
Questo tutorial mostra come utilizzare TensorFlow Transform (la libreria tf.Transform ) per implementare la preelaborazione dei dati per l'apprendimento automatico (ML). La libreria tf.Transform per TensorFlow ti consente di definire trasformazioni di dati sia a livello di istanza che a passaggio completo attraverso pipeline di preelaborazione dei dati. Queste pipeline vengono eseguite in modo efficiente con Apache Beam e creano come sottoprodotti un grafico TensorFlow per applicare le stesse trasformazioni durante la previsione di quando viene servito il modello.
Questo tutorial fornisce un esempio end-to-end utilizzando Dataflow come runner per Apache Beam. Si presuppone che tu abbia familiarità con BigQuery , Dataflow, Vertex AI e l'API TensorFlow Keras . Si presuppone inoltre che tu abbia una certa esperienza nell'uso dei notebook Jupyter, ad esempio con Vertex AI Workbench .
Questo tutorial presuppone inoltre che tu abbia familiarità con i concetti di tipi, sfide e opzioni di preelaborazione su Google Cloud, come descritto in Preelaborazione dei dati per ML: opzioni e consigli .
Obiettivi
- Implementa la pipeline Apache Beam utilizzando la libreria
tf.Transform. - Esegui la pipeline in Dataflow.
- Implementa il modello TensorFlow utilizzando la libreria
tf.Transform. - Addestrare e utilizzare il modello per le previsioni.
Costi
Questo tutorial utilizza i seguenti componenti fatturabili di Google Cloud:
Per stimare il costo di esecuzione di questo tutorial, presupponendo che utilizzi tutte le risorse per un'intera giornata, utilizza il calcolatore dei prezzi preconfigurato.
Prima di iniziare
Nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud .
Assicurati che la fatturazione sia abilitata per il tuo progetto Cloud. Scopri come verificare se la fatturazione è abilitata su un progetto .
Abilita le API Dataflow, Vertex AI e Notebooks. Abilita le API
Notebook Jupyter per questa soluzione
I seguenti notebook Jupyter mostrano l'esempio di implementazione:
- Il taccuino 1 riguarda la preelaborazione dei dati. I dettagli vengono forniti nella sezione Implementazione della pipeline Apache Beam più avanti.
- Il quaderno 2 riguarda la formazione dei modelli. I dettagli vengono forniti nella sezione Implementazione del modello TensorFlow più avanti.
Nelle sezioni seguenti si clonano questi notebook e quindi si eseguono i notebook per scoprire come funziona l'esempio di implementazione.
Avvia un'istanza di notebook gestiti dall'utente
Nella console Google Cloud, vai alla pagina Vertex AI Workbench .
Nella scheda Taccuini gestiti dall'utente , fai clic su +Nuovo taccuino .
Seleziona TensorFlow Enterprise 2.8 (con LTS) senza GPU come tipo di istanza.
Fare clic su Crea .
Dopo aver creato il notebook, attendere il completamento dell'inizializzazione del proxy per JupyterLab. Quando è pronto, accanto al nome del notebook viene visualizzato Apri JupyterLab .
Clona il taccuino
Nella scheda Notebook gestiti dall'utente , accanto al nome del notebook, fare clic su Apri JupyterLab . L'interfaccia JupyterLab si apre in una nuova scheda.
Se JupyterLab visualizza una finestra di dialogo Build consigliata , fare clic su Annulla per rifiutare la build suggerita.
Nella scheda Avvio applicazioni , fai clic su Terminale .
Nella finestra del terminale, clona il notebook:
git clone https://github.com/GoogleCloudPlatform/training-data-analyst
Implementa la pipeline Apache Beam
Questa sezione e la sezione successiva Esegui la pipeline in Dataflow forniscono una panoramica e un contesto per il notebook 1. Il notebook fornisce un esempio pratico per descrivere come utilizzare la libreria tf.Transform per preelaborare i dati. Questo esempio utilizza il set di dati Natality, utilizzato per prevedere il peso del bambino in base a vari input. I dati vengono archiviati nella tabella di natalità pubblica in BigQuery.
Esegui il taccuino 1
Nell'interfaccia JupyterLab, fare clic su File > Apri dal percorso , quindi immettere il seguente percorso:
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_01.ipynbFare clic su Modifica > Cancella tutti gli output .
Nella sezione Installa pacchetti richiesti , esegui la prima cella per eseguire il comando
pip install apache-beam.L'ultima parte dell'output è la seguente:
Successfully installed ...È possibile ignorare gli errori di dipendenza nell'output. Non è ancora necessario riavviare il kernel.
Esegui la seconda cella per eseguire il comando
pip install tensorflow-transform. L'ultima parte dell'output è la seguente:Successfully installed ... Note: you may need to restart the kernel to use updated packages.È possibile ignorare gli errori di dipendenza nell'output.
Fare clic su Kernel > Riavvia kernel .
Esegui le celle nelle sezioni Conferma i pacchetti installati e Crea setup.py per installare i pacchetti nei contenitori Dataflow .
