
В этом руководстве показано, как использовать TensorFlow Transform (библиотеку tf.Transform ) для реализации предварительной обработки данных для машинного обучения (ML). Библиотека tf.Transform для TensorFlow позволяет определять преобразования данных как на уровне экземпляра, так и полнопроходные с помощью конвейеров предварительной обработки данных. Эти конвейеры эффективно выполняются с помощью Apache Beam и в качестве побочных продуктов создают граф TensorFlow для применения тех же преобразований во время прогнозирования, что и при обслуживании модели.
В этом руководстве представлен комплексный пример использования Dataflow в качестве средства запуска Apache Beam. Предполагается, что вы знакомы с BigQuery , Dataflow, Vertex AI и TensorFlow Keras API. Также предполагается, что у вас есть некоторый опыт использования Jupyter Notebooks, например Vertex AI Workbench .
В этом руководстве также предполагается, что вы знакомы с концепциями типов предварительной обработки, задач и параметров в Google Cloud, как описано в разделе Предварительная обработка данных для машинного обучения: параметры и рекомендации .
Цели
- Реализуйте конвейер Apache Beam, используя библиотеку
tf.Transform. - Запустите конвейер в Dataflow.
- Реализуйте модель TensorFlow, используя библиотеку
tf.Transform. - Обучите и используйте модель для прогнозов.
Затраты
В этом руководстве используются следующие платные компоненты Google Cloud:
Чтобы оценить стоимость выполнения этого руководства, предполагая, что вы используете каждый ресурс в течение всего дня, воспользуйтесь предварительно настроенным калькулятором цен .
Прежде чем начать
В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud .
Убедитесь, что для вашего облачного проекта включена оплата. Узнайте, как проверить, включена ли оплата в проекте .
Включите API-интерфейсы Dataflow, Vertex AI и Notebooks. Включите API
Блокноты Jupyter для этого решения
В следующих блокнотах Jupyter показан пример реализации:
- В тетради 1 рассматривается предварительная обработка данных. Подробности представлены в разделе «Реализация конвейера Apache Beam» ниже.
- Блокнот 2 посвящен обучению моделей. Подробности представлены в разделе «Реализация модели TensorFlow» позже.
В следующих разделах вы клонируете эти записные книжки, а затем запускаете их, чтобы узнать, как работает пример реализации.
Запуск экземпляра блокнотов, управляемых пользователем.
В консоли Google Cloud перейдите на страницу Vertex AI Workbench .
На вкладке Блокноты, управляемые пользователями , нажмите +Новый блокнот .
В качестве типа экземпляра выберите TensorFlow Enterprise 2.8 (с LTS) без графических процессоров .
Нажмите Создать .
После создания записной книжки подождите, пока прокси-сервер JupyterLab завершит инициализацию. Когда все будет готово, рядом с именем записной книжки отобразится надпись «Открыть JupyterLab» .
Клонировать блокнот
На вкладке «Блокноты, управляемые пользователями» рядом с именем блокнота нажмите « Открыть JupyterLab» . Интерфейс JupyterLab откроется в новой вкладке.
Если JupyterLab отображает диалоговое окно «Рекомендуется сборка» , нажмите «Отмена» , чтобы отклонить предложенную сборку.
На вкладке «Лаунчер» нажмите «Терминал» .
В окне терминала клонируйте блокнот:
git clone https://github.com/GoogleCloudPlatform/training-data-analyst
Реализация конвейера Apache Beam
В этом и следующем разделах «Запуск конвейера в потоке данных» представлены обзор и контекст блокнота 1. В блокноте представлен практический пример, описывающий, как использовать библиотеку tf.Transform для предварительной обработки данных. В этом примере используется набор данных Natality, который используется для прогнозирования веса ребенка на основе различных входных данных. Данные хранятся в общедоступной таблице рождаемости в BigQuery.
Запустить блокнот 1
В интерфейсе JupyterLab нажмите «Файл» > «Открыть по пути» , а затем введите следующий путь:
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_01.ipynbНажмите «Редактировать» > «Очистить все выходные данные» .
В разделе «Установить необходимые пакеты» выполните первую ячейку для запуска команды
pip install apache-beam.Последняя часть вывода выглядит следующим образом:
Successfully installed ...Вы можете игнорировать ошибки зависимостей в выводе. Перезапускать ядро пока не нужно.
Выполните вторую ячейку, чтобы запустить команду
pip install tensorflow-transform. Последняя часть вывода выглядит следующим образом:Successfully installed ... Note: you may need to restart the kernel to use updated packages.Вы можете игнорировать ошибки зависимостей в выводе.
Нажмите «Ядро» > «Перезапустить ядро» .
Выполните ячейки в разделах «Подтвердите установленные пакеты» и «Создайте файл setup.py для установки пакетов в контейнеры потока данных» .
