
W tym samouczku pokazano, jak używać TensorFlow Transform (biblioteki tf.Transform ) do implementowania wstępnego przetwarzania danych na potrzeby uczenia maszynowego (ML). Biblioteka tf.Transform dla TensorFlow umożliwia definiowanie transformacji danych zarówno na poziomie instancji, jak i w trybie pełnego przejścia za pośrednictwem potoków wstępnego przetwarzania danych. Potoki te są wydajnie wykonywane za pomocą Apache Beam i jako produkty uboczne tworzą wykres TensorFlow, który umożliwia zastosowanie tych samych transformacji podczas prognozowania, co podczas udostępniania modelu.
W tym samouczku przedstawiono kompleksowy przykład użycia Dataflow jako modułu uruchamiającego Apache Beam. Zakłada się, że znasz BigQuery , Dataflow, Vertex AI i interfejs API TensorFlow Keras . Zakłada się również, że masz pewne doświadczenie w korzystaniu z notesów Jupyter, na przykład z Vertex AI Workbench .
W tym samouczku założono również, że znasz koncepcje typów wstępnego przetwarzania, wyzwań i opcji w Google Cloud, zgodnie z opisem w temacie Wstępne przetwarzanie danych dla uczenia maszynowego: opcje i zalecenia .
Cele
- Zaimplementuj potok Apache Beam przy użyciu biblioteki
tf.Transform. - Uruchom potok w Dataflow.
- Zaimplementuj model TensorFlow korzystając z biblioteki
tf.Transform. - Trenuj i używaj modelu do prognozowania.
Koszty
W tym samouczku wykorzystano następujące płatne komponenty Google Cloud:
Aby oszacować koszt uruchomienia tego samouczka, zakładając, że wykorzystujesz wszystkie zasoby przez cały dzień, użyj wstępnie skonfigurowanego kalkulatora cen .
Zanim zaczniesz
W konsoli Google Cloud na stronie wyboru projektu wybierz lub utwórz projekt Google Cloud .
Upewnij się, że w Twoim projekcie w chmurze są włączone rozliczenia. Dowiedz się, jak sprawdzić, czy w projekcie włączono płatności .
Włącz interfejsy API Dataflow, Vertex AI i Notebooks. Włącz interfejsy API
Notatniki Jupyter dla tego rozwiązania
Poniższe notesy Jupyter pokazują przykład implementacji:
- Notatnik 1 obejmuje wstępne przetwarzanie danych. Szczegóły znajdują się w dalszej części sekcji Implementowanie potoku Apache Beam .
- Notatnik 2 obejmuje szkolenie modelowe. Szczegółowe informacje znajdują się w dalszej części sekcji Implementowanie modelu TensorFlow .
W poniższych sekcjach klonujesz te notesy, a następnie uruchamiasz je, aby dowiedzieć się, jak działa przykładowa implementacja.
Uruchom instancję notatników zarządzanych przez użytkownika
W konsoli Google Cloud przejdź do strony Vertex AI Workbench .
Na karcie Notatniki zarządzane przez użytkowników kliknij opcję +Nowy notatnik .
Jako typ instancji wybierz TensorFlow Enterprise 2.8 (z LTS) bez procesorów graficznych .
Kliknij opcję Utwórz .
Po utworzeniu notatnika poczekaj, aż serwer proxy JupyterLab zakończy inicjowanie. Gdy będzie gotowy, obok nazwy notesu wyświetli się Open JupyterLab .
Sklonuj notatnik
Na karcie Notatniki zarządzane przez użytkowników obok nazwy notatnika kliknij Otwórz JupyterLab . Interfejs JupyterLab otwiera się w nowej karcie.
Jeśli JupyterLab wyświetli okno dialogowe Zalecana kompilacja , kliknij Anuluj, aby odrzucić sugerowaną kompilację.
Na karcie Uruchamianie kliknij Terminal .
W oknie terminala sklonuj notatnik:
git clone https://github.com/GoogleCloudPlatform/training-data-analyst
Zaimplementuj potok Apache Beam
Ta sekcja i następna sekcja Uruchamianie potoku w Dataflow zawierają przegląd i kontekst Notatnika 1. Notatnik zawiera praktyczny przykład opisujący sposób używania biblioteki tf.Transform do wstępnego przetwarzania danych. W tym przykładzie wykorzystano zbiór danych Natality, który służy do przewidywania masy ciała dziecka na podstawie różnych danych wejściowych. Dane są przechowywane w publicznej tabeli urodzeń w BigQuery.
Uruchom Notatnik 1
W interfejsie JupyterLab kliknij opcję Plik > Otwórz ze ścieżki , a następnie wprowadź następującą ścieżkę:
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_01.ipynbKliknij Edycja > Wyczyść wszystkie dane wyjściowe .
W sekcji Zainstaluj wymagane pakiety wykonaj pierwszą komórkę, aby uruchomić polecenie
pip install apache-beam.Ostatnia część wyniku jest następująca:
Successfully installed ...Błędy zależności można zignorować w wynikach. Nie musisz jeszcze restartować jądra.
Wykonaj drugą komórkę, aby uruchomić polecenie
pip install tensorflow-transform. Ostatnia część wyniku jest następująca:Successfully installed ... Note: you may need to restart the kernel to use updated packages.Błędy zależności można zignorować w wynikach.
Kliknij Jądro > Uruchom ponownie jądro .
