
이 튜토리얼에서는 TensorFlow Transform ( tf.Transform 라이브러리)을 사용하여 기계 학습(ML)을 위한 데이터 사전 처리를 구현하는 방법을 보여줍니다. TensorFlow용 tf.Transform 라이브러리를 사용하면 데이터 사전 처리 파이프라인을 통해 인스턴스 수준 및 전체 전달 데이터 변환을 모두 정의할 수 있습니다. 이러한 파이프라인은 Apache Beam을 통해 효율적으로 실행되며 부산물로서 TensorFlow 그래프를 생성하여 모델이 제공될 때와 예측 중에 동일한 변환을 적용합니다.
이 가이드에서는 Dataflow를 Apache Beam 실행기로 사용하는 엔드 투 엔드 예시를 제공합니다. 여기에서는 사용자가 BigQuery , Dataflow, Vertex AI , TensorFlow Keras API에 익숙하다고 가정합니다. 또한 Vertex AI Workbench 와 같은 Jupyter Notebook을 사용한 경험이 있다고 가정합니다.
또한 이 튜토리얼에서는 ML을 위한 데이터 사전 처리: 옵션 및 권장 사항 에 설명된 대로 사용자가 GCP의 사전 처리 유형, 과제, 옵션 개념에 익숙하다고 가정합니다.
목표
-
tf.Transform라이브러리를 사용하여 Apache Beam 파이프라인을 구현합니다. - Dataflow에서 파이프라인을 실행합니다.
-
tf.Transform라이브러리를 사용하여 TensorFlow 모델을 구현합니다. - 예측을 위해 모델을 훈련하고 사용합니다.
소송 비용
이 가이드에서는 다음과 같은 청구 가능한 Google Cloud 구성요소를 사용합니다.
하루 종일 모든 리소스를 사용한다고 가정하고 이 튜토리얼을 실행하는 데 드는 비용을 추정하려면 사전 구성된 가격 계산기를 사용하세요.
시작하기 전에
Google Cloud 콘솔의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다 .
Cloud 프로젝트에 결제가 사용 설정되어 있는지 확인하세요. 프로젝트에 결제가 활성화되어 있는지 확인하는 방법을 알아보세요.
Dataflow, Vertex AI, Notebooks API를 사용 설정합니다. API 활성화
이 솔루션을 위한 Jupyter 노트북
다음 Jupyter 노트북은 구현 예를 보여줍니다.
- 노트북 1은 데이터 전처리를 다룹니다. 자세한 내용은 나중에 Apache Beam 파이프라인 구현 섹션에서 제공됩니다.
- 노트북 2에서는 모델 교육을 다룹니다. 자세한 내용은 나중에 TensorFlow 모델 구현 섹션에서 제공됩니다.
다음 섹션에서는 이러한 노트북을 복제한 다음 노트북을 실행하여 구현 예제의 작동 방식을 알아봅니다.
사용자 관리 노트북 인스턴스 실행
Google Cloud 콘솔에서 Vertex AI Workbench 페이지로 이동합니다.
사용자 관리 노트북 탭에서 +새 노트북 을 클릭합니다.
인스턴스 유형으로 GPU가 없는 TensorFlow Enterprise 2.8(LTS 포함)을 선택하세요.
만들기 를 클릭합니다.
노트북을 생성한 후 JupyterLab에 대한 프록시 초기화가 완료될 때까지 기다립니다. 준비가 되면 노트북 이름 옆에 Open JupyterLab이 표시됩니다.
노트북 복제
사용자 관리 노트북 탭 에서 노트북 이름 옆에 있는 JupyterLab 열기를 클릭합니다. JupyterLab 인터페이스가 새 탭에서 열립니다.
JupyterLab에 빌드 권장 대화 상자가 표시되면 취소를 클릭하여 제안된 빌드를 거부합니다.
실행기 탭에서 터미널 을 클릭합니다.
터미널 창에서 노트북을 복제합니다.
git clone https://github.com/GoogleCloudPlatform/training-data-analyst
Apache Beam 파이프라인 구현
이 섹션과 다음 섹션 인 Dataflow에서 파이프라인 실행에서는 노트북 1에 대한 개요와 컨텍스트를 제공합니다. 노트북은 tf.Transform 라이브러리를 사용하여 데이터를 사전 처리하는 방법을 설명하는 실제 예시를 제공합니다. 이 예에서는 다양한 입력을 기반으로 아기 체중을 예측하는 데 사용되는 Natality 데이터세트를 사용합니다. 데이터는 BigQuery의 공개 출생률 테이블에 저장됩니다.
노트북 1 실행
JupyterLab 인터페이스에서 파일 > 경로에서 열기를 클릭한 후 다음 경로를 입력합니다.
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_01.ipynb편집 > 모든 출력 지우기를 클릭합니다.
필수 패키지 설치 섹션에서 첫 번째 셀을 실행하여
pip install apache-beam명령을 실행합니다.출력의 마지막 부분은 다음과 같습니다.
Successfully installed ...출력에서 종속성 오류를 무시할 수 있습니다. 아직 커널을 다시 시작할 필요는 없습니다.
두 번째 셀을 실행하여
pip install tensorflow-transform명령을 실행합니다. 출력의 마지막 부분은 다음과 같습니다.Successfully installed ... Note: you may need to restart the kernel to use updated packages.출력에서 종속성 오류를 무시할 수 있습니다.
커널 > 커널 다시 시작을 클릭합니다.