В разделе «Установить глобальные флаги» рядом с
PROJECTиBUCKETзаменитеyour-projectна идентификатор своего облачного проекта, а затем выполните ячейку.Выполните все оставшиеся ячейки до последней ячейки в тетради. Информацию о том, что делать в каждой ячейке, смотрите в инструкции в тетради.
Обзор трубопровода
В примере с записной книжкой Dataflow запускает конвейер tf.Transform в масштабе для подготовки данных и создания артефактов преобразования. В последующих разделах этого документа описываются функции, выполняющие каждый шаг конвейера. Общие этапы конвейера следующие:
- Чтение данных обучения из BigQuery.
- Анализируйте и преобразуйте данные обучения с помощью библиотеки
tf.Transform. - Запишите преобразованные данные обучения в Cloud Storage в формате TFRecord .
- Прочтите данные оценки из BigQuery.
- Преобразуйте данные оценки с помощью графика
transform_fn, созданного на шаге 2. - Запишите преобразованные данные обучения в Cloud Storage в формате TFRecord.
- Запишите артефакты преобразования в Cloud Storage, которые позже будут использоваться для создания и экспорта модели.
В следующем примере показан код Python для всего конвейера. В следующих разделах приводятся пояснения и списки кодов для каждого шага.
def run_transformation_pipeline(args):
pipeline_options = beam.pipeline.PipelineOptions(flags=[], **args)
runner = args['runner']
data_size = args['data_size']
transformed_data_location = args['transformed_data_location']
transform_artefact_location = args['transform_artefact_location']
temporary_dir = args['temporary_dir']
debug = args['debug']
# Instantiate the pipeline
with beam.Pipeline(runner, options=pipeline_options) as pipeline:
with impl.Context(temporary_dir):
# Preprocess train data
step = 'train'
# Read raw train data from BigQuery
raw_train_dataset = read_from_bq(pipeline, step, data_size)
# Analyze and transform raw_train_dataset
transformed_train_dataset, transform_fn = analyze_and_transform(raw_train_dataset, step)
# Write transformed train data to sink as tfrecords
write_tfrecords(transformed_train_dataset, transformed_data_location, step)
# Preprocess evaluation data
step = 'eval'
# Read raw eval data from BigQuery
raw_eval_dataset = read_from_bq(pipeline, step, data_size)
# Transform eval data based on produced transform_fn
transformed_eval_dataset = transform(raw_eval_dataset, transform_fn, step)
# Write transformed eval data to sink as tfrecords
write_tfrecords(transformed_eval_dataset, transformed_data_location, step)
# Write transformation artefacts
write_transform_artefacts(transform_fn, transform_artefact_location)
# (Optional) for debugging, write transformed data as text
step = 'debug'
# Write transformed train data as text if debug enabled
if debug == True:
write_text(transformed_train_dataset, transformed_data_location, step)
Чтение необработанных данных обучения из BigQuery.
Первый шаг — прочитать необработанные данные обучения из BigQuery с помощью функции read_from_bq . Эта функция возвращает объект raw_dataset , извлеченный из BigQuery. Вы передаете значение data_size и значение step train или eval . Исходный запрос BigQuery создается с использованием функции get_source_query , как показано в следующем примере:
def read_from_bq(pipeline, step, data_size):
source_query = get_source_query(step, data_size)
raw_data = (
pipeline
| '{} - Read Data from BigQuery'.format(step) >> beam.io.Read(
beam.io.BigQuerySource(query=source_query, use_standard_sql=True))
| '{} - Clean up Data'.format(step) >> beam.Map(prep_bq_row)
)
raw_metadata = create_raw_metadata()
raw_dataset = (raw_data, raw_metadata)
return raw_dataset
Прежде чем выполнять предварительную обработку tf.Transform , вам может потребоваться выполнить типичную обработку на основе Apache Beam, включая обработку карт, фильтров, групп и окон. В примере код очищает записи, считанные из BigQuery, с помощью метода beam.Map(prep_bq_row) , где prep_bq_row — пользовательская функция. Эта пользовательская функция преобразует числовой код категориального признака в удобочитаемые метки.
