
| | |  Kaynağı GitHub'da görüntüleyin Kaynağı GitHub'da görüntüleyin | |
Bu not defteri tabanlı öğreticide, giriş verilerini doğrulamak ve bir ML modeli oluşturmak için TFX ardışık düzenleri oluşturup çalıştıracağız. Bu defter biz inşa TFX boru hattı dayanmaktadır Basit TFX Boru Hattı Öğreticisi . Bu öğreticiyi henüz okumadıysanız, bu not defterine geçmeden önce okumalısınız.
Herhangi bir veri bilimi veya makine öğrenimi projesindeki ilk görev, aşağıdakileri içeren verileri anlamak ve temizlemektir:
- Her bir özellik hakkında veri türlerini, dağılımları ve diğer bilgileri (örneğin, ortalama değer veya benzersiz sayısı) anlama
- Verileri açıklayan bir ön şema oluşturma
- Verilen şemaya göre verilerdeki anormallikleri ve eksik değerleri belirleme
Bu eğitimde, iki TFX ardışık düzen oluşturacağız.
İlk olarak, veri kümesini analiz etmek için bir işlem hattı oluşturacağız ve verilen veri kümesinin ön şemasını oluşturacağız. Bu boru hattı, iki yeni bileşenler içerecektir StatisticsGen ve SchemaGen .
Verilerin uygun bir şemasına sahip olduğumuzda, önceki öğreticideki ardışık düzene dayalı olarak bir ML sınıflandırma modelini eğitmek için bir ardışık düzen oluşturacağız. Bu boru hattı, biz ilk boru hattı ve yeni bileşen, şemadan kullanacak ExampleValidator girdi verilerini doğrulamak için.
Üç yeni parçaları, StatisticsGen, SchemaGen ve ExampleValidator, veri analizi ve doğrulama için TFX bileşenleridir ve bunlar kullanılarak uygulanan TensorFlow Veri Doğrulama kitaplığı.
Bakınız TFX Boru hatları anlama Tfx çeşitli kavramlar hakkında daha fazla bilgi edinmek.
Kurmak
Öncelikle TFX Python paketini kurmamız ve modelimiz için kullanacağımız veri setini indirmemiz gerekiyor.
Pip'i Yükselt
Yerel olarak çalışırken bir sistemde Pip'i yükseltmekten kaçınmak için Colab'da çalıştığımızdan emin olun. Yerel sistemler elbette ayrı ayrı yükseltilebilir.
try:
import colab
!pip install --upgrade pip
except:
pass
TFX'i yükleyin
pip install -U tfx
Çalışma zamanını yeniden başlattınız mı?
Google Colab kullanıyorsanız, yukarıdaki hücreyi ilk kez çalıştırdığınızda, yukarıdaki "ÇALIŞTIRMA ZAMINI YENİDEN BAŞLAT" düğmesini tıklayarak veya "Çalışma Zamanı > Çalışma zamanını yeniden başlat ..." menüsünü kullanarak çalışma zamanını yeniden başlatmanız gerekir. Bunun nedeni Colab'ın paketleri yükleme şeklidir.
TensorFlow ve TFX sürümlerini kontrol edin.
import tensorflow as tf
print('TensorFlow version: {}'.format(tf.__version__))
from tfx import v1 as tfx
print('TFX version: {}'.format(tfx.__version__))
TensorFlow version: 2.6.2 TFX version: 1.4.0
Değişkenleri ayarla
Bir boru hattını tanımlamak için kullanılan bazı değişkenler vardır. Bu değişkenleri istediğiniz gibi özelleştirebilirsiniz. Varsayılan olarak, işlem hattından gelen tüm çıktılar geçerli dizin altında oluşturulacaktır.
import os
# We will create two pipelines. One for schema generation and one for training.
SCHEMA_PIPELINE_NAME = "penguin-tfdv-schema"
PIPELINE_NAME = "penguin-tfdv"
# Output directory to store artifacts generated from the pipeline.
SCHEMA_PIPELINE_ROOT = os.path.join('pipelines', SCHEMA_PIPELINE_NAME)
PIPELINE_ROOT = os.path.join('pipelines', PIPELINE_NAME)
# Path to a SQLite DB file to use as an MLMD storage.
SCHEMA_METADATA_PATH = os.path.join('metadata', SCHEMA_PIPELINE_NAME,
'metadata.db')
METADATA_PATH = os.path.join('metadata', PIPELINE_NAME, 'metadata.db')
# Output directory where created models from the pipeline will be exported.
SERVING_MODEL_DIR = os.path.join('serving_model', PIPELINE_NAME)
from absl import logging
logging.set_verbosity(logging.INFO) # Set default logging level.
Örnek verileri hazırlayın
TFX ardışık düzenimizde kullanmak için örnek veri kümesini indireceğiz. Kullandığımız veri kümesi olan Palmer Penguenler veri kümesi aynı zamanda diğer kullanılır TFX örnekler .
Bu veri kümesinde dört sayısal özellik vardır:
- culmen_length_mm
- culmen_depth_mm
- flipper_length_mm
- body_mass_g
Tüm özellikler zaten [0,1] aralığına sahip olacak şekilde normalleştirildi. Biz tahmin eden bir sınıflandırma modeli inşa edecek species penguenleri.
TFX ExampleGen bileşeni bir dizinden girdileri okuduğundan, bir dizin oluşturmamız ve veri kümesini ona kopyalamamız gerekir.
import urllib.request
import tempfile
DATA_ROOT = tempfile.mkdtemp(prefix='tfx-data') # Create a temporary directory.
_data_url = 'https://raw.githubusercontent.com/tensorflow/tfx/master/tfx/examples/penguin/data/labelled/penguins_processed.csv'
_data_filepath = os.path.join(DATA_ROOT, "data.csv")
urllib.request.urlretrieve(_data_url, _data_filepath)
('/tmp/tfx-datan3p7t1d2/data.csv', <http.client.HTTPMessage at 0x7f8d2f9f9110>)
CSV dosyasına hızlı bir göz atın.
head {_data_filepath}
species,culmen_length_mm,culmen_depth_mm,flipper_length_mm,body_mass_g 0,0.2545454545454545,0.6666666666666666,0.15254237288135594,0.2916666666666667 0,0.26909090909090905,0.5119047619047618,0.23728813559322035,0.3055555555555556 0,0.29818181818181805,0.5833333333333334,0.3898305084745763,0.1527777777777778 0,0.16727272727272732,0.7380952380952381,0.3559322033898305,0.20833333333333334 0,0.26181818181818167,0.892857142857143,0.3050847457627119,0.2638888888888889 0,0.24727272727272717,0.5595238095238096,0.15254237288135594,0.2569444444444444 0,0.25818181818181823,0.773809523809524,0.3898305084745763,0.5486111111111112 0,0.32727272727272727,0.5357142857142859,0.1694915254237288,0.1388888888888889 0,0.23636363636363636,0.9642857142857142,0.3220338983050847,0.3055555555555556
Beş özellik sütunu görebilmeniz gerekir. species 0, 1 veya 2 biridir ve diğer tüm özellikleri Bu veri kümesini analiz etmek için bir TFX boru hattı yaratacak 0 ile 1 arasında değerlere sahip olmalıdır.
Bir ön şema oluşturun
TFX ardışık düzenleri Python API'leri kullanılarak tanımlanır. Giriş örneklerinden otomatik olarak bir şema oluşturmak için bir ardışık düzen oluşturacağız. Bu şema bir insan tarafından gözden geçirilebilir ve gerektiğinde ayarlanabilir. Şema sonlandırıldığında, sonraki görevlerde eğitim ve örnek doğrulama için kullanılabilir.
Ek olarak CsvExampleGen kullanılan Basit TFX Boru Hattı Öğreticisi , biz kullanacağız StatisticsGen ve SchemaGen :
- StatisticsGen veri kümesi için istatistikler hesaplanır.
- SchemaGen istatistiklerini inceler ve ilk veri şemasını oluşturur.
Her bileşen için kılavuzları bakın veya TFX bileşenleri öğretici bu bileşenler üzerinde daha fazla bilgi edinmek için.
Bir işlem hattı tanımı yazın
Bir TFX boru hattı oluşturmak için bir fonksiyon tanımlıyoruz. Bir Pipeline nesnesi TFX destekleri bu boru düzenleme sistemlerinden biri kullanılarak çalıştırılabilir bir TFX boru hattı temsil etmektedir.
def _create_schema_pipeline(pipeline_name: str,
pipeline_root: str,
data_root: str,
metadata_path: str) -> tfx.dsl.Pipeline:
"""Creates a pipeline for schema generation."""
# Brings data into the pipeline.
example_gen = tfx.components.CsvExampleGen(input_base=data_root)
# NEW: Computes statistics over data for visualization and schema generation.
statistics_gen = tfx.components.StatisticsGen(
examples=example_gen.outputs['examples'])
# NEW: Generates schema based on the generated statistics.
schema_gen = tfx.components.SchemaGen(
statistics=statistics_gen.outputs['statistics'], infer_feature_shape=True)
components = [
example_gen,
statistics_gen,
schema_gen,
]
return tfx.dsl.Pipeline(
pipeline_name=pipeline_name,
pipeline_root=pipeline_root,
metadata_connection_config=tfx.orchestration.metadata
.sqlite_metadata_connection_config(metadata_path),
components=components)
Boru hattını çalıştırın
Biz kullanacağız LocalDagRunner önceki öğretici olduğu gibi.
tfx.orchestration.LocalDagRunner().run(
_create_schema_pipeline(
pipeline_name=SCHEMA_PIPELINE_NAME,
pipeline_root=SCHEMA_PIPELINE_ROOT,
data_root=DATA_ROOT,
metadata_path=SCHEMA_METADATA_PATH))
INFO:absl:Excluding no splits because exclude_splits is not set.
INFO:absl:Excluding no splits because exclude_splits is not set.