설치된 패키지 확인 및 setup.py를 만들어 Dataflow 컨테이너에 패키지 설치 섹션의 셀을 실행합니다.
PROJECT및BUCKET옆에 있는 전역 플래그 설정 섹션에서your-projectCloud 프로젝트 ID로 바꾼 후 셀을 실행합니다.Notebook의 마지막 셀을 통해 나머지 셀을 모두 실행합니다. 각 셀에서 수행할 작업에 대한 자세한 내용은 Notebook의 지침을 참조하세요.
파이프라인 개요
노트북 예시에서 Dataflow는 tf.Transform 파이프라인을 대규모로 실행하여 데이터를 준비하고 변환 아티팩트를 생성합니다. 이 문서의 후반부 섹션에서는 파이프라인의 각 단계를 수행하는 기능을 설명합니다. 전체 파이프라인 단계는 다음과 같습니다.
- BigQuery에서 학습 데이터를 읽습니다.
-
tf.Transform라이브러리를 사용하여 학습 데이터를 분석하고 변환합니다. - 변환된 학습 데이터를 TFRecord 형식으로 Cloud Storage에 씁니다.
- BigQuery에서 평가 데이터를 읽습니다.
- 2단계에서 생성된
transform_fn그래프를 사용하여 평가 데이터를 변환합니다. - 변환된 학습 데이터를 TFRecord 형식으로 Cloud Storage에 씁니다.
- 나중에 모델을 만들고 내보내는 데 사용할 변환 아티팩트를 Cloud Storage에 기록합니다.
다음 예에서는 전체 파이프라인에 대한 Python 코드를 보여줍니다. 다음 섹션에서는 각 단계에 대한 설명과 코드 목록을 제공합니다.
def run_transformation_pipeline(args):
pipeline_options = beam.pipeline.PipelineOptions(flags=[], **args)
runner = args['runner']
data_size = args['data_size']
transformed_data_location = args['transformed_data_location']
transform_artefact_location = args['transform_artefact_location']
temporary_dir = args['temporary_dir']
debug = args['debug']
# Instantiate the pipeline
with beam.Pipeline(runner, options=pipeline_options) as pipeline:
with impl.Context(temporary_dir):
# Preprocess train data
step = 'train'
# Read raw train data from BigQuery
raw_train_dataset = read_from_bq(pipeline, step, data_size)
# Analyze and transform raw_train_dataset
transformed_train_dataset, transform_fn = analyze_and_transform(raw_train_dataset, step)
# Write transformed train data to sink as tfrecords
write_tfrecords(transformed_train_dataset, transformed_data_location, step)
# Preprocess evaluation data
step = 'eval'
# Read raw eval data from BigQuery
raw_eval_dataset = read_from_bq(pipeline, step, data_size)
# Transform eval data based on produced transform_fn
transformed_eval_dataset = transform(raw_eval_dataset, transform_fn, step)
# Write transformed eval data to sink as tfrecords
write_tfrecords(transformed_eval_dataset, transformed_data_location, step)
# Write transformation artefacts
write_transform_artefacts(transform_fn, transform_artefact_location)
# (Optional) for debugging, write transformed data as text
step = 'debug'
# Write transformed train data as text if debug enabled
if debug == True:
write_text(transformed_train_dataset, transformed_data_location, step)
BigQuery에서 원시 학습 데이터 읽기
첫 번째 단계는 read_from_bq 함수를 사용하여 BigQuery에서 원시 학습 데이터를 읽는 것입니다. 이 함수는 BigQuery에서 추출된 raw_dataset 객체를 반환합니다. data_size 값을 전달하고 train 또는 eval 의 step 값을 전달합니다. BigQuery 소스 쿼리는 다음 예와 같이 get_source_query 함수를 사용하여 구성됩니다.
def read_from_bq(pipeline, step, data_size):
source_query = get_source_query(step, data_size)
raw_data = (
pipeline
| '{} - Read Data from BigQuery'.format(step) >> beam.io.Read(
beam.io.BigQuerySource(query=source_query, use_standard_sql=True))
| '{} - Clean up Data'.format(step) >> beam.Map(prep_bq_row)
)
raw_metadata = create_raw_metadata()
raw_dataset = (raw_data, raw_metadata)
return raw_dataset
tf.Transform 사전 처리를 수행하기 전에 맵, 필터, 그룹 및 창 처리를 포함한 일반적인 Apache Beam 기반 처리를 수행해야 할 수도 있습니다. 예시에서 코드는 beam.Map(prep_bq_row) 메서드를 사용하여 BigQuery에서 읽은 레코드를 정리합니다. 여기서 prep_bq_row 는 커스텀 함수입니다. 이 사용자 정의 함수는 범주형 기능의 숫자 코드를 사람이 읽을 수 있는 레이블로 변환합니다.
또한 tf.Transform 라이브러리를 사용하여 BigQuery에서 추출된 raw_data 객체를 분석하고 변환하려면 raw_data 및 raw_metadata 객체의 튜플인 raw_dataset 객체를 생성해야 합니다. raw_metadata 객체는 다음과 같이 create_raw_metadata 함수를 사용하여 생성됩니다.