Nella sezione Imposta flag globali , accanto a
PROJECTeBUCKET, sostituisciyour-projectcon l'ID del tuo progetto cloud, quindi esegui la cella.Esegui tutte le celle rimanenti attraverso l'ultima cella del taccuino. Per informazioni su cosa fare in ciascuna cella, vedere le istruzioni nel taccuino.
Panoramica del gasdotto
Nell'esempio del notebook, Dataflow esegue la pipeline tf.Transform su larga scala per preparare i dati e produrre gli artefatti di trasformazione. Le sezioni successive di questo documento descrivono le funzioni che eseguono ogni passaggio della pipeline. I passaggi complessivi della pipeline sono i seguenti:
- Leggi i dati di addestramento da BigQuery.
- Analizza e trasforma i dati di training utilizzando la libreria
tf.Transform. - Scrivi i dati di allenamento trasformati su Cloud Storage nel formato TFRecord .
- Leggi i dati di valutazione da BigQuery.
- Trasformare i dati di valutazione utilizzando il grafico
transform_fnprodotto dal passaggio 2. - Scrivi i dati di allenamento trasformati su Cloud Storage nel formato TFRecord.
- Scrivi gli artefatti di trasformazione in Cloud Storage che verranno utilizzati in seguito per creare ed esportare il modello.
L'esempio seguente mostra il codice Python per la pipeline complessiva. Le sezioni che seguono forniscono spiegazioni ed elenchi di codici per ogni passaggio.
def run_transformation_pipeline(args):
pipeline_options = beam.pipeline.PipelineOptions(flags=[], **args)
runner = args['runner']
data_size = args['data_size']
transformed_data_location = args['transformed_data_location']
transform_artefact_location = args['transform_artefact_location']
temporary_dir = args['temporary_dir']
debug = args['debug']
# Instantiate the pipeline
with beam.Pipeline(runner, options=pipeline_options) as pipeline:
with impl.Context(temporary_dir):
# Preprocess train data
step = 'train'
# Read raw train data from BigQuery
raw_train_dataset = read_from_bq(pipeline, step, data_size)
# Analyze and transform raw_train_dataset
transformed_train_dataset, transform_fn = analyze_and_transform(raw_train_dataset, step)
# Write transformed train data to sink as tfrecords
write_tfrecords(transformed_train_dataset, transformed_data_location, step)
# Preprocess evaluation data
step = 'eval'
# Read raw eval data from BigQuery
raw_eval_dataset = read_from_bq(pipeline, step, data_size)
# Transform eval data based on produced transform_fn
transformed_eval_dataset = transform(raw_eval_dataset, transform_fn, step)
# Write transformed eval data to sink as tfrecords
write_tfrecords(transformed_eval_dataset, transformed_data_location, step)
# Write transformation artefacts
write_transform_artefacts(transform_fn, transform_artefact_location)
# (Optional) for debugging, write transformed data as text
step = 'debug'
# Write transformed train data as text if debug enabled
if debug == True:
write_text(transformed_train_dataset, transformed_data_location, step)
Leggi i dati di addestramento grezzi da BigQuery
Il primo passaggio consiste nel leggere i dati di addestramento non elaborati da BigQuery utilizzando la funzione read_from_bq . Questa funzione restituisce un oggetto raw_dataset estratto da BigQuery. Si passa un valore data_size e si passa un valore di step train o eval . La query di origine BigQuery viene costruita utilizzando la funzione get_source_query , come mostrato nell'esempio seguente:
def read_from_bq(pipeline, step, data_size):
source_query = get_source_query(step, data_size)
raw_data = (
pipeline
| '{} - Read Data from BigQuery'.format(step) >> beam.io.Read(
beam.io.BigQuerySource(query=source_query, use_standard_sql=True))
| '{} - Clean up Data'.format(step) >> beam.Map(prep_bq_row)
)
raw_metadata = create_raw_metadata()
raw_dataset = (raw_data, raw_metadata)
return raw_dataset
Prima di eseguire la preelaborazione tf.Transform , potrebbe essere necessario eseguire l'elaborazione tipica basata su Apache Beam, inclusa l'elaborazione di mappe, filtri, gruppi e finestre. Nell'esempio, il codice pulisce i record letti da BigQuery utilizzando il metodo beam.Map(prep_bq_row) , dove prep_bq_row è una funzione personalizzata. Questa funzione personalizzata converte il codice numerico per una caratteristica categoriale in etichette leggibili dall'uomo.
