
این آموزش به شما نشان می دهد که چگونه از TensorFlow Transform (کتابخانه tf.Transform ) برای اجرای پیش پردازش داده برای یادگیری ماشین (ML) استفاده کنید. کتابخانه tf.Transform برای TensorFlow به شما این امکان را می دهد که هم تبدیل داده در سطح نمونه و هم با عبور کامل را از طریق خطوط لوله پیش پردازش داده تعریف کنید. این خطوط لوله به طور موثر با پرتو آپاچی اجرا می شوند و به عنوان محصول فرعی یک گراف TensorFlow را ایجاد می کنند تا در طول پیش بینی همان تبدیل های زمانی که مدل ارائه می شود اعمال شود.
این آموزش یک مثال انتها به انتها با استفاده از Dataflow به عنوان رانر برای Apache Beam ارائه می دهد. فرض بر این است که شما با BigQuery ، Dataflow، Vertex AI و TensorFlow Keras API آشنا هستید. همچنین فرض میکند که تجربه استفاده از نوتبوکهای Jupyter، مانند Vertex AI Workbench را دارید.
این آموزش همچنین فرض میکند که شما با مفاهیم انواع پیشپردازش، چالشها و گزینهها در Google Cloud، همانطور که در پیشپردازش دادهها برای ML توضیح داده شده است، آشنا هستید: گزینهها و توصیهها .
اهداف
- با استفاده از کتابخانه
tf.Transformخط لوله Apache Beam را پیاده سازی کنید. - خط لوله را در Dataflow اجرا کنید.
- مدل TensorFlow را با استفاده از کتابخانه
tf.Transformپیاده سازی کنید. - آموزش و استفاده از مدل برای پیش بینی.
هزینه ها
این آموزش از اجزای قابل پرداخت زیر در Google Cloud استفاده می کند:
برای تخمین هزینه اجرای این آموزش، با فرض استفاده از هر منبع برای یک روز کامل، از ماشین حساب قیمت گذاری از پیش تنظیم شده استفاده کنید.
قبل از شروع
در کنسول Google Cloud، در صفحه انتخابگر پروژه، یک پروژه Google Cloud را انتخاب یا ایجاد کنید .
مطمئن شوید که صورتحساب برای پروژه Cloud شما فعال است. با نحوه بررسی فعال بودن صورتحساب در پروژه آشنا شوید.
APIهای Dataflow، Vertex AI و Notebooks را فعال کنید. API ها را فعال کنید
نوت بوک های Jupyter برای این راه حل
نوت بوک های Jupyter زیر مثال پیاده سازی را نشان می دهند:
- Notebook 1 پیش پردازش داده ها را پوشش می دهد. جزئیات در بخش اجرای خط لوله پرتو آپاچی بعدا ارائه شده است.
- نوت بوک 2 آموزش مدل را پوشش می دهد. جزئیات در بخش پیاده سازی مدل TensorFlow بعداً ارائه می شود.
در بخشهای بعدی، این نوتبوکها را شبیهسازی میکنید و سپس نوتبوکها را اجرا میکنید تا نحوه عملکرد مثال پیادهسازی را یاد بگیرید.
یک نمونه نوت بوک مدیریت شده توسط کاربر را راه اندازی کنید
در کنسول Google Cloud، به صفحه Vertex AI Workbench بروید.
در برگه نوتبوکهای مدیریتشده توسط کاربر ، روی +New notebook کلیک کنید.
TensorFlow Enterprise 2.8 (با LTS) بدون GPU را برای نوع نمونه انتخاب کنید.
روی ایجاد کلیک کنید.
پس از ایجاد نوت بوک، منتظر بمانید تا پروکسی JupyterLab شروع به کار کند. وقتی آماده شد، Open JupyterLab در کنار نام نوت بوک نمایش داده می شود.
نوت بوک را شبیه سازی کنید
در برگه نوتبوکهای مدیریتشده توسط کاربر ، در کنار نام نوتبوک، روی Open JupyterLab کلیک کنید. رابط JupyterLab در یک تب جدید باز می شود.
اگر JupyterLab یک گفتگوی Build Recommended را نشان می دهد، روی Cancel کلیک کنید تا ساخت پیشنهادی رد شود.
در تب Launcher ، روی Terminal کلیک کنید.
در پنجره ترمینال، نوت بوک را شبیه سازی کنید:
git clone https://github.com/GoogleCloudPlatform/training-data-analyst
اجرای خط لوله Apache Beam
این بخش و بخش بعدی Run the pipeline در Dataflow یک نمای کلی و زمینه را برای Notebook 1 ارائه می دهد. این نوت بوک یک مثال عملی برای توضیح نحوه استفاده از کتابخانه tf.Transform برای پیش پردازش داده ها ارائه می دهد. این مثال از مجموعه داده Natality استفاده می کند که برای پیش بینی وزن نوزاد بر اساس ورودی های مختلف استفاده می شود. داده ها در جدول تولد عمومی در BigQuery ذخیره می شوند.
نوت بوک 1 را اجرا کنید
در رابط JupyterLab، روی File > Open from path کلیک کنید و سپس مسیر زیر را وارد کنید:
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_01.ipynbروی Edit > Clear all outputs کلیک کنید.
در قسمت نصب بستههای لازم ، اولین سلولی را که دستور
pip install apache-beamاجرا میکند، اجرا کنید.قسمت آخر خروجی به صورت زیر است:
Successfully installed ...می توانید خطاهای وابستگی را در خروجی نادیده بگیرید. هنوز نیازی به راه اندازی مجدد هسته ندارید.
سلول دوم را برای اجرای دستور
pip install tensorflow-transformاجرا کنید. قسمت آخر خروجی به صورت زیر است:Successfully installed ... Note: you may need to restart the kernel to use updated packages.می توانید خطاهای وابستگی را در خروجی نادیده بگیرید.