CATEGORICAL_FEATURE_NAMES = ['is_male', 'mother_race']
NUMERIC_FEATURE_NAMES = ['mother_age', 'plurality', 'gestation_weeks']
TARGET_FEATURE_NAME = 'weight_pounds'
def create_raw_metadata():
feature_spec = dict(
[(name, tf.io.FixedLenFeature([], tf.string)) for name in CATEGORICAL_FEATURE_NAMES] +
[(name, tf.io.FixedLenFeature([], tf.float32)) for name in NUMERIC_FEATURE_NAMES] +
[(TARGET_FEATURE_NAME, tf.io.FixedLenFeature([], tf.float32))])
raw_metadata = dataset_metadata.DatasetMetadata(
schema_utils.schema_from_feature_spec(feature_spec))
return raw_metadata
이 메서드를 정의하는 셀 바로 뒤에 있는 노트북에서 셀을 실행하면 raw_metadata.schema 개체의 콘텐츠가 표시됩니다. 여기에는 다음 열이 포함됩니다.
-
gestation_weeks(유형:FLOAT) -
is_male(유형:BYTES) -
mother_age(유형:FLOAT) -
mother_race(유형:BYTES) -
plurality(유형:FLOAT) -
weight_pounds(유형:FLOAT)
원시 훈련 데이터 변환
ML을 준비하기 위해 훈련 데이터의 입력 원시 특성에 일반적인 사전 처리 변환을 적용한다고 가정해 보십시오. 이러한 변환에는 다음 표에 표시된 것처럼 전체 전달 및 인스턴스 수준 작업이 모두 포함됩니다.
| 입력 기능 | 변환 | 필요한 통계 | 유형 | 출력 기능 |
|---|---|---|---|---|
weight_pound | 없음 | 없음 | 해당 없음 | weight_pound |
mother_age | 정규화 | 뜻, var | 풀패스 | mother_age_normalized |
mother_age | 동일한 크기 버킷화 | 분위수 | 풀패스 | mother_age_bucketized |
mother_age | 로그 계산 | 없음 | 인스턴스 수준 | mother_age_log |
plurality | 아기가 한 명인지 여러 명인지 표시하세요. | 없음 | 인스턴스 수준 | is_multiple |
is_multiple | 명목 값을 숫자 인덱스로 변환 | 어휘 | 풀패스 | is_multiple_index |
gestation_weeks | 0과 1 사이의 비율 | 최소, 최대 | 풀패스 | gestation_weeks_scaled |
mother_race | 명목 값을 숫자 인덱스로 변환 | 어휘 | 풀패스 | mother_race_index |
is_male | 명목 값을 숫자 인덱스로 변환 | 어휘 | 풀패스 | is_male_index |
이러한 변환은 텐서 사전( input_features )을 기대하고 처리된 기능 사전( output_features )을 반환하는 preprocess_fn 함수에서 구현됩니다.
다음 코드는 tf.Transform 전체 전달 변환 API( tft. 접두사가 붙음) 및 TensorFlow( tf. 접두사가 붙음) 인스턴스 수준 작업을 사용하여 preprocess_fn 함수의 구현을 보여줍니다.
def preprocess_fn(input_features):
output_features = {}
# target feature
output_features['weight_pounds'] = input_features['weight_pounds']
# normalization
output_features['mother_age_normalized'] = tft.scale_to_z_score(input_features['mother_age'])
# scaling
output_features['gestation_weeks_scaled'] = tft.scale_to_0_1(input_features['gestation_weeks'])
# bucketization based on quantiles
output_features['mother_age_bucketized'] = tft.bucketize(input_features['mother_age'], num_buckets=5)
# you can compute new features based on custom formulas
output_features['mother_age_log'] = tf.math.log(input_features['mother_age'])
# or create flags/indicators
is_multiple = tf.as_string(input_features['plurality'] > tf.constant(1.0))
# convert categorical features to indexed vocab
output_features['mother_race_index'] = tft.compute_and_apply_vocabulary(input_features['mother_race'], vocab_filename='mother_race')
output_features['is_male_index'] = tft.compute_and_apply_vocabulary(input_features['is_male'], vocab_filename='is_male')
output_features['is_multiple_index'] = tft.compute_and_apply_vocabulary(is_multiple, vocab_filename='is_multiple')
return output_features
tf.Transform 프레임워크에는 다음 표에 나열된 변환을 포함하여 이전 예제의 변환 외에도 여러 가지 다른 변환이 있습니다.
| 변환 | 적용대상 | 설명 |
|---|---|---|
scale_by_min_max | 숫자 특징 | 숫자 열을 [ output_min , output_max ] 범위로 조정합니다. |
scale_to_0_1 | 숫자 특징 | 범위 [ 0 , 1 ]을 갖도록 스케일링된 입력 열인 열을 반환합니다. |
scale_to_z_score | 숫자 특징 | 평균이 0이고 분산이 1인 표준화된 열을 반환합니다. |
tfidf | 텍스트 기능 | x 의 용어를 해당 용어 빈도 * 역문서 빈도에 매핑합니다. |
compute_and_apply_vocabulary | 범주형 기능 | 범주형 특성에 대한 어휘를 생성하고 이 어휘를 사용하여 정수에 매핑합니다. |
ngrams | 텍스트 기능 | n-gram의 SparseTensor 생성합니다. |
hash_strings | 범주형 기능 | 문자열을 버킷으로 해시합니다. |
pca | 숫자 특징 | 편향된 공분산을 사용하여 데이터 세트에서 PCA를 계산합니다. |
bucketize | 숫자 특징 | 각 입력에 버킷 인덱스가 할당된 동일한 크기(분위수 기반) 버킷화된 열을 반환합니다. |
preprocess_fn 함수에서 구현된 변환을 파이프라인의 이전 단계에서 생성된 raw_train_dataset 객체에 적용하려면 AnalyzeAndTransformDataset 메서드를 사용합니다. 이 메서드는 raw_dataset 개체를 입력으로 예상하고, preprocess_fn 함수를 적용하고, transformed_dataset 개체와 transform_fn 그래프를 생성합니다. 다음 코드는 이 처리를 보여줍니다.
