
Tutorial ini menunjukkan cara menggunakan TensorFlow Transform (library tf.Transform ) untuk mengimplementasikan prapemrosesan data untuk machine learning (ML). Pustaka tf.Transform untuk TensorFlow memungkinkan Anda menentukan transformasi data tingkat instance dan jalur penuh melalui pipeline prapemrosesan data. Pipeline ini dieksekusi secara efisien dengan Apache Beam dan membuat grafik TensorFlow sebagai produk sampingan untuk menerapkan transformasi yang sama selama prediksi seperti saat model disajikan.
Tutorial ini memberikan contoh end-to-end menggunakan Dataflow sebagai runner untuk Apache Beam. Diasumsikan Anda sudah familiar dengan BigQuery , Dataflow, Vertex AI , dan TensorFlow Keras API. Ini juga mengasumsikan bahwa Anda memiliki pengalaman menggunakan Jupyter Notebooks, seperti dengan Vertex AI Workbench .
Tutorial ini juga mengasumsikan bahwa Anda sudah memahami konsep jenis, tantangan, dan opsi prapemrosesan di Google Cloud, seperti yang dijelaskan dalam Prapemrosesan data untuk ML: opsi dan rekomendasi .
Tujuan
- Implementasikan pipeline Apache Beam menggunakan pustaka
tf.Transform. - Jalankan alur di Dataflow.
- Implementasikan model TensorFlow menggunakan perpustakaan
tf.Transform. - Latih dan gunakan model untuk prediksi.
Biaya
Tutorial ini menggunakan komponen Google Cloud yang dapat ditagih berikut:
Untuk memperkirakan biaya menjalankan tutorial ini, dengan asumsi Anda menggunakan setiap sumber daya selama satu hari penuh, gunakan kalkulator harga yang telah dikonfigurasi sebelumnya .
Sebelum Anda mulai
Di konsol Google Cloud, pada halaman pemilih proyek, pilih atau buat proyek Google Cloud .
Pastikan penagihan diaktifkan untuk proyek Cloud Anda. Pelajari cara memeriksa apakah penagihan diaktifkan pada suatu proyek .
Aktifkan API Dataflow, Vertex AI, dan Notebooks. Aktifkan API
Notebook Jupyter untuk solusi ini
Notebook Jupyter berikut memperlihatkan contoh implementasi:
- Notebook 1 mencakup prapemrosesan data. Detailnya diberikan di bagian Mengimplementasikan pipeline Apache Beam nanti.
- Notebook 2 mencakup pelatihan model. Detailnya diberikan di bagian Menerapkan model TensorFlow nanti.
Di bagian berikut, Anda mengkloning buku catatan ini, lalu menjalankan buku catatan tersebut untuk mempelajari cara kerja contoh implementasi.
Luncurkan instans buku catatan yang dikelola pengguna
Di konsol Google Cloud, buka halaman Vertex AI Workbench .
Pada tab Buku catatan yang dikelola pengguna , klik +Buku catatan baru .
Pilih TensorFlow Enterprise 2.8 (dengan LTS) tanpa GPU untuk jenis instance.
Klik Buat .
Setelah Anda membuat notebook, tunggu hingga proksi ke JupyterLab selesai diinisialisasi. Jika sudah siap, Open JupyterLab ditampilkan di sebelah nama notebook.
Kloning buku catatannya
Pada tab Buku catatan yang dikelola pengguna , di samping nama buku catatan, klik Buka JupyterLab . Antarmuka JupyterLab terbuka di tab baru.
Jika JupyterLab menampilkan dialog Build Direkomendasikan , klik Batal untuk menolak build yang disarankan.
Pada tab Peluncur , klik Terminal .
Di jendela terminal, kloning notebook:
git clone https://github.com/GoogleCloudPlatform/training-data-analyst
Menerapkan alur Apache Beam
Bagian ini dan bagian berikutnya Jalankan alur di Dataflow memberikan gambaran umum dan konteks untuk Buku Catatan 1. Buku catatan ini memberikan contoh praktis untuk menjelaskan cara menggunakan pustaka tf.Transform untuk melakukan praproses data. Contoh ini menggunakan dataset Natality yang digunakan untuk memprediksi berat badan bayi berdasarkan berbagai input. Data disimpan dalam tabel kelahiran publik di BigQuery.
Jalankan Buku Catatan 1
Di antarmuka JupyterLab, klik File > Buka dari jalur , lalu masukkan jalur berikut:
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_01.ipynbKlik Edit > Hapus semua keluaran .
Di bagian Instal paket yang diperlukan , jalankan sel pertama untuk menjalankan perintah
pip install apache-beam.Bagian terakhir dari outputnya adalah sebagai berikut:
Successfully installed ...Anda dapat mengabaikan kesalahan ketergantungan pada output. Anda belum perlu me-restart kernel.
Jalankan sel kedua untuk menjalankan perintah
pip install tensorflow-transform. Bagian terakhir dari outputnya adalah sebagai berikut:Successfully installed ... Note: you may need to restart the kernel to use updated packages.Anda dapat mengabaikan kesalahan ketergantungan pada output.
Klik Kernel > Mulai Ulang Kernel .
Jalankan sel di bagian Konfirmasi paket yang diinstal dan Buat setup.py untuk menginstal paket ke kontainer Dataflow .