INFO:absl:Using deployment config:
executor_specs {
key: "CsvExampleGen"
value {
beam_executable_spec {
python_executor_spec {
class_path: "tfx.components.example_gen.csv_example_gen.executor.Executor"
}
}
}
}
executor_specs {
key: "SchemaGen"
value {
python_class_executable_spec {
class_path: "tfx.components.schema_gen.executor.Executor"
}
}
}
executor_specs {
key: "StatisticsGen"
value {
beam_executable_spec {
python_executor_spec {
class_path: "tfx.components.statistics_gen.executor.Executor"
}
}
}
}
custom_driver_specs {
key: "CsvExampleGen"
value {
python_class_executable_spec {
class_path: "tfx.components.example_gen.driver.FileBasedDriver"
}
}
}
metadata_connection_config {
sqlite {
filename_uri: "metadata/penguin-tfdv-schema/metadata.db"
connection_mode: READWRITE_OPENCREATE
}
}
INFO:absl:Using connection config:
sqlite {
filename_uri: "metadata/penguin-tfdv-schema/metadata.db"
connection_mode: READWRITE_OPENCREATE
}
INFO:absl:Component CsvExampleGen is running.
INFO:absl:Running launcher for node_info {
type {
name: "tfx.components.example_gen.csv_example_gen.component.CsvExampleGen"
}
id: "CsvExampleGen"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv-schema"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:06.420329"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv-schema.CsvExampleGen"
}
}
}
}
outputs {
outputs {
key: "examples"
value {
artifact_spec {
type {
name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
}
}
}
}
}
parameters {
parameters {
key: "input_base"
value {
field_value {
string_value: "/tmp/tfx-datan3p7t1d2"
}
}
}
parameters {
key: "input_config"
value {
field_value {
string_value: "{\n \"splits\": [\n {\n \"name\": \"single_split\",\n \"pattern\": \"*\"\n }\n ]\n}"
}
}
}
parameters {
key: "output_config"
value {
field_value {
string_value: "{\n \"split_config\": {\n \"splits\": [\n {\n \"hash_buckets\": 2,\n \"name\": \"train\"\n },\n {\n \"hash_buckets\": 1,\n \"name\": \"eval\"\n }\n ]\n }\n}"
}
}
}
parameters {
key: "output_data_format"
value {
field_value {
int_value: 6
}
}
}
parameters {
key: "output_file_format"
value {
field_value {
int_value: 5
}
}
}
}
downstream_nodes: "StatisticsGen"
execution_options {
caching_options {
}
}
INFO:absl:MetadataStore with DB connection initialized
WARNING: Logging before InitGoogleLogging() is written to STDERR
I1205 11:10:06.444468 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
I1205 11:10:06.453292 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
I1205 11:10:06.460209 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
I1205 11:10:06.467104 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
INFO:absl:select span and version = (0, None)
INFO:absl:latest span and version = (0, None)
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Going to run a new execution 1
I1205 11:10:06.521926 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
INFO:absl:Going to run a new execution: ExecutionInfo(execution_id=1, input_dict={}, output_dict=defaultdict(<class 'list'>, {'examples': [Artifact(artifact: uri: "pipelines/penguin-tfdv-schema/CsvExampleGen/examples/1"
custom_properties {
key: "input_fingerprint"
value {
string_value: "split:single_split,num_files:1,total_bytes:25648,xor_checksum:1638702606,sum_checksum:1638702606"
}
}
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv-schema:2021-12-05T11:10:06.420329:CsvExampleGen:examples:0"
}
}
custom_properties {
key: "span"
value {
int_value: 0
}
}
, artifact_type: name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
)]}), exec_properties={'input_config': '{\n "splits": [\n {\n "name": "single_split",\n "pattern": "*"\n }\n ]\n}', 'output_config': '{\n "split_config": {\n "splits": [\n {\n "hash_buckets": 2,\n "name": "train"\n },\n {\n "hash_buckets": 1,\n "name": "eval"\n }\n ]\n }\n}', 'input_base': '/tmp/tfx-datan3p7t1d2', 'output_file_format': 5, 'output_data_format': 6, 'span': 0, 'version': None, 'input_fingerprint': 'split:single_split,num_files:1,total_bytes:25648,xor_checksum:1638702606,sum_checksum:1638702606'}, execution_output_uri='pipelines/penguin-tfdv-schema/CsvExampleGen/.system/executor_execution/1/executor_output.pb', stateful_working_dir='pipelines/penguin-tfdv-schema/CsvExampleGen/.system/stateful_working_dir/2021-12-05T11:10:06.420329', tmp_dir='pipelines/penguin-tfdv-schema/CsvExampleGen/.system/executor_execution/1/.temp/', pipeline_node=node_info {
type {
name: "tfx.components.example_gen.csv_example_gen.component.CsvExampleGen"
}
id: "CsvExampleGen"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv-schema"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:06.420329"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv-schema.CsvExampleGen"
}
}
}
}
outputs {
outputs {
key: "examples"
value {
artifact_spec {
type {
name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
}
}
}
}
}
parameters {
parameters {
key: "input_base"
value {
field_value {
string_value: "/tmp/tfx-datan3p7t1d2"
}
}
}
parameters {
key: "input_config"
value {
field_value {
string_value: "{\n \"splits\": [\n {\n \"name\": \"single_split\",\n \"pattern\": \"*\"\n }\n ]\n}"
}
}
}
parameters {
key: "output_config"
value {
field_value {
string_value: "{\n \"split_config\": {\n \"splits\": [\n {\n \"hash_buckets\": 2,\n \"name\": \"train\"\n },\n {\n \"hash_buckets\": 1,\n \"name\": \"eval\"\n }\n ]\n }\n}"
}
}
}
parameters {
key: "output_data_format"
value {
field_value {
int_value: 6
}
}
}
parameters {
key: "output_file_format"
value {
field_value {
int_value: 5
}
}
}
}
downstream_nodes: "StatisticsGen"
execution_options {
caching_options {
}
}
, pipeline_info=id: "penguin-tfdv-schema"
, pipeline_run_id='2021-12-05T11:10:06.420329')
INFO:absl:Generating examples.
WARNING:apache_beam.runners.interactive.interactive_environment:Dependencies required for Interactive Beam PCollection visualization are not available, please use: `pip install apache-beam[interactive]` to install necessary dependencies to enable all data visualization features.
INFO:absl:Processing input csv data /tmp/tfx-datan3p7t1d2/* to TFExample.
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
WARNING:apache_beam.io.tfrecordio:Couldn't find python-snappy so the implementation of _TFRecordUtil._masked_crc32c is not as fast as it could be.
INFO:absl:Examples generated.
INFO:absl:Cleaning up stateless execution info.
INFO:absl:Execution 1 succeeded.
INFO:absl:Cleaning up stateful execution info.
INFO:absl:Publishing output artifacts defaultdict(<class 'list'>, {'examples': [Artifact(artifact: uri: "pipelines/penguin-tfdv-schema/CsvExampleGen/examples/1"
custom_properties {
key: "input_fingerprint"
value {
string_value: "split:single_split,num_files:1,total_bytes:25648,xor_checksum:1638702606,sum_checksum:1638702606"
}
}
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv-schema:2021-12-05T11:10:06.420329:CsvExampleGen:examples:0"
}
}
custom_properties {
key: "span"
value {
int_value: 0
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.4.0"
}
}
, artifact_type: name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
)]}) for execution 1
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Component CsvExampleGen is finished.
INFO:absl:Component StatisticsGen is running.
INFO:absl:Running launcher for node_info {
type {
name: "tfx.components.statistics_gen.component.StatisticsGen"
}
id: "StatisticsGen"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv-schema"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:06.420329"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv-schema.StatisticsGen"
}
}
}
}
inputs {
inputs {
key: "examples"
value {
channels {
producer_node_query {
id: "CsvExampleGen"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv-schema"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:06.420329"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv-schema.CsvExampleGen"
}
}
}
artifact_query {
type {
name: "Examples"
}
}
output_key: "examples"
}
min_count: 1
}
}
}
outputs {
outputs {
key: "statistics"
value {
artifact_spec {
type {
name: "ExampleStatistics"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
}
}
}
}
}
parameters {
parameters {
key: "exclude_splits"
value {
field_value {
string_value: "[]"
}
}
}
}
upstream_nodes: "CsvExampleGen"
downstream_nodes: "SchemaGen"
execution_options {
caching_options {
}
}
INFO:absl:MetadataStore with DB connection initialized
I1205 11:10:08.104562 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Going to run a new execution 2
INFO:absl:Going to run a new execution: ExecutionInfo(execution_id=2, input_dict={'examples': [Artifact(artifact: id: 1
type_id: 15
uri: "pipelines/penguin-tfdv-schema/CsvExampleGen/examples/1"
properties {
key: "split_names"
value {
string_value: "[\"train\", \"eval\"]"
}
}
custom_properties {
key: "file_format"
value {
string_value: "tfrecords_gzip"
}
}
custom_properties {
key: "input_fingerprint"
value {
string_value: "split:single_split,num_files:1,total_bytes:25648,xor_checksum:1638702606,sum_checksum:1638702606"
}
}
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv-schema:2021-12-05T11:10:06.420329:CsvExampleGen:examples:0"
}
}
custom_properties {
key: "payload_format"
value {
string_value: "FORMAT_TF_EXAMPLE"
}
}
custom_properties {
key: "span"
value {
int_value: 0
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.4.0"
}
}
state: LIVE
create_time_since_epoch: 1638702608076
last_update_time_since_epoch: 1638702608076
, artifact_type: id: 15
name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
)]}, output_dict=defaultdict(<class 'list'>, {'statistics': [Artifact(artifact: uri: "pipelines/penguin-tfdv-schema/StatisticsGen/statistics/2"
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv-schema:2021-12-05T11:10:06.420329:StatisticsGen:statistics:0"
}
}
, artifact_type: name: "ExampleStatistics"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
)]}), exec_properties={'exclude_splits': '[]'}, execution_output_uri='pipelines/penguin-tfdv-schema/StatisticsGen/.system/executor_execution/2/executor_output.pb', stateful_working_dir='pipelines/penguin-tfdv-schema/StatisticsGen/.system/stateful_working_dir/2021-12-05T11:10:06.420329', tmp_dir='pipelines/penguin-tfdv-schema/StatisticsGen/.system/executor_execution/2/.temp/', pipeline_node=node_info {
type {
name: "tfx.components.statistics_gen.component.StatisticsGen"
}
id: "StatisticsGen"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv-schema"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:06.420329"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv-schema.StatisticsGen"
}
}
}
}
inputs {
inputs {
key: "examples"
value {
channels {
producer_node_query {
id: "CsvExampleGen"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv-schema"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:06.420329"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv-schema.CsvExampleGen"
}
}
}
artifact_query {
type {
name: "Examples"
}
}
output_key: "examples"
}
min_count: 1
}
}
}
outputs {
outputs {
key: "statistics"
value {
artifact_spec {
type {
name: "ExampleStatistics"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
}
}
}
}
}
parameters {
parameters {
key: "exclude_splits"
value {
field_value {
string_value: "[]"
}
}
}
}
upstream_nodes: "CsvExampleGen"
downstream_nodes: "SchemaGen"
execution_options {
caching_options {
}
}
, pipeline_info=id: "penguin-tfdv-schema"
, pipeline_run_id='2021-12-05T11:10:06.420329')
INFO:absl:Generating statistics for split train.