Inoltre, per utilizzare la libreria tf.Transform per analizzare e trasformare l'oggetto raw_data estratto da BigQuery, devi creare un oggetto raw_dataset , ovvero una tupla di oggetti raw_data e raw_metadata . L'oggetto raw_metadata viene creato utilizzando la funzione create_raw_metadata , come segue:
CATEGORICAL_FEATURE_NAMES = ['is_male', 'mother_race']
NUMERIC_FEATURE_NAMES = ['mother_age', 'plurality', 'gestation_weeks']
TARGET_FEATURE_NAME = 'weight_pounds'
def create_raw_metadata():
feature_spec = dict(
[(name, tf.io.FixedLenFeature([], tf.string)) for name in CATEGORICAL_FEATURE_NAMES] +
[(name, tf.io.FixedLenFeature([], tf.float32)) for name in NUMERIC_FEATURE_NAMES] +
[(TARGET_FEATURE_NAME, tf.io.FixedLenFeature([], tf.float32))])
raw_metadata = dataset_metadata.DatasetMetadata(
schema_utils.schema_from_feature_spec(feature_spec))
return raw_metadata
Quando si esegue la cella nel notebook che segue immediatamente la cella che definisce questo metodo, viene visualizzato il contenuto dell'oggetto raw_metadata.schema . Comprende le seguenti colonne:
-
gestation_weeks(tipo:FLOAT) -
is_male(tipo:BYTES) -
mother_age(tipo:FLOAT) -
mother_race(tipo:BYTES) -
plurality(tipo:FLOAT) -
weight_pounds(tipo:FLOAT)
Trasforma i dati di addestramento grezzi
Immagina di voler applicare tipiche trasformazioni di preelaborazione alle funzionalità grezze di input dei dati di addestramento per prepararli per il machine learning. Queste trasformazioni includono operazioni sia a passaggio completo che a livello di istanza, come mostrato nella tabella seguente:
| Funzionalità di input | Trasformazione | Servono statistiche | Tipo | Funzionalità di uscita |
|---|---|---|---|---|
weight_pound | Nessuno | Nessuno | N / A | weight_pound |
mother_age | Normalizzare | significa, var | Passaggio completo | mother_age_normalized |
mother_age | Bucketizzazione di pari dimensioni | quantili | Passaggio completo | mother_age_bucketized |
mother_age | Calcola il registro | Nessuno | A livello di istanza | mother_age_log |
plurality | Indicare se si tratta di bambini singoli o multipli | Nessuno | A livello di istanza | is_multiple |
is_multiple | Convertire i valori nominali in indici numerici | vocabolario | Passaggio completo | is_multiple_index |
gestation_weeks | Scala tra 0 e 1 | minimo, massimo | Passaggio completo | gestation_weeks_scaled |
mother_race | Convertire i valori nominali in indici numerici | vocabolario | Passaggio completo | mother_race_index |
is_male | Convertire i valori nominali in indici numerici | vocabolario | Passaggio completo | is_male_index |
Queste trasformazioni sono implementate in una funzione preprocess_fn , che prevede un dizionario di tensori ( input_features ) e restituisce un dizionario di funzionalità elaborate ( output_features ).
Il codice seguente mostra l'implementazione della funzione preprocess_fn , utilizzando le API di trasformazione a passaggio completo tf.Transform (con prefisso tft. ) e le operazioni a livello di istanza TensorFlow (con prefisso tf. ):
def preprocess_fn(input_features):
output_features = {}
# target feature
output_features['weight_pounds'] = input_features['weight_pounds']
# normalization
output_features['mother_age_normalized'] = tft.scale_to_z_score(input_features['mother_age'])
# scaling
output_features['gestation_weeks_scaled'] = tft.scale_to_0_1(input_features['gestation_weeks'])
# bucketization based on quantiles
output_features['mother_age_bucketized'] = tft.bucketize(input_features['mother_age'], num_buckets=5)
# you can compute new features based on custom formulas
output_features['mother_age_log'] = tf.math.log(input_features['mother_age'])
# or create flags/indicators
is_multiple = tf.as_string(input_features['plurality'] > tf.constant(1.0))
# convert categorical features to indexed vocab
output_features['mother_race_index'] = tft.compute_and_apply_vocabulary(input_features['mother_race'], vocab_filename='mother_race')
output_features['is_male_index'] = tft.compute_and_apply_vocabulary(input_features['is_male'], vocab_filename='is_male')
output_features['is_multiple_index'] = tft.compute_and_apply_vocabulary(is_multiple, vocab_filename='is_multiple')
return output_features
Il framework tf.Transform dispone di numerose altre trasformazioni oltre a quelle dell'esempio precedente, incluse quelle elencate nella tabella seguente:
| Trasformazione | Si applica a | Descrizione |
|---|---|---|
scale_by_min_max | Caratteristiche numeriche | Ridimensiona una colonna numerica nell'intervallo [ output_min , output_max ] |
scale_to_0_1 | Caratteristiche numeriche | Restituisce una colonna che è la colonna di input ridimensionata per avere intervallo [ 0 , 1 ] |
scale_to_z_score | Caratteristiche numeriche | Restituisce una colonna standardizzata con media 0 e varianza 1 |
tfidf | Caratteristiche del testo | Mappa i termini in x sulla frequenza dei termini * frequenza inversa del documento |
compute_and_apply_vocabulary | Caratteristiche categoriche | Genera un vocabolario per una caratteristica categoriale e lo mappa su un numero intero con questo vocabolario |
ngrams | Caratteristiche del testo | Crea uno SparseTensor di n-grammi |
hash_strings | Caratteristiche categoriche | Esegue l'hashing delle stringhe nei bucket |
pca | Caratteristiche numeriche | Calcola la PCA sul set di dati utilizzando la covarianza distorta |
bucketize | Caratteristiche numeriche | Restituisce una colonna con intervalli di pari dimensioni (basata su quantili), con un indice di intervalli assegnato a ciascun input |
Per applicare le trasformazioni implementate nella funzione preprocess_fn all'oggetto raw_train_dataset prodotto nel passaggio precedente della pipeline, si utilizza il metodo AnalyzeAndTransformDataset . Questo metodo prevede l'oggetto raw_dataset come input, applica la funzione preprocess_fn e produce l'oggetto transformed_dataset e il grafico transform_fn . Il codice seguente illustra questa elaborazione:
def analyze_and_transform(raw_dataset, step):
transformed_dataset, transform_fn = (
raw_dataset
| '{} - Analyze & Transform'.format(step) >> tft_beam.AnalyzeAndTransformDataset(
preprocess_fn, output_record_batches=True)
)
return transformed_dataset, transform_fn
Le trasformazioni vengono applicate ai dati grezzi in due fasi: la fase di analisi e la fase di trasformazione. La figura 3 più avanti in questo documento illustra come il metodo AnalyzeAndTransformDataset viene scomposto nel metodo AnalyzeDataset e nel metodo TransformDataset .
