
 Ver fonte no GitHub
Ver fonte no GitHubNeste tutorial baseado em notebook, criaremos e executaremos pipelines TFX para validar os dados de entrada e criar um modelo de ML. Este notebook é baseado no gasoduto TFX nós construímos em simples TFX Pipeline Tutorial . Se você ainda não leu esse tutorial, deve lê-lo antes de prosseguir com este bloco de notas.
A primeira tarefa em qualquer ciência de dados ou projeto de ML é entender e limpar os dados, o que inclui:
- Compreender os tipos de dados, distribuições e outras informações (por exemplo, valor médio ou número de únicos) sobre cada recurso
- Gerar um esquema preliminar que descreve os dados
- Identificação de anomalias e valores ausentes nos dados em relação a determinado esquema
Neste tutorial, criaremos dois pipelines TFX.
Primeiro, criaremos um pipeline para analisar o conjunto de dados e gerar um esquema preliminar do conjunto de dados fornecido. Este gasoduto irá incluir dois novos componentes, StatisticsGen e SchemaGen .
Assim que tivermos um esquema adequado dos dados, criaremos um pipeline para treinar um modelo de classificação de ML com base no pipeline do tutorial anterior. Neste gasoduto, vamos usar o esquema do primeiro gasoduto e um novo componente, ExampleValidator , para validar os dados introduzidos.
Os três novos componentes, StatisticsGen, SchemaGen e ExampleValidator, são componentes TFX para análise de dados e validação, e eles são implementados usando o TensorFlow Validação de dados biblioteca.
Consulte Compreender TFX Pipelines para aprender mais sobre vários conceitos em TFX.
Configurar
Primeiro precisamos instalar o pacote TFX Python e baixar o conjunto de dados que usaremos em nosso modelo.
Atualizar Pip
Para evitar a atualização do Pip em um sistema quando executado localmente, verifique se estamos executando no Colab. É claro que os sistemas locais podem ser atualizados separadamente.
try:
import colab
!pip install --upgrade pip
except:
pass
Instale TFX
pip install -U tfx
Você reiniciou o tempo de execução?
Se você estiver usando o Google Colab, na primeira vez que executar a célula acima, você deve reiniciar o tempo de execução clicando acima do botão "RESTART RUNTIME" ou usando o menu "Runtime> Restart runtime ...". Isso ocorre devido à maneira como o Colab carrega os pacotes.
Verifique as versões do TensorFlow e TFX.
import tensorflow as tf
print('TensorFlow version: {}'.format(tf.__version__))
from tfx import v1 as tfx
print('TFX version: {}'.format(tfx.__version__))
TensorFlow version: 2.6.2 TFX version: 1.4.0
Configurar variáveis
Existem algumas variáveis usadas para definir um pipeline. Você pode personalizar essas variáveis como quiser. Por padrão, toda a saída do pipeline será gerada no diretório atual.
import os
# We will create two pipelines. One for schema generation and one for training.
SCHEMA_PIPELINE_NAME = "penguin-tfdv-schema"
PIPELINE_NAME = "penguin-tfdv"
# Output directory to store artifacts generated from the pipeline.
SCHEMA_PIPELINE_ROOT = os.path.join('pipelines', SCHEMA_PIPELINE_NAME)
PIPELINE_ROOT = os.path.join('pipelines', PIPELINE_NAME)
# Path to a SQLite DB file to use as an MLMD storage.
SCHEMA_METADATA_PATH = os.path.join('metadata', SCHEMA_PIPELINE_NAME,
'metadata.db')
METADATA_PATH = os.path.join('metadata', PIPELINE_NAME, 'metadata.db')
# Output directory where created models from the pipeline will be exported.
SERVING_MODEL_DIR = os.path.join('serving_model', PIPELINE_NAME)
from absl import logging
logging.set_verbosity(logging.INFO) # Set default logging level.
Prepare dados de exemplo
Faremos o download do conjunto de dados de exemplo para uso em nosso pipeline TFX. O conjunto de dados que estamos usando é Palmer Penguins conjunto de dados que também é usada em outros exemplos TFX .
Existem quatro recursos numéricos neste conjunto de dados:
- culmen_length_mm
- culmen_depth_mm
- flipper_length_mm
- body_mass_g
Todos os recursos já foram normalizados para ter intervalo [0,1]. Vamos construir um modelo de classificação que prevê as species de pingüins.
Como o componente TFX ExampleGen lê as entradas de um diretório, precisamos criar um diretório e copiar o conjunto de dados para ele.
import urllib.request
import tempfile
DATA_ROOT = tempfile.mkdtemp(prefix='tfx-data') # Create a temporary directory.
_data_url = 'https://raw.githubusercontent.com/tensorflow/tfx/master/tfx/examples/penguin/data/labelled/penguins_processed.csv'
_data_filepath = os.path.join(DATA_ROOT, "data.csv")
urllib.request.urlretrieve(_data_url, _data_filepath)
('/tmp/tfx-datan3p7t1d2/data.csv', <http.client.HTTPMessage at 0x7f8d2f9f9110>)
Dê uma olhada rápida no arquivo CSV.
head {_data_filepath}
species,culmen_length_mm,culmen_depth_mm,flipper_length_mm,body_mass_g 0,0.2545454545454545,0.6666666666666666,0.15254237288135594,0.2916666666666667 0,0.26909090909090905,0.5119047619047618,0.23728813559322035,0.3055555555555556 0,0.29818181818181805,0.5833333333333334,0.3898305084745763,0.1527777777777778 0,0.16727272727272732,0.7380952380952381,0.3559322033898305,0.20833333333333334 0,0.26181818181818167,0.892857142857143,0.3050847457627119,0.2638888888888889 0,0.24727272727272717,0.5595238095238096,0.15254237288135594,0.2569444444444444 0,0.25818181818181823,0.773809523809524,0.3898305084745763,0.5486111111111112 0,0.32727272727272727,0.5357142857142859,0.1694915254237288,0.1388888888888889 0,0.23636363636363636,0.9642857142857142,0.3220338983050847,0.3055555555555556
Você deve ser capaz de ver cinco colunas de recursos. species é um de 0, 1 ou 2, e todos os outros recursos devem ter valores entre 0 e 1. Vamos criar um gasoduto TFX analisar este conjunto de dados.
Gere um esquema preliminar
Os pipelines TFX são definidos usando APIs Python. Criaremos um pipeline para gerar um esquema a partir dos exemplos de entrada automaticamente. Este esquema pode ser revisado por uma pessoa e ajustado conforme necessário. Assim que o esquema for finalizado, ele pode ser usado para treinamento e validação de exemplo em tarefas posteriores.
Além CsvExampleGen que é usado em simples TFX Pipeline Tutorial , usaremos StatisticsGen e SchemaGen :
- StatisticsGen calcula estatísticas para o conjunto de dados.
- SchemaGen examina as estatísticas e cria um esquema de dados inicial.
Veja as guias para cada componente ou componentes TFX tutorial para aprender mais sobre estes componentes.
Escreva uma definição de pipeline
Definimos uma função para criar um pipeline TFX. Um Pipeline objecto representa um oleoduto TFX que pode ser executado utilizando um dos sistemas de orquestração oleoduto que TFX suportes.
def _create_schema_pipeline(pipeline_name: str,
pipeline_root: str,
data_root: str,
metadata_path: str) -> tfx.dsl.Pipeline:
"""Creates a pipeline for schema generation."""
# Brings data into the pipeline.
example_gen = tfx.components.CsvExampleGen(input_base=data_root)
# NEW: Computes statistics over data for visualization and schema generation.
statistics_gen = tfx.components.StatisticsGen(
examples=example_gen.outputs['examples'])
# NEW: Generates schema based on the generated statistics.
schema_gen = tfx.components.SchemaGen(
statistics=statistics_gen.outputs['statistics'], infer_feature_shape=True)
components = [
example_gen,
statistics_gen,
schema_gen,
]
return tfx.dsl.Pipeline(
pipeline_name=pipeline_name,
pipeline_root=pipeline_root,
metadata_connection_config=tfx.orchestration.metadata
.sqlite_metadata_connection_config(metadata_path),
components=components)
Execute o pipeline
Usaremos LocalDagRunner como no tutorial anterior.
tfx.orchestration.LocalDagRunner().run(
_create_schema_pipeline(
pipeline_name=SCHEMA_PIPELINE_NAME,
pipeline_root=SCHEMA_PIPELINE_ROOT,
data_root=DATA_ROOT,
metadata_path=SCHEMA_METADATA_PATH))
INFO:absl:Excluding no splits because exclude_splits is not set.
INFO:absl:Excluding no splits because exclude_splits is not set.
INFO:absl:Using deployment config:
executor_specs {
key: "CsvExampleGen"
value {
beam_executable_spec {
python_executor_spec {
class_path: "tfx.components.example_gen.csv_example_gen.executor.Executor"
}
}
}
}
executor_specs {
key: "SchemaGen"
value {
python_class_executable_spec {
class_path: "tfx.components.schema_gen.executor.Executor"
}
}
}
executor_specs {
key: "StatisticsGen"
value {
beam_executable_spec {
python_executor_spec {
class_path: "tfx.components.statistics_gen.executor.Executor"
}
}
}
}
custom_driver_specs {
key: "CsvExampleGen"
value {
python_class_executable_spec {
class_path: "tfx.components.example_gen.driver.FileBasedDriver"
}
}
}
metadata_connection_config {
sqlite {
filename_uri: "metadata/penguin-tfdv-schema/metadata.db"
connection_mode: READWRITE_OPENCREATE
}
}
INFO:absl:Using connection config:
sqlite {
filename_uri: "metadata/penguin-tfdv-schema/metadata.db"
connection_mode: READWRITE_OPENCREATE
}
INFO:absl:Component CsvExampleGen is running.