Кроме того, чтобы использовать библиотеку tf.Transform для анализа и преобразования объекта raw_data , извлеченного из BigQuery, вам необходимо создать объект raw_dataset , который представляет собой кортеж объектов raw_data и raw_metadata . Объект raw_metadata создается с помощью функции create_raw_metadata следующим образом:
CATEGORICAL_FEATURE_NAMES = ['is_male', 'mother_race']
NUMERIC_FEATURE_NAMES = ['mother_age', 'plurality', 'gestation_weeks']
TARGET_FEATURE_NAME = 'weight_pounds'
def create_raw_metadata():
feature_spec = dict(
[(name, tf.io.FixedLenFeature([], tf.string)) for name in CATEGORICAL_FEATURE_NAMES] +
[(name, tf.io.FixedLenFeature([], tf.float32)) for name in NUMERIC_FEATURE_NAMES] +
[(TARGET_FEATURE_NAME, tf.io.FixedLenFeature([], tf.float32))])
raw_metadata = dataset_metadata.DatasetMetadata(
schema_utils.schema_from_feature_spec(feature_spec))
return raw_metadata
Когда вы выполняете ячейку в записной книжке, которая следует сразу за ячейкой, определяющей этот метод, отображается содержимое объекта raw_metadata.schema . Он включает в себя следующие столбцы:
-
gestation_weeks(тип:FLOAT) -
is_male(тип:BYTES) -
mother_age(тип:FLOAT) -
mother_race(тип:BYTES) -
plurality(тип:FLOAT) -
weight_pounds(тип:FLOAT)
Преобразование необработанных данных обучения
Представьте, что вы хотите применить типичные преобразования предварительной обработки к входным необработанным функциям обучающих данных, чтобы подготовить их к машинному обучению. Эти преобразования включают как полнопроходные операции, так и операции на уровне экземпляра, как показано в следующей таблице:
| Функция ввода | Трансформация | Нужна статистика | Тип | Функция вывода |
|---|---|---|---|---|
weight_pound | Никто | Никто | NA | weight_pound |
mother_age | Нормализовать | имею в виду, вар | Полный проход | mother_age_normalized |
mother_age | Разделение на сегменты одинакового размера | квантили | Полный проход | mother_age_bucketized |
mother_age | Вычислить журнал | Никто | Уровень экземпляра | mother_age_log |
plurality | Укажите, один или несколько детей | Никто | Уровень экземпляра | is_multiple |
is_multiple | Преобразование номинальных значений в числовой индекс | словарный запас | Полный проход | is_multiple_index |
gestation_weeks | Масштаб от 0 до 1 | мин, макс | Полный проход | gestation_weeks_scaled |
mother_race | Преобразование номинальных значений в числовой индекс | словарный запас | Полный проход | mother_race_index |
is_male | Преобразование номинальных значений в числовой индекс | словарный запас | Полный проход | is_male_index |
Эти преобразования реализованы в функции preprocess_fn , которая ожидает словарь тензоров ( input_features ) и возвращает словарь обработанных функций ( output_features ).
В следующем коде показана реализация функции preprocess_fn с использованием API полнопроходного преобразования tf.Transform (с префиксом tft. ) и TensorFlow (с префиксом tf. ) операций уровня экземпляра:
def preprocess_fn(input_features):
output_features = {}
# target feature
output_features['weight_pounds'] = input_features['weight_pounds']
# normalization
output_features['mother_age_normalized'] = tft.scale_to_z_score(input_features['mother_age'])
# scaling
output_features['gestation_weeks_scaled'] = tft.scale_to_0_1(input_features['gestation_weeks'])
# bucketization based on quantiles
output_features['mother_age_bucketized'] = tft.bucketize(input_features['mother_age'], num_buckets=5)
# you can compute new features based on custom formulas
output_features['mother_age_log'] = tf.math.log(input_features['mother_age'])
# or create flags/indicators
is_multiple = tf.as_string(input_features['plurality'] > tf.constant(1.0))
# convert categorical features to indexed vocab
output_features['mother_race_index'] = tft.compute_and_apply_vocabulary(input_features['mother_race'], vocab_filename='mother_race')
output_features['is_male_index'] = tft.compute_and_apply_vocabulary(input_features['is_male'], vocab_filename='is_male')
output_features['is_multiple_index'] = tft.compute_and_apply_vocabulary(is_multiple, vocab_filename='is_multiple')
return output_features
Платформа tf.Transform имеет несколько других преобразований в дополнение к трансформациям из предыдущего примера, включая те, которые перечислены в следующей таблице:
| Трансформация | Применяется к | Описание |
|---|---|---|
scale_by_min_max | Числовые функции | Масштабирует числовой столбец в диапазон [ output_min , output_max ] |
scale_to_0_1 | Числовые функции | Возвращает столбец, который является входным столбцом, масштабированным до диапазона [ 0 , 1 ] |
scale_to_z_score | Числовые функции | Возвращает стандартизированный столбец со средним значением 0 и отклонением 1. |
tfidf | Текстовые функции | Сопоставляет термины в x с их частотой терминов * обратная частота документов |
compute_and_apply_vocabulary | Категориальные особенности | Создает словарь для категориального признака и сопоставляет его с целым числом с помощью этого словаря. |
ngrams | Текстовые функции | Создает SparseTensor из n-грамм. |
hash_strings | Категориальные особенности | Хеширует строки в сегменты |
pca | Числовые функции | Вычисляет PCA для набора данных, используя смещенную ковариацию. |
bucketize | Числовые функции | Возвращает сегментированный столбец одинакового размера (на основе квантилей) с индексом сегмента, назначенным каждому входу. |
Чтобы применить преобразования, реализованные в функции preprocess_fn , к объекту raw_train_dataset , созданному на предыдущем этапе конвейера, вы используете метод AnalyzeAndTransformDataset . Этот метод ожидает объект raw_dataset в качестве входных данных, применяет функцию preprocess_fn и создает объект transformed_dataset и график transform_fn . Следующий код иллюстрирует эту обработку:
def analyze_and_transform(raw_dataset, step):
transformed_dataset, transform_fn = (
raw_dataset
| '{} - Analyze & Transform'.format(step) >> tft_beam.AnalyzeAndTransformDataset(
preprocess_fn, output_record_batches=True)
)
return transformed_dataset, transform_fn
Преобразования применяются к необработанным данным в два этапа: этап анализа и этап преобразования. На рисунке 3 далее в этом документе показано, как метод AnalyzeAndTransformDataset разбивается на метод AnalyzeDataset и метод TransformDataset .