def analyze_and_transform(raw_dataset, step):
transformed_dataset, transform_fn = (
raw_dataset
| '{} - Analyze & Transform'.format(step) >> tft_beam.AnalyzeAndTransformDataset(
preprocess_fn, output_record_batches=True)
)
return transformed_dataset, transform_fn
변환은 분석 단계와 변환 단계의 두 단계로 원시 데이터에 적용됩니다. 이 문서 뒷부분의 그림 3에서는 AnalyzeAndTransformDataset 메서드가 AnalyzeDataset 메서드와 TransformDataset 메서드로 분해되는 방법을 보여줍니다.
분석 단계
분석 단계에서는 변환에 필요한 통계를 계산하기 위해 전체 전달 프로세스에서 원시 교육 데이터를 분석합니다. 여기에는 평균, 분산, 최소값, 최대값, 분위수 및 어휘 계산이 포함됩니다. 분석 프로세스에서는 원시 데이터 세트(원시 데이터 + 원시 메타데이터)를 예상하며 다음 두 가지 출력을 생성합니다.
-
transform_fn: 분석 단계에서 계산된 통계와 인스턴스 수준 작업으로 통계를 사용하는 변환 논리를 포함하는 TensorFlow 그래프입니다. 나중에 그래프 저장 에서 설명하는 것처럼,transform_fn그래프는 모델serving_fn함수에 연결되도록 저장됩니다. 이를 통해 온라인 예측 데이터 포인트에 동일한 변환을 적용할 수 있습니다. -
transform_metadata: 변환 후 예상되는 데이터 스키마를 설명하는 개체입니다.
분석 단계는 다음 다이어그램, 그림 1에 설명되어 있습니다.

tf.Transform 분석 단계. tf.Transform 분석기 에는 min , max , sum , size , mean , var , covariance , quantiles , vocabulary 및 pca 가 포함됩니다.
변환 단계
변환 단계에서는 변환된 훈련 데이터를 생성하기 위해 분석 단계에서 생성된 transform_fn 그래프를 사용하여 인스턴스 수준 프로세스에서 원시 훈련 데이터를 변환합니다. 변환된 훈련 데이터는 변환된 메타데이터(분석 단계에서 생성됨)와 쌍을 이루어 transformed_train_dataset 데이터세트를 생성합니다.
변환 단계는 다음 다이어그램, 그림 2에 설명되어 있습니다.

tf.Transform 변환 단계. 기능을 사전 처리하려면 preprocess_fn 함수 구현에서 필요한 tensorflow_transform 변환(코드에서 tft 로 가져옴)을 호출합니다. 예를 들어, tft.scale_to_z_score 작업을 호출하면 tf.Transform 라이브러리는 이 함수 호출을 평균 및 분산 분석기로 변환하고 분석 단계에서 통계를 계산한 다음 이러한 통계를 적용하여 변환 단계에서 숫자 기능을 정규화합니다. 이 모든 작업은 AnalyzeAndTransformDataset(preprocess_fn) 메서드를 호출하여 자동으로 수행됩니다.
이 호출로 생성된 transformed_metadata.schema 엔터티에는 다음 열이 포함됩니다.
-
gestation_weeks_scaled(유형:FLOAT) -
is_male_index(유형:INT, is_categorical:True) -
is_multiple_index(유형:INT, is_categorical:True) -
mother_age_bucketized(유형:INT, is_categorical:True) -
mother_age_log(유형:FLOAT) -
mother_age_normalized(유형:FLOAT) -
mother_race_index(유형:INT, is_categorical:True) -
weight_pounds(유형:FLOAT)
이 시리즈의 첫 번째 부분에 있는 전처리 작업 에서 설명한 대로 특성 변환은 범주형 특성을 숫자 표현으로 변환합니다. 변환 후 범주형 특성은 정수 값으로 표시됩니다. transformed_metadata.schema 엔터티에서 INT 유형 열의 is_categorical 플래그는 열이 범주형 기능을 나타내는지 아니면 실제 숫자 기능을 나타내는지 여부를 나타냅니다.
변환된 훈련 데이터 쓰기
훈련 데이터가 분석 및 변환 단계를 통해 preprocess_fn 함수로 전처리된 후 TensorFlow 모델 훈련에 사용할 싱크에 데이터를 쓸 수 있습니다. Dataflow를 사용하여 Apache Beam 파이프라인을 실행하는 경우 싱크는 Cloud Storage입니다. 그렇지 않은 경우 싱크는 로컬 디스크입니다. 데이터를 고정 너비 형식의 CSV 파일로 쓸 수 있지만 TensorFlow 데이터 세트에 권장되는 파일 형식은 TFRecord 형식입니다. 이는 tf.train.Example 프로토콜 버퍼 메시지로 구성된 간단한 레코드 중심 바이너리 형식입니다.