INFO:absl:Running launcher for node_info {
type {
name: "tfx.components.example_gen.csv_example_gen.component.CsvExampleGen"
}
id: "CsvExampleGen"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv-schema"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:06.420329"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv-schema.CsvExampleGen"
}
}
}
}
outputs {
outputs {
key: "examples"
value {
artifact_spec {
type {
name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
}
}
}
}
}
parameters {
parameters {
key: "input_base"
value {
field_value {
string_value: "/tmp/tfx-datan3p7t1d2"
}
}
}
parameters {
key: "input_config"
value {
field_value {
string_value: "{\n \"splits\": [\n {\n \"name\": \"single_split\",\n \"pattern\": \"*\"\n }\n ]\n}"
}
}
}
parameters {
key: "output_config"
value {
field_value {
string_value: "{\n \"split_config\": {\n \"splits\": [\n {\n \"hash_buckets\": 2,\n \"name\": \"train\"\n },\n {\n \"hash_buckets\": 1,\n \"name\": \"eval\"\n }\n ]\n }\n}"
}
}
}
parameters {
key: "output_data_format"
value {
field_value {
int_value: 6
}
}
}
parameters {
key: "output_file_format"
value {
field_value {
int_value: 5
}
}
}
}
downstream_nodes: "StatisticsGen"
execution_options {
caching_options {
}
}
INFO:absl:MetadataStore with DB connection initialized
WARNING: Logging before InitGoogleLogging() is written to STDERR
I1205 11:10:06.444468 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
I1205 11:10:06.453292 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
I1205 11:10:06.460209 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
I1205 11:10:06.467104 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
INFO:absl:select span and version = (0, None)
INFO:absl:latest span and version = (0, None)
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Going to run a new execution 1
I1205 11:10:06.521926 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
INFO:absl:Going to run a new execution: ExecutionInfo(execution_id=1, input_dict={}, output_dict=defaultdict(<class 'list'>, {'examples': [Artifact(artifact: uri: "pipelines/penguin-tfdv-schema/CsvExampleGen/examples/1"
custom_properties {
key: "input_fingerprint"
value {
string_value: "split:single_split,num_files:1,total_bytes:25648,xor_checksum:1638702606,sum_checksum:1638702606"
}
}
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv-schema:2021-12-05T11:10:06.420329:CsvExampleGen:examples:0"
}
}
custom_properties {
key: "span"
value {
int_value: 0
}
}
, artifact_type: name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
)]}), exec_properties={'input_config': '{\n "splits": [\n {\n "name": "single_split",\n "pattern": "*"\n }\n ]\n}', 'output_config': '{\n "split_config": {\n "splits": [\n {\n "hash_buckets": 2,\n "name": "train"\n },\n {\n "hash_buckets": 1,\n "name": "eval"\n }\n ]\n }\n}', 'input_base': '/tmp/tfx-datan3p7t1d2', 'output_file_format': 5, 'output_data_format': 6, 'span': 0, 'version': None, 'input_fingerprint': 'split:single_split,num_files:1,total_bytes:25648,xor_checksum:1638702606,sum_checksum:1638702606'}, execution_output_uri='pipelines/penguin-tfdv-schema/CsvExampleGen/.system/executor_execution/1/executor_output.pb', stateful_working_dir='pipelines/penguin-tfdv-schema/CsvExampleGen/.system/stateful_working_dir/2021-12-05T11:10:06.420329', tmp_dir='pipelines/penguin-tfdv-schema/CsvExampleGen/.system/executor_execution/1/.temp/', pipeline_node=node_info {
type {
name: "tfx.components.example_gen.csv_example_gen.component.CsvExampleGen"
}
id: "CsvExampleGen"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv-schema"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:06.420329"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv-schema.CsvExampleGen"
}
}
}
}
outputs {
outputs {
key: "examples"
value {
artifact_spec {
type {
name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
}
}
}
}
}
parameters {
parameters {
key: "input_base"
value {
field_value {
string_value: "/tmp/tfx-datan3p7t1d2"
}
}
}
parameters {
key: "input_config"
value {
field_value {
string_value: "{\n \"splits\": [\n {\n \"name\": \"single_split\",\n \"pattern\": \"*\"\n }\n ]\n}"
}
}
}
parameters {
key: "output_config"
value {
field_value {
string_value: "{\n \"split_config\": {\n \"splits\": [\n {\n \"hash_buckets\": 2,\n \"name\": \"train\"\n },\n {\n \"hash_buckets\": 1,\n \"name\": \"eval\"\n }\n ]\n }\n}"
}
}
}
parameters {
key: "output_data_format"
value {
field_value {
int_value: 6
}
}
}
parameters {
key: "output_file_format"
value {
field_value {
int_value: 5
}
}
}
}
downstream_nodes: "StatisticsGen"
execution_options {
caching_options {
}
}
, pipeline_info=id: "penguin-tfdv-schema"
, pipeline_run_id='2021-12-05T11:10:06.420329')
INFO:absl:Generating examples.
WARNING:apache_beam.runners.interactive.interactive_environment:Dependencies required for Interactive Beam PCollection visualization are not available, please use: `pip install apache-beam[interactive]` to install necessary dependencies to enable all data visualization features.
INFO:absl:Processing input csv data /tmp/tfx-datan3p7t1d2/* to TFExample.
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
WARNING:apache_beam.io.tfrecordio:Couldn't find python-snappy so the implementation of _TFRecordUtil._masked_crc32c is not as fast as it could be.
INFO:absl:Examples generated.
INFO:absl:Cleaning up stateless execution info.
INFO:absl:Execution 1 succeeded.
INFO:absl:Cleaning up stateful execution info.
INFO:absl:Publishing output artifacts defaultdict(<class 'list'>, {'examples': [Artifact(artifact: uri: "pipelines/penguin-tfdv-schema/CsvExampleGen/examples/1"
custom_properties {
key: "input_fingerprint"
value {
string_value: "split:single_split,num_files:1,total_bytes:25648,xor_checksum:1638702606,sum_checksum:1638702606"
}
}
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv-schema:2021-12-05T11:10:06.420329:CsvExampleGen:examples:0"
}
}
custom_properties {
key: "span"
value {
int_value: 0
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.4.0"
}
}
, artifact_type: name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
)]}) for execution 1
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Component CsvExampleGen is finished.
INFO:absl:Component StatisticsGen is running.
INFO:absl:Running launcher for node_info {
type {
name: "tfx.components.statistics_gen.component.StatisticsGen"
}
id: "StatisticsGen"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv-schema"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:06.420329"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv-schema.StatisticsGen"
}
}
}
}
inputs {
inputs {
key: "examples"
value {
channels {
producer_node_query {
id: "CsvExampleGen"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv-schema"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:06.420329"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv-schema.CsvExampleGen"
}
}
}
artifact_query {
type {
name: "Examples"
}
}
output_key: "examples"
}
min_count: 1
}
}
}
outputs {
outputs {
key: "statistics"
value {
artifact_spec {
type {
name: "ExampleStatistics"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
}
}
}
}
}
parameters {
parameters {
key: "exclude_splits"
value {
field_value {
string_value: "[]"
}
}
}
}
upstream_nodes: "CsvExampleGen"
downstream_nodes: "SchemaGen"
execution_options {
caching_options {
}
}
INFO:absl:MetadataStore with DB connection initialized
I1205 11:10:08.104562 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Going to run a new execution 2
INFO:absl:Going to run a new execution: ExecutionInfo(execution_id=2, input_dict={'examples': [Artifact(artifact: id: 1
type_id: 15
uri: "pipelines/penguin-tfdv-schema/CsvExampleGen/examples/1"
properties {
key: "split_names"
value {
string_value: "[\"train\", \"eval\"]"
}
}
custom_properties {
key: "file_format"
value {
string_value: "tfrecords_gzip"
}
}
custom_properties {
key: "input_fingerprint"
value {
string_value: "split:single_split,num_files:1,total_bytes:25648,xor_checksum:1638702606,sum_checksum:1638702606"
}
}
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv-schema:2021-12-05T11:10:06.420329:CsvExampleGen:examples:0"
}
}
custom_properties {
key: "payload_format"
value {
string_value: "FORMAT_TF_EXAMPLE"
}
}
custom_properties {
key: "span"
value {
int_value: 0
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.4.0"
}
}
state: LIVE
create_time_since_epoch: 1638702608076
last_update_time_since_epoch: 1638702608076
, artifact_type: id: 15
name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
)]}, output_dict=defaultdict(<class 'list'>, {'statistics': [Artifact(artifact: uri: "pipelines/penguin-tfdv-schema/StatisticsGen/statistics/2"
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv-schema:2021-12-05T11:10:06.420329:StatisticsGen:statistics:0"
}
}
, artifact_type: name: "ExampleStatistics"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
)]}), exec_properties={'exclude_splits': '[]'}, execution_output_uri='pipelines/penguin-tfdv-schema/StatisticsGen/.system/executor_execution/2/executor_output.pb', stateful_working_dir='pipelines/penguin-tfdv-schema/StatisticsGen/.system/stateful_working_dir/2021-12-05T11:10:06.420329', tmp_dir='pipelines/penguin-tfdv-schema/StatisticsGen/.system/executor_execution/2/.temp/', pipeline_node=node_info {
type {
name: "tfx.components.statistics_gen.component.StatisticsGen"
}
id: "StatisticsGen"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv-schema"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:06.420329"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv-schema.StatisticsGen"
}
}
}
}
inputs {
inputs {
key: "examples"
value {
channels {
producer_node_query {
id: "CsvExampleGen"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv-schema"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:06.420329"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv-schema.CsvExampleGen"
}
}
}
artifact_query {
type {
name: "Examples"
}
}
output_key: "examples"
}
min_count: 1
}
}
}
outputs {
outputs {
key: "statistics"
value {
artifact_spec {
type {
name: "ExampleStatistics"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
}
}
}
}
}
parameters {
parameters {
key: "exclude_splits"
value {
field_value {
string_value: "[]"
}
}
}
}
upstream_nodes: "CsvExampleGen"
downstream_nodes: "SchemaGen"
execution_options {
caching_options {
}
}
, pipeline_info=id: "penguin-tfdv-schema"
, pipeline_run_id='2021-12-05T11:10:06.420329')
INFO:absl:Generating statistics for split train.