La fase di analisi
Nella fase di analisi, i dati grezzi di training vengono analizzati in un processo full-pass per calcolare le statistiche necessarie per le trasformazioni. Ciò include il calcolo della media, della varianza, del minimo, del massimo, dei quantili e del vocabolario. Il processo di analisi prevede un set di dati grezzi (dati grezzi più metadati grezzi) e produce due output:
-
transform_fn: un grafico TensorFlow che contiene le statistiche calcolate dalla fase di analisi e la logica di trasformazione (che utilizza le statistiche) come operazioni a livello di istanza. Come discusso più avanti in Salvare il grafico , il graficotransform_fnviene salvato per essere collegato alla funzione modelloserving_fn. Ciò rende possibile applicare la stessa trasformazione ai punti dati di previsione online. -
transform_metadata: un oggetto che descrive lo schema previsto dei dati dopo la trasformazione.
La fase di analisi è illustrata nello schema seguente, figura 1:

tf.Transform . Gli analizzatori tf.Transform includono min , max , sum , size , mean , var , covariance , quantiles , vocabulary e pca .
La fase di trasformazione
Nella fase di trasformazione, il grafico transform_fn prodotto dalla fase di analisi viene utilizzato per trasformare i dati di addestramento grezzi in un processo a livello di istanza al fine di produrre i dati di addestramento trasformati. I dati di addestramento trasformati vengono accoppiati con i metadati trasformati (prodotti dalla fase di analisi) per produrre il set di dati transformed_train_dataset .
La fase di trasformazione è illustrata nel diagramma seguente, figura 2:

tf.Transform . Per preelaborare le funzionalità, chiami le trasformazioni tensorflow_transform richieste (importate come tft nel codice) nell'implementazione della funzione preprocess_fn . Ad esempio, quando chiami le operazioni tft.scale_to_z_score , la libreria tf.Transform traduce questa chiamata di funzione in analizzatori di media e varianza, calcola le statistiche nella fase di analisi e quindi applica queste statistiche per normalizzare la caratteristica numerica nella fase di trasformazione. Tutto questo viene fatto automaticamente chiamando il metodo AnalyzeAndTransformDataset(preprocess_fn) .
L'entità transformed_metadata.schema prodotta da questa chiamata include le seguenti colonne:
-
gestation_weeks_scaled(tipo:FLOAT) -
is_male_index(tipo:INT, is_categorical:True) -
is_multiple_index(tipo:INT, is_categorical:True) -
mother_age_bucketized(tipo:INT, is_categorical:True) -
mother_age_log(tipo:FLOAT) -
mother_age_normalized(tipo:FLOAT) -
mother_race_index(tipo:INT, is_categorical:True) -
weight_pounds(tipo:FLOAT)
Come spiegato nelle operazioni di preelaborazione nella prima parte di questa serie, la trasformazione delle caratteristiche converte le caratteristiche categoriali in una rappresentazione numerica. Dopo la trasformazione, le caratteristiche categoriali sono rappresentate da valori interi. Nell'entità transformed_metadata.schema , il flag is_categorical per le colonne di tipo INT indica se la colonna rappresenta una caratteristica categoriale o una vera caratteristica numerica.
Scrivere dati di allenamento trasformati
Dopo che i dati di training sono stati preelaborati con la funzione preprocess_fn attraverso le fasi di analisi e trasformazione, è possibile scrivere i dati in un sink da utilizzare per il training del modello TensorFlow. Quando esegui la pipeline Apache Beam utilizzando Dataflow, il sink è Cloud Storage. Altrimenti il sink è il disco locale. Sebbene sia possibile scrivere i dati come file CSV di file formattati a larghezza fissa, il formato file consigliato per i set di dati TensorFlow è il formato TFRecord. Si tratta di un semplice formato binario orientato ai record costituito da messaggi buffer del protocollo tf.train.Example .