INFO:absl:Statistics for split train written to pipelines/penguin-tfdv-schema/StatisticsGen/statistics/2/Split-train.
INFO:absl:Generating statistics for split eval.
INFO:absl:Statistics for split eval written to pipelines/penguin-tfdv-schema/StatisticsGen/statistics/2/Split-eval.
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
INFO:absl:Cleaning up stateless execution info.
INFO:absl:Execution 2 succeeded.
INFO:absl:Cleaning up stateful execution info.
INFO:absl:Publishing output artifacts defaultdict(<class 'list'>, {'statistics': [Artifact(artifact: uri: "pipelines/penguin-tfdv-schema/StatisticsGen/statistics/2"
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv-schema:2021-12-05T11:10:06.420329:StatisticsGen:statistics:0"
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.4.0"
}
}
, artifact_type: name: "ExampleStatistics"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
)]}) for execution 2
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Component StatisticsGen is finished.
INFO:absl:Component SchemaGen is running.
INFO:absl:Running launcher for node_info {
type {
name: "tfx.components.schema_gen.component.SchemaGen"
}
id: "SchemaGen"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv-schema"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:06.420329"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv-schema.SchemaGen"
}
}
}
}
inputs {
inputs {
key: "statistics"
value {
channels {
producer_node_query {
id: "StatisticsGen"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv-schema"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:06.420329"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv-schema.StatisticsGen"
}
}
}
artifact_query {
type {
name: "ExampleStatistics"
}
}
output_key: "statistics"
}
min_count: 1
}
}
}
outputs {
outputs {
key: "schema"
value {
artifact_spec {
type {
name: "Schema"
}
}
}
}
}
parameters {
parameters {
key: "exclude_splits"
value {
field_value {
string_value: "[]"
}
}
}
parameters {
key: "infer_feature_shape"
value {
field_value {
int_value: 1
}
}
}
}
upstream_nodes: "StatisticsGen"
execution_options {
caching_options {
}
}
INFO:absl:MetadataStore with DB connection initialized
I1205 11:10:10.975282 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Going to run a new execution 3
INFO:absl:Going to run a new execution: ExecutionInfo(execution_id=3, input_dict={'statistics': [Artifact(artifact: id: 2
type_id: 17
uri: "pipelines/penguin-tfdv-schema/StatisticsGen/statistics/2"
properties {
key: "split_names"
value {
string_value: "[\"train\", \"eval\"]"
}
}
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv-schema:2021-12-05T11:10:06.420329:StatisticsGen:statistics:0"
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.4.0"
}
}
state: LIVE
create_time_since_epoch: 1638702610957
last_update_time_since_epoch: 1638702610957
, artifact_type: id: 17
name: "ExampleStatistics"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
)]}, output_dict=defaultdict(<class 'list'>, {'schema': [Artifact(artifact: uri: "pipelines/penguin-tfdv-schema/SchemaGen/schema/3"
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv-schema:2021-12-05T11:10:06.420329:SchemaGen:schema:0"
}
}
, artifact_type: name: "Schema"
)]}), exec_properties={'exclude_splits': '[]', 'infer_feature_shape': 1}, execution_output_uri='pipelines/penguin-tfdv-schema/SchemaGen/.system/executor_execution/3/executor_output.pb', stateful_working_dir='pipelines/penguin-tfdv-schema/SchemaGen/.system/stateful_working_dir/2021-12-05T11:10:06.420329', tmp_dir='pipelines/penguin-tfdv-schema/SchemaGen/.system/executor_execution/3/.temp/', pipeline_node=node_info {
type {
name: "tfx.components.schema_gen.component.SchemaGen"
}
id: "SchemaGen"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv-schema"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:06.420329"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv-schema.SchemaGen"
}
}
}
}
inputs {
inputs {
key: "statistics"
value {
channels {
producer_node_query {
id: "StatisticsGen"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv-schema"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:06.420329"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv-schema.StatisticsGen"
}
}
}
artifact_query {
type {
name: "ExampleStatistics"
}
}
output_key: "statistics"
}
min_count: 1
}
}
}
outputs {
outputs {
key: "schema"
value {
artifact_spec {
type {
name: "Schema"
}
}
}
}
}
parameters {
parameters {
key: "exclude_splits"
value {
field_value {
string_value: "[]"
}
}
}
parameters {
key: "infer_feature_shape"
value {
field_value {
int_value: 1
}
}
}
}
upstream_nodes: "StatisticsGen"
execution_options {
caching_options {
}
}
, pipeline_info=id: "penguin-tfdv-schema"
, pipeline_run_id='2021-12-05T11:10:06.420329')
INFO:absl:Processing schema from statistics for split train.
INFO:absl:Processing schema from statistics for split eval.
INFO:absl:Schema written to pipelines/penguin-tfdv-schema/SchemaGen/schema/3/schema.pbtxt.
INFO:absl:Cleaning up stateless execution info.
INFO:absl:Execution 3 succeeded.
INFO:absl:Cleaning up stateful execution info.
INFO:absl:Publishing output artifacts defaultdict(<class 'list'>, {'schema': [Artifact(artifact: uri: "pipelines/penguin-tfdv-schema/SchemaGen/schema/3"
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv-schema:2021-12-05T11:10:06.420329:SchemaGen:schema:0"
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.4.0"
}
}
, artifact_type: name: "Schema"
)]}) for execution 3
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Component SchemaGen is finished.
I1205 11:10:11.010145 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
"INFO:absl:Component SchemaGen tamamlandı" ifadesini görmelisiniz. boru hattı başarıyla tamamlandıysa.
Veri kümemizi anlamak için boru hattının çıktısını inceleyeceğiz.
İşlem hattının çıktılarını gözden geçirin
Önceki öğretici açıklandığı gibi, bir TFX boru çıkışları, eserler ve iki türlü üretir meta veri DB (MLMD) eser ve boru hattı infaz meta verileri içerir. Bu çıktıların konumunu yukarıdaki hücrelerde tanımladık. Varsayılan olarak, eserler altında saklanır pipelines dizin ve meta altında sqlite veritabanı olarak depolanır metadata dizinine.
Bu çıktıları programlı olarak bulmak için MLMD API'lerini kullanabilirsiniz. İlk olarak, henüz üretilmiş çıktı yapılarını aramak için bazı yardımcı fonksiyonlar tanımlayacağız.
from ml_metadata.proto import metadata_store_pb2
# Non-public APIs, just for showcase.
from tfx.orchestration.portable.mlmd import execution_lib
# TODO(b/171447278): Move these functions into the TFX library.
def get_latest_artifacts(metadata, pipeline_name, component_id):
"""Output artifacts of the latest run of the component."""
context = metadata.store.get_context_by_type_and_name(
'node', f'{pipeline_name}.{component_id}')
executions = metadata.store.get_executions_by_context(context.id)
latest_execution = max(executions,
key=lambda e:e.last_update_time_since_epoch)
return execution_lib.get_artifacts_dict(metadata, latest_execution.id,
[metadata_store_pb2.Event.OUTPUT])
# Non-public APIs, just for showcase.
from tfx.orchestration.experimental.interactive import visualizations
def visualize_artifacts(artifacts):
"""Visualizes artifacts using standard visualization modules."""
for artifact in artifacts:
visualization = visualizations.get_registry().get_visualization(
artifact.type_name)
if visualization:
visualization.display(artifact)
from tfx.orchestration.experimental.interactive import standard_visualizations
standard_visualizations.register_standard_visualizations()
Şimdi boru hattı yürütmesinden çıktıları inceleyebiliriz.
# Non-public APIs, just for showcase.
from tfx.orchestration.metadata import Metadata
from tfx.types import standard_component_specs
metadata_connection_config = tfx.orchestration.metadata.sqlite_metadata_connection_config(
SCHEMA_METADATA_PATH)
with Metadata(metadata_connection_config) as metadata_handler:
# Find output artifacts from MLMD.
stat_gen_output = get_latest_artifacts(metadata_handler, SCHEMA_PIPELINE_NAME,
'StatisticsGen')
stats_artifacts = stat_gen_output[standard_component_specs.STATISTICS_KEY]
schema_gen_output = get_latest_artifacts(metadata_handler,
SCHEMA_PIPELINE_NAME, 'SchemaGen')
schema_artifacts = schema_gen_output[standard_component_specs.SCHEMA_KEY]
INFO:absl:MetadataStore with DB connection initialized
Her bileşenin çıktılarını incelemenin zamanı geldi. Yukarıda tarif edildiği gibi, Tensorflow Veri Doğrulama (TFDV) kullanılır StatisticsGen ve SchemaGen ve TFDV da bu bileşenlerden çıkışların görselleştirme sağlar.