INFO:absl:Statistics for split train written to pipelines/penguin-tfdv-schema/StatisticsGen/statistics/2/Split-train.
INFO:absl:Generating statistics for split eval.
INFO:absl:Statistics for split eval written to pipelines/penguin-tfdv-schema/StatisticsGen/statistics/2/Split-eval.
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
INFO:absl:Cleaning up stateless execution info.
INFO:absl:Execution 2 succeeded.
INFO:absl:Cleaning up stateful execution info.
INFO:absl:Publishing output artifacts defaultdict(<class 'list'>, {'statistics': [Artifact(artifact: uri: "pipelines/penguin-tfdv-schema/StatisticsGen/statistics/2"
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv-schema:2021-12-05T11:10:06.420329:StatisticsGen:statistics:0"
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.4.0"
}
}
, artifact_type: name: "ExampleStatistics"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
)]}) for execution 2
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Component StatisticsGen is finished.
INFO:absl:Component SchemaGen is running.
INFO:absl:Running launcher for node_info {
type {
name: "tfx.components.schema_gen.component.SchemaGen"
}
id: "SchemaGen"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv-schema"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:06.420329"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv-schema.SchemaGen"
}
}
}
}
inputs {
inputs {
key: "statistics"
value {
channels {
producer_node_query {
id: "StatisticsGen"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv-schema"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:06.420329"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv-schema.StatisticsGen"
}
}
}
artifact_query {
type {
name: "ExampleStatistics"
}
}
output_key: "statistics"
}
min_count: 1
}
}
}
outputs {
outputs {
key: "schema"
value {
artifact_spec {
type {
name: "Schema"
}
}
}
}
}
parameters {
parameters {
key: "exclude_splits"
value {
field_value {
string_value: "[]"
}
}
}
parameters {
key: "infer_feature_shape"
value {
field_value {
int_value: 1
}
}
}
}
upstream_nodes: "StatisticsGen"
execution_options {
caching_options {
}
}
INFO:absl:MetadataStore with DB connection initialized
I1205 11:10:10.975282 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Going to run a new execution 3
INFO:absl:Going to run a new execution: ExecutionInfo(execution_id=3, input_dict={'statistics': [Artifact(artifact: id: 2
type_id: 17
uri: "pipelines/penguin-tfdv-schema/StatisticsGen/statistics/2"
properties {
key: "split_names"
value {
string_value: "[\"train\", \"eval\"]"
}
}
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv-schema:2021-12-05T11:10:06.420329:StatisticsGen:statistics:0"
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.4.0"
}
}
state: LIVE
create_time_since_epoch: 1638702610957
last_update_time_since_epoch: 1638702610957
, artifact_type: id: 17
name: "ExampleStatistics"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
)]}, output_dict=defaultdict(<class 'list'>, {'schema': [Artifact(artifact: uri: "pipelines/penguin-tfdv-schema/SchemaGen/schema/3"
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv-schema:2021-12-05T11:10:06.420329:SchemaGen:schema:0"
}
}
, artifact_type: name: "Schema"
)]}), exec_properties={'exclude_splits': '[]', 'infer_feature_shape': 1}, execution_output_uri='pipelines/penguin-tfdv-schema/SchemaGen/.system/executor_execution/3/executor_output.pb', stateful_working_dir='pipelines/penguin-tfdv-schema/SchemaGen/.system/stateful_working_dir/2021-12-05T11:10:06.420329', tmp_dir='pipelines/penguin-tfdv-schema/SchemaGen/.system/executor_execution/3/.temp/', pipeline_node=node_info {
type {
name: "tfx.components.schema_gen.component.SchemaGen"
}
id: "SchemaGen"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv-schema"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:06.420329"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv-schema.SchemaGen"
}
}
}
}
inputs {
inputs {
key: "statistics"
value {
channels {
producer_node_query {
id: "StatisticsGen"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv-schema"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:06.420329"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv-schema.StatisticsGen"
}
}
}
artifact_query {
type {
name: "ExampleStatistics"
}
}
output_key: "statistics"
}
min_count: 1
}
}
}
outputs {
outputs {
key: "schema"
value {
artifact_spec {
type {
name: "Schema"
}
}
}
}
}
parameters {
parameters {
key: "exclude_splits"
value {
field_value {
string_value: "[]"
}
}
}
parameters {
key: "infer_feature_shape"
value {
field_value {
int_value: 1
}
}
}
}
upstream_nodes: "StatisticsGen"
execution_options {
caching_options {
}
}
, pipeline_info=id: "penguin-tfdv-schema"
, pipeline_run_id='2021-12-05T11:10:06.420329')
INFO:absl:Processing schema from statistics for split train.
INFO:absl:Processing schema from statistics for split eval.
INFO:absl:Schema written to pipelines/penguin-tfdv-schema/SchemaGen/schema/3/schema.pbtxt.
INFO:absl:Cleaning up stateless execution info.
INFO:absl:Execution 3 succeeded.
INFO:absl:Cleaning up stateful execution info.
INFO:absl:Publishing output artifacts defaultdict(<class 'list'>, {'schema': [Artifact(artifact: uri: "pipelines/penguin-tfdv-schema/SchemaGen/schema/3"
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv-schema:2021-12-05T11:10:06.420329:SchemaGen:schema:0"
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.4.0"
}
}
, artifact_type: name: "Schema"
)]}) for execution 3
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Component SchemaGen is finished.
I1205 11:10:11.010145 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
Você deverá ver "INFO: absl: Component SchemaGen concluído." se o pipeline foi concluído com sucesso.
Vamos examinar a saída do pipeline para entender nosso conjunto de dados.
Reveja os resultados do pipeline
Tal como explicado no tutorial anterior, uma tubagem TFX produz dois tipos de saídas, artefactos e um metadados DB (MLMD) que contém metadados de artefactos e execuções de oleodutos. Definimos a localização dessas saídas nas células acima. Por padrão, os artefatos são armazenados sob a pipelines diretório e metadados são armazenados como um banco de dados SQLite sob a metadata diretório.
Você pode usar APIs MLMD para localizar essas saídas de maneira programática. Primeiro, definiremos algumas funções utilitárias para pesquisar os artefatos de saída que acabaram de ser produzidos.
from ml_metadata.proto import metadata_store_pb2
# Non-public APIs, just for showcase.
from tfx.orchestration.portable.mlmd import execution_lib
# TODO(b/171447278): Move these functions into the TFX library.
def get_latest_artifacts(metadata, pipeline_name, component_id):
"""Output artifacts of the latest run of the component."""
context = metadata.store.get_context_by_type_and_name(
'node', f'{pipeline_name}.{component_id}')
executions = metadata.store.get_executions_by_context(context.id)
latest_execution = max(executions,
key=lambda e:e.last_update_time_since_epoch)
return execution_lib.get_artifacts_dict(metadata, latest_execution.id,
[metadata_store_pb2.Event.OUTPUT])
# Non-public APIs, just for showcase.
from tfx.orchestration.experimental.interactive import visualizations
def visualize_artifacts(artifacts):
"""Visualizes artifacts using standard visualization modules."""
for artifact in artifacts:
visualization = visualizations.get_registry().get_visualization(
artifact.type_name)
if visualization:
visualization.display(artifact)
from tfx.orchestration.experimental.interactive import standard_visualizations
standard_visualizations.register_standard_visualizations()
Agora podemos examinar as saídas da execução do pipeline.
# Non-public APIs, just for showcase.
from tfx.orchestration.metadata import Metadata
from tfx.types import standard_component_specs
metadata_connection_config = tfx.orchestration.metadata.sqlite_metadata_connection_config(
SCHEMA_METADATA_PATH)
with Metadata(metadata_connection_config) as metadata_handler:
# Find output artifacts from MLMD.
stat_gen_output = get_latest_artifacts(metadata_handler, SCHEMA_PIPELINE_NAME,
'StatisticsGen')
stats_artifacts = stat_gen_output[standard_component_specs.STATISTICS_KEY]
schema_gen_output = get_latest_artifacts(metadata_handler,
SCHEMA_PIPELINE_NAME, 'SchemaGen')
schema_artifacts = schema_gen_output[standard_component_specs.SCHEMA_KEY]
INFO:absl:MetadataStore with DB connection initialized
É hora de examinar as saídas de cada componente. Tal como descrito acima, Tensorflow de validação de dados (TFDV) é usado em StatisticsGen e SchemaGen , e TFDV também proporciona a visualização das saídas destes componentes.
Neste tutorial, usaremos os métodos auxiliares de visualização em TFX que usam TFDV internamente para mostrar a visualização.