Фаза анализа
На этапе анализа необработанные данные обучения анализируются в рамках полного процесса для вычисления статистики, необходимой для преобразований. Это включает в себя вычисление среднего значения, дисперсии, минимума, максимума, квантилей и словарного запаса. Процесс анализа ожидает необработанный набор данных (необработанные данные плюс необработанные метаданные) и выдает два результата:
-
transform_fn: граф TensorFlow, который содержит вычисленную статистику на этапе анализа и логику преобразования (которая использует статистику) в качестве операций уровня экземпляра. Как обсуждается позже в разделе «Сохранение графика» , графикtransform_fnсохраняется для прикрепления к функцииserving_fn. Это позволяет применить то же преобразование к точкам данных онлайн-прогноза. -
transform_metadata: объект, описывающий ожидаемую схему данных после преобразования.
Этап анализа проиллюстрирован на следующей диаграмме, рисунок 1:

tf.Transform . Анализаторы tf.Transform включают min , max , sum , size , mean , var , covariance , quantiles , vocabulary и pca .
Фаза преобразования
На этапе преобразования граф transform_fn , созданный на этапе анализа, используется для преобразования необработанных данных обучения в процессе уровня экземпляра с целью создания преобразованных данных обучения. Преобразованные данные обучения объединяются с преобразованными метаданными (созданными на этапе анализа) для создания набора данных transformed_train_dataset .
Фаза преобразования проиллюстрирована на следующей диаграмме, рисунок 2:

tf.Transform . Для предварительной обработки функций вы вызываете необходимые преобразования tensorflow_transform (импортированные в код как tft ) в вашей реализации функции preprocess_fn . Например, когда вы вызываете операции tft.scale_to_z_score , библиотека tf.Transform преобразует этот вызов функции в анализаторы среднего и дисперсии, вычисляет статистику на этапе анализа, а затем применяет эту статистику для нормализации числового признака на этапе преобразования. Все это делается автоматически путем вызова метода AnalyzeAndTransformDataset(preprocess_fn) .
Объект transformed_metadata.schema , созданный этим вызовом, включает в себя следующие столбцы:
-
gestation_weeks_scaled(тип:FLOAT) -
is_male_index(тип:INT, is_categorical:True) -
is_multiple_index(тип:INT, is_categorical:True) -
mother_age_bucketized(тип:INT, is_categorical:True) -
mother_age_log(тип:FLOAT) -
mother_age_normalized(тип:FLOAT) -
mother_race_index(тип:INT, is_categorical:True) -
weight_pounds(тип:FLOAT)
Как объяснялось в разделе «Операции предварительной обработки» в первой части этой серии статей, преобразование объектов преобразует категориальные объекты в числовое представление. После преобразования категориальные признаки представляются целочисленными значениями. В сущности transformed_metadata.schema флаг is_categorical для столбцов типа INT указывает, представляет ли столбец категориальный признак или настоящий числовой признак.
Запись преобразованных обучающих данных
После предварительной обработки обучающих данных с помощью функции preprocess_fn на этапах анализа и преобразования вы можете записать данные в приемник, которые будут использоваться для обучения модели TensorFlow. Когда вы выполняете конвейер Apache Beam с помощью Dataflow, приемником является облачное хранилище. В противном случае приемником является локальный диск. Хотя вы можете записывать данные в виде файла CSV с форматированными файлами фиксированной ширины, рекомендуемым форматом файлов для наборов данных TensorFlow является формат TFRecord. Это простой двоичный формат, ориентированный на записи, который состоит из буферных сообщений протокола tf.train.Example .