Kernel > Restart Kernel را کلیک کنید.
سلولهای موجود در Confirm the installed packages را اجرا کنید و setup.py را برای نصب بستهها در Dataflow containers ایجاد کنید .
در قسمت Set global flags ، در کنار
PROJECTوBUCKET،your-projectبا ID پروژه Cloud خود جایگزین کنید و سپس سلول را اجرا کنید.تمام سلول های باقی مانده را از طریق آخرین سلول در دفترچه یادداشت اجرا کنید. برای اطلاعات در مورد کارهایی که باید در هر سلول انجام دهید، به دستورالعمل های دفترچه یادداشت مراجعه کنید.
نمای کلی خط لوله
در مثال نوت بوک، Dataflow خط لوله tf.Transform را در مقیاس اجرا می کند تا داده ها را آماده کند و مصنوعات تبدیل را تولید کند. بخشهای بعدی این سند، عملکردهایی را که هر مرحله را در خط لوله انجام میدهند، شرح میدهند. مراحل کلی خط لوله به شرح زیر است:
- داده های آموزشی را از BigQuery بخوانید.
- تجزیه و تحلیل و تبدیل داده های آموزشی با استفاده از کتابخانه
tf.Transform. - داده های آموزشی تبدیل شده را در فضای ذخیره سازی ابری در قالب TFRecord بنویسید.
- داده های ارزیابی را از BigQuery بخوانید.
- داده های ارزیابی را با استفاده از نمودار
transform_fnکه در مرحله 2 تولید شده است، تبدیل کنید. - داده های آموزشی تبدیل شده را در فضای ذخیره سازی ابری در قالب TFRecord بنویسید.
- مصنوعات تبدیل را در Cloud Storage بنویسید که بعداً برای ایجاد و صادرات مدل استفاده میشود.
مثال زیر کد پایتون را برای خط لوله کلی نشان می دهد. بخشهایی که در ادامه میآیند، توضیحات و فهرست کدهایی را برای هر مرحله ارائه میکنند.
def run_transformation_pipeline(args):
pipeline_options = beam.pipeline.PipelineOptions(flags=[], **args)
runner = args['runner']
data_size = args['data_size']
transformed_data_location = args['transformed_data_location']
transform_artefact_location = args['transform_artefact_location']
temporary_dir = args['temporary_dir']
debug = args['debug']
# Instantiate the pipeline
with beam.Pipeline(runner, options=pipeline_options) as pipeline:
with impl.Context(temporary_dir):
# Preprocess train data
step = 'train'
# Read raw train data from BigQuery
raw_train_dataset = read_from_bq(pipeline, step, data_size)
# Analyze and transform raw_train_dataset
transformed_train_dataset, transform_fn = analyze_and_transform(raw_train_dataset, step)
# Write transformed train data to sink as tfrecords
write_tfrecords(transformed_train_dataset, transformed_data_location, step)
# Preprocess evaluation data
step = 'eval'
# Read raw eval data from BigQuery
raw_eval_dataset = read_from_bq(pipeline, step, data_size)
# Transform eval data based on produced transform_fn
transformed_eval_dataset = transform(raw_eval_dataset, transform_fn, step)
# Write transformed eval data to sink as tfrecords
write_tfrecords(transformed_eval_dataset, transformed_data_location, step)
# Write transformation artefacts
write_transform_artefacts(transform_fn, transform_artefact_location)
# (Optional) for debugging, write transformed data as text
step = 'debug'
# Write transformed train data as text if debug enabled
if debug == True:
write_text(transformed_train_dataset, transformed_data_location, step)
داده های آموزشی خام را از BigQuery بخوانید
اولین قدم خواندن داده های آموزشی خام از BigQuery با استفاده از تابع read_from_bq است. این تابع یک شیء raw_dataset را که از BigQuery استخراج شده است، برمی گرداند. شما یک مقدار data_size را ارسال می کنید و یک مقدار step از train یا eval را ارسال می کنید. پرس و جو منبع BigQuery با استفاده از تابع get_source_query ساخته شده است، همانطور که در مثال زیر نشان داده شده است:
def read_from_bq(pipeline, step, data_size):
source_query = get_source_query(step, data_size)
raw_data = (
pipeline
| '{} - Read Data from BigQuery'.format(step) >> beam.io.Read(
beam.io.BigQuerySource(query=source_query, use_standard_sql=True))
| '{} - Clean up Data'.format(step) >> beam.Map(prep_bq_row)
)
raw_metadata = create_raw_metadata()
raw_dataset = (raw_data, raw_metadata)
return raw_dataset
قبل از انجام پیشپردازش tf.Transform ، ممکن است نیاز به پردازش معمولی مبتنی بر پرتو Apache، از جمله پردازش نقشه، فیلتر، گروه و پنجره داشته باشید. در مثال، کد رکوردهای خوانده شده از BigQuery را با استفاده از روش beam.Map(prep_bq_row) پاک می کند، جایی که prep_bq_row یک تابع سفارشی است. این تابع سفارشی کد عددی یک ویژگی طبقه بندی را به برچسب های قابل خواندن توسط انسان تبدیل می کند.