Examine a saída do StatisticsGen
# docs-infra: no-execute
visualize_artifacts(stats_artifacts)
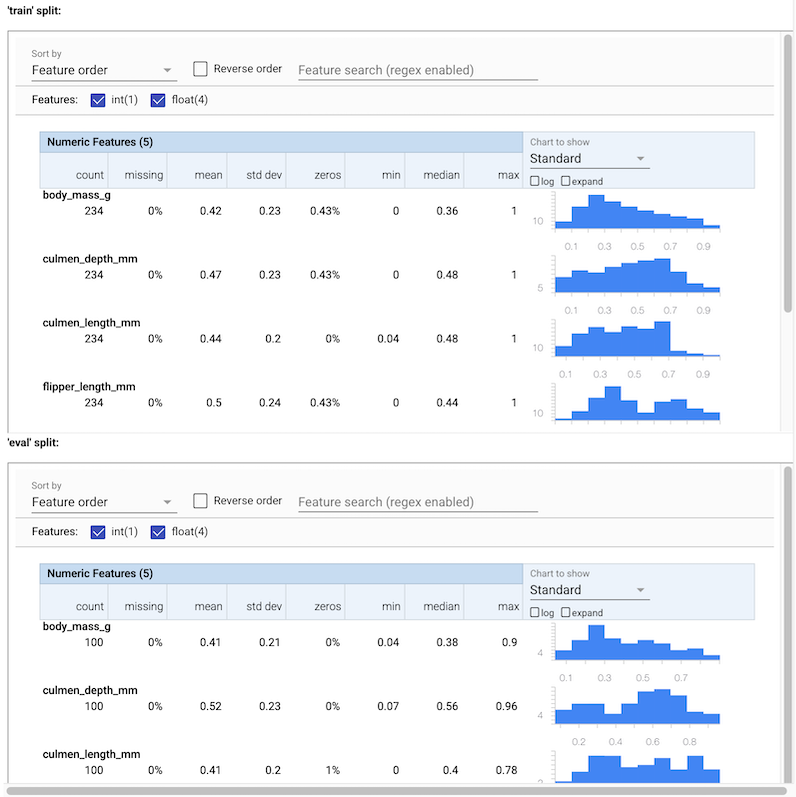
Você pode ver várias estatísticas para os dados de entrada. Estas estatísticas são fornecidos para SchemaGen para construir um esquema inicial de dados automaticamente.
Examine a saída do SchemaGen
visualize_artifacts(schema_artifacts)
Este esquema é inferido automaticamente da saída de StatisticsGen. Você deve ser capaz de ver 4 recursos FLOAT e 1 recurso INT.
Exporte o esquema para uso futuro
Precisamos revisar e refinar o esquema gerado. O esquema revisado precisa ser persistido para ser usado em pipelines subsequentes para o treinamento do modelo de ML. Em outras palavras, você pode querer adicionar o arquivo de esquema ao seu sistema de controle de versão para casos de uso reais. Neste tutorial, vamos apenas copiar o esquema para um caminho de sistema de arquivos predefinido para simplificar.
import shutil
_schema_filename = 'schema.pbtxt'
SCHEMA_PATH = 'schema'
os.makedirs(SCHEMA_PATH, exist_ok=True)
_generated_path = os.path.join(schema_artifacts[0].uri, _schema_filename)
# Copy the 'schema.pbtxt' file from the artifact uri to a predefined path.
shutil.copy(_generated_path, SCHEMA_PATH)
'schema/schema.pbtxt'
O arquivo de esquema usa formato de texto buffer de protocolo e uma instância de TensorFlow Metadados Schema proto .
print(f'Schema at {SCHEMA_PATH}-----')
!cat {SCHEMA_PATH}/*
Schema at schema-----
feature {
name: "body_mass_g"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "culmen_depth_mm"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "culmen_length_mm"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "flipper_length_mm"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "species"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
Você deve certificar-se de revisar e possivelmente editar a definição do esquema conforme necessário. Neste tutorial, usaremos apenas o esquema gerado inalterado.
Valide exemplos de entrada e treine um modelo de ML
Nós vamos voltar ao gasoduto que criamos no Simples TFX Pipeline Tutorial , para treinar um modelo ML e utilizar o esquema gerado para escrever o código de treinamento do modelo.
Nós também irá adicionar uma ExampleValidator componente que irá procurar por anomalias e valores ausentes no conjunto de dados de entrada em relação ao esquema.
Escreva o código de treinamento do modelo
Precisamos escrever o código do modelo como fizemos no Simples TFX Pipeline Tutorial .
O modelo em si é o mesmo do tutorial anterior, mas desta vez usaremos o esquema gerado no pipeline anterior em vez de especificar os recursos manualmente. A maior parte do código não foi alterada. A única diferença é que não precisamos especificar os nomes e tipos de recursos neste arquivo. Em vez disso, lê-los a partir do arquivo de esquema.
_trainer_module_file = 'penguin_trainer.py'
%%writefile {_trainer_module_file}
from typing import List
from absl import logging
import tensorflow as tf
from tensorflow import keras
from tensorflow_transform.tf_metadata import schema_utils
from tfx import v1 as tfx
from tfx_bsl.public import tfxio
from tensorflow_metadata.proto.v0 import schema_pb2
# We don't need to specify _FEATURE_KEYS and _FEATURE_SPEC any more.
# Those information can be read from the given schema file.
_LABEL_KEY = 'species'
_TRAIN_BATCH_SIZE = 20
_EVAL_BATCH_SIZE = 10
def _input_fn(file_pattern: List[str],
data_accessor: tfx.components.DataAccessor,
schema: schema_pb2.Schema,
batch_size: int = 200) -> tf.data.Dataset:
"""Generates features and label for training.
Args:
file_pattern: List of paths or patterns of input tfrecord files.
data_accessor: DataAccessor for converting input to RecordBatch.
schema: schema of the input data.
batch_size: representing the number of consecutive elements of returned
dataset to combine in a single batch
Returns:
A dataset that contains (features, indices) tuple where features is a
dictionary of Tensors, and indices is a single Tensor of label indices.
"""
return data_accessor.tf_dataset_factory(
file_pattern,
tfxio.TensorFlowDatasetOptions(
batch_size=batch_size, label_key=_LABEL_KEY),
schema=schema).repeat()
def _build_keras_model(schema: schema_pb2.Schema) -> tf.keras.Model:
"""Creates a DNN Keras model for classifying penguin data.
Returns:
A Keras Model.
"""
# The model below is built with Functional API, please refer to
# https://www.tensorflow.org/guide/keras/overview for all API options.
# ++ Changed code: Uses all features in the schema except the label.
feature_keys = [f.name for f in schema.feature if f.name != _LABEL_KEY]
inputs = [keras.layers.Input(shape=(1,), name=f) for f in feature_keys]
# ++ End of the changed code.
d = keras.layers.concatenate(inputs)
for _ in range(2):
d = keras.layers.Dense(8, activation='relu')(d)
outputs = keras.layers.Dense(3)(d)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile(
optimizer=keras.optimizers.Adam(1e-2),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[keras.metrics.SparseCategoricalAccuracy()])
model.summary(print_fn=logging.info)
return model
# TFX Trainer will call this function.
def run_fn(fn_args: tfx.components.FnArgs):
"""Train the model based on given args.
Args:
fn_args: Holds args used to train the model as name/value pairs.
"""
# ++ Changed code: Reads in schema file passed to the Trainer component.
schema = tfx.utils.parse_pbtxt_file(fn_args.schema_path, schema_pb2.Schema())
# ++ End of the changed code.
train_dataset = _input_fn(
fn_args.train_files,
fn_args.data_accessor,
schema,
batch_size=_TRAIN_BATCH_SIZE)
eval_dataset = _input_fn(
fn_args.eval_files,
fn_args.data_accessor,
schema,
batch_size=_EVAL_BATCH_SIZE)
model = _build_keras_model(schema)
model.fit(
train_dataset,
steps_per_epoch=fn_args.train_steps,
validation_data=eval_dataset,
validation_steps=fn_args.eval_steps)
# The result of the training should be saved in `fn_args.serving_model_dir`
# directory.
model.save(fn_args.serving_model_dir, save_format='tf')
Writing penguin_trainer.py
Agora você concluiu todas as etapas de preparação para construir um pipeline TFX para treinamento de modelo.
Escreva uma definição de pipeline
Nós vamos adicionar dois novos componentes, Importer e ExampleValidator . O importador traz um arquivo externo para o pipeline do TFX. Nesse caso, é um arquivo que contém a definição do esquema. ExampleValidator examinará os dados de entrada e validará se todos os dados de entrada estão em conformidade com o esquema de dados que fornecemos.
def _create_pipeline(pipeline_name: str, pipeline_root: str, data_root: str,
schema_path: str, module_file: str, serving_model_dir: str,
metadata_path: str) -> tfx.dsl.Pipeline:
"""Creates a pipeline using predefined schema with TFX."""
# Brings data into the pipeline.
example_gen = tfx.components.CsvExampleGen(input_base=data_root)
# Computes statistics over data for visualization and example validation.
statistics_gen = tfx.components.StatisticsGen(
examples=example_gen.outputs['examples'])
# NEW: Import the schema.
schema_importer = tfx.dsl.Importer(
source_uri=schema_path,
artifact_type=tfx.types.standard_artifacts.Schema).with_id(
'schema_importer')
# NEW: Performs anomaly detection based on statistics and data schema.
example_validator = tfx.components.ExampleValidator(
statistics=statistics_gen.outputs['statistics'],
schema=schema_importer.outputs['result'])
# Uses user-provided Python function that trains a model.
trainer = tfx.components.Trainer(
module_file=module_file,
examples=example_gen.outputs['examples'],
schema=schema_importer.outputs['result'], # Pass the imported schema.
train_args=tfx.proto.TrainArgs(num_steps=100),
eval_args=tfx.proto.EvalArgs(num_steps=5))
# Pushes the model to a filesystem destination.
pusher = tfx.components.Pusher(
model=trainer.outputs['model'],
push_destination=tfx.proto.PushDestination(
filesystem=tfx.proto.PushDestination.Filesystem(
base_directory=serving_model_dir)))
components = [
example_gen,
# NEW: Following three components were added to the pipeline.
statistics_gen,
schema_importer,
example_validator,
trainer,
pusher,
]
return tfx.dsl.Pipeline(
pipeline_name=pipeline_name,
pipeline_root=pipeline_root,
metadata_connection_config=tfx.orchestration.metadata
.sqlite_metadata_connection_config(metadata_path),
components=components)
Execute o pipeline
tfx.orchestration.LocalDagRunner().run(
_create_pipeline(
pipeline_name=PIPELINE_NAME,
pipeline_root=PIPELINE_ROOT,
data_root=DATA_ROOT,
schema_path=SCHEMA_PATH,
module_file=_trainer_module_file,
serving_model_dir=SERVING_MODEL_DIR,
metadata_path=METADATA_PATH))
INFO:absl:Excluding no splits because exclude_splits is not set.