Каждая запись tf.train.Example содержит одну или несколько функций. Они преобразуются в тензоры, когда передаются в модель для обучения. Следующий код записывает преобразованный набор данных в файлы TFRecord в указанном месте:
def write_tfrecords(transformed_dataset, location, step):
from tfx_bsl.coders import example_coder
transformed_data, transformed_metadata = transformed_dataset
(
transformed_data
| '{} - Encode Transformed Data'.format(step) >> beam.FlatMapTuple(
lambda batch, _: example_coder.RecordBatchToExamples(batch))
| '{} - Write Transformed Data'.format(step) >> beam.io.WriteToTFRecord(
file_path_prefix=os.path.join(location,'{}'.format(step)),
file_name_suffix='.tfrecords')
)
Чтение, преобразование и запись оценочных данных
После того как вы преобразуете данные обучения и создадите график transform_fn , вы можете использовать его для преобразования данных оценки. Сначала вы считываете и очищаете оценочные данные из BigQuery с помощью функции read_from_bq , описанной ранее в разделе Чтение необработанных обучающих данных из BigQuery , и передаёте значение eval для параметра step . Затем вы используете следующий код для преобразования необработанного набора оценочных данных ( raw_dataset ) в ожидаемый преобразованный формат ( transformed_dataset ):
def transform(raw_dataset, transform_fn, step):
transformed_dataset = (
(raw_dataset, transform_fn)
| '{} - Transform'.format(step) >> tft_beam.TransformDataset(output_record_batches=True)
)
return transformed_dataset
При преобразовании оценочных данных применяются только операции уровня экземпляра, используя как логику графа transform_fn , так и статистику, вычисленную на этапе анализа в обучающих данных. Другими словами, вы не анализируете данные оценки полнопроходным способом для вычисления новых статистических данных, таких как среднее значение и дисперсия для нормализации z-показателя числовых функций в данных оценки. Вместо этого вы используете вычисленную статистику из данных обучения для преобразования данных оценки на уровне экземпляра.
Поэтому вы используете метод AnalyzeAndTransform в контексте обучающих данных для вычисления статистики и преобразования данных. В то же время вы используете метод TransformDataset в контексте преобразования данных оценки, чтобы преобразовать данные только с использованием статистики, вычисленной на основе обучающих данных.
Затем вы записываете данные в приемник (Cloud Storage или локальный диск, в зависимости от бегуна) в формате TFRecord для оценки модели TensorFlow в процессе обучения. Для этого вы используете функцию write_tfrecords , которая обсуждается в разделе «Запись преобразованных обучающих данных» . На следующей диаграмме (рис. 3) показано, как график transform_fn , созданный на этапе анализа обучающих данных, используется для преобразования оценочных данных.

transform_fn .Сохраните график
Последним шагом в конвейере предварительной обработки tf.Transform является сохранение артефактов, в том числе графа transform_fn , созданного на этапе анализа обучающих данных. Код для хранения артефактов показан в следующей функции write_transform_artefacts :
def write_transform_artefacts(transform_fn, location):
(
transform_fn
| 'Write Transform Artifacts' >> transform_fn_io.WriteTransformFn(location)
)
Эти артефакты будут использоваться позже для обучения модели и экспорта для обслуживания. Также создаются следующие артефакты, как показано в следующем разделе:
-
saved_model.pb: представляет граф TensorFlow, который включает логику преобразования (графtransform_fn), который должен быть прикреплен к интерфейсу обслуживания модели для преобразования необработанных точек данных в преобразованный формат. -
variables: включает статистику, вычисленную на этапе анализа обучающих данных, и используется в логике преобразования в артефактеsaved_model.pb. -
assets: включает файлы словаря, по одному для каждого категориального признака, обработанного с помощью методаcompute_and_apply_vocabulary, которые будут использоваться во время обслуживания для преобразования входного необработанного номинального значения в числовой индекс. -
transformed_metadata: каталог, содержащий файлschema.json, описывающий схему преобразованных данных.
Запустите конвейер в Dataflow
После определения конвейера tf.Transform вы запускаете его с помощью Dataflow. На следующей диаграмме (рис. 4) показан граф выполнения потока данных конвейера tf.Transform , описанного в примере.