علاوه بر این، برای استفاده از کتابخانه tf.Transform برای تجزیه و تحلیل و تبدیل شی raw_data استخراج شده از BigQuery، باید یک شی raw_dataset ایجاد کنید، که مجموعه ای از اشیاء raw_data و raw_metadata است. شی raw_metadata با استفاده از تابع create_raw_metadata به صورت زیر ایجاد می شود:
CATEGORICAL_FEATURE_NAMES = ['is_male', 'mother_race']
NUMERIC_FEATURE_NAMES = ['mother_age', 'plurality', 'gestation_weeks']
TARGET_FEATURE_NAME = 'weight_pounds'
def create_raw_metadata():
feature_spec = dict(
[(name, tf.io.FixedLenFeature([], tf.string)) for name in CATEGORICAL_FEATURE_NAMES] +
[(name, tf.io.FixedLenFeature([], tf.float32)) for name in NUMERIC_FEATURE_NAMES] +
[(TARGET_FEATURE_NAME, tf.io.FixedLenFeature([], tf.float32))])
raw_metadata = dataset_metadata.DatasetMetadata(
schema_utils.schema_from_feature_spec(feature_spec))
return raw_metadata
وقتی سلولی را در نوت بوک اجرا می کنید که بلافاصله بعد از سلولی که این روش را تعریف می کند، محتوای شی raw_metadata.schema نمایش داده می شود. شامل ستون های زیر است:
-
gestation_weeks(نوع:FLOAT) -
is_male(نوع:BYTES) -
mother_age(نوع:FLOAT) -
mother_race(نوع:BYTES) -
plurality(نوع:FLOAT) -
weight_pounds(نوع:FLOAT)
تبدیل داده های خام آموزشی
تصور کنید که می خواهید تبدیل های پیش پردازش معمولی را به ویژگی های خام ورودی داده های آموزشی اعمال کنید تا آن را برای ML آماده کنید. همانطور که در جدول زیر نشان داده شده است، این تبدیل ها شامل عملیات های تمام گذر و سطح نمونه هستند:
| ویژگی ورودی | دگرگونی | آمار مورد نیاز | تایپ کنید | ویژگی خروجی |
|---|---|---|---|---|
weight_pound | هیچ کدام | هیچ کدام | NA | weight_pound |
mother_age | عادی کردن | میانگین، var | پاس کامل | mother_age_normalized |
mother_age | سطل سازی با اندازه مساوی | چندک | پاس کامل | mother_age_bucketized |
mother_age | گزارش را محاسبه کنید | هیچ کدام | سطح نمونه | mother_age_log |
plurality | تک فرزند بودن یا چند قلو بودن را مشخص کنید | هیچ کدام | سطح نمونه | is_multiple |
is_multiple | تبدیل مقادیر اسمی به شاخص عددی | واژگان | پاس کامل | is_multiple_index |
gestation_weeks | مقیاس بین 0 و 1 | حداقل، حداکثر | پاس کامل | gestation_weeks_scaled |
mother_race | تبدیل مقادیر اسمی به شاخص عددی | واژگان | پاس کامل | mother_race_index |
is_male | تبدیل مقادیر اسمی به شاخص عددی | واژگان | پاس کامل | is_male_index |
این تبدیلها در یک تابع preprocess_fn پیادهسازی میشوند که انتظار یک فرهنگ لغت تانسورها ( input_features ) را دارد و یک فرهنگ لغت از ویژگیهای پردازش شده ( output_features ) را برمیگرداند.
کد زیر اجرای تابع preprocess_fn را با استفاده از عملیات سطح نمونه tf.Transform Transformation APIهای تمام گذر (با پیشوند tft. ) و TensorFlow (با پیشوند tf. ) نشان می دهد:
def preprocess_fn(input_features):
output_features = {}
# target feature
output_features['weight_pounds'] = input_features['weight_pounds']
# normalization
output_features['mother_age_normalized'] = tft.scale_to_z_score(input_features['mother_age'])
# scaling
output_features['gestation_weeks_scaled'] = tft.scale_to_0_1(input_features['gestation_weeks'])
# bucketization based on quantiles
output_features['mother_age_bucketized'] = tft.bucketize(input_features['mother_age'], num_buckets=5)
# you can compute new features based on custom formulas
output_features['mother_age_log'] = tf.math.log(input_features['mother_age'])
# or create flags/indicators
is_multiple = tf.as_string(input_features['plurality'] > tf.constant(1.0))
# convert categorical features to indexed vocab
output_features['mother_race_index'] = tft.compute_and_apply_vocabulary(input_features['mother_race'], vocab_filename='mother_race')
output_features['is_male_index'] = tft.compute_and_apply_vocabulary(input_features['is_male'], vocab_filename='is_male')
output_features['is_multiple_index'] = tft.compute_and_apply_vocabulary(is_multiple, vocab_filename='is_multiple')
return output_features
چارچوب tf.Transform علاوه بر مواردی که در مثال قبل ارائه شد، چندین تغییر دیگر نیز دارد، از جمله مواردی که در جدول زیر ذکر شده است:
| دگرگونی | اعمال می شود | توضیحات |
|---|---|---|
scale_by_min_max | ویژگی های عددی | یک ستون عددی را در محدوده [ output_min ، output_max ] مقیاس میدهد. |
scale_to_0_1 | ویژگی های عددی | ستونی را برمیگرداند که ستون ورودی است که دارای محدوده [ 0 , 1 ] است. |
scale_to_z_score | ویژگی های عددی | یک ستون استاندارد شده را با میانگین 0 و واریانس 1 برمی گرداند |
tfidf | ویژگی های متن | اصطلاحات را در x به فرکانس عبارت * فرکانس سند معکوس نگاشت می کند |
compute_and_apply_vocabulary | ویژگی های دسته بندی | یک واژگان برای یک ویژگی دسته بندی ایجاد می کند و با این واژگان آن را به یک عدد صحیح نگاشت می کند. |
ngrams | ویژگی های متن | یک SparseTensor از n گرم ایجاد می کند |
hash_strings | ویژگی های طبقه بندی شده | رشته ها را در سطل ها درهم می کند |
pca | ویژگی های عددی | PCA را روی مجموعه داده با استفاده از کوواریانس بایاس محاسبه می کند |
bucketize | ویژگی های عددی | یک ستون سطلی با اندازه مساوی (مبتنی بر چندک) را با یک شاخص سطلی اختصاص داده شده به هر ورودی برمیگرداند. |
برای اعمال تبدیل های اجرا شده در تابع preprocess_fn به شی raw_train_dataset تولید شده در مرحله قبلی خط لوله، از روش AnalyzeAndTransformDataset استفاده می کنید. این روش از شیء raw_dataset به عنوان ورودی انتظار میرود، تابع preprocess_fn را اعمال میکند و شی transformed_dataset و نمودار transform_fn تولید میکند. کد زیر این پردازش را نشان می دهد:
def analyze_and_transform(raw_dataset, step):
transformed_dataset, transform_fn = (
raw_dataset
| '{} - Analyze & Transform'.format(step) >> tft_beam.AnalyzeAndTransformDataset(
preprocess_fn, output_record_batches=True)
)
return transformed_dataset, transform_fn
تبدیل ها بر روی داده های خام در دو فاز اعمال می شوند: فاز تجزیه و تحلیل و فاز تبدیل. شکل 3 بعدی در این سند نشان می دهد که چگونه روش AnalyzeAndTransformDataset به روش AnalyzeDataset و روش TransformDataset تجزیه می شود.