INFO:absl:Excluding no splits because exclude_splits is not set.
INFO:absl:Generating ephemeral wheel package for '/tmpfs/src/temp/docs/tutorials/tfx/penguin_trainer.py' (including modules: ['penguin_trainer']).
INFO:absl:User module package has hash fingerprint version 000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2.
INFO:absl:Executing: ['/tmpfs/src/tf_docs_env/bin/python', '/tmp/tmp50dqc5bp/_tfx_generated_setup.py', 'bdist_wheel', '--bdist-dir', '/tmp/tmp6_kn7s87', '--dist-dir', '/tmp/tmpwt7plki0']
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/setuptools/command/install.py:37: SetuptoolsDeprecationWarning: setup.py install is deprecated. Use build and pip and other standards-based tools.
setuptools.SetuptoolsDeprecationWarning,
listing git files failed - pretending there aren't any
INFO:absl:Successfully built user code wheel distribution at 'pipelines/penguin-tfdv/_wheels/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3-none-any.whl'; target user module is 'penguin_trainer'.
INFO:absl:Full user module path is 'penguin_trainer@pipelines/penguin-tfdv/_wheels/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3-none-any.whl'
INFO:absl:Using deployment config:
executor_specs {
key: "CsvExampleGen"
value {
beam_executable_spec {
python_executor_spec {
class_path: "tfx.components.example_gen.csv_example_gen.executor.Executor"
}
}
}
}
executor_specs {
key: "ExampleValidator"
value {
python_class_executable_spec {
class_path: "tfx.components.example_validator.executor.Executor"
}
}
}
executor_specs {
key: "Pusher"
value {
python_class_executable_spec {
class_path: "tfx.components.pusher.executor.Executor"
}
}
}
executor_specs {
key: "StatisticsGen"
value {
beam_executable_spec {
python_executor_spec {
class_path: "tfx.components.statistics_gen.executor.Executor"
}
}
}
}
executor_specs {
key: "Trainer"
value {
python_class_executable_spec {
class_path: "tfx.components.trainer.executor.GenericExecutor"
}
}
}
custom_driver_specs {
key: "CsvExampleGen"
value {
python_class_executable_spec {
class_path: "tfx.components.example_gen.driver.FileBasedDriver"
}
}
}
metadata_connection_config {
sqlite {
filename_uri: "metadata/penguin-tfdv/metadata.db"
connection_mode: READWRITE_OPENCREATE
}
}
INFO:absl:Using connection config:
sqlite {
filename_uri: "metadata/penguin-tfdv/metadata.db"
connection_mode: READWRITE_OPENCREATE
}
INFO:absl:Component CsvExampleGen is running.
INFO:absl:Running launcher for node_info {
type {
name: "tfx.components.example_gen.csv_example_gen.component.CsvExampleGen"
}
id: "CsvExampleGen"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.CsvExampleGen"
}
}
}
}
outputs {
outputs {
key: "examples"
value {
artifact_spec {
type {
name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
}
}
}
}
}
parameters {
parameters {
key: "input_base"
value {
field_value {
string_value: "/tmp/tfx-datan3p7t1d2"
}
}
}
parameters {
key: "input_config"
value {
field_value {
string_value: "{\n \"splits\": [\n {\n \"name\": \"single_split\",\n \"pattern\": \"*\"\n }\n ]\n}"
}
}
}
parameters {
key: "output_config"
value {
field_value {
string_value: "{\n \"split_config\": {\n \"splits\": [\n {\n \"hash_buckets\": 2,\n \"name\": \"train\"\n },\n {\n \"hash_buckets\": 1,\n \"name\": \"eval\"\n }\n ]\n }\n}"
}
}
}
parameters {
key: "output_data_format"
value {
field_value {
int_value: 6
}
}
}
parameters {
key: "output_file_format"
value {
field_value {
int_value: 5
}
}
}
}
downstream_nodes: "StatisticsGen"
downstream_nodes: "Trainer"
execution_options {
caching_options {
}
}
INFO:absl:MetadataStore with DB connection initialized
I1205 11:10:11.685647 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
I1205 11:10:11.692644 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
I1205 11:10:11.699625 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
I1205 11:10:11.708110 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
INFO:absl:select span and version = (0, None)
INFO:absl:latest span and version = (0, None)
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Going to run a new execution 1
I1205 11:10:11.722760 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
INFO:absl:Going to run a new execution: ExecutionInfo(execution_id=1, input_dict={}, output_dict=defaultdict(<class 'list'>, {'examples': [Artifact(artifact: uri: "pipelines/penguin-tfdv/CsvExampleGen/examples/1"
custom_properties {
key: "input_fingerprint"
value {
string_value: "split:single_split,num_files:1,total_bytes:25648,xor_checksum:1638702606,sum_checksum:1638702606"
}
}
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv:2021-12-05T11:10:11.667239:CsvExampleGen:examples:0"
}
}
custom_properties {
key: "span"
value {
int_value: 0
}
}
, artifact_type: name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
)]}), exec_properties={'input_base': '/tmp/tfx-datan3p7t1d2', 'input_config': '{\n "splits": [\n {\n "name": "single_split",\n "pattern": "*"\n }\n ]\n}', 'output_data_format': 6, 'output_config': '{\n "split_config": {\n "splits": [\n {\n "hash_buckets": 2,\n "name": "train"\n },\n {\n "hash_buckets": 1,\n "name": "eval"\n }\n ]\n }\n}', 'output_file_format': 5, 'span': 0, 'version': None, 'input_fingerprint': 'split:single_split,num_files:1,total_bytes:25648,xor_checksum:1638702606,sum_checksum:1638702606'}, execution_output_uri='pipelines/penguin-tfdv/CsvExampleGen/.system/executor_execution/1/executor_output.pb', stateful_working_dir='pipelines/penguin-tfdv/CsvExampleGen/.system/stateful_working_dir/2021-12-05T11:10:11.667239', tmp_dir='pipelines/penguin-tfdv/CsvExampleGen/.system/executor_execution/1/.temp/', pipeline_node=node_info {
type {
name: "tfx.components.example_gen.csv_example_gen.component.CsvExampleGen"
}
id: "CsvExampleGen"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.CsvExampleGen"
}
}
}
}
outputs {
outputs {
key: "examples"
value {
artifact_spec {
type {
name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
}
}
}
}
}
parameters {
parameters {
key: "input_base"
value {
field_value {
string_value: "/tmp/tfx-datan3p7t1d2"
}
}
}
parameters {
key: "input_config"
value {
field_value {
string_value: "{\n \"splits\": [\n {\n \"name\": \"single_split\",\n \"pattern\": \"*\"\n }\n ]\n}"
}
}
}
parameters {
key: "output_config"
value {
field_value {
string_value: "{\n \"split_config\": {\n \"splits\": [\n {\n \"hash_buckets\": 2,\n \"name\": \"train\"\n },\n {\n \"hash_buckets\": 1,\n \"name\": \"eval\"\n }\n ]\n }\n}"
}
}
}
parameters {
key: "output_data_format"
value {
field_value {
int_value: 6
}
}
}
parameters {
key: "output_file_format"
value {
field_value {
int_value: 5
}
}
}
}
downstream_nodes: "StatisticsGen"
downstream_nodes: "Trainer"
execution_options {
caching_options {
}
}
, pipeline_info=id: "penguin-tfdv"
, pipeline_run_id='2021-12-05T11:10:11.667239')
INFO:absl:Generating examples.
INFO:absl:Processing input csv data /tmp/tfx-datan3p7t1d2/* to TFExample.
running bdist_wheel
running build
running build_py
creating build
creating build/lib
copying penguin_trainer.py -> build/lib
installing to /tmp/tmp6_kn7s87
running install
running install_lib
copying build/lib/penguin_trainer.py -> /tmp/tmp6_kn7s87
running install_egg_info
running egg_info
creating tfx_user_code_Trainer.egg-info
writing tfx_user_code_Trainer.egg-info/PKG-INFO
writing dependency_links to tfx_user_code_Trainer.egg-info/dependency_links.txt
writing top-level names to tfx_user_code_Trainer.egg-info/top_level.txt
writing manifest file 'tfx_user_code_Trainer.egg-info/SOURCES.txt'
reading manifest file 'tfx_user_code_Trainer.egg-info/SOURCES.txt'
writing manifest file 'tfx_user_code_Trainer.egg-info/SOURCES.txt'
Copying tfx_user_code_Trainer.egg-info to /tmp/tmp6_kn7s87/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3.7.egg-info
running install_scripts
creating /tmp/tmp6_kn7s87/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2.dist-info/WHEEL
creating '/tmp/tmpwt7plki0/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3-none-any.whl' and adding '/tmp/tmp6_kn7s87' to it
adding 'penguin_trainer.py'
adding 'tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2.dist-info/METADATA'
adding 'tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2.dist-info/WHEEL'
adding 'tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2.dist-info/top_level.txt'
adding 'tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2.dist-info/RECORD'
removing /tmp/tmp6_kn7s87
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
INFO:absl:Examples generated.
