un modèle. Il s'agit d'une API de haut niveau pour lire les données et les transformer en un formulaire utilisé pour la formation.
Étant donné que l'ensemble de données est un fichier texte au format CSV, utilisez la fonction tf.data.experimental.make_csv_dataset pour analyser les données dans un format approprié. Étant donné que cette fonction génère des données pour les modèles d'apprentissage, le comportement par défaut consiste à mélanger les données ( shuffle=True, shuffle_buffer_size=10000 ) et à répéter indéfiniment l'ensemble de données ( num_epochs=None ). Nous définissons également le paramètre batch_size :
batch_size = 32
train_dataset = tf.data.experimental.make_csv_dataset(
train_dataset_fp,
batch_size,
column_names=column_names,
label_name=label_name,
num_epochs=1)
La fonction make_csv_dataset renvoie un tf.data.Dataset de paires (features, label) , où features est un dictionnaire : {'feature_name': value}
Ces objets Dataset sont itérables. Regardons un lot de fonctionnalités :
features, labels = next(iter(train_dataset))
print(features)
OrderedDict([('sepal_length', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([5. , 7.4, 6. , 7.2, 5.9, 5.8, 5. , 5. , 7.7, 5.7, 6.3, 5.8, 5. ,
4.8, 6.6, 6.3, 5.4, 6.9, 4.8, 6.6, 5.8, 7.7, 6.7, 7.6, 5.5, 6.4,
5.6, 6.4, 4.4, 4.5, 6.5, 6.3], dtype=float32)>), ('sepal_width', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([3.5, 2.8, 2.7, 3.2, 3. , 2.6, 2. , 3.4, 3. , 2.8, 2.3, 2.7, 3.6,
3.1, 2.9, 3.3, 3. , 3.1, 3. , 3. , 4. , 2.6, 3. , 3. , 2.4, 2.7,
2.7, 2.8, 3. , 2.3, 2.8, 2.5], dtype=float32)>), ('petal_length', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([1.6, 6.1, 5.1, 6. , 5.1, 4. , 3.5, 1.6, 6.1, 4.5, 4.4, 5.1, 1.4,
1.6, 4.6, 4.7, 4.5, 5.1, 1.4, 4.4, 1.2, 6.9, 5. , 6.6, 3.7, 5.3,
4.2, 5.6, 1.3, 1.3, 4.6, 5. ], dtype=float32)>), ('petal_width', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([0.6, 1.9, 1.6, 1.8, 1.8, 1.2, 1. , 0.4, 2.3, 1.3, 1.3, 1.9, 0.2,
0.2, 1.3, 1.6, 1.5, 2.3, 0.3, 1.4, 0.2, 2.3, 1.7, 2.1, 1. , 1.9,
1.3, 2.1, 0.2, 0.3, 1.5, 1.9], dtype=float32)>)])
Notez que les caractéristiques similaires sont regroupées ou regroupées . Les champs de chaque exemple de ligne sont ajoutés au tableau d'entités correspondant. Modifiez batch_size pour définir le nombre d'exemples stockés dans ces tableaux de fonctionnalités.
Vous pouvez commencer à voir certains clusters en traçant quelques caractéristiques du lot :
plt.scatter(features['petal_length'],
features['sepal_length'],
c=labels,
cmap='viridis')
plt.xlabel("Petal length")
plt.ylabel("Sepal length")
plt.show()
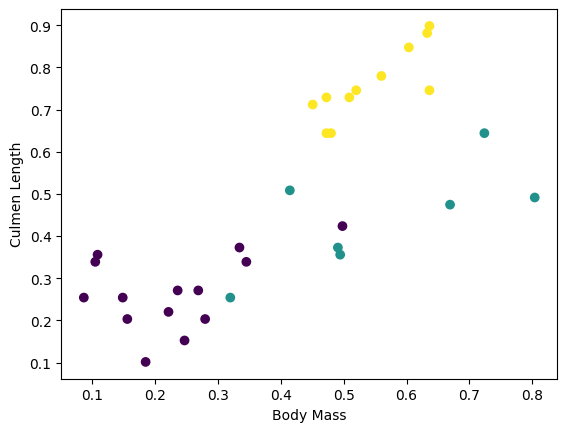
Pour simplifier l'étape de construction du modèle, créez une fonction pour reconditionner le dictionnaire de fonctionnalités dans un seul tableau avec la forme : (batch_size, num_features) .