Bu eğitimde, görselleştirmeyi göstermek için TFDV'yi dahili olarak kullanan TFX'teki görselleştirme yardımcı yöntemlerini kullanacağız.
StatisticsGen'den gelen çıktıyı inceleyin
# docs-infra: no-execute
visualize_artifacts(stats_artifacts)
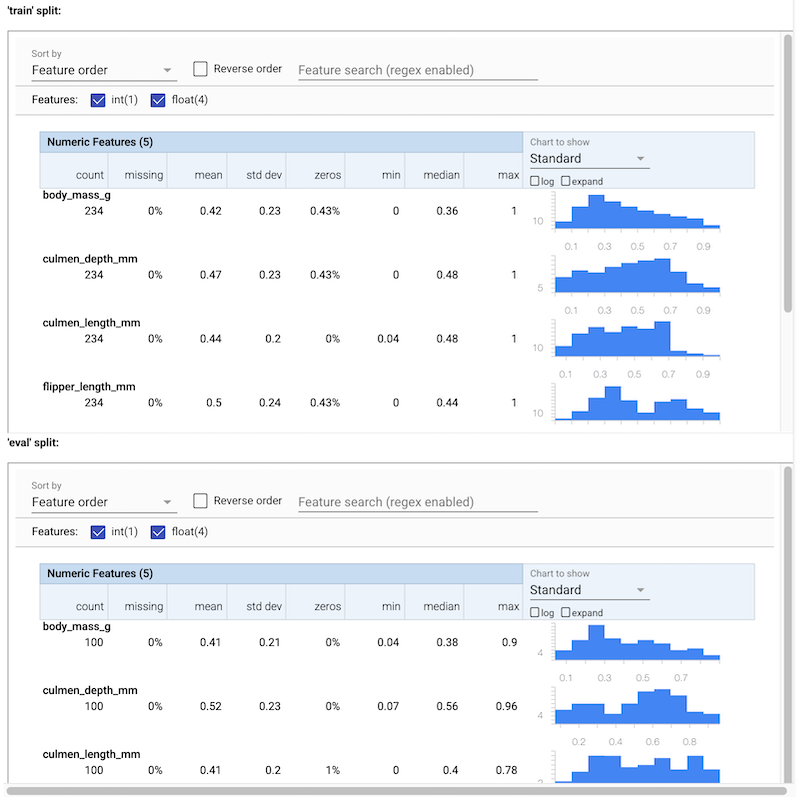
Giriş verileri için çeşitli istatistikleri görebilirsiniz. Bu istatistik beslenir SchemaGen otomatik verilerinin bir ilk şema oluşturmak için.
Çıktıyı SchemaGen'den inceleyin
visualize_artifacts(schema_artifacts)
Bu şema, StatisticsGen'in çıktısından otomatik olarak çıkarılır. 4 FLOAT özelliği ve 1 INT özelliği görebilmelisiniz.
Şemayı ileride kullanmak üzere dışa aktarın
Oluşturulan şemayı gözden geçirmemiz ve iyileştirmemiz gerekiyor. ML model eğitimi için sonraki işlem hatlarında kullanılmak üzere gözden geçirilen şemanın kalıcı olması gerekir. Başka bir deyişle, gerçek kullanım durumları için şema dosyasını sürüm kontrol sisteminize eklemek isteyebilirsiniz. Bu öğreticide, basitlik için şemayı önceden tanımlanmış bir dosya sistemi yoluna kopyalayacağız.
import shutil
_schema_filename = 'schema.pbtxt'
SCHEMA_PATH = 'schema'
os.makedirs(SCHEMA_PATH, exist_ok=True)
_generated_path = os.path.join(schema_artifacts[0].uri, _schema_filename)
# Copy the 'schema.pbtxt' file from the artifact uri to a predefined path.
shutil.copy(_generated_path, SCHEMA_PATH)
'schema/schema.pbtxt'
Şema dosyası kullanır Protokol Tampon metin biçiminde ve bir örneğini TensorFlow Meta Veri Şeması proto .
print(f'Schema at {SCHEMA_PATH}-----')
!cat {SCHEMA_PATH}/*
Schema at schema-----
feature {
name: "body_mass_g"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "culmen_depth_mm"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "culmen_length_mm"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "flipper_length_mm"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "species"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
Şema tanımını gerektiği gibi gözden geçirdiğinizden ve muhtemelen düzenlediğinizden emin olmalısınız. Bu eğitimde, oluşturulan şemayı değişmeden kullanacağız.
Giriş örneklerini doğrulayın ve bir makine öğrenimi modelini eğitin
Biz oluşturulan bu boru hattına geri döner Basit TFX Boru Hattı Öğreticisi bir ML modelini eğitmek ve model eğitim kodunu yazmak için oluşturulan şema kullanmak.
Biz de bir katacak ExampleValidator şemaya göre, gelen veri kümesindeki anomaliler ve eksik değerler arayacaktır bileşeni.
Model eğitim kodunu yazın
Biz de yaptığımız gibi model kodu yazmak gerekir Basit TFX Boru Hattı Öğreticisi .
Modelin kendisi önceki öğreticidekiyle aynıdır, ancak bu sefer özellikleri manuel olarak belirtmek yerine önceki boru hattından oluşturulan şemayı kullanacağız. Kodun çoğu değiştirilmedi. Tek fark, bu dosyadaki özelliklerin adlarını ve türlerini belirtmemize gerek olmamasıdır. Bunun yerine, şema dosyadan okuyarak.
_trainer_module_file = 'penguin_trainer.py'
%%writefile {_trainer_module_file}
from typing import List
from absl import logging
import tensorflow as tf
from tensorflow import keras
from tensorflow_transform.tf_metadata import schema_utils
from tfx import v1 as tfx
from tfx_bsl.public import tfxio
from tensorflow_metadata.proto.v0 import schema_pb2
# We don't need to specify _FEATURE_KEYS and _FEATURE_SPEC any more.
# Those information can be read from the given schema file.
_LABEL_KEY = 'species'
_TRAIN_BATCH_SIZE = 20
_EVAL_BATCH_SIZE = 10
def _input_fn(file_pattern: List[str],
data_accessor: tfx.components.DataAccessor,
schema: schema_pb2.Schema,
batch_size: int = 200) -> tf.data.Dataset:
"""Generates features and label for training.
Args:
file_pattern: List of paths or patterns of input tfrecord files.
data_accessor: DataAccessor for converting input to RecordBatch.
schema: schema of the input data.
batch_size: representing the number of consecutive elements of returned
dataset to combine in a single batch
Returns:
A dataset that contains (features, indices) tuple where features is a
dictionary of Tensors, and indices is a single Tensor of label indices.
"""
return data_accessor.tf_dataset_factory(
file_pattern,
tfxio.TensorFlowDatasetOptions(
batch_size=batch_size, label_key=_LABEL_KEY),
schema=schema).repeat()
def _build_keras_model(schema: schema_pb2.Schema) -> tf.keras.Model:
"""Creates a DNN Keras model for classifying penguin data.
Returns:
A Keras Model.
"""
# The model below is built with Functional API, please refer to
# https://www.tensorflow.org/guide/keras/overview for all API options.
# ++ Changed code: Uses all features in the schema except the label.
feature_keys = [f.name for f in schema.feature if f.name != _LABEL_KEY]
inputs = [keras.layers.Input(shape=(1,), name=f) for f in feature_keys]
# ++ End of the changed code.
d = keras.layers.concatenate(inputs)
for _ in range(2):
d = keras.layers.Dense(8, activation='relu')(d)
outputs = keras.layers.Dense(3)(d)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile(
optimizer=keras.optimizers.Adam(1e-2),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[keras.metrics.SparseCategoricalAccuracy()])
model.summary(print_fn=logging.info)
return model
# TFX Trainer will call this function.
def run_fn(fn_args: tfx.components.FnArgs):
"""Train the model based on given args.
Args:
fn_args: Holds args used to train the model as name/value pairs.
"""
# ++ Changed code: Reads in schema file passed to the Trainer component.
schema = tfx.utils.parse_pbtxt_file(fn_args.schema_path, schema_pb2.Schema())
# ++ End of the changed code.
train_dataset = _input_fn(
fn_args.train_files,
fn_args.data_accessor,
schema,
batch_size=_TRAIN_BATCH_SIZE)
eval_dataset = _input_fn(
fn_args.eval_files,
fn_args.data_accessor,
schema,
batch_size=_EVAL_BATCH_SIZE)
model = _build_keras_model(schema)
model.fit(
train_dataset,
steps_per_epoch=fn_args.train_steps,
validation_data=eval_dataset,
validation_steps=fn_args.eval_steps)
# The result of the training should be saved in `fn_args.serving_model_dir`
# directory.
model.save(fn_args.serving_model_dir, save_format='tf')
Writing penguin_trainer.py
Artık model eğitimi için bir TFX işlem hattı oluşturmak için tüm hazırlık adımlarını tamamladınız.
Bir işlem hattı tanımı yazın
İki yeni bileşenleri katacak Importer ve ExampleValidator . İçe aktarıcı, TFX ardışık düzenine harici bir dosya getirir. Bu durumda şema tanımını içeren bir dosyadır. ExampleValidator, giriş verilerini inceleyecek ve tüm giriş verilerinin sağladığımız veri şemasına uyup uymadığını doğrulayacaktır.
def _create_pipeline(pipeline_name: str, pipeline_root: str, data_root: str,
schema_path: str, module_file: str, serving_model_dir: str,
metadata_path: str) -> tfx.dsl.Pipeline:
"""Creates a pipeline using predefined schema with TFX."""