Ogni record tf.train.Example contiene una o più funzionalità. Questi vengono convertiti in tensori quando vengono inseriti nel modello per l'addestramento. Il codice seguente scrive il set di dati trasformato nei file TFRecord nella posizione specificata:
def write_tfrecords(transformed_dataset, location, step):
from tfx_bsl.coders import example_coder
transformed_data, transformed_metadata = transformed_dataset
(
transformed_data
| '{} - Encode Transformed Data'.format(step) >> beam.FlatMapTuple(
lambda batch, _: example_coder.RecordBatchToExamples(batch))
| '{} - Write Transformed Data'.format(step) >> beam.io.WriteToTFRecord(
file_path_prefix=os.path.join(location,'{}'.format(step)),
file_name_suffix='.tfrecords')
)
Leggere, trasformare e scrivere dati di valutazione
Dopo aver trasformato i dati di training e prodotto il grafico transform_fn , puoi utilizzarlo per trasformare i dati di valutazione. Innanzitutto, leggi e pulisci i dati di valutazione da BigQuery utilizzando la funzione read_from_bq descritta in precedenza in Leggere i dati di addestramento non elaborati da BigQuery e passando un valore eval per il parametro step . Quindi, utilizza il codice seguente per trasformare il set di dati di valutazione non elaborato ( raw_dataset ) nel formato trasformato previsto ( transformed_dataset ):
def transform(raw_dataset, transform_fn, step):
transformed_dataset = (
(raw_dataset, transform_fn)
| '{} - Transform'.format(step) >> tft_beam.TransformDataset(output_record_batches=True)
)
return transformed_dataset
Quando trasformi i dati di valutazione, si applicano solo le operazioni a livello di istanza, utilizzando sia la logica nel grafico transform_fn che le statistiche calcolate dalla fase di analisi nei dati di training. In altre parole, non si analizzano i dati di valutazione in modo completo per calcolare nuove statistiche, come la media e la varianza per la normalizzazione del punteggio z delle caratteristiche numeriche nei dati di valutazione. Utilizza invece le statistiche calcolate dai dati di training per trasformare i dati di valutazione a livello di istanza.
Pertanto, si utilizza il metodo AnalyzeAndTransform nel contesto dei dati di training per calcolare le statistiche e trasformare i dati. Allo stesso tempo, utilizzi il metodo TransformDataset nel contesto della trasformazione dei dati di valutazione per trasformare solo i dati utilizzando le statistiche calcolate sui dati di training.
Quindi si scrivono i dati su un sink (Cloud Storage o disco locale, a seconda del runner) nel formato TFRecord per valutare il modello TensorFlow durante il processo di training. A tale scopo, utilizza la funzione write_tfrecords illustrata in Scrittura di dati di training trasformati . Il diagramma seguente, figura 3, mostra come viene utilizzato il grafico transform_fn prodotto nella fase di analisi dei dati di training per trasformare i dati di valutazione.

transform_fn .Salva il grafico
Un passaggio finale nella pipeline di preelaborazione tf.Transform consiste nell'archiviare gli artefatti, che include il grafico transform_fn prodotto dalla fase di analisi sui dati di training. Il codice per la memorizzazione degli artefatti è mostrato nella seguente funzione write_transform_artefacts :
def write_transform_artefacts(transform_fn, location):
(
transform_fn
| 'Write Transform Artifacts' >> transform_fn_io.WriteTransformFn(location)
)
Questi artefatti verranno utilizzati in seguito per l'addestramento del modello e l'esportazione per la pubblicazione. Vengono prodotti anche i seguenti artefatti, come mostrato nella sezione successiva:
-
saved_model.pb: rappresenta il grafico TensorFlow che include la logica di trasformazione (il graficotransform_fn), che deve essere collegato all'interfaccia di servizio del modello per trasformare i punti dati grezzi nel formato trasformato. -
variables: include le statistiche calcolate durante la fase di analisi dei dati di training e viene utilizzata nella logica di trasformazione nell'artefattosaved_model.pb. -
assets: include file di vocabolario, uno per ciascuna caratteristica categoriale elaborata con il metodocompute_and_apply_vocabulary, da utilizzare durante la pubblicazione per convertire un valore nominale grezzo di input in un indice numerico. -
transformed_metadata: una directory che contiene il fileschema.jsonche descrive lo schema dei dati trasformati.
Esegui la pipeline in Dataflow
Dopo aver definito la pipeline tf.Transform , esegui la pipeline utilizzando Dataflow. Il diagramma seguente, figura 4, mostra il grafico di esecuzione del flusso di dati della pipeline tf.Transform descritta nell'esempio.