Di bagian Tetapkan bendera global , di samping
PROJECTdanBUCKET, gantiyour-projectdengan ID proyek Cloud Anda, lalu jalankan sel tersebut.Jalankan semua sel yang tersisa melalui sel terakhir di buku catatan. Untuk informasi tentang apa yang harus dilakukan di setiap sel, lihat petunjuk di buku catatan.
Ikhtisar pipa
Dalam contoh notebook, Dataflow menjalankan alur tf.Transform dalam skala besar untuk menyiapkan data dan menghasilkan artefak transformasi. Bagian selanjutnya dalam dokumen ini menjelaskan fungsi yang menjalankan setiap langkah dalam alur. Langkah-langkah pipeline secara keseluruhan adalah sebagai berikut:
- Baca data pelatihan dari BigQuery.
- Analisis dan transformasi data pelatihan menggunakan perpustakaan
tf.Transform. - Tulis data pelatihan yang diubah ke Cloud Storage dalam format TFRecord .
- Baca data evaluasi dari BigQuery.
- Transformasikan data evaluasi menggunakan grafik
transform_fnyang dihasilkan pada langkah 2. - Tulis data pelatihan yang diubah ke Cloud Storage dalam format TFRecord.
- Tulis artefak transformasi ke Cloud Storage yang nantinya akan digunakan untuk membuat dan mengekspor model.
Contoh berikut menunjukkan kode Python untuk keseluruhan alur. Bagian berikut memberikan penjelasan dan daftar kode untuk setiap langkah.
def run_transformation_pipeline(args):
pipeline_options = beam.pipeline.PipelineOptions(flags=[], **args)
runner = args['runner']
data_size = args['data_size']
transformed_data_location = args['transformed_data_location']
transform_artefact_location = args['transform_artefact_location']
temporary_dir = args['temporary_dir']
debug = args['debug']
# Instantiate the pipeline
with beam.Pipeline(runner, options=pipeline_options) as pipeline:
with impl.Context(temporary_dir):
# Preprocess train data
step = 'train'
# Read raw train data from BigQuery
raw_train_dataset = read_from_bq(pipeline, step, data_size)
# Analyze and transform raw_train_dataset
transformed_train_dataset, transform_fn = analyze_and_transform(raw_train_dataset, step)
# Write transformed train data to sink as tfrecords
write_tfrecords(transformed_train_dataset, transformed_data_location, step)
# Preprocess evaluation data
step = 'eval'
# Read raw eval data from BigQuery
raw_eval_dataset = read_from_bq(pipeline, step, data_size)
# Transform eval data based on produced transform_fn
transformed_eval_dataset = transform(raw_eval_dataset, transform_fn, step)
# Write transformed eval data to sink as tfrecords
write_tfrecords(transformed_eval_dataset, transformed_data_location, step)
# Write transformation artefacts
write_transform_artefacts(transform_fn, transform_artefact_location)
# (Optional) for debugging, write transformed data as text
step = 'debug'
# Write transformed train data as text if debug enabled
if debug == True:
write_text(transformed_train_dataset, transformed_data_location, step)
Baca data pelatihan mentah dari BigQuery
Langkah pertama adalah membaca data pelatihan mentah dari BigQuery menggunakan fungsi read_from_bq . Fungsi ini mengembalikan objek raw_dataset yang diekstrak dari BigQuery. Anda meneruskan nilai data_size dan meneruskan nilai step train atau eval . Kueri sumber BigQuery dibuat menggunakan fungsi get_source_query , seperti yang ditunjukkan dalam contoh berikut:
def read_from_bq(pipeline, step, data_size):
source_query = get_source_query(step, data_size)
raw_data = (
pipeline
| '{} - Read Data from BigQuery'.format(step) >> beam.io.Read(
beam.io.BigQuerySource(query=source_query, use_standard_sql=True))
| '{} - Clean up Data'.format(step) >> beam.Map(prep_bq_row)
)
raw_metadata = create_raw_metadata()
raw_dataset = (raw_data, raw_metadata)
return raw_dataset
Sebelum Anda melakukan prapemrosesan tf.Transform , Anda mungkin perlu melakukan pemrosesan khas berbasis Apache Beam, termasuk pemrosesan Peta, Filter, Grup, dan Jendela. Dalam contoh ini, kode membersihkan catatan yang dibaca dari BigQuery menggunakan metode beam.Map(prep_bq_row) , dengan prep_bq_row sebagai fungsi khusus. Fungsi khusus ini mengubah kode numerik untuk fitur kategorikal menjadi label yang dapat dibaca manusia.