# Brings data into the pipeline.
example_gen = tfx.components.CsvExampleGen(input_base=data_root)
# Computes statistics over data for visualization and example validation.
statistics_gen = tfx.components.StatisticsGen(
examples=example_gen.outputs['examples'])
# NEW: Import the schema.
schema_importer = tfx.dsl.Importer(
source_uri=schema_path,
artifact_type=tfx.types.standard_artifacts.Schema).with_id(
'schema_importer')
# NEW: Performs anomaly detection based on statistics and data schema.
example_validator = tfx.components.ExampleValidator(
statistics=statistics_gen.outputs['statistics'],
schema=schema_importer.outputs['result'])
# Uses user-provided Python function that trains a model.
trainer = tfx.components.Trainer(
module_file=module_file,
examples=example_gen.outputs['examples'],
schema=schema_importer.outputs['result'], # Pass the imported schema.
train_args=tfx.proto.TrainArgs(num_steps=100),
eval_args=tfx.proto.EvalArgs(num_steps=5))
# Pushes the model to a filesystem destination.
pusher = tfx.components.Pusher(
model=trainer.outputs['model'],
push_destination=tfx.proto.PushDestination(
filesystem=tfx.proto.PushDestination.Filesystem(
base_directory=serving_model_dir)))
components = [
example_gen,
# NEW: Following three components were added to the pipeline.
statistics_gen,
schema_importer,
example_validator,
trainer,
pusher,
]
return tfx.dsl.Pipeline(
pipeline_name=pipeline_name,
pipeline_root=pipeline_root,
metadata_connection_config=tfx.orchestration.metadata
.sqlite_metadata_connection_config(metadata_path),
components=components)
Boru hattını çalıştırın
tfx.orchestration.LocalDagRunner().run(
_create_pipeline(
pipeline_name=PIPELINE_NAME,
pipeline_root=PIPELINE_ROOT,
data_root=DATA_ROOT,
schema_path=SCHEMA_PATH,
module_file=_trainer_module_file,
serving_model_dir=SERVING_MODEL_DIR,
metadata_path=METADATA_PATH))
INFO:absl:Excluding no splits because exclude_splits is not set.
INFO:absl:Excluding no splits because exclude_splits is not set.
INFO:absl:Generating ephemeral wheel package for '/tmpfs/src/temp/docs/tutorials/tfx/penguin_trainer.py' (including modules: ['penguin_trainer']).
INFO:absl:User module package has hash fingerprint version 000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2.
INFO:absl:Executing: ['/tmpfs/src/tf_docs_env/bin/python', '/tmp/tmp50dqc5bp/_tfx_generated_setup.py', 'bdist_wheel', '--bdist-dir', '/tmp/tmp6_kn7s87', '--dist-dir', '/tmp/tmpwt7plki0']
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/setuptools/command/install.py:37: SetuptoolsDeprecationWarning: setup.py install is deprecated. Use build and pip and other standards-based tools.
setuptools.SetuptoolsDeprecationWarning,
listing git files failed - pretending there aren't any
INFO:absl:Successfully built user code wheel distribution at 'pipelines/penguin-tfdv/_wheels/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3-none-any.whl'; target user module is 'penguin_trainer'.
INFO:absl:Full user module path is 'penguin_trainer@pipelines/penguin-tfdv/_wheels/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3-none-any.whl'
INFO:absl:Using deployment config:
executor_specs {
key: "CsvExampleGen"
value {
beam_executable_spec {
python_executor_spec {
class_path: "tfx.components.example_gen.csv_example_gen.executor.Executor"
}
}
}
}
executor_specs {
key: "ExampleValidator"
value {
python_class_executable_spec {
class_path: "tfx.components.example_validator.executor.Executor"
}
}
}
executor_specs {
key: "Pusher"
value {
python_class_executable_spec {
class_path: "tfx.components.pusher.executor.Executor"
}
}
}
executor_specs {
key: "StatisticsGen"
value {
beam_executable_spec {
python_executor_spec {
class_path: "tfx.components.statistics_gen.executor.Executor"
}
}
}
}
executor_specs {
key: "Trainer"
value {
python_class_executable_spec {
class_path: "tfx.components.trainer.executor.GenericExecutor"
}
}
}
custom_driver_specs {
key: "CsvExampleGen"
value {
python_class_executable_spec {
class_path: "tfx.components.example_gen.driver.FileBasedDriver"
}
}
}
metadata_connection_config {
sqlite {
filename_uri: "metadata/penguin-tfdv/metadata.db"
connection_mode: READWRITE_OPENCREATE
}
}
INFO:absl:Using connection config:
sqlite {
filename_uri: "metadata/penguin-tfdv/metadata.db"
connection_mode: READWRITE_OPENCREATE
}
INFO:absl:Component CsvExampleGen is running.
INFO:absl:Running launcher for node_info {
type {
name: "tfx.components.example_gen.csv_example_gen.component.CsvExampleGen"
}
id: "CsvExampleGen"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.CsvExampleGen"
}
}
}
}
outputs {
outputs {
key: "examples"
value {
artifact_spec {
type {
name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
}
}
}
}
}
parameters {
parameters {
key: "input_base"
value {
field_value {
string_value: "/tmp/tfx-datan3p7t1d2"
}
}
}
parameters {
key: "input_config"
value {
field_value {
string_value: "{\n \"splits\": [\n {\n \"name\": \"single_split\",\n \"pattern\": \"*\"\n }\n ]\n}"
}
}
}
parameters {
key: "output_config"
value {
field_value {
string_value: "{\n \"split_config\": {\n \"splits\": [\n {\n \"hash_buckets\": 2,\n \"name\": \"train\"\n },\n {\n \"hash_buckets\": 1,\n \"name\": \"eval\"\n }\n ]\n }\n}"
}
}
}
parameters {
key: "output_data_format"
value {
field_value {
int_value: 6
}
}
}
parameters {
key: "output_file_format"
value {
field_value {
int_value: 5
}
}
}
}
downstream_nodes: "StatisticsGen"
downstream_nodes: "Trainer"
execution_options {
caching_options {
}
}
INFO:absl:MetadataStore with DB connection initialized
I1205 11:10:11.685647 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
I1205 11:10:11.692644 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
I1205 11:10:11.699625 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
I1205 11:10:11.708110 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
INFO:absl:select span and version = (0, None)
INFO:absl:latest span and version = (0, None)
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Going to run a new execution 1
I1205 11:10:11.722760 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
INFO:absl:Going to run a new execution: ExecutionInfo(execution_id=1, input_dict={}, output_dict=defaultdict(<class 'list'>, {'examples': [Artifact(artifact: uri: "pipelines/penguin-tfdv/CsvExampleGen/examples/1"
custom_properties {
key: "input_fingerprint"
value {
string_value: "split:single_split,num_files:1,total_bytes:25648,xor_checksum:1638702606,sum_checksum:1638702606"
}
}
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv:2021-12-05T11:10:11.667239:CsvExampleGen:examples:0"
}
}
custom_properties {
key: "span"
value {
int_value: 0
}
}
, artifact_type: name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
)]}), exec_properties={'input_base': '/tmp/tfx-datan3p7t1d2', 'input_config': '{\n "splits": [\n {\n "name": "single_split",\n "pattern": "*"\n }\n ]\n}', 'output_data_format': 6, 'output_config': '{\n "split_config": {\n "splits": [\n {\n "hash_buckets": 2,\n "name": "train"\n },\n {\n "hash_buckets": 1,\n "name": "eval"\n }\n ]\n }\n}', 'output_file_format': 5, 'span': 0, 'version': None, 'input_fingerprint': 'split:single_split,num_files:1,total_bytes:25648,xor_checksum:1638702606,sum_checksum:1638702606'}, execution_output_uri='pipelines/penguin-tfdv/CsvExampleGen/.system/executor_execution/1/executor_output.pb', stateful_working_dir='pipelines/penguin-tfdv/CsvExampleGen/.system/stateful_working_dir/2021-12-05T11:10:11.667239', tmp_dir='pipelines/penguin-tfdv/CsvExampleGen/.system/executor_execution/1/.temp/', pipeline_node=node_info {
type {
name: "tfx.components.example_gen.csv_example_gen.component.CsvExampleGen"
}
id: "CsvExampleGen"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.CsvExampleGen"
}
}
}
}
outputs {
outputs {
key: "examples"
value {
artifact_spec {
type {
name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
}
}
}
}
}
parameters {
parameters {
key: "input_base"
value {
field_value {
string_value: "/tmp/tfx-datan3p7t1d2"
}
}
}
parameters {
key: "input_config"
value {
field_value {
string_value: "{\n \"splits\": [\n {\n \"name\": \"single_split\",\n \"pattern\": \"*\"\n }\n ]\n}"
}
}
}
parameters {
key: "output_config"
value {
field_value {
string_value: "{\n \"split_config\": {\n \"splits\": [\n {\n \"hash_buckets\": 2,\n \"name\": \"train\"\n },\n {\n \"hash_buckets\": 1,\n \"name\": \"eval\"\n }\n ]\n }\n}"
}
}
}
parameters {
key: "output_data_format"
value {
field_value {
int_value: 6
}
}
}
parameters {
key: "output_file_format"
value {
field_value {
int_value: 5
}
}
}
}
downstream_nodes: "StatisticsGen"
downstream_nodes: "Trainer"
execution_options {
caching_options {
}
}
, pipeline_info=id: "penguin-tfdv"
, pipeline_run_id='2021-12-05T11:10:11.667239')
INFO:absl:Generating examples.