각 tf.train.Example 레코드에는 하나 이상의 기능이 포함되어 있습니다. 이는 훈련을 위해 모델에 입력될 때 텐서로 변환됩니다. 다음 코드는 변환된 데이터 세트를 지정된 위치의 TFRecord 파일에 씁니다.
def write_tfrecords(transformed_dataset, location, step):
from tfx_bsl.coders import example_coder
transformed_data, transformed_metadata = transformed_dataset
(
transformed_data
| '{} - Encode Transformed Data'.format(step) >> beam.FlatMapTuple(
lambda batch, _: example_coder.RecordBatchToExamples(batch))
| '{} - Write Transformed Data'.format(step) >> beam.io.WriteToTFRecord(
file_path_prefix=os.path.join(location,'{}'.format(step)),
file_name_suffix='.tfrecords')
)
평가 데이터 읽기, 변환, 쓰기
훈련 데이터를 변환하고 transform_fn 그래프를 생성한 후 이를 사용하여 평가 데이터를 변환할 수 있습니다. 먼저 앞서 BigQuery에서 원시 학습 데이터 읽기 에서 설명한 read_from_bq 함수를 사용하고 step 매개변수에 eval 값을 전달하여 BigQuery에서 평가 데이터를 읽고 정리합니다. 그런 다음 다음 코드를 사용하여 원시 평가 데이터세트( raw_dataset )를 예상되는 변환 형식( transformed_dataset )으로 변환합니다.
def transform(raw_dataset, transform_fn, step):
transformed_dataset = (
(raw_dataset, transform_fn)
| '{} - Transform'.format(step) >> tft_beam.TransformDataset(output_record_batches=True)
)
return transformed_dataset
평가 데이터를 변환하면 transform_fn 그래프의 논리와 교육 데이터의 분석 단계에서 계산된 통계를 모두 사용하여 인스턴스 수준 작업만 적용됩니다. 즉, 평가 데이터의 숫자 특성에 대한 z-점수 정규화에 대한 평균 및 분산과 같은 새로운 통계를 계산하기 위해 전체 전달 방식으로 평가 데이터를 분석하지 않습니다. 대신 훈련 데이터에서 계산된 통계를 사용하여 인스턴스 수준 방식으로 평가 데이터를 변환합니다.
따라서 훈련 데이터의 맥락에서 AnalyzeAndTransform 메서드를 사용하여 통계를 계산하고 데이터를 변환합니다. 동시에 평가 데이터를 변환하는 맥락에서 TransformDataset 메서드를 사용하면 훈련 데이터에 대해 계산된 통계를 사용하여 데이터만 변환할 수 있습니다.
그런 다음 학습 프로세스 중에 TensorFlow 모델을 평가하기 위해 TFRecord 형식으로 싱크(실행기에 따라 Cloud Storage 또는 로컬 디스크)에 데이터를 씁니다. 이렇게 하려면 변환된 학습 데이터 쓰기 에서 설명한 write_tfrecords 함수를 사용합니다. 다음 다이어그램(그림 3)은 훈련 데이터의 분석 단계에서 생성된 transform_fn 그래프가 평가 데이터를 변환하는 데 사용되는 방법을 보여줍니다.

transform_fn 를 사용하여 평가 데이터 변환.그래프 저장
tf.Transform 사전 처리 파이프라인의 마지막 단계는 훈련 데이터에 대한 분석 단계에서 생성된 transform_fn 그래프를 포함하는 아티팩트를 저장하는 것입니다. 아티팩트를 저장하기 위한 코드는 다음 write_transform_artefacts 함수에 표시됩니다.
def write_transform_artefacts(transform_fn, location):
(
transform_fn
| 'Write Transform Artifacts' >> transform_fn_io.WriteTransformFn(location)
)
이러한 아티팩트는 나중에 모델 학습 및 제공을 위한 내보내기에 사용됩니다. 다음 섹션에 표시된 대로 다음 아티팩트도 생성됩니다.
-
saved_model.pb: 원시 데이터 포인트를 변환된 형식으로 변환하기 위해 모델 제공 인터페이스에 연결되는 변환 로직(transform_fn그래프)을 포함하는 TensorFlow 그래프를 나타냅니다. -
variables: 훈련 데이터의 분석 단계에서 계산된 통계를 포함하며,saved_model.pb아티팩트의 변환 논리에 사용됩니다. -
assets: 입력 원시 명목 값을 숫자 인덱스로 변환하기 위해 제공하는 동안 사용되는compute_and_apply_vocabulary메소드로 처리된 각 범주형 기능에 대해 하나씩 어휘 파일을 포함합니다. -
transformed_metadata: 변환된 데이터의 스키마를 설명하는schema.json파일이 포함된 디렉터리입니다.
Dataflow에서 파이프라인 실행
tf.Transform 파이프라인을 정의한 후 Dataflow를 사용하여 파이프라인을 실행합니다. 다음 다이어그램(그림 4)은 예시에 설명된 tf.Transform 파이프라인의 Dataflow 실행 그래프를 보여줍니다.