Cette fonction utilise la méthode tf.stack qui prend les valeurs d'une liste de tenseurs et crée un tenseur combiné à la dimension spécifiée :
def pack_features_vector(features, labels):
"""Pack the features into a single array."""
features = tf.stack(list(features.values()), axis=1)
return features, labels
Utilisez ensuite la méthode tf.data.Dataset#map pour regrouper les features de chaque paire (features,label) dans l'ensemble de données d'apprentissage :
train_dataset = train_dataset.map(pack_features_vector)
L'élément features du Dataset sont maintenant des tableaux avec shape (batch_size, num_features) . Voyons les premiers exemples :
features, labels = next(iter(train_dataset))
print(features[:5])
tf.Tensor( [[4.9 3. 1.4 0.2] [6.1 3. 4.9 1.8] [6.1 2.6 5.6 1.4] [6.9 3.2 5.7 2.3] [6.7 3.1 4.4 1.4]], shape=(5, 4), dtype=float32)
Sélectionnez le type de modèle
Pourquoi modéliser ?
Un modèle est une relation entre les caractéristiques et l'étiquette. Pour le problème de classification d'Iris, le modèle définit la relation entre les mesures des sépales et des pétales et les espèces d'Iris prédites. Certains modèles simples peuvent être décrits avec quelques lignes d'algèbre, mais les modèles complexes d'apprentissage automatique ont un grand nombre de paramètres difficiles à résumer.
Pourriez-vous déterminer la relation entre les quatre caractéristiques et les espèces d'iris sans utiliser l'apprentissage automatique ? Autrement dit, pourriez-vous utiliser des techniques de programmation traditionnelles (par exemple, un grand nombre d'instructions conditionnelles) pour créer un modèle ? Peut-être, si vous avez analysé l'ensemble de données suffisamment longtemps pour déterminer les relations entre les mesures des pétales et des sépales pour une espèce particulière. Et cela devient difficile, voire impossible, sur des ensembles de données plus complexes. Une bonne approche d'apprentissage automatique détermine le modèle pour vous . Si vous introduisez suffisamment d'exemples représentatifs dans le bon type de modèle d'apprentissage automatique, le programme déterminera les relations pour vous.
Sélectionnez le modèle
Nous devons sélectionner le type de modèle à entraîner. Il existe de nombreux types de modèles et en choisir un bon demande de l'expérience. Ce tutoriel utilise un réseau de neurones pour résoudre le problème de classification Iris. Les réseaux de neurones peuvent trouver des relations complexes entre les caractéristiques et l'étiquette. C'est un graphe très structuré, organisé en une ou plusieurs couches cachées . Chaque couche cachée est constituée d'un ou plusieurs neurones . Il existe plusieurs catégories de réseaux de neurones et ce programme utilise un réseau de neurones dense ou entièrement connecté : les neurones d'une couche reçoivent des connexions d'entrée de chaque neurone de la couche précédente. Par exemple, la figure 2 illustre un réseau de neurones dense composé d'une couche d'entrée, de deux couches cachées et d'une couche de sortie :