INFO:absl:Processing input csv data /tmp/tfx-datan3p7t1d2/* to TFExample.
running bdist_wheel
running build
running build_py
creating build
creating build/lib
copying penguin_trainer.py -> build/lib
installing to /tmp/tmp6_kn7s87
running install
running install_lib
copying build/lib/penguin_trainer.py -> /tmp/tmp6_kn7s87
running install_egg_info
running egg_info
creating tfx_user_code_Trainer.egg-info
writing tfx_user_code_Trainer.egg-info/PKG-INFO
writing dependency_links to tfx_user_code_Trainer.egg-info/dependency_links.txt
writing top-level names to tfx_user_code_Trainer.egg-info/top_level.txt
writing manifest file 'tfx_user_code_Trainer.egg-info/SOURCES.txt'
reading manifest file 'tfx_user_code_Trainer.egg-info/SOURCES.txt'
writing manifest file 'tfx_user_code_Trainer.egg-info/SOURCES.txt'
Copying tfx_user_code_Trainer.egg-info to /tmp/tmp6_kn7s87/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3.7.egg-info
running install_scripts
creating /tmp/tmp6_kn7s87/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2.dist-info/WHEEL
creating '/tmp/tmpwt7plki0/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3-none-any.whl' and adding '/tmp/tmp6_kn7s87' to it
adding 'penguin_trainer.py'
adding 'tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2.dist-info/METADATA'
adding 'tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2.dist-info/WHEEL'
adding 'tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2.dist-info/top_level.txt'
adding 'tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2.dist-info/RECORD'
removing /tmp/tmp6_kn7s87
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
INFO:absl:Examples generated.
INFO:absl:Cleaning up stateless execution info.
INFO:absl:Execution 1 succeeded.
INFO:absl:Cleaning up stateful execution info.
INFO:absl:Publishing output artifacts defaultdict(<class 'list'>, {'examples': [Artifact(artifact: uri: "pipelines/penguin-tfdv/CsvExampleGen/examples/1"
custom_properties {
key: "input_fingerprint"
value {
string_value: "split:single_split,num_files:1,total_bytes:25648,xor_checksum:1638702606,sum_checksum:1638702606"
}
}
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv:2021-12-05T11:10:11.667239:CsvExampleGen:examples:0"
}
}
custom_properties {
key: "span"
value {
int_value: 0
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.4.0"
}
}
, artifact_type: name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
)]}) for execution 1
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Component CsvExampleGen is finished.
INFO:absl:Component schema_importer is running.
INFO:absl:Running launcher for node_info {
type {
name: "tfx.dsl.components.common.importer.Importer"
}
id: "schema_importer"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.schema_importer"
}
}
}
}
outputs {
outputs {
key: "result"
value {
artifact_spec {
type {
name: "Schema"
}
}
}
}
}
parameters {
parameters {
key: "artifact_uri"
value {
field_value {
string_value: "schema"
}
}
}
parameters {
key: "reimport"
value {
field_value {
int_value: 0
}
}
}
}
downstream_nodes: "ExampleValidator"
downstream_nodes: "Trainer"
execution_options {
caching_options {
}
}
INFO:absl:Running as an importer node.
INFO:absl:MetadataStore with DB connection initialized
I1205 11:10:12.796727 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
INFO:absl:Processing source uri: schema, properties: {}, custom_properties: {}
INFO:absl:Component schema_importer is finished.
I1205 11:10:12.806819 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
INFO:absl:Component StatisticsGen is running.
INFO:absl:Running launcher for node_info {
type {
name: "tfx.components.statistics_gen.component.StatisticsGen"
}
id: "StatisticsGen"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.StatisticsGen"
}
}
}
}
inputs {
inputs {
key: "examples"
value {
channels {
producer_node_query {
id: "CsvExampleGen"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.CsvExampleGen"
}
}
}
artifact_query {
type {
name: "Examples"
}
}
output_key: "examples"
}
min_count: 1
}
}
}
outputs {
outputs {
key: "statistics"
value {
artifact_spec {
type {
name: "ExampleStatistics"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
}
}
}
}
}
parameters {
parameters {
key: "exclude_splits"
value {
field_value {
string_value: "[]"
}
}
}
}
upstream_nodes: "CsvExampleGen"
downstream_nodes: "ExampleValidator"
execution_options {
caching_options {
}
}
INFO:absl:MetadataStore with DB connection initialized
I1205 11:10:12.827589 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Going to run a new execution 3
INFO:absl:Going to run a new execution: ExecutionInfo(execution_id=3, input_dict={'examples': [Artifact(artifact: id: 1
type_id: 15
uri: "pipelines/penguin-tfdv/CsvExampleGen/examples/1"
properties {
key: "split_names"
value {
string_value: "[\"train\", \"eval\"]"
}
}
custom_properties {
key: "file_format"
value {
string_value: "tfrecords_gzip"
}
}
custom_properties {
key: "input_fingerprint"
value {
string_value: "split:single_split,num_files:1,total_bytes:25648,xor_checksum:1638702606,sum_checksum:1638702606"
}
}
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv:2021-12-05T11:10:11.667239:CsvExampleGen:examples:0"
}
}
custom_properties {
key: "payload_format"
value {
string_value: "FORMAT_TF_EXAMPLE"
}
}
custom_properties {
key: "span"
value {
int_value: 0
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.4.0"
}
}
state: LIVE
create_time_since_epoch: 1638702612780
last_update_time_since_epoch: 1638702612780
, artifact_type: id: 15
name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
)]}, output_dict=defaultdict(<class 'list'>, {'statistics': [Artifact(artifact: uri: "pipelines/penguin-tfdv/StatisticsGen/statistics/3"
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv:2021-12-05T11:10:11.667239:StatisticsGen:statistics:0"
}
}
, artifact_type: name: "ExampleStatistics"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
)]}), exec_properties={'exclude_splits': '[]'}, execution_output_uri='pipelines/penguin-tfdv/StatisticsGen/.system/executor_execution/3/executor_output.pb', stateful_working_dir='pipelines/penguin-tfdv/StatisticsGen/.system/stateful_working_dir/2021-12-05T11:10:11.667239', tmp_dir='pipelines/penguin-tfdv/StatisticsGen/.system/executor_execution/3/.temp/', pipeline_node=node_info {
type {
name: "tfx.components.statistics_gen.component.StatisticsGen"
}
id: "StatisticsGen"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.StatisticsGen"
}
}
}
}
inputs {
inputs {
key: "examples"
value {
channels {
producer_node_query {
id: "CsvExampleGen"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.CsvExampleGen"
}
}
}
artifact_query {
type {
name: "Examples"
}
}
output_key: "examples"
}
min_count: 1
}
}
}
outputs {
outputs {
key: "statistics"
value {
artifact_spec {
type {
name: "ExampleStatistics"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
}
}
}
}
}
parameters {
parameters {
key: "exclude_splits"
value {
field_value {
string_value: "[]"
}
}
}
}
upstream_nodes: "CsvExampleGen"
downstream_nodes: "ExampleValidator"
execution_options {
caching_options {
}
}
, pipeline_info=id: "penguin-tfdv"
, pipeline_run_id='2021-12-05T11:10:11.667239')
INFO:absl:Generating statistics for split train.
INFO:absl:Statistics for split train written to pipelines/penguin-tfdv/StatisticsGen/statistics/3/Split-train.
INFO:absl:Generating statistics for split eval.
INFO:absl:Statistics for split eval written to pipelines/penguin-tfdv/StatisticsGen/statistics/3/Split-eval.
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
INFO:absl:Cleaning up stateless execution info.
INFO:absl:Execution 3 succeeded.
INFO:absl:Cleaning up stateful execution info.
INFO:absl:Publishing output artifacts defaultdict(<class 'list'>, {'statistics': [Artifact(artifact: uri: "pipelines/penguin-tfdv/StatisticsGen/statistics/3"
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv:2021-12-05T11:10:11.667239:StatisticsGen:statistics:0"
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.4.0"
}
}
, artifact_type: name: "ExampleStatistics"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
)]}) for execution 3
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Component StatisticsGen is finished.
INFO:absl:Component Trainer is running.