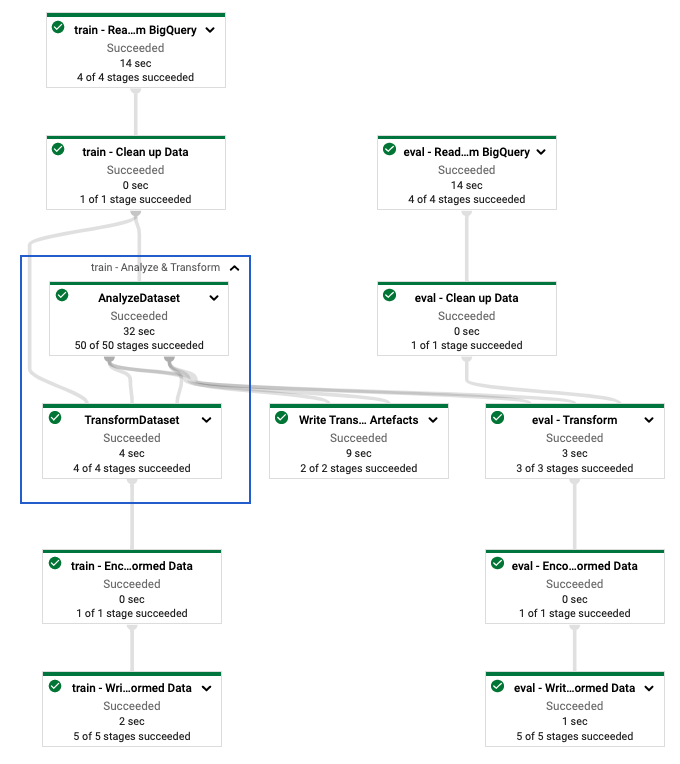
tf.Transform 파이프라인의 데이터 흐름 실행 그래프. Dataflow 파이프라인을 실행하여 학습 및 평가 데이터를 사전 처리한 후 노트북의 마지막 셀을 실행하여 Cloud Storage에서 생성된 객체를 탐색할 수 있습니다. 이 섹션의 코드 스니펫은 결과를 보여줍니다. 여기서 YOUR_BUCKET_NAME 은 Cloud Storage 버킷의 이름입니다.
TFRecord 형식으로 변환된 훈련 및 평가 데이터는 다음 위치에 저장됩니다.
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed
변환 아티팩트는 다음 위치에서 생성됩니다.
gs://YOUR_BUCKET_NAME/babyweight_tft/transform
다음 목록은 생성된 데이터 객체와 아티팩트를 보여주는 파이프라인의 출력입니다.
transformed data:
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/eval-00000-of-00001.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00000-of-00002.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00001-of-00002.tfrecords
transformed metadata:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/asset_map
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/schema.pbtxt
transform artefact:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/saved_model.pb
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/variables/
transform assets:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_male
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_multiple
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/mother_race
TensorFlow 모델 구현
이 섹션과 다음 섹션인 예측을 위한 모델 학습 및 사용에서는 노트북 2에 대한 개요와 컨텍스트를 제공합니다. 노트북은 아기 체중을 예측하기 위한 예시 ML 모델을 제공합니다. 이 예에서는 TensorFlow 모델이 Keras API를 사용하여 구현됩니다. 모델은 앞서 설명한 tf.Transform 사전 처리 파이프라인에서 생성된 데이터와 아티팩트를 사용합니다.
노트북 2 실행
JupyterLab 인터페이스에서 파일 > 경로에서 열기를 클릭한 후 다음 경로를 입력합니다.
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_02.ipynb편집 > 모든 출력 지우기를 클릭합니다.
필수 패키지 설치 섹션에서 첫 번째 셀을 실행하여
pip install tensorflow-transform명령을 실행합니다.출력의 마지막 부분은 다음과 같습니다.
Successfully installed ... Note: you may need to restart the kernel to use updated packages.출력에서 종속성 오류를 무시할 수 있습니다.
커널 메뉴에서 커널 다시 시작 을 선택합니다.
설치된 패키지 확인 및 setup.py를 만들어 Dataflow 컨테이너에 패키지 설치 섹션의 셀을 실행합니다.
PROJECT및BUCKET옆에 있는 전역 플래그 설정 섹션에서your-project클라우드 프로젝트 ID로 바꾼 후 셀을 실행합니다.Notebook의 마지막 셀을 통해 나머지 셀을 모두 실행합니다. 각 셀에서 수행할 작업에 대한 자세한 내용은 Notebook의 지침을 참조하세요.
모델 생성 개요
모델을 생성하는 단계는 다음과 같습니다.
-
transformed_metadata디렉터리에 저장된 스키마 정보를 사용하여 특성 열을 생성합니다. - 특성 열을 모델에 대한 입력으로 사용하여 Keras API로 와이드 앤 딥 모델을 만듭니다.
- 변환 아티팩트를 사용하여 교육 및 평가 데이터를 읽고 구문 분석하려면
tfrecords_input_fn함수를 만듭니다. - 모델을 훈련하고 평가합니다.
-
transform_fn그래프가 연결된serving_fn함수를 정의하여 훈련된 모델을 내보냅니다. -
saved_model_cli도구를 사용하여 내보낸 모델을 검사합니다. - 예측을 위해 내보낸 모델을 사용합니다.
이 문서에서는 모델 구축 방법을 설명하지 않으므로 모델 구축 또는 학습 방법을 자세히 논의하지 않습니다. 그러나 다음 섹션에서는 tf.Transform 프로세스에 의해 생성된 transform_metadata 디렉터리에 저장된 정보가 모델의 특성 열을 생성하는 데 어떻게 사용되는지 보여줍니다. 또한 이 문서에서는 서빙을 위해 모델을 내보낼 때 tf.Transform 프로세스에 의해 생성된 transform_fn 그래프가 serving_fn 함수에서 사용되는 방법도 보여줍니다.