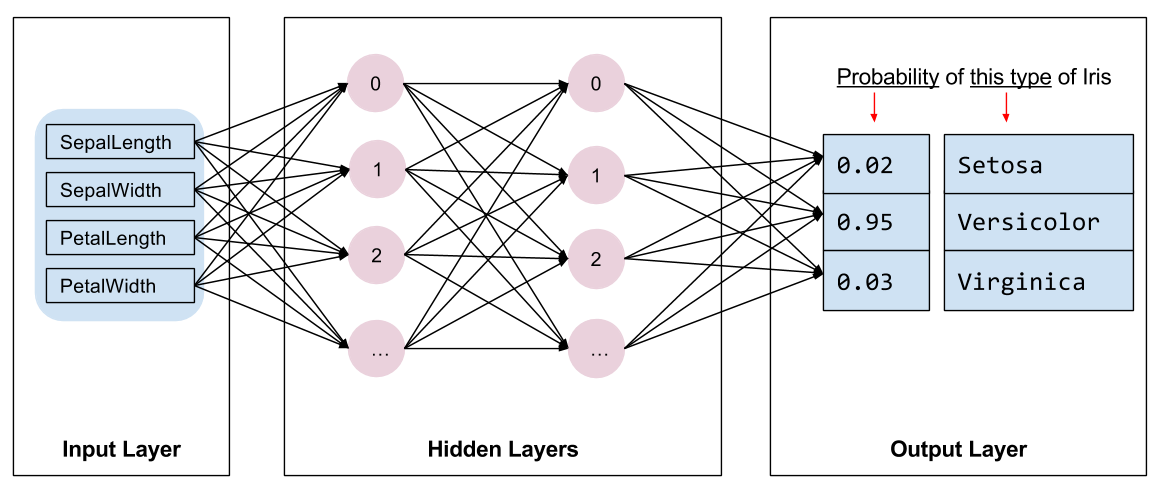 |
| Figure 2. Un réseau de neurones avec des fonctionnalités, des couches cachées et des prédictions. |
Lorsque le modèle de la figure 2 est formé et alimenté avec un exemple non étiqueté, il donne trois prédictions : la probabilité que cette fleur soit l'espèce d'iris donnée. Cette prédiction est appelée inférence . Pour cet exemple, la somme des prédictions de sortie est de 1,0. Dans la figure 2, cette prédiction se décompose comme suit : 0.02 pour Iris setosa , 0.95 pour Iris versicolor et 0.03 pour Iris virginica . Cela signifie que le modèle prédit, avec une probabilité de 95 %, qu'un exemple de fleur sans étiquette est un Iris versicolor .
Créer un modèle à l'aide de Keras
L'API TensorFlow tf.keras est le moyen privilégié pour créer des modèles et des calques. Cela facilite la construction de modèles et l'expérimentation tandis que Keras gère la complexité de tout connecter ensemble.
Le modèle tf.keras.Sequential est un empilement linéaire de couches. Son constructeur prend une liste d'instances de couche, dans ce cas, deux couches tf.keras.layers.Dense avec 10 nœuds chacune, et une couche de sortie avec 3 nœuds représentant nos prédictions d'étiquettes. Le paramètre input_shape de la première couche correspond au nombre d'entités du jeu de données et est obligatoire :
model = tf.keras.Sequential([
tf.keras.layers.Dense(10, activation=tf.nn.relu, input_shape=(4,)), # input shape required
tf.keras.layers.Dense(10, activation=tf.nn.relu),
tf.keras.layers.Dense(3)
])
La fonction d'activation détermine la forme de sortie de chaque nœud de la couche. Ces non-linéarités sont importantes - sans elles, le modèle serait équivalent à une seule couche. Il existe de nombreuses tf.keras.activations , mais ReLU est courant pour les couches cachées.
Le nombre idéal de couches cachées et de neurones dépend du problème et de l'ensemble de données. Comme de nombreux aspects de l'apprentissage automatique, choisir la meilleure forme de réseau de neurones nécessite un mélange de connaissances et d'expérimentation. En règle générale, l'augmentation du nombre de couches et de neurones cachés crée généralement un modèle plus puissant, qui nécessite plus de données pour s'entraîner efficacement.
Utilisation du modèle
Jetons un coup d'œil à ce que ce modèle fait à un lot de fonctionnalités :
predictions = model(features)
predictions[:5]
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[-4.0874639e+00, 1.5199981e-03, -9.9991310e-01],
[-5.3246369e+00, -1.8366380e-01, -1.3161827e+00],
[-5.1154275e+00, -2.8129923e-01, -1.3305402e+00],
[-6.0694785e+00, -2.1251860e-01, -1.5091233e+00],
[-5.6730523e+00, -1.4321266e-01, -1.4437559e+00]], dtype=float32)>
Ici, chaque exemple renvoie un logit pour chaque classe.