INFO:absl:Running launcher for node_info {
type {
name: "tfx.components.trainer.component.Trainer"
}
id: "Trainer"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.Trainer"
}
}
}
}
inputs {
inputs {
key: "examples"
value {
channels {
producer_node_query {
id: "CsvExampleGen"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.CsvExampleGen"
}
}
}
artifact_query {
type {
name: "Examples"
}
}
output_key: "examples"
}
min_count: 1
}
}
inputs {
key: "schema"
value {
channels {
producer_node_query {
id: "schema_importer"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.schema_importer"
}
}
}
artifact_query {
type {
name: "Schema"
}
}
output_key: "result"
}
}
}
}
outputs {
outputs {
key: "model"
value {
artifact_spec {
type {
name: "Model"
}
}
}
}
outputs {
key: "model_run"
value {
artifact_spec {
type {
name: "ModelRun"
}
}
}
}
}
parameters {
parameters {
key: "custom_config"
value {
field_value {
string_value: "null"
}
}
}
parameters {
key: "eval_args"
value {
field_value {
string_value: "{\n \"num_steps\": 5\n}"
}
}
}
parameters {
key: "module_path"
value {
field_value {
string_value: "penguin_trainer@pipelines/penguin-tfdv/_wheels/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3-none-any.whl"
}
}
}
parameters {
key: "train_args"
value {
field_value {
string_value: "{\n \"num_steps\": 100\n}"
}
}
}
}
upstream_nodes: "CsvExampleGen"
upstream_nodes: "schema_importer"
downstream_nodes: "Pusher"
execution_options {
caching_options {
}
}
INFO:absl:MetadataStore with DB connection initialized
I1205 11:10:15.426606 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Going to run a new execution 4
INFO:absl:Going to run a new execution: ExecutionInfo(execution_id=4, input_dict={'examples': [Artifact(artifact: id: 1
type_id: 15
uri: "pipelines/penguin-tfdv/CsvExampleGen/examples/1"
properties {
key: "split_names"
value {
string_value: "[\"train\", \"eval\"]"
}
}
custom_properties {
key: "file_format"
value {
string_value: "tfrecords_gzip"
}
}
custom_properties {
key: "input_fingerprint"
value {
string_value: "split:single_split,num_files:1,total_bytes:25648,xor_checksum:1638702606,sum_checksum:1638702606"
}
}
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv:2021-12-05T11:10:11.667239:CsvExampleGen:examples:0"
}
}
custom_properties {
key: "payload_format"
value {
string_value: "FORMAT_TF_EXAMPLE"
}
}
custom_properties {
key: "span"
value {
int_value: 0
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.4.0"
}
}
state: LIVE
create_time_since_epoch: 1638702612780
last_update_time_since_epoch: 1638702612780
, artifact_type: id: 15
name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
)], 'schema': [Artifact(artifact: id: 2
type_id: 17
uri: "schema"
custom_properties {
key: "tfx_version"
value {
string_value: "1.4.0"
}
}
state: LIVE
create_time_since_epoch: 1638702612810
last_update_time_since_epoch: 1638702612810
, artifact_type: id: 17
name: "Schema"
)]}, output_dict=defaultdict(<class 'list'>, {'model_run': [Artifact(artifact: uri: "pipelines/penguin-tfdv/Trainer/model_run/4"
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv:2021-12-05T11:10:11.667239:Trainer:model_run:0"
}
}
, artifact_type: name: "ModelRun"
)], 'model': [Artifact(artifact: uri: "pipelines/penguin-tfdv/Trainer/model/4"
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv:2021-12-05T11:10:11.667239:Trainer:model:0"
}
}
, artifact_type: name: "Model"
)]}), exec_properties={'eval_args': '{\n "num_steps": 5\n}', 'module_path': 'penguin_trainer@pipelines/penguin-tfdv/_wheels/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3-none-any.whl', 'custom_config': 'null', 'train_args': '{\n "num_steps": 100\n}'}, execution_output_uri='pipelines/penguin-tfdv/Trainer/.system/executor_execution/4/executor_output.pb', stateful_working_dir='pipelines/penguin-tfdv/Trainer/.system/stateful_working_dir/2021-12-05T11:10:11.667239', tmp_dir='pipelines/penguin-tfdv/Trainer/.system/executor_execution/4/.temp/', pipeline_node=node_info {
type {
name: "tfx.components.trainer.component.Trainer"
}
id: "Trainer"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.Trainer"
}
}
}
}
inputs {
inputs {
key: "examples"
value {
channels {
producer_node_query {
id: "CsvExampleGen"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.CsvExampleGen"
}
}
}
artifact_query {
type {
name: "Examples"
}
}
output_key: "examples"
}
min_count: 1
}
}
inputs {
key: "schema"
value {
channels {
producer_node_query {
id: "schema_importer"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.schema_importer"
}
}
}
artifact_query {
type {
name: "Schema"
}
}
output_key: "result"
}
}
}
}
outputs {
outputs {
key: "model"
value {
artifact_spec {
type {
name: "Model"
}
}
}
}
outputs {
key: "model_run"
value {
artifact_spec {
type {
name: "ModelRun"
}
}
}
}
}
parameters {
parameters {
key: "custom_config"
value {
field_value {
string_value: "null"
}
}
}
parameters {
key: "eval_args"
value {
field_value {
string_value: "{\n \"num_steps\": 5\n}"
}
}
}
parameters {
key: "module_path"
value {
field_value {
string_value: "penguin_trainer@pipelines/penguin-tfdv/_wheels/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3-none-any.whl"
}
}
}
parameters {
key: "train_args"
value {
field_value {
string_value: "{\n \"num_steps\": 100\n}"
}
}
}
}
upstream_nodes: "CsvExampleGen"
upstream_nodes: "schema_importer"
downstream_nodes: "Pusher"
execution_options {
caching_options {
}
}
, pipeline_info=id: "penguin-tfdv"
, pipeline_run_id='2021-12-05T11:10:11.667239')
INFO:absl:Train on the 'train' split when train_args.splits is not set.
INFO:absl:Evaluate on the 'eval' split when eval_args.splits is not set.
INFO:absl:udf_utils.get_fn {'eval_args': '{\n "num_steps": 5\n}', 'module_path': 'penguin_trainer@pipelines/penguin-tfdv/_wheels/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3-none-any.whl', 'custom_config': 'null', 'train_args': '{\n "num_steps": 100\n}'} 'run_fn'
INFO:absl:Installing 'pipelines/penguin-tfdv/_wheels/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3-none-any.whl' to a temporary directory.
INFO:absl:Executing: ['/tmpfs/src/tf_docs_env/bin/python', '-m', 'pip', 'install', '--target', '/tmp/tmpbb1l9_v7', 'pipelines/penguin-tfdv/_wheels/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3-none-any.whl']
Processing ./pipelines/penguin-tfdv/_wheels/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3-none-any.whl
INFO:absl:Successfully installed 'pipelines/penguin-tfdv/_wheels/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3-none-any.whl'.
INFO:absl:Training model.
INFO:absl:Feature body_mass_g has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature culmen_depth_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature culmen_length_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature flipper_length_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature species has a shape dim {
size: 1
}
. Setting to DenseTensor.
Installing collected packages: tfx-user-code-Trainer
Successfully installed tfx-user-code-Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2
INFO:absl:Feature body_mass_g has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature culmen_depth_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature culmen_length_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature flipper_length_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature species has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature body_mass_g has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature culmen_depth_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature culmen_length_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature flipper_length_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature species has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature body_mass_g has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature culmen_depth_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature culmen_length_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature flipper_length_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature species has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Model: "model"
INFO:absl:__________________________________________________________________________________________________
INFO:absl:Layer (type) Output Shape Param # Connected to
INFO:absl:==================================================================================================
INFO:absl:body_mass_g (InputLayer) [(None, 1)] 0
INFO:absl:__________________________________________________________________________________________________
INFO:absl:culmen_depth_mm (InputLayer) [(None, 1)] 0
INFO:absl:__________________________________________________________________________________________________
INFO:absl:culmen_length_mm (InputLayer) [(None, 1)] 0
INFO:absl:__________________________________________________________________________________________________
INFO:absl:flipper_length_mm (InputLayer) [(None, 1)] 0
INFO:absl:__________________________________________________________________________________________________
INFO:absl:concatenate (Concatenate) (None, 4) 0 body_mass_g[0][0]
INFO:absl: culmen_depth_mm[0][0]
INFO:absl: culmen_length_mm[0][0]
INFO:absl: flipper_length_mm[0][0]
INFO:absl:__________________________________________________________________________________________________
INFO:absl:dense (Dense) (None, 8) 40 concatenate[0][0]
INFO:absl:__________________________________________________________________________________________________
INFO:absl:dense_1 (Dense) (None, 8) 72 dense[0][0]
INFO:absl:__________________________________________________________________________________________________
INFO:absl:dense_2 (Dense) (None, 3) 27 dense_1[0][0]
INFO:absl:==================================================================================================
INFO:absl:Total params: 139
INFO:absl:Trainable params: 139
INFO:absl:Non-trainable params: 0
INFO:absl:__________________________________________________________________________________________________
100/100 [==============================] - 1s 3ms/step - loss: 0.5752 - sparse_categorical_accuracy: 0.8165 - val_loss: 0.2294 - val_sparse_categorical_accuracy: 0.9400
2021-12-05 11:10:20.208161: W tensorflow/python/util/util.cc:348] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
INFO:tensorflow:Assets written to: pipelines/penguin-tfdv/Trainer/model/4/Format-Serving/assets
INFO:tensorflow:Assets written to: pipelines/penguin-tfdv/Trainer/model/4/Format-Serving/assets
INFO:absl:Training complete. Model written to pipelines/penguin-tfdv/Trainer/model/4/Format-Serving. ModelRun written to pipelines/penguin-tfdv/Trainer/model_run/4
INFO:absl:Cleaning up stateless execution info.
INFO:absl:Execution 4 succeeded.
INFO:absl:Cleaning up stateful execution info.
INFO:absl:Publishing output artifacts defaultdict(<class 'list'>, {'model_run': [Artifact(artifact: uri: "pipelines/penguin-tfdv/Trainer/model_run/4"
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv:2021-12-05T11:10:11.667239:Trainer:model_run:0"
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.4.0"
}
}
, artifact_type: name: "ModelRun"
)], 'model': [Artifact(artifact: uri: "pipelines/penguin-tfdv/Trainer/model/4"
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv:2021-12-05T11:10:11.667239:Trainer:model:0"
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.4.0"
}
}
, artifact_type: name: "Model"
)]}) for execution 4
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Component Trainer is finished.
I1205 11:10:20.766410 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
I1205 11:10:20.770478 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
INFO:absl:Component ExampleValidator is running.