모델 학습에서 생성된 변환 아티팩트 사용
TensorFlow 모델을 훈련할 때 이전 데이터 처리 단계에서 생성된 변환된 train 및 eval 객체를 사용합니다. 이러한 객체는 TFRecord 형식의 샤딩된 파일로 저장됩니다. 이전 단계에서 생성된 transformed_metadata 디렉터리의 스키마 정보는 훈련 및 평가를 위해 모델에 제공할 데이터( tf.train.Example 객체)를 구문 분석하는 데 유용할 수 있습니다.
데이터 분석
훈련 및 평가 데이터를 모델에 제공하기 위해 TFRecord 형식의 파일을 읽기 때문에 파일의 각 tf.train.Example 객체를 구문 분석하여 기능 사전(텐서)을 생성해야 합니다. 이렇게 하면 모델 훈련 및 평가 인터페이스 역할을 하는 특성 열을 사용하여 특성이 모델 입력 계층에 매핑됩니다. 데이터를 구문 분석하려면 이전 단계에서 생성된 아티팩트에서 생성된 TFTransformOutput 객체를 사용합니다.
그래프 저장 섹션에 설명된 대로 이전 전처리 단계에서 생성되고 저장된 아티팩트에서
TFTransformOutput개체를 만듭니다.tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)TFTransformOutput객체에서feature_spec객체를 추출합니다.tf_transform_output.transformed_feature_spec()tfrecords_input_fn함수에서와 같이tf.train.Example객체에 포함된 기능을 지정하려면feature_spec객체를 사용하세요.def tfrecords_input_fn(files_name_pattern, batch_size=512): tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR) TARGET_FEATURE_NAME = 'weight_pounds' batched_dataset = tf.data.experimental.make_batched_features_dataset( file_pattern=files_name_pattern, batch_size=batch_size, features=tf_transform_output.transformed_feature_spec(), reader=tf.data.TFRecordDataset, label_key=TARGET_FEATURE_NAME, shuffle=True).prefetch(tf.data.experimental.AUTOTUNE) return batched_dataset
특성 열 만들기
파이프라인은 훈련 및 평가를 위해 모델에서 예상하는 변환된 데이터의 스키마를 설명하는 transformed_metadata 디렉터리에 스키마 정보를 생성합니다. 스키마에는 다음과 같은 기능 이름과 데이터 유형이 포함됩니다.
-
gestation_weeks_scaled(유형:FLOAT) -
is_male_index(유형:INT, is_categorical:True) -
is_multiple_index(유형:INT, is_categorical:True) -
mother_age_bucketized(유형:INT, is_categorical:True) -
mother_age_log(유형:FLOAT) -
mother_age_normalized(유형:FLOAT) -
mother_race_index(유형:INT, is_categorical:True) -
weight_pounds(유형:FLOAT)
이 정보를 보려면 다음 명령을 사용하십시오.
transformed_metadata = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR).transformed_metadata
transformed_metadata.schema
다음 코드는 특성 이름을 사용하여 특성 열을 생성하는 방법을 보여줍니다.
def create_wide_and_deep_feature_columns():
deep_feature_columns = []
wide_feature_columns = []
inputs = {}
categorical_columns = {}
# Select features you've checked from the metadata
# Categorical features are associated with the vocabulary size (starting from 0)
numeric_features = ['mother_age_log', 'mother_age_normalized', 'gestation_weeks_scaled']
categorical_features = [('is_male_index', 1), ('is_multiple_index', 1),
('mother_age_bucketized', 4), ('mother_race_index', 10)]
for feature in numeric_features:
deep_feature_columns.append(tf.feature_column.numeric_column(feature))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='float32')
for feature, vocab_size in categorical_features:
categorical_columns[feature] = (
tf.feature_column.categorical_column_with_identity(feature, num_buckets=vocab_size+1))
wide_feature_columns.append(tf.feature_column.indicator_column(categorical_columns[feature]))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='int64')
mother_race_X_mother_age_bucketized = tf.feature_column.crossed_column(
[categorical_columns['mother_age_bucketized'],
categorical_columns['mother_race_index']], 55)
wide_feature_columns.append(tf.feature_column.indicator_column(mother_race_X_mother_age_bucketized))
mother_race_X_mother_age_bucketized_embedded = tf.feature_column.embedding_column(
mother_race_X_mother_age_bucketized, 5)
deep_feature_columns.append(mother_race_X_mother_age_bucketized_embedded)
return wide_feature_columns, deep_feature_columns, inputs
코드는 숫자 특성에 대해 tf.feature_column.numeric_column 열을 생성하고 범주형 특성에 대해 tf.feature_column.categorical_column_with_identity 열을 생성합니다.
이 시리즈의 첫 번째 부분에 있는 옵션 C: TensorFlow 에 설명된 대로 확장 기능 열을 생성할 수도 있습니다. 이 시리즈에 사용된 예시에서는 tf.feature_column.crossed_column 특성 열을 사용하여 mother_race 및 mother_age_bucketized 특성을 교차하여 mother_race_X_mother_age_bucketized 라는 새로운 특성이 생성됩니다. 이 교차 특성의 저차원 조밀 표현은 tf.feature_column.embedding_column 특성 열을 사용하여 생성됩니다.
다음 다이어그램(그림 5)은 변환된 데이터와 변환된 메타데이터가 TensorFlow 모델을 정의하고 훈련하는 데 사용되는 방법을 보여줍니다.