Selain itu, untuk menggunakan pustaka tf.Transform guna menganalisis dan mentransformasikan objek raw_data yang diekstrak dari BigQuery, Anda perlu membuat objek raw_dataset , yang merupakan tuple dari objek raw_data dan raw_metadata . Objek raw_metadata dibuat menggunakan fungsi create_raw_metadata , sebagai berikut:
CATEGORICAL_FEATURE_NAMES = ['is_male', 'mother_race']
NUMERIC_FEATURE_NAMES = ['mother_age', 'plurality', 'gestation_weeks']
TARGET_FEATURE_NAME = 'weight_pounds'
def create_raw_metadata():
feature_spec = dict(
[(name, tf.io.FixedLenFeature([], tf.string)) for name in CATEGORICAL_FEATURE_NAMES] +
[(name, tf.io.FixedLenFeature([], tf.float32)) for name in NUMERIC_FEATURE_NAMES] +
[(TARGET_FEATURE_NAME, tf.io.FixedLenFeature([], tf.float32))])
raw_metadata = dataset_metadata.DatasetMetadata(
schema_utils.schema_from_feature_spec(feature_spec))
return raw_metadata
Saat Anda menjalankan sel di buku catatan yang langsung mengikuti sel yang mendefinisikan metode ini, konten objek raw_metadata.schema ditampilkan. Ini mencakup kolom berikut:
-
gestation_weeks(tipe:FLOAT) -
is_male(ketik:BYTES) -
mother_age(ketik:FLOAT) -
mother_race(ketik:BYTES) -
plurality(tipe:FLOAT) -
weight_pounds(ketik:FLOAT)
Ubah data pelatihan mentah
Bayangkan Anda ingin menerapkan transformasi pra-pemrosesan yang umum pada fitur input mentah dari data pelatihan untuk mempersiapkannya untuk ML. Transformasi ini mencakup operasi tingkat penuh dan tingkat instans, seperti yang ditunjukkan dalam tabel berikut:
| Fitur masukan | Transformasi | Statistik dibutuhkan | Jenis | Fitur keluaran |
|---|---|---|---|---|
weight_pound | Tidak ada | Tidak ada | TIDAK | weight_pound |
mother_age | Normalisasi | maksudnya, var | Lulus penuh | mother_age_normalized |
mother_age | Bucketisasi berukuran sama | kuantil | Lulus penuh | mother_age_bucketized |
mother_age | Hitung lognya | Tidak ada | Tingkat instans | mother_age_log |
plurality | Tunjukkan apakah itu bayi tunggal atau ganda | Tidak ada | Tingkat instans | is_multiple |
is_multiple | Ubah nilai nominal menjadi indeks numerik | kosakata | Lulus penuh | is_multiple_index |
gestation_weeks | Skala antara 0 dan 1 | min, maks | Lulus penuh | gestation_weeks_scaled |
mother_race | Ubah nilai nominal menjadi indeks numerik | kosakata | Lulus penuh | mother_race_index |
is_male | Ubah nilai nominal menjadi indeks numerik | kosakata | Lulus penuh | is_male_index |
Transformasi ini diimplementasikan dalam fungsi preprocess_fn , yang mengharapkan kamus tensor ( input_features ) dan mengembalikan kamus fitur yang diproses ( output_features ).
Kode berikut menunjukkan implementasi fungsi preprocess_fn , menggunakan API transformasi full-pass tf.Transform (diawali dengan tft. ), dan operasi tingkat instance TensorFlow (diawali dengan tf. ):
def preprocess_fn(input_features):
output_features = {}
# target feature
output_features['weight_pounds'] = input_features['weight_pounds']
# normalization
output_features['mother_age_normalized'] = tft.scale_to_z_score(input_features['mother_age'])
# scaling
output_features['gestation_weeks_scaled'] = tft.scale_to_0_1(input_features['gestation_weeks'])
# bucketization based on quantiles
output_features['mother_age_bucketized'] = tft.bucketize(input_features['mother_age'], num_buckets=5)
# you can compute new features based on custom formulas
output_features['mother_age_log'] = tf.math.log(input_features['mother_age'])
# or create flags/indicators
is_multiple = tf.as_string(input_features['plurality'] > tf.constant(1.0))
# convert categorical features to indexed vocab
output_features['mother_race_index'] = tft.compute_and_apply_vocabulary(input_features['mother_race'], vocab_filename='mother_race')
output_features['is_male_index'] = tft.compute_and_apply_vocabulary(input_features['is_male'], vocab_filename='is_male')
output_features['is_multiple_index'] = tft.compute_and_apply_vocabulary(is_multiple, vocab_filename='is_multiple')
return output_features
Framework tf.Transform memiliki beberapa transformasi lain selain transformasi pada contoh sebelumnya, termasuk yang tercantum dalam tabel berikut:
| Transformasi | Berlaku untuk | Keterangan |
|---|---|---|
scale_by_min_max | Fitur numerik | Menskalakan kolom numerik ke dalam rentang [ output_min , output_max ] |
scale_to_0_1 | Fitur numerik | Mengembalikan kolom yang merupakan kolom masukan yang diskalakan memiliki rentang [ 0 , 1 ] |
scale_to_z_score | Fitur numerik | Mengembalikan kolom terstandar dengan mean 0 dan varians 1 |
tfidf | Fitur teks | Memetakan suku-suku dalam x ke frekuensi sukunya * frekuensi dokumen terbalik |
compute_and_apply_vocabulary | Fitur kategoris | Menghasilkan kosakata untuk fitur kategorikal dan memetakannya ke bilangan bulat dengan kosakata ini |
ngrams | Fitur teks | Membuat SparseTensor n-gram |
hash_strings | Fitur kategoris | Hash string ke dalam ember |
pca | Fitur numerik | Menghitung PCA pada kumpulan data menggunakan kovarians yang bias |
bucketize | Fitur numerik | Mengembalikan kolom keranjang berukuran sama (berbasis kuantitas), dengan indeks keranjang yang ditetapkan ke setiap masukan |
Untuk menerapkan transformasi yang diterapkan dalam fungsi preprocess_fn ke objek raw_train_dataset yang dihasilkan pada langkah alur sebelumnya, Anda menggunakan metode AnalyzeAndTransformDataset . Metode ini mengharapkan objek raw_dataset sebagai input, menerapkan fungsi preprocess_fn , dan menghasilkan objek transformed_dataset dan grafik transform_fn . Kode berikut mengilustrasikan pemrosesan ini:
def analyze_and_transform(raw_dataset, step):
transformed_dataset, transform_fn = (
raw_dataset
| '{} - Analyze & Transform'.format(step) >> tft_beam.AnalyzeAndTransformDataset(
preprocess_fn, output_record_batches=True)
)
return transformed_dataset, transform_fn
Transformasi diterapkan pada data mentah dalam dua tahap: tahap analisis dan tahap transformasi. Gambar 3 selanjutnya dalam dokumen ini menunjukkan bagaimana metode AnalyzeAndTransformDataset didekomposisi menjadi metode AnalyzeDataset dan metode TransformDataset .