Pour convertir ces logits en probabilité pour chaque classe, utilisez la fonction softmax :
tf.nn.softmax(predictions[:5])
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[0.01210616, 0.7224865 , 0.26540732],
[0.00440638, 0.75297093, 0.24262273],
[0.00585618, 0.7362918 , 0.25785193],
[0.00224076, 0.7835035 , 0.21425581],
[0.00310779, 0.7834839 , 0.21340834]], dtype=float32)>
Prendre le tf.argmax entre les classes nous donne l'indice de classe prédit. Mais, le modèle n'a pas encore été formé, donc ce ne sont pas de bonnes prédictions :
print("Prediction: {}".format(tf.argmax(predictions, axis=1)))
print(" Labels: {}".format(labels))
Prediction: [1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]
Labels: [0 2 2 2 1 1 0 1 1 2 2 1 0 2 2 2 1 0 2 2 1 0 2 1 2 0 1 1 2 2 1 2]
Former le modèle
La formation est l'étape de l'apprentissage automatique lorsque le modèle est progressivement optimisé ou que le modèle apprend l'ensemble de données. L'objectif est d'en apprendre suffisamment sur la structure de l'ensemble de données d'apprentissage pour faire des prédictions sur des données invisibles. Si vous en apprenez trop sur l'ensemble de données d'entraînement, les prédictions ne fonctionnent que pour les données qu'il a vues et ne seront pas généralisables. Ce problème s'appelle le surajustement — c'est comme mémoriser les réponses au lieu de comprendre comment résoudre un problème.
Le problème de classification d'Iris est un exemple d' apprentissage automatique supervisé : le modèle est entraîné à partir d'exemples contenant des étiquettes. Dans le machine learning non supervisé , les exemples ne contiennent pas d'étiquettes. Au lieu de cela, le modèle trouve généralement des modèles parmi les fonctionnalités.
Définir la fonction de perte et de gradient
Les étapes de formation et d'évaluation doivent calculer la perte du modèle . Cela mesure à quel point les prédictions d'un modèle sont éloignées de l'étiquette souhaitée, en d'autres termes, à quel point le modèle fonctionne mal. Nous voulons minimiser, ou optimiser, cette valeur.
Notre modèle calculera sa perte à l'aide de la fonction tf.keras.losses.SparseCategoricalCrossentropy qui prend les prédictions de probabilité de classe du modèle et l'étiquette souhaitée, et renvoie la perte moyenne dans les exemples.
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
def loss(model, x, y, training):
# training=training is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
y_ = model(x, training=training)
return loss_object(y_true=y, y_pred=y_)
l = loss(model, features, labels, training=False)
print("Loss test: {}".format(l))
Loss test: 1.6059828996658325
Utilisez le contexte tf.GradientTape pour calculer les gradients utilisés pour optimiser votre modèle :
def grad(model, inputs, targets):
with tf.GradientTape() as tape:
loss_value = loss(model, inputs, targets, training=True)
return loss_value, tape.gradient(loss_value, model.trainable_variables)
Créer un optimiseur
Un optimiseur applique les gradients calculés aux variables du modèle pour minimiser la fonction de loss . Vous pouvez considérer la fonction de perte comme une surface courbe (voir Figure 3) et nous voulons trouver son point le plus bas en nous promenant. Les pentes pointent dans la direction de l'ascension la plus raide - nous allons donc voyager dans le sens opposé et descendre la colline. En calculant de manière itérative la perte et le gradient pour chaque lot, nous ajusterons le modèle pendant la formation. Progressivement, le modèle trouvera la meilleure combinaison de pondérations et de biais pour minimiser les pertes. Et plus la perte est faible, meilleures sont les prédictions du modèle.
 |
| Figure 3. Algorithmes d'optimisation visualisés au fil du temps dans l'espace 3D. (Source : Stanford classe CS231n , licence MIT, crédit image : Alec Radford ) |
TensorFlow propose de nombreux algorithmes d'optimisation pour l'entraînement. Ce modèle utilise le tf.keras.optimizers.SGD qui implémente l'algorithme de descente de gradient stochastique (SGD). Le learning_rate définit la taille du pas à prendre pour chaque itération en bas de la colline. Il s'agit d'un hyperparamètre que vous ajusterez généralement pour obtenir de meilleurs résultats.