INFO:absl:Cleaning up stateless execution info.
INFO:absl:Execution 1 succeeded.
INFO:absl:Cleaning up stateful execution info.
INFO:absl:Publishing output artifacts defaultdict(<class 'list'>, {'examples': [Artifact(artifact: uri: "pipelines/penguin-tfdv/CsvExampleGen/examples/1"
custom_properties {
key: "input_fingerprint"
value {
string_value: "split:single_split,num_files:1,total_bytes:25648,xor_checksum:1638702606,sum_checksum:1638702606"
}
}
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv:2021-12-05T11:10:11.667239:CsvExampleGen:examples:0"
}
}
custom_properties {
key: "span"
value {
int_value: 0
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.4.0"
}
}
, artifact_type: name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
)]}) for execution 1
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Component CsvExampleGen is finished.
INFO:absl:Component schema_importer is running.
INFO:absl:Running launcher for node_info {
type {
name: "tfx.dsl.components.common.importer.Importer"
}
id: "schema_importer"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.schema_importer"
}
}
}
}
outputs {
outputs {
key: "result"
value {
artifact_spec {
type {
name: "Schema"
}
}
}
}
}
parameters {
parameters {
key: "artifact_uri"
value {
field_value {
string_value: "schema"
}
}
}
parameters {
key: "reimport"
value {
field_value {
int_value: 0
}
}
}
}
downstream_nodes: "ExampleValidator"
downstream_nodes: "Trainer"
execution_options {
caching_options {
}
}
INFO:absl:Running as an importer node.
INFO:absl:MetadataStore with DB connection initialized
I1205 11:10:12.796727 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
INFO:absl:Processing source uri: schema, properties: {}, custom_properties: {}
INFO:absl:Component schema_importer is finished.
I1205 11:10:12.806819 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
INFO:absl:Component StatisticsGen is running.
INFO:absl:Running launcher for node_info {
type {
name: "tfx.components.statistics_gen.component.StatisticsGen"
}
id: "StatisticsGen"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.StatisticsGen"
}
}
}
}
inputs {
inputs {
key: "examples"
value {
channels {
producer_node_query {
id: "CsvExampleGen"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.CsvExampleGen"
}
}
}
artifact_query {
type {
name: "Examples"
}
}
output_key: "examples"
}
min_count: 1
}
}
}
outputs {
outputs {
key: "statistics"
value {
artifact_spec {
type {
name: "ExampleStatistics"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
}
}
}
}
}
parameters {
parameters {
key: "exclude_splits"
value {
field_value {
string_value: "[]"
}
}
}
}
upstream_nodes: "CsvExampleGen"
downstream_nodes: "ExampleValidator"
execution_options {
caching_options {
}
}
INFO:absl:MetadataStore with DB connection initialized
I1205 11:10:12.827589 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Going to run a new execution 3
INFO:absl:Going to run a new execution: ExecutionInfo(execution_id=3, input_dict={'examples': [Artifact(artifact: id: 1
type_id: 15
uri: "pipelines/penguin-tfdv/CsvExampleGen/examples/1"
properties {
key: "split_names"
value {
string_value: "[\"train\", \"eval\"]"
}
}
custom_properties {
key: "file_format"
value {
string_value: "tfrecords_gzip"
}
}
custom_properties {
key: "input_fingerprint"
value {
string_value: "split:single_split,num_files:1,total_bytes:25648,xor_checksum:1638702606,sum_checksum:1638702606"
}
}
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv:2021-12-05T11:10:11.667239:CsvExampleGen:examples:0"
}
}
custom_properties {
key: "payload_format"
value {
string_value: "FORMAT_TF_EXAMPLE"
}
}
custom_properties {
key: "span"
value {
int_value: 0
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.4.0"
}
}
state: LIVE
create_time_since_epoch: 1638702612780
last_update_time_since_epoch: 1638702612780
, artifact_type: id: 15
name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
)]}, output_dict=defaultdict(<class 'list'>, {'statistics': [Artifact(artifact: uri: "pipelines/penguin-tfdv/StatisticsGen/statistics/3"
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv:2021-12-05T11:10:11.667239:StatisticsGen:statistics:0"
}
}
, artifact_type: name: "ExampleStatistics"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
)]}), exec_properties={'exclude_splits': '[]'}, execution_output_uri='pipelines/penguin-tfdv/StatisticsGen/.system/executor_execution/3/executor_output.pb', stateful_working_dir='pipelines/penguin-tfdv/StatisticsGen/.system/stateful_working_dir/2021-12-05T11:10:11.667239', tmp_dir='pipelines/penguin-tfdv/StatisticsGen/.system/executor_execution/3/.temp/', pipeline_node=node_info {
type {
name: "tfx.components.statistics_gen.component.StatisticsGen"
}
id: "StatisticsGen"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.StatisticsGen"
}
}
}
}
inputs {
inputs {
key: "examples"
value {
channels {
producer_node_query {
id: "CsvExampleGen"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.CsvExampleGen"
}
}
}
artifact_query {
type {
name: "Examples"
}
}
output_key: "examples"
}
min_count: 1
}
}
}
outputs {
outputs {
key: "statistics"
value {
artifact_spec {
type {
name: "ExampleStatistics"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
}
}
}
}
}
parameters {
parameters {
key: "exclude_splits"
value {
field_value {
string_value: "[]"
}
}
}
}
upstream_nodes: "CsvExampleGen"
downstream_nodes: "ExampleValidator"
execution_options {
caching_options {
}
}
, pipeline_info=id: "penguin-tfdv"
, pipeline_run_id='2021-12-05T11:10:11.667239')
INFO:absl:Generating statistics for split train.
INFO:absl:Statistics for split train written to pipelines/penguin-tfdv/StatisticsGen/statistics/3/Split-train.
INFO:absl:Generating statistics for split eval.
INFO:absl:Statistics for split eval written to pipelines/penguin-tfdv/StatisticsGen/statistics/3/Split-eval.
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
INFO:absl:Cleaning up stateless execution info.
INFO:absl:Execution 3 succeeded.
INFO:absl:Cleaning up stateful execution info.
INFO:absl:Publishing output artifacts defaultdict(<class 'list'>, {'statistics': [Artifact(artifact: uri: "pipelines/penguin-tfdv/StatisticsGen/statistics/3"
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv:2021-12-05T11:10:11.667239:StatisticsGen:statistics:0"
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.4.0"
}
}
, artifact_type: name: "ExampleStatistics"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
)]}) for execution 3
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Component StatisticsGen is finished.
INFO:absl:Component Trainer is running.