Fase analisis
Pada fase analisis, data pelatihan mentah dianalisis dalam proses full-pass untuk menghitung statistik yang diperlukan untuk transformasi. Ini termasuk menghitung mean, varians, minimum, maksimum, kuantil, dan kosakata. Proses analisis mengharapkan kumpulan data mentah (data mentah ditambah metadata mentah), dan menghasilkan dua keluaran:
-
transform_fn: grafik TensorFlow yang berisi statistik yang dihitung dari fase analisis dan logika transformasi (yang menggunakan statistik) sebagai operasi tingkat instance. Seperti yang dibahas nanti di Simpan grafik , grafiktransform_fndisimpan untuk dilampirkan ke fungsi modelserving_fn. Hal ini memungkinkan penerapan transformasi yang sama pada titik data prediksi online. -
transform_metadata: objek yang menggambarkan skema data yang diharapkan setelah transformasi.
Tahap analisa diilustrasikan pada diagram berikut, gambar 1:

tf.Transform . Penganalisis tf.Transform mencakup min , max , sum , size , mean , var , covariance , quantiles , vocabulary , dan pca .
Fase transformasi
Pada fase transformasi, grafik transform_fn yang dihasilkan oleh fase analisis digunakan untuk mentransformasikan data pelatihan mentah dalam proses tingkat instans untuk menghasilkan data pelatihan yang diubah. Data pelatihan yang diubah dipasangkan dengan metadata yang diubah (diproduksi oleh fase analisis) untuk menghasilkan kumpulan data transformed_train_dataset .
Fase transformasi diilustrasikan pada diagram berikut, gambar 2:

tf.Transform . Untuk melakukan praproses fitur, Anda memanggil transformasi tensorflow_transform yang diperlukan (diimpor sebagai tft dalam kode) dalam implementasi fungsi preprocess_fn Anda. Misalnya, saat Anda memanggil operasi tft.scale_to_z_score , pustaka tf.Transform menerjemahkan pemanggilan fungsi ini menjadi penganalisis mean dan varians, menghitung statistik dalam fase analisis, lalu menerapkan statistik ini untuk menormalkan fitur numerik dalam fase transformasi. Ini semua dilakukan secara otomatis dengan memanggil metode AnalyzeAndTransformDataset(preprocess_fn) .
Entitas transformed_metadata.schema yang dihasilkan oleh panggilan ini mencakup kolom berikut:
-
gestation_weeks_scaled(ketik:FLOAT) -
is_male_index(ketik:INT, is_categorical:True) -
is_multiple_index(ketik:INT, is_categorical:True) -
mother_age_bucketized(ketik:INT, is_categorical:True) -
mother_age_log(ketik:FLOAT) -
mother_age_normalized(ketik:FLOAT) -
mother_race_index(ketik:INT, is_categorical:True) -
weight_pounds(ketik:FLOAT)
Seperti yang dijelaskan dalam Operasi prapemrosesan di bagian pertama seri ini, transformasi fitur mengubah fitur kategorikal menjadi representasi numerik. Setelah transformasi, fitur kategoris diwakili oleh nilai integer. Dalam entitas transformed_metadata.schema , tanda is_categorical untuk kolom tipe INT menunjukkan apakah kolom tersebut mewakili fitur kategorikal atau fitur numerik sebenarnya.
Tulis data pelatihan yang diubah
Setelah data pelatihan diproses terlebih dahulu dengan fungsi preprocess_fn melalui fase analisis dan transformasi, Anda dapat menulis data ke sink untuk digunakan dalam pelatihan model TensorFlow. Saat Anda menjalankan pipeline Apache Beam menggunakan Dataflow, sinknya adalah Cloud Storage. Jika tidak, wastafelnya adalah disk lokal. Meskipun Anda dapat menulis data sebagai file CSV dengan format lebar tetap, format file yang disarankan untuk kumpulan data TensorFlow adalah format TFRecord. Ini adalah format biner berorientasi rekaman sederhana yang terdiri dari pesan buffer protokol tf.train.Example .