Wykonaj komórki w sekcjach Potwierdź zainstalowane pakiety i Utwórz plik setup.py, aby zainstalować pakiety w kontenerach Dataflow .
W sekcji Ustaw flagi globalne obok
PROJECTiBUCKETzastąpyour-projectidentyfikatorem projektu Cloud, a następnie wykonaj komórkę.Wykonaj wszystkie pozostałe komórki w ostatniej komórce w notatniku. Informacje o tym, co należy zrobić w poszczególnych komórkach, można znaleźć w instrukcjach w notatniku.
Przegląd rurociągu
W przykładzie notesu Dataflow uruchamia potok tf.Transform na dużą skalę, aby przygotować dane i wygenerować artefakty transformacji. W dalszych sekcjach tego dokumentu opisano funkcje wykonujące każdy krok potoku. Ogólne etapy rurociągu są następujące:
- Odczytaj dane szkoleniowe z BigQuery.
- Analizuj i przekształcaj dane szkoleniowe za pomocą biblioteki
tf.Transform. - Zapisz przekształcone dane szkoleniowe w Cloud Storage w formacie TFRecord .
- Przeczytaj dane oceny z BigQuery.
- Przekształć dane oceny, korzystając z wykresu
transform_fnutworzonego w kroku 2. - Zapisz przekształcone dane szkoleniowe w Cloud Storage w formacie TFRecord.
- Zapisz artefakty transformacji w Cloud Storage, które będą później używane do tworzenia i eksportowania modelu.
Poniższy przykład przedstawia kod języka Python dla całego potoku. W poniższych sekcjach znajdują się wyjaśnienia i listy kodów dla każdego kroku.
def run_transformation_pipeline(args):
pipeline_options = beam.pipeline.PipelineOptions(flags=[], **args)
runner = args['runner']
data_size = args['data_size']
transformed_data_location = args['transformed_data_location']
transform_artefact_location = args['transform_artefact_location']
temporary_dir = args['temporary_dir']
debug = args['debug']
# Instantiate the pipeline
with beam.Pipeline(runner, options=pipeline_options) as pipeline:
with impl.Context(temporary_dir):
# Preprocess train data
step = 'train'
# Read raw train data from BigQuery
raw_train_dataset = read_from_bq(pipeline, step, data_size)
# Analyze and transform raw_train_dataset
transformed_train_dataset, transform_fn = analyze_and_transform(raw_train_dataset, step)
# Write transformed train data to sink as tfrecords
write_tfrecords(transformed_train_dataset, transformed_data_location, step)
# Preprocess evaluation data
step = 'eval'
# Read raw eval data from BigQuery
raw_eval_dataset = read_from_bq(pipeline, step, data_size)
# Transform eval data based on produced transform_fn
transformed_eval_dataset = transform(raw_eval_dataset, transform_fn, step)
# Write transformed eval data to sink as tfrecords
write_tfrecords(transformed_eval_dataset, transformed_data_location, step)
# Write transformation artefacts
write_transform_artefacts(transform_fn, transform_artefact_location)
# (Optional) for debugging, write transformed data as text
step = 'debug'
# Write transformed train data as text if debug enabled
if debug == True:
write_text(transformed_train_dataset, transformed_data_location, step)
Odczytuj surowe dane szkoleniowe z BigQuery
Pierwszym krokiem jest odczytanie surowych danych szkoleniowych z BigQuery za pomocą funkcji read_from_bq . Ta funkcja zwraca obiekt raw_dataset wyodrębniony z BigQuery. Przekazujesz wartość data_size i przekazujesz wartość step train lub eval . Zapytanie źródłowe BigQuery jest konstruowane przy użyciu funkcji get_source_query , jak pokazano w poniższym przykładzie:
def read_from_bq(pipeline, step, data_size):
source_query = get_source_query(step, data_size)
raw_data = (
pipeline
| '{} - Read Data from BigQuery'.format(step) >> beam.io.Read(
beam.io.BigQuerySource(query=source_query, use_standard_sql=True))
| '{} - Clean up Data'.format(step) >> beam.Map(prep_bq_row)
)
raw_metadata = create_raw_metadata()
raw_dataset = (raw_data, raw_metadata)
return raw_dataset
Przed wykonaniem wstępnego przetwarzania tf.Transform może być konieczne wykonanie typowego przetwarzania opartego na Apache Beam, w tym przetwarzania mapy, filtru, grupy i okna. W przykładzie kod czyści rekordy odczytane z BigQuery za pomocą metody beam.Map(prep_bq_row) , gdzie prep_bq_row jest funkcją niestandardową. Ta funkcja niestandardowa konwertuje kod numeryczny cechy kategorycznej na etykiety czytelne dla człowieka.