مرحله تحلیل
در مرحله تجزیه و تحلیل، داده های آموزشی خام در یک فرآیند تمام گذر مورد تجزیه و تحلیل قرار می گیرند تا آمارهای مورد نیاز برای تبدیل ها محاسبه شود. این شامل محاسبه میانگین، واریانس، حداقل، حداکثر، چندک ها و واژگان است. فرآیند تجزیه و تحلیل یک مجموعه داده خام (داده های خام به اضافه ابرداده خام) را انتظار دارد و دو خروجی تولید می کند:
-
transform_fn: یک نمودار TensorFlow که شامل آمارهای محاسبه شده از فاز تحلیل و منطق تبدیل (که از آمارها استفاده می کند) به عنوان عملیات سطح نمونه است. همانطور که بعداً در Save the graph بحث شد، نمودارtransform_fnذخیره می شود تا به تابع modelserving_fnمتصل شود. این امکان اعمال همان تبدیل را در نقاط داده پیش بینی آنلاین فراهم می کند. -
transform_metadata: یک شی که طرح مورد انتظار داده ها را پس از تبدیل توصیف می کند.
مرحله تجزیه و تحلیل در نمودار زیر، شکل 1 نشان داده شده است:

tf.Transform . تحلیلگرهای tf.Transform شامل min , max , sum , size , mean , var , covariance , quantiles , vocabulary and pca .
فاز تبدیل
در فاز تبدیل، نمودار transform_fn که توسط فاز تحلیل تولید میشود، برای تبدیل دادههای آموزشی خام در یک فرآیند سطح نمونه به منظور تولید دادههای آموزشی تبدیلشده استفاده میشود. دادههای آموزشی تبدیلشده با ابردادههای تبدیلشده (تولید شده در مرحله تحلیل) جفت میشوند تا مجموعه داده transformed_train_dataset تولید شود.
فاز تبدیل در نمودار زیر، شکل 2 نشان داده شده است:

tf.Transform . برای پیش پردازش ویژگی ها، در اجرای تابع preprocess_fn ، تبدیل های tensorflow_transform مورد نیاز (وارد شده به صورت tft در کد) را فراخوانی می کنید. به عنوان مثال، هنگامی که عملیات tft.scale_to_z_score فراخوانی می کنید، کتابخانه tf.Transform این فراخوانی تابع را به تحلیلگرهای میانگین و واریانس ترجمه می کند، آمارها را در مرحله تجزیه و تحلیل محاسبه می کند و سپس این آمارها را برای عادی سازی ویژگی عددی در فاز تبدیل اعمال می کند. این همه به طور خودکار با فراخوانی روش AnalyzeAndTransformDataset(preprocess_fn) انجام می شود.
موجودیت transformed_metadata.schema تولید شده توسط این فراخوانی شامل ستون های زیر است:
-
gestation_weeks_scaled(نوع:FLOAT) -
is_male_index(نوع:INT، is_categorical:True) -
is_multiple_index(نوع:INT، is_categorical:True) -
mother_age_bucketized(نوع:INT, is_categorical:True) -
mother_age_log(نوع:FLOAT) -
mother_age_normalized(نوع:FLOAT) -
mother_race_index(نوع:INT، is_categorical:True) -
weight_pounds(نوع:FLOAT)
همانطور که در عملیات پیش پردازش در قسمت اول این سری توضیح داده شد، تبدیل ویژگی ویژگی های طبقه بندی را به یک نمایش عددی تبدیل می کند. پس از تبدیل، ویژگی های طبقه بندی شده با مقادیر صحیح نشان داده می شوند. در موجودیت transformed_metadata.schema ، پرچم is_categorical برای ستونهای نوع INT نشان میدهد که آیا ستون یک ویژگی طبقهبندی را نشان میدهد یا یک ویژگی عددی واقعی.
داده های آموزشی تبدیل شده را بنویسید
پس از اینکه داده های آموزشی با تابع preprocess_fn از طریق فازهای تجزیه و تحلیل و تبدیل پیش پردازش شدند، می توانید داده ها را در یک سینک بنویسید تا برای آموزش مدل TensorFlow استفاده شود. وقتی خط لوله Apache Beam را با استفاده از Dataflow اجرا می کنید، سینک Cloud Storage است. در غیر این صورت، سینک دیسک محلی است. اگرچه می توانید داده ها را به عنوان یک فایل CSV از فایل های فرمت شده با عرض ثابت بنویسید، فرمت فایل توصیه شده برای مجموعه داده های TensorFlow فرمت TFRecord است. این یک فرمت باینری ساده برای ضبط است که از پیام های بافر پروتکل tf.train.Example تشکیل شده است.