INFO:absl:Running launcher for node_info {
type {
name: "tfx.components.trainer.component.Trainer"
}
id: "Trainer"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.Trainer"
}
}
}
}
inputs {
inputs {
key: "examples"
value {
channels {
producer_node_query {
id: "CsvExampleGen"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.CsvExampleGen"
}
}
}
artifact_query {
type {
name: "Examples"
}
}
output_key: "examples"
}
min_count: 1
}
}
inputs {
key: "schema"
value {
channels {
producer_node_query {
id: "schema_importer"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.schema_importer"
}
}
}
artifact_query {
type {
name: "Schema"
}
}
output_key: "result"
}
}
}
}
outputs {
outputs {
key: "model"
value {
artifact_spec {
type {
name: "Model"
}
}
}
}
outputs {
key: "model_run"
value {
artifact_spec {
type {
name: "ModelRun"
}
}
}
}
}
parameters {
parameters {
key: "custom_config"
value {
field_value {
string_value: "null"
}
}
}
parameters {
key: "eval_args"
value {
field_value {
string_value: "{\n \"num_steps\": 5\n}"
}
}
}
parameters {
key: "module_path"
value {
field_value {
string_value: "penguin_trainer@pipelines/penguin-tfdv/_wheels/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3-none-any.whl"
}
}
}
parameters {
key: "train_args"
value {
field_value {
string_value: "{\n \"num_steps\": 100\n}"
}
}
}
}
upstream_nodes: "CsvExampleGen"
upstream_nodes: "schema_importer"
downstream_nodes: "Pusher"
execution_options {
caching_options {
}
}
INFO:absl:MetadataStore with DB connection initialized
I1205 11:10:15.426606 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Going to run a new execution 4
INFO:absl:Going to run a new execution: ExecutionInfo(execution_id=4, input_dict={'examples': [Artifact(artifact: id: 1
type_id: 15
uri: "pipelines/penguin-tfdv/CsvExampleGen/examples/1"
properties {
key: "split_names"
value {
string_value: "[\"train\", \"eval\"]"
}
}
custom_properties {
key: "file_format"
value {
string_value: "tfrecords_gzip"
}
}
custom_properties {
key: "input_fingerprint"
value {
string_value: "split:single_split,num_files:1,total_bytes:25648,xor_checksum:1638702606,sum_checksum:1638702606"
}
}
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv:2021-12-05T11:10:11.667239:CsvExampleGen:examples:0"
}
}
custom_properties {
key: "payload_format"
value {
string_value: "FORMAT_TF_EXAMPLE"
}
}
custom_properties {
key: "span"
value {
int_value: 0
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.4.0"
}
}
state: LIVE
create_time_since_epoch: 1638702612780
last_update_time_since_epoch: 1638702612780
, artifact_type: id: 15
name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
)], 'schema': [Artifact(artifact: id: 2
type_id: 17
uri: "schema"
custom_properties {
key: "tfx_version"
value {
string_value: "1.4.0"
}
}
state: LIVE
create_time_since_epoch: 1638702612810
last_update_time_since_epoch: 1638702612810
, artifact_type: id: 17
name: "Schema"
)]}, output_dict=defaultdict(<class 'list'>, {'model_run': [Artifact(artifact: uri: "pipelines/penguin-tfdv/Trainer/model_run/4"
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv:2021-12-05T11:10:11.667239:Trainer:model_run:0"
}
}
, artifact_type: name: "ModelRun"
)], 'model': [Artifact(artifact: uri: "pipelines/penguin-tfdv/Trainer/model/4"
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv:2021-12-05T11:10:11.667239:Trainer:model:0"
}
}
, artifact_type: name: "Model"
)]}), exec_properties={'eval_args': '{\n "num_steps": 5\n}', 'module_path': 'penguin_trainer@pipelines/penguin-tfdv/_wheels/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3-none-any.whl', 'custom_config': 'null', 'train_args': '{\n "num_steps": 100\n}'}, execution_output_uri='pipelines/penguin-tfdv/Trainer/.system/executor_execution/4/executor_output.pb', stateful_working_dir='pipelines/penguin-tfdv/Trainer/.system/stateful_working_dir/2021-12-05T11:10:11.667239', tmp_dir='pipelines/penguin-tfdv/Trainer/.system/executor_execution/4/.temp/', pipeline_node=node_info {
type {
name: "tfx.components.trainer.component.Trainer"
}
id: "Trainer"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.Trainer"
}
}
}
}
inputs {
inputs {
key: "examples"
value {
channels {
producer_node_query {
id: "CsvExampleGen"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.CsvExampleGen"
}
}
}
artifact_query {
type {
name: "Examples"
}
}
output_key: "examples"
}
min_count: 1
}
}
inputs {
key: "schema"
value {
channels {
producer_node_query {
id: "schema_importer"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.schema_importer"
}
}
}
artifact_query {
type {
name: "Schema"
}
}
output_key: "result"
}
}
}
}
outputs {
outputs {
key: "model"
value {
artifact_spec {
type {
name: "Model"
}
}
}
}
outputs {
key: "model_run"
value {
artifact_spec {
type {
name: "ModelRun"
}
}
}
}
}
parameters {
parameters {
key: "custom_config"
value {
field_value {
string_value: "null"
}
}
}
parameters {
key: "eval_args"
value {
field_value {
string_value: "{\n \"num_steps\": 5\n}"
}
}
}
parameters {
key: "module_path"
value {
field_value {
string_value: "penguin_trainer@pipelines/penguin-tfdv/_wheels/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3-none-any.whl"
}
}
}
parameters {
key: "train_args"
value {
field_value {
string_value: "{\n \"num_steps\": 100\n}"
}
}
}
}
upstream_nodes: "CsvExampleGen"
upstream_nodes: "schema_importer"
downstream_nodes: "Pusher"
execution_options {
caching_options {
}
}
, pipeline_info=id: "penguin-tfdv"
, pipeline_run_id='2021-12-05T11:10:11.667239')
INFO:absl:Train on the 'train' split when train_args.splits is not set.
INFO:absl:Evaluate on the 'eval' split when eval_args.splits is not set.
INFO:absl:udf_utils.get_fn {'eval_args': '{\n "num_steps": 5\n}', 'module_path': 'penguin_trainer@pipelines/penguin-tfdv/_wheels/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3-none-any.whl', 'custom_config': 'null', 'train_args': '{\n "num_steps": 100\n}'} 'run_fn'
INFO:absl:Installing 'pipelines/penguin-tfdv/_wheels/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3-none-any.whl' to a temporary directory.
INFO:absl:Executing: ['/tmpfs/src/tf_docs_env/bin/python', '-m', 'pip', 'install', '--target', '/tmp/tmpbb1l9_v7', 'pipelines/penguin-tfdv/_wheels/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3-none-any.whl']
Processing ./pipelines/penguin-tfdv/_wheels/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3-none-any.whl
INFO:absl:Successfully installed 'pipelines/penguin-tfdv/_wheels/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3-none-any.whl'.
INFO:absl:Training model.
INFO:absl:Feature body_mass_g has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature culmen_depth_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature culmen_length_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature flipper_length_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature species has a shape dim {
size: 1
}
. Setting to DenseTensor.
Installing collected packages: tfx-user-code-Trainer
Successfully installed tfx-user-code-Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2
INFO:absl:Feature body_mass_g has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature culmen_depth_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature culmen_length_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature flipper_length_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature species has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature body_mass_g has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature culmen_depth_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature culmen_length_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature flipper_length_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature species has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature body_mass_g has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature culmen_depth_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature culmen_length_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature flipper_length_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature species has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Model: "model"
INFO:absl:__________________________________________________________________________________________________
INFO:absl:Layer (type) Output Shape Param # Connected to
INFO:absl:==================================================================================================
INFO:absl:body_mass_g (InputLayer) [(None, 1)] 0
INFO:absl:__________________________________________________________________________________________________
INFO:absl:culmen_depth_mm (InputLayer) [(None, 1)] 0
INFO:absl:__________________________________________________________________________________________________
INFO:absl:culmen_length_mm (InputLayer) [(None, 1)] 0
INFO:absl:__________________________________________________________________________________________________
INFO:absl:flipper_length_mm (InputLayer) [(None, 1)] 0
INFO:absl:__________________________________________________________________________________________________
INFO:absl:concatenate (Concatenate) (None, 4) 0 body_mass_g[0][0]
INFO:absl: culmen_depth_mm[0][0]
INFO:absl: culmen_length_mm[0][0]
INFO:absl: flipper_length_mm[0][0]
INFO:absl:__________________________________________________________________________________________________
INFO:absl:dense (Dense) (None, 8) 40 concatenate[0][0]
INFO:absl:__________________________________________________________________________________________________
INFO:absl:dense_1 (Dense) (None, 8) 72 dense[0][0]
INFO:absl:__________________________________________________________________________________________________
INFO:absl:dense_2 (Dense) (None, 3) 27 dense_1[0][0]
INFO:absl:==================================================================================================
INFO:absl:Total params: 139
INFO:absl:Trainable params: 139
INFO:absl:Non-trainable params: 0
INFO:absl:__________________________________________________________________________________________________
100/100 [==============================] - 1s 3ms/step - loss: 0.5752 - sparse_categorical_accuracy: 0.8165 - val_loss: 0.2294 - val_sparse_categorical_accuracy: 0.9400
2021-12-05 11:10:20.208161: W tensorflow/python/util/util.cc:348] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
INFO:tensorflow:Assets written to: pipelines/penguin-tfdv/Trainer/model/4/Format-Serving/assets
INFO:tensorflow:Assets written to: pipelines/penguin-tfdv/Trainer/model/4/Format-Serving/assets
INFO:absl:Training complete. Model written to pipelines/penguin-tfdv/Trainer/model/4/Format-Serving. ModelRun written to pipelines/penguin-tfdv/Trainer/model_run/4
INFO:absl:Cleaning up stateless execution info.
INFO:absl:Execution 4 succeeded.
INFO:absl:Cleaning up stateful execution info.
INFO:absl:Publishing output artifacts defaultdict(<class 'list'>, {'model_run': [Artifact(artifact: uri: "pipelines/penguin-tfdv/Trainer/model_run/4"
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv:2021-12-05T11:10:11.667239:Trainer:model_run:0"
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.4.0"
}
}
, artifact_type: name: "ModelRun"
)], 'model': [Artifact(artifact: uri: "pipelines/penguin-tfdv/Trainer/model/4"
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv:2021-12-05T11:10:11.667239:Trainer:model:0"
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.4.0"
}
}
, artifact_type: name: "Model"
)]}) for execution 4
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Component Trainer is finished.
I1205 11:10:20.766410 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
I1205 11:10:20.770478 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
INFO:absl:Component ExampleValidator is running.