Dodatkowo, aby użyć biblioteki tf.Transform do analizy i transformacji obiektu raw_data wyodrębnionego z BigQuery, należy utworzyć obiekt raw_dataset , będący krotką obiektów raw_data i raw_metadata . Obiekt raw_metadata tworzony jest za pomocą funkcji create_raw_metadata w następujący sposób:
CATEGORICAL_FEATURE_NAMES = ['is_male', 'mother_race']
NUMERIC_FEATURE_NAMES = ['mother_age', 'plurality', 'gestation_weeks']
TARGET_FEATURE_NAME = 'weight_pounds'
def create_raw_metadata():
feature_spec = dict(
[(name, tf.io.FixedLenFeature([], tf.string)) for name in CATEGORICAL_FEATURE_NAMES] +
[(name, tf.io.FixedLenFeature([], tf.float32)) for name in NUMERIC_FEATURE_NAMES] +
[(TARGET_FEATURE_NAME, tf.io.FixedLenFeature([], tf.float32))])
raw_metadata = dataset_metadata.DatasetMetadata(
schema_utils.schema_from_feature_spec(feature_spec))
return raw_metadata
Po uruchomieniu komórki w notatniku, która następuje bezpośrednio po komórce definiującej tę metodę, zostanie wyświetlona zawartość obiektu raw_metadata.schema . Zawiera następujące kolumny:
-
gestation_weeks(typ:FLOAT) -
is_male(typ:BYTES) -
mother_age(typ:FLOAT) -
mother_race(typ:BYTES) -
plurality(typ:FLOAT) -
weight_pounds(typ:FLOAT)
Przekształcaj surowe dane szkoleniowe
Wyobraź sobie, że chcesz zastosować typowe przekształcenia przetwarzania wstępnego do wejściowych surowych funkcji danych szkoleniowych, aby przygotować je do uczenia maszynowego. Transformacje te obejmują zarówno operacje pełnego przebiegu, jak i na poziomie instancji, jak pokazano w poniższej tabeli:
| Funkcja wprowadzania | Transformacja | Potrzebne statystyki | Typ | Funkcja wyjściowa |
|---|---|---|---|---|
weight_pound | Nic | Nic | NA | weight_pound |
mother_age | Normalizować | znaczy, odm | Pełne przejście | mother_age_normalized |
mother_age | Wiaderko o jednakowej wielkości | kwantyle | Pełne przejście | mother_age_bucketized |
mother_age | Oblicz log | Nic | Poziom instancji | mother_age_log |
plurality | Wskaż, czy jest to dziecko jedno czy wielokrotne | Nic | Poziom instancji | is_multiple |
is_multiple | Konwertuj wartości nominalne na indeks liczbowy | słownictwo | Pełne przejście | is_multiple_index |
gestation_weeks | Skala od 0 do 1 | min., maks | Pełne przejście | gestation_weeks_scaled |
mother_race | Konwertuj wartości nominalne na indeks liczbowy | słownictwo | Pełne przejście | mother_race_index |
is_male | Konwertuj wartości nominalne na indeks liczbowy | słownictwo | Pełne przejście | is_male_index |
Transformacje te są implementowane w funkcji preprocess_fn , która oczekuje słownika tensorów ( input_features ) i zwraca słownik przetworzonych cech ( output_features ).
Poniższy kod przedstawia implementację funkcji preprocess_fn przy użyciu interfejsów API transformacji pełnoprzepustowej tf.Transform (z przedrostkiem tft. ) i operacji na poziomie instancji TensorFlow (z przedrostkiem tf. ):
def preprocess_fn(input_features):
output_features = {}
# target feature
output_features['weight_pounds'] = input_features['weight_pounds']
# normalization
output_features['mother_age_normalized'] = tft.scale_to_z_score(input_features['mother_age'])
# scaling
output_features['gestation_weeks_scaled'] = tft.scale_to_0_1(input_features['gestation_weeks'])
# bucketization based on quantiles
output_features['mother_age_bucketized'] = tft.bucketize(input_features['mother_age'], num_buckets=5)
# you can compute new features based on custom formulas
output_features['mother_age_log'] = tf.math.log(input_features['mother_age'])
# or create flags/indicators
is_multiple = tf.as_string(input_features['plurality'] > tf.constant(1.0))
# convert categorical features to indexed vocab
output_features['mother_race_index'] = tft.compute_and_apply_vocabulary(input_features['mother_race'], vocab_filename='mother_race')
output_features['is_male_index'] = tft.compute_and_apply_vocabulary(input_features['is_male'], vocab_filename='is_male')
output_features['is_multiple_index'] = tft.compute_and_apply_vocabulary(is_multiple, vocab_filename='is_multiple')
return output_features
Oprócz tych z poprzedniego przykładu struktura tf.Transform zawiera kilka innych transformacji, w tym te wymienione w poniższej tabeli:
| Transformacja | Dotyczy | Opis |
|---|---|---|
scale_by_min_max | Funkcje numeryczne | Skaluje kolumnę numeryczną do zakresu [ output_min , output_max .] |
scale_to_0_1 | Funkcje numeryczne | Zwraca kolumnę będącą kolumną wejściową przeskalowaną tak, aby zawierała zakres [ 0 , 1 ] |
scale_to_z_score | Funkcje numeryczne | Zwraca standaryzowaną kolumnę ze średnią 0 i wariancją 1 |
tfidf | Funkcje tekstowe | Odwzorowuje terminy w x na ich częstotliwość terminów * odwrotną częstotliwość dokumentu |
compute_and_apply_vocabulary | Cechy kategoryczne | Generuje słownik dla cechy kategorycznej i odwzorowuje go na liczbę całkowitą za pomocą tego słownictwa |
ngrams | Funkcje tekstowe | Tworzy SparseTensor o wartości n-gramów |
hash_strings | Cechy kategoryczne | Miesza ciągi znaków w wiadrach |
pca | Funkcje numeryczne | Oblicza PCA na zbiorze danych przy użyciu obciążonej kowariancji |
bucketize | Funkcje numeryczne | Zwraca kolumnę segmentową o równej wielkości (opartą na kwantylach) z indeksem segmentu przypisanym do każdego wejścia |
Aby zastosować transformacje zaimplementowane w funkcji preprocess_fn do obiektu raw_train_dataset wytworzonego w poprzednim kroku potoku, należy skorzystać z metody AnalyzeAndTransformDataset . Ta metoda oczekuje obiektu raw_dataset jako danych wejściowych, stosuje funkcję preprocess_fn i generuje obiekt transformed_dataset oraz wykres transform_fn . Poniższy kod ilustruje to przetwarzanie:
def analyze_and_transform(raw_dataset, step):
transformed_dataset, transform_fn = (
raw_dataset
| '{} - Analyze & Transform'.format(step) >> tft_beam.AnalyzeAndTransformDataset(
preprocess_fn, output_record_batches=True)
)
return transformed_dataset, transform_fn
Transformacje są stosowane na surowych danych w dwóch fazach: fazie analizy i fazie transformacji. Rysunek 3 w dalszej części tego dokumentu przedstawia rozkład metody AnalyzeAndTransformDataset na metody AnalyzeDataset i TransformDataset .