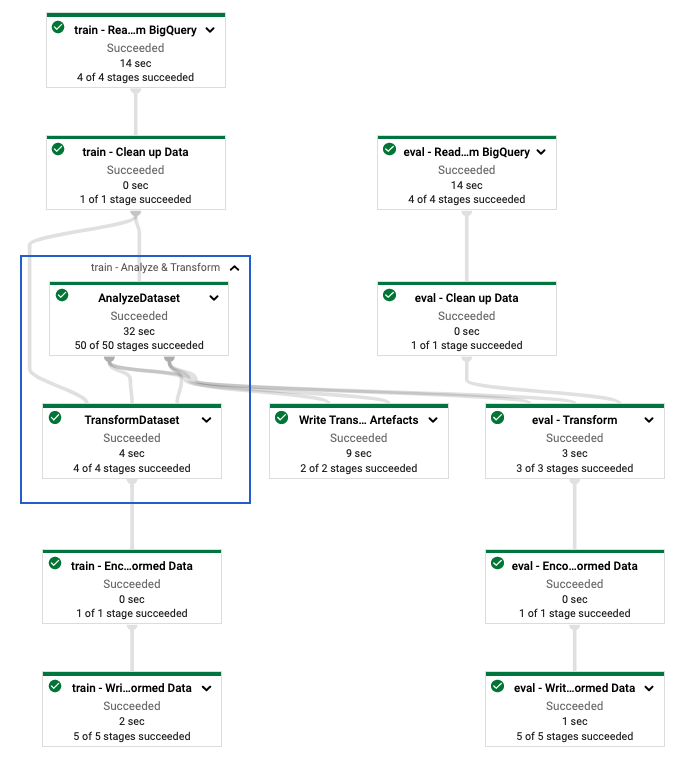
tf.Transform . Dopo aver eseguito la pipeline Dataflow per preelaborare i dati di addestramento e valutazione, puoi esplorare gli oggetti prodotti in Cloud Storage eseguendo l'ultima cella nel notebook. Gli snippet di codice in questa sezione mostrano i risultati, dove YOUR_BUCKET_NAME è il nome del tuo bucket Cloud Storage.
I dati di addestramento e valutazione trasformati nel formato TFRecord vengono archiviati nella seguente posizione:
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed
Gli artefatti di trasformazione vengono prodotti nella seguente posizione:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform
L'elenco seguente è l'output della pipeline, che mostra gli oggetti dati e gli artefatti prodotti:
transformed data:
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/eval-00000-of-00001.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00000-of-00002.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00001-of-00002.tfrecords
transformed metadata:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/asset_map
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/schema.pbtxt
transform artefact:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/saved_model.pb
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/variables/
transform assets:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_male
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_multiple
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/mother_race
Implementare il modello TensorFlow
Questa sezione e quella successiva, Addestrare e utilizzare il modello per le previsioni , forniscono una panoramica e un contesto per il Notebook 2. Il notebook fornisce un modello ML di esempio per prevedere il peso del bambino. In questo esempio, un modello TensorFlow viene implementato utilizzando l'API Keras. Il modello utilizza i dati e gli artefatti prodotti dalla pipeline di preelaborazione tf.Transform spiegata in precedenza.
Esegui il taccuino 2
Nell'interfaccia JupyterLab, fare clic su File > Apri dal percorso e quindi immettere il seguente percorso:
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_02.ipynbFare clic su Modifica > Cancella tutti gli output .
Nella sezione Installa pacchetti richiesti , esegui la prima cella per eseguire il comando
pip install tensorflow-transform.L'ultima parte dell'output è la seguente:
Successfully installed ... Note: you may need to restart the kernel to use updated packages.È possibile ignorare gli errori di dipendenza nell'output.
Nel menu Kernel , seleziona Riavvia Kernel .
Esegui le celle nelle sezioni Conferma i pacchetti installati e Crea setup.py per installare i pacchetti nei contenitori Dataflow .
Nella sezione Imposta flag globali , accanto a
PROJECTeBUCKET, sostituisciyour-projectcon l'ID del tuo progetto cloud, quindi esegui la cella.Esegui tutte le celle rimanenti attraverso l'ultima cella del taccuino. Per informazioni su cosa fare in ciascuna cella, vedere le istruzioni nel taccuino.
Panoramica della creazione del modello
I passaggi per la creazione del modello sono i seguenti:
- Crea colonne di funzionalità utilizzando le informazioni sullo schema archiviate nella directory
transformed_metadata. - Crea il modello ampio e profondo con l'API Keras utilizzando le colonne delle funzionalità come input per il modello.
- Crea la funzione
tfrecords_input_fnper leggere e analizzare i dati di training e valutazione utilizzando gli artefatti di trasformazione. - Formare e valutare il modello.
- Esporta il modello addestrato definendo una funzione
serving_fna cui è allegato il graficotransform_fn. - Ispeziona il modello esportato utilizzando lo strumento
saved_model_cli. - Utilizza il modello esportato per la previsione.
Questo documento non spiega come costruire il modello, quindi non discute in dettaglio come il modello è stato costruito o addestrato. Tuttavia, le sezioni seguenti mostrano come le informazioni archiviate nella directory transform_metadata , prodotta dal processo tf.Transform , vengono utilizzate per creare le colonne delle funzionalità del modello. Il documento mostra anche come il grafico transform_fn , anch'esso prodotto dal processo tf.Transform , viene utilizzato nella funzione serving_fn quando il modello viene esportato per la distribuzione.