Setiap catatan tf.train.Example berisi satu atau lebih fitur. Ini diubah menjadi tensor ketika dimasukkan ke model untuk pelatihan. Kode berikut menulis kumpulan data yang diubah ke file TFRecord di lokasi yang ditentukan:
def write_tfrecords(transformed_dataset, location, step):
from tfx_bsl.coders import example_coder
transformed_data, transformed_metadata = transformed_dataset
(
transformed_data
| '{} - Encode Transformed Data'.format(step) >> beam.FlatMapTuple(
lambda batch, _: example_coder.RecordBatchToExamples(batch))
| '{} - Write Transformed Data'.format(step) >> beam.io.WriteToTFRecord(
file_path_prefix=os.path.join(location,'{}'.format(step)),
file_name_suffix='.tfrecords')
)
Membaca, mengubah, dan menulis data evaluasi
Setelah Anda mentransformasikan data pelatihan dan menghasilkan grafik transform_fn , Anda dapat menggunakannya untuk mentransformasikan data evaluasi. Pertama, Anda membaca dan membersihkan data evaluasi dari BigQuery menggunakan fungsi read_from_bq yang dijelaskan sebelumnya dalam Membaca data pelatihan mentah dari BigQuery , dan meneruskan nilai eval untuk parameter step . Kemudian, Anda menggunakan kode berikut untuk mengubah kumpulan data evaluasi mentah ( raw_dataset ) ke format transformasi yang diharapkan ( transformed_dataset ):
def transform(raw_dataset, transform_fn, step):
transformed_dataset = (
(raw_dataset, transform_fn)
| '{} - Transform'.format(step) >> tft_beam.TransformDataset(output_record_batches=True)
)
return transformed_dataset
Saat Anda mentransformasikan data evaluasi, hanya operasi tingkat instans yang berlaku, menggunakan logika dalam grafik transform_fn dan statistik yang dihitung dari fase analisis dalam data pelatihan. Dengan kata lain, Anda tidak menganalisis data evaluasi secara menyeluruh untuk menghitung statistik baru, seperti mean dan varians untuk normalisasi skor-z fitur numerik dalam data evaluasi. Sebagai gantinya, Anda menggunakan statistik yang dihitung dari data pelatihan untuk mengubah data evaluasi dalam cara tingkat instans.
Oleh karena itu, Anda menggunakan metode AnalyzeAndTransform dalam konteks data pelatihan untuk menghitung statistik dan mengubah data. Pada saat yang sama, Anda menggunakan metode TransformDataset dalam konteks transformasi data evaluasi untuk hanya mengubah data menggunakan statistik yang dihitung pada data pelatihan.
Anda kemudian menulis data ke sink (Cloud Storage atau disk lokal, bergantung pada runner) dalam format TFRecord untuk mengevaluasi model TensorFlow selama proses pelatihan. Untuk melakukannya, gunakan fungsi write_tfrecords yang dibahas di Menulis data pelatihan yang diubah . Diagram berikut, gambar 3, menunjukkan bagaimana grafik transform_fn yang dihasilkan dalam fase analisis data pelatihan digunakan untuk mentransformasikan data evaluasi.

transform_fn .Simpan grafiknya
Langkah terakhir dalam pipeline prapemrosesan tf.Transform adalah menyimpan artefak, yang mencakup grafik transform_fn yang dihasilkan oleh fase analisis pada data pelatihan. Kode untuk menyimpan artefak ditunjukkan dalam fungsi write_transform_artefacts berikut:
def write_transform_artefacts(transform_fn, location):
(
transform_fn
| 'Write Transform Artifacts' >> transform_fn_io.WriteTransformFn(location)
)
Artefak ini nantinya akan digunakan untuk pelatihan model dan diekspor untuk penayangan. Artefak berikut juga diproduksi, seperti yang ditunjukkan pada bagian berikutnya:
-
saved_model.pb: mewakili grafik TensorFlow yang menyertakan logika transformasi (grafiktransform_fn), yang akan dilampirkan ke antarmuka penyajian model untuk mengubah titik data mentah ke format yang diubah. -
variables: mencakup statistik yang dihitung selama fase analisis data pelatihan, dan digunakan dalam logika transformasi di artefaksaved_model.pb. -
assets: termasuk file kosakata, satu untuk setiap fitur kategorikal yang diproses dengan metodecompute_and_apply_vocabulary, untuk digunakan selama penayangan guna mengonversi nilai nominal mentah masukan menjadi indeks numerik. -
transformed_metadata: direktori yang berisi fileschema.jsonyang menjelaskan skema data yang diubah.
Jalankan alur di Dataflow
Setelah Anda menentukan alur tf.Transform , Anda menjalankan alur menggunakan Dataflow. Diagram berikut, gambar 4, memperlihatkan grafik eksekusi Dataflow dari pipeline tf.Transform yang dijelaskan dalam contoh.