Faza analizy
W fazie analizy surowe dane szkoleniowe są analizowane w procesie pełnoprzepustowym w celu obliczenia statystyk potrzebnych do transformacji. Obejmuje to obliczanie średniej, wariancji, minimum, maksimum, kwantyli i słownictwa. Proces analizy oczekuje surowego zbioru danych (surowe dane plus surowe metadane) i generuje dwa wyniki:
-
transform_fn: wykres TensorFlow zawierający obliczone statystyki z fazy analizy i logikę transformacji (która wykorzystuje statystyki) jako operacje na poziomie instancji. Jak omówiono później w sekcji Zapisywanie wykresu , wykrestransform_fnjest zapisywany w celu dołączenia do funkcji modeluserving_fn. Dzięki temu możliwe jest zastosowanie tej samej transformacji do punktów danych prognozy online. -
transform_metadata: obiekt opisujący oczekiwany schemat danych po transformacji.
Fazę analizy ilustruje poniższy diagram, rysunek 1:

tf.Transform . Analizatory tf.Transform obejmują min , max , sum , size , mean , var , covariance , quantiles , vocabulary i pca .
Faza transformacji
W fazie transformacji wykres transform_fn utworzony w fazie analizy służy do przekształcania surowych danych szkoleniowych w procesie na poziomie instancji w celu wygenerowania przekształconych danych szkoleniowych. Przekształcone dane szkoleniowe są łączone w pary z przekształconymi metadanymi (wytworzonymi w fazie analizy) w celu wytworzenia zestawu danych transformed_train_dataset .
Fazę transformacji przedstawiono na poniższym schemacie, rysunek 2:

tf.Transform . Aby wstępnie przetworzyć funkcje, wywołujesz wymagane transformacje tensorflow_transform (zaimportowane w kodzie jako tft ) w implementacji funkcji preprocess_fn . Na przykład po wywołaniu operacji tft.scale_to_z_score biblioteka tf.Transform tłumaczy to wywołanie funkcji na analizatory średnich i wariancji, oblicza statystyki w fazie analizy, a następnie stosuje te statystyki do normalizacji cechy liczbowej w fazie transformacji. Wszystko to odbywa się automatycznie poprzez wywołanie metody AnalyzeAndTransformDataset(preprocess_fn) .
Jednostka transformed_metadata.schema utworzona w wyniku tego wywołania zawiera następujące kolumny:
-
gestation_weeks_scaled(typ:FLOAT) -
is_male_index(typ:INT, is_categorical:True) -
is_multiple_index(typ:INT, is_categorical:True) -
mother_age_bucketized(typ:INT, is_categorical:True) -
mother_age_log(typ:FLOAT) -
mother_age_normalized(typ:FLOAT) -
mother_race_index(typ:INT, is_categorical:True) -
weight_pounds(typ:FLOAT)
Jak wyjaśniono w operacjach przetwarzania wstępnego w pierwszej części tej serii, transformacja cech przekształca cechy kategoryczne w reprezentację numeryczną. Po przekształceniu cechy kategoryczne są reprezentowane przez wartości całkowite. W encji transformed_metadata.schema flaga is_categorical dla kolumn typu INT wskazuje, czy kolumna reprezentuje cechę kategoryczną, czy prawdziwą cechę liczbową.
Zapisz przekształcone dane szkoleniowe
Po wstępnym przetworzeniu danych szkoleniowych za pomocą funkcji preprocess_fn w fazach analizy i transformacji można zapisać dane w ujściu, które będą używane do uczenia modelu TensorFlow. Gdy uruchamiasz potok Apache Beam przy użyciu Dataflow, ujściem jest Cloud Storage. W przeciwnym razie ujściem jest dysk lokalny. Chociaż dane można zapisać jako plik CSV zawierający pliki w formacie o stałej szerokości, zalecanym formatem pliku dla zestawów danych TensorFlow jest format TFRecord. Jest to prosty format binarny zorientowany na rekordy, który składa się z komunikatów buforowych protokołu tf.train.Example .