Utilizzare gli artefatti di trasformazione generati nell'addestramento del modello
Quando esegui il training del modello TensorFlow, utilizzi gli oggetti train e eval trasformati prodotti nella fase precedente di elaborazione dei dati. Questi oggetti vengono archiviati come file partizionati nel formato TFRecord. Le informazioni sullo schema nella directory transformed_metadata generata nel passaggio precedente possono essere utili per analizzare i dati (oggetti tf.train.Example ) da inserire nel modello per l'addestramento e la valutazione.
Analizzare i dati
Poiché leggi i file nel formato TFRecord per alimentare il modello con dati di addestramento e valutazione, devi analizzare ogni oggetto tf.train.Example nei file per creare un dizionario di funzionalità (tensori). Ciò garantisce che le funzionalità siano mappate al livello di input del modello utilizzando le colonne delle funzionalità, che fungono da interfaccia di addestramento e valutazione del modello. Per analizzare i dati, utilizza l'oggetto TFTransformOutput creato dagli artefatti generati nel passaggio precedente:
Crea un oggetto
TFTransformOutputdagli artefatti generati e salvati nella fase di preelaborazione precedente, come descritto nella sezione Salvare il grafico :tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)Estrai un oggetto
feature_specdall'oggettoTFTransformOutput:tf_transform_output.transformed_feature_spec()Utilizza l'oggetto
feature_specper specificare le funzionalità contenute nell'oggettotf.train.Examplecome nella funzionetfrecords_input_fn:def tfrecords_input_fn(files_name_pattern, batch_size=512): tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR) TARGET_FEATURE_NAME = 'weight_pounds' batched_dataset = tf.data.experimental.make_batched_features_dataset( file_pattern=files_name_pattern, batch_size=batch_size, features=tf_transform_output.transformed_feature_spec(), reader=tf.data.TFRecordDataset, label_key=TARGET_FEATURE_NAME, shuffle=True).prefetch(tf.data.experimental.AUTOTUNE) return batched_dataset
Creare le colonne delle funzionalità
La pipeline produce le informazioni sullo schema nella directory transformed_metadata che descrive lo schema dei dati trasformati previsto dal modello per l'addestramento e la valutazione. Lo schema contiene il nome della funzionalità e il tipo di dati, come i seguenti:
-
gestation_weeks_scaled(tipo:FLOAT) -
is_male_index(tipo:INT, is_categorical:True) -
is_multiple_index(tipo:INT, is_categorical:True) -
mother_age_bucketized(tipo:INT, is_categorical:True) -
mother_age_log(tipo:FLOAT) -
mother_age_normalized(tipo:FLOAT) -
mother_race_index(tipo:INT, is_categorical:True) -
weight_pounds(tipo:FLOAT)
Per visualizzare queste informazioni, utilizzare i seguenti comandi:
transformed_metadata = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR).transformed_metadata
transformed_metadata.schema
Il codice seguente mostra come utilizzare il nome della funzionalità per creare colonne di funzionalità:
def create_wide_and_deep_feature_columns():
deep_feature_columns = []
wide_feature_columns = []
inputs = {}
categorical_columns = {}
# Select features you've checked from the metadata
# Categorical features are associated with the vocabulary size (starting from 0)
numeric_features = ['mother_age_log', 'mother_age_normalized', 'gestation_weeks_scaled']
categorical_features = [('is_male_index', 1), ('is_multiple_index', 1),
('mother_age_bucketized', 4), ('mother_race_index', 10)]
for feature in numeric_features:
deep_feature_columns.append(tf.feature_column.numeric_column(feature))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='float32')
for feature, vocab_size in categorical_features:
categorical_columns[feature] = (
tf.feature_column.categorical_column_with_identity(feature, num_buckets=vocab_size+1))
wide_feature_columns.append(tf.feature_column.indicator_column(categorical_columns[feature]))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='int64')
mother_race_X_mother_age_bucketized = tf.feature_column.crossed_column(
[categorical_columns['mother_age_bucketized'],
categorical_columns['mother_race_index']], 55)
wide_feature_columns.append(tf.feature_column.indicator_column(mother_race_X_mother_age_bucketized))
mother_race_X_mother_age_bucketized_embedded = tf.feature_column.embedding_column(
mother_race_X_mother_age_bucketized, 5)
deep_feature_columns.append(mother_race_X_mother_age_bucketized_embedded)
return wide_feature_columns, deep_feature_columns, inputs
Il codice crea una colonna tf.feature_column.numeric_column per le funzionalità numeriche e una colonna tf.feature_column.categorical_column_with_identity per le funzionalità categoriali.
Puoi anche creare colonne di funzionalità estese, come descritto in Opzione C: TensorFlow nella prima parte di questa serie. Nell'esempio utilizzato per questa serie, viene creata una nuova funzionalità, mother_race_X_mother_age_bucketized , incrociando le funzionalità mother_race e mother_age_bucketized utilizzando la colonna della funzionalità tf.feature_column.crossed_column . La rappresentazione densa e a bassa dimensione di questa funzione incrociata viene creata utilizzando la colonna della funzione tf.feature_column.embedding_column .
Il diagramma seguente, figura 5, mostra i dati trasformati e il modo in cui i metadati trasformati vengono utilizzati per definire e addestrare il modello TensorFlow:

Esporta il modello per la previsione della pubblicazione
Dopo aver addestrato il modello TensorFlow con l'API Keras, esporti il modello addestrato come oggetto SavedModel, in modo che possa fornire nuovi punti dati per la previsione. Quando esporti il modello, devi definire la sua interfaccia, ovvero lo schema delle funzionalità di input previsto durante l'elaborazione. Questo schema delle caratteristiche di input è definito nella serving_fn , come mostrato nel codice seguente:
def export_serving_model(model, output_dir):
tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)
# The layer has to be saved to the model for Keras tracking purposes.
model.tft_layer = tf_transform_output.transform_features_layer()
@tf.function
def serveing_fn(uid, is_male, mother_race, mother_age, plurality, gestation_weeks):
features = {
'is_male': is_male,
'mother_race': mother_race,
'mother_age': mother_age,
'plurality': plurality,
'gestation_weeks': gestation_weeks
}
transformed_features = model.tft_layer(features)
outputs = model(transformed_features)
# The prediction results have multiple elements in general.
# But we need only the first element in our case.
outputs = tf.map_fn(lambda item: item[0], outputs)
return {'uid': uid, 'weight': outputs}
concrete_serving_fn = serveing_fn.get_concrete_function(
tf.TensorSpec(shape=[None], dtype=tf.string, name='uid'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='is_male'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='mother_race'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='mother_age'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='plurality'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='gestation_weeks')
)
signatures = {'serving_default': concrete_serving_fn}
model.save(output_dir, save_format='tf', signatures=signatures)
Durante l'elaborazione, il modello prevede che i punti dati siano nella loro forma grezza (ovvero, funzionalità grezze prima delle trasformazioni). Pertanto, la serving_fn riceve le funzionalità grezze e le memorizza in un oggetto features come dizionario Python. Tuttavia, come discusso in precedenza, il modello addestrato prevede i punti dati nello schema trasformato. Per convertire le funzionalità grezze negli oggetti transformed_features previsti dall'interfaccia del modello, applicare il grafico transform_fn salvato all'oggetto features con i seguenti passaggi:
Crea l'oggetto
TFTransformOutputdagli artefatti generati e salvati nella fase di preelaborazione precedente:tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)Crea un oggetto
TransformFeaturesLayerdall'oggettoTFTransformOutput:model.tft_layer = tf_transform_output.transform_features_layer()Applica il grafico
transform_fnutilizzando l'oggettoTransformFeaturesLayer:transformed_features = model.tft_layer(features)
Il diagramma seguente, figura 6, illustra il passaggio finale dell'esportazione di un modello per la pubblicazione:

transform_fn allegato. Addestrare e utilizzare il modello per le previsioni
È possibile addestrare il modello localmente eseguendo le celle del notebook. Per esempi su come creare pacchetti del codice e addestrare il modello su larga scala utilizzando Vertex AI Training, consulta gli esempi e le guide nel repository GitHub cloudml-samples di Google Cloud.
Quando controlli l'oggetto SavedModel esportato utilizzando lo strumento saved_model_cli , vedi che gli elementi inputs della definizione di firma signature_def includono le funzionalità grezze, come mostrato nell'esempio seguente:
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input(s):
inputs['gestation_weeks'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_gestation_weeks:0
inputs['is_male'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_is_male:0
inputs['mother_age'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_mother_age:0
inputs['mother_race'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_mother_race:0
inputs['plurality'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_plurality:0
inputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_uid:0
The given SavedModel SignatureDef contains the following output(s):
outputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: StatefulPartitionedCall_6:0
outputs['weight'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: StatefulPartitionedCall_6:1
Method name is: tensorflow/serving/predict
Le celle rimanenti del notebook mostrano come utilizzare il modello esportato per una previsione locale e come distribuire il modello come microservizio utilizzando Vertex AI Prediction. È importante evidenziare che in entrambi i casi il punto dati di input (campione) si trova nello schema grezzo.
Ripulire
Per evitare di incorrere in addebiti aggiuntivi sul tuo account Google Cloud per le risorse utilizzate in questo tutorial, elimina il progetto che contiene le risorse.
Elimina il progetto
Nella console Google Cloud, vai alla pagina Gestisci risorse .
Nell'elenco dei progetti, seleziona il progetto che desideri eliminare, quindi fai clic su Elimina .
Nella finestra di dialogo, digitare l'ID progetto, quindi fare clic su Arresta per eliminare il progetto.
Qual è il prossimo passo?
- Per conoscere i concetti, le sfide e le opzioni della preelaborazione dei dati per il machine learning su Google Cloud, consulta il primo articolo di questa serie, Preelaborazione dei dati per ML: opzioni e consigli .
- Per ulteriori informazioni su come implementare, creare pacchetti ed eseguire una pipeline tf.Transform su Dataflow, vedere l'esempio Previsione del reddito con il set di dati del censimento .
- Ottieni la specializzazione Coursera su ML con TensorFlow su Google Cloud .
- Scopri le best practice per l'ingegneria ML in Rules of ML .
- Per ulteriori architetture di riferimento, diagrammi e best practice, esplora il Cloud Architecture Center .