INFO:absl:Running launcher for node_info {
type {
name: "tfx.components.example_validator.component.ExampleValidator"
}
id: "ExampleValidator"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.ExampleValidator"
}
}
}
}
inputs {
inputs {
key: "schema"
value {
channels {
producer_node_query {
id: "schema_importer"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.schema_importer"
}
}
}
artifact_query {
type {
name: "Schema"
}
}
output_key: "result"
}
min_count: 1
}
}
inputs {
key: "statistics"
value {
channels {
producer_node_query {
id: "StatisticsGen"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.StatisticsGen"
}
}
}
artifact_query {
type {
name: "ExampleStatistics"
}
}
output_key: "statistics"
}
min_count: 1
}
}
}
outputs {
outputs {
key: "anomalies"
value {
artifact_spec {
type {
name: "ExampleAnomalies"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
}
}
}
}
}
parameters {
parameters {
key: "exclude_splits"
value {
field_value {
string_value: "[]"
}
}
}
}
upstream_nodes: "StatisticsGen"
upstream_nodes: "schema_importer"
execution_options {
caching_options {
}
}
INFO:absl:MetadataStore with DB connection initialized
I1205 11:10:20.793696 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Going to run a new execution 5
INFO:absl:Going to run a new execution: ExecutionInfo(execution_id=5, input_dict={'statistics': [Artifact(artifact: id: 3
type_id: 19
uri: "pipelines/penguin-tfdv/StatisticsGen/statistics/3"
properties {
key: "split_names"
value {
string_value: "[\"train\", \"eval\"]"
}
}
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv:2021-12-05T11:10:11.667239:StatisticsGen:statistics:0"
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.4.0"
}
}
state: LIVE
create_time_since_epoch: 1638702615406
last_update_time_since_epoch: 1638702615406
, artifact_type: id: 19
name: "ExampleStatistics"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
)], 'schema': [Artifact(artifact: id: 2
type_id: 17
uri: "schema"
custom_properties {
key: "tfx_version"
value {
string_value: "1.4.0"
}
}
state: LIVE
create_time_since_epoch: 1638702612810
last_update_time_since_epoch: 1638702612810
, artifact_type: id: 17
name: "Schema"
)]}, output_dict=defaultdict(<class 'list'>, {'anomalies': [Artifact(artifact: uri: "pipelines/penguin-tfdv/ExampleValidator/anomalies/5"
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv:2021-12-05T11:10:11.667239:ExampleValidator:anomalies:0"
}
}
, artifact_type: name: "ExampleAnomalies"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
)]}), exec_properties={'exclude_splits': '[]'}, execution_output_uri='pipelines/penguin-tfdv/ExampleValidator/.system/executor_execution/5/executor_output.pb', stateful_working_dir='pipelines/penguin-tfdv/ExampleValidator/.system/stateful_working_dir/2021-12-05T11:10:11.667239', tmp_dir='pipelines/penguin-tfdv/ExampleValidator/.system/executor_execution/5/.temp/', pipeline_node=node_info {
type {
name: "tfx.components.example_validator.component.ExampleValidator"
}
id: "ExampleValidator"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.ExampleValidator"
}
}
}
}
inputs {
inputs {
key: "schema"
value {
channels {
producer_node_query {
id: "schema_importer"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.schema_importer"
}
}
}
artifact_query {
type {
name: "Schema"
}
}
output_key: "result"
}
min_count: 1
}
}
inputs {
key: "statistics"
value {
channels {
producer_node_query {
id: "StatisticsGen"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.StatisticsGen"
}
}
}
artifact_query {
type {
name: "ExampleStatistics"
}
}
output_key: "statistics"
}
min_count: 1
}
}
}
outputs {
outputs {
key: "anomalies"
value {
artifact_spec {
type {
name: "ExampleAnomalies"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
}
}
}
}
}
parameters {
parameters {
key: "exclude_splits"
value {
field_value {
string_value: "[]"
}
}
}
}
upstream_nodes: "StatisticsGen"
upstream_nodes: "schema_importer"
execution_options {
caching_options {
}
}
, pipeline_info=id: "penguin-tfdv"
, pipeline_run_id='2021-12-05T11:10:11.667239')
INFO:absl:Validating schema against the computed statistics for split train.
INFO:absl:Validation complete for split train. Anomalies written to pipelines/penguin-tfdv/ExampleValidator/anomalies/5/Split-train.
INFO:absl:Validating schema against the computed statistics for split eval.
INFO:absl:Validation complete for split eval. Anomalies written to pipelines/penguin-tfdv/ExampleValidator/anomalies/5/Split-eval.
INFO:absl:Cleaning up stateless execution info.
INFO:absl:Execution 5 succeeded.
INFO:absl:Cleaning up stateful execution info.
INFO:absl:Publishing output artifacts defaultdict(<class 'list'>, {'anomalies': [Artifact(artifact: uri: "pipelines/penguin-tfdv/ExampleValidator/anomalies/5"
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv:2021-12-05T11:10:11.667239:ExampleValidator:anomalies:0"
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.4.0"
}
}
, artifact_type: name: "ExampleAnomalies"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
)]}) for execution 5
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Component ExampleValidator is finished.
INFO:absl:Component Pusher is running.
INFO:absl:Running launcher for node_info {
type {
name: "tfx.components.pusher.component.Pusher"
}
id: "Pusher"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.Pusher"
}
}
}
}
inputs {
inputs {
key: "model"
value {
channels {
producer_node_query {
id: "Trainer"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.Trainer"
}
}
}
artifact_query {
type {
name: "Model"
}
}
output_key: "model"
}
}
}
}
outputs {
outputs {
key: "pushed_model"
value {
artifact_spec {
type {
name: "PushedModel"
}
}
}
}
}
parameters {
parameters {
key: "custom_config"
value {
field_value {
string_value: "null"
}
}
}
parameters {
key: "push_destination"
value {
field_value {
string_value: "{\n \"filesystem\": {\n \"base_directory\": \"serving_model/penguin-tfdv\"\n }\n}"
}
}
}
}
upstream_nodes: "Trainer"
execution_options {
caching_options {
}
}
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:MetadataStore with DB connection initialized
I1205 11:10:20.848567 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
INFO:absl:Going to run a new execution 6
INFO:absl:Going to run a new execution: ExecutionInfo(execution_id=6, input_dict={'model': [Artifact(artifact: id: 5
type_id: 22
uri: "pipelines/penguin-tfdv/Trainer/model/4"
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv:2021-12-05T11:10:11.667239:Trainer:model:0"
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.4.0"
}
}
state: LIVE
create_time_since_epoch: 1638702620774
last_update_time_since_epoch: 1638702620774
, artifact_type: id: 22
name: "Model"
)]}, output_dict=defaultdict(<class 'list'>, {'pushed_model': [Artifact(artifact: uri: "pipelines/penguin-tfdv/Pusher/pushed_model/6"
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv:2021-12-05T11:10:11.667239:Pusher:pushed_model:0"
}
}
, artifact_type: name: "PushedModel"
)]}), exec_properties={'push_destination': '{\n "filesystem": {\n "base_directory": "serving_model/penguin-tfdv"\n }\n}', 'custom_config': 'null'}, execution_output_uri='pipelines/penguin-tfdv/Pusher/.system/executor_execution/6/executor_output.pb', stateful_working_dir='pipelines/penguin-tfdv/Pusher/.system/stateful_working_dir/2021-12-05T11:10:11.667239', tmp_dir='pipelines/penguin-tfdv/Pusher/.system/executor_execution/6/.temp/', pipeline_node=node_info {
type {
name: "tfx.components.pusher.component.Pusher"
}
id: "Pusher"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.Pusher"
}
}
}
}
inputs {
inputs {
key: "model"
value {
channels {
producer_node_query {
id: "Trainer"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2021-12-05T11:10:11.667239"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.Trainer"
}
}
}
artifact_query {
type {
name: "Model"
}
}
output_key: "model"
}
}
}
}
outputs {
outputs {
key: "pushed_model"
value {
artifact_spec {
type {
name: "PushedModel"
}
}
}
}
}
parameters {
parameters {
key: "custom_config"
value {
field_value {
string_value: "null"
}
}
}
parameters {
key: "push_destination"
value {
field_value {
string_value: "{\n \"filesystem\": {\n \"base_directory\": \"serving_model/penguin-tfdv\"\n }\n}"
}
}
}
}
upstream_nodes: "Trainer"
execution_options {
caching_options {
}
}
, pipeline_info=id: "penguin-tfdv"
, pipeline_run_id='2021-12-05T11:10:11.667239')
WARNING:absl:Pusher is going to push the model without validation. Consider using Evaluator or InfraValidator in your pipeline.
INFO:absl:Model version: 1638702620
INFO:absl:Model written to serving path serving_model/penguin-tfdv/1638702620.
INFO:absl:Model pushed to pipelines/penguin-tfdv/Pusher/pushed_model/6.
INFO:absl:Cleaning up stateless execution info.
INFO:absl:Execution 6 succeeded.
INFO:absl:Cleaning up stateful execution info.
INFO:absl:Publishing output artifacts defaultdict(<class 'list'>, {'pushed_model': [Artifact(artifact: uri: "pipelines/penguin-tfdv/Pusher/pushed_model/6"
custom_properties {
key: "name"
value {
string_value: "penguin-tfdv:2021-12-05T11:10:11.667239:Pusher:pushed_model:0"
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.4.0"
}
}
, artifact_type: name: "PushedModel"
)]}) for execution 6
INFO:absl:MetadataStore with DB connection initialized
I1205 11:10:20.879335 4006 rdbms_metadata_access_object.cc:686] No property is defined for the Type
INFO:absl:Component Pusher is finished.
Você deverá ver "INFO: absl: Component Pusher is completed." se o pipeline foi concluído com sucesso.
Examine as saídas do pipeline
Treinamos o modelo de classificação para pinguins e também validamos os exemplos de entrada no componente ExampleValidator. Podemos analisar a saída de ExampleValidator como fizemos com o pipeline anterior.
metadata_connection_config = tfx.orchestration.metadata.sqlite_metadata_connection_config(
METADATA_PATH)
with Metadata(metadata_connection_config) as metadata_handler:
ev_output = get_latest_artifacts(metadata_handler, PIPELINE_NAME,
'ExampleValidator')
anomalies_artifacts = ev_output[standard_component_specs.ANOMALIES_KEY]
INFO:absl:MetadataStore with DB connection initialized
ExampleAnomalies do ExampleValidator também podem ser visualizados.
visualize_artifacts(anomalies_artifacts)
Você deve ver "Nenhuma anomalia encontrada" para cada divisão de exemplos. Como usamos os mesmos dados que foram usados para a geração do esquema neste pipeline, nenhuma anomalia é esperada aqui. Se você executar este pipeline repetidamente com novos dados de entrada, ExampleValidator deverá ser capaz de encontrar quaisquer discrepâncias entre os novos dados e o esquema existente.
Se alguma anomalia foi encontrada, você pode revisar seus dados para verificar se algum exemplo não segue suas suposições. Saídas de outros componentes como StatisticsGen podem ser úteis. No entanto, quaisquer anomalias encontradas NÃO bloquearão outras execuções do pipeline.
Próximos passos
Você pode encontrar mais recursos sobre https://www.tensorflow.org/tfx/tutorials
Consulte Compreender TFX Pipelines para aprender mais sobre vários conceitos em TFX.