هر رکورد tf.train.Example شامل یک یا چند ویژگی است. اینها وقتی به مدل برای آموزش داده می شوند به تانسور تبدیل می شوند. کد زیر مجموعه داده تبدیل شده را در فایل های TFRecord در مکان مشخص شده می نویسد:
def write_tfrecords(transformed_dataset, location, step):
from tfx_bsl.coders import example_coder
transformed_data, transformed_metadata = transformed_dataset
(
transformed_data
| '{} - Encode Transformed Data'.format(step) >> beam.FlatMapTuple(
lambda batch, _: example_coder.RecordBatchToExamples(batch))
| '{} - Write Transformed Data'.format(step) >> beam.io.WriteToTFRecord(
file_path_prefix=os.path.join(location,'{}'.format(step)),
file_name_suffix='.tfrecords')
)
خواندن، تبدیل، و نوشتن داده های ارزیابی
پس از تبدیل داده های آموزشی و تولید نمودار transform_fn ، می توانید از آن برای تبدیل داده های ارزیابی استفاده کنید. ابتدا، دادههای ارزیابی را از BigQuery با استفاده از تابع read_from_bq که قبلاً در خواندن دادههای آموزشی خام از BigQuery توضیح داده شد، میخوانید و پاک میکنید و مقدار eval برای پارامتر step ارسال میکنید. سپس، از کد زیر برای تبدیل مجموعه داده ارزیابی خام ( raw_dataset ) به قالب مورد انتظار تبدیل شده ( transformed_dataset ) استفاده می کنید:
def transform(raw_dataset, transform_fn, step):
transformed_dataset = (
(raw_dataset, transform_fn)
| '{} - Transform'.format(step) >> tft_beam.TransformDataset(output_record_batches=True)
)
return transformed_dataset
وقتی دادههای ارزیابی را تغییر میدهید، فقط عملیات سطح نمونه اعمال میشود که هم از منطق موجود در نمودار transform_fn و هم از آمار محاسبهشده از مرحله تجزیه و تحلیل در دادههای آموزشی استفاده میکند. به عبارت دیگر، شما دادههای ارزیابی را برای محاسبه آمارهای جدید، مانند میانگین و واریانس برای نرمالسازی امتیاز z ویژگیهای عددی در دادههای ارزیابی، به صورت کامل تجزیه و تحلیل نمیکنید. در عوض، شما از آمار محاسبه شده از داده های آموزشی برای تبدیل داده های ارزیابی در سطح نمونه استفاده می کنید.
بنابراین، شما از روش AnalyzeAndTransform در زمینه داده های آموزشی برای محاسبه آمار و تبدیل داده ها استفاده می کنید. در همان زمان، شما از روش TransformDataset در زمینه تبدیل داده های ارزیابی استفاده می کنید تا فقط داده ها را با استفاده از آمار محاسبه شده بر روی داده های آموزشی تبدیل کنید.
سپس داده ها را در یک سینک (Cloud Storage یا دیسک محلی، بسته به نوع دونده) در قالب TFRecord برای ارزیابی مدل TensorFlow در طول فرآیند آموزش می نویسید. برای انجام این کار، از تابع write_tfrecords که در Write transformed training data بحث شده است استفاده می کنید. نمودار زیر، شکل 3، نشان می دهد که چگونه نمودار transform_fn که در مرحله تجزیه و تحلیل داده های آموزشی تولید می شود، برای تبدیل داده های ارزیابی استفاده می شود.

transform_fn .نمودار را ذخیره کنید
آخرین مرحله در خط لوله پیش پردازش tf.Transform ذخیره سازی مصنوعات است که شامل نمودار transform_fn است که در مرحله تجزیه و تحلیل بر روی داده های آموزشی تولید می شود. کد ذخیره سازی آرتیفکت ها در تابع write_transform_artefacts زیر نشان داده شده است:
def write_transform_artefacts(transform_fn, location):
(
transform_fn
| 'Write Transform Artifacts' >> transform_fn_io.WriteTransformFn(location)
)
این مصنوعات بعداً برای آموزش مدل و صادرات برای خدمت استفاده خواهند شد. مصنوعات زیر نیز همانطور که در بخش بعدی نشان داده شده است تولید می شوند:
-
saved_model.pb: نمودار TensorFlow را نشان میدهد که شامل منطق تبدیل (گرافtransform_fn) است، که باید به رابط سرویسدهی مدل متصل شود تا نقاط داده خام را به فرمت تبدیلشده تبدیل کند. -
variables: شامل آمار محاسبه شده در مرحله تجزیه و تحلیل داده های آموزشی است و در منطق تبدیل در مصنوعsaved_model.pbاستفاده می شود. -
assets: شامل فایلهای واژگانی، یک فایل برای هر ویژگی طبقهبندی شده با روشcompute_and_apply_vocabulary، که در حین ارائه برای تبدیل یک مقدار اسمی خام ورودی به یک شاخص عددی استفاده میشود. -
transformed_metadata: دایرکتوری حاوی فایلschema.jsonکه طرحواره داده های تبدیل شده را توصیف می کند.
خط لوله را در Dataflow اجرا کنید
بعد از اینکه خط لوله tf.Transform را تعریف کردید، خط لوله را با استفاده از Dataflow اجرا می کنید. نمودار زیر، شکل 4، نمودار اجرای Dataflow خط لوله tf.Transform را نشان می دهد که در مثال توضیح داده شده است.