예측 제공을 위해 모델 내보내기
Keras API를 사용하여 TensorFlow 모델을 훈련한 후 예측을 위한 새로운 데이터 포인트를 제공할 수 있도록 훈련된 모델을 SavedModel 객체로 내보냅니다. 모델을 내보낼 때 해당 인터페이스, 즉 제공 중에 예상되는 입력 특성 스키마를 정의해야 합니다. 이 입력 기능 스키마는 다음 코드에 표시된 대로 serving_fn 함수에 정의됩니다.
def export_serving_model(model, output_dir):
tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)
# The layer has to be saved to the model for Keras tracking purposes.
model.tft_layer = tf_transform_output.transform_features_layer()
@tf.function
def serveing_fn(uid, is_male, mother_race, mother_age, plurality, gestation_weeks):
features = {
'is_male': is_male,
'mother_race': mother_race,
'mother_age': mother_age,
'plurality': plurality,
'gestation_weeks': gestation_weeks
}
transformed_features = model.tft_layer(features)
outputs = model(transformed_features)
# The prediction results have multiple elements in general.
# But we need only the first element in our case.
outputs = tf.map_fn(lambda item: item[0], outputs)
return {'uid': uid, 'weight': outputs}
concrete_serving_fn = serveing_fn.get_concrete_function(
tf.TensorSpec(shape=[None], dtype=tf.string, name='uid'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='is_male'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='mother_race'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='mother_age'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='plurality'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='gestation_weeks')
)
signatures = {'serving_default': concrete_serving_fn}
model.save(output_dir, save_format='tf', signatures=signatures)
서빙 중에 모델은 원시 형식(즉, 변환 전 원시 특성)의 데이터 포인트를 기대합니다. 따라서 serving_fn 함수는 원시 기능을 수신하여 features 객체에 Python 사전으로 저장합니다. 그러나 앞서 설명한 것처럼 훈련된 모델은 변환된 스키마의 데이터 포인트를 기대합니다. 원시 기능을 모델 인터페이스에서 예상하는 transformed_features 개체로 변환하려면 다음 단계를 통해 저장된 transform_fn 그래프를 features 개체에 적용합니다.
이전 전처리 단계에서 생성되고 저장된 아티팩트에서
TFTransformOutput객체를 만듭니다.tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)TFTransformOutput객체에서TransformFeaturesLayer객체를 생성합니다.model.tft_layer = tf_transform_output.transform_features_layer()TransformFeaturesLayer개체를 사용하여transform_fn그래프를 적용합니다.transformed_features = model.tft_layer(features)
다음 다이어그램(그림 6)은 제공을 위해 모델을 내보내는 마지막 단계를 보여줍니다.

transform_fn 그래프를 사용하여 제공하기 위한 모델 내보내기. 예측을 위해 모델 학습 및 사용
노트북의 셀을 실행하여 로컬에서 모델을 학습할 수 있습니다. Vertex AI Training을 사용하여 대규모로 코드를 패키징하고 모델을 학습시키는 방법에 대한 예시는 Google Cloud cloudml-samples GitHub 저장소의 샘플과 가이드를 참조하세요.
saved_model_cli 도구를 사용하여 내보낸 SavedModel 객체를 검사하면 다음 예에 표시된 대로 서명 정의 signature_def 의 inputs 요소에 원시 기능이 포함되어 있음을 알 수 있습니다.
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input(s):
inputs['gestation_weeks'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_gestation_weeks:0
inputs['is_male'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_is_male:0
inputs['mother_age'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_mother_age:0
inputs['mother_race'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_mother_race:0
inputs['plurality'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_plurality:0
inputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_uid:0
The given SavedModel SignatureDef contains the following output(s):
outputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: StatefulPartitionedCall_6:0
outputs['weight'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: StatefulPartitionedCall_6:1
Method name is: tensorflow/serving/predict
노트북의 나머지 셀에서는 로컬 예측을 위해 내보낸 모델을 사용하는 방법과 Vertex AI Prediction을 사용하여 모델을 마이크로서비스로 배포하는 방법을 보여줍니다. 두 경우 모두 입력(샘플) 데이터 포인트가 원시 스키마에 있다는 점을 강조하는 것이 중요합니다.
정리하다
이 가이드에 사용된 리소스에 대해 GCP 계정에 추가 비용이 발생하지 않도록 하려면 리소스가 포함된 프로젝트를 삭제하세요.
프로젝트 삭제
Google Cloud 콘솔에서 리소스 관리 페이지로 이동합니다.
프로젝트 목록에서 삭제하려는 프로젝트를 선택한 후 삭제 를 클릭하세요.
대화 상자에서 프로젝트 ID를 입력한 다음 종료를 클릭하여 프로젝트를 삭제합니다.
다음은 무엇입니까?
- Google Cloud의 기계 학습을 위한 데이터 사전 처리의 개념, 과제, 옵션에 대해 알아보려면 이 시리즈의 첫 번째 문서인 ML을 위한 데이터 사전 처리: 옵션 및 권장 사항을 참조하세요.
- Dataflow에서 tf.Transform 파이프라인을 구현, 패키징, 실행하는 방법에 대한 자세한 내용은 인구 조사 데이터 세트를 사용한 소득 예측 샘플을 참조하세요.
- Google Cloud에서 TensorFlow를 사용하여 ML에 대한 Coursera 전문 과정을 이수하세요.
- ML 규칙 에서 ML 엔지니어링 모범 사례에 대해 알아보세요.
- 더 많은 참조 아키텍처, 다이어그램 및 모범 사례를 보려면 클라우드 아키텍처 센터를 살펴보세요.