Configurons l'optimiseur :
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
Nous allons l'utiliser pour calculer une seule étape d'optimisation :
loss_value, grads = grad(model, features, labels)
print("Step: {}, Initial Loss: {}".format(optimizer.iterations.numpy(),
loss_value.numpy()))
optimizer.apply_gradients(zip(grads, model.trainable_variables))
print("Step: {}, Loss: {}".format(optimizer.iterations.numpy(),
loss(model, features, labels, training=True).numpy()))
Step: 0, Initial Loss: 1.6059828996658325 Step: 1, Loss: 1.3759253025054932
Boucle d'entraînement
Avec toutes les pièces en place, le modèle est prêt pour l'entraînement ! Une boucle de formation alimente les exemples d'ensembles de données dans le modèle pour l'aider à faire de meilleures prédictions. Le bloc de code suivant configure ces étapes d'entraînement :
- Itérez chaque époque . Une époque est un passage dans l'ensemble de données.
- Au sein d'une époque, parcourez chaque exemple de l'ensemble de
Datasetd'apprentissage en saisissant ses caractéristiques (x) et son étiquette (y). - En utilisant les fonctionnalités de l'exemple, faites une prédiction et comparez-la avec l'étiquette. Mesurez l'imprécision de la prédiction et utilisez-la pour calculer la perte et les gradients du modèle.
- Utilisez un
optimizerpour mettre à jour les variables du modèle. - Gardez une trace de certaines statistiques pour la visualisation.
- Répétez pour chaque époque.
La variable num_epochs est le nombre de boucles sur la collection de l'ensemble de données. Contre-intuitivement, former un modèle plus longtemps ne garantit pas un meilleur modèle. num_epochs est un hyperparamètre que vous pouvez régler. Choisir le bon nombre nécessite généralement à la fois de l'expérience et de l'expérimentation :
## Note: Rerunning this cell uses the same model variables
# Keep results for plotting
train_loss_results = []
train_accuracy_results = []
num_epochs = 201
for epoch in range(num_epochs):
epoch_loss_avg = tf.keras.metrics.Mean()
epoch_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
# Training loop - using batches of 32
for x, y in train_dataset:
# Optimize the model
loss_value, grads = grad(model, x, y)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# Track progress
epoch_loss_avg.update_state(loss_value) # Add current batch loss
# Compare predicted label to actual label
# training=True is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
epoch_accuracy.update_state(y, model(x, training=True))
# End epoch
train_loss_results.append(epoch_loss_avg.result())
train_accuracy_results.append(epoch_accuracy.result())