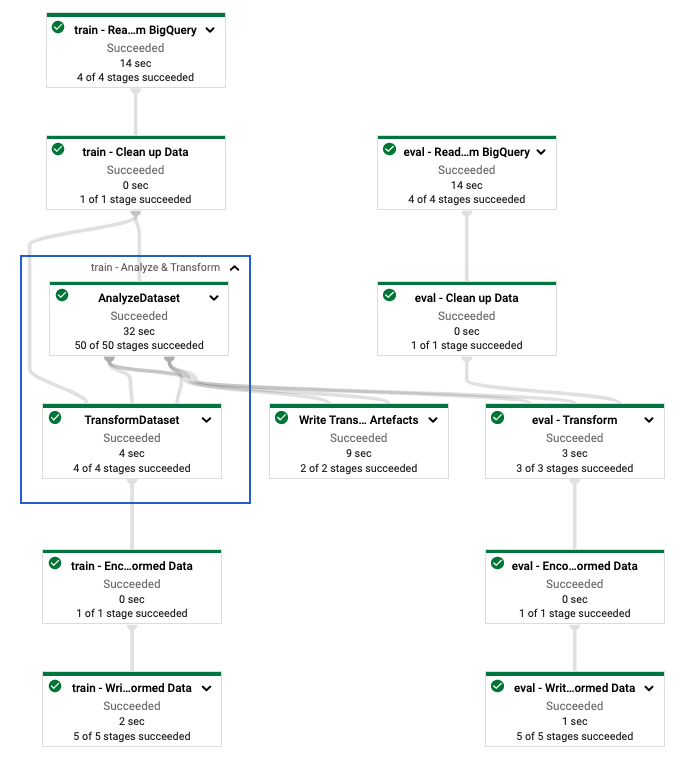
tf.Transform . پس از اجرای خط لوله Dataflow برای پیش پردازش داده های آموزشی و ارزیابی، می توانید اشیاء تولید شده در Cloud Storage را با اجرای آخرین سلول در نوت بوک کاوش کنید. قطعه کد در این بخش نتایج را نشان می دهد، جایی که YOUR_BUCKET_NAME نام سطل فضای ذخیره سازی ابری شما است.
داده های آموزش و ارزیابی تبدیل شده در قالب TFRecord در مکان زیر ذخیره می شود:
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed
مصنوعات تبدیل در مکان زیر تولید می شوند:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform
لیست زیر خروجی خط لوله است که اشیا و مصنوعات داده تولید شده را نشان می دهد:
transformed data:
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/eval-00000-of-00001.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00000-of-00002.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00001-of-00002.tfrecords
transformed metadata:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/asset_map
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/schema.pbtxt
transform artefact:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/saved_model.pb
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/variables/
transform assets:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_male
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_multiple
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/mother_race
پیاده سازی مدل TensorFlow
این بخش و بخش بعدی، آموزش و استفاده از مدل برای پیش بینی ها ، یک نمای کلی و زمینه ای برای Notebook 2 ارائه می دهد. این دفترچه یک نمونه مدل ML را برای پیش بینی وزن نوزاد ارائه می دهد. در این مثال، یک مدل TensorFlow با استفاده از Keras API پیاده سازی شده است. این مدل از داده ها و مصنوعاتی استفاده می کند که توسط خط لوله پیش پردازش tf.Transform که قبلا توضیح داده شد تولید می شود.
نوت بوک 2 را اجرا کنید
در رابط JupyterLab، روی File > Open from path کلیک کنید و سپس مسیر زیر را وارد کنید:
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_02.ipynbروی Edit > Clear all outputs کلیک کنید.
در قسمت نصب بستههای مورد نیاز ، اولین سلولی را که دستور
pip install tensorflow-transformاجرا میکند، اجرا کنید.قسمت آخر خروجی به صورت زیر است:
Successfully installed ... Note: you may need to restart the kernel to use updated packages.می توانید خطاهای وابستگی را در خروجی نادیده بگیرید.
در منوی Kernel ، Restart Kernel را انتخاب کنید.
سلولهای موجود در Confirm the installed packages را اجرا کنید و setup.py را برای نصب بستهها در Dataflow containers ایجاد کنید .
در قسمت Set global flags ، در کنار
PROJECTوBUCKET،your-projectبا ID پروژه Cloud خود جایگزین کنید و سپس سلول را اجرا کنید.تمام سلول های باقی مانده را از طریق آخرین سلول در دفترچه یادداشت اجرا کنید. برای اطلاعات در مورد کارهایی که باید در هر سلول انجام دهید، به دستورالعمل های دفترچه یادداشت مراجعه کنید.
مروری بر ایجاد مدل
مراحل ساخت مدل به شرح زیر است:
- ستون های ویژگی را با استفاده از اطلاعات طرحواره ای که در دایرکتوری
transformed_metadataذخیره شده است ایجاد کنید. - با استفاده از ستون های ویژگی به عنوان ورودی مدل، مدل گسترده و عمیق را با Keras API ایجاد کنید.
- تابع
tfrecords_input_fnرا برای خواندن و تجزیه داده های آموزش و ارزیابی با استفاده از مصنوعات تبدیل ایجاد کنید. - آموزش و ارزیابی مدل.
- با تعریف تابع
serving_fnکه گرافtransform_fnبه آن متصل است، مدل آموزش دیده را صادر کنید. - مدل صادر شده را با استفاده از ابزار
saved_model_cliبررسی کنید. - از مدل صادراتی برای پیش بینی استفاده کنید.
این سند نحوه ساخت مدل را توضیح نمی دهد، بنابراین به طور مفصل درباره نحوه ساخت یا آموزش مدل صحبت نمی کند. با این حال، بخشهای زیر نشان میدهند که چگونه اطلاعات ذخیرهشده در دایرکتوری transform_metadata - که توسط فرآیند tf.Transform تولید میشود - برای ایجاد ستونهای ویژگی مدل استفاده میشود. این سند همچنین نشان میدهد که چگونه نمودار transform_fn – که توسط فرآیند tf.Transform نیز تولید میشود – در تابع serving_fn زمانی که مدل برای سرویسدهی صادر میشود، استفاده میشود.