Każdy rekord tf.train.Example zawiera jedną lub więcej funkcji. Są one przekształcane w tensory, gdy są podawane do modelu w celu szkolenia. Poniższy kod zapisuje przekształcony zbiór danych do plików TFRecord w określonej lokalizacji:
def write_tfrecords(transformed_dataset, location, step):
from tfx_bsl.coders import example_coder
transformed_data, transformed_metadata = transformed_dataset
(
transformed_data
| '{} - Encode Transformed Data'.format(step) >> beam.FlatMapTuple(
lambda batch, _: example_coder.RecordBatchToExamples(batch))
| '{} - Write Transformed Data'.format(step) >> beam.io.WriteToTFRecord(
file_path_prefix=os.path.join(location,'{}'.format(step)),
file_name_suffix='.tfrecords')
)
Odczytuj, przekształcaj i zapisuj dane ewaluacyjne
Po przekształceniu danych szkoleniowych i utworzeniu wykresu transform_fn można go użyć do przekształcenia danych oceny. Najpierw odczytujesz i czyścisz dane ewaluacyjne z BigQuery za pomocą funkcji read_from_bq opisanej wcześniej w artykule Odczyt surowych danych szkoleniowych z BigQuery i przekazując wartość eval dla parametru step . Następnie użyj następującego kodu, aby przekształcić surowy zestaw danych ewaluacyjnych ( raw_dataset ) do oczekiwanego przekształconego formatu ( transformed_dataset ):
def transform(raw_dataset, transform_fn, step):
transformed_dataset = (
(raw_dataset, transform_fn)
| '{} - Transform'.format(step) >> tft_beam.TransformDataset(output_record_batches=True)
)
return transformed_dataset
Podczas przekształcania danych oceny obowiązują tylko operacje na poziomie instancji, wykorzystując zarówno logikę na wykresie transform_fn , jak i statystyki obliczone na podstawie fazy analizy w danych szkoleniowych. Innymi słowy, nie analizuje się danych ewaluacyjnych w sposób pełnoprzepustowy w celu obliczenia nowych statystyk, takich jak średnia i wariancja normalizacji cech numerycznych w danych ewaluacyjnych za pomocą wyniku Z. Zamiast tego używasz statystyk obliczonych na podstawie danych szkoleniowych, aby przekształcić dane oceny w sposób na poziomie instancji.
W związku z tym używasz metody AnalyzeAndTransform w kontekście danych szkoleniowych do obliczania statystyk i przekształcania danych. Jednocześnie używasz metody TransformDataset w kontekście przekształcania danych ewaluacyjnych, aby przekształcać dane wyłącznie przy użyciu statystyk obliczonych na danych szkoleniowych.
Następnie zapisujesz dane do ujścia (Cloud Storage lub dysk lokalny, w zależności od modułu uruchamiającego) w formacie TFRecord w celu oceny modelu TensorFlow podczas procesu uczenia. Aby to zrobić, użyj funkcji write_tfrecords omówionej w artykule Zapisywanie przekształconych danych szkoleniowych . Poniższy diagram (rysunek 3) pokazuje, w jaki sposób wykres transform_fn utworzony w fazie analizy danych szkoleniowych jest używany do przekształcania danych oceny.

transform_fn .Zapisz wykres
Ostatnim krokiem w potoku przetwarzania wstępnego tf.Transform jest przechowywanie artefaktów, które obejmują wykres transform_fn generowany w fazie analizy na danych szkoleniowych. Kod do przechowywania artefaktów jest pokazany w następującej funkcji write_transform_artefacts :
def write_transform_artefacts(transform_fn, location):
(
transform_fn
| 'Write Transform Artifacts' >> transform_fn_io.WriteTransformFn(location)
)
Te artefakty zostaną później użyte do uczenia modeli i eksportowania w celu wyświetlenia. Produkowane są również następujące artefakty, jak pokazano w następnej sekcji:
-
saved_model.pb: reprezentuje wykres TensorFlow zawierający logikę transformacji (wykrestransform_fn), który ma zostać dołączony do interfejsu obsługującego model w celu przekształcenia surowych punktów danych do przekształconego formatu. -
variables: obejmuje statystyki obliczone podczas fazy analizy danych szkoleniowych i jest używane w logice transformacji w artefakciesaved_model.pb. -
assets: zawiera pliki słownictwa, po jednym dla każdej cechy kategorycznej przetworzonej metodącompute_and_apply_vocabulary, które mają być użyte podczas udostępniania w celu przekształcenia wejściowej surowej wartości nominalnej na indeks liczbowy. -
transformed_metadata: katalog zawierający plikschema.jsonopisujący schemat przekształconych danych.
Uruchom potok w Dataflow
Po zdefiniowaniu potoku tf.Transform należy go uruchomić przy użyciu Dataflow. Poniższy diagram, rysunek 4, przedstawia wykres wykonania przepływu danych dla potoku tf.Transform opisanego w przykładzie.