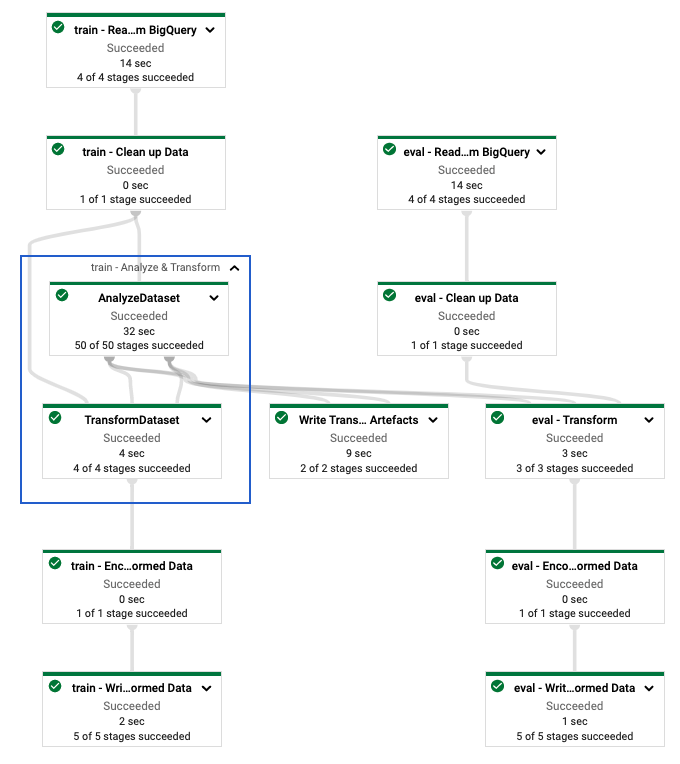
tf.Transform . После выполнения конвейера потока данных для предварительной обработки данных обучения и оценки вы можете изучить созданные объекты в Cloud Storage, выполнив последнюю ячейку в записной книжке. Фрагменты кода в этом разделе показывают результаты, где YOUR_BUCKET_NAME — это имя вашего сегмента Cloud Storage.
Преобразованные данные обучения и оценки в формате TFRecord хранятся в следующем месте:
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed
Артефакты преобразования создаются в следующем месте:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform
Следующий список представляет собой выходные данные конвейера, показывающие созданные объекты данных и артефакты:
transformed data:
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/eval-00000-of-00001.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00000-of-00002.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00001-of-00002.tfrecords
transformed metadata:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/asset_map
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/schema.pbtxt
transform artefact:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/saved_model.pb
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/variables/
transform assets:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_male
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_multiple
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/mother_race
Реализовать модель TensorFlow
В этом и следующем разделах « Обучение и использование модели для прогнозирования» представлены обзор и контекст для Блокнота 2. В блокноте представлен пример модели машинного обучения для прогнозирования веса ребенка. В этом примере модель TensorFlow реализована с использованием API Keras. Модель использует данные и артефакты, создаваемые конвейером предварительной обработки tf.Transform , описанным ранее.
Запустить Блокнот 2
В интерфейсе JupyterLab нажмите «Файл» > «Открыть по пути» , а затем введите следующий путь:
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_02.ipynbНажмите «Редактировать» > «Очистить все выходные данные» .
В разделе «Установить необходимые пакеты» выполните первую ячейку, чтобы запустить команду
pip install tensorflow-transform.Последняя часть вывода выглядит следующим образом:
Successfully installed ... Note: you may need to restart the kernel to use updated packages.Вы можете игнорировать ошибки зависимостей в выводе.
В меню «Ядро» выберите «Перезапустить ядро» .
Выполните ячейки в разделах «Подтвердите установленные пакеты» и «Создайте файл setup.py для установки пакетов в контейнеры потока данных» .
В разделе «Установить глобальные флаги» рядом с
PROJECTиBUCKETзаменитеyour-projectна идентификатор своего облачного проекта, а затем выполните ячейку.Выполните все оставшиеся ячейки до последней ячейки в тетради. Информацию о том, что делать в каждой ячейке, смотрите в инструкции в тетради.
Обзор создания модели
Этапы создания модели следующие:
- Создайте столбцы объектов, используя информацию о схеме, которая хранится в каталоге
transformed_metadata. - Создайте широкую и глубокую модель с помощью API Keras, используя столбцы функций в качестве входных данных для модели.
- Создайте функцию
tfrecords_input_fnдля чтения и анализа данных обучения и оценки с использованием артефактов преобразования. - Обучите и оцените модель.
- Экспортируйте обученную модель, определив функцию
serving_fn, к которой прикреплен графикtransform_fn. - Проверьте экспортированную модель с помощью инструмента
saved_model_cli. - Используйте экспортированную модель для прогнозирования.
В этом документе не объясняется, как построить модель, поэтому в нем не обсуждается подробно, как модель была построена или обучена. Однако в следующих разделах показано, как информация, хранящаяся в каталоге transform_metadata , созданном процессом tf.Transform , используется для создания столбцов функций модели. В документе также показано, как график transform_fn , который также создается процессом tf.Transform , используется в serving_fn , когда модель экспортируется для обслуживания.
Используйте сгенерированные артефакты преобразования при обучении модели.
Когда вы обучаете модель TensorFlow, вы используете преобразованные объекты train и eval , созданные на предыдущем этапе обработки данных. Эти объекты хранятся в виде сегментированных файлов в формате TFRecord. Информация о схеме в каталоге transformed_metadata , созданная на предыдущем шаге, может быть полезна при анализе данных (объекты tf.train.Example ) для передачи в модель для обучения и оценки.