if epoch % 50 == 0:
print("Epoch {:03d}: Loss: {:.3f}, Accuracy: {:.3%}".format(epoch,
epoch_loss_avg.result(),
epoch_accuracy.result()))
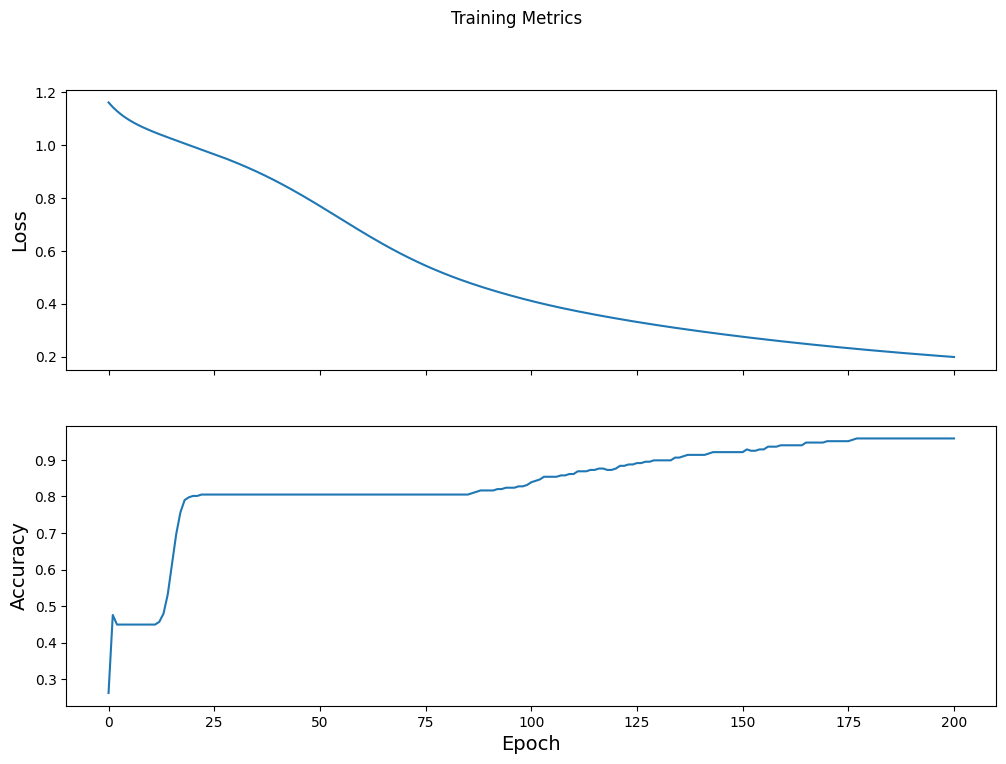
Epoch 000: Loss: 1.766, Accuracy: 43.333% Epoch 050: Loss: 0.579, Accuracy: 71.667% Epoch 100: Loss: 0.398, Accuracy: 82.500% Epoch 150: Loss: 0.307, Accuracy: 92.500% Epoch 200: Loss: 0.224, Accuracy: 95.833%
Visualisez la fonction de perte dans le temps
Bien qu'il soit utile d'imprimer la progression de la formation du modèle, il est souvent plus utile de voir cette progression. TensorBoard est un bel outil de visualisation fourni avec TensorFlow, mais nous pouvons créer des graphiques de base à l'aide du module matplotlib .
L'interprétation de ces graphiques demande une certaine expérience, mais vous voulez vraiment voir la perte diminuer et la précision augmenter :
fig, axes = plt.subplots(2, sharex=True, figsize=(12, 8))
fig.suptitle('Training Metrics')
axes[0].set_ylabel("Loss", fontsize=14)
axes[0].plot(train_loss_results)
axes[1].set_ylabel("Accuracy", fontsize=14)
axes[1].set_xlabel("Epoch", fontsize=14)
axes[1].plot(train_accuracy_results)
plt.show()
Évaluer l'efficacité du modèle
Maintenant que le modèle est formé, nous pouvons obtenir des statistiques sur ses performances.
Évaluer signifie déterminer l'efficacité avec laquelle le modèle fait des prédictions. Pour déterminer l'efficacité du modèle lors de la classification de l'iris, transmettez certaines mesures de sépales et de pétales au modèle et demandez au modèle de prédire quelles espèces d'iris ils représentent. Comparez ensuite les prédictions du modèle à l'étiquette réelle. Par exemple, un modèle qui a choisi la bonne espèce sur la moitié des exemples d'entrée a une précision de 0.5 . La figure 4 montre un modèle légèrement plus efficace, obtenant 4 prédictions sur 5 correctes avec une précision de 80 % :
| Exemples de fonctionnalités | Étiqueter | Prédiction du modèle | |||
|---|---|---|---|---|---|
| 5.9 | 3.0 | 4.3 | 1.5 | 1 | 1 |
| 6.9 | 3.1 | 5.4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1.7 | 0,5 | 0 | 0 |
| 6.0 | 3.4 | 4.5 | 1.6 | 1 | 2 |
| 5.5 | 2.5 | 4.0 | 1.3 | 1 | 1 |
| Figure 4. Un classificateur Iris précis à 80 %. | |||||
Configurer le jeu de données de test
L'évaluation du modèle est similaire à la formation du modèle. La plus grande différence est que les exemples proviennent d'un ensemble de tests distinct plutôt que de l'ensemble d'apprentissage. Pour évaluer équitablement l'efficacité d'un modèle, les exemples utilisés pour évaluer un modèle doivent être différents des exemples utilisés pour former le modèle.