INFO:absl:Running launcher for node_info {
type {
name: "tfx.components.example_validator.component.ExampleValidator"
}
id: "ExampleValidator"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.ExampleValidator"
}
}
}
}
inputs {
inputs {
key: "schema"
value {
channels {
producer_node_query {
id: "schema_importer"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.schema_importer"
}
}
}
artifact_query {
type {
name: "Schema"
}
}
output_key: "result"
}
min_count: 1
}
}
inputs {
key: "statistics"
value {
channels {
producer_node_query {
id: "StatisticsGen"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.StatisticsGen"
}
}
}
artifact_query {
type {
name: "ExampleStatistics"
}
}
output_key: "statistics"
}
min_count: 1
}
}
}
outputs {
outputs {
key: "anomalies"
value {
artifact_spec {
type {
name: "ExampleAnomalies"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
}
}
}
}
}
parameters {
parameters {
key: "exclude_splits"
value {
field_value {
string_value: "[]"
}
}
}
}
upstream_nodes: "StatisticsGen"
upstream_nodes: "schema_importer"
execution_options {
caching_options {
}
}
INFO:absl:MetadataStore with DB connection initialized
I1205 11:10:20.793696 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Going to run a new execution 5
INFO:absl:Going to run a new execution: ExecutionInfo(execution_id=5, input_dict={'statistics': [Artifact(artifact: id: 3
type_id: 19
uri: "pipelines/penguin-tfdv/StatisticsGen/statistics/3"
properties {
key: "split_names"
value {
string_value: "[\"train\", \"eval\"]"
}
}
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv:2021-12-05T11:10:11.667239:StatisticsGen:statistics:0"
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.4.0"
}
}
state: LIVE
create_time_since_epoch: 1638702615406
last_update_time_since_epoch: 1638702615406
, artifact_type: id: 19
name: "ExampleStatistics"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
)], 'schema': [Artifact(artifact: id: 2
type_id: 17
uri: "schema"
custom_properties {
key: "tfx_version"
value {
string_value: "1.4.0"
}
}
state: LIVE
create_time_since_epoch: 1638702612810
last_update_time_since_epoch: 1638702612810
, artifact_type: id: 17
name: "Schema"
)]}, output_dict=defaultdict(<class 'list'>, {'anomalies': [Artifact(artifact: uri: "pipelines/penguin-tfdv/ExampleValidator/anomalies/5"
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv:2021-12-05T11:10:11.667239:ExampleValidator:anomalies:0"
}
}
, artifact_type: name: "ExampleAnomalies"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
)]}), exec_properties={'exclude_splits': '[]'}, execution_output_uri='pipelines/penguin-tfdv/ExampleValidator/.system/executor_execution/5/executor_output.pb', stateful_working_dir='pipelines/penguin-tfdv/ExampleValidator/.system/stateful_working_dir/2021-12-05T11:10:11.667239', tmp_dir='pipelines/penguin-tfdv/ExampleValidator/.system/executor_execution/5/.temp/', pipeline_node=node_info {
type {
name: "tfx.components.example_validator.component.ExampleValidator"
}
id: "ExampleValidator"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.ExampleValidator"
}
}
}
}
inputs {
inputs {
key: "schema"
value {
channels {
producer_node_query {
id: "schema_importer"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.schema_importer"
}
}
}
artifact_query {
type {
name: "Schema"
}
}
output_key: "result"
}
min_count: 1
}
}
inputs {
key: "statistics"
value {
channels {
producer_node_query {
id: "StatisticsGen"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.StatisticsGen"
}
}
}
artifact_query {
type {
name: "ExampleStatistics"
}
}
output_key: "statistics"
}
min_count: 1
}
}
}
outputs {
outputs {
key: "anomalies"
value {
artifact_spec {
type {
name: "ExampleAnomalies"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
}
}
}
}
}
parameters {
parameters {
key: "exclude_splits"
value {
field_value {
string_value: "[]"
}
}
}
}
upstream_nodes: "StatisticsGen"
upstream_nodes: "schema_importer"
execution_options {
caching_options {
}
}
, pipeline_info=id: "penguin-tfdv"
, pipeline_run_id='2021-12-05T11:10:11.667239')
INFO:absl:Validating schema against the computed statistics for split train.
INFO:absl:Validation complete for split train. Anomalies written to pipelines/penguin-tfdv/ExampleValidator/anomalies/5/Split-train.
INFO:absl:Validating schema against the computed statistics for split eval.
INFO:absl:Validation complete for split eval. Anomalies written to pipelines/penguin-tfdv/ExampleValidator/anomalies/5/Split-eval.
INFO:absl:Cleaning up stateless execution info.
INFO:absl:Execution 5 succeeded.
INFO:absl:Cleaning up stateful execution info.
INFO:absl:Publishing output artifacts defaultdict(<class 'list'>, {'anomalies': [Artifact(artifact: uri: "pipelines/penguin-tfdv/ExampleValidator/anomalies/5"
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv:2021-12-05T11:10:11.667239:ExampleValidator:anomalies:0"
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.4.0"
}
}
, artifact_type: name: "ExampleAnomalies"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
)]}) for execution 5
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Component ExampleValidator is finished.
INFO:absl:Component Pusher is running.
INFO:absl:Running launcher for node_info {
type {
name: "tfx.components.pusher.component.Pusher"
}
id: "Pusher"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.Pusher"
}
}
}
}
inputs {
inputs {
key: "model"
value {
channels {
producer_node_query {
id: "Trainer"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.Trainer"
}
}
}
artifact_query {
type {
name: "Model"
}
}
output_key: "model"
}
}
}
}
outputs {
outputs {
key: "pushed_model"
value {
artifact_spec {
type {
name: "PushedModel"
}
}
}
}
}
parameters {
parameters {
key: "custom_config"
value {
field_value {
string_value: "null"
}
}
}
parameters {
key: "push_destination"
value {
field_value {
string_value: "{\n \"filesystem\": {\n \"base_directory\": \"serving_model/penguin-tfdv\"\n }\n}"
}
}
}
}
upstream_nodes: "Trainer"
execution_options {
caching_options {
}
}
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:MetadataStore with DB connection initialized
I1205 11:10:20.848567 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
INFO:absl:Going to run a new execution 6
INFO:absl:Going to run a new execution: ExecutionInfo(execution_id=6, input_dict={'model': [Artifact(artifact: id: 5
type_id: 22
uri: "pipelines/penguin-tfdv/Trainer/model/4"
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv:2021-12-05T11:10:11.667239:Trainer:model:0"
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.4.0"
}
}
state: LIVE
create_time_since_epoch: 1638702620774
last_update_time_since_epoch: 1638702620774
, artifact_type: id: 22
name: "Model"
)]}, output_dict=defaultdict(<class 'list'>, {'pushed_model': [Artifact(artifact: uri: "pipelines/penguin-tfdv/Pusher/pushed_model/6"
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv:2021-12-05T11:10:11.667239:Pusher:pushed_model:0"
}
}
, artifact_type: name: "PushedModel"
)]}), exec_properties={'push_destination': '{\n "filesystem": {\n "base_directory": "serving_model/penguin-tfdv"\n }\n}', 'custom_config': 'null'}, execution_output_uri='pipelines/penguin-tfdv/Pusher/.system/executor_execution/6/executor_output.pb', stateful_working_dir='pipelines/penguin-tfdv/Pusher/.system/stateful_working_dir/2021-12-05T11:10:11.667239', tmp_dir='pipelines/penguin-tfdv/Pusher/.system/executor_execution/6/.temp/', pipeline_node=node_info {
type {
name: "tfx.components.pusher.component.Pusher"
}
id: "Pusher"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.Pusher"
}
}
}
}
inputs {
inputs {
key: "model"
value {
channels {
producer_node_query {
id: "Trainer"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.Trainer"
}
}
}
artifact_query {
type {
name: "Model"
}
}
output_key: "model"
}
}
}
}
outputs {
outputs {
key: "pushed_model"
value {
artifact_spec {
type {
name: "PushedModel"
}
}
}
}
}
parameters {
parameters {
key: "custom_config"
value {
field_value {
string_value: "null"
}
}
}
parameters {
key: "push_destination"
value {
field_value {
string_value: "{\n \"filesystem\": {\n \"base_directory\": \"serving_model/penguin-tfdv\"\n }\n}"
}
}
}
}
upstream_nodes: "Trainer"
execution_options {
caching_options {
}
}
, pipeline_info=id: "penguin-tfdv"
, pipeline_run_id='2021-12-05T11:10:11.667239')
WARNING:absl:Pusher is going to push the model without validation. Consider using Evaluator or InfraValidator in your pipeline.
INFO:absl:Model version: 1638702620
INFO:absl:Model written to serving path serving_model/penguin-tfdv/1638702620.
INFO:absl:Model pushed to pipelines/penguin-tfdv/Pusher/pushed_model/6.
INFO:absl:Cleaning up stateless execution info.
INFO:absl:Execution 6 succeeded.
INFO:absl:Cleaning up stateful execution info.
INFO:absl:Publishing output artifacts defaultdict(<class 'list'>, {'pushed_model': [Artifact(artifact: uri: "pipelines/penguin-tfdv/Pusher/pushed_model/6"
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv:2021-12-05T11:10:11.667239:Pusher:pushed_model:0"
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.4.0"
}
}
, artifact_type: name: "PushedModel"
)]}) for execution 6
INFO:absl:MetadataStore with DB connection initialized
I1205 11:10:20.879335 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
INFO:absl:Component Pusher is finished.
"INFO:absl:Component İtici tamamlandı" ifadesini görmelisiniz. boru hattı başarıyla tamamlandıysa.
Boru hattının çıktılarını inceleyin
Penguenler için sınıflandırma modelini eğittik ve ayrıca ExampleValidator bileşenindeki giriş örneklerini doğruladık. Önceki ardışık düzende yaptığımız gibi ExampleValidator'ın çıktısını analiz edebiliriz.
metadata_connection_config = tfx.orchestration.metadata.sqlite_metadata_connection_config(
METADATA_PATH)
with Metadata(metadata_connection_config) as metadata_handler:
ev_output = get_latest_artifacts(metadata_handler, PIPELINE_NAME,
'ExampleValidator')
anomalies_artifacts = ev_output[standard_component_specs.ANOMALIES_KEY]
INFO:absl:MetadataStore with DB connection initialized
ExampleValidator'daki Örnek Anomaliler de görselleştirilebilir.
visualize_artifacts(anomalies_artifacts)
Örneklerin her bir bölümü için "Anormallik bulunamadı" ifadesini görmelisiniz. Bu ardışık düzende şema oluşturma için kullanılan aynı verileri kullandığımız için burada herhangi bir anormallik beklenmez. Bu ardışık düzeni yeni gelen verilerle art arda çalıştırırsanız, ExampleValidator yeni verilerle mevcut şema arasındaki tüm tutarsızlıkları bulabilmelidir.
Herhangi bir anormallik bulunursa, herhangi bir örneğin varsayımlarınıza uymadığını kontrol etmek için verilerinizi gözden geçirebilirsiniz. İstatistikGen gibi diğer bileşenlerin çıktıları faydalı olabilir. Ancak, bulunan herhangi bir anormallik daha fazla boru hattı yürütmesini ENGELLEMEZ.
Sonraki adımlar
Üzerinde daha fazla kaynak bulabilirsiniz https://www.tensorflow.org/tfx/tutorials
Bakınız TFX Boru hatları anlama Tfx çeşitli kavramlar hakkında daha fazla bilgi edinmek.