Анализ данных
Поскольку вы читаете файлы в формате TFRecord, чтобы передать в модель данные обучения и оценки, вам необходимо проанализировать каждый объект tf.train.Example в файлах, чтобы создать словарь функций (тензоров). Это гарантирует, что объекты будут сопоставлены с входным слоем модели с помощью столбцов объектов, которые действуют как интерфейс обучения и оценки модели. Для анализа данных вы используете объект TFTransformOutput , созданный из артефактов, созданных на предыдущем шаге:
Создайте объект
TFTransformOutputиз артефактов, созданных и сохраненных на предыдущем этапе предварительной обработки, как описано в разделе «Сохранение графа» :tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)Извлеките объект
feature_specиз объектаTFTransformOutput:tf_transform_output.transformed_feature_spec()Используйте объект
feature_spec, чтобы указать функции, содержащиеся в объектеtf.train.Example, как в функцииtfrecords_input_fn:def tfrecords_input_fn(files_name_pattern, batch_size=512): tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR) TARGET_FEATURE_NAME = 'weight_pounds' batched_dataset = tf.data.experimental.make_batched_features_dataset( file_pattern=files_name_pattern, batch_size=batch_size, features=tf_transform_output.transformed_feature_spec(), reader=tf.data.TFRecordDataset, label_key=TARGET_FEATURE_NAME, shuffle=True).prefetch(tf.data.experimental.AUTOTUNE) return batched_dataset
Создайте столбцы функций
Конвейер создает информацию о схеме в каталоге transformed_metadata , которая описывает схему преобразованных данных, ожидаемых моделью для обучения и оценки. Схема содержит имя объекта и тип данных, например:
-
gestation_weeks_scaled(тип:FLOAT) -
is_male_index(тип:INT, is_categorical:True) -
is_multiple_index(тип:INT, is_categorical:True) -
mother_age_bucketized(тип:INT, is_categorical:True) -
mother_age_log(тип:FLOAT) -
mother_age_normalized(тип:FLOAT) -
mother_race_index(тип:INT, is_categorical:True) -
weight_pounds(тип:FLOAT)
Чтобы просмотреть эту информацию, используйте следующие команды:
transformed_metadata = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR).transformed_metadata
transformed_metadata.schema
Следующий код показывает, как использовать имя функции для создания столбцов функции:
def create_wide_and_deep_feature_columns():
deep_feature_columns = []
wide_feature_columns = []
inputs = {}
categorical_columns = {}
# Select features you've checked from the metadata
# Categorical features are associated with the vocabulary size (starting from 0)
numeric_features = ['mother_age_log', 'mother_age_normalized', 'gestation_weeks_scaled']
categorical_features = [('is_male_index', 1), ('is_multiple_index', 1),
('mother_age_bucketized', 4), ('mother_race_index', 10)]
for feature in numeric_features:
deep_feature_columns.append(tf.feature_column.numeric_column(feature))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='float32')
for feature, vocab_size in categorical_features:
categorical_columns[feature] = (
tf.feature_column.categorical_column_with_identity(feature, num_buckets=vocab_size+1))
wide_feature_columns.append(tf.feature_column.indicator_column(categorical_columns[feature]))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='int64')
mother_race_X_mother_age_bucketized = tf.feature_column.crossed_column(
[categorical_columns['mother_age_bucketized'],
categorical_columns['mother_race_index']], 55)
wide_feature_columns.append(tf.feature_column.indicator_column(mother_race_X_mother_age_bucketized))
mother_race_X_mother_age_bucketized_embedded = tf.feature_column.embedding_column(
mother_race_X_mother_age_bucketized, 5)
deep_feature_columns.append(mother_race_X_mother_age_bucketized_embedded)
return wide_feature_columns, deep_feature_columns, inputs
Код создает столбец tf.feature_column.numeric_column для числовых функций и столбец tf.feature_column.categorical_column_with_identity для категориальных функций.
Вы также можете создавать столбцы расширенных функций, как описано в Варианте C: TensorFlow в первой части этой серии. В примере, использованном для этой серии, создается новый объект mother_race_X_mother_age_bucketized путем скрещивания функций mother_race и mother_age_bucketized с использованием столбца объекта tf.feature_column.crossed_column . Низкоразмерное, плотное представление этого перекрестного объекта создается с использованием столбца объекта tf.feature_column.embedding_column .
На следующей диаграмме (рис. 5) показаны преобразованные данные и то, как преобразованные метаданные используются для определения и обучения модели TensorFlow:

Экспортируйте модель для обслуживания прогнозов.
После обучения модели TensorFlow с помощью Keras API вы экспортируете обученную модель как объект SavedModel, чтобы она могла предоставлять новые точки данных для прогнозирования. При экспорте модели необходимо определить ее интерфейс, то есть схему входных объектов, которая ожидается во время обслуживания. Эта схема входных объектов определяется в serving_fn , как показано в следующем коде:
def export_serving_model(model, output_dir):
tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)
# The layer has to be saved to the model for Keras tracking purposes.
model.tft_layer = tf_transform_output.transform_features_layer()
@tf.function
def serveing_fn(uid, is_male, mother_race, mother_age, plurality, gestation_weeks):
features = {
'is_male': is_male,
'mother_race': mother_race,
'mother_age': mother_age,
'plurality': plurality,
'gestation_weeks': gestation_weeks
}
transformed_features = model.tft_layer(features)
outputs = model(transformed_features)
# The prediction results have multiple elements in general.
# But we need only the first element in our case.
outputs = tf.map_fn(lambda item: item[0], outputs)
return {'uid': uid, 'weight': outputs}
concrete_serving_fn = serveing_fn.get_concrete_function(
tf.TensorSpec(shape=[None], dtype=tf.string, name='uid'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='is_male'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='mother_race'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='mother_age'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='plurality'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='gestation_weeks')
)
signatures = {'serving_default': concrete_serving_fn}
model.save(output_dir, save_format='tf', signatures=signatures)
Во время обслуживания модель ожидает точки данных в их необработанной форме (то есть необработанные функции до преобразований). Таким образом, serving_fn получает необработанные функции и сохраняет их в объекте features в виде словаря Python. Однако, как обсуждалось ранее, обученная модель ожидает точки данных в преобразованной схеме. Чтобы преобразовать необработанные объекты в объекты transformed_features , ожидаемые интерфейсом модели, вы применяете сохраненный график transform_fn к объекту features , выполнив следующие шаги:
Создайте объект
TFTransformOutputиз артефактов, созданных и сохраненных на предыдущем этапе предварительной обработки:tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)Создайте объект
TransformFeaturesLayerиз объектаTFTransformOutput:model.tft_layer = tf_transform_output.transform_features_layer()Примените график
transform_fn, используя объектTransformFeaturesLayer:transformed_features = model.tft_layer(features)
Следующая диаграмма (рис. 6) иллюстрирует последний этап экспорта модели для обслуживания:

transform_fn . Обучите и используйте модель для прогнозов
Вы можете обучать модель локально, выполняя ячейки блокнота. Примеры упаковки кода и масштабного обучения модели с помощью Vertex AI Training см. в примерах и руководствах в репозитории Google Cloudml-samples на GitHub.
Когда вы проверяете экспортированный объект SavedModel с помощью инструмента saved_model_cli , вы видите, что inputs элементы определения подписи signature_def включают необработанные функции, как показано в следующем примере:
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input(s):
inputs['gestation_weeks'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_gestation_weeks:0
inputs['is_male'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_is_male:0
inputs['mother_age'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_mother_age:0
inputs['mother_race'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_mother_race:0
inputs['plurality'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_plurality:0
inputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_uid:0
The given SavedModel SignatureDef contains the following output(s):
outputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: StatefulPartitionedCall_6:0
outputs['weight'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: StatefulPartitionedCall_6:1
Method name is: tensorflow/serving/predict
Остальные ячейки блокнота показывают, как использовать экспортированную модель для локального прогнозирования и как развернуть модель в качестве микросервиса с помощью Vertex AI Prediction. Важно подчеркнуть, что точка входных (выборочных) данных в обоих случаях находится в необработанной схеме.
Очистить
Чтобы избежать дополнительных расходов с вашей учетной записи Google Cloud за ресурсы, используемые в этом руководстве, удалите проект, содержащий ресурсы.
Удалить проект
В консоли Google Cloud перейдите на страницу «Управление ресурсами» .
В списке проектов выберите проект, который хотите удалить, и нажмите «Удалить» .
В диалоговом окне введите идентификатор проекта, а затем нажмите «Завершить работу» , чтобы удалить проект.
Что дальше
- Чтобы узнать о концепциях, проблемах и вариантах предварительной обработки данных для машинного обучения в Google Cloud, прочтите первую статью этой серии « Предварительная обработка данных для машинного обучения: варианты и рекомендации» .
- Дополнительные сведения о том, как реализовать, упаковать и запустить конвейер tf.Transform в Dataflow, см. в образце «Прогнозирование дохода с помощью набора данных переписи» .
- Пройдите специализацию Coursera по машинному обучению с помощью TensorFlow в Google Cloud .
- Узнайте о лучших методах разработки машинного обучения в Правилах машинного обучения .
- Дополнительные эталонные архитектуры, диаграммы и рекомендации можно найти в Центре облачной архитектуры .