La configuration de l'ensemble de Dataset de test est similaire à celle de l'ensemble de données d' Dataset . Téléchargez le fichier texte CSV et analysez ces valeurs, puis mélangez-le un peu :
test_url = "https://storage.googleapis.com/download.tensorflow.org/data/iris_test.csv"
test_fp = tf.keras.utils.get_file(fname=os.path.basename(test_url),
origin=test_url)
test_dataset = tf.data.experimental.make_csv_dataset(
test_fp,
batch_size,
column_names=column_names,
label_name='species',
num_epochs=1,
shuffle=False)
test_dataset = test_dataset.map(pack_features_vector)
Évaluer le modèle sur le jeu de données de test
Contrairement à la phase d'apprentissage, le modèle n'évalue qu'une seule époque des données de test. Dans la cellule de code suivante, nous parcourons chaque exemple de l'ensemble de test et comparons la prédiction du modèle à l'étiquette réelle. Ceci est utilisé pour mesurer la précision du modèle sur l'ensemble de l'ensemble de test :
test_accuracy = tf.keras.metrics.Accuracy()
for (x, y) in test_dataset:
# training=False is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
logits = model(x, training=False)
prediction = tf.argmax(logits, axis=1, output_type=tf.int32)
test_accuracy(prediction, y)
print("Test set accuracy: {:.3%}".format(test_accuracy.result()))
Test set accuracy: 96.667%
On peut voir sur le dernier lot, par exemple, que le modèle est généralement correct :
tf.stack([y,prediction],axis=1)
<tf.Tensor: shape=(30, 2), dtype=int32, numpy=
array([[1, 1],
[2, 2],
[0, 0],
[1, 1],
[1, 1],
[1, 1],
[0, 0],
[2, 2],
[1, 1],
[2, 2],
[2, 2],
[0, 0],
[2, 2],
[1, 1],
[1, 1],
[0, 0],
[1, 1],
[0, 0],
[0, 0],
[2, 2],
[0, 0],
[1, 1],
[2, 2],
[1, 2],
[1, 1],
[1, 1],
[0, 0],
[1, 1],
[2, 2],
[1, 1]], dtype=int32)>
Utiliser le modèle formé pour faire des prédictions
Nous avons formé un modèle et "prouvé" qu'il est bon, mais pas parfait, pour classer les espèces d'iris. Utilisons maintenant le modèle formé pour faire des prédictions sur des exemples non étiquetés ; c'est-à-dire sur des exemples qui contiennent des fonctionnalités mais pas d'étiquette.
Dans la vie réelle, les exemples sans étiquette peuvent provenir de nombreuses sources différentes, notamment des applications, des fichiers CSV et des flux de données. Pour l'instant, nous allons fournir manuellement trois exemples sans étiquette pour prédire leurs étiquettes. Rappelez-vous, les numéros d'étiquette sont mappés à une représentation nommée comme :
-
0: Iris setosa -
1: Iris versicolore -
2: Iris virginica
predict_dataset = tf.convert_to_tensor([
[5.1, 3.3, 1.7, 0.5,],
[5.9, 3.0, 4.2, 1.5,],
[6.9, 3.1, 5.4, 2.1]
])
# training=False is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
predictions = model(predict_dataset, training=False)
for i, logits in enumerate(predictions):
class_idx = tf.argmax(logits).numpy()
p = tf.nn.softmax(logits)[class_idx]
name = class_names[class_idx]
print("Example {} prediction: {} ({:4.1f}%)".format(i, name, 100*p))
Example 0 prediction: Iris setosa (97.6%) Example 1 prediction: Iris versicolor (82.0%) Example 2 prediction: Iris virginica (56.4%)