از مصنوعات تبدیل تولید شده در آموزش مدل استفاده کنید
هنگامی که مدل TensorFlow را آموزش می دهید، از train تبدیل شده و اشیاء eval تولید شده در مرحله پردازش داده قبلی استفاده می کنید. این اشیاء به صورت فایل های خرد شده در قالب TFRecord ذخیره می شوند. اطلاعات طرحواره در دایرکتوری transformed_metadata تولید شده در مرحله قبل می تواند در تجزیه داده ها (اشیاء tf.train.Example ) برای تغذیه در مدل برای آموزش و ارزیابی مفید باشد.
داده ها را تجزیه کنید
از آنجا که فایلها را در قالب TFRecord میخوانید تا مدل را با دادههای آموزش و ارزیابی تغذیه کنید، باید هر شی tf.train.Example را در فایلها تجزیه کنید تا فرهنگ لغت ویژگیها (تانسورها) ایجاد کنید. این تضمین می کند که ویژگی ها با استفاده از ستون های ویژگی که به عنوان رابط آموزش و ارزیابی مدل عمل می کنند به لایه ورودی مدل نگاشت می شوند. برای تجزیه داده ها، از شی TFTransformOutput استفاده می کنید که از آرتیفکت های تولید شده در مرحله قبل ایجاد شده است:
همانطور که در بخش Save the graph توضیح داده شده است، یک شی
TFTransformOutputاز آرتیفکت هایی که در مرحله پیش پردازش قبلی تولید و ذخیره شده اند ایجاد کنید:tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)یک شی
feature_specرا از شیTFTransformOutputاستخراج کنید:tf_transform_output.transformed_feature_spec()از شی
feature_specبرای تعیین ویژگی های موجود در شیtf.train.Exampleمانند تابعtfrecords_input_fnاستفاده کنید:def tfrecords_input_fn(files_name_pattern, batch_size=512): tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR) TARGET_FEATURE_NAME = 'weight_pounds' batched_dataset = tf.data.experimental.make_batched_features_dataset( file_pattern=files_name_pattern, batch_size=batch_size, features=tf_transform_output.transformed_feature_spec(), reader=tf.data.TFRecordDataset, label_key=TARGET_FEATURE_NAME, shuffle=True).prefetch(tf.data.experimental.AUTOTUNE) return batched_dataset
ستون های ویژگی را ایجاد کنید
خط لوله اطلاعات طرح را در دایرکتوری transformed_metadata تولید می کند که طرحی از داده های تبدیل شده را که توسط مدل برای آموزش و ارزیابی انتظار می رود، توصیف می کند. این طرح شامل نام ویژگی و نوع داده است، مانند موارد زیر:
-
gestation_weeks_scaled(نوع:FLOAT) -
is_male_index(نوع:INT، is_categorical:True) -
is_multiple_index(نوع:INT، is_categorical:True) -
mother_age_bucketized(نوع:INT, is_categorical:True) -
mother_age_log(نوع:FLOAT) -
mother_age_normalized(نوع:FLOAT) -
mother_race_index(نوع:INT، is_categorical:True) -
weight_pounds(نوع:FLOAT)
برای مشاهده این اطلاعات از دستورات زیر استفاده کنید:
transformed_metadata = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR).transformed_metadata
transformed_metadata.schema
کد زیر نحوه استفاده از نام ویژگی را برای ایجاد ستون های ویژگی نشان می دهد:
def create_wide_and_deep_feature_columns():
deep_feature_columns = []
wide_feature_columns = []
inputs = {}
categorical_columns = {}
# Select features you've checked from the metadata
# Categorical features are associated with the vocabulary size (starting from 0)
numeric_features = ['mother_age_log', 'mother_age_normalized', 'gestation_weeks_scaled']
categorical_features = [('is_male_index', 1), ('is_multiple_index', 1),
('mother_age_bucketized', 4), ('mother_race_index', 10)]
for feature in numeric_features:
deep_feature_columns.append(tf.feature_column.numeric_column(feature))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='float32')
for feature, vocab_size in categorical_features:
categorical_columns[feature] = (
tf.feature_column.categorical_column_with_identity(feature, num_buckets=vocab_size+1))
wide_feature_columns.append(tf.feature_column.indicator_column(categorical_columns[feature]))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='int64')
mother_race_X_mother_age_bucketized = tf.feature_column.crossed_column(
[categorical_columns['mother_age_bucketized'],
categorical_columns['mother_race_index']], 55)
wide_feature_columns.append(tf.feature_column.indicator_column(mother_race_X_mother_age_bucketized))
mother_race_X_mother_age_bucketized_embedded = tf.feature_column.embedding_column(
mother_race_X_mother_age_bucketized, 5)
deep_feature_columns.append(mother_race_X_mother_age_bucketized_embedded)
return wide_feature_columns, deep_feature_columns, inputs
کد یک ستون tf.feature_column.numeric_column برای ویژگی های عددی و یک ستون tf.feature_column.categorical_column_with_identity برای ویژگی های دسته بندی ایجاد می کند.
شما همچنین می توانید ستون های ویژگی های توسعه یافته ایجاد کنید، همانطور که در گزینه C: TensorFlow در قسمت اول این مجموعه توضیح داده شده است. در مثال مورد استفاده برای این سری، با عبور از ویژگی های mother_race و mother_age_bucketized با استفاده از ستون ویژگی tf.feature_column.crossed_column ، یک ویژگی جدید ایجاد می شود، mother_race_X_mother_age_bucketized . نمایش کمبعد و متراکم این ویژگی متقاطع با استفاده از ستون ویژگی tf.feature_column.embedding_column ایجاد میشود.