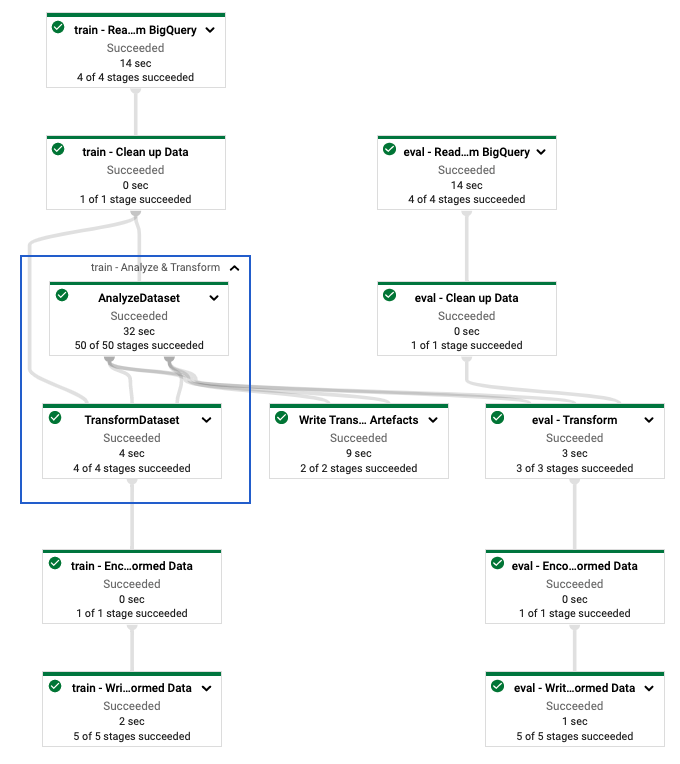
tf.Transform . Po uruchomieniu potoku Dataflow w celu wstępnego przetworzenia danych szkoleniowych i ewaluacyjnych możesz eksplorować utworzone obiekty w Cloud Storage, wykonując ostatnią komórkę w notatniku. Fragmenty kodu w tej sekcji pokazują wyniki, gdzie YOUR_BUCKET_NAME to nazwa Twojego segmentu Cloud Storage.
Przekształcone dane szkoleniowe i ewaluacyjne w formacie TFRecord są przechowywane w następującej lokalizacji:
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed
Artefakty transformacji powstają w następującej lokalizacji:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform
Poniższa lista stanowi wynik potoku, pokazując wytworzone obiekty danych i artefakty:
transformed data:
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/eval-00000-of-00001.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00000-of-00002.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00001-of-00002.tfrecords
transformed metadata:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/asset_map
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/schema.pbtxt
transform artefact:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/saved_model.pb
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/variables/
transform assets:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_male
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_multiple
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/mother_race
Zaimplementuj model TensorFlow
Ta sekcja i następna sekcja, Trenowanie i używanie modelu do przewidywania , zawierają przegląd i kontekst Notatnika 2. Notatnik zawiera przykładowy model ML do przewidywania masy ciała dziecka. W tym przykładzie model TensorFlow jest zaimplementowany przy użyciu interfejsu API Keras. Model wykorzystuje dane i artefakty generowane przez potok przetwarzania wstępnego tf.Transform wyjaśniony wcześniej.
Uruchom Notatnik 2
W interfejsie JupyterLab kliknij opcję Plik > Otwórz ze ścieżki , a następnie wprowadź następującą ścieżkę:
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_02.ipynbKliknij Edycja > Wyczyść wszystkie dane wyjściowe .
W sekcji Zainstaluj wymagane pakiety wykonaj pierwszą komórkę, aby uruchomić polecenie
pip install tensorflow-transform.Ostatnia część wyniku jest następująca:
Successfully installed ... Note: you may need to restart the kernel to use updated packages.Błędy zależności można zignorować w wynikach.
W menu Jądro wybierz opcję Uruchom ponownie jądro .
Wykonaj komórki w sekcjach Potwierdź zainstalowane pakiety i Utwórz plik setup.py, aby zainstalować pakiety w kontenerach Dataflow .
W sekcji Ustaw flagi globalne obok
PROJECTiBUCKETzastąpyour-projectidentyfikatorem projektu Cloud, a następnie wykonaj komórkę.Wykonaj wszystkie pozostałe komórki w ostatniej komórce w notatniku. Informacje o tym, co należy zrobić w poszczególnych komórkach, można znaleźć w instrukcjach w notatniku.
Omówienie tworzenia modelu
Etapy tworzenia modelu są następujące:
- Utwórz kolumny funkcji, korzystając z informacji o schemacie przechowywanych w katalogu
transformed_metadata. - Utwórz szeroki i głęboki model za pomocą interfejsu API Keras, używając kolumn funkcji jako danych wejściowych do modelu.
- Utwórz funkcję
tfrecords_input_fnaby odczytywać i analizować dane szkoleniowe i ewaluacyjne przy użyciu artefaktów transformacji. - Trenuj i oceniaj model.
- Wyeksportuj przeszkolony model, definiując funkcję
serving_fn, do której dołączony jest wykrestransform_fn. - Sprawdź wyeksportowany model za pomocą narzędzia
saved_model_cli. - Użyj wyeksportowanego modelu do prognozowania.
Ten dokument nie wyjaśnia, jak zbudować model, więc nie omawia szczegółowo, w jaki sposób model został zbudowany lub wyszkolony. Jednak w poniższych sekcjach pokazano, w jaki sposób informacje przechowywane w katalogu transform_metadata — generowanym przez proces tf.Transform — są wykorzystywane do tworzenia kolumn funkcji modelu. W dokumencie pokazano również, w jaki sposób wykres transform_fn — który również jest generowany w procesie tf.Transform — jest używany w funkcji serving_fn , gdy model jest eksportowany w celu udostępnienia.
Użyj wygenerowanych artefaktów transformacji w szkoleniu modelu
Podczas uczenia modelu TensorFlow używasz przekształconych obiektów train i eval utworzonych w poprzednim kroku przetwarzania danych. Obiekty te są przechowywane jako pliki podzielone na fragmenty w formacie TFRecord. Informacje o schemacie w katalogu transformed_metadata wygenerowanym w poprzednim kroku mogą być przydatne podczas analizowania danych (obiektów tf.train.Example ) w celu wprowadzenia ich do modelu na potrzeby uczenia i oceny.
Przeanalizuj dane
Ponieważ czytasz pliki w formacie TFRecord w celu zasilania modelu danymi szkoleniowymi i ewaluacyjnymi, musisz przeanalizować każdy obiekt tf.train.Example w plikach, aby utworzyć słownik cech (tensorów). Zapewnia to, że funkcje są mapowane na warstwę wejściową modelu przy użyciu kolumn funkcji, które działają jako interfejs uczenia i oceny modelu. Aby przeanalizować dane, użyj obiektu TFTransformOutput utworzonego na podstawie artefaktów wygenerowanych w poprzednim kroku:
Utwórz obiekt
TFTransformOutputna podstawie artefaktów wygenerowanych i zapisanych w poprzednim kroku przetwarzania wstępnego, zgodnie z opisem w sekcji Zapisywanie wykresu :tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)Wyodrębnij obiekt
feature_specz obiektuTFTransformOutput:tf_transform_output.transformed_feature_spec()Użyj obiektu
feature_spec, aby określić funkcje zawarte w obiekcietf.train.Example, tak jak w funkcjitfrecords_input_fn:def tfrecords_input_fn(files_name_pattern, batch_size=512): tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR) TARGET_FEATURE_NAME = 'weight_pounds' batched_dataset = tf.data.experimental.make_batched_features_dataset( file_pattern=files_name_pattern, batch_size=batch_size, features=tf_transform_output.transformed_feature_spec(), reader=tf.data.TFRecordDataset, label_key=TARGET_FEATURE_NAME, shuffle=True).prefetch(tf.data.experimental.AUTOTUNE) return batched_dataset
Utwórz kolumny funkcji
Potok generuje informacje o schemacie w katalogu transformed_metadata , który opisuje schemat przekształconych danych oczekiwany przez model na potrzeby uczenia i oceny. Schemat zawiera nazwę funkcji i typ danych, na przykład:
-
gestation_weeks_scaled(typ:FLOAT) -
is_male_index(typ:INT, is_categorical:True) -
is_multiple_index(typ:INT, is_categorical:True) -
mother_age_bucketized(typ:INT, is_categorical:True) -
mother_age_log(typ:FLOAT) -
mother_age_normalized(typ:FLOAT) -
mother_race_index(typ:INT, is_categorical:True) -
weight_pounds(typ:FLOAT)
Aby zobaczyć te informacje, użyj następujących poleceń:
transformed_metadata = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR).transformed_metadata
transformed_metadata.schema
Poniższy kod pokazuje, jak używać nazwy funkcji do tworzenia kolumn funkcji:
def create_wide_and_deep_feature_columns():
deep_feature_columns = []
wide_feature_columns = []
inputs = {}
categorical_columns = {}
# Select features you've checked from the metadata
# Categorical features are associated with the vocabulary size (starting from 0)
numeric_features = ['mother_age_log', 'mother_age_normalized', 'gestation_weeks_scaled']
categorical_features = [('is_male_index', 1), ('is_multiple_index', 1),
('mother_age_bucketized', 4), ('mother_race_index', 10)]
for feature in numeric_features:
deep_feature_columns.append(tf.feature_column.numeric_column(feature))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='float32')
for feature, vocab_size in categorical_features:
categorical_columns[feature] = (
tf.feature_column.categorical_column_with_identity(feature, num_buckets=vocab_size+1))
wide_feature_columns.append(tf.feature_column.indicator_column(categorical_columns[feature]))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='int64')
mother_race_X_mother_age_bucketized = tf.feature_column.crossed_column(
[categorical_columns['mother_age_bucketized'],
categorical_columns['mother_race_index']], 55)
wide_feature_columns.append(tf.feature_column.indicator_column(mother_race_X_mother_age_bucketized))
mother_race_X_mother_age_bucketized_embedded = tf.feature_column.embedding_column(
mother_race_X_mother_age_bucketized, 5)
deep_feature_columns.append(mother_race_X_mother_age_bucketized_embedded)
return wide_feature_columns, deep_feature_columns, inputs
Kod tworzy kolumnę tf.feature_column.numeric_column dla obiektów liczbowych i kolumnę tf.feature_column.categorical_column_with_identity dla obiektów kategorialnych.
Możesz także tworzyć kolumny funkcji rozszerzonych, jak opisano w Opcji C: TensorFlow w pierwszej części tej serii. W przykładzie użytym w tej serii tworzona jest nowa cecha, mother_race_X_mother_age_bucketized , poprzez skrzyżowanie cech mother_race i mother_age_bucketized przy użyciu kolumny funkcji tf.feature_column.crossed_column . Niskowymiarowa, gęsta reprezentacja tego skrzyżowanego obiektu jest tworzona przy użyciu kolumny cech tf.feature_column.embedding_column .
Poniższy diagram, rysunek 5, przedstawia przekształcone dane i sposób wykorzystania przekształconych metadanych do definiowania i uczenia modelu TensorFlow:

Wyeksportuj model do prognozowania wyświetlania
Po przeszkoleniu modelu TensorFlow za pomocą interfejsu API Keras wyeksportowany model zostanie wyeksportowany jako obiekt SavedModel, dzięki czemu będzie mógł udostępniać nowe punkty danych na potrzeby przewidywania. Eksportując model, musisz zdefiniować jego interfejs — czyli schemat funkcji wejściowych, który jest oczekiwany podczas udostępniania. Ten schemat funkcji wejściowych jest zdefiniowany w funkcji serving_fn , jak pokazano w następującym kodzie:
def export_serving_model(model, output_dir):
tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)
# The layer has to be saved to the model for Keras tracking purposes.
model.tft_layer = tf_transform_output.transform_features_layer()
@tf.function
def serveing_fn(uid, is_male, mother_race, mother_age, plurality, gestation_weeks):
features = {
'is_male': is_male,
'mother_race': mother_race,
'mother_age': mother_age,
'plurality': plurality,
'gestation_weeks': gestation_weeks
}
transformed_features = model.tft_layer(features)
outputs = model(transformed_features)
# The prediction results have multiple elements in general.
# But we need only the first element in our case.
outputs = tf.map_fn(lambda item: item[0], outputs)
return {'uid': uid, 'weight': outputs}
concrete_serving_fn = serveing_fn.get_concrete_function(
tf.TensorSpec(shape=[None], dtype=tf.string, name='uid'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='is_male'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='mother_race'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='mother_age'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='plurality'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='gestation_weeks')
)
signatures = {'serving_default': concrete_serving_fn}
model.save(output_dir, save_format='tf', signatures=signatures)
Podczas udostępniania model oczekuje punktów danych w ich surowej postaci (tzn. surowych cech przed przekształceniami). Dlatego funkcja serving_fn odbiera surowe funkcje i przechowuje je w obiekcie features jako słownik języka Python. Jednakże, jak omówiono wcześniej, przeszkolony model oczekuje punktów danych w przekształconym schemacie. Aby przekonwertować surowe funkcje na obiekty transformed_features , których oczekuje interfejs modelu, zastosuj zapisany wykres transform_fn do obiektu features , wykonując następujące kroki:
Utwórz obiekt
TFTransformOutputna podstawie artefaktów wygenerowanych i zapisanych w poprzednim kroku przetwarzania wstępnego:tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)Utwórz obiekt
TransformFeaturesLayerz obiektuTFTransformOutput:model.tft_layer = tf_transform_output.transform_features_layer()Zastosuj wykres
transform_fnprzy użyciu obiektuTransformFeaturesLayer:transformed_features = model.tft_layer(features)
Poniższy diagram, rysunek 6, ilustruje ostatni krok eksportowania modelu do wyświetlenia:

transform_fn . Trenuj i używaj modelu do prognozowania
Model można wytrenować lokalnie, wykonując komórki notatnika. Przykłady pakowania kodu i uczenia modelu na dużą skalę przy użyciu narzędzia Vertex AI Training znajdziesz w przykładach i przewodnikach w repozytorium Google Cloud cloudml-samples na GitHubie.
Kiedy sprawdzasz wyeksportowany obiekt SavedModel za pomocą narzędzia saved_model_cli , widzisz, że elementy inputs definicji podpisu signature_def zawierają surowe funkcje, jak pokazano w poniższym przykładzie:
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input(s):
inputs['gestation_weeks'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_gestation_weeks:0
inputs['is_male'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_is_male:0
inputs['mother_age'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_mother_age:0
inputs['mother_race'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_mother_race:0
inputs['plurality'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_plurality:0
inputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_uid:0
The given SavedModel SignatureDef contains the following output(s):
outputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: StatefulPartitionedCall_6:0
outputs['weight'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: StatefulPartitionedCall_6:1
Method name is: tensorflow/serving/predict
Pozostałe komórki notatnika pokazują, jak używać wyeksportowanego modelu do prognozy lokalnej oraz jak wdrożyć model jako mikrousługę przy użyciu prognozy Vertex AI. Należy podkreślić, że w obu przypadkach wejściowy (przykładowy) punkt danych znajduje się w surowym schemacie.
Posprzątać
Aby uniknąć dodatkowych opłat na koncie Google Cloud za zasoby wykorzystane w tym samouczku, usuń projekt zawierający te zasoby.
Usuń projekt
W konsoli Google Cloud przejdź do strony Zarządzaj zasobami .
Na liście projektów wybierz projekt, który chcesz usunąć, a następnie kliknij Usuń .
W oknie dialogowym wpisz identyfikator projektu, a następnie kliknij Zamknij , aby usunąć projekt.
Co dalej
- Aby poznać koncepcje, wyzwania i możliwości wstępnego przetwarzania danych na potrzeby uczenia maszynowego w Google Cloud, zapoznaj się z pierwszym artykułem z tej serii, Wstępne przetwarzanie danych dla ML: opcje i rekomendacje .
- Aby uzyskać więcej informacji na temat wdrażania, pakowania i uruchamiania potoku tf.Transform w Dataflow, zobacz przykład Przewidywanie dochodu za pomocą zestawu danych Census .
- Skorzystaj ze specjalizacji Coursera w zakresie uczenia maszynowego z TensorFlow w Google Cloud .
- Dowiedz się o najlepszych praktykach inżynierii uczenia maszynowego w Zasadach uczenia maszynowego .
- Więcej architektur referencyjnych, diagramów i najlepszych praktyk znajdziesz w Centrum architektury chmury .