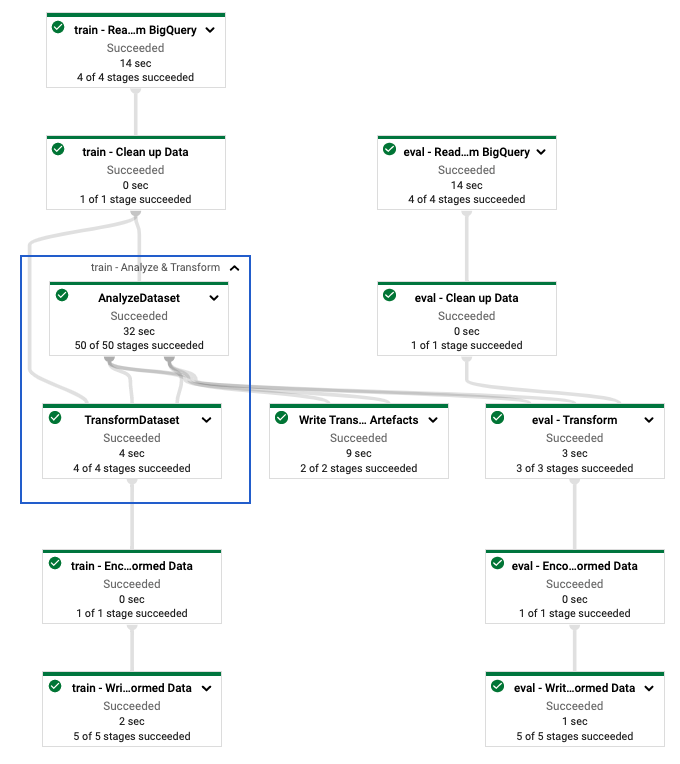
tf.Transform . Setelah Anda menjalankan pipeline Dataflow untuk melakukan praproses data pelatihan dan evaluasi, Anda dapat menjelajahi objek yang dihasilkan di Cloud Storage dengan mengeksekusi sel terakhir di notebook. Cuplikan kode di bagian ini menunjukkan hasilnya, dengan YOUR_BUCKET_NAME adalah nama bucket Cloud Storage Anda.
Data pelatihan dan evaluasi yang diubah dalam format TFRecord disimpan di lokasi berikut:
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed
Artefak transformasi diproduksi di lokasi berikut:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform
Daftar berikut adalah output dari alur, yang memperlihatkan objek data dan artefak yang dihasilkan:
transformed data:
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/eval-00000-of-00001.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00000-of-00002.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00001-of-00002.tfrecords
transformed metadata:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/asset_map
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/schema.pbtxt
transform artefact:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/saved_model.pb
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/variables/
transform assets:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_male
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_multiple
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/mother_race
Menerapkan model TensorFlow
Bagian ini dan bagian berikutnya, Melatih dan menggunakan model untuk prediksi , memberikan gambaran umum dan konteks untuk Buku Catatan 2. Buku catatan ini memberikan contoh model ML untuk memprediksi berat bayi. Dalam contoh ini, model TensorFlow diimplementasikan menggunakan Keras API. Model ini menggunakan data dan artefak yang dihasilkan oleh pipeline prapemrosesan tf.Transform yang dijelaskan sebelumnya.
Jalankan Buku Catatan 2
Di antarmuka JupyterLab, klik File > Buka dari jalur , lalu masukkan jalur berikut:
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_02.ipynbKlik Edit > Hapus semua keluaran .
Di bagian Instal paket yang diperlukan , jalankan sel pertama untuk menjalankan perintah
pip install tensorflow-transform.Bagian terakhir dari outputnya adalah sebagai berikut:
Successfully installed ... Note: you may need to restart the kernel to use updated packages.Anda dapat mengabaikan kesalahan ketergantungan pada output.
Di menu Kernel , pilih Mulai Ulang Kernel .
Jalankan sel di bagian Konfirmasi paket yang diinstal dan Buat setup.py untuk menginstal paket ke kontainer Dataflow .
Di bagian Tetapkan bendera global , di samping
PROJECTdanBUCKET, gantiyour-projectdengan ID proyek Cloud Anda, lalu jalankan sel tersebut.Jalankan semua sel yang tersisa melalui sel terakhir di buku catatan. Untuk informasi tentang apa yang harus dilakukan di setiap sel, lihat petunjuk di buku catatan.
Ikhtisar pembuatan model
Langkah-langkah membuat modelnya adalah sebagai berikut:
- Buat kolom fitur menggunakan informasi skema yang disimpan di direktori
transformed_metadata. - Buat model lebar dan dalam dengan Keras API menggunakan kolom fitur sebagai masukan ke model.
- Buat fungsi
tfrecords_input_fnuntuk membaca dan mengurai data pelatihan dan evaluasi menggunakan artefak transformasi. - Latih dan evaluasi model.
- Ekspor model terlatih dengan menentukan fungsi
serving_fnyang dilengkapi grafiktransform_fn. - Periksa model yang diekspor menggunakan alat
saved_model_cli. - Gunakan model yang diekspor untuk prediksi.
Dokumen ini tidak menjelaskan cara membuat model, sehingga tidak membahas secara detail cara model dibuat atau dilatih. Namun, bagian berikut menunjukkan bagaimana informasi yang disimpan dalam direktori transform_metadata —yang dihasilkan oleh proses tf.Transform —digunakan untuk membuat kolom fitur model. Dokumen tersebut juga menunjukkan bagaimana grafik transform_fn —yang juga dihasilkan oleh proses tf.Transform —digunakan dalam fungsi serving_fn saat model diekspor untuk penyajian.
Gunakan artefak transformasi yang dihasilkan dalam pelatihan model
Saat Anda melatih model TensorFlow, Anda menggunakan objek train dan eval yang ditransformasikan yang dihasilkan pada langkah pemrosesan data sebelumnya. Objek-objek ini disimpan sebagai file shard dalam format TFRecord. Informasi skema dalam direktori transformed_metadata yang dihasilkan pada langkah sebelumnya dapat berguna dalam penguraian data ( objek tf.train.Example ) untuk dimasukkan ke dalam model untuk pelatihan dan evaluasi.
Parsing datanya
Karena Anda membaca file dalam format TFRecord untuk memberi makan model dengan data pelatihan dan evaluasi, Anda perlu mengurai setiap objek tf.train.Example dalam file untuk membuat kamus fitur (tensor). Hal ini memastikan bahwa fitur dipetakan ke lapisan input model menggunakan kolom fitur, yang bertindak sebagai antarmuka pelatihan dan evaluasi model. Untuk mengurai data, gunakan objek TFTransformOutput yang dibuat dari artefak yang dihasilkan pada langkah sebelumnya:
Buat objek
TFTransformOutputdari artefak yang dibuat dan disimpan pada langkah prapemrosesan sebelumnya, seperti yang dijelaskan di bagian Simpan grafik :tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)Ekstrak objek
feature_specdari objekTFTransformOutput:tf_transform_output.transformed_feature_spec()Gunakan objek
feature_specuntuk menentukan fitur yang terdapat pada objektf.train.Exampleseperti pada fungsitfrecords_input_fn:def tfrecords_input_fn(files_name_pattern, batch_size=512): tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR) TARGET_FEATURE_NAME = 'weight_pounds' batched_dataset = tf.data.experimental.make_batched_features_dataset( file_pattern=files_name_pattern, batch_size=batch_size, features=tf_transform_output.transformed_feature_spec(), reader=tf.data.TFRecordDataset, label_key=TARGET_FEATURE_NAME, shuffle=True).prefetch(tf.data.experimental.AUTOTUNE) return batched_dataset
Buat kolom fitur
Pipeline menghasilkan informasi skema di direktori transformed_metadata yang menjelaskan skema data yang diubah yang diharapkan oleh model untuk pelatihan dan evaluasi. Skema berisi nama fitur dan tipe data, seperti berikut:
-
gestation_weeks_scaled(ketik:FLOAT) -
is_male_index(ketik:INT, is_categorical:True) -
is_multiple_index(ketik:INT, is_categorical:True) -
mother_age_bucketized(ketik:INT, is_categorical:True) -
mother_age_log(ketik:FLOAT) -
mother_age_normalized(ketik:FLOAT) -
mother_race_index(ketik:INT, is_categorical:True) -
weight_pounds(ketik:FLOAT)
Untuk melihat informasi ini, gunakan perintah berikut:
transformed_metadata = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR).transformed_metadata
transformed_metadata.schema
Kode berikut menunjukkan bagaimana Anda menggunakan nama fitur untuk membuat kolom fitur:
def create_wide_and_deep_feature_columns():
deep_feature_columns = []
wide_feature_columns = []
inputs = {}
categorical_columns = {}
# Select features you've checked from the metadata
# Categorical features are associated with the vocabulary size (starting from 0)
numeric_features = ['mother_age_log', 'mother_age_normalized', 'gestation_weeks_scaled']
categorical_features = [('is_male_index', 1), ('is_multiple_index', 1),
('mother_age_bucketized', 4), ('mother_race_index', 10)]
for feature in numeric_features:
deep_feature_columns.append(tf.feature_column.numeric_column(feature))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='float32')
for feature, vocab_size in categorical_features:
categorical_columns[feature] = (
tf.feature_column.categorical_column_with_identity(feature, num_buckets=vocab_size+1))
wide_feature_columns.append(tf.feature_column.indicator_column(categorical_columns[feature]))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='int64')
mother_race_X_mother_age_bucketized = tf.feature_column.crossed_column(
[categorical_columns['mother_age_bucketized'],
categorical_columns['mother_race_index']], 55)
wide_feature_columns.append(tf.feature_column.indicator_column(mother_race_X_mother_age_bucketized))
mother_race_X_mother_age_bucketized_embedded = tf.feature_column.embedding_column(
mother_race_X_mother_age_bucketized, 5)
deep_feature_columns.append(mother_race_X_mother_age_bucketized_embedded)
return wide_feature_columns, deep_feature_columns, inputs
Kode ini membuat kolom tf.feature_column.numeric_column untuk fitur numerik, dan kolom tf.feature_column.categorical_column_with_identity untuk fitur kategorikal.
Anda juga dapat membuat kolom fitur yang diperluas, seperti yang dijelaskan dalam Opsi C: TensorFlow di bagian pertama seri ini. Dalam contoh yang digunakan untuk rangkaian ini, fitur baru dibuat, mother_race_X_mother_age_bucketized , dengan menyilangkan fitur mother_race dan mother_age_bucketized menggunakan kolom fitur tf.feature_column.crossed_column . Representasi padat dan berdimensi rendah dari fitur bersilang ini dibuat menggunakan kolom fitur tf.feature_column.embedding_column .
Diagram berikut, gambar 5, menunjukkan data yang diubah dan cara metadata yang diubah digunakan untuk menentukan dan melatih model TensorFlow:

Ekspor model untuk menyajikan prediksi
Setelah Anda melatih model TensorFlow dengan Keras API, Anda mengekspor model yang dilatih sebagai objek SavedModel, sehingga dapat menyajikan titik data baru untuk prediksi. Saat mengekspor model, Anda harus menentukan antarmukanya—yaitu, skema fitur masukan yang diharapkan selama penayangan. Skema fitur masukan ini ditentukan dalam fungsi serving_fn , seperti yang ditunjukkan dalam kode berikut:
def export_serving_model(model, output_dir):
tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)
# The layer has to be saved to the model for Keras tracking purposes.
model.tft_layer = tf_transform_output.transform_features_layer()
@tf.function
def serveing_fn(uid, is_male, mother_race, mother_age, plurality, gestation_weeks):
features = {
'is_male': is_male,
'mother_race': mother_race,
'mother_age': mother_age,
'plurality': plurality,
'gestation_weeks': gestation_weeks
}
transformed_features = model.tft_layer(features)
outputs = model(transformed_features)
# The prediction results have multiple elements in general.
# But we need only the first element in our case.
outputs = tf.map_fn(lambda item: item[0], outputs)
return {'uid': uid, 'weight': outputs}
concrete_serving_fn = serveing_fn.get_concrete_function(
tf.TensorSpec(shape=[None], dtype=tf.string, name='uid'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='is_male'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='mother_race'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='mother_age'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='plurality'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='gestation_weeks')
)
signatures = {'serving_default': concrete_serving_fn}
model.save(output_dir, save_format='tf', signatures=signatures)
Selama penayangan, model mengharapkan titik data dalam bentuk mentahnya (yaitu, fitur mentah sebelum transformasi). Oleh karena itu, fungsi serving_fn menerima fitur mentah dan menyimpannya dalam objek features sebagai kamus Python. Namun, seperti yang dibahas sebelumnya, model yang dilatih mengharapkan titik data dalam skema yang diubah. Untuk mengonversi fitur mentah menjadi objek transformed_features yang diharapkan oleh antarmuka model, terapkan grafik transform_fn yang disimpan ke objek features dengan langkah-langkah berikut:
Buat objek
TFTransformOutputdari artefak yang dihasilkan dan disimpan pada langkah prapemrosesan sebelumnya:tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)Buat objek
TransformFeaturesLayerdari objekTFTransformOutput:model.tft_layer = tf_transform_output.transform_features_layer()Terapkan grafik
transform_fnmenggunakan objekTransformFeaturesLayer:transformed_features = model.tft_layer(features)
Diagram berikut, gambar 6, mengilustrasikan langkah terakhir mengekspor model untuk ditayangkan:

transform_fn terlampir. Latih dan gunakan model untuk prediksi
Anda dapat melatih model secara lokal dengan mengeksekusi sel di buku catatan. Untuk contoh cara mengemas kode dan melatih model Anda dalam skala besar menggunakan Pelatihan Vertex AI, lihat contoh dan panduan di repositori GitHub Google Cloud cloudml-samples .
Saat Anda memeriksa objek SavedModel yang diekspor menggunakan alat saved_model_cli , Anda akan melihat bahwa elemen inputs dari definisi tanda tangan signature_def menyertakan fitur mentah, seperti yang ditunjukkan dalam contoh berikut:
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input(s):
inputs['gestation_weeks'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_gestation_weeks:0
inputs['is_male'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_is_male:0
inputs['mother_age'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_mother_age:0
inputs['mother_race'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_mother_race:0
inputs['plurality'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_plurality:0
inputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_uid:0
The given SavedModel SignatureDef contains the following output(s):
outputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: StatefulPartitionedCall_6:0
outputs['weight'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: StatefulPartitionedCall_6:1
Method name is: tensorflow/serving/predict
Sel sisa buku catatan menunjukkan kepada Anda cara menggunakan model yang diekspor untuk prediksi lokal, dan cara menyebarkan model sebagai layanan mikro menggunakan Vertex AI Prediction. Penting untuk digarisbawahi bahwa titik data masukan (sampel) berada dalam skema mentah dalam kedua kasus.
Membersihkan
Untuk menghindari dikenakan biaya tambahan pada akun Google Cloud Anda untuk resource yang digunakan dalam tutorial ini, hapus project yang berisi resource tersebut.
Hapus proyek
Di konsol Google Cloud, buka halaman Kelola sumber daya .
Dalam daftar proyek, pilih proyek yang ingin Anda hapus, lalu klik Hapus .
Dalam dialog, ketikkan ID proyek, lalu klik Matikan untuk menghapus proyek.
Apa selanjutnya
- Untuk mempelajari konsep, tantangan, dan opsi prapemrosesan data untuk pembelajaran mesin di Google Cloud, lihat artikel pertama dalam seri ini, Prapemrosesan data untuk ML: opsi dan rekomendasi .
- Untuk informasi selengkapnya tentang cara menerapkan, mengemas, dan menjalankan alur tf.Transform di Dataflow, lihat contoh Memprediksi pendapatan dengan Kumpulan Data Sensus .
- Ambil spesialisasi Coursera di ML dengan TensorFlow di Google Cloud .
- Pelajari tentang praktik terbaik untuk rekayasa ML di Aturan ML .
- Untuk referensi arsitektur, diagram, dan praktik terbaik lainnya, jelajahi Pusat Arsitektur Cloud .