نمودار زیر، شکل 5، داده های تبدیل شده و نحوه استفاده از ابرداده تبدیل شده برای تعریف و آموزش مدل TensorFlow را نشان می دهد:

مدل را برای پیشبینی ارائه صادر کنید
بعد از اینکه مدل TensorFlow را با Keras API آموزش دادید، مدل آموزش دیده را به عنوان یک شی SavedModel صادر می کنید تا بتواند نقاط داده جدیدی را برای پیش بینی ارائه دهد. هنگامی که مدل را صادر می کنید، باید رابط آن را تعریف کنید - یعنی طرح ویژگی های ورودی که در طول ارائه انتظار می رود. این طرح ویژگی های ورودی در تابع serving_fn تعریف شده است، همانطور که در کد زیر نشان داده شده است:
def export_serving_model(model, output_dir):
tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)
# The layer has to be saved to the model for Keras tracking purposes.
model.tft_layer = tf_transform_output.transform_features_layer()
@tf.function
def serveing_fn(uid, is_male, mother_race, mother_age, plurality, gestation_weeks):
features = {
'is_male': is_male,
'mother_race': mother_race,
'mother_age': mother_age,
'plurality': plurality,
'gestation_weeks': gestation_weeks
}
transformed_features = model.tft_layer(features)
outputs = model(transformed_features)
# The prediction results have multiple elements in general.
# But we need only the first element in our case.
outputs = tf.map_fn(lambda item: item[0], outputs)
return {'uid': uid, 'weight': outputs}
concrete_serving_fn = serveing_fn.get_concrete_function(
tf.TensorSpec(shape=[None], dtype=tf.string, name='uid'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='is_male'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='mother_race'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='mother_age'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='plurality'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='gestation_weeks')
)
signatures = {'serving_default': concrete_serving_fn}
model.save(output_dir, save_format='tf', signatures=signatures)
در طول خدمت، مدل انتظار دارد که نقاط داده به شکل خام (یعنی ویژگیهای خام قبل از تبدیل) باشند. بنابراین، تابع serving_fn ویژگی های خام را دریافت کرده و آنها را در یک شیء features به عنوان فرهنگ لغت پایتون ذخیره می کند. با این حال، همانطور که قبلاً بحث شد، مدل آموزش دیده انتظار دارد که نقاط داده در طرحواره تبدیل شده باشد. برای تبدیل ویژگیهای خام به اشیاء transformed_features که توسط رابط مدل انتظار میرود، نمودار ذخیرهشده transform_fn را با مراحل زیر به شی features اعمال میکنید:
شی
TFTransformOutputاز آرتیفکت های تولید شده و ذخیره شده در مرحله پیش پردازش قبلی ایجاد کنید:tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)یک شی
TransformFeaturesLayerاز شیTFTransformOutputایجاد کنید:model.tft_layer = tf_transform_output.transform_features_layer()گراف
transform_fnرا با استفاده از شیTransformFeaturesLayerاعمال کنید:transformed_features = model.tft_layer(features)
نمودار زیر، شکل 6، مرحله نهایی صدور یک مدل برای سرویس دهی را نشان می دهد:

transform_fn پیوست شده است. آموزش و استفاده از مدل برای پیش بینی
با اجرای سلول های نوت بوک می توانید مدل را به صورت محلی آموزش دهید. برای نمونه هایی از نحوه بسته بندی کد و آموزش مدل خود در مقیاس با استفاده از آموزش هوش مصنوعی Vertex، به نمونه ها و راهنماهای موجود در مخزن Google Cloud cloudml-samples GitHub مراجعه کنید.
وقتی شی SavedModel صادر شده را با استفاده از ابزار saved_model_cli بررسی میکنید، میبینید که عناصر inputs تعریف امضا signature_def شامل ویژگیهای خام است، همانطور که در مثال زیر نشان داده شده است:
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input(s):
inputs['gestation_weeks'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_gestation_weeks:0
inputs['is_male'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_is_male:0
inputs['mother_age'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_mother_age:0
inputs['mother_race'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_mother_race:0
inputs['plurality'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_plurality:0
inputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_uid:0
The given SavedModel SignatureDef contains the following output(s):
outputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: StatefulPartitionedCall_6:0
outputs['weight'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: StatefulPartitionedCall_6:1
Method name is: tensorflow/serving/predict
سلولهای باقیمانده نوتبوک به شما نشان میدهند که چگونه از مدل صادر شده برای پیشبینی محلی استفاده کنید، و چگونه مدل را بهعنوان یک میکروسرویس با استفاده از Vertex AI Prediction اجرا کنید. مهم است که مشخص شود نقطه داده ورودی (نمونه) در طرحواره خام در هر دو مورد است.
پاک کن
برای جلوگیری از تحمیل هزینه های اضافی به حساب Google Cloud خود برای منابع استفاده شده در این آموزش، پروژه حاوی منابع را حذف کنید.
پروژه را حذف کنید
در کنسول Google Cloud، به صفحه مدیریت منابع بروید.
در لیست پروژه، پروژه ای را که می خواهید حذف کنید انتخاب کنید و سپس روی Delete کلیک کنید.
در محاوره، شناسه پروژه را تایپ کنید و سپس روی Shut down کلیک کنید تا پروژه حذف شود.
بعدش چی
- برای آشنایی با مفاهیم، چالشها و گزینههای پیشپردازش دادهها برای یادگیری ماشین در Google Cloud، به اولین مقاله این مجموعه، پیشپردازش دادهها برای ML: گزینهها و توصیهها مراجعه کنید.
- برای اطلاعات بیشتر در مورد نحوه پیاده سازی، بسته بندی و اجرای خط لوله tf.Transform در Dataflow، به نمونه پیش بینی درآمد با مجموعه داده سرشماری مراجعه کنید.
- تخصص Coursera در ML با TensorFlow در Google Cloud را انتخاب کنید.
- در مورد بهترین شیوه های مهندسی ML در قوانین ML بیاموزید.
- برای معماریهای مرجع، نمودارها و بهترین شیوهها، مرکز معماری ابری را